Grouped Query Attention (GQA) is an optimization technique for transformer models that balances computational efficiency and model performance. Inspired by the multi-head attention mechanism introduced in the seminal "Attention Is All You Need" paper, GQA addresses limitations of its predecessors: multi-head attention (MHA) and multi-query attention (MQA). Below is a detailed analysis of its architecture, benchmarks and tradeoffs.
Core Architecture
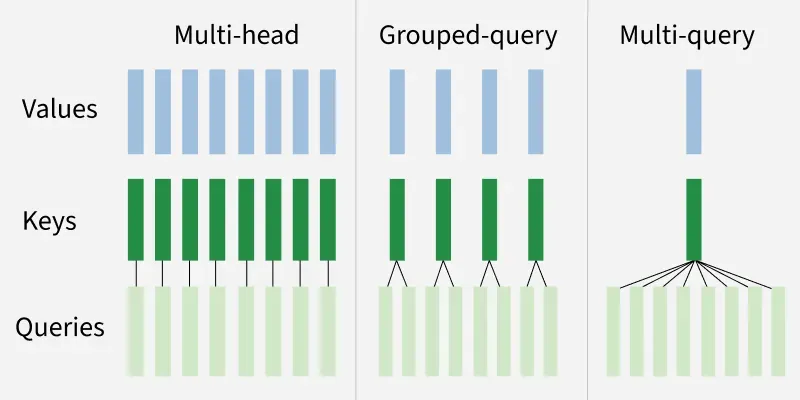
GQA divides query heads into G groups, each sharing a single key and value head. This contrasts with:
- MHA: Each query head has unique key/value heads (high accuracy, high memory cost).
- MQA: All query heads share one key/value head (lower memory cost, reduced accuracy).
The attention computation follows these steps:
1. Query-Key Dot Product: For each query group, compute dot products between queries and shared keys:
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V
where
2. Softmax Normalization: Apply softmax to generate attention weights.
3. Value Weighting: Multiply weights by shared value vectors to produce contextual outputs.
Performance-Cost Tradeoffs
GQA interpolates between MHA and MQA, optimizing for:
- Memory Bandwidth: Reduces KV cache size by up to 90% vs. MHA.
- Inference Speed: 30 - 40% faster than MHA while retaining near-equivalent accuracy.
- Model Quality: Outperforms MQA in tasks like summarization and long-context processing.
Benchmark Comparisons
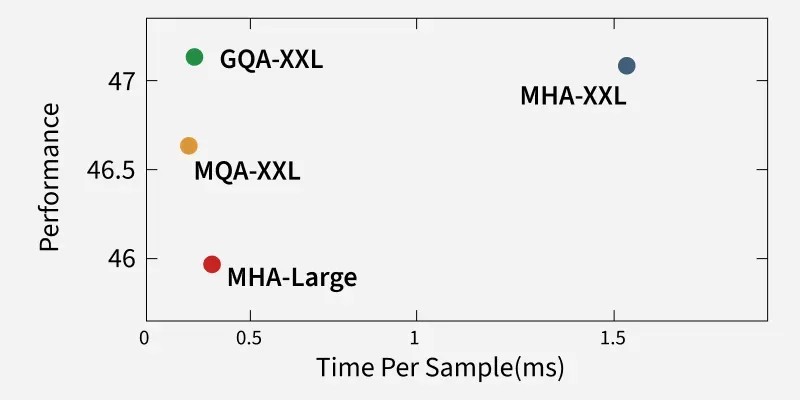
Method | KV Heads | Inference Speed | Accuracy (vs. MHA) | Memory Use |
|---|---|---|---|---|
Multi-Head (MHA) | H | Baseline | 100% | Highest |
Multi-Query (MQA) | 1 | 1.5–2× faster | ↓ 5–15% | Lowest |
GQA (G=8) | H/8 | 1.3–1.4× faster | ↓ 1–3% | Medium |
Key Advantages
1. Scalability for Long Contexts: GQA reduces memory complexity from
2. Hardware Optimization: When group count
3. Flexible Configuration: Adjusting
- Low
G (e.g., 1 -> MQA): Best for latency-critical applications. - High
G (e.g.,G=H -> MHA): Ideal for high-accuracy scenarios.
Enhancements and Limitations
- Dynamic Key Grouping (DGQA): Uses key-vector norms to allocate queries adaptively, improving accuracy by up to 8% in vision transformers.
- Suboptimal Head Configuration: Fixed grouping can underutilize hardware; recent work decouples head count from hidden dimensions for cost-optimal designs .
- Sokoban RL Limitation: While not directly applied in RL, GQA’s memory efficiency principles could optimize reward-calculation modules in game-level generators (e.g., reducing tile-editing overhead).
