LLMs, while originally designed for text-based tasks, can be fine-tuned or prompted for regression by treating the numeric prediction as a language generation problem. Regression tasks can be framed as "predict the next value" problems using either few-shot examples in prompts or by fine-tuning on structured data transformed into natural language. Embeddings from LLMs can also be extracted and passed to traditional regression models (like XGBoost or linear regression).
Key Features of Using LLMs for Regression
- Text-to-number regression via generation
- Ability to use natural language prompts
- Semantic understanding from pretrained corpora
- Strong generalization to unseen data
- Multi-modal support (text, image, etc.)
- Embedding extraction for structured data regression and Better Interpretability via attention/weights
Workflow for LLM-based Regression
Assumptions
- The LLM understands numerical format through its pretraining
- The task is formulated clearly in natural language
- Appropriate examples or fine-tuning are used for precision
Steps of Implementation
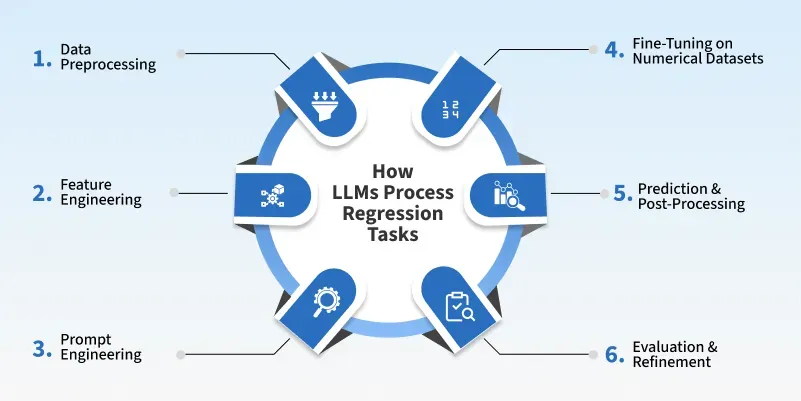
1. Problem Formulation, Data pre-processing: Convert the regression task into a natural language format
E.g., "Given features X1, X2, ..., predict Y"
2. Feature engineering and Prompt engineering
- Format input data into prompts
- Prompt Engineering can be performed using various techniques
- E.g., "Height: 180 cm, Weight: 70 kg ⇒ BMI: ? " is a way of prompting the LLM, and it returns the BMI as generated output.
3. Model Selection and Embeddings Extraction: Choose LLM to be used: GPT, Claude, LLaMA, or fine-tuned T5/BERT. Alternatively, use embeddings from LLMs and feed them to a regression model
4. Inference: Generate output and parse numerical value (may require post-processing). Apply temperature = 0 for deterministic output
5. Post-processing: Convert text/numeric tokens into float/int. Apply thresholds, rounding, or domain-specific constraints if required
6. Evaluation and Refinement: Compare outputs using metrics like MAE, RMSE, R², etc.
Techniques used in Regression
There are various ways in which LLMs can be used for regression. Some common types include:
- Prompt-based regression
- Fine-tuning for numerical output
- LLM embedding + ML regressor
- Code LLMs (for numeric programming output)
- Multimodal LLMs (for vision/text-based regression)
Let's discuss these techniques:
1. Prompt-based Regression
Use natural language prompts to ask the LLM to predict a numerical value. Works well with GPT models (e.g., OpenAI's GPT-4). No training is required; instead, inference is based on well-designed prompts.
2. Fine-tuning an LLM for Regression
Fine-tune a base model (like T5, GPT-2, or BERT) using labeled training data with numeric targets. Converts structured data into natural text format and outputs numeric predictions. Fine-tuning is done using MSE/MAE Loss and evaluated.
3. Embedding Extraction + Classical Regressor
Use LLMs or Embedding models to extract embeddings (e.g., sentence representations), then pass them to traditional regressors like XGBoost, SVR, or Linear Regression. The Regression model is fit on vectors and target values.
4. Code Generation LLM for Mathematical Regression
Ask a code-oriented LLM (like GPT-4 Code Interpreter or Code Llama) to write and execute a regression model on given data (ideal for data scientists). The generated model is executed and evaluated, and the predicted values are finally extracted.
5. Vision-Text Multimodal Regression with LLM
Use multimodal models like GPT-4V or Flamingo to take both text and image inputs and produce numeric outputs. For example, predicting car prices from images + descriptions. The models process multimodal input data, encode it and generate numeric output, which is further fine-tuned.
Sample Prompt-based Example
Prompt: "The average temperature in May in Delhi is __."
Expected Output: "36.4°C" (model-generated numeric value)
Examples of LLMs for Regression
1. GPT-4 : Can perform regression via zero/few-shot prompting. Supports numeric output through formatted text. Easy deployment, strong generalization. Not always accurate for precise numeric values. Requires training on specific tasks.
2. T5 (Text-to-Text Transfer Transformer) : Can be fine-tuned for regression tasks by formulating output as text. Fully supervised learning; customizable.
3. OpenAI Embedding Models + XGBoost : Use LLM to extract semantic embeddings, then apply classical regression model. High accuracy, interpretable pipeline. Needs good embedding-to-output mapping.
4. BERT Regression Fine-Tune : Trained with regression head for specific tasks like score prediction. High performance in NLP regression. Training is resource-intensive.
5. LLaMA 3 (Meta) : Open-source, can be trained or prompted for regression tasks. Customizable, scalable. Requires more engineering for regression handling.
Advantages of LLMs for Regression
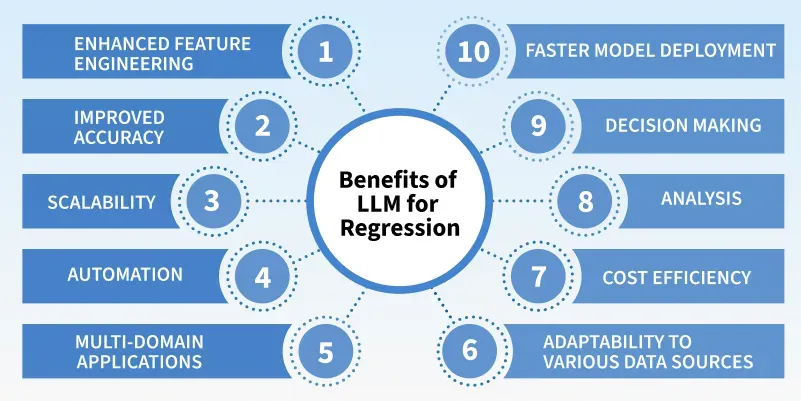
The above image demonstrates various benefits of utilizing Large Language Models for Regression.
- Natural Language Interface: Enables intuitive interaction with models for non-experts
- Rich Semantic Understanding: Handles complex inputs well
- Multi-domain Flexibility: Can work with finance, healthcare, physics, etc.
- Robust to Noisy Data: Learns patterns even with inconsistencies
- Scalability and Automation: Can be used with traditional ML models, large scale datasets, and have automated workflows
- Multimodal Support: Enables regression using image, text, etc.
Disadvantages of LLMs for Regression
- Black-box Behavior: Lacks interpretability compared to linear models
- Resource Intensive: Requires significant compute for inference or fine-tuning
- Overfitting Risk in Small Datasets: Without regularization
- Prompt Sensitivity: Output varies with tiny changes in input
- Limited Domain Fine-tuning: Generic models may underperform in niche areas
- Cost of API Usage: Paid APIs may increase operational costs
Applications of LLM-based Regression
- House Price Prediction from Listings
- Healthcare Outcome Prediction
- Stock Price Movement Forecasting
- Student Grade Prediction
- Energy Consumption Forecasting
