Overfitting occurs when a neural network learns the training data too well, resulting in poor generalization to unseen data. While techniques like dropout, weight regularization and data augmentation help reduce overfitting, one of the most effective approaches is early stopping.
Early stopping halts training once the model’s performance on a validation set stops improving, thereby preventing the network from over-optimizing on the training data.
Early Stopping
Early stopping is a regularization strategy that monitors the model’s performance on a validation set during training. When the validation loss stops decreasing for a specified number of epochs (called patience) then training is paused. The goal is to capture the model at the point where it performs best on unseen data.
Rather than training until a fixed number of epochs, early stopping uses feedback from validation performance to prevent overfitting.
Key Benefits of Early Stopping
- Prevents Overfitting: Stops training once the model starts overfitting as indicated by increasing validation loss.
- Reduces Training Time: Saves computational resources by avoiding unnecessary epochs.
- Improves Generalization: Models trained with early stopping often perform better on real-world data.
- Simple to Implement: Requires minimal configuration and no changes to model architecture.
Example: Early Stopping on MNIST Dataset
To demonstrate early stopping, we will train two neural networks on the MNIST dataset, one with early stopping and one without it and compare their performance.
Step 1: Load and Preprocess the Data
The MNIST dataset consists of 28x28 grayscale images of handwritten digits (0–9). Pixel values are normalized to the range [0, 1] for stable training.
import tensorflow as tf
from tensorflow.keras.datasets import mnist
# Load MNIST dataset
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Normalize pixel values
x_train, x_test = x_train / 255.0, x_test / 255.0
Step 2: Define and Compile the Models
We define two models with identical architectures using Keras’ Sequential API:
- Input layer flattens the image.
- Dense hidden layer with ReLU activation.
- Dropout layer (rate: 0.2) to reduce overfitting.
- Output layer with softmax for multi-class classification.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Dropout
# Model without early stopping
model_without_early_stopping = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dropout(0.2),
Dense(10, activation='softmax')
])
model_without_early_stopping.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
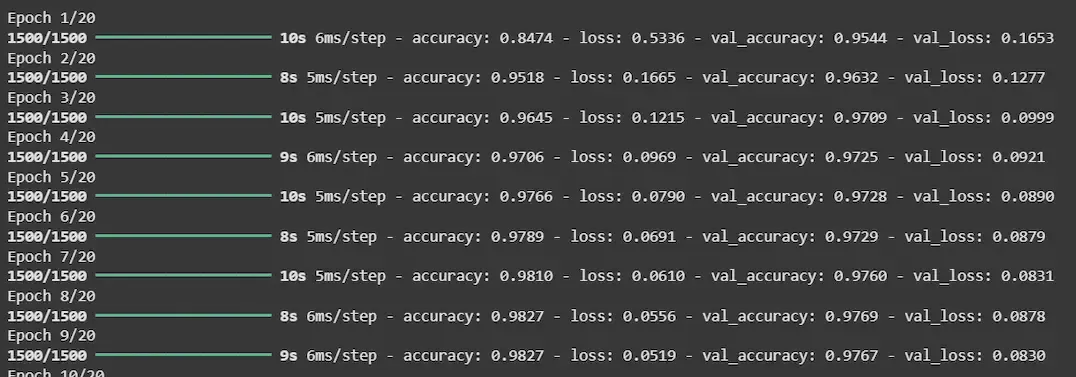
Step 3: Train Without Early Stopping
The model is trained for 20 epochs with 20% of the training data reserved for validation.
# Train model without early stopping
history_without_early_stopping = model_without_early_stopping.fit(
x_train, y_train,
epochs=20,
validation_split=0.2
)
Output:
Step 4: Train With Early Stopping
We now use Keras EarlyStopping callback to monitor validation loss and stop training if it does not improve for 3 consecutive epochs.
from tensorflow.keras.callbacks import EarlyStopping
# Define model with early stopping
model_with_early_stopping = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dropout(0.2),
Dense(10, activation='softmax')
])
model_with_early_stopping.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Set early stopping callback
early_stopping = EarlyStopping(monitor='val_loss', patience=3)
# Train with early stopping
history_with_early_stopping = model_with_early_stopping.fit(
x_train, y_train,
epochs=20,
validation_split=0.2,
callbacks=[early_stopping]
)
Output:
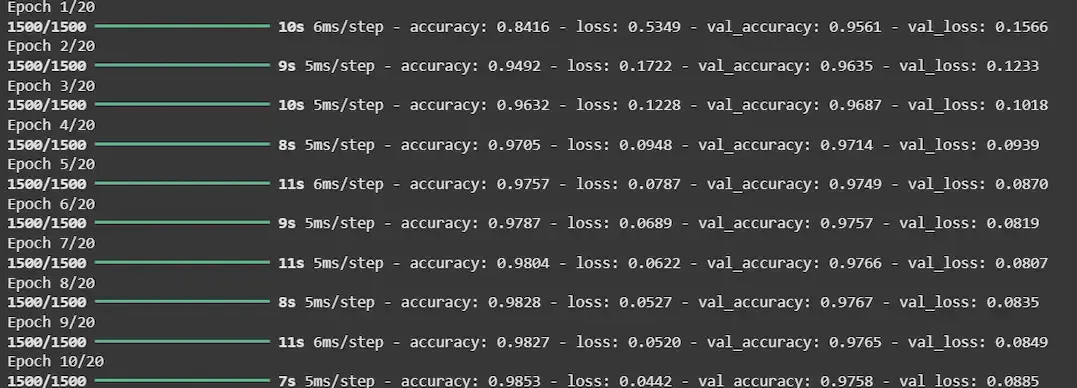
The epochs here stop on 10th iteration, due to the given condition.
Step 5: Evaluate and Compare
Finally, both models are evaluated on the test set to compare performance.
# Evaluate both models
test_loss_without, test_acc_without = model_without_early_stopping.evaluate(x_test, y_test)
test_loss_with, test_acc_with = model_with_early_stopping.evaluate(x_test, y_test)
print("Test Accuracy without Early Stopping:", test_acc_without)
print("Test Accuracy with Early Stopping:", test_acc_with)
Output:

While both models perform well, the model trained with early stopping achieves slightly better generalization and finishes training in fewer epochs.
Why Early Stopping Matters
The difference in test accuracy may appear minor, early stopping offers significant advantages in practice:
- The model trained without early stopping might continue learning noise from the training data beyond a certain point, leading to overfitting.
- Early stopping avoids this by halting training once validation performance no longer improves, resulting in a model that's more robust to unseen data.
- In large-scale models and datasets, this technique can save hours of training time while improving deployment reliability.
Early stopping is a simple technique to prevent overfitting in neural networks. It requires no changes to the model architecture and only a few lines of code to implement. By monitoring validation loss and stopping training at the right time, early stopping saves computational resources and builds more reliable models for real-world applications.
