Machine Learning enables systems to learn patterns from data and make predictions or decisions without being explicitly programmed. The Machine learning libraries provide pre-built tools and algorithms that simplify model development and improve efficiency.
- Reduce development time by providing optimized implementations of ML algorithms.
- Simplify tasks such as preprocessing, feature engineering, training, and evaluation.

1. NumPy
NumPy is a fundamental numerical computing library in Python that provides support for large, multi-dimensional arrays and matrices, along with a comprehensive collection of mathematical functions. In machine learning, it is widely used for handling numerical data, performing mathematical computations, and working with multi-dimensional arrays.
- Enables fast numerical computations and vectorized operations on datasets.
- Provides efficient array handling for large datasets and serves as the foundation for many ML libraries.
Example: Let's see an example of NumPy library with the help of movies dataset.
- Converts genre counts into numerical arrays
- Computes statistical measures like mean and standard deviation
- Helps analyze feature distribution in the dataset
import numpy as np
import pandas as pd
df = pd.read_csv("movies.csv")
genre_counts = df["genres"].apply(lambda x: len(x.split("|"))).values
genre_counts = np.array(genre_counts)
mean_genres = np.mean(genre_counts)
std_genres = np.std(genre_counts)
print(mean_genres, std_genres)
Output:
2.2668856497639087 1.1231909568458625
2. Pandas
Pandas is a high-level data analysis and manipulation library built on top of NumPy. It provides powerful data structures like DataFrame and Series that help organize, clean, and process structured data efficiently for machine learning tasks.
- Simplifies data cleaning, transformation, and exploratory data analysis.
- Handles missing, inconsistent, and categorical data efficiently.
- Integrates seamlessly with ML and visualization libraries
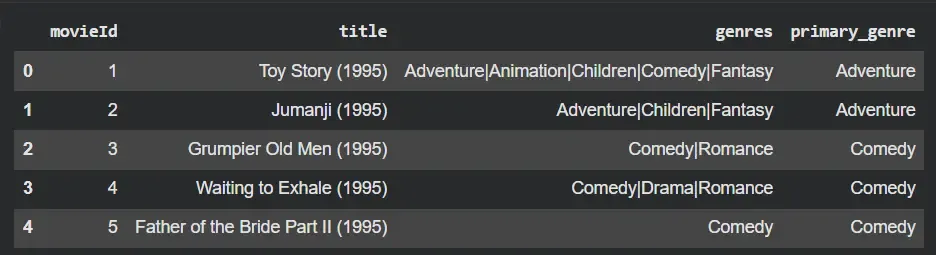
Example: Let's see an example of Pandas library.
- Handles missing genre information
- Extracts primary genre
- Prepares clean categorical feature
import pandas as pd
df = pd.read_csv("movies.csv")
df["genres"] = df["genres"].replace("(no genres listed)", "Unknown")
df["primary_genre"] = df["genres"].apply(lambda x: x.split("|")[0])
print(df.head())
Output:
3. Matplotlib
Matplotlib is a comprehensive data visualization library used to create static and interactive plots. In machine learning, it plays a critical role in understanding data distributions, detecting patterns and interpreting model performance through graphical representations.
- Helps visualize data distributions, trends, and model outputs effectively.
- Supports customizable plots for analysis and result interpretation.
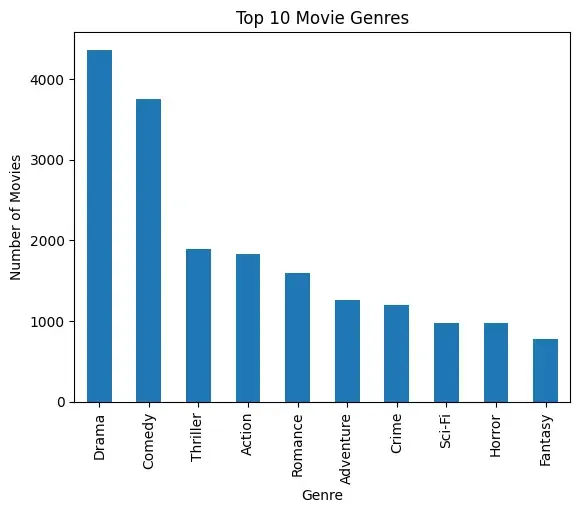
Example: Let's see an example of Matplotlib library.
- Splits multi-genre values
- Counts genre frequency
- Creates bar chart for visualization
- Highlights dominant genres in the dataset
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv("movies.csv")
genres = df["genres"].str.split("|").explode()
genre_counts = genres.value_counts().head(10)
genre_counts.plot(kind="bar")
plt.xlabel("Genre")
plt.ylabel("Number of Movies")
plt.title("Top 10 Movie Genres")
plt.show()
Output:
4. Scikit-learn
Scikit-learn is a widely used machine learning library that provides simple and efficient tools for building and evaluating machine learning models. It supports tasks such as classification, regression, clustering, preprocessing, and model evaluation.
- Provides a consistent and easy-to-use API for machine learning workflows.
- Includes tools for preprocessing, model training, testing, and evaluation.
Example: Let's see an example of scikit-learn library.
- Creates numerical feature
- Encodes categorical target
- Splits data into train and test
- Trains classification model
- Evaluates accuracy
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.linear_model import LogisticRegression
import pandas as pd
df = pd.read_csv("movies.csv")
df["genre_count"] = df["genres"].apply(lambda x: len(x.split("|")))
df["primary_genre"] = df["genres"].apply(lambda x: x.split("|")[0])
X = df[["genre_count"]]
encoder = LabelEncoder()
y = encoder.fit_transform(df["primary_genre"])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
print(model.score(X_test, y_test))
Output:
0.3771164699846075
5. TensorFlow
TensorFlow is an open-source deep learning framework developed by Google for building, training, and deploying neural network models. It is widely used for large-scale machine learning and deep learning applications.
- Supports scalable deep learning with GPU and distributed training capabilities.
- Provides flexible APIs for designing and training neural network architectures.
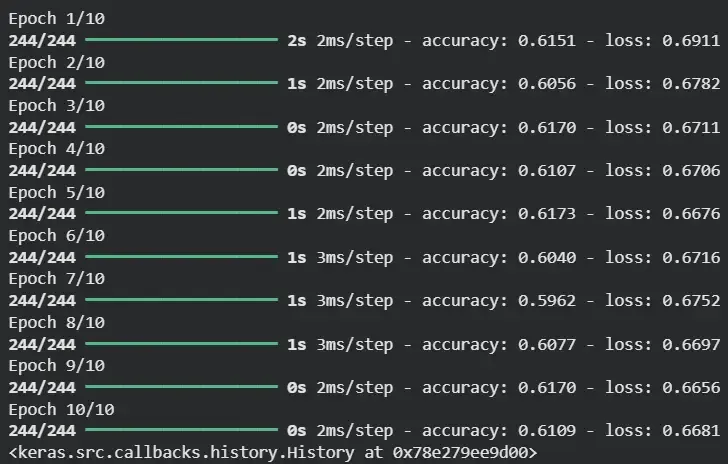
Example: Let's see an example of TensorFlow library.
- Defines a real-world binary classification task
- Builds a neural network model
- Trains using gradient-based optimization
- Demonstrates deep learning usage
import tensorflow as tf
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv("movies.csv")
df["is_comedy"] = df["genres"].apply(lambda x: 1 if "Comedy" in x else 0)
df["genre_count"] = df["genres"].apply(lambda x: len(x.split("|")))
X = df[["genre_count"]].values
y = df["is_comedy"].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = tf.keras.Sequential([
tf.keras.layers.Dense(8, activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")
])
model.compile(optimizer="adam", loss="binary_crossentropy",
metrics=["accuracy"])
model.fit(X_train, y_train, epochs=10, batch_size=32)
Output:
6. Keras
Keras is a high-level neural network API that simplifies deep learning model development. It abstracts much of the complexity involved in building neural networks, making it especially suitable for beginners and rapid prototyping.
- Simplifies neural network creation with minimal and readable code.
- Supports fast development for regression and classification tasks.
Example: Let's see an example of Keras library.
- Builds a regression-based neural network
- Predicts numerical movie attributes
- Uses mean squared error loss
- Highlights Keras simplicity
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import pandas as pd
df = pd.read_csv("movies.csv")
df["genre_count"] = df["genres"].apply(lambda x: len(x.split("|")))
X = df["movieId"].values.reshape(-1, 1)
y = df["genre_count"].values
model = Sequential([
Dense(16, activation="relu", input_shape=(1,)),
Dense(1)
])
model.compile(optimizer="adam", loss="mse")
model.fit(X, y, epochs=10, batch_size=32)
Output:
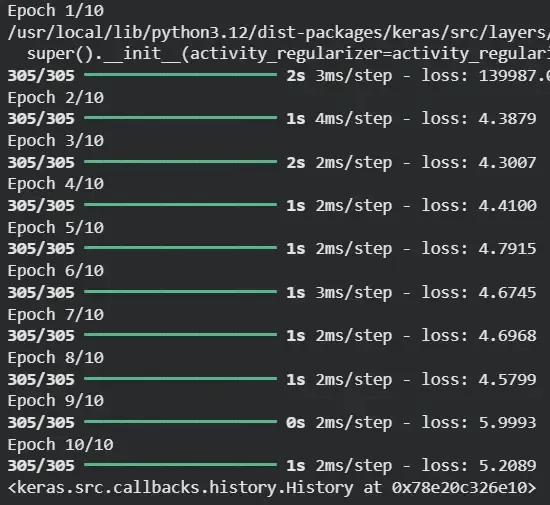
7. PyTorch
PyTorch is an open-source deep learning library known for its dynamic computation graph, which allows models to be modified during execution. This makes PyTorch highly flexible and popular in research and experimentation.
- Supports dynamic and flexible model development
- Simplifies debugging and custom model creation
- Supports custom training logic
Example: Let's see an example of PyTorch library.
- Converts movie features into tensors
- Builds a custom classifier
- Implements manual training loop
- Demonstrates PyTorch control
import torch
import torch.nn as nn
import pandas as pd
df = pd.read_csv("movies.csv")
X = torch.tensor(df["genres"].apply(lambda x: len(
x.split("|"))).values, dtype=torch.float32).view(-1, 1)
y = torch.tensor(df["genres"].apply(
lambda x: 1 if "Drama" in x else 0).values, dtype=torch.float32).view(-1, 1)
model = nn.Linear(1, 1)
loss_fn = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
for _ in range(50):
optimizer.zero_grad()
output = model(X)
loss = loss_fn(output, y)
loss.backward()
optimizer.step()
print(loss.item())
Output:
0.6867777109146118
8. Seaborn
Seaborn is a statistical data visualization library built on Matplotlib that simplifies the creation of informative and visually appealing plots. It is widely used in machine learning and data analysis to explore patterns, relationships and distributions within datasets.
- Used for exploratory data analysis
- Simplifies statistical data visualization
- Integrates seamlessly with pandas DataFrames
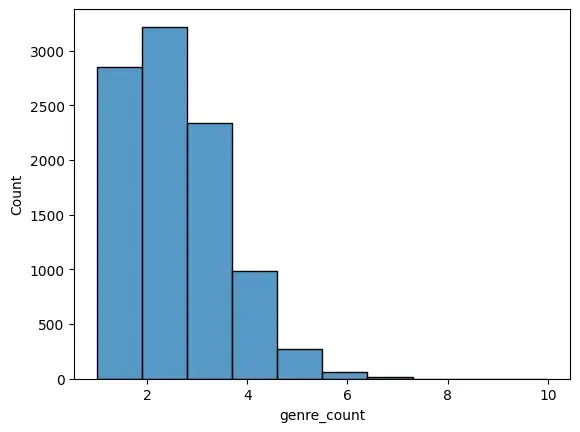
Example: Let's see an example of Seaborn library by visualizing data distributions, correlations, trends and relationships between variables for exploratory data analysis.
import seaborn as sns
import pandas as pd
df = pd.read_csv("movies.csv")
df["genre_count"] = df["genres"].apply(lambda x: len(x.split("|")))
sns.histplot(df["genre_count"], bins=10)
Output: