Recommendation systems have become a important part of modern software platforms, serving as intelligent filters that suggest personalized content to users. While massive data availability benefits users by enhancing access and connectivity, it also complicates the discovery of relevant content.
Among the most widely used techniques powering these systems are Content-Based Filtering (CBF) and Collaborative Filtering (CF). Both of these methods aim to match users with relevant items, they differ significantly in methodology, strengths and use cases.
Recommendation Systems
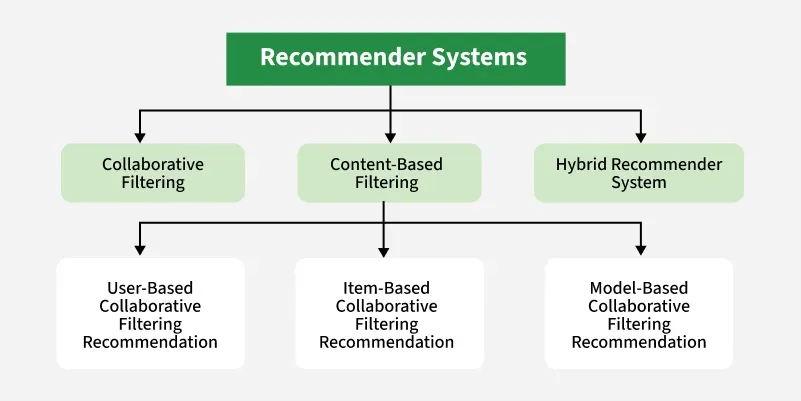
As users are generating interactions daily, platforms like Netflix, Amazon, and YouTube need efficient ways to surface relevant content. Recommendation systems achieve this by learning user preferences and predicting which products, services or content pieces each individual might enjoy. Among various algorithms developed for this purpose collaborative filtering and content-based filtering have emerged as foundational approaches.
Collaborative Filtering
Collaborative Filtering works on the principle that users with similar behavior in the past are likely to have similar preferences in the future. It uses collective intelligence from a group of users to recommend items to an individual.
The process begins by collecting user-item interaction data such as clicks, ratings, views or purchases. This data is then cleaned and normalized before being used to compute similarities, either between users or between items. The system then recommends content based on this similarity.
Types of Collaborative Filtering
- User-Based Collaborative Filtering : Recommends items that similar users have liked. It works well in small communities with minimal user diversity.
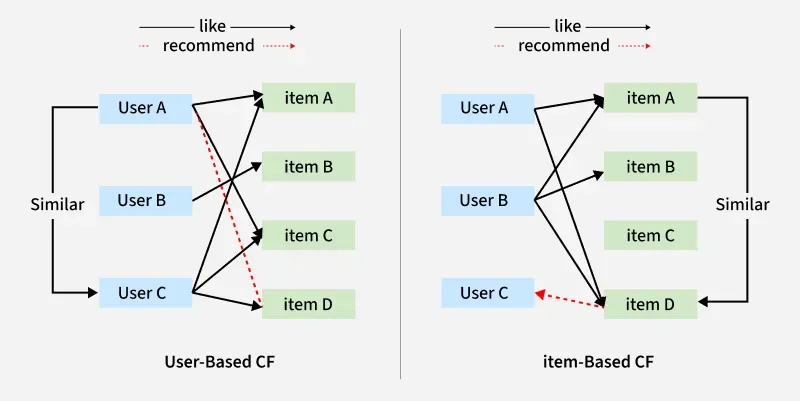
- Item-Based Collaborative Filtering : Recommends items similar to those a user has previously interacted with. It’s widely used in e-commerce and media platforms.
- Model-Based Collaborative Filtering : Uses machine learning models to learn patterns from user behavior data and predict future preferences. Techniques like matrix factorization or neural networks are commonly employed here.
Advantages
- No Need for Feature Extraction: CF operates purely on user interaction data.
- High Novelty: Recommendations are based on behaviors across the user base, often leading to serendipitous discoveries.
- Highly Personalized: Learns from community patterns to give suggestions.
- Effective for Unstructured Content: Works well with abstract data like music or videos.
Limitations
- Cold Start Problem: Struggles with recommending for new users or new items due to lack of historical data.
- Data Sparsity: In large datasets, user-item interactions are sparse, reducing prediction accuracy.
- Scalability Issues: As data volume increases, so do the computational requirements.
- Over-reliance on User History: Limits exploration and may reinforce past behavior excessively.
Content-Based Filtering
Content-Based Filtering recommends items similar to those a user has liked in the past by analyzing the features of items. It builds a profile of a user’s preferences by extracting and representing content in vector form (product descriptions, genres, keywords) and then measuring similarity, often using cosine similarity.
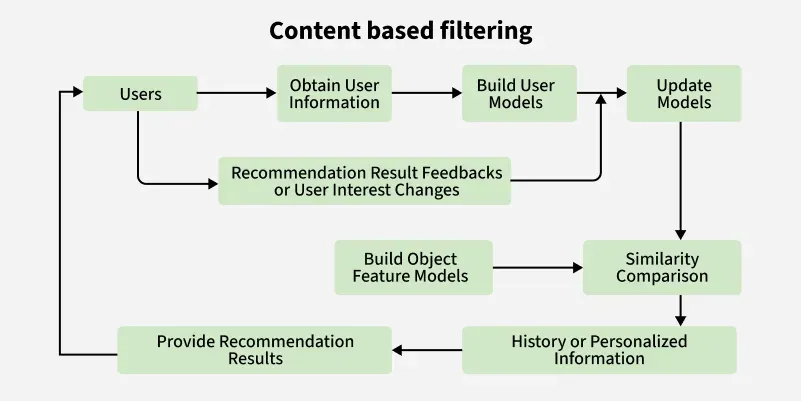
Procedure for Content-Based Filtering
- Feature Extraction from Users and Items : CBF begins by gathering textual and behavioral data, such as user profiles, product descriptions, clicks and reviews. This information is used to build detailed feature sets representing user preferences and item characteristics.
- Vectorization of Features : The collected features are then transformed into numerical vectors using a vector space model. This allows for structured comparison between user profiles and item attributes.
- Similarity Computation : All feature vectors are mapped into the same space, where usually cosine similarity is used to measure how closely items align with a user’s preferences. The most similar items are then recommended.
Advantages
- Less Dependent on Other Users: Does not require a large user base.
- Explainable Recommendations: Clear rationale for why a suggestion was made.
- Good for Minority Interests: Performs well for niche content or rare user preferences.
Limitations
- Feature Engineering Required: Needs well-defined item metadata or accurate text descriptions.
- Limited Novelty: Tends to recommend items very similar to what the user has already seen (filter bubble).
- Hard to Handle Abstract Data: Struggles with content like humor, sarcasm, or nuanced art.
Comparison between Collaborative Filtering and Content-Based Filtering
| Aspect | Collaborative Filtering | Content-Based Filtering |
|---|---|---|
| Data Source | User-item interactions | Item metadata/features |
| Cold Start | Problematic for new users/items | Better with new users |
| Diversity | Good | Can be narrow |
| Scalability | Complex with large data | More manageable |
| Explainability | Hard to interpret | Easy to justify recommendations |
| Personalization | Based on crowd behavior | Based on individual behavior |
- Collaborative Filtering thrives in media platforms (Netflix, Spotify) where user engagement is rich and frequent.
- Content-Based Filtering works well in search systems, bookstores or niche content platforms where metadata is structured and plentiful.
Hybrid Approaches
Given the distinct advantages and limitations of each method, modern recommendation systems often use hybrid models that combine content-based and collaborative filtering. These systems:
- Blend item similarity with user similarity scores
- Use CF when enough user data is available and fall back on CBF otherwise
- Use deep learning to encode both user behaviors and item content into shared latent spaces
