Gradient boosting algorithms have become a cornerstone in machine learning, particularly in handling complex datasets with heterogeneous features and noisy data. One of the most prominent gradient boosting libraries is CatBoost, known for its ability to process categorical features effectively. However, like other boosting algorithms, CatBoost faces the challenge of dealing with imbalanced datasets, where one class significantly outnumbers the other. This article delves into the techniques and solutions CatBoost offers to tackle the issue of imbalanced classes.
Table of Content
The Problem of Imbalanced Classes
Imbalanced datasets are common in many real-world applications, such as fraud detection, medical diagnosis, and customer churn prediction. In these scenarios, one class (e.g., the positive class) is significantly underrepresented compared to the other class (e.g., the negative class). This imbalance can lead to biased models that favor the majority class, resulting in poor performance on the minority class.
Techniques for Handling Imbalanced Data in CatBoost
CatBoost provides several built-in mechanisms to handle imbalanced datasets. These include:
- Class Weights
- Auto Class Weights
- Sampling Techniques
Let's walk through a practical example demonstrating how to handle an imbalanced dataset using CatBoost, and then validate its performance. We'll use a synthetic dataset and evaluate the effectiveness of different techniques.
1. Dataset Preparation
First, let's generate a synthetic imbalanced dataset for demonstration purposes using make_classification from scikit-learn:
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
import pandas as pd
X, y = make_classification(n_samples=1000, n_features=10, n_informative=8,
n_redundant=2, n_classes=2, weights=[0.95, 0.05], random_state=42)
df = pd.DataFrame(X, columns=[f'feature_{i}' for i in range(X.shape[1])])
df['target'] = y
X_train, X_test, y_train, y_test = train_test_split(df.drop('target', axis=1), df['target'], test_size=0.2, random_state=42)
1. Class Weights
Class weights are used to assign different importance to different classes. By increasing the weight of the minority class, the model is penalized more for misclassifying minority class instances, thus improving its performance on the minority class.
from catboost import CatBoostClassifier
from sklearn.metrics import classification_report
# Define CatBoost model with class weights
model_class_weights = CatBoostClassifier(class_weights={0: 1, 1: 10}, random_state=42, verbose=0)
model_class_weights.fit(X_train, y_train)
y_pred_class_weights = model_class_weights.predict(X_test)
print("Classification Report - Class Weights:")
print(classification_report(y_test, y_pred_class_weights))
Output:
Classification Report - Class Weights:
precision recall f1-score support
0 0.98 1.00 0.99 1868
1 0.94 0.73 0.83 132
accuracy 0.98 2000
macro avg 0.96 0.87 0.91 2000
weighted avg 0.98 0.98 0.98 20002. Auto Class Weights
CatBoost also offers an automatic way to balance class weights using the auto_class_weights parameter. This parameter can be set to 'Balanced' to automatically calculate and assign weights based on the class distribution.
# Initialize CatBoostClassifier with auto class weights
model = CatBoostClassifier(auto_class_weights='Balanced', verbose=0)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("Predictions:", y_pred)
Output:
Predictions: [0 0 0 ... 0 0 0]3. Sampling Techniques
Sampling techniques such as oversampling the minority class or undersampling the majority class can also be used to balance the dataset. These techniques can be combined with CatBoost to improve model performance.
Oversampling:
from imblearn.over_sampling import SMOTE
# Apply SMOTE to oversample the minority class
smote = SMOTE()
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
model = CatBoostClassifier(verbose=0)
model.fit(X_resampled, y_resampled)
y_pred = model.predict(X_test)
print("Predictions:", y_pred)
Output:
Predictions: [0 0 0 ... 0 0 0]Undersampling:
from imblearn.under_sampling import RandomUnderSampler
# Apply RandomUnderSampler to undersample the majority class
rus = RandomUnderSampler()
X_resampled, y_resampled = rus.fit_resample(X_train, y_train)
model = CatBoostClassifier(verbose=0)
model.fit(X_resampled, y_resampled)
y_pred = model.predict(X_test)
print("Predictions:", y_pred)
Output:
Predictions: [0 0 0 ... 0 0 0]Handling Imbalanced Dataset in CatBoost : Practical Example
Problem Statement: You have a dataset from a telecom company containing customer information such as service usage patterns, customer demographics, and whether the customer churned or not. The goal is to build a model that predicts whether a customer will churn based on these features.
Step-by-Step Example: Predicting Customer Purchase
1. Generate Random Dataset
Let's generate a random dataset using Python's numpy and pandas libraries:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.metrics import classification_report, roc_auc_score
from catboost import CatBoostClassifier
np.random.seed(42)
n_samples = 1000
# Features: customer demographics and behavior
age = np.random.randint(18, 70, size=n_samples)
income = np.random.normal(50000, 20000, size=n_samples)
days_since_last_purchase = np.random.randint(0, 365, size=n_samples)
num_visits_last_month = np.random.randint(1, 30, size=n_samples)
avg_purchase_amount = np.random.normal(50, 20, size=n_samples)
customer_type = np.random.choice(['Regular', 'Premium'], size=n_samples)
location = np.random.choice(['Urban', 'Rural'], size=n_samples)
# Target: whether customer made a purchase (binary: 0 or 1)
purchase = np.random.choice([0, 1], size=n_samples, p=[0.8, 0.2])
data = pd.DataFrame({
'Age': age,
'Income': income,
'Days_Since_Last_Purchase': days_since_last_purchase,
'Num_Visits_Last_Month': num_visits_last_month,
'Avg_Purchase_Amount': avg_purchase_amount,
'Customer_Type': customer_type,
'Location': location,
'Purchase': purchase
})
# Display class distribution
print(data['Purchase'].value_counts())
Output:
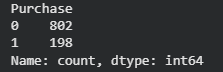
2. Data Preprocessing
Now, let's preprocess the dataset:
label_encoder = LabelEncoder()
data['Customer_Type'] = label_encoder.fit_transform(data['Customer_Type'])
data['Location'] = label_encoder.fit_transform(data['Location'])
X = data.drop('Purchase', axis=1)
y = data['Purchase']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Stratified train-test split to preserve class distribution
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, test_size=0.2, random_state=42, stratify=y
)
3. Baseline CatBoost Model (No Class Weights)
This step trains a simple CatBoost model without applying any balancing techniques. It helps us understand how the model naturally behaves on imbalanced data.
- The model is trained normally on the stratified dataset.
- No weights are added, so the majority class has more influence during training.
- This acts as a reference point to compare later improvements.
baseline_model = CatBoostClassifier(
iterations=1000,
learning_rate=0.1,
depth=6,
eval_metric='AUC',
random_seed=42,
verbose=100
)
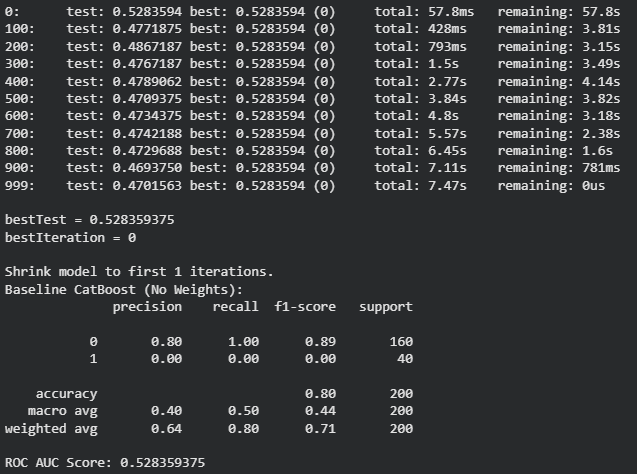
baseline_model.fit(X_train, y_train, eval_set=(X_test, y_test))
y_pred_baseline = baseline_model.predict(X_test)
print("Baseline CatBoost (No Weights):")
print(classification_report(y_test, y_pred_baseline))
print("ROC AUC Score:", roc_auc_score(y_test, baseline_model.predict_proba(X_test)[:, 1]))
Output:
4. Handling Imbalanced Classes with CatBoost
CatBoost with Class Weights: You can manually adjust the class_weights parameter in CatBoost to handle class imbalance:
catboost_model_weights = CatBoostClassifier(
iterations=1000,
learning_rate=0.1,
depth=6,
eval_metric='AUC',
random_seed=42,
class_weights=[1, 4], # Adjusted for minority class
verbose=100
)
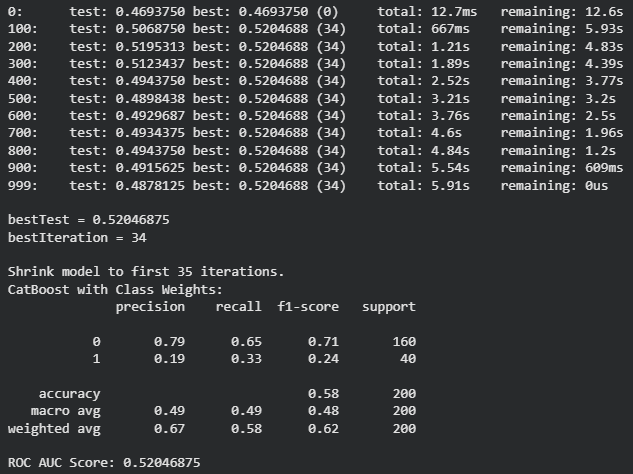
catboost_model_weights.fit(X_train, y_train, eval_set=(X_test, y_test))
y_pred_weights = catboost_model_weights.predict(X_test)
print("CatBoost with Class Weights:")
print(classification_report(y_test, y_pred_weights))
print("ROC AUC Score:", roc_auc_score(y_test, catboost_model_weights.predict_proba(X_test)[:, 1]))
Output:
Using Auto Class Weights: CatBoost provides an option to automatically calculate class weights based on the training data using auto_class_weights='Balanced':
catboost_model_auto_weights = CatBoostClassifier(
iterations=1000,
learning_rate=0.1,
depth=6,
eval_metric='AUC',
random_seed=42,
auto_class_weights='Balanced', # Automatically balance classes
verbose=100
)
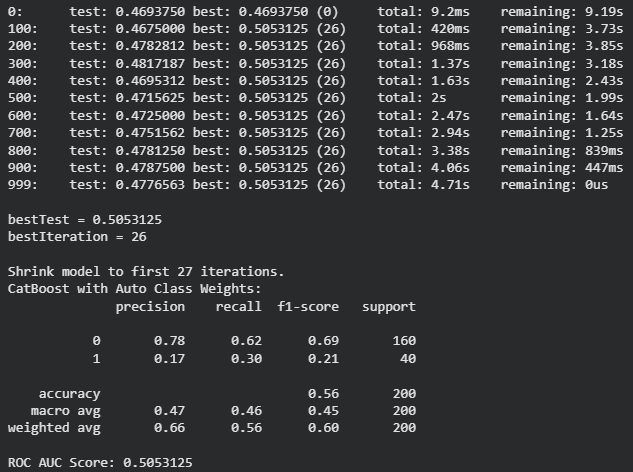
catboost_model_auto_weights.fit(X_train, y_train, eval_set=(X_test, y_test))
y_pred_auto_weights = catboost_model_auto_weights.predict(X_test)
print("CatBoost with Auto Class Weights:")
print(classification_report(y_test, y_pred_auto_weights))
print("ROC AUC Score:", roc_auc_score(y_test, catboost_model_auto_weights.predict_proba(X_test)[:, 1]))
Output:
Choosing the Right Strategy
- Class Weights Adjustment: Ideal for scenarios where the dataset size is manageable and imbalance is moderate. Adjust weights to penalize misclassifications of the minority class more heavily during training.
- Auto Class Weights (Balanced): Suitable for datasets with severe imbalance or where the distribution of classes varies significantly. Automatically adjusts class weights based on class frequencies in the training data.
- Sampling Techniques:
- Over-sampling (SMOTE): Effective when the minority class is underrepresented and needs augmentation.
- Under-sampling (RandomUnderSampler): Useful when dataset size is large and computational efficiency is a concern.
Choosing Based on Scenario:
- For Moderate Imbalance: Start with adjusting class weights or using Auto Class Weights in CatBoost. Evaluate model performance metrics like precision, recall, and F1-score to fine-tune.
- For Severe Imbalance: Consider combining techniques like SMOTE with class weights adjustment or using Auto Class Weights. Evaluate both model performance and computational feasibility.
- Model Sensitivity Considerations: Experiment with different strategies and assess how each affects model behavior and performance metrics specific to your task.
Conclusion
Handling imbalanced datasets is a critical aspect of building robust machine learning models. CatBoost provides several effective techniques to address this challenge, including class weights, auto class weights, and sampling techniques. By leveraging these methods and choosing appropriate evaluation metrics, you can significantly improve the performance of your models on imbalanced datasets. Whether you're working on fraud detection, medical diagnosis, or customer churn prediction, CatBoost offers powerful tools to help you achieve better results.
