Super-Resolution Generative Adversarial Networks (SRGANs) are used for image upscaling by converting low-resolution images into sharper and more realistic high-resolution images while preserving important textures and details.
- Enhances low-resolution images into high-resolution outputs
- Preserves textures, edges, and fine image details
- Uses adversarial training for realistic image generation
- Traditional interpolation methods often produce overly smooth images
- Focuses on improving perceptual quality, not just pixel accuracy
Architecture Overview
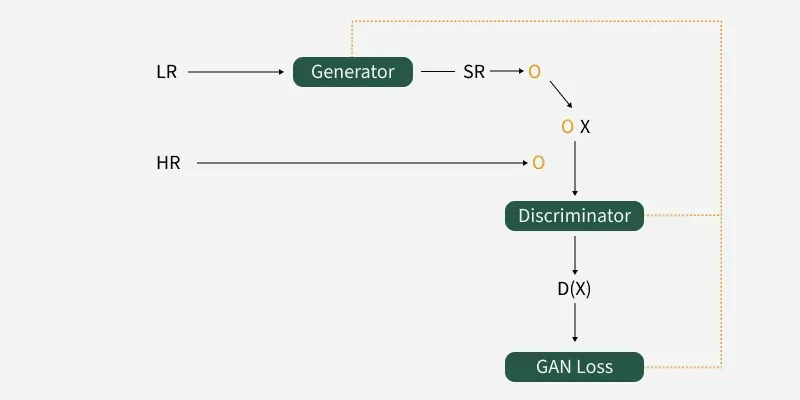
SRGAN follows the GAN framework using two neural networks, a generator and a discriminator. The generator converts low-resolution images into super-resolution images, while the discriminator distinguishes between real high-resolution images and generated images.
- Generator creates high-resolution images from low-resolution inputs
- Discriminator identifies real and generated images
- Adversarial training improves image realism and quality
- Helps generate sharper and more detailed outputs
Generator Architecture
The SRGAN generator uses a Residual Network (ResNet) architecture to generate high-resolution images effectively. Residual connections help improve gradient flow and support deeper network training.
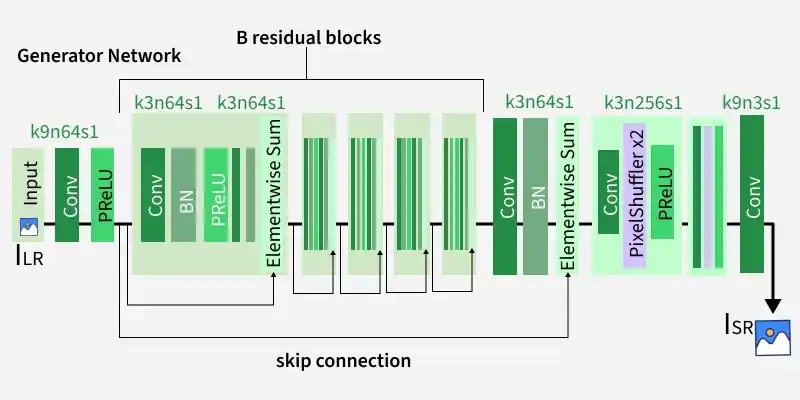
- Uses 16 residual blocks for feature learning
- Each block contains two 3×3 convolution layers with 64 feature maps
- Batch normalization improves training stability
- PReLU activation learns adaptive negative slopes for better performance
- Uses sub-pixel convolution layers for efficient learned upsampling
- Produces sharper and more detailed high-resolution images
Discriminator Architecture
The discriminator uses multiple convolutional layers to distinguish between real high-resolution images and generated images.
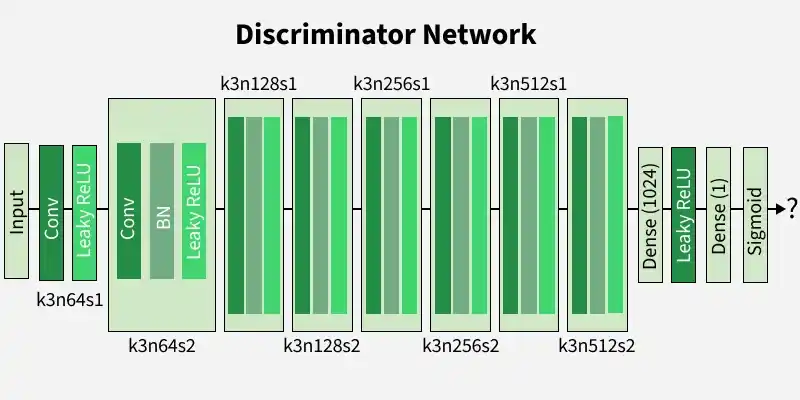
- Uses eight convolutional layers with 3×33 \times 33×3 kernels
- Feature maps increase from 64 to 512 through strided convolutions
- Spatial resolution decreases progressively during processing
- Ends with dense layers and a sigmoid activation function
- Outputs the probability of an image being real or generated
Loss Function Design
SRGAN uses a perceptual loss function that combines content loss and adversarial loss to improve both image quality and realism.
Content Loss
Traditional super-resolution methods typically use Mean Squared Error (MSE) as the content loss, which measures pixel-wise differences between generated and target images. However, MSE tends to produce overly smooth images because it averages over all possible high-resolution images that could relate to a given low-resolution input.
l^{SR}_{VGG/i,j} = \frac{1}{W_{i,j} H_{i,j}} \sum_{x=1}^{W_{i,j}} \sum_{y=1}^{H_{i,j}} \left( \left( \phi_{i,j}(I^{HR})_{x,y} - \phi_{i,j}(G_{\theta_G}(I^{LR}))_{x,y} \right)^2 \right)
l^{SR}_{VGG/i,j} : Perceptual (VGG) loss at layer(i,j) .W_{i,j}, H_{i,j} : Width and height of the VGG feature map, used for normalization.\phi_{i,j} : Feature map extracted from layer(i,j) of the pre-trained VGG network.I^{HR} : Ground-truth high-resolution image.I^{LR} : Low-resolution input image.G_{\theta_G}(I^{LR}) : Super-resolved output image generated by the generator GGG.(x,y) : Spatial position in the feature map.
SRGAN proposes using VGG loss instead, which computes the difference between feature representations extracted from a pre-trained VGG-19 network. This approach focuses on perceptually important features rather than raw pixel values. The VGG loss can be computed at different network depths:
- VGG2,2: Features from the second convolution layer before the second max-pooling (low-level features)
- VGG5,4: Features from the fourth convolution layer before the fifth max-pooling (high-level features)
Adversarial Loss
Adversarial loss encourages the generator to produce images that appear realistic to the discriminator.
l^{SR}_{Gen} = \sum_{n=1}^{N} -\log D_{\theta_D}(G_{\theta_G}(I^{LR}))
l^{SR}_{Gen} : Adversarial (generator) loss for super-resolution.N : Total number of training samples.G_{\theta_G}(I^{LR}) : Super-resolved image generated by the generator GGG using low-resolution inputI^{LR} .D_{\theta_D}(\cdot) : Discriminator’s probability that the input image is real.-\log D_{\theta_D}(G_{\theta_G}(I^{LR})) : Penalizes the generator if the discriminator easily detects the fake image.
Total Loss - Perceptual loss
l^{SR} = l^{SR}_X + 10^{-3} l^{SR}_{Gen}
l^{SR} : Overall super-resolution loss.l^{SR}_X : Content loss (often based on VGG perceptual loss).l^{SR}_{Gen} : Adversarial loss from the generator.
Training Process and Results
During training, high-resolution images are downsampled to create low-resolution inputs for the generator. The generator and discriminator then train adversarially to improve image quality and realism.
- Generator converts low-resolution images into high-resolution outputs
- Discriminator checks whether images are real or generated
- Adversarial training continuously improves image realism
- Produces sharper textures and finer image details
- Achieves strong performance in objective metrics and Mean Opinion Score (MOS)
Limitations
Although SRGAN produces high-quality images, it also has some limitations.
- Training can be unstable and may face convergence issues
- Requires high computational power and GPU memory
- Performance depends heavily on training data quality
- May prioritize perceptual quality over exact pixel accuracy
- Real-time applications may require model optimization
Applications
SRGAN is widely used in tasks where high visual quality is important.
- Medical image enhancement
- Satellite image super-resolution
- Mobile photography and image enhancement
- Consumer applications requiring realistic image upscaling
- Foundation for advanced models like ESRGAN and Real-ESRGAN
