Support Vector Machines (SVM) are used for classification tasks but their performance depends on the right choice of hyperparameters like C and gamma. Finding the optimal combination of these hyperparameters can be an issue. GridSearchCV automates this process by systematically testing various combinations of hyperparameters and selecting the best one based on cross-validation results.
Let's see its implementation:
Step 1: Importing Necessary Libraries
We will be using Pandas, NumPy and Scikit-learn for building and evaluating the model.
import pandas as pd
import numpy as np
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.datasets import load_breast_cancer
from sklearn.svm import SVC
Step 2: Loading and Printing the Dataset
In this example we will use Breast Cancer dataset from Scikit-learn. This dataset contains data about cell features and their corresponding cancer diagnosis i.e malignant or benign.
cancer = load_breast_cancer()
df_feat = pd.DataFrame(cancer['data'], columns=cancer['feature_names'])
df_target = pd.DataFrame(cancer['target'], columns=['Cancer'])
print("Feature Variables: ")
print(df_feat.info())
print("Dataframe looks like : ")
print(df_feat.head())
Output:
Step 3: Splitting the Data into Training and Testing Sets
We will split the dataset into training (70%) and testing (30%) sets using train_test_split.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
df_feat, np.ravel(df_target),
test_size = 0.30, random_state = 101)
Step 4: Training an SVM Model without Hyperparameter Tuning
Before tuning the model let’s train a simple SVM classifier without any hyperparameter tuning.
model = SVC()
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print(classification_report(y_test, predictions))
Output:

While the accuracy is around 92%, we can improve the model’s performance by tuning the hyperparameters.
Step 5: Hyperparameter Tuning with GridSearchCV
Now let’s use GridSearchCV to find the best combination of C, gamma and kernel hyperparameters for the SVM model. But before that let's understand these parameters:
- C: Controls the trade-off between a wider margin (low C) and correctly classifying all points (high C).
- gamma: Controls the influence of data points. High gamma leads to a tight boundary and may cause overfitting.
- kernel: Defines the function used to transform data for separating classes. In this implementation, only the RBF kernel is used, which helps the SVM handle non-linear relationships in the data.
from sklearn.model_selection import GridSearchCV
param_grid = {'C': [0.1, 1, 10, 100, 1000],
'gamma': [1, 0.1, 0.01, 0.001, 0.0001],
'kernel': ['rbf']}
grid = GridSearchCV(SVC(), param_grid, refit = True, verbose = 3)
grid.fit(X_train, y_train)
Output:

Step 6: Get the Best Hyperparameters and Model
After grid search finishes we can check best hyperparameters and the optimized model.
print(grid.best_params_)
print(grid.best_estimator_)
Output:

Step 7: Evaluating the Optimized Model
We can evaluate the optimized model on the test dataset.
grid_predictions = grid.predict(X_test)
print(classification_report(y_test, grid_predictions))
Output:
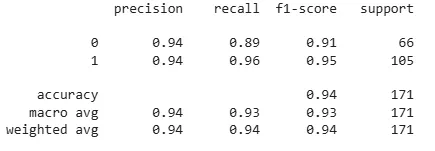
After hyperparameter tuning, the accuracy of the model increased to 94% showing that the tuning process improved the model’s performance. By using this approach, we can improve the model which helps in making it more accurate and reliable.
