Adversarial machine learning (AML) is refers to machine learning threats which aims to trick machine learning models by providing deceptive input. Such attacks force the machine learning model to make wrong predictions and release important information. AML focuses on techniques used by attackers to fool machine learning models into making incorrect predictions or sometimes cloning of the model.
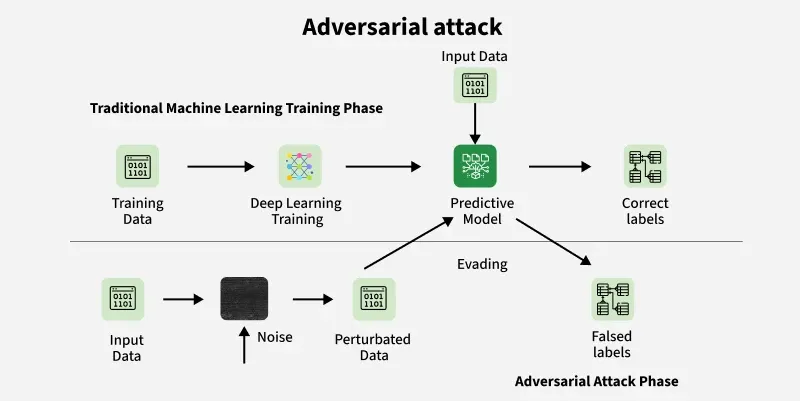
Why is it a threat for machine learning models?
- Safety risks: Adversarial attacks force machine learning models to make incorrect decisions which can result into safety risks. For example in medical diagnostics model
- Security breach: Attackers can extract sensitive and confidential information through model extraction or inversion attacks which can lead to data leaks and model cloning.
- Loss of Trust: As AI is a growing field user's trust is very important, these attacks can make users and organizations trust that machine learning models can be easily deceived, it undermines confidence in these systems which can make them reluctant to adopt AI models.
Types of Adversarial attacks
1. Poisoning Attacks
- Attacks during the training phase of machine learning models are referred to as “poisoning” or “contaminating” Attacks.
- In these attacks an adversary "poisons" or presents labeled data to a classifier which makes the system to predict skewed or inaccurate decisions in the future.
- For Example:
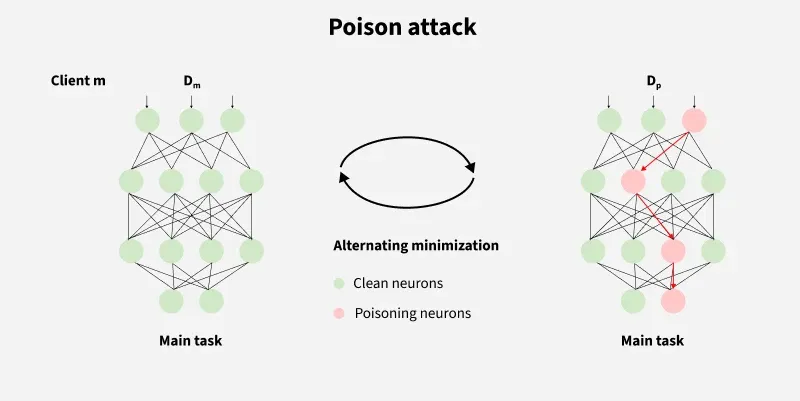
This diagram shows how poisoning neurons in a neural network can affect the functionality of the model.
2. Envasion Attacks
- Attacks which take place after the training phase of machine learning models and occurs when a model is making predictions for it's new input.
- In these attacks the attacker fools the machine learning model and manipulates the data during deployment to deceive previously trained classifiers.
- For example:
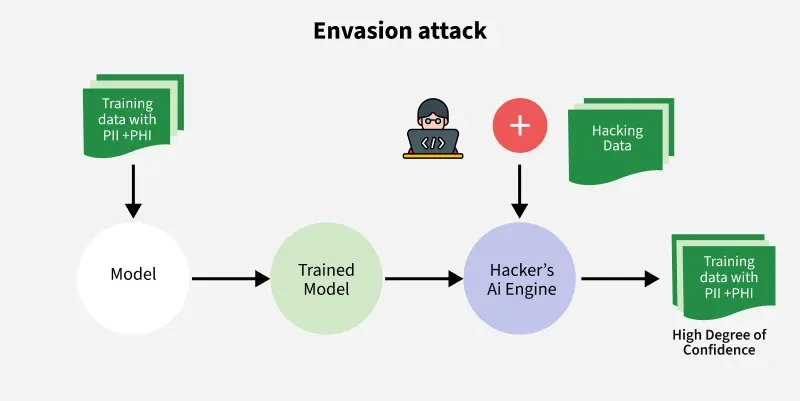
This diagram shows how hackers use a trained machine learning model to infer confidential data through envasion attacks.
3. Model Attacks
- Attacks which results in model stealing or model extraction in order to either reconstruct the model or extract the data it was trained on.
- These are the attacks which involves an attacker manipulating a machine learning model to create a replica of the model or steal data from the model.
- For Example:
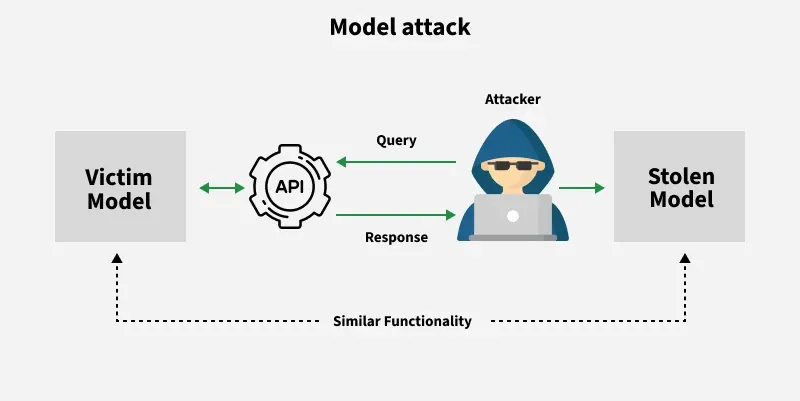
This diagram shows how attackers try to steal the identity of a model by using model extraction attacks.
4. Inference Attacks
- Inference attacks focuses on the training data of the machine learning model.
- The main goal of these attacks is to extract confidential data from the model. Attackers do not care about the whole model their main focus is only on some specific information.
- For Example:
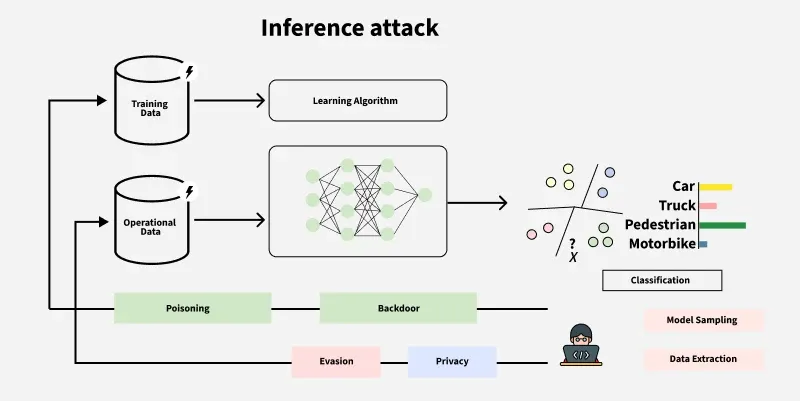
This diagram shows that the model is trained using training and operational data then it's outputs are exploited using various inference attacks.
5. Black box attacks
- Black box attacks involve the attacker having limited knowledge of the model and cannot access the model’s internal architecture, parameters, or training data and can only interact with the model by querying it and observing the outputs.
- For example:
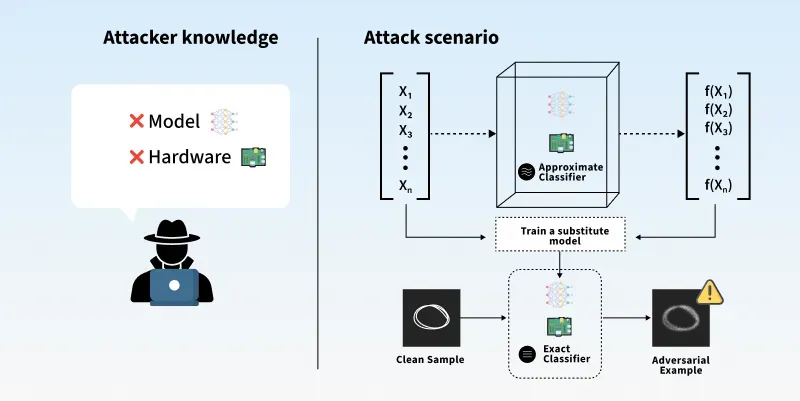
This diagram shows that the attacker have limited access to knowledge of the model and hence cannot access it's information.
6. White box attacks
- White box attacks involves having full knowledge of the model. The attacker has full access to the model’s architecture, parameters and training data.
- For example:
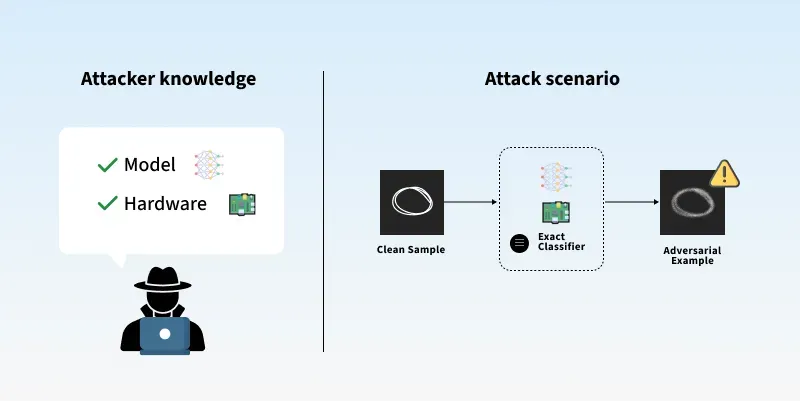
This diagram shows that the attacker have all the access to knowledge of the model and hence can access it's information.
Defending techniques against Adversarial Attacks
1. Adversarial training
- This technique involves augmenting training data with adversarial examples to improve the model's accuracy against attacks.
- The main goal is to expose the model to adversarial perturbations in its's training phase to improve it's accuracy by recognizing attacks.
2. Defensive distillation
- This approach involves training a model to mimic the output probabilities of another model. We first train a standard model on the original dataset and it generates labels for the training data.
- A student model is then trained on these soft labels resulting into a model with smoother decision boundaries.
3. Gradient masking
- Gradient masking is a technique which involves a variety of techniques that hide the gradients of the model.
- For example: Model switching is a gradient masking approach which involves using multiple models within your system. The model is changed after every prediction due to which attacker would not know which model is currently in use.
Adversarial deep reinforcement learning
- Adversarial deep reinforcement learning is an emerging area of research in reinforcement learning In this research area that shows how malicious perturbations can disrupt or manipulate the behavior of agents trained using deep learning in reinforcement learning environments.
- In deep reinforcement learning agents learn to make decisions through interactions with an environment and optimizing their behavior based on rewards and penalties.
Adversarial natural language processing
- Adversarial Natural Language Processing is a sub branch of adversarial machine learning which focuses on understanding, evaluating, and improving the robustness of NLP models against incorrect or unexpected inputs designed to fool them.
- These attacks aim to degrade performance of machine learning models and reveal model's confidential information or vulnerabilities.
