If a DataFrame has rows that don’t meet certain conditions, you can remove them while keeping all other rows unchanged. For example, suppose a DataFrame has player ages [22, 27, 19, 30] and you want to keep only rows where age ≥ 25, resulting DataFrame will have ages [27, 30].
Using Boolean Indexing
Boolean indexing allows dropping rows by creating a boolean mask that identifies rows to keep. Rows not satisfying the condition are automatically dropped.
In this article, we have used nba.csv dataset to download CSV used click here.
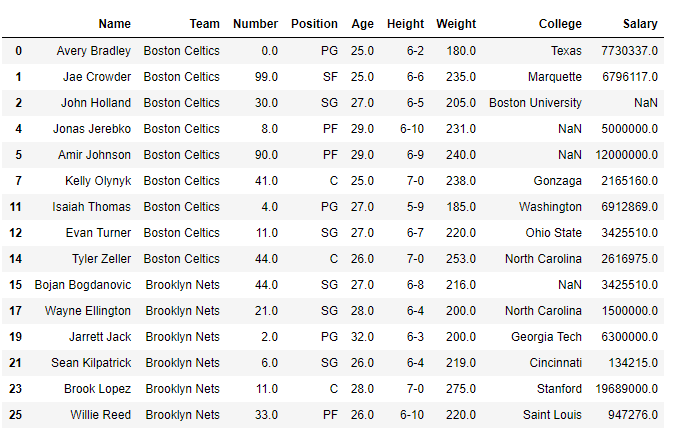
Example: This code drops all NBA players whose Age is greater than and equal to 25.
import pandas as pd
df = pd.read_csv('nba.csv')
b = df[df['Age'] >= 25]
print(b.head(15))
Output
Explanation:
- df['Age'] >= 25 generates a boolean Series for rows to keep.
- df[df['Age'] >= 25] filters the DataFrame, automatically dropping rows where Age < 25.
Using DataFrame.query()
The query() method lets you drop rows using a string-based expression. It supports logical operators and is ideal for complex conditions.
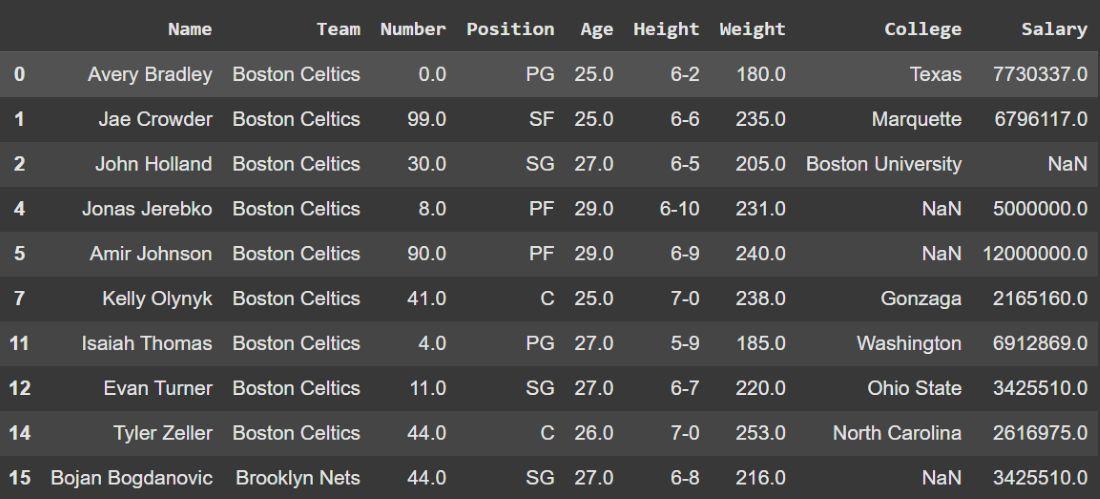
Example: In this example, we drop players whose Age is not between 25 and 30.
df = df.query('25 <= Age <= 30')
print(df.head(10))
Output
Explanation:
- The expression '25 <= Age <= 30' evaluates for each row.
- Only rows satisfying the condition are kept; all others are dropped.
Using DataFrame.loc[]
loc[] can filter rows based on a condition, dropping all rows not meeting the criteria. It works similarly to boolean indexing but allows selecting specific columns at the same time if needed.
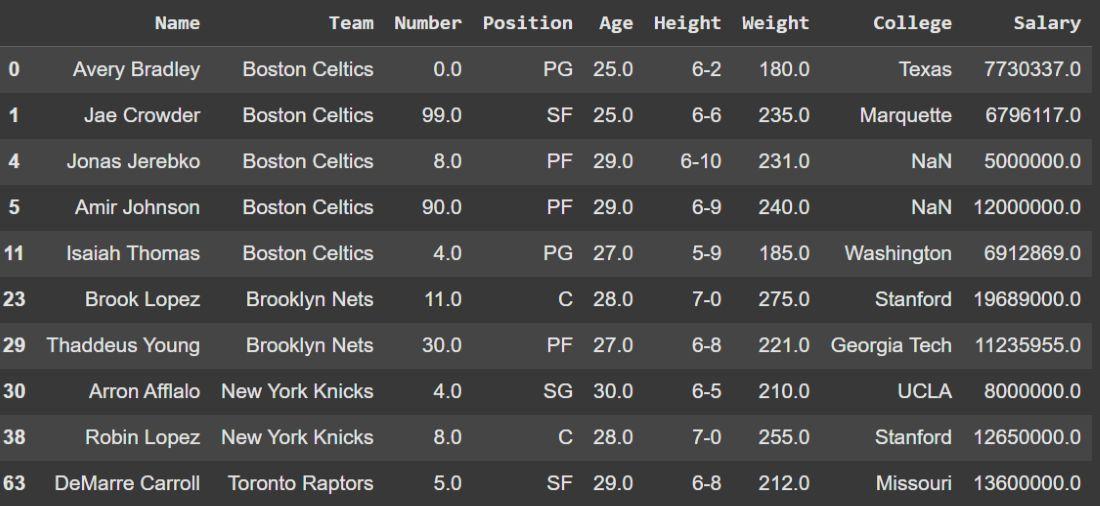
Example: Here we, drop players whose Salary is below 5,000,000.
df = df.loc[df['Salary'] >= 5000000]
print(df.head(10))
Output
Explanation:
- df['Salary'] >= 5000000 creates a boolean Series.
- df.loc[condition] retains only rows satisfying the condition and drops all others.
Using DataFrame.drop() with Conditional Index
drop() can remove rows by index. First, identify the rows to drop using a condition, then delete them permanently.
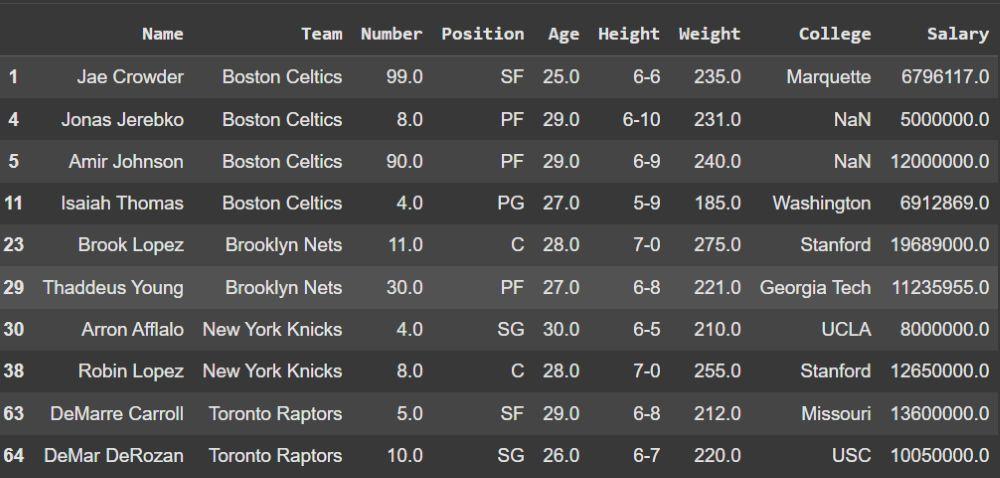
Example: This programs drop all players whose Weight is less than 185.
indices_to_drop = df[df['Weight'] < 185].index
df.drop(indices_to_drop, inplace=True)
print(df.head(10))
Output
Explanation:
- (df['Weight'] < 185) identifies rows to drop.
- .index fetches their index labels.
- df.drop(indices, inplace=True) permanently removes those rows.
For more, you can refer to: How to drop rows or columns based on their labels
