The caret (Classification And Regression Training) package in R provides a unified framework for training, tuning and evaluating a wide range of machine learning algorithms.
Installing and Loading the caret Package
We will install caret and load it along with any other necessary dependencies.
install.packages("caret")
library(caret)
Preparing the Data
We will be using the iris data set which is a built-in dataset in R Language. We will load the data and set a random seed and use createDataPartition() to split into 80% training and 20% testing to evaluate performance on unseen observations.
set.seed(123)
data(iris)
idx <- createDataPartition(iris$Species, p = 0.8, list = FALSE)
train_data <- iris[idx, ]
test_data <- iris[-idx, ]
Classification Algorithms
There are many classification algorithms available in Caret package. We will define cross-validation, implement the model and evaluate the model on test data.
1. Random Forest
Random Forest aggregates many decision trees to reduce overfitting and improve accuracy.
install.packages("randomForest")
library(randomForest)
ctrl <- trainControl(method = "cv", number = 10)
rf_model <- train(Species ~ ., data = train_data,
method = "rf",
trControl = ctrl)
rf_preds <- predict(rf_model, test_data)
confusionMatrix(rf_preds, test_data$Species)
Output:
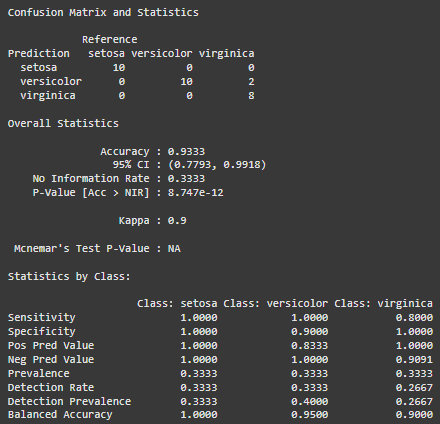
2. CART (Decision Tree)
CART builds a single tree and prunes it based on the complexity parameter (cp).
install.packages("rpart")
library(rpart)
cart_model <- train(Species ~ ., data = train_data,
method = "rpart",
trControl = ctrl)
cart_preds <- predict(cart_model, test_data)
confusionMatrix(cart_preds, test_data$Species)
Output:
3. k-Nearest Neighbors (k-NN)
k-NN classifies observations based on the majority vote of their k nearest neighbors.
knn_grid <- expand.grid(k = seq(3, 15, by = 2))
knn_model <- train(Species ~ ., data = train_data,
method = "knn",
trControl = ctrl,
tuneGrid = knn_grid)
knn_preds <- predict(knn_model, test_data)
confusionMatrix(knn_preds, test_data$Species)
Output:
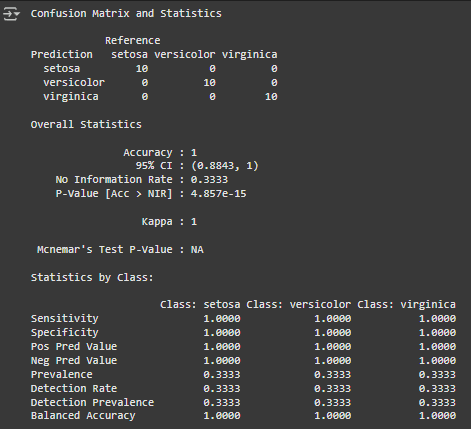
4. Support Vector Machine (SVM)
SVM separates classes by finding the hyperplane with maximum margin.
install.packages("kernlab")
library(kernlab)
svm_model <- train(Species ~ ., data = train_data,
method = "svmRadial",
trControl = ctrl,
preProcess = c("center", "scale"))
svm_preds <- predict(svm_model, test_data)
confusionMatrix(svm_preds, test_data$Species)
Output:
Regression Algorithms
There are many classification algorithms available in Caret package. We will define cross-validation and summarise the model and evaluate the model using Root mean squared error (RMSE).
Data Split for Regression
We’ll use the mtcars dataset to demonstrate regression examples.
set.seed(456)
data(mtcars)
idx2 <- createDataPartition(mtcars$mpg, p = 0.8, list = FALSE)
train_reg <- mtcars[idx2, ]
test_reg <- mtcars[-idx2, ]
1. Linear Regression
Ordinary least squares provides a baseline for regression.
ctrl_reg <- trainControl(method = "cv", number = 5)
lm_model <- train(mpg ~ ., data = train_reg,
method = "lm",
trControl = ctrl_reg)
print(lm_model)
lm_preds <- predict(lm_model, test_reg)
RMSE(lm_preds, test_reg$mpg)
Output:
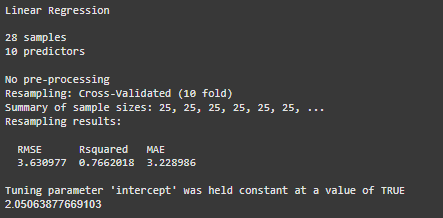
2. Random Forest Regression
Random Forest Regression is an ensemble method that builds multiple decision trees and combines their results to improve accuracy and reduce overfitting.
rf_reg <- train(mpg ~ ., data = train_reg,
method = "rf",
trControl = ctrl_reg)
print(rf_reg)
rf_reg_preds <- predict(rf_reg, test_reg)
RMSE(rf_reg_preds, test_reg$mpg)
Output:
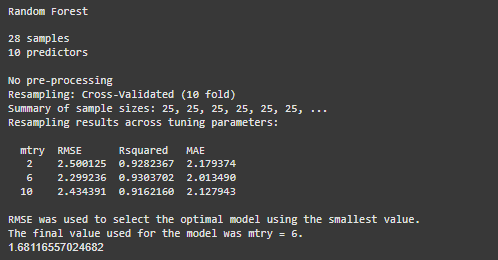
In this article, we demonstrated how to train and evaluate different classification and regression algorithms using the caret package in R, providing a consistent framework for model building, tuning and comparison.
