Indexing is a performance optimization technique in SQL Server that improves the speed of data retrieval. It help reduce query execution time by allowing the database to locate data more efficiently.
Clustered Index
A Clustered Index defines the physical order of rows in a table. When you create a clustered index on a column, SQL Server rearranges the actual data rows to match the index order. This is why a table can have only one clustered index. It is created only when both the following conditions are satisfied:
- The data can be stored in a sequential or sorted manner.
- The column used as the key must contain unique values.
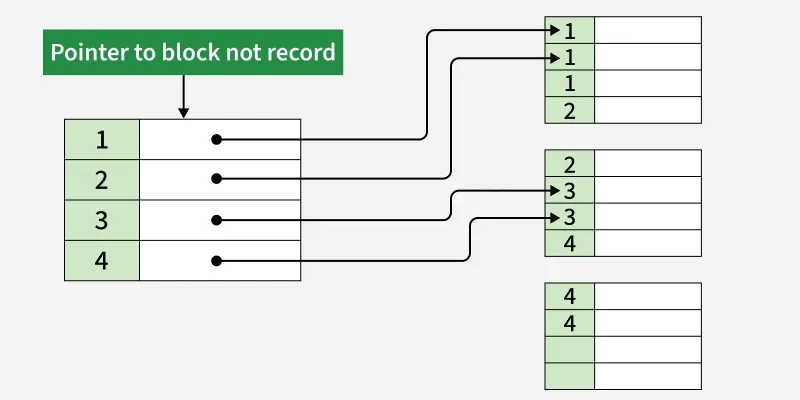
Example of Clustered Index
In the Student table, Roll_No is the primary key, so SQL Server automatically creates a clustered index on it. The rows are stored in ascending order of Roll_No.
Non-Clustered Index
A non-clustered index stores indexed values separately from the table and uses pointers to locate the actual rows. Multiple non-clustered indexes can be created to improve query performance.
- Stores index data separately from the table.
- Multiple non-clustered indexes can exist on a table.
- Contains a copy of the indexed column(s) and a pointer to the actual data row.
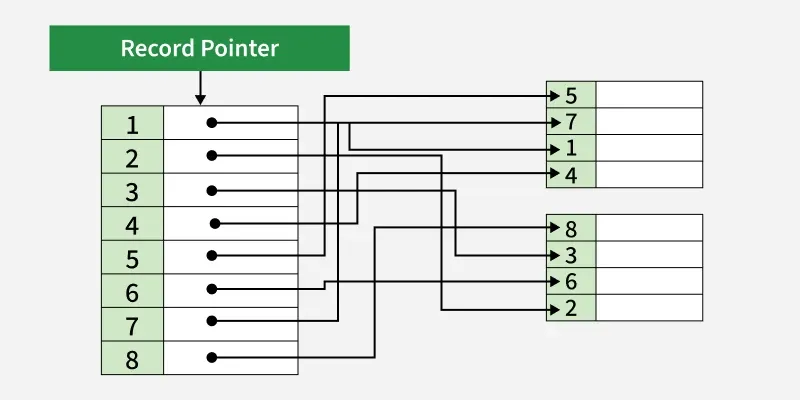
Example of Non-Clustered Index
In the Student table, a non-clustered index can be created on the Name column. It stores the indexed values separately along with pointers to the corresponding rows, improving search performance on the Name column.
Query:
CREATE NONCLUSTERED INDEX NIX_FTE_Name
ON Student (Name ASC);
Output:
Clustered vs. Non-Clustered Index
| Clustered Index | Non-Clustered Index |
|---|---|
| Faster for range-based queries and sorting. | Better for specific lookups on non-key columns. |
| Requires less memory for operations. | Requires additional storage for the index structure. |
| A table can have only one clustered index. | A table can have multiple non-clustered indexes. |
| Leaf nodes contain the actual table data. | Leaf nodes contain index values and row pointers. |
| Typically larger in size. | Usually smaller in size. |
| Ideal for range queries and ordered data retrieval. | Suitable for optimizing searches, filters and joins on non-primary columns. |
