




一、概念
什么是SVM?对于SVM的定义是这样的:
支持向量机(support vector machine,常简称为SVM,又名支持向量网络)是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。SVM模型是将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。
简单来说,SVM其实就是一个二类分类的模型,将两类特征点分类,他的基本模型是的定义在特征空间上的间隔最大的线性分类器,而SVM的学习策略就是间隔最大化。
1、线性分类模型
一般将两类特征点以散点图的形式画在直角坐标系上,每个点以(x, y)的方式表现,其中x为特征点的特征向量(图中默认每个点的特征都是一个,以二维的形式方便理解),而y为分类的标签(一般选择-1和1作为分类的标签)
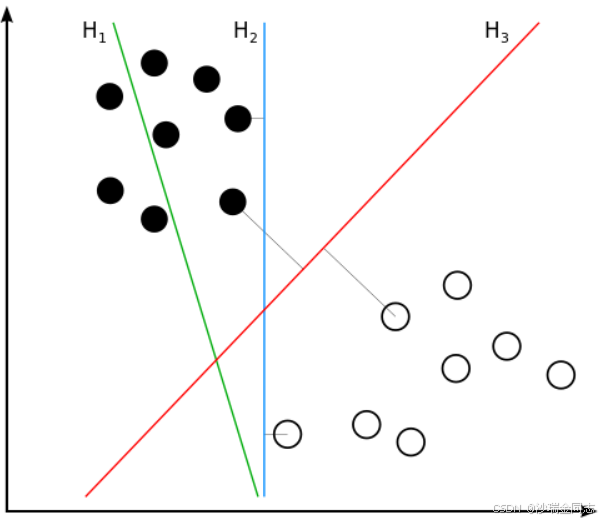
假设该坐标上的黑点和白点分别代表了两种特征点,而三根线(H1, H2, H3)是三种分类器,那么那个分类器是最好的呢。
以我们的直观来说,肯定是H3更适合
虽然看上去H2也能够完美地将图中地两种点分开,但是,这些点是我们观测的数据,既然是观测的,那么数据肯定多少会有点误差,也就是说,这些点的真实位置可能还要改变;况且,这仅仅只是我们训练集的数据,但凡测试集的数据和训练集的差别过大,这个分类器就不起作用了。因此我们需要一个容差率大一点的分类器
所以,H3确实是最适合的分类器,但是,为什么呢?为什么H3是最合适的?
SVM的提出者认为,这根线(分类器)分别向两边的两类点移动,一旦碰到一边的向量就停止,另一边也是如此,这些碰到的向量就被称为支持向量(Support Vector),他认为,支持向量到分割线(分类器)的距离最大即是最适合的分类器。
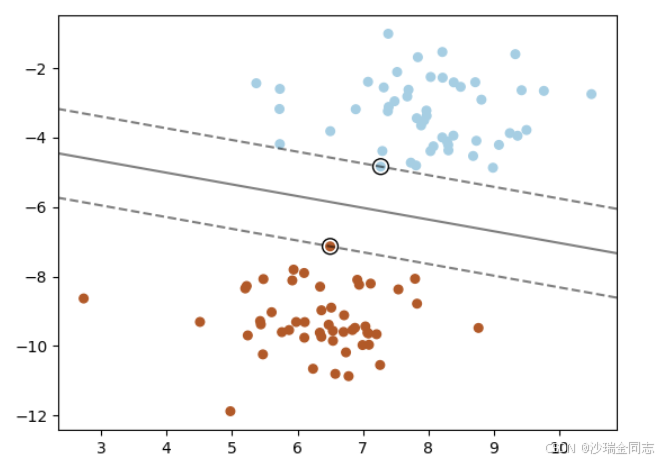
如上图所示,虚线所触碰到的向量即为支持向量,那么,按照




















 2811
2811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










