



检索增强生成(RAG)无疑是当下大模型落地最热门的技术方案之一。它让大模型不再“凭空作答”,而是先检索相关知识,再生成回答,在客服、知识库、文档问答等场景中表现亮眼。
不过,很多人在做 RAG 原型时效果还行,一上线就翻车——
- 问公司内部制度,它引用了过时的旧版文档
- 问天气,它非要从产品手册里“硬找”文字
- 答案看着靠谱,实则关键数据完全错误
问题出在哪?检索不准、召回不全、上下文干扰,以及大模型本身的“幻觉”。
这篇文章总结了一套从浅到深、从通用到进阶的 RAG 优化方案,帮你把 RAG 从“能跑”升级到“好用”。
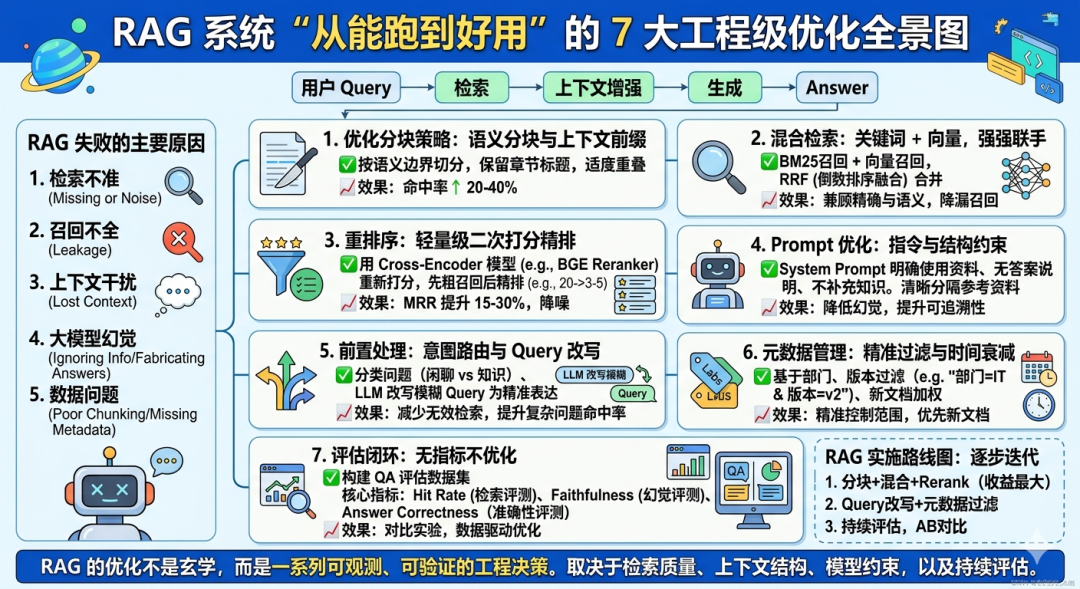
一、先搞清楚:你的 RAG 卡在哪一步?
优化之前不妨先定位瓶颈。RAG 的核心流程是:
Query → 检索 → 上下文增强 → 生成 → Answer
主要的失败模式包括:
| 阶段 | 典型问题 |
|---|---|
| 检索 | 搜不到相关内容、搜到大量噪声 |
| 上下文 | 窗口太长、关键信息被淹没 |
| 生成 | 模型忽略检索结果、编造答案 |
| 数据 | 原始文档分块不合理、元数据缺失 |
绝大多数优化都可以归到这四类。
二、7 个行之有效的优化技巧
1. 优化分块策略:先问“最小信息单元”是什么
很多人不分青红皂白固定 512 token 切分,导致答案被截断或跨块信息丢失。
✅ 建议做法:
- 按语义边界切分:段落、表格、列表项尽量整体保留
- 保留章节标题:让块携带“上下文前缀”
- 适度重叠:chunk overlap 设为 10-20%,避免关键句被切到两块边缘
📈 效果:命中率提升 20-40%,尤其适合长文档
2. 混合检索:关键词 + 向量,谁也别取代谁
纯向量检索语义好,但遇到精确术语(如“ISO9001-2025”)反而不如关键词。
✅ 建议做法:
- 用 BM25(关键词)召回 + 向量召回
- 通过 RRF(倒数排序融合) 合并结果
- 常用比例:BM25 : 向量 = 3 : 7 或 4 : 6
📈 效果:兼顾语义广度与精确匹配,显著降低漏召回
3. 重排序(Rerank):前 20 条里挑 5 条黄金
检索出来的 20 个片段,很可能只有 3-5 条真正有用。
用轻量级 cross-encoder 模型重新打分,再取 Top‑K。
✅ 建议做法:
- 常用模型:
bge-reranker-base、Cohere rerank - 先粗召回(如 20 条),再精排(取 3–5 条)
- 根据场景调整阈值:高精确率场景(医疗、法律)th 设高,高召回场景适当降低
📈 效果:MRR 一般提升 15-30%,噪声大幅减少
4. 指令与结构提示:告诉模型“如何使用检索内容”
默认情况下,模型可能无视检索结果,或者过度依赖。
✅ 建议做法:
在 system prompt 中明确:
你是一个基于给定资料回答问题的助手。
- 如果资料中有答案,请优先使用
- 如果资料中没有,请说明“根据现有资料无法确认”
- 不要补充外部知识
- 引用资料中的具体段落
再加上清晰的分隔:
[参考资料开始]
{检索到的文本}
[参考资料结束]
问题:{query}
📈 效果:降低幻觉,提升可追溯性
5. 意图路由 + Query 改写:别让“你好”去搜文档
很多用户问题根本不是 RAG 该接的,或者说法太模糊。
✅ 建议做法:
- 意图分类:闲聊 / 知识问答 / 数学计算 / 代码等 → 不同处理
- Query 改写:用 LLM 把用户口语转为更适合检索的表达
- 用户问:“它那个价格后来变了没?”
- 改写为:“产品X的价格变更历史”
📈 效果:减少无效检索,提升复杂问题的命中率
6. 元数据过滤与时间衰减
文档元数据(来源、版本、时间、部门)经常被浪费,但在企业场景中非常关键。
✅ 建议做法:
- 过滤:只检索“部门=IT & 版本=v2”
- 时间衰减:较新的文档权重更高
- 结构化字段:存储为独立字段,不放进 embedding
📈 效果:精准控制范围 + 自动优先新文档
7. 评估闭环:没有指标,优化就是盲试
你必须知道“改完到底是变好还是变差”。
✅ 建议做法:
构建一个评估数据集(50-200 条 QA 对),自动跑三项指标:
| 指标 | 含义 | 如何计算 |
|---|---|---|
| Hit Rate | 正确答案是否在 Top‑K 中 | 检索评测 |
| Faithfulness | 答案是否来自检索内容 | LLM-as-Judge |
| Answer Correctness | 答案语义是否正确 | 对比标准答案 |
📈 效果:快速对比实验效果,不再凭感觉调参
三、从优化到生产:别一次性全上
RAG 优化很容易陷入“疯狂加功能”的误区。
一个更稳妥的路线:
- ✅ 先把分块 + 混合检索 + rerank 做好(收益最大)
- ✅ 再加 query 改写 + 元数据过滤
- ✅ 同时跑自动化评估
- ✅ 持续调优 chunk size / top‑K / 温度参数
每一步都做 AB 对比,只合并有效改动。
写在最后
RAG 的优化不是玄学,而是一系列可观测、可验证、可迭代的工程决策。
真正好用的 RAG 不是靠一个“更强的模型”堆出来的,而是检索的质量、上下文结构、对模型的约束,以及持续评估共同作用的结果。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】


















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










