




Java道经第3卷 - 第9阶 - SpringAI(一)
传送门:JB3-9-SpringAI(一)
传送门:JB3-9-SpringAI(二)
文章目录
心法:本章使用 Maven 父子结构项目进行练习。
练习项目结构如下:
|_ v3-9-ssm-ai
|_ 13901 springai-chat
|_ 13902 springai-rag
|_ 13903 springai-tool-calling
|_ 13904 springai-mcp-server
|_ 13905 springai-mcp-client
|_ 13906 springai-graph
|_ 13907 springai-agent-chat
|_ 13908 springai-agent-skills
|_ 13909 springai-agent-supervisor
|_ 13910 springai-agent-parallel
|_ 13911 springai-agent-routing
|_ 13999 springai-web
武技:搭建练习项目结构。
- 创建父项目 v3-9-ssm-ai,删除 src 目录。
- 在父项目中锁定版本(SpringAI 对 Jackson 版本要求较高,而 SpringBoot3.2.5 提供的 Jackson 版本是 2.15.4,这里手动提高到 2.17.0 版本):
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<junit.version>4.13.2</junit.version>
<lombok.version>1.18.24</lombok.version>
<hutool-all.version>5.8.25</hutool-all.version>
<jackson.version>2.17.0</jackson.version>
<spring-boot.version>3.2.5</spring-boot.version>
<spring-ai.version>1.1.2</spring-ai.version>
<spring-ai-alibaba.version>1.1.2.0</spring-ai-alibaba.version>
<spring-ai-alibaba-extensions.version>1.1.2.0</spring-ai-alibaba-extensions.version>
<ST4.version>4.3.4</ST4.version>
<redisson-spring-boot-starter.version>3.33.0</redisson-spring-boot-starter.version>
<spring-ai-alibaba-studio.version>1.1.2.2</spring-ai-alibaba-studio.version>
</properties>
- 在父项目中配置里程碑仓库:Spring AI Alibaba 的依赖包暂未完全发布到 Maven 中央仓库,而是在 Spring 官方的里程碑仓库(milestone)里:
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
- 在父项目中管理依赖:
| 依赖项 | 版本 | 描述 |
|---|---|---|
| spring-boot-dependencies | 3.2.5 | SpringBoot 核心依赖清单 |
| spring-ai-bom | 1.1.2 | SpringAI 核心依赖清单 |
| spring-ai-alibaba-bom | 1.1.2.0 | SpringAIAlibaba 核心依赖清单 |
| spring-ai-alibaba-extensions-bom | 1.1.2.0 | SpringAIAlibaba 扩展依赖清单 |
<dependencyManagement>
<dependencies>
<!--spring-boot-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring-ai-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring-ai-alibaba-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>${spring-ai-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring-ai-alibaba-extensions-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-extensions-bom</artifactId>
<version>${spring-ai-alibaba-extensions.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
- 在父项目中引入通用依赖:
<dependencies>
<!--junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<!--hutool-all-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>${hutool-all.version}</version>
</dependency>
<!--jackson-databind-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>${jackson.version}</version>
</dependency>
<!--jackson-core-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>${jackson.version}</version>
</dependency>
<!--jackson-annotations-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>${jackson.version}</version>
</dependency>
</dependencies>
S01. SpringAI入门
AI 系统能力进化路径:
| 阶段 | 系统定位 | 中文 | 简述(工具指的均为 @Tool 方法) | 包含的相关组件 / 技术 |
|---|---|---|---|---|
| 1 | Chat | 基础对话系统 | 提供纯自然语言对话能力,无外部依赖 | 对话模型(ChatModel/ChatClient) 对话选项(ChatOptions) 实体响应(entity) 预设角色(defaultSystem) 对话记忆、模型日志等(advisor) |
| 2 | MultiModal | 多模态系统 | 支持图片、音频等多种模态输入输出 属于横向能力,可附加给任意阶段 | 文生图片模型(ImageModel) 文生音频模型(AudioModel) 文生视频模型(VideoModel) |
| 3 | RAG-Chat | 增强型对话系统 | 基于私有知识库检索 提供精准、专业的领域知识问答 | 检索增强(RAG + ETL) 向量数据库(VectorStore) |
| 4 | Skill | 功能型系统 | 具备对话理解能力 可调用工具执行特定业务动作 | 本地工具调用(FunctionCall/ToolCalling) 外部工具调用(MCP,可选) |
| 5 | Workflow | 工作流系统 | 采用预定义的固定执行路径 不依赖大模型自主决策 工具与流程编排均需手动开发 | 状态图编排(Graph,可选实现方式) |
| 6 | SingleAgent | 单智能体系统 | 动态生成执行路径 由大模型自主决策工具调用顺序与入参 仅需开发工具,无需手动编排流程 | 自主决策智能体(ReactAgent) 状态图编排(Graph,可选实现方式) |
| 7 | MultiAgent | 多智能体系统 | 依靠角色分工、任务拆解与结果汇总 多个独立智能体协同完成复杂目标 | 多智能体编排(AgentScope/AgentGen) |
E01. AI语言模型
心法:LLM(Large Language Model)即大型语言模型,依托海量海量文本数据完成预训练,具备自然语言理解、逻辑推理与内容生成能力,是当下主流人工智能核心基座。
1. 生成式大模型
心法:生成式大模型是能依据提示生成文本、图像、音频、视频、软件代码等全新内容的人工智能。
传统的 LLM 和 生成式 LLM 对比如下:
技术原理方面:
- 传统的 AI:常基于规则和算法,通过对大量标注数据的学习来提取特征,实现分类、预测等任务。
- 生成式 AI:以生成模型为核心,通过对海量数据的无监督或半监督学习,掌握数据内在模式和分布,进而生成新数据。
功能特点方面:
- 传统的 AI:擅长执行特定任务,像语音识别、图像识别、医疗影像诊断、金融风险预测等,专注在已知模式和规则下对输入数据分类、判断和预测,不具备内容创造能力。
- 生成式 AI:突出特点是创造新内容,涵盖文本、图像、音频、视频等,还能进行代码补全、场景模拟等。例如根据文本描述生成对应图像,或依据简单旋律拓展成完整乐曲。
应用场景方面:
- 传统的 AI:广泛用于需要精准判断和预测的领域,比如在安防监控中识别异常行为,电商推荐系统依据用户行为和偏好推荐商品,工业生产中检测产品缺陷等。
- 生成式 AI:多用于创意和内容生成领域,比如广告营销生成创意文案和设计,游戏开发自动生成地图、角色和剧情,影视制作生成特效和虚拟场景。
2. 令牌单位Token
心法:Token 是大模型解析、处理、输出文本的最小运算单位,各厂商分词规则略有差异,各家 LLM 厂商都有自己的切字逻辑,但整体来看,大约一个 token 等于 0.5 ~ 1 个汉字。
AI 接口单次请求总消耗 Token 计算公式:
# 总 Token 数 = (输入提示词 Token) + (模型回复 Token) + (缓存上下文 Token)
total_tokens = prompt_tokens + completion_tokens + cached_tokens
3. 提示词Prompt
心法:提示词,是你向大模型下发的指令、问题与交互上下文,是控制模型输出效果的核心,一个完整的提示词包含模型 model,用户输入 input 和请求参数 parameters 三部分。
模型 model:主要规定了本次请求使用的大模型:
- 如深推理模型 qwen-max:深度思考模型。
- 如纯文本模型 qwen-plus:通用文本模型,默认值。
- 如多模态模型 qwen3.6-plus:多模态专用模,需手动启用。
- 其它模型参考 阿里模型列表 即可。
用户输入 input:包含各种角色以及对应的消息内容,目前内置四大交互角色:
- 系统角色 system:设定模型人设风格,官方不推荐滥用,易干扰逻辑推理
- 用户角色 user:用于向模型传递问题、指令或上下文等
- 助手角色 assistant:模型对用户消息的回复
- 工具角色 tool:函数调用、外部工具返回结果
示例:
"input": {
"messages": [
{ "role": "user", "content": "50字以内,介绍常用的AI编程工具" }
]
},
请求参数 parameters:本次调用附加的其它参数配置(均在 "parameters": {} 中进行配置):
| 配置项 | 简述 | 详述 |
|---|---|---|
temperature: 0.8 | 随机采样温度 | 控制模型生成文本的多样性,取值范围 [0, 1] 数值越高,回答越灵活发散 数值越低,回答越严谨固定、重复性越强 qwen-plus 默认 0.8 |
maxTokens: 59277 | 最大输出长度 | 限制模型单次回复最大 Token 数量 超出则提前终止并返回 finish_reason: lengthqwen-turbo 最大 Token 数量 ≤ 1500 qwen-plus 最大 Token 数量 ≤ 2000 qwen-max 最大 Token 数量 ≤ 8192 qwen3.6-plus 最大 Token 数量 ≤ 65536 |
enable_thinking: true | 深度思考开关 | 开启深度思考模型的思考模式(其它模型开启无效),参考 深度思考 true: 开启后,思考内容将通过 reasoning_content 字段返回 false:关闭深度思考,精简 Token 消耗、提升响应速度 |
stream: false | 流式输出开关 | 是否使用流式回复(底层使用 SSE 推送): true:流式逐字输出。 false:完整一次性输出,默认值。 |
multi_model: true | 多模态能力开关 | 如果使用多模态模型如 qwen3.6-plus,则必须配置此项,纯文本模型无需配置 |
武技:测试标准请求体格式。
- 在父项目中直接新建一个 PromptTest.http 文件,组装提示词并向 阿里云百炼通义大模型的文本生成标准调用接口 发送请求:
POST https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation
Authorization: Bearer {{API_KEY}}
Content-Type: application/json
{
"model": "qwen-plus",
"input": {
"messages": [
{
"role": "user",
"content": "50字以内,介绍Ollama工具"
}
]
},
"parameters": {
"temperature": 0.8,
"max_tokens": 2000,
"stream": false
}
}
3. 本地部署Deepseek
心法:Ollama 是一款开源、轻量、跨平台的本地大模型运行管理工具,主打一键在个人电脑或服务器上部署、调度各类开源大语言模型(Deepseek,Llama、Qwen、Mistral、Phi、Llama3、GLM 等),不用复杂配置环境,普通人也能轻松跑本地的大模型。
Ollama 工具常用命令:
| 命令 | 英文说明 | 中文释义 |
|---|---|---|
| ollama | Show all available commands | 展示全部可用命令 |
| ollama serve | Start ollama | 启动 Ollama 后台服务 |
| ollama create | Create a model from a Modelfile | 根据 Modelfile 文件创建自定义模型 |
| ollama show | Show information for a model | 查看指定模型的详细信息 |
| ollama run | Run a model | 运行并加载模型,开启对话交互 |
| ollama stop | Stop a running model | 停止正在运行中的模型 |
| ollama pull | Pull a model from a registry | 从模型仓库拉取下载模型 |
| ollama push | Push a model to a registry | 将本地模型上传推送至模型仓库 |
| ollama list | List models | 列出本地已下载的所有模型 |
| ollama ps | List running models | 查看当前正在运行的模型 |
| ollama cp | Copy a model | 复制模型(可给模型起新标签别名) |
| ollama rm | Remove a model | 删除本地存储的模型文件 |
| ollama help | Help about any command | 查看任意命令的详细帮助文档 |
武技:使用 Ollama 工具,本地部署 Deepseek 模型。
- 下载 ollama 工具,该工具会在本地服务监听 11434 端口。
- 安装 ollama 工具:双击安装默认在 C 盘,推荐使用 CMD 命令行指定位置安装:
# 使用 CMD 指定位置安装 ollama 工具(目录需要自己提前创建)
OllamaSetup.exe /DIR=D:\ollama
# 查看 ollama 工具版本
ollama --version
- 配置系统环境变量,指定大模型产品的安装位置(默认安装到 C 盘):
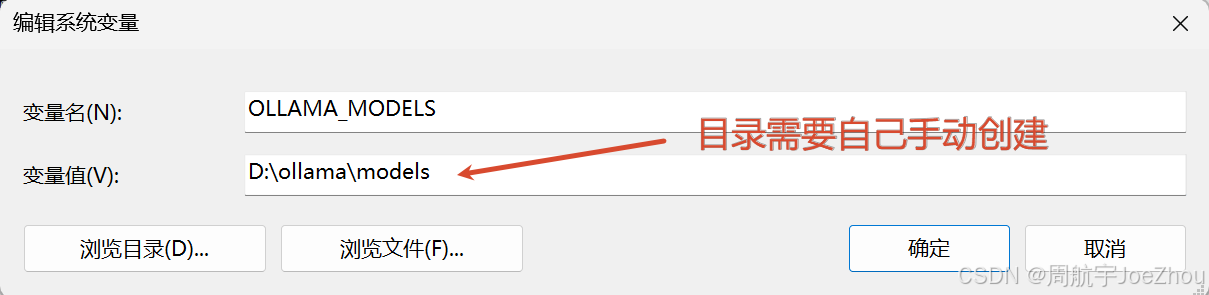
- 原地重启 ollama 工具(右下角退出),否则不生效。
- 使用 CMD 命令下载 deepseek-r1:1.5b 模型:
ollama run deepseek-r1:1.5b
- 启动模型,测试交互:
cd D:\ollama\bin
# 展示全部下载的大模型
ollama list
# 启动模型
ollama run deepseek-r1:1.5b
4. 通义千问模型Qwen
心法:阿里通义系列大模型是阿里云百炼平台(类似模型商店)主推的商用大模型(商店中的具体产品),覆盖通用对话、深度推理、代码开发、长文本处理等全场景,不同版本定位、性能、上下文长度与适用业务差异明确,可按需选型接入。
为何使用阿里的通义千问模型:
- 原生适配中文生态,对国内开发者使用门槛更低、上手更顺畅。
- 提供丰富免费资源与试用额度,低成本起步、轻松试水。
- 国内节点布局完善,网络访问延迟低、运行稳定性强。
- 与 Spring AI 生态深度适配,项目集成简洁高效,开发效率拉满。
通义千问主流模型分类:
| 特性 | Qwen-3.6-Plus | Qwen-Max | Qwen-Plus |
|---|---|---|---|
| 产品定位 | 全新旗舰 | 高端推理旗舰 | 通用均衡主力 |
| 上线时间 | 2026 年 4 月 最新迭代版本 | 早期经典高端版本 | 早期通用主流版本 |
| 产品定位 | 代码开发 + 智能体专属模型 | 强逻辑 + 高难度深度推理模型 | 高性价比全场景通用模型 |
| 上下文窗口 | 最高 100 万超长 Token | 常规 8K~32K Token | 常规 32K Token |
| 优势适用场景 | 全栈代码生成 项目开发 百万级长文档解析 智能体编排 | 专业医疗研判 金融风控分析 复杂数理推导 高精逻辑运算 | 智能客服接待 文本归纳摘要 日常问答 普通文案创作 |
| 市场表现 | 全球接口调用量稳居前列 | 推理精度高、调用成本偏高 | 受众广、调用成本适中、稳定性强 |
武技:获取阿里云百炼的 API_KEY,该 KEY 相当于调用其大模型服务的身份通行证,系统通过它来识别你的身份、进行权限管理和费用核算。
- 登录 阿里云百炼 页面。
- 对自己的账号进行认证,否则后续使用 API-Key 的时候可能会响应 403 权限不足的错误。
- 依次点击
右上角设置 - API-Key - 创建 API-KEY,然后将 API KEY 记录下来(SK 开头的),归属业务空间选择默认业务空间即可,描述可省略。
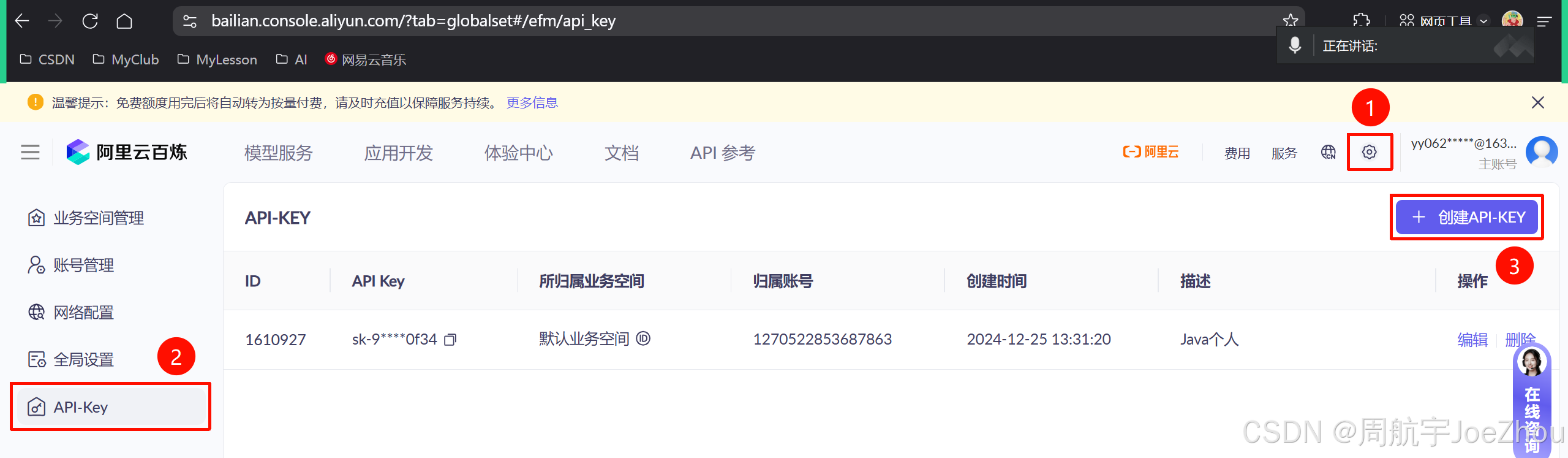
# 设置系统环境变量
setx DASHSCOPE_API_KEY sk-xxxxxxx
# 检查 API-KEY 的环境变量是否生效
echo %DASHSCOPE_API_KEY%
- 可以直接在百炼官网进行 模型调试,如图:
E02. AI应用框架
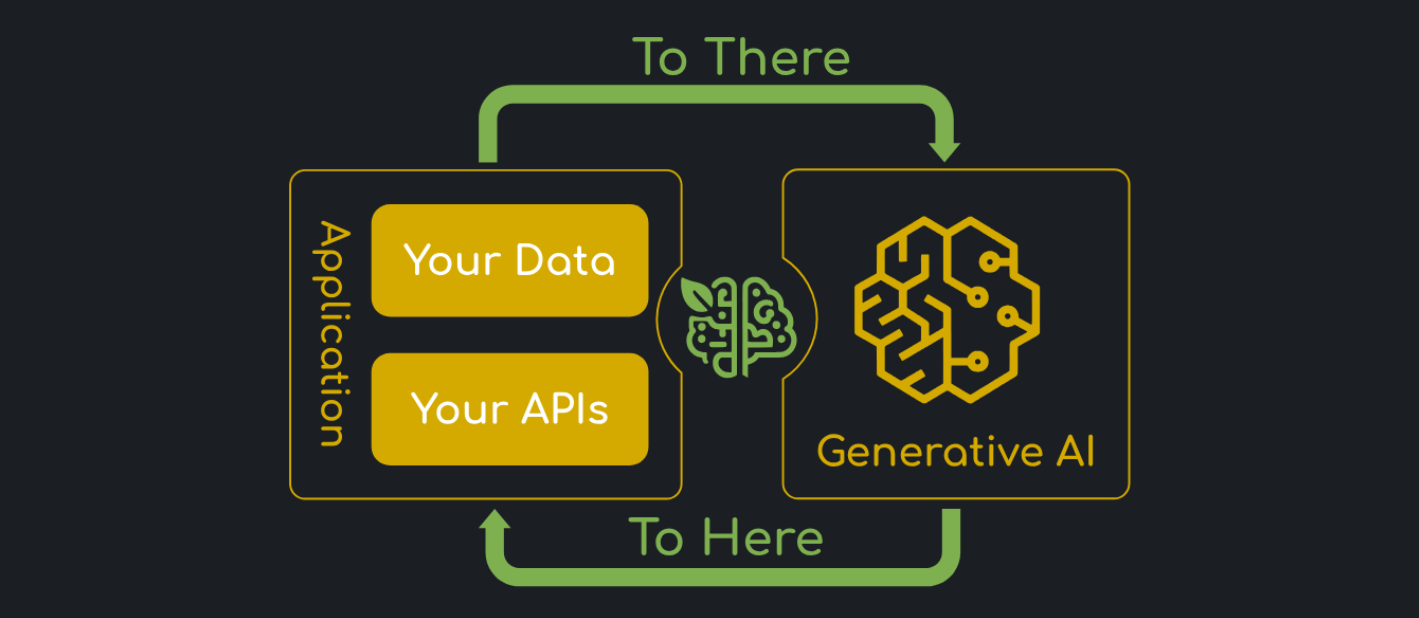
心法:AI 应用框架和大模型的交互,就类似于 WEB 模型中的请求和响应,AI 应用给大模型发消息,大模型给应用返结果。
AI 应用和大模型的交互流程 - 图示:
- To There:AI 应用将自身的数据和通过 API 获取的信息发送给大模型,供其处理和利用。
- To Here:大模型处理完信息后,将结果返回给 AI 应用。
1. SpringAI
心法:SpringAI 是 Spring 官方 2024 年正式推出的 AI 开发框架,借鉴 LangChain、LlamaIndex 主流 AI 框架设计思想,并非简单复刻移植,专为 Java 生态量身打造,实现像写 SpringBoot 项目一样轻松开发 AI 应用。
SpringAI 设计理念:生成式 AI 应用不再局限于 Python 技术栈,全面向 Java 等主流编程语言下沉,让后端开发者低成本快速落地 AI 业务。
SpringAI 框架特点:堪称大模型领域的通用标准适配器,开发者只需掌握一套统一接口,即可无缝对接市面上各类主流大模型:
- SpringAI 制定并统一了 Java 生态下 AI 开发的标准与编程范式。
- SpringAI 统一封装了对话模型、对话客户端、提示词、向量嵌入、向量数据库、MCP 工具调用等核心顶层接口。
- SpringAI 彻底屏蔽不同厂商模型的调用差异,做到 “一套代码随意切换模型”,无需重复修改业务逻辑。
2. SpringAiAlibaba
心法:SpringAiAlibaba 早期仅作为 SpringAI 对接阿里云模型的适配插件,1.1.2.x 及以上高版本全面升级,成为 Java 端一站式企业级 AI 全栈开发框架,集齐模型调用、智能体开发、流程编排、可视化运维全能力。
SpringAI Alibaba 框架定位:深度对接阿里云百炼 DashScope 服务,极速接入通义千问、DeepSeek、文生图、语音合成、多模态识图等全品类 AI 能力,自动封装密钥鉴权、请求组装、结果解析、全局异常捕获,简化阿里云生态 AI 开发流程。
SpringAI Alibaba 组件如下:
| 组件名称 | 定位 | 通俗功能说明 |
|---|---|---|
| Spring AI Alibaba Agent | 智能体框架 | 专为复杂业务打造的智能执行中枢,自带 ReAct 推理思考能力 能自动拆分繁杂任务、统一管理对话上下文,还可自主调用各类工具 也能实现多个智能体配合协作,独立完成整套业务流程 |
| Spring AI Alibaba Graph | 工作流引擎 | AI 业务专属流程编排工具,把零散的 AI 功能有序串联起来 支持设置流程走向分支、多任务同步运行 也能随时暂停中断流程,出错自动重试 还能保存执行状态,后续继续接续运行 |
| Spring AI Alibaba Admin | 可视化管理平台 | 一站式调试运维管理后台,轻松对接企业现有业务平台,大幅简化上线与日常维护工作 可直观调试对话效果、查看调用链路与耗时数据,评测模型输出质量等 |
SpringAI 对比 SpringAI Alibaba:单纯使用通用大模型调用,只用原生 SpringAI 即可,如需要对接阿里云专属能力、开发智能体业务,必须引入 SpringAI Alibaba 依赖:
- SpringAI:顶层通用标准,定接口、定规范,是所有 Java AI 框架的基础底座。
- SpringAI Alibaba:基于 SpringAI 标准做阿里云生态深度落地,在通用能力之上,新增智能体、工作流、可视化平台等企业级高阶能力。
S02. 智能对话
E01. 基础对话模型
心法:通过 ChatClient API,你可以方便地向 AI 聊天模型发送消息,并且接收它回复的消息,就像在和一个真实的人聊天一样。
武技:创建 springai-chat 子项目,并完成初始化。
- 添加三方依赖:
<dependencies>
<!--spring-boot-starter-web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--spring-ai-alibaba-starter-dashscope-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<!--ST4-->
<dependency>
<groupId>org.antlr</groupId>
<artifactId>ST4</artifactId>
<version>${ST4.version}</version>
</dependency>
</dependencies>
- 开发主配文件:
server:
port: 13901 # 端口号
servlet:
encoding:
charset: utf-8 # 字符集(解决 stream 中文乱码)
enabled: true # 启用字符编码(解决 stream 中文乱码)
force: true # 强制使用字符编码(解决 stream 中文乱码)
spring:
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY} # 阿里云百炼 API_KEY
read-timeout: 100000 # 读取超时时间(毫秒)
chat:
options:
model: qwen-plus # 基础对话模型
max-tokens: 1000 # Token 限制
temperature: 0.5 # 采样温度
retry:
max-attempts: 10 # 最大重试次数(默认3次,调大)
backoff:
initial-interval: 10000 # 初始轮询间隔(毫秒)
max-interval: 20000 # 最大轮询间隔(毫秒)
- 开发启动类:
package com.joezhou;
/** @author 周航宇 */
@SpringBootApplication
public class ChatApp {
public static void main(String[] args) {
SpringApplication.run(ChatApp.class, args);
}
}
1. ChatModel
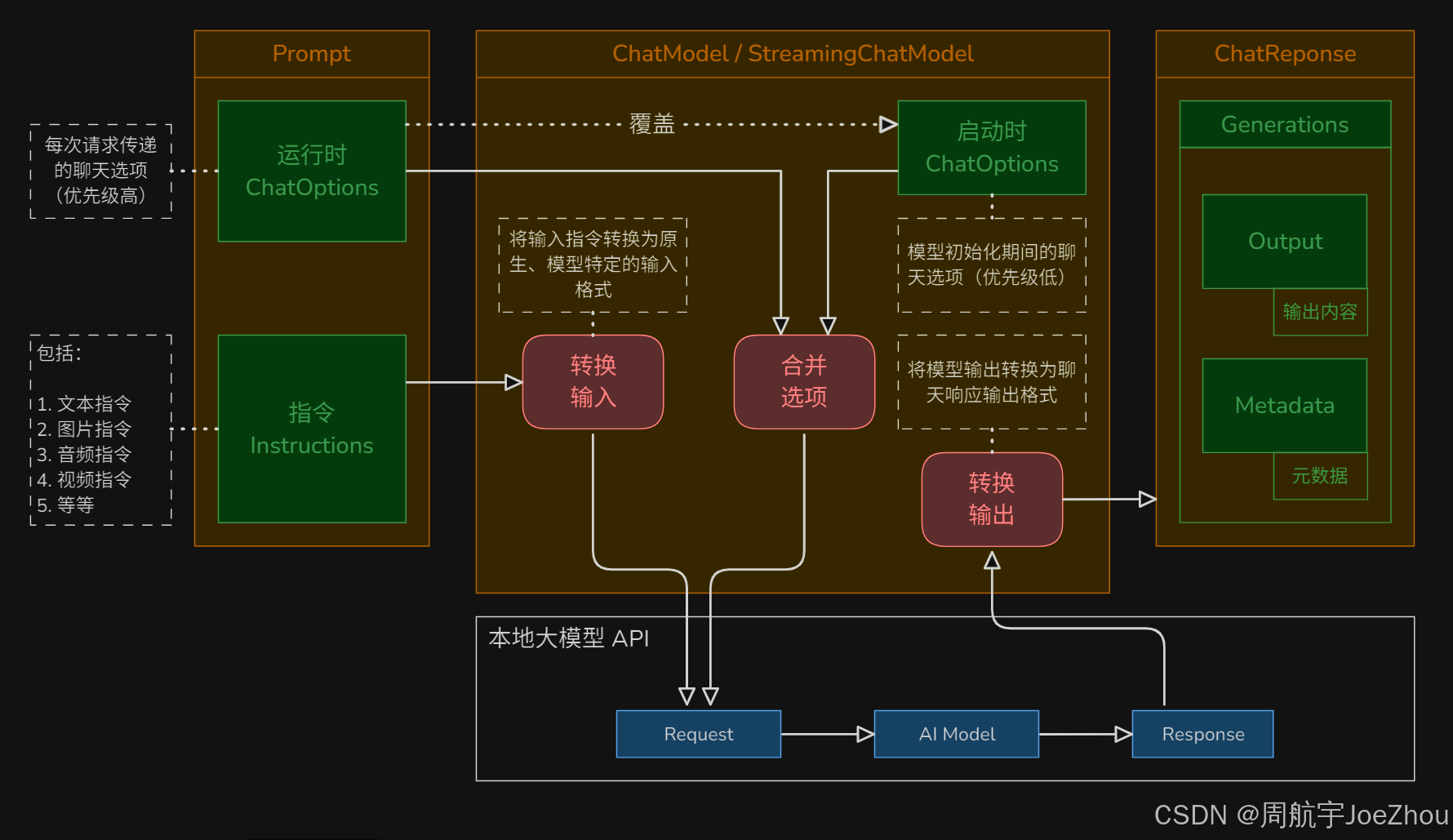
心法:SpringAI 提供了 ChatModel 接口(代表与大模型的对话能力),封装了模型调用的细节,只负责发送请求和获取回复,无任何业务能力,引入模型的 starter 启动器后可以直接从容器中注入使用,该接口支持 “同步” 和 “流式” 两种获取消息的类型。
模型调用过程:
| 步骤 | 简述 | 详述 |
|---|---|---|
| 01 | 发送请求 | 浏览器发送请求,携带 Prompt(包含用户输入 Message 和运行时 ChatOptions) |
| 02 | 合并配置 | 服务器使用 “用户运行时 ChatOptions 配置” 覆盖 “系统启动时 ChatOptions 配置” |
| 03 | 输入转换 | 服务器将参数和合并后的 ChatOptions 配置封装为对应大模型的原生 Request 对象 |
| 04 | 模型交互 | 服务器将 Request 发送给 AIModel,模型推理并返回原生 Response 对象 |
| 05 | 输出转换 | 服务器将原生 Response 转换为统一的 ChatResponse 格式 |
| 06 | 执行响应 | 服务器将 ChatResponse 返回给浏览器 |
图示如下:
武技:使用 ChatModel 与模型进行交互。
- 开发控制器:
package com.joezhou.controller;
import org.springframework.ai.chat.model.ChatModel;
/** @author 周航宇 */
@RequestMapping("/api/v1/chatModel")
@RestController
@CrossOrigin
public class ChatModelController {
private final ChatModel chatModel;
public ChatModelController(ChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("call")
public String call(@RequestParam("msg") String msg) {
return chatModel.call(msg);
}
@GetMapping("stream")
public Flux<String> stream(@RequestParam("msg") String msg) {
return chatModel.stream(msg);
}
}
- 测试控制器:
### call
GET http://localhost:13901/api/v1/chatModel/call?
msg=讲个50字左右的笑话
### stream
GET http://localhost:13901/api/v1/chatModel/stream?
msg=讲个50字左右的笑话
2. ChatOptions
心法:ChatOptions 是 SpringAI 提供的一个用于配置大模型参数的对象,统一封装了 temperature,model,maxTokens 等模型参数。
ChatOptions 分类:
- 启动时配置对象:如果在创建 ChatModel 的时候指定 ChatOptions 对象,那么该对象就是一个启动时配置对象,优先级低(等效于主配中的对应配置)。
- 运行时配置对象:如果在调用 call() 或 stream() 方法时指定 ChatOptions 对象,那么该对象就是一个运行时配置对象,优先级高,会覆盖启动时配置对象中的对应配置项。
武技:测试 ChatOptions 对象。
- 开发控制器:
package com.joezhou.controller;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.messages.Message;
/** @author 周航宇 */
@RequestMapping("/api/v1/chatOptions")
@RestController
@CrossOrigin
public class ChatOptionsController {
private final ChatModel chatModel;
public ChatOptionsController(ChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("options")
public String options(@RequestParam("msg") String msg) {
// 构建消息
List<Message> messages = List.of(
new SystemMessage("你是一个专业的AI助手。"),
new UserMessage(msg)
);
// 构建配置
ChatOptions chatOptions = ChatOptions.builder()
.model("qwen-max")
.temperature(0.9)
.maxTokens(20)
.build();
// 构建提示词
Prompt prompt = new Prompt(messages, chatOptions);
// 交互
ChatResponse chatResponse = chatModel.call(prompt);
// 查看元数据
ChatResponseMetadata metadata = chatResponse.getMetadata();
System.out.println("响应ID:" + metadata.getId());
System.out.println("输入token:" + metadata.getUsage().getPromptTokens());
System.out.println("输出token:" + metadata.getUsage().getCompletionTokens());
System.out.println("总计token:" + metadata.getUsage().getTotalTokens());
// 响应
return chatResponse.getResult().getOutput().getText();
}
}
- 测试控制器:
### options
GET http://localhost:13901/api/v1/chatOptions/options?
msg=讲个笑话
3. ChatClient
心法:ChatClient 是对 ChatModel 的同步对话或流式对话的封装,封装了模型输入(Prompt),解析模型输出(ChatResponse)以及和设置模型参数(ChatOptions) 这三个基本功能,但本身默认也没有提供对话记忆,工具调用,流程控制等业务功能。
ChatClient 构建方式(一):自己创建 ChatClient.Builder 对象:
private final ChatClient chatClient;
public AiChatController(ChatModel chatModel) {
this.chatClient = ChatClient.builder(chatModel).build();
}
ChatClient 构建方式(二):直接从容器中注入 ChatClient.Builder 对象(推荐):
private final ChatClient chatClient;
public AiChatController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
武技:使用 ChatClient 与模型进行对话。
- 开发控制器:
package com.joezhou.controller;
import org.springframework.ai.chat.model.ChatModel;
/** @author 周航宇 */
@RequestMapping("/api/v1/chatClient")
@RestController
@CrossOrigin
@SuppressWarnings("all")
public class ChatClientController {
private final ChatClient chatClient;
private final ChatClient chatClient02;
public ChatClientController(ChatClient.Builder chatClientBuilder, ChatModel chatModel) {
this.chatClient = chatClientBuilder.build();
this.chatClient02 = ChatClient.builder(chatModel).build();
}
@GetMapping("call")
public String call(@RequestParam("msg") String msg) {
return chatClient.prompt()
// 设置用户消息
.user(msg)
// 同步发送消息,此时该方法会将响应结果一次性响应给前端
.call()
// 获取响应内容
.content();
}
@GetMapping("stream")
public Flux<String> stream(@RequestParam("msg") String msg) {
return chatClient.prompt()
// 设置用户消息
.user(msg)
// 流式发送消息,此时该方法会将响应结果以流的形式推送给前端
.stream()
// 获取响应内容
.content()
// 约定返回一个结束标记,方便前端灵活终止 SSE 推送
.concatWith(Flux.just("[over]"));
}
@GetMapping("options")
public String options(@RequestParam("msg") String msg) {
// 构建配置
ChatOptions chatOptions = ChatOptions.builder()
.model("qwen-max")
.temperature(0.9)
.maxTokens(20)
.build();
ChatResponse chatResponse = chatClient.prompt()
// 设置用户消息
.user(msg)
// 设置模型参数
.options(chatOptions)
// 同步发送消息,此时该方法会将响应结果一次性响应给前端
.call()
// 获取 ChatReponse 类型的响应
.chatResponse();
// 查看元数据
ChatResponseMetadata metadata = chatResponse.getMetadata();
System.out.println("响应ID:" + metadata.getId());
System.out.println("输入token:" + metadata.getUsage().getPromptTokens());
System.out.println("输出token:" + metadata.getUsage().getCompletionTokens());
System.out.println("总计token:" + metadata.getUsage().getTotalTokens());
// 返回响应内容
return chatResponse.getResult().getOutput().getText();
}
}
- 测试控制器:
### call
GET http://localhost:13901/api/v1/chatClient/call?
msg=讲个50字以内的笑话
### stream
GET http://localhost:13901/api/v1/chatClient/stream?
msg=讲个50字以内的笑话
### options
GET http://localhost:13901/api/v1/chatClient/options?
msg=讲个50字以内的笑话
4. 响应实体数据
心法:实际开发中,我们期望模型返回结构化数据以方便前端处理,ChatResponse 原生数据冗余且杂乱,因此需要将响应转换为自定义 Bean 对象,提升数据可读性与操作便捷性。
注意:使用实体类作为返回,只能使用 call() 同步调用,无法使用 stream() 流式调用。
武技:测试将模型响应转为实体类。
- 开发实体类:
package com.joezhou.entity;
/** @author 周航宇 */
@Data
public class UserVO implements Serializable {
private String name;
private Integer age;
private Integer gender;
private String info;
}
- 开发控制器:
package com.joezhou.controller;
import com.joezhou.entity.UserVO;
/** @author 周航宇 */
@RequestMapping("/api/v1/chatEntity")
@RestController
@CrossOrigin
public class ChatEntityController {
private final ChatClient chatClient;
public ChatEntityController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@GetMapping("generateUser")
public UserVO generateUser() {
return chatClient.prompt()
.user("根据《乡村爱情电视剧》生成1条剧中人物信息,每条包括:姓名、年龄、性别(0女1男2保密)、信息介绍")
.call()
.entity(UserVO.class);
}
@GetMapping("generateUsers")
public List<UserVO> generateUsers() {
return chatClient.prompt()
.user("根据《乡村爱情电视剧》生成3条剧中人物信息,每条包括:姓名、年龄、性别(0女1男2保密)、信息介绍")
.call()
// 大括号里必须置空
.entity(new ParameterizedTypeReference<List<UserVO>>() {});
}
}
- 测试控制器:
### generateUser
GET http://localhost:13901/api/v1/chatEntity/generateUser
### generateUsers
GET http://localhost:13901/api/v1/chatEntity/generateUsers
5. 预设模型角色
心法:在使用 ChatClient.Builder 构建 ChatClient 时,可以使用
builder.defaultSystem()方法设置预设的系统信息(字符串),该信息通常会作为初始指令传递给 AI 模型,帮助其理解对话的上下文、角色或任务要求。
注意事项:
- 系统信息通常是纯文本,但某些 API 可能支持 Markdown 或其他格式(需查阅具体文档)。
- 避免使用特殊字符或格式,除非 API 明确支持。
- 系统信息会应用于所有对话轮次,除非在单次请求中覆盖它。
- 某些 API 可能对系统信息的长度有限制(例如 OpenAI 的 GPT 模型建议控制在几百个 token 内)。
- 不要在系统信息中包含敏感信息(如 API 密钥、用户数据等)。
武技:测试 SpringAI 的预设角色功能。
- 开发控制器:
package com.joezhou.controller;
/** @author 周航宇 */
@RequestMapping("/api/v1/systemRole")
@RestController
@CrossOrigin
public class SystemRoleController {
private final ChatClient chatClient;
public SystemRoleController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
.defaultSystem("""
你叫詹姆斯9527,你是一个脾气非常不好的人;
你从来不会用 “我” 来指代自己,你只会用 “老子” 来指代自己;
今天的日期是 {today};
""")
.build();
}
@GetMapping("call")
public String call(@RequestParam("msg") String msg) {
return chatClient.prompt()
.user(msg.trim())
.system(e -> e.param("today", LocalDate.now()))
.call()
.content();
}
}
- 测试控制器:
### call()
GET http://localhost:13901/api/v1/systemRole/call?
msg=你是谁啊
6. 提示词动态渲染
心法:StringTemplate4(简称 ST4),来自 org.antlr:ST4 依赖,是一套标准化、高复用、安全稳定的 Prompt 动态渲染工具,相比原生字符串拼接 / 格式化,ST4 可以彻底隔离业务代码与提示词文本,大幅降低超长、复杂结构化提示词的编写、迭代与维护成本,适配企业级 AI 应用提示词工程化落地。
ST4 核心:它只负责安全、灵活地把变量填充进 Prompt 骨架,生成最终发给大模型的文本。
ST4 提示词 对比 原生提示词:
| 对比维度 | String 代码行提示词 | String 代码块提示词 | ST4 模板提示词 |
|---|---|---|---|
| 可读性 灵活性 | 用加号拼接,参数越多,代码越乱 可读性差,灵活度高 | 使用内置的占位符如 %s 等可读性高,灵活度低 | 使用自定义占位符如 <name> 等可读性高,灵活度高 |
| 安全性 | 拼错只会生成错乱文本,不抛异常 全程无校验,安全性极差 | 仅参数数量、类型不匹配时抛异常 运行期校验,安全性中等 | 变量和语法等错误直接抛出异常 渲染期 + 编译期双重校验,最安全 |
| 功能性 | 只能纯文本拼接,不支持逻辑处理 功能性低 | 只能纯文本拼接,不支持逻辑处理 功能性低 | 原生支持分支、循环、嵌套、函数等 功能性高 |
| 复用性 | 每个接口都需要重复写一遍提示词 复用性低 | 每个接口都需要重复写一遍提示词 复用性低 | 模板全局复用,一处修改全项目生效 复用性高 |
| 耦合度 维护性 | 提示词硬编码嵌入业务代码 耦合度高,维护性低 | 提示词硬编码嵌入业务代码 耦合度高,维护性低 | 模板内容可以抽离成单独的 st 文件 耦合度低,维护性高 |
| 扩展性 | 新增内容时所有拼接代码全部改动 扩展性低 | 新增内容时所有拼接代码全部改动 扩展性低 | 仅修改模板,业务调用代码无需改动 扩展性高 |
| 适用场景 | 超简短单句静态文本拼接 | 短文本、少量变量填充的提示词 | 企业级复杂模板和结构化输出 |
ST4 转义规则:
- ST 模板内支持单行注释
//和块注释/* 内容 */,渲染时自动丢弃注释内容,但禁止使用行尾注释,以免破坏换行排版与解析。 - ST 模板内的
< > $ " “” \ { }都是 ST 关键字,直接写会解析崩溃,推荐统一使用单引号或使用转义字符。 - ST 内联模板可使用
"""字符块定义,保留换行,空格和缩进,而 ST 文件自带换行排版,无需额外处理。 - ST 模板中的所有所有变量必须通过
add(key, val)注入,严禁止字符串拼接,杜绝拼接带来的安全漏洞。 - ST 模板中出现的所有变量必须通过
add(key, val)完整赋值,缺失变量渲染直接抛出异常,不会填充空值兜底。
ST4 语法示例:
// 定义 ST 模板内容
String stTemplate = """
你是:<name>
核心职责:
<duties:{ duty |<i>、<duty>;
}>
回答规则(必须严格遵守):
<if(showRules)>
- 每条回复字数不超过 <maxLength> 字。
<endif>
""";
// 创建字符串模板对象,默认使用 < 和 > 作为模板变量的前后缀
ST st = new ST(stTemplate);
// 填充模板参数
st.add("name", "办公助手");
st.add("duties", List.of("记录日程", "会议管理", "会议记录"));
st.add("showRules", true);
st.add("maxLength", 20);
// 渲染生成最终系统提示词
log.info("渲染后的系统提示词: \n{}", st.render());
武技:测试使用 ST 模板建造提示词。
- 开发提示词 ST 文件:采用
$$作为变量分隔符,适配部分场景避免和尖括号冲,文件位置和名称随意:
classpath:prompt/commonPrompt.st:
你是:$name$
核心职责:
$duties:{ duty |$i$、$duty$;
}$
回答规则(必须严格遵守):
$if(showRules)$
- 每条回复字数不超过 $maxLength$ 字。
- 只输出纯中文文本,严禁输出JSON、代码块或其他格式。
- 禁止展示思考过程、推理过程或任何工具调用细节。
- 若无法回答,直接告知用户“无法回答”,不做额外解释。
$endif$
- 开发 ST 工具类:
package com.joezhou.util;
/** @author 周航宇 */
@Slf4j
public class StUtil {
/** 模板分隔符开始字符 */
private static final char DELIMITER_START_CHAR = '$';
/** 模板分隔符结束字符 */
private static final char DELIMITER_STOP_CHAR = '$';
/** 资源加载器 */
private static final DefaultResourceLoader RESOURCE_LOADER = new DefaultResourceLoader();
/**
* 通过加载 .st 文件模板(使用 $ 分隔符)来构建 ST 实例
*
* @param location 资源路径 prompt/xxx.st
* @return ST 实例
*/
public static ST loadStFile(String location) {
try {
// 加载资源,支持 classpath 下的文件
Resource resource = RESOURCE_LOADER.getResource(location);
// 读取文件内容
Path path = resource.getFile().toPath();
// 读取文件内容
String content = Files.readString(path, StandardCharsets.UTF_8);
// 构建 ST 对象
return new ST(content, DELIMITER_START_CHAR, DELIMITER_STOP_CHAR);
} catch (Exception e) {
throw new RuntimeException("加载 classpath 下 .st 文件模板失败", e);
}
}
/**
* 构建内联字符串模板(使用 < 和 > 分隔符)
*
* @param templateText 模板文本
* @return ST 实例
*/
public static ST build(String templateText) {
return new ST(templateText);
}
}
- 开发控制器:
package com.joezhou.controller;
/** @author 周航宇 */
@Slf4j
@RequestMapping("/api/v1/promptTemplate")
@RestController
@CrossOrigin
public class PromptTemplateController {
private final ChatClient chatClient;
public PromptTemplateController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@SneakyThrows
@GetMapping("/office")
public Flux<String> office(@RequestParam("msg") String msg) {
// 创建 ST 对象,默认使用 < 和 > 作为模板变量的前后缀
ST st = StUtil.build("""
你是:<name>
核心职责:
<duties:{ duty |<i>、<duty>;
}>
回答规则(必须严格遵守):
<if(showRules)>
- 每条回复字数不超过 <maxLength> 字。
- 只输出纯中文文本,严禁输出JSON、代码块或其他格式。
- 禁止展示思考过程、推理过程或任何工具调用细节。
- 若无法回答,直接告知用户“无法回答”,不做额外解释。
<endif>
""");
// 设置模板参数
st.add("name", "办公助手");
st.add("duties", List.of("记录日程", "会议管理", "会议记录"));
st.add("showRules", true);
st.add("maxLength", 20);
// 渲染模板
String systemPrompt = st.render();
log.info("渲染后的系统提示词: \n{}", systemPrompt);
// 交互
return chatClient.prompt()
.user(msg)
.system(systemPrompt)
.stream()
.content()
.concatWith(Flux.just("[over]"));
}
@SneakyThrows
@GetMapping("/ticket")
public Flux<String> ticket(@RequestParam("msg") String msg) {
// 创建 ST 对象,默认使用 $ 作为模板变量的前后缀
ST st = StUtil.load("classpath:prompt/commonPrompt.st");
// 设置模板参数
st.add("name", "电影票助手");
st.add("duties", List.of("查询电影票", "购买电影票", "取消电影票"));
st.add("showRules", true);
st.add("maxLength", 20);
// 渲染模板
String systemPrompt = st.render();
log.info("渲染后的系统提示词: \n{}", systemPrompt);
// 交互
return chatClient.prompt()
.user(msg)
.system(systemPrompt)
.stream()
.content()
.concatWith(Flux.just("[over]"));
}
}
- 测试控制器:
### office
GET http://localhost:13901/api/v1/promptTemplate/office?
msg=记录今天下午2点的会议,主题是如何成为阿凡达
### ticket
GET http://localhost:13901/api/v1/promptTemplate/ticket?
msg=帮我买一张《阿凡达》的电影票,影院,场次和座位等信息都随意选择
E02. 多模态模型
心法:通义体系多模态统一依托 DashScope 对接,Spring AI 提供 ImageModel,AudioModel 和 VideoModel 等标准顶层接口,设计范式完全一致。
多模态模型选择:
| 相关模型 | 模型定位 | 核心特点 | 适用场景 |
|---|---|---|---|
| CosyVoice-v3-flash | 文 → 语音 | 延迟低,实时性高 成本低,性价比高 | 智能客服,实时语音助手,直播,短视频等 对实时性要求高的交互场景 |
| CosyVoice-v3-plus | 文 → 语音 | 音质高,情感丰富 支持精细指令控制 | 有声书,新闻播报,精品课,角色配音等 对音质和表现力要求高的内容场景 |
| wan2.2-t2i-flash | 文 → 图 | 支持文本生成图像 支持以图搜图、图像问答 支持理解图像中的元素 | 广告设计,创意配图,图片分析等场景 |
| wan2.2-t2i-flash | 文 → 视频 | 支持文本生成视频 支持结合图像生成视频 | 广告创意短片,社交媒体动态内容等场景 |
1. 文生图ImageModel
心法:ImageModel 是 Spring AI 提供的图像生成模型统一接口,通过它,我们可以使用一行代码来对接阿里云通义万相、Stable Diffusion 等文生图模型,实现根据文字描述来自动生成图片的 AI 能力。
文生图核心流程:
| 步骤 | 描述 | 其它 |
|---|---|---|
| 01 | 创建图像配置对象 | 使用 DashScopeImageOptions 创建配置(会覆盖主配中的对应配置): 模型:推荐 wan2.2-t2i-flash(阿里云通义万相极速模型) 图像尺寸:推荐 1024 * 1024 图像数量:推荐 1,默认 1 张 |
| 02 | 构建提示词 | 将用户提示词 + 生成配置封装成 ImagePrompt 对象 |
| 03 | 发起模型调用 | 调用 ImageModel 发起文生图请求,得到 ImageResponse 响应结果 |
| 04 | 获取图片 URL | 从响应结果中获取图片 URL(AI 模型一般返回云端临时地址) |
| 05 | 下载图片 | 通过 URL 下载图片到服务端内存 |
| 06 | 进行响应 | 通过 HttpServletResponse 将图片流直接返回给前端展示 |
文生图模型列表参考 文生图模型列表参考
武技:根据用户输入的文本描述,调用阿里云通义万相模型生成图像,并将图像返回给客户端。
- 开发配置文件(额外添加文生图相关配置):
spring:
ai:
dashscope:
...
image:
options:
model: wan2.2-t2i-flash # 文生图模型
width: 1024 # 图片宽度
height: 1024 # 图片高度
n: 1 # 生成数量
- 开发控制器:
package com.joezhou.controller;
import java.net.URL;
/** @author 周航宇 */
@RequestMapping("/api/v1/imageModel")
@RestController
@CrossOrigin
public class ImageModelController {
private final ImageModel imageModel;
private final DashScopeImageOptions dashScopeImageOptions;
public ImageModelController(ImageModel imageModel) {
this.imageModel = imageModel;
// 构建 DashScopeImageOptions 图片配置对象(会覆盖主配中的配置)
this.dashScopeImageOptions = DashScopeImageOptions.builder()
// 设置模型
.model("wan2.2-t2i-flash")
// 设置宽度
.width(1024)
// 设置高度
.height(1024)
// 设置生成图片的数量
.n(1)
.build();
}
@GetMapping("generate")
public void generate(@RequestParam("msg") String msg, HttpServletResponse resp) throws IOException {
// 创建 ImagePrompt 提示词对象:包含文本和配置选项
ImagePrompt imagePrompt = new ImagePrompt(msg, dashScopeImageOptions);
// 调用模型生成图片
ImageResponse imageResponse = imageModel.call(imagePrompt);
// 从 ImageResponse 对象中获取生成的图片的地址
String imageUrl = imageResponse.getResult().getOutput().getUrl();
// 从 URL 下载图片
BufferedImage bufferedImage = ImageIO.read(new URL(imageUrl));
// 设置响应类型为图片
resp.setContentType("image/jpeg");
// 输出图片流给前端
try (ServletOutputStream outputStream = resp.getOutputStream()) {
ImageIO.write(bufferedImage, "jpg", outputStream);
outputStream.flush();
}
}
}
2. 文生音频AudioModel
心法:AudioModel 是 Spring AI 统一音频生成顶层接口,标准化对接阿里云语音生成模型(cosyvoice 等),输入文字文案,一键合成人声音频文件,和 ImageModel 代码结构对齐,一套编程范式适配全部生成类多模态能力。
文生音频核心流程:
| 步骤 | 描述 | 其它 |
|---|---|---|
| 01 | 创建音频配置对象 | 使用 DashScopeAudioSpeechOptions 创建配置(会覆盖主配中的对应配置): 模型:推荐 cosyvoice-v3-flash 音色:推荐 longanhuan(女)或 longanyang(男),其余参考 音色列表 格式:推荐 MP3,兼容性最好,Web 实时播放首选 语速:推荐 1.0,范围 0.5(最慢)~ 2.0(最快),默认 1.0 音量:推荐 50,范围 0(静音)~ 100(全开),默认 50 音调:推荐 1.0,范围 0.5(最低)~ 1.5(最高),默认 1.0 采样率:推荐 24000,值越大音质越好,文件也越大: - 可选 8000Hz(类比低清) - 可选 16000Hz(类比标清) - 可选 22050Hz(类比 720p 高清) - 可选 24000Hz(类比 1080p 高清) - 可选 48000Hz(类比 4K 超高清)(默认值) |
| 02 | 构建提示词 | 将用户台词 + 生成配置封装成 TextToSpeechPrompt 对象 |
| 03 | 发起模型调用 | 调用 AudioSpeechModel 发起文生音频请求 得到 Flux<TextToSpeechResponse> 响应结果 |
| 04 | 组装音频数据 | 收集流式返回的音频二进制分片,组装为完整音频字节数组 |
| 05 | 响应音频数据 | 将组装好的音频字节数组返回给客户端,前端支持如下处理: - 使用浏览器直接播放 - 使用 <audio src="接口地址"> 播放- 使用 new Audio(url).play() 播放 |
武技:根据用户输入的文本,调用阿里云通义万相模型生成对应文本的语音,并将语音返回给客户端。
- 开发配置文件(额外添加文生语音相关配置):
spring:
ai:
dashscope:
...
audio:
synthesis:
options:
model: cosyvoice-v3-flash # 语音合成模型
voice: longanhuan # 音色
response-format: mp3 # 音频格式
sample-rate: 24000 # 采样率
speed: 1.0 # 语速
volume: 50 # 音量
pitch: 1.0 # 音调
- 开发控制器:
package com.joezhou.controller;
import org.springframework.http.MediaType;
import java.util.UUID;
/** @author 周航宇 */
@RequestMapping("/api/v1/audioModel")
@RestController
@CrossOrigin
public class AudioModelController {
private final DashScopeAudioSpeechModel audioSpeechModel;
private final TextToSpeechOptions textToSpeechOptions;
public AudioModelController(DashScopeAudioSpeechModel audioSpeechModel) {
this.audioSpeechModel = audioSpeechModel;
// 构建 TextToSpeechOptions 音频配置对象(会覆盖主配中的配置)
this.textToSpeechOptions = DashScopeAudioSpeechOptions.builder()
// 模型
.model("cosyvoice-v3-flash")
// 音色
.voice("longanhuan")
// 音频格式
.responseFormat(DashScopeAudioSpeechApi.ResponseFormat.MP3)
// 采样率
.sampleRate(24000)
// 语速
.speed(1.0)
// 音量
.volume(50)
// 音调
.pitch(1.0)
.build();
}
@GetMapping(value = "/generate")
public ResponseEntity<byte[]> generate(@RequestParam("text") String text) {
// 创建 TextToSpeechPrompt 提示词对象:包含文本和配置选项
TextToSpeechPrompt prompt = new TextToSpeechPrompt(text, textToSpeechOptions);
// 调用模型生成音频流(流式调用,性能更好)
Flux<TextToSpeechResponse> responseFlux = audioSpeechModel.stream(prompt);
// 收集音频数据
byte[] audioData = this.collectAudioData(responseFlux);
// 创建响应头对象,指定音频格式,数据长度以及内联播放(不下载)
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.parseMediaType("audio/mpeg"));
headers.setContentLength(audioData.length);
headers.set(HttpHeaders.CONTENT_DISPOSITION, "inline");
// 直接返回音频数据,浏览器会播放音频
return ResponseEntity.ok().headers(headers).body(audioData);
}
@GetMapping("generateAndDownload")
public String generateAndDownload(@RequestParam("text") String text) {
// 创建 TextToSpeechPrompt 提示词对象:包含文本和配置选项
TextToSpeechPrompt prompt = new TextToSpeechPrompt(text, textToSpeechOptions);
// 调用模型生成音频流(流式调用,性能更好)
Flux<TextToSpeechResponse> responseFlux = audioSpeechModel.stream(prompt);
// 收集音频数据
byte[] audioData = this.collectAudioData(responseFlux);
// 定义本地存储目录,UUID 防止文件名重复冲突
String saveDir = "D:\\workspace\\java\\v3-9-ssm-ai\\springai-chat\\src\\main\\resources\\audio\\";
String fileName = UUID.randomUUID() + ".mp3";
String fullFilePath = saveDir + fileName;
// 写入本地 MP3 文件
try (FileOutputStream fos = new FileOutputStream(fullFilePath)) {
fos.write(audioData);
} catch (IOException e) {
throw new RuntimeException("保存音频文件失败: " + e.getMessage(), e);
}
// 返回音频文件路径
return "音频生成成功:" + fullFilePath;
}
/**
* 收集流式返回的音频二进制分片,拼接为完整音频字节数组
*
* @param flux 语音合成流式响应Flux流,每一项携带一段音频byte分片
* @return 拼接完成的完整音频二进制字节数组,无数据时返回空byte数组
*/
private byte[] collectAudioData(Flux<TextToSpeechResponse> flux) {
// 获取所有音频分片
List<byte[]> chunks = flux
// 过滤空响应、空结果对象
.filter(response -> response != null && response.getResult() != null)
// 从响应结果中提取音频二进制分片
.map(response -> response.getResult().getOutput())
// 收集为 List 列表
.collectList()
// 阻塞等待流式数据全部接收完毕
.block();
// 无音频分片时直接返回空字节数组
if (chunks == null || chunks.isEmpty()) {
throw new RuntimeException("语音合成失败:未生成音频数据");
}
// 计算所有分片总字节长度,初始化最终完整数组
int totalLength = chunks.stream().mapToInt(arr -> arr.length).sum();
byte[] result = new byte[totalLength];
// 记录当前写入位置偏移量
int offset = 0;
// 循环把每一段分片拷贝到大数组内,依次拼接
for (byte[] chunk : chunks) {
System.arraycopy(chunk, 0, result, offset, chunk.length);
offset += chunk.length;
}
// 返回拼接完整音频字节数组
return result;
}
}
- 使用浏览器直接访问控制器 http://localhost:13901/api/v1/audioModel/generate?text=你好,欢迎使用语音合成服务
- 使用浏览器直接访问控制器 http://localhost:13901/api/v1/audioModel/generateAndDownload?text=你好,欢迎使用语音合成服务
3. 文生视频VideoModel
心法:VideoModel 是 Spring AI 统一视频生成顶层接口,视频生成耗时较长(通常 1 ~ 5 分钟),采用异步任务模式提交任务获取 taskId,轮询等待完成后获取视频 URL,而非像音频那样流式返回。
文生视频核心流程:
| 步骤 | 描述 | 其它 |
|---|---|---|
| 01 | 创建音频配置对象 | 使用 DashScopeVideoOptions 创建配置(会覆盖主配中的对应配置): 模型:推荐 wan2.1-t2v-turbo 分辨率:推荐 720P,比 1080P 性价比高 负提示:推荐 “模糊、变形、低画质、扭曲、画面抖动” 等 智能改写:推荐启用,默认关闭 视频种子:固定种子可复现结果,默认随机种子 时长:默认 5 秒 |
| 02 | 构建提示词 | 将用户描述 + 生成配置封装成 VideoPrompt 对象 |
| 03 | 发起模型调用 | 调用 VideoModel 发起文生视频请求 得到 VideoResponse 响应结果 |
| 04 | 拉取视频数据 | 从 VideoResponse 对象中获取生成的临时视频的地址 拉取完整视频二进制字节 |
| 05 | 响应视频数据 | 将组装好的视频字节数组返回给客户端,前端支持如下处理: - 使用浏览器直接播放 - 使用 <video src="接口地址"> 播放- 使用 new Video(url).play() 播放 |
武技:根据用户输入的文本生成视频。
- 开发配置文件(额外添加文生视频相关配置):
spring:
ai:
dashscope:
...
video:
options:
model: wan2.1-t2v-turbo # 文生视频模型
resolution: 720P # 视频分辨率
negative-prompt: 模糊、变形、低画质、扭曲、画面抖动 # 负提示词,避免生成人
promptExtend: true # 开启智能改写,效果更好
seed: 12345 # 固定种子可复现结果,默认随机种子
- 开发控制器:
package com.joezhou.controller;
import org.springframework.http.MediaType;
import java.util.UUID;
/** @author 周航宇 */
@RequestMapping("/api/v1/audioModel")
@RestController
@CrossOrigin
public class AudioModelController {
private final DashScopeVideoModel videoModel;
private final DashScopeVideoOptions videoOptions;
public VideoModelController(DashScopeVideoModel videoModel) {
this.videoModel = videoModel;
// 构建 DashScopeVideoOptions 视频配置对象(会覆盖主配中的配置)
this.videoOptions = DashScopeVideoOptions.builder()
// 通义万相极速文生视频模型
.model("wan2.7-t2v-2026-04-25")
// 分辨率:720P 或 1080P(1080P费用更高)
.resolution("720P")
// 负提示词:避免生成的视频包含指定的内容
.negativePrompt("模糊、变形、低画质、扭曲、画面抖动")
// 视频时长:2~15秒,整数,默认 5 秒
.duration(2)
// 开启智能改写,效果更好
.promptExtend(true)
// 固定种子可复现结果,默认随机种子
.seed(12345L)
.build();
}
@GetMapping("generate")
public ResponseEntity<byte[]> generate(@RequestParam("text") String text) throws IOException {
// 创建 VideoPrompt 提示词对象:包含画面描述文本和自定义配置
VideoPrompt videoPrompt = new VideoPrompt(text, videoOptions);
// 调用模型生成视频任务
VideoResponse videoResponse = videoModel.call(videoPrompt);
// 从 VideoResponse 对象中获取生成的视频的地址(临时的)
String videoUrl = videoResponse.getResult().getOutput().getVideoUrl();
// 拉取完整视频二进制字节
byte[] videoBytes;
try (BufferedInputStream bis = new BufferedInputStream(new URL(videoUrl).openStream())) {
videoBytes = bis.readAllBytes();
}
// 创建响应头对象,指定视频格式,数据长度以及内联播放(不下载)
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.parseMediaType("video/mp4"));
headers.setContentLength(videoBytes.length);
headers.set(HttpHeaders.CONTENT_DISPOSITION, "inline");
// 直接返回视频数据,浏览器会播放视频
return ResponseEntity.ok().headers(headers).body(videoBytes);
}
@GetMapping("generateAndDownload")
public String generateSaveLocal(@RequestParam("text") String text) {
// 创建 VideoPrompt 提示词对象:包含画面描述文本和自定义配置
VideoPrompt videoPrompt = new VideoPrompt(text, videoOptions);
// 调用模型生成视频任务
VideoResponse videoResponse = videoModel.call(videoPrompt);
// 从 VideoResponse 对象中获取生成的视频的地址(临时的)
String videoUrl = videoResponse.getResult().getOutput().getVideoUrl();
// 定义本地存储目录,UUID 防止文件名重复冲突
String saveDir = "D:\\workspace\\java\\v3-9-ssm-ai\\springai-chat\\src\\main\\resources\\video\\";
String fileName = UUID.randomUUID() + ".mp4";
String fullFilePath = saveDir + fileName;
// 写入本地 MP4 文件
try (BufferedInputStream bis = new BufferedInputStream(new URL(videoUrl).openStream());
FileOutputStream fos = new FileOutputStream(fullFilePath)) {
bis.transferTo(fos);
} catch (IOException e) {
throw new RuntimeException("视频文件保存失败: " + e.getMessage(), e);
}
// 返回成功信息
return "视频生成保存成功,文件完整路径:" + fullFilePath;
}
}
- 使用浏览器直接访问控制器 http://localhost:13901/api/v1/videoModel/generate?text=一只在夕阳下散步的猫
- 使用浏览器直接访问控制器 http://localhost:13901/api/v1/videoModel/generateAndDownload?text=一只在夕阳下狂奔的狗
E03. 顾问拦截器
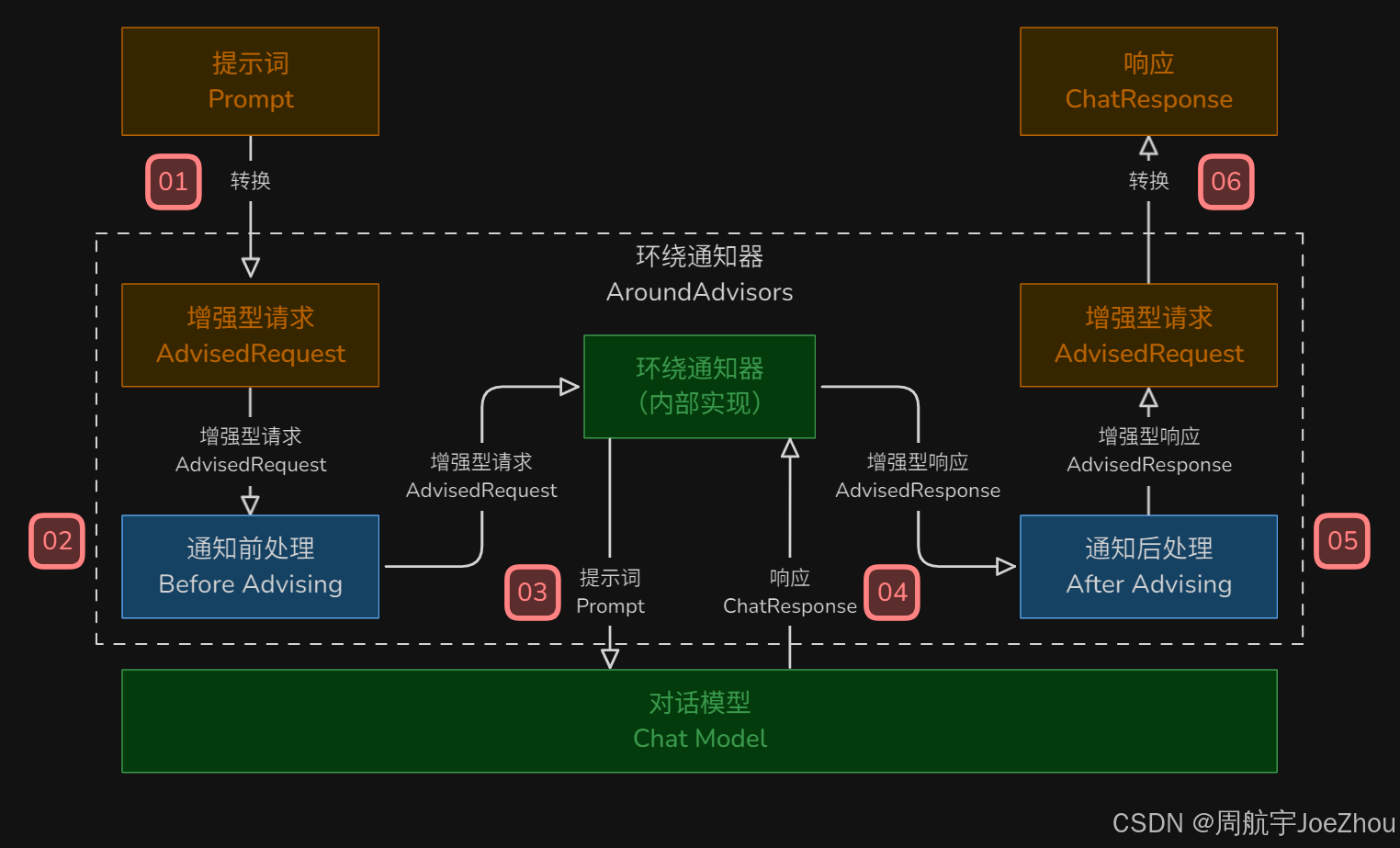
心法:Advisors API 顾问拦截器(简称顾问器)是 SpringAI 里一套灵活强大的扩展机制,本质上就是 AI 交互的拦截器,可以在 ChatClient 调用 call()、stream() 时自动切入,对请求和响应做拦截、修改与增强,以满足不同的业务需求和优化应用程序的 AI 功能。
Advisors 执行流程图示:
1. 请求日志顾问器
心法:SimpleLoggerAdvisor 就是 Spring AI 自带的 自动日志打印工具,你不用写任何
System.out.println或者log.info(),只要把它加到 AI 调用里,它就会自动帮你打印 “用户发送了什么” 以及 “大模型返回了什么”,而且它 不侵入业务代码,所以特别适合开发时调试 bug,生产环境监控,审计对话内容等场景。
SimpleLoggerAdvisor 核心特性:
- 开箱即用:Spring-AI-Chat-Client-starter 已内置 SimpleLoggerAdvisor,直接使用即可。
- 自动抓包:AI 请求发出去前、响应回来后,自动全部记录下来,不用你手动打印:
- 自动抓取请求信息:包含用户消息、系统消息、历史对话等内容。
- 自动抓取响应信息:包含生成的文本、元数据(像 token 数量、模型信息)等内容。
- 自定义打印内容:你可以自定义打印请求的哪部分、响应的哪部分,从而满足不同的调试和审计要求。
- 开关自由:支持根据不同的日志级别(例如 DEBUG、INFO)来开启或关闭日志记录功能,生产环境不会乱打印:
- SimpleLoggerAdvisor 默认使用 DEBUG 级别的输出日志,必须在配置文件中开启对应包的日志权限。
- 即插即用:采用 AOP 切面方式实现,不会对现有的业务逻辑造成影响,加进去就生效。
武技:测试 SimpleLoggerAdvisor 日志通知。
- 调整 SimpleLoggerAdvisor 日志等级以达到开启 SimpleLoggerAdvisor 日志功能的效果:
application.yml:
logging:
level:
org.springframework.ai.chat.client.advisor: DEBUG # 开启 SimpleLoggerAdvisor 日志功能
- 开发控制器:
package com.joezhou.controller;
import java.util.function.Function;
/** @author 周航宇 */
@RequestMapping("/api/v1/loggerAdvisor")
@RestController
@CrossOrigin
public class LoggerAdvisorController {
private final ChatClient chatClient;
public LoggerAdvisorController(ChatClient.Builder chatClientBuilder) {
// 自定义:需要打印的请求日志内容(获取完整提示词文本)
Function<ChatClientRequest, String> requestLogFunction = req -> req.prompt().getContents();
// 自定义:需要打印的响应日志内容(获取AI返回的文本结果)
Function<ChatResponse, String> responseLogFunction = res -> res.getResult().getOutput().getText();
// 执行优先级:数字越小越先执行(0 = 最高优先级)
int order = 0;
// 初始化日志增强器
SimpleLoggerAdvisor loggerAdvisor = new SimpleLoggerAdvisor(requestLogFunction, responseLogFunction, order);
// 构建带日志增强的 ChatClient
this.chatClient = chatClientBuilder
.defaultAdvisors(loggerAdvisor)
.build();
}
@GetMapping("call")
public String call(@RequestParam("msg") String msg) {
return chatClient.prompt()
.user(msg)
.call()
.content();
}
@GetMapping("stream")
public Flux<String> stream(@RequestParam("msg") String msg) {
return chatClient.prompt()
.user(msg)
.stream()
.content()
.concatWith(Flux.just("[over]"));
}
}
- 测试控制器:发送请求后,观察控制台是否记录了对应的请求和响应的日志:
### call:发送请求后,观察控制台是否记录了对应的请求和响应的日志
GET http://localhost:13901/api/v1/loggerAdvisor/call?
msg=讲个50字以内的笑话
### stream:发送请求后,观察控制台是否记录了对应的请求和响应的日志
GET http://localhost:13901/api/v1/loggerAdvisor/stream?
msg=讲个50字以内的笑话
2. 对话记忆顾问器
心法:MessageChatMemoryAdvisor 是 Spring AI 的 对话记忆 顾问器(可以记住历史对话),配合 MessageWindowChatMemory 实现滑动窗口式上下文记忆,让 AI 能记住历史对话内容。
MessageWindowChatMemory:滑动窗口式对话存储器,用来控制 AI 记忆,你可以设置最多记住几条对话,超过数量自动删除最早的记录,防止上下文太长导致请求失败、耗费 token。
conversationId:对话的唯一标识,会话唯一标识。相同标识的对话会共享上下文记忆,不同标识相互隔离,以此实现多用户、多会话的记忆隔离:
- 相同 ID:同一个对话,共享记忆。
- 不同 ID:全新对话,记忆不互通。
武技:测试使用记忆通知功能。
- 开发控制器:
package com.joezhou.controller;
/** @author 周航宇 */
@RequestMapping("/api/v1/memoryAdvisor")
@RestController
@CrossOrigin
public class MemoryAdvisorController {
private final ChatClient chatClient;
public MemoryAdvisorController(ChatClient.Builder chatClientBuilder) {
// 创建滑动窗口记忆对象
MessageWindowChatMemory messageWindowChatMemory = MessageWindowChatMemory.builder()
// 记忆窗口大小:最多保留 10 条对话(用户 + AI各算一条),防止上下文过长
.maxMessages(10)
.build();
// 创建记忆顾问对象:用于将对话记忆注入到 AI 请求中,实现上下文感知
MessageChatMemoryAdvisor messageChatMemoryAdvisor = MessageChatMemoryAdvisor.builder(messageWindowChatMemory)
.build();
// 构建带记忆的 ChatClient
this.chatClient = chatClientBuilder
// 注册记忆顾问(核心:开启对话记忆功能)
.defaultAdvisors(messageChatMemoryAdvisor)
.build();
}
@GetMapping("call")
public String call(@RequestParam("msg") String msg, @RequestParam("conversationId") String conversationId) {
return chatClient
.prompt()
.user(msg)
// 设置对话ID:相同ID使用同一套记忆
.advisors(e -> e.param(ChatMemory.CONVERSATION_ID, conversationId))
.call()
.content();
}
}
- 测试控制器:
### 测试1:发送个人信息(对话ID:123456)
GET http://localhost:13901/api/v1/memoryAdvisor/call?
msg=我今年100岁了&
conversationId=123456
### 测试2:询问年龄(AI 会记住上一条消息,正确回答)
GET http://localhost:13901/api/v1/memoryAdvisor/call?
msg=我多大了&
conversationId=123456
### 测试3:更换对话ID(无记忆,AI 无法回答)
GET http://localhost:13901/api/v1/memoryAdvisor/call?
msg=我多大了&
conversationId=654321
3. 自定义顾问器
心法:Spring AI 中 BaseAdvisor 的核心本质等同于 AOP 环绕增强,能够在大模型调用的全链路前后,实现自定义逻辑的切入与拓展。
Advisor:AI 对话调用的拦截增强器,作用贯穿大模型请求全流程,支持在调用前后介入业务逻辑处理:
- before():AI 发起调用前触发执行,适用于请求日志打印、非法请求拦截、提示词动态组装与优化等场景。
- after():AI 响应返回后触发执行,多用于持久化保存模型回答、更新会话记忆、后置数据统计等场景。
武技:开发自定义助手,用于在 redis 中存储对话记忆。
- 使用 Docker 启动 Redis 服务。
- 在子项目的 POM 文件中添加 Redission 依赖:
<!--redisson-spring-boot-starter-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>${redisson-spring-boot-starter.version}</version>
</dependency>
- 在主配文件中添加 Redission 相关配置:
spring:
data:
redis:
host: 192.168.40.77 # Redis 主机
port: 6379 # Redis 端口
- 开发通知类:
package com.joezhou.advisor;
import org.springframework.ai.chat.messages.Message;
/** @author 周航宇 */
@Slf4j
@Component
@SuppressWarnings("all")
public class RedisAdvisor implements BaseAdvisor {
@Resource
private RedissonClient redissonClient;
/** Redis Key 前缀 */
private static final String KEY_PREFIX = "RedisAdvisor:";
/** 对话 ID 键名 */
private static final String CONVERSATION_ID = "conversationId";
/** 滑动窗口最大消息数(用户 + AI 各算1条) */
private static final int MAX_MESSAGES = 10;
/** 记忆过期时间(分钟):30分钟无操作自动删除 */
private static final long EXPIRE = 30;
/**
* AI 调用前执行:
* 1. 读取 Redis 历史记忆
* 2. 拼接本次用户消息
* 3. 构建完整上下文提示词
*/
@Override
public ChatClientRequest before(ChatClientRequest chatClientRequest, AdvisorChain advisorChain) {
// 获取对话ID:相同ID使用同一套记忆
String conversationId = getConversationId(chatClientRequest);
// 获取本次用户消息
List<Message> currentUserMessages = chatClientRequest.prompt().getInstructions();
// 获取历史消息(用户 + AI):这里 redisMessages 和 promptMessages 均表示历史消息,但作用不同:
// redisMessages:RList 类型,用于更新 Redis 内容
// promptMessages:ArrayList 类型,用于构建新提示词
String key = KEY_PREFIX + conversationId;
RList<Message> redisHistoryMessages = redissonClient.getList(key);
List<Message> promptMessages = new ArrayList<>(redisHistoryMessages);
// 把本次用户消息存入 Redis(更新记忆)
redisHistoryMessages.addAll(currentUserMessages);
redisHistoryMessages.expire(EXPIRE, TimeUnit.MINUTES);
// 构建新提示词(Prompt 是只读对象,必须使用 mutate 构建新对象)
promptMessages.addAll(currentUserMessages);
Prompt newPrompt = chatClientRequest.prompt().mutate().messages(promptMessages).build();
// 构建新请求并返回(请求对象只读,不允许直接修改,只能通过 mutate 方法修改)
log.info("上下文拼接完成,总消息数量:{}", promptMessages.size());
return chatClientRequest.mutate().prompt(newPrompt).build();
}
/**
* AI 调用后执行:
* 1. 获取 AI 回答内容
* 2. 存入 Redis 记忆
* 3. 滑动窗口裁剪
*/
@Override
public ChatClientResponse after(ChatClientResponse chatClientResponse, AdvisorChain advisorChain) {
// 获取对话ID:相同ID使用同一套记忆
String conversationId = getConversationId(chatClientResponse);
String key = KEY_PREFIX + conversationId;
// 获取历史消息(用户 + AI)
RList<Message> historyMessages = redissonClient.getList(key);
// 获取 AI 回复消息
AssistantMessage aiMessage = chatClientResponse.chatResponse().getResult().getOutput();
// 把 AI 回答消息存入 Redis(更新记忆)
historyMessages.add(aiMessage);
// 滑动窗口:只保留最新 MAX_MESSAGES 条,防止上下文过长
if (historyMessages.size() > MAX_MESSAGES) {
List<Message> latestMessages = historyMessages.subList(
historyMessages.size() - MAX_MESSAGES,
historyMessages.size()
);
historyMessages.clear();
historyMessages.addAll(latestMessages);
}
// 刷新过期时间
historyMessages.expire(EXPIRE, TimeUnit.MINUTES);
log.info("记忆保存成功,当前记忆条数:{}", historyMessages.size());
// 返回响应
return chatClientResponse;
}
/** Advisor 唯一名称 */
@Override
public String getName() {
return "RedisAdvisor";
}
/** 执行顺序:数字越小,越先执行 */
@Override
public int getOrder() {
return 0;
}
/**
* 安全获取对话ID,防止空指针异常
*
* @param request 对话请求对象
* @return 对话ID
*/
private String getConversationId(ChatClientRequest chatClientRequest) {
Object id = chatClientRequest.context().get(CONVERSATION_ID);
if (ObjectUtil.isEmpty(id)) {
throw new IllegalArgumentException("请传入对话ID:conversationId");
}
return id.toString();
}
/**
* 安全获取对话ID,防止空指针异常
*
* @param response 对话响应对象
* @return 对话ID
*/
private String getConversationId(ChatClientResponse chatClientResponse) {
Object id = chatClientResponse.context().get(CONVERSATION_ID);
if (ObjectUtil.isEmpty(id)) {
throw new IllegalArgumentException("请传入对话ID:conversationId");
}
return id.toString();
}
}
- 开发控制器:
package com.joezhou.controller;
/** @author 周航宇 */
@RequestMapping("/api/v1/redisAdvisor")
@RestController
@CrossOrigin
public class RedisAdvisorController {
private final ChatClient chatClient;
public RedisAdvisorController(ChatClient.Builder chatClientBuilder, RedisAdvisor redisAdvisor) {
// 构建带记忆的 ChatClient
this.chatClient = chatClientBuilder
// 注册自定义的顾问:开启对话记忆功能
.defaultAdvisors(redisAdvisor)
.build();
}
@GetMapping("call")
public String call(@RequestParam("msg") String msg, @RequestParam("conversationId") String conversationId) {
return chatClient
.prompt()
.user(msg)
// 设置对话ID:相同ID使用同一套记忆
.advisors(e -> e.param("conversationId", conversationId))
.call()
.content();
}
}
- 测试控制器:
### 测试1:发送请求后,查看 redis 中是否存储了该条记忆(一共两条,一条用户消息,一条模型消息)
GET http://localhost:13901/api/v1/redisAdvisor/call?
msg=我今年80岁了&
conversationId=123456
### 测试2:查看模型是否会记住上一条消息,正确回答
GET http://localhost:13901/api/v1/redisAdvisor/call?
msg=我多大了&
conversationId=123456
### 测试3:更换对话ID(无记忆,AI 无法回答)
GET http://localhost:13901/api/v1/redisAdvisor/call?
msg=我多大了&
conversationId=654321
S03. 检索增强
心法:RAG 全称 Retrieval Augmented Generation,即检索增强生成,核心作用是给大模型外挂一套可实时更新的外部知识库,从根源上提升 AI 应用回答的可靠性、时效性与专业度。
传统大语言模型,只能依赖预训练阶段固化的内置知识点作答。一旦遇到实时新知、行业专属业务、私有文档这类内容,很容易答非所问、信息滞后,甚至产生 AI 幻觉(输出看似逻辑通顺、实则完全错误的虚假内容)。
而接入 RAG 架构后,用户提问时会先通过检索算法,从外部文档、数据库、知识库等资源中,精准召回和问题高度相关的上下文信息,再把检索到的真实资料作为上下文喂给大模型,让模型基于真实素材整合生成答案。
相当于给大模型配备了随时可更新的专属 “参考教材”,不再只靠预训练的老旧知识硬答,从根本上减少幻觉、提升答案准确性与专业性。
武技:创建 springai-rag 子项目,并完成初始化工作。
- 添加三方依赖:
<dependencies>
<!--spring-boot-starter-web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--spring-ai-alibaba-starter-dashscope-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<!--spring-ai-advisors-vector-store-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<!--spring-ai-starter-vector-store-redis-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>
<!--spring-ai-tika-document-reader-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
</dependencies>
- 开发主配文件:
server:
port: 13902 # 端口号
servlet:
encoding:
charset: utf-8 # 字符集(解决 stream 中文乱码)
enabled: true # 启用字符编码(解决 stream 中文乱码)
force: true # 强制使用字符编码(解决 stream 中文乱码)
spring:
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY} # 阿里云百炼 API_KEY
read-timeout: 100000 # 读取超时时间(毫秒)
chat:
options:
model: qwen-plus # 基础对话模型
max-tokens: 1000 # Token 限制
temperature: 0.5 # 采样温度
embedding:
options:
model: text-embedding-v1 # 向量模型,阿里云百炼默认模型,不能修改
dimensions: 1536 # 向量维度:阿里云该模型固定 1536,不能修改
- 开发启动类:
package com.joezhou;
/** @author 周航宇 */
@SpringBootApplication
public class RagApp {
public static void main(String[] args) {
SpringApplication.run(RagApp.class, args);
}
}
- 在 classpath:rag/ 目录下,开发几个用于 RAG 测试的知识库文件:
companyInfo.txt:
公司成立于1945年10月1号.
公司法人是赵四.
公司经理是刘能.
公司法务代表是广坤.
公司销售团队包括刘英,苏玉红,李银萍,王云等.
userInfo.txt:
{
"name": "赵四",
"age": 20,
"gender": "男",
"email": "zhangsan@example.com",
"phone": "13800000000",
"address": "中国 北京",
"company": "中国公司",
"hiredate": "2023-01-01",
"position": "销售代表",
"department": "销售部",
"salary": 5000,
"friends": ["刘英", "苏玉红", "李银萍", "王云"]
}
bookInfo.txt:
《@水&浒*传》 施耐庵 (元末明初)
书籍概要:《@水&浒*传》是中国历史上第一部用白话文写成的章回体长篇小说,也是四大名著之一。
E01. RAG流程解析
心法:RAG 的完整流程大概分为 离线索引 和 在线问答 两个阶段,推荐使用 ETL framework 进行具体实现。
ETL:Spring AI 官方推荐的文档预处理标准方案,专门为 RAG 服务,它就像一个数据化妆师,先从各类文档中 抽取 有效信息,再 清洗整理 成 AI 能理解的干净格式,最后 加载 进知识库,让 AI 能快速检索并精准回答。
1. 离线索引阶段
心法:离线索引阶段,指的是知识库构建阶段,仅在首次接入或更新文档时执行。
具体流程:
- 读取(Reading):将 PDF、Word、HTML 等原始文档加载到系统中,并封装为 Document 对象列表。
- 清洗(Cleaning):清洗原始文档中的多余空行、多余空格、乱码、格式噪声、水印等脏内容。
- 切块(Splitting):将大文档切分为语义连贯的小块,避免过长上下文影响模型理解。
- 元数据增强(Enhancing):生成对应文档的摘要、关键词、实体等,存入元数据。
- 向量化(Embedding):使用 Embedding 模型生成对应文档的高维向量(文本的数学表示,用于后续相似度计算)。
- 存储(Storing):将高维向量、原文本片段和元数据一同存入向量数据库,构建可快速检索的知识库索引。
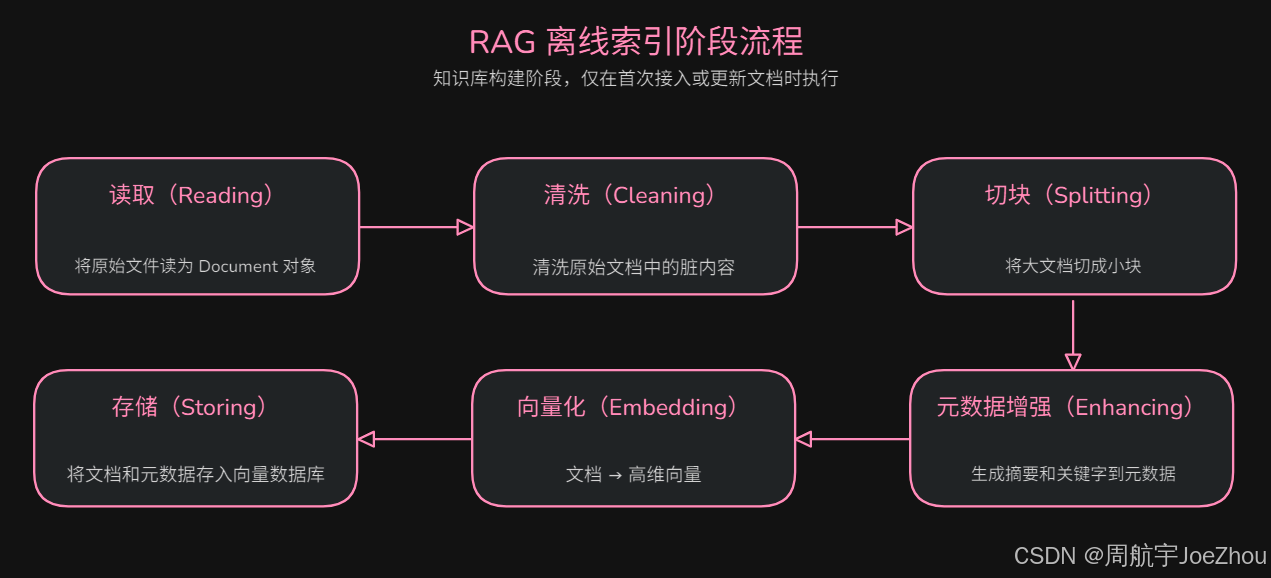
2. 用户提问阶段
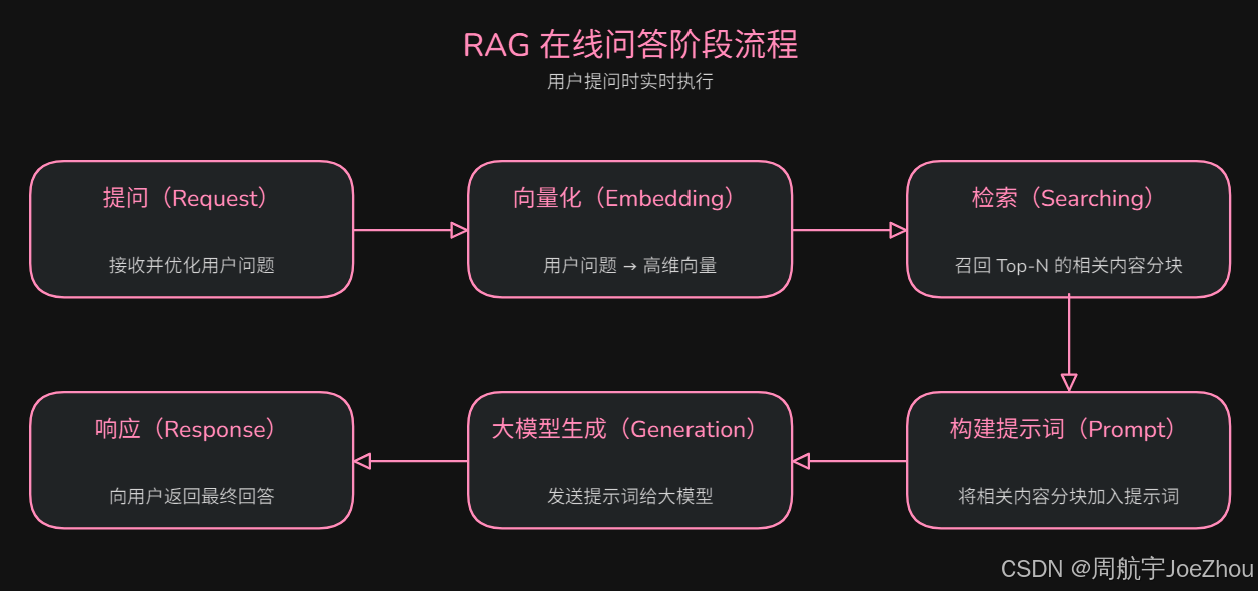
心法:用户提问阶段,在每次用户发送提问请求时实时执行。
具体流程:
- 提问(Request):接收用户问题,进行清洗、改写、关键词扩展等预处理,优化检索效果。
- 向量化(Embedding):使用 Embedding 模型生成对应用户问题的高维向量(文本的数学表示,用于后续相似度计算)。
- 检索(Searching):在向量数据库中,通过相似度算法召回与问题最相关的 Top-N 分块。
- 构建提示词(Prompt):将 “用户问题 + 检索到的上下文片段 + 系统指令” 拼接为完整的提示词。
- 大模型生成(Generation):发送提示词给大模型,让模型基于检索到的上下文信息生成答案,减少幻觉、提升准确性。
- 响应(Response):向用户返回最终回答,并可附带参考来源、原文片段或链接,方便用户溯源验证。
E02. ETL提取Extract
心法:Extract 是 ETL 中的第 1 个步骤,它负责从各类格式的文件中抽取原始内容,并将其标准化为 RAG 架构通用的 Document 对象列表,为后续的文本转换与向量化奠定坚实基础。
Document 组成结构:
| 核心要素 | 简述 | 详述 |
|---|---|---|
| ID | 唯一标识 | 文档在向量库中的主键,未显式指定时,系统通常会自动生成 UUID 以确保数据唯一性 |
| Text | 核心文本 | 经过初步清洗与切分后的纯文本内容,是承载核心语义与生成向量的基础载体 |
| Metadata | 业务元数据 | 键值对形式的附加信息(如来源、页码、分类标签等),主要用于后续的精准过滤与溯源 |
1. 资源绑定Resource
心法:在 ETL 流程启动前,必须通过 org.springframework.core.io.Resource 接口完成文件绑定,统一封装本地、类路径、网络等各类数据源,为文档读取提供标准入口。
资源绑定方式:
| 代码 | 简述 | 返回值 |
|---|---|---|
new FileSystemResource("D:\\xxx.md") | 绑定操作系统本地文件 | Resource |
new ClassPathResource("rag/info.txt") | 绑定项目 classpath 路径下文件 | Resource |
new UrlResource("https://xxx.html") | 绑定网络远程资源(网页 / 文件) | Resource |
武技:测试 3 种常用的资源绑定方案。
- 开发单元测试类:
package base;
import org.junit.Test;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import org.springframework.core.io.UrlResource;
/** @author 周航宇 */
public class ResourceTest {
@SneakyThrows
@Test
public void fileSystemResource() {
String filePath = "D:\\workspace\\java\\v3-9-ssm-ai\\springai-rag\\src\\main\\resources\\rag\\companyInfo.txt";
// 绑定本地文件
Resource resource = new FileSystemResource(filePath);
// 查看文件内容
String content = new String(resource.getInputStream().readAllBytes(), StandardCharsets.UTF_8);
System.out.println("====================");
System.out.println(content);
System.out.println("====================");
}
@SneakyThrows
@Test
public void classPathResource() {
String filePath = "rag/companyInfo.txt";
// 绑定项目 classpath 下的文件
Resource resource = new ClassPathResource(filePath);
// 查看文件内容
String content = new String(resource.getInputStream().readAllBytes(), StandardCharsets.UTF_8);
System.out.println("====================");
System.out.println(content);
System.out.println("====================");
}
@SneakyThrows
@Test
public void urlResource() {
String filePath = "https://blog.csdn.net/CSDN_JOEZHOU/article/details/148041303";
// 绑定网络资源
Resource resource = new UrlResource(filePath);
// 查看文件内容
String content = new String(resource.getInputStream().readAllBytes(), StandardCharsets.UTF_8);
System.out.println("====================");
System.out.println(content);
System.out.println("====================");
}
}
2. 读取器DocumentReader
心法:DocumentReader 是 RAG ETL 流程中的数据入口,用于将各类文件、网页、数据库等异构数据源,统一读取并解析为标准的 Document 文档对象,为后续清洗、切分、增强提供统一数据格式。
DocumentReader 读取器:以下均为 DocumentReader 接口的实现类:
- 可能需要额外引入 org.springframework.ai(1.0.0)包中的对应依赖。
- 可能需要额外引入 com.alibaba.cloud.ai(1.0.0.4)包中的对应依赖。
| 读取器名称 | 支持的文件类型 | 核心备注 | 所需依赖 |
|---|---|---|---|
| TextReader | TXT | 轻量读取纯文本,简单场景专用 | 不需要 |
| JsonReader | JSON | 自动解析 JSON,支持按字段读取 | 不需要 |
| TikaDocumentReader | 几乎所有格式 | 生产首选,通用型全能解析器 | spring-ai-tika-document-reader |
| PagePdfDocumentReader | 按页读取 PDF | spring-ai-pdf-document-reader | |
| ParagraphPdfDocumentReader | 按段落读取 PDF(RAG 首选) | spring-ai-pdf-document-reader | |
| YuQueDocumentReader | 语雀文档 | 企业知识库常用 | spring-ai-alibaba-starter-yuque |
| LarkDocumentReader | 飞书文档 | 飞书数据接入 | spring-ai-alibaba-starter-lark |
| WeChatDocumentReader | 微信公众号文章 | 提取文章正文 | spring-ai-alibaba-starter-wechat |
| DatabaseDocumentReader | MySQL 等数据表 | 直接读取库表数据转文档 | spring-ai-alibaba-starter-database |
武技:测试 3 种常用的读取器。
- 开发控制器:
package com.joezhou.controller;
import org.springframework.ai.document.Document;
import org.springframework.core.io.Resource;
import org.springframework.core.io.ClassPathResource;
import org.springframework.ai.reader.JsonReader;
@RequestMapping("/api/v1/documentReader")
@RestController
@CrossOrigin
public class DocumentReaderController {
@GetMapping("textReader")
public List<Document> textReader() {
// 绑定项目 classpath 下的文件
Resource resource = new ClassPathResource("rag/companyInfo.txt");
// 读取 txt 文件中的所有内容
DocumentReader documentReader = new TextReader(resource);
return documentReader.read();
}
@GetMapping("jsonReader")
public List<Document> jsonReader() {
// 绑定项目 classpath 下的文件
Resource resource = new ClassPathResource("rag/userInfo.json");
// 读取 json 文件中的 name, age, gender 字段,缺省是读取所有字段
DocumentReader documentReader = new JsonReader(resource, "name", "age", "gender");
return documentReader.read();
}
@GetMapping("tikaDocumentReader")
public List<Document> tikaDocumentReader() {
// 绑定项目 classpath 下的文件
Resource resource = new ClassPathResource("rag/companyInfo.txt");
// 读取 txt 文件中的所有内容
DocumentReader documentReader = new TikaDocumentReader(resource);
return documentReader.read();
}
}
- 测试控制器:
### textReader
GET http://localhost:13902/api/v1/documentReader/textReader
### jsonReader
GET http://localhost:13902/api/v1/documentReader/jsonReader
### tikaDocumentReader
GET http://localhost:13902/api/v1/documentReader/tikaDocumentReader
E03. ETL转换Transform
心法:Transform 是 ETL 中的第 2 个步骤,指的是对原始文档进行加工处理,使其更适合 RAG 系统的检索与嵌入,具体可分为清理,分块和增强三个可选步骤。
Transform 具体分类:
| 分类 | 简述 | |
|---|---|---|
| Cleaning | 内容清理 | 清洗原始文档中的多余空行、多余空格、乱码、格式噪声、水印等脏内容 |
| Splitting | 内容分块 | 将大文档切分为语义连贯的小块,避免过长上下文影响模型理解 |
| Enhancing | 元数据增强 | 生成对应文档的摘要、关键词、实体等,存入元数据 |
1. 清洗Cleaning
心法:Cleaning 指的是在文档切块前,对原始文本做降噪、格式化、去冗余处理,让后续切分、向量化、检索更干净、更准确,核心目标就是 “只保留有效语义,剔除所有干扰信息”,但要注意,清洗不是越干净越好,而是只删干扰、不删语义。
常见的清洗需求如下:
- 去除乱码字符:具体哪些符号属于乱码,由具体业务决定。
- 去除多余空格:将文本中间的多个连续空格缩减为一个。
- 去除两端空格:大多数情况下,两端的空格都是没有意义的。
- 统一换行符号:将
\r\n、\r、\n全部统一为\n,避免切分错乱。 - 合并多余空行:连续 2 个及以上换行 → 合并为 1 个换行,保持段落清晰。
- 去除页眉页脚:如 “第 X 页 共 Y 页”、文档标题重复、公司水印、页码、网址、版权声明。
- 去除冗余符号:连续
---,===,***,###等装饰线。 - 去除表格噪声:剔除残缺表格、乱码表格线、无效单元格。
- 统一标点符号:中文标点
,。!?与英文标点, . ! ?混乱的统一规范。 - 剔除无意义短句:如 “点击查看”、“返回顶部”、“加载中” 等网页噪声。
- 格式化排版:保证句子完整、段落清晰,不破坏语义结构。
武技:测试使用正则表达式等手段,手动清洗数据。
- 开发控制器:
package com.joezhou.controller;
import org.springframework.core.io.Resource;
import org.springframework.core.io.ClassPathResource;
/** @author 周航宇 */
@RequestMapping("/api/v1/cleaning")
@RestController
@CrossOrigin
@Slf4j
public class CleaningController {
@GetMapping("clean")
public List<Document> clean() {
// 使用 TikaDocumentReader 读取文档
List<Document> documents = extract("rag/bookInfo.txt");
log.info(">> 文档读取完成,共读取 {} 条文档", documents.size());
log.info(">> 开始清洗文档");
// 清洗数据
documents = documents.stream().map(document -> {
// 获取文档内容和元数据
String text = document.getText();
Map<String, Object> metadata = document.getMetadata();
log.info(">> 清理前的元数据:{}", metadata);
log.info(">> 清理前的内容:\n==========\n{}\n==========\n", text);
// 去除乱码:假设视 @,& 和 * 为乱码(后续自己根据业务补充黑名单)
text = text.replaceAll("[@&*]", "");
log.info(">> 已去除乱码字符:\n==========\n{}\n==========\n", text);
// 去除多余空格 :将文本中间的多个连续空格缩减为一个
text = text.replaceAll(" {2,}", " ");
log.info(">> 已去除多余空格:\n==========\n{}\n==========\n", text);
// 去除两端空格
text = text.trim();
log.info(">> 已去除两端空格:\n==========\n{}\n==========\n", text);
// 填充元数据:添加作者信息
metadata.put("author", "JoeZhou");
metadata.put("datetime", LocalDateTime.now());
log.info(">> 已添加作者信息和时间戳:{}", metadata);
// 重新构建文档对象并返回
return Document.builder().text(text).metadata(metadata).build();
}).toList();
log.info(">> 全部文档清洗完成,共清洗 {} 条文档", documents.size());
return documents;
}
/**
* 从指定文件路径读取文档
*
* @param filePath 文件路径
* @return 文档列表
*/
private List<Document> extract(String filePath) {
// 使用 TikaDocumentReader 读取文档
Resource resource = new ClassPathResource(filePath);
return new TikaDocumentReader(resource).read();
}
}
- 测试控制器:
### clean
GET http://localhost:13902/api/v1/cleaning/clean
2. 切分器TokenTextSplitter
心法:TokenTextSplitter 是 DocumentTransformer 接口的实现类,底层按照 token 数量 进行切块,最适合 RAG 操作,保证不超上下文窗口。
TokenTextSplitter 常用配置:
| 配置 | 描述 | 默认值 |
|---|---|---|
| chunkSize | 分块最多包含多少个 Token | 800 |
| maxNumChunks | 最多切出多少个分块 | 10000 |
| minChunkLengthToEmbed | 小于等于多少个字符的分块会被丢弃 | 5 |
| keepSeparator | 切成的分块中,是否保留换行符 | true |
| minChunkSizeChars | 仅当存在边界标点时生效: 若边界标点的位置 < 350:不截断分块 若边界标点的位置 ≥ 350:截断分块 | 350 |
TokenTextSplitter 切分流程:
首先将原始文本编码为 List<Integer> 类型的 token 列表(记录 token 与原始文本的映射关系),然后循环执行以下步骤,直到 token 列表为空,或分块数量达到 maxNumChunks 值:
| 步骤 | 简述 | 详述 |
|---|---|---|
| 1 | 粗切分段 | 从原始 token 列表中截取前 chunkSize 个 token 作为当前分块,不足则直接取完 |
| 2 | 解码文本 | 将当前分块的 token 列表解码为字符串 chunkText |
| 3 | 跳过空块 | 若当前分块为空块,则直接从原始 token 列表中移除,并开启下一轮循环 |
| 4 | 寻找边界 | 在 chunkText 中寻找最后一个英文边界标点的位置 pos(句号、问号、叹号,换行符都算): 若找到了,且 pos > minChunkSizeChars,则进入第 5 步(进行截断) 若未找到,或 pos ≤ minChunkSizeChars,则进入第 6 步(跳过截断) |
| 5 | 截断处理 | 将 chunkText 截断至边界标点的下一个位置(保留边界标点) |
| 6 | 格式处理 | 根据 keepSeparator 配置决定如何处理分块中的换行符: 若为 true:保留换行符,仅执行 trim 操作 若为 false:将换行符替换为空格,再执行 trim 操作 |
| 7 | 长度过滤 | 若 chunkText 的长度 > minChunkLengthToEmbed 则将该分块加入结果列表 若 chunkText 的长度 ≤ minChunkLengthToEmbed 则直接丢弃该分块 |
| 8 | 移出分块 | 对 chunkText 重新编码得到其 token 列表,再从原始 token 列表中移出它们 |
循环结束后,若仍有未处理的 token,则将它们视为最后一个分块,并依次执行表格中的 2, 6 和 7 步骤。
武技:测试 TokenTextSplitter 切分器。
- 开发控制器:
package com.joezhou.controller;
import org.springframework.ai.document.Document;
import org.springframework.core.io.ClassPathResource;
/** @author 周航宇 */
@RequestMapping("/api/v1/tokenTextSplitter")
@RestController
@CrossOrigin
@Slf4j
public class TokenTextSplitterController {
@GetMapping("split")
public List<Document> split() {
// 使用 TikaDocumentReader 读取文档
List<Document> documents = extract("rag/companyInfo.txt");
log.info(">> 文档读取完成,共读取 {} 条文档", documents.size());
// 创建 TokenTextSplitter 切分器
DocumentTransformer tokenTextSplitter = TokenTextSplitter.builder()
.withChunkSize(50) // 每块最多 50 个 Token
.withMaxNumChunks(10000) // 最多分 10000 块
.withMinChunkSizeChars(10) // 若边界标点的位置小于 10 则不截断,保留原块
.withMinChunkLengthToEmbed(5) // 丢弃字符数不超过 5 个字符的分块
.withKeepSeparator(true) // 保留分块中的换行符
.build();
// 根据 Token 数量切块
return tokenTextSplitter.apply(documents);
}
/**
* 从指定文件路径读取文档
*
* @param filePath 文件路径
* @return 文档列表
*/
private List<Document> extract(String filePath) {
// 使用 TikaDocumentReader 读取文档
Resource resource = new ClassPathResource(filePath);
return new TikaDocumentReader(resource).read();
}
}
- 测试控制器:
### split
GET http://localhost:13902/api/v1/tokenTextSplitter/split
3. 切分器SentenceSplitter
心法:SentenceSplitter 是 DocumentTransformer 接口的实现类,底层按照 句子边界标点 进行切块,语义最完整,但容易超长。
TokenTextSplitter 常用配置:
| 配置 | 描述 | 默认值 |
|---|---|---|
| chunkSize | 分块最多包含多少个 Token | 1024 |
SentenceSplitter 切分流程:
首先使用 OpenNLP 的 SentenceDetectorME 模型将原始文本按英文句号、问号、叹号(不包括换行符)分割为句子数组 texts,然后循环遍历该数组,并依次执行以下步骤,直到所有句子处理完毕:
| 步骤 | 简述 | 详述 |
|---|---|---|
| 1 | 计算增量 | 计算当前分块已占用的 Token 数和当前句子的 Token 数的总和 totalCount |
| 2 | 溢出判断 | 若 totalCount > chunkSize,则进入第 3 步(换块处理) 若 totalCount ≤ chunkSize,则进入第 4 步(追加处理) |
| 3 | 换块处理 | 1. 将当前分块(不含当前句子)加入结果列表(若第一句就执行换块,则会加入一个空块) 2. 新建一个空的分块作为新的当前分块 3. 将当前句子追加到当前分块的末尾 |
| 4 | 追加处理 | 将该句子直接追加到当前分块的末尾 |
| 5 | 收尾归档 | 若当前句子为数组中的最后一个句子,直接将当前分块加入结果列表 |
武技:测试 SentenceSplitter 切分器。
- 开发控制器:
package com.joezhou.controller;
import org.springframework.ai.document.Document;
import org.springframework.core.io.ClassPathResource;
/** @author 周航宇 */
@RequestMapping("/api/v1/sentenceSplitter")
@RestController
@CrossOrigin
@Slf4j
public class SentenceSplitterController {
@GetMapping("split")
public List<Document> split() {
// 使用 TikaDocumentReader 读取文档
List<Document> documents = extract("rag/companyInfo.txt");
log.info(">> 文档读取完成,共读取 {} 条文档", documents.size());
// 每块最多 15 个 Token
int chunkSize = 15;
// 创建 SentenceSplitter 切分器
DocumentTransformer sentenceSplitter = new SentenceSplitter(chunkSize);
// 根据句子切块
return sentenceSplitter.apply(documents);
}
/**
* 从指定文件路径读取文档
*
* @param filePath 文件路径
* @return 文档列表
*/
private List<Document> extract(String filePath) {
// 使用 TikaDocumentReader 读取文档
Resource resource = new ClassPathResource(filePath);
return new TikaDocumentReader(resource).read();
}
}
- 测试控制器:
### split
GET http://localhost:13902/api/v1/sentenceSplitter/split
4. 切分器RecursiveCharacterTextSplitter
心法:RecursiveCharacterTextSplitter 是 DocumentTransformer 接口的实现类,底层按照 固定字符长度 进行切块,通用性最强,是 LangChain 标准切分器。
RecursiveCharacterTextSplitter 常用配置:
| 配置 | 描述 | 默认值 |
|---|---|---|
| chunkSize | 分块最多包含多少个 Token | 1024 |
| separators | 分隔符数组(按优先级排序) | \n\n,\n, 。, !, ?, ;, ,, " " |
RecursiveCharacterTextSplitter 切分流程:
首先将整个文本作为第一个切块,传递给负责切分的函数中,然后递归执行以下步骤,直到切块足够小(字符数小于等于 chunkSize),或分隔符号使用耗尽时结束递归:
| 步骤 | 简述 | 详述(假设分块的字符长度为 len) |
|---|---|---|
| 1 | 根据切块长度 判断是否结束递归 (递归出口) | 若 len = 0:表示切出了空分块,直接结束递归 若 len ≤ chunkSize:说明分块已经足够小,将分块加入结果列表并结束递归 若 len > chunkSize:说明分块不够小,进入第 2 步骤 |
| 2 | 根据分隔符耗尽情况 判断是否结束递归 (递归出口) | 若 separators 数组中的全部分割符已用尽(均已被使用了一遍) 则固定从头截取该分块的 chunkSize 个字符(不足则截完),加入结果列表并结束递归 否则进入第 3 步 |
| 3 | 获取当前分隔符 | 从 separators 数组中按优先级获取一个分隔符 |
| 4 | 分割文本 | 使用当前分隔符把文本切成若干个字符串分块(调用字符串的 split 方法,所以分隔符会被丢弃) |
| 5 | 递归处理 | 遍历每一个分块,判断分块的字符长度 len(和步骤 1 重复,是为了递归健壮性): 若 len > chunkSize:说明分块不够小,使用 separators 数组中的下一个分隔符,继续递归切分 若 len ≤ chunkSize:说明分块已经足够小,直接加入结果列表 |
所有递归结束后,所有分块均满足小于等于 chunkSize,返回最终结果。
武技:测试 RecursiveCharacterTextSplitter 切分器。
- 开发控制器:
package com.joezhou.controller;
import org.springframework.ai.document.Document;
import org.springframework.core.io.ClassPathResource;
/** @author 周航宇 */
@RequestMapping("/api/v1/recursiveCharacterTextSplitter")
@RestController
@CrossOrigin
@Slf4j
public class RecursiveCharacterTextSplitterController {
@GetMapping("split")
public List<Document> split() {
// 使用 TikaDocumentReader 读取文档
List<Document> documents = extract("rag/companyInfo.txt");
log.info(">> 文档读取完成,共读取 {} 条文档", documents.size());
// 每块最多 15 个字符
int chunkSize = 15;
// 创建 RecursiveCharacterTextSplitter 切分器
DocumentTransformer recursiveCharacterTextSplitter = new RecursiveCharacterTextSplitter(chunkSize);
// 根据字符切块
return recursiveCharacterTextSplitter.apply(documents);
}
/**
* 从指定文件路径读取文档
*
* @param filePath 文件路径
* @return 文档列表
*/
private List<Document> extract(String filePath) {
// 使用 TikaDocumentReader 读取文档
Resource resource = new ClassPathResource(filePath);
return new TikaDocumentReader(resource).read();
}
}
- 测试控制器:
### split
GET http://localhost:13902/api/v1/recursiveCharacterTextSplitter/split
5. 增强器SummaryMetadataEnricher
心法:SummaryMetadataEnricher 是 DocumentTransformer 接口的实现类(实例化时需要传入 chatModel 对象),可以为文档生成摘要 summary 并写入元数据,为后续检索和模型理解提供更丰富的上下文信号。
内置摘要类型:均为 SummaryMetadataEnricher.SummaryType 枚举类的属性
| 枚举属性 | 简述 | 详述 | 元数据字段 |
|---|---|---|---|
| PREVIOUS | 包含上一个切块的内容 | 生成的摘要包含 “上文背景” 或前情提示 | prev_section_summary |
| CURRENT | 包含当前切块的内容 | 最常用的选项,用于生成当前段落或页面的核心摘要 | section_summary |
| NEXT | 包含下一个切块的内容 | 生成的摘要包含 “下文预告” 或后续信息 | next_section_summary |
武技:测试 SummaryMetadataEnricher 增强器。
- 开发控制器:
package com.joezhou.controller;
import org.springframework.ai.document.Document;
import org.springframework.core.io.ClassPathResource;
import org.springframework.ai.chat.model.ChatModel;
/** @author 周航宇 */
@RequestMapping("/api/v1/summaryMetadataEnricher")
@RestController
@CrossOrigin
@Slf4j
public class SummaryMetadataEnricherController {
private final ChatModel chatModel;
public SummaryMetadataEnricherController(ChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("enhance")
public List<Document> enhance() {
// 使用 TikaDocumentReader 读取文档
List<Document> documents = extract("rag/companyInfo.txt");
log.info(">> 文档读取完成,共读取 {} 条文档", documents.size());
// 使用 TokenTextSplitter 切分文档
List<Document> chunks = split(documents);
log.info(">> 文档切分完成,共切分 {} 条文档", chunks.size());
// 准备摘要类型
// PREVIOUS 类型表示包含之前的内容,如果你希望生成的摘要能帮助模型理解“上文背景”,就加入这个
// CURRENT 类型表示当前切块的内容,这是最常用的选项,用于生成当前段落或页面的核心摘要
// NEXT 类型表示下一个切块的内容,如果你希望摘要包含“下文预告”或后续信息,就选这个
List<SummaryMetadataEnricher.SummaryType> summaryTypes = List.of(
SummaryMetadataEnricher.SummaryType.PREVIOUS,
SummaryMetadataEnricher.SummaryType.CURRENT,
SummaryMetadataEnricher.SummaryType.NEXT
);
// 创建 SummaryMetadataEnricher 摘要增强器
DocumentTransformer summaryEnricher = new SummaryMetadataEnricher(chatModel, summaryTypes);
// 开始增强切块:附加摘要
return summaryEnricher.apply(chunks);
}
/**
* 从指定文件路径读取文档
*
* @param filePath 文件路径
* @return 文档列表
*/
private List<Document> extract(String filePath) {
// 使用 TikaDocumentReader 读取文档
Resource resource = new ClassPathResource(filePath);
return new TikaDocumentReader(resource).read();
}
/**
* 对文档列表进行 Token 切分
*
* @param documents 文档列表
* @return 切分后的文档列表
*/
private List<Document> split(List<Document> documents) {
return TokenTextSplitter.builder()
.withChunkSize(50)
.withMinChunkSizeChars(10)
.build().apply(documents);
}
}
- 测试控制器:
### enhance
GET http://localhost:13902/api/v1/summaryMetadataEnricher/enhance
6. 增强器KeywordMetadataEnricher
心法:KeywordMetadataEnricher 是 DocumentTransformer 接口的实现类(实例化时需要传入 chatModel 对象),可以为文档生成关键字 keyword 并写入元数据,为后续检索和模型理解提供更丰富的上下文信号。
KeywordMetadataEnricher 常用参数:
| 参数 | 简述 | 详述 |
|---|---|---|
| keywordCount | 关键字数量 | 希望生成多少个关键字 |
武技:测试 KeywordMetadataEnricher 增强器。
- 开发控制器:
package com.joezhou.controller;
import org.springframework.ai.document.Document;
import org.springframework.core.io.ClassPathResource;
import org.springframework.ai.chat.model.ChatModel;
/** @author 周航宇 */
@RequestMapping("/api/v1/keywordMetadataEnricher")
@RestController
@CrossOrigin
@Slf4j
public class KeywordMetadataEnricherController {
private final ChatModel chatModel;
public KeywordMetadataEnricherController(ChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("enhance")
public List<Document> enhance() {
// 使用 TikaDocumentReader 读取文档
List<Document> documents = extract("rag/companyInfo.txt");
log.info(">> 文档读取完成,共读取 {} 条文档", documents.size());
// 使用 TokenTextSplitter 切分文档
List<Document> chunks = split(documents);
log.info(">> 文档切分完成,共切分 {} 条文档", chunks.size());
// 创建 KeywordMetadataEnricher 关键词增强器,生成 5 个关键词
int keywordCount = 5;
DocumentTransformer keywordEnricher = new KeywordMetadataEnricher(chatModel, keywordCount);
// 开始增强切块:附加关键词
return keywordEnricher.apply(chunks);
}
/**
* 从指定文件路径读取文档
*
* @param filePath 文件路径
* @return 文档列表
*/
private List<Document> extract(String filePath) {
// 使用 TikaDocumentReader 读取文档
Resource resource = new ClassPathResource(filePath);
return new TikaDocumentReader(resource).read();
}
/**
* 对文档列表进行 Token 切分
*
* @param documents 文档列表
* @return 切分后的文档列表
*/
private List<Document> split(List<Document> documents) {
return TokenTextSplitter.builder()
.withChunkSize(50)
.withMinChunkSizeChars(10)
.build().apply(documents);
}
}
- 测试控制器:
### enhance
GET http://localhost:13902/api/v1/keywordMetadataEnricher/enhance
7. 向量化Embedding
心法:大模型无法直接理解文字语义,机器仅能运算数值,因此要把段落、句子、词语转换成一串高维数字数组,该过程被称为向量化:
- 向量:高维数字数组,语义越相近的文本,向量在空间中的距离越接近。
- 向量维度:数字数组的长度,维度越高语义刻画越精细、匹配精度上限越高,但存储、算力开销更大,检索速度变慢。
- 向量数据库:专门持久存储向量、原文片段与元数据,并依靠专属索引快速完成海量向量相似度比对的存储引擎。
向量数据库 VS 普通数据库:
| 对比项 | 普通数据库 | 向量数据库 |
|---|---|---|
| 存储内容 | 普通文本、业务结构化数据 | 原文元数据 + 高维向量数组 |
| 检索方式 | 关键词匹配、模糊查询、精确查询 | 语义相似度匹配 |
| 语义理解能力 | 仅匹配字面字符,无法理解语句含义 | 读懂文本语义,按含义匹配而非字面匹配 |
| RAG 适配性 | 勉强适配,检索精准度差、易漏内容 | 专为 RAG 知识库场景设计,适配度拉满 |
| 大数据检索性能 | 数据量越大检索越慢,无向量索引优化 | 内置向量索引,千万级数据也能毫秒级响应 |
常见第三方向量数据库:
| 向量数据库 | 描述 | 适用场景 |
|---|---|---|
| Chroma | 轻量级开源向量库,开箱即用 | 小型项目 |
| RedisStack | 基于 Redis 扩展,自带向量检索、JSON、搜索等能力 | 中型项目 |
| Qdrant | 高性能开源向量库,检索速度快、支持丰富过滤条件 | 大型项目 |
| Milvus | 开源高性能专业向量库,支持亿级海量数据 | 企业级项目 |
| Pinecone | 云端托管向量数据库,无需自建运维 | 云端项目 |
| Elasticsearch | 兼具全文检索与向量检索 | 关键词搜索 + RAG 混合场景 |
武技:搭建 redis-stack 向量数据库。
- 安装 redis-stack 容器:
# 准备相关目录
mkdir -p /opt/redis-stack/data;
chmod -R 777 /opt/redis-stack;
# 拉取镜像(二选一)
docker pull redis/redis-stack:7.4.2;
docker pull registry.cn-hangzhou.aliyuncs.com/joezhou/redis-stack:7.4.2;
# 创建并启动容器
docker run --name redis-stack \
--network my-net \
-p 5379:6379 \
-p 8001:8001 \
-v /opt/redis-stack/data:/data \
-e REDIS_ARGS="--requirepass joezhou" \
-itd registry.cn-hangzhou.aliyuncs.com/joezhou/redis-stack:7.4.2;
- 访问向量数据库界面:输入密码 joezhou 即可。
E04. ETL加载Loading-入库
心法:Loading 是 ETL 中的第 3 个步骤,指的是先将切分向量化,再通过 VectorStore 接口,将向量、原文片段与元数据统一持久化至向量数据库,构建结构化知识库,为后续检索问答提供数据支撑。
QuestionAnswerAdvisor 是 Spring AI 官方内置的 RAG 自动执行拦截器,相当于 RAG 的自动引擎,它让开发者无需手动编写 “检索 → 组装 → 注入” 逻辑,只需注入拦截器,即可一键实现完整 RAG 功能,大幅简化开发流程,当用户调用 chatClient.call() 发起对话时,QuestionAnswerAdvisor 会自动拦截请求并执行以下标准 RAG 逻辑:
| 步骤 | 描述 |
|---|---|
| 1 | 自动拦截用户输入的问题文本 |
| 2 | 将用户问题通过嵌入模型转为向量表示(Embedding) |
| 3 | 基于向量相似度,在 VectorStore 中检索最相关的知识库文档片段 |
| 4 | 将检索到的内容作为参考上下文,自动注入 AI 模型的 Prompt 中 |
| 5 | 将携带上下文的增强提示发送给大模型,使模型基于知识库内容生成准确、可溯源的回答 |
VectorStore 常用方法:
| 方法分类 | 详细方法签名 | 核心简述 |
|---|---|---|
| 批量存入文档 | add(List<Document> documents) | 底层自动调用模型转为向量并建立索引 |
| 批量存入文档 | ddDocuments(List<Document> documents) | 该方法是 add 方法的语义化别名,功能完全一致 |
| 基础检索 | similaritySearch(String query) | 传入问题文本,返回最相关的文档列表 |
| 高级检索 | similaritySearch(SearchRequest request) | 支持自定义 topK、相似度阈值及元数据过滤 |
| 带评分检索 | similaritySearchWithScore(String query) | 检索的同时返回文档内容及其与问题的相似度分值 |
| 多样性检索 | maxMarginalRelevanceSearch(String query) | 在相关的基础上过滤重复内容,提升信息丰富度 |
| 按主键删除文档 | delete(List<String> idList) | 根据文档的唯一标识符(ID)物理删除指定的向量数据 |
| 按条件删除文档 | delete(DeleteRequest deleteRequest) | 支持通过元数据过滤表达式(如 id == '77')批量删除 |
| 适配器转换 | asRetriever() | 将存储接口包装为标准的 Retriever 检索器,供 Advisor 调用 |
武技:搭建 ETL-Loading 起始测试环境。
- 开发主配文件(加入向量库相关配置):
spring:
ai:
dashscope:
...
embedding:
options:
model: text-embedding-v1 # 向量模型,阿里云百炼默认模型,不能修改
dimensions: 1536 # 向量维度:阿里云该模型固定 1536,不能修改
1. 内存向量库SimpleVectorStore
心法:SimpleVectorStore 本质是内存型的 VectorStore 实现,新增文档、向量、元数据全部放在 JVM 内存,程序重启、服务关闭后,内存数据直接清空,检索时直接在内存做相似度计算,速度极快,无网络 IO 消耗,适合练习。
武技:测试使用 SimpleVectorStore 进行向量存储。
- 开发配置类:
package com.joezhou.config;
import org.springframework.ai.embedding.EmbeddingModel;
/** @author 周航宇 */
@Configuration
public class SimpleVectorStoreConfig {
@Bean("simpleVectorStore")
public VectorStore simpleVectorStore(EmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}
}
- 开发控制器:
package com.joezhou.controller;
import org.springframework.ai.document.Document;
import org.springframework.core.io.ClassPathResource;
/** @author 周航宇 */
@Slf4j
@RestController
@CrossOrigin
@RequestMapping("/api/v1/simpleVectorStore")
public class SimpleVectorStoreController {
private final VectorStore simpleVectorStore;
private final ChatClient chatClient;
public SimpleVectorStoreController(ChatClient.Builder chatClientBuilder, @Qualifier("simpleVectorStore") VectorStore simpleVectorStore) {
this.chatClient = chatClientBuilder
.defaultSystem("""
你只能根据给定的知识库内容回答问题。
如果知识库中没有相关信息,请直接回答“我不清楚”,不要编造内容。
回答要简洁明了,不要添加无关信息。
""")
.build();
this.simpleVectorStore = simpleVectorStore;
}
@PostMapping("/load")
public List<String> load() {
// 使用 TikaDocumentReader 读取文档
List<Document> documents = extract("rag/companyInfo.txt");
log.info(">> 文档读取完成,共读取 {} 条文档", documents.size());
// 使用 TokenTextSplitter 切分文档
List<Document> chunks = split(documents);
log.info(">> 文档切分完成,共切分 {} 条文档", chunks.size());
// 存入向量数据库,这个过程会自动调用 embeddingModel 将文本变成向量再存入向量库
simpleVectorStore.add(chunks);
// 从 chunks 里直获取 ID 列表
List<String> ids = chunks.stream().map(Document::getId).toList();
log.info(">> 知识库添加成功,生成ID:" + ids);
// 直接返回所有 ID 列表
return ids;
}
@PostMapping("/add")
public List<String> add(@RequestParam("text") String text) {
// 将传入的文本包装成 Document
Document document = Document.builder().text(text).build();
log.info(">> 文本包装成 Document 完成,文本内容: {}", document.getText());
// 使用 TokenTextSplitter 切分文档
List<Document> chunks = split(List.of(document));
log.info(">> 文档切分完成,共切分 {} 条文档", chunks.size());
// 存入向量数据库
simpleVectorStore.add(chunks);
// 从 chunks 里直获取 ID 列表
List<String> ids = chunks.stream().map(Document::getId).toList();
System.out.println(">> 知识库添加成功,生成ID:" + ids);
// 直接返回所有 ID 列表
return ids;
}
@GetMapping("/search")
public List<Document> search(@RequestParam("text") String text) {
// 构建 SearchRequest 对象
SearchRequest searchRequest = SearchRequest.builder()
.query(text) // 搜索文本
.topK(2) // 只返回最相似的 2 条结果
.similarityThreshold(0.1) // 只返回 0.1 以上相似度的文档,0表示完全不相似,1表示完全相似度
.build();
// 相似度搜索(最多找2条)
return simpleVectorStore.similaritySearch(searchRequest);
}
@DeleteMapping("/delete/{id}")
public String delete(@PathVariable("id") String id) {
simpleVectorStore.delete(List.of(id));
return "根据 ID 删除成功:" + id;
}
@GetMapping("/chat")
public String chat(@RequestParam("msg") String msg) {
// 首先使用 QuestionAnswerAdvisor 将用户消息转为向量
// 然后再检索最相关的文档
// 最后将检索到的内容作为上下文(Context)一起发给大模型
return chatClient.prompt()
.user(msg)
.advisors(QuestionAnswerAdvisor.builder(simpleVectorStore).build())
.call()
.content();
}
/**
* 从指定文件路径读取文档
*
* @param filePath 文件路径
* @return 文档列表
*/
private List<Document> extract(String filePath) {
// 使用 TikaDocumentReader 读取文档
Resource resource = new ClassPathResource(filePath);
return new TikaDocumentReader(resource).read();
}
/**
* 对文档列表进行 Token 切分
*
* @param documents 文档列表
* @return 切分后的文档列表
*/
private List<Document> split(List<Document> documents) {
return TokenTextSplitter.builder()
.withChunkSize(50)
.withMinChunkSizeChars(10)
.build().apply(documents);
}
}
- 访问控制器:
### load:"f32c0dbd-9d9b-4281-91ac-751f229eee3f","04b8d545-bb80-4a70-9e08-553a86af80f9"
POST http://localhost:13902/api/v1/simpleVectorStore/load
### add:"a0486370-9250-4ce1-8f7b-0ac75cf8ec52"
POST http://localhost:13902/api/v1/simpleVectorStore/add?
text=小熊是粉色的
### search
GET http://localhost:13902/api/v1/simpleVectorStore/search?
text=小熊是什么颜色的?
### delete
DELETE http://localhost:13902/api/v1/simpleVectorStore/delete/a0486370-9250-4ce1-8f7b-0ac75cf8ec52
### chat
GET http://localhost:13902/api/v1/simpleVectorStore/chat?
msg=小熊是什么颜色的?
### chat
GET http://localhost:13902/api/v1/simpleVectorStore/chat?
msg=小狗是什么颜色的?
### chat
GET http://localhost:13902/api/v1/simpleVectorStore/chat?
msg=公司什么时间成立的?
2. 持久向量库RedisVectorStore
心法:RedisVectorStore 是基于 Redis Stack 向量模块实现的商用级 VectorStore 的实现,文档、向量、元数据统一持久存入 Redis 实例,服务重启数据不会丢失;依托 Redis 内存高速读写与向量索引能力,检索性能稳定,支持并发读写、分片扩容,适合中小型线上业务落地。
武技:测试使用 RedisVectorStore 进行向量存储。
- 开发配置类:
package com.joezhou.config;
import org.springframework.ai.embedding.EmbeddingModel;
/** @author 周航宇 */
@Configuration
public class RedisVectorStoreConfig {
private final String REDIS_HOST = "192.168.40.77";
private final int REDIS_PORT = 5379;
private final String REDIS_PASSWORD = "joezhou";
private final String REDIS_PREFIX = "doc:";
@Bean
public VectorStore redisVectorStore(EmbeddingModel embeddingModel) {
// 创建独立 Redis Stack 连接
JedisPooled jedisPooled = new JedisPooled(REDIS_HOST, REDIS_PORT, null, REDIS_PASSWORD);
return RedisVectorStore.builder(jedisPooled, embeddingModel)
.prefix(REDIS_PREFIX)
.initializeSchema(true) // 自动创建索引
.build();
}
}
- 开发控制器:
package com.joezhou.controller;
import org.springframework.ai.document.Document;
import org.springframework.core.io.ClassPathResource;
/** @author 周航宇 */
@Slf4j
@RestController
@CrossOrigin
@RequestMapping("/api/v1/redisVectorStore")
public class RedisVectorStoreController {
private final VectorStore vectorStore;
private final ChatClient chatClient;
public RedisVectorStoreController(ChatClient.Builder chatClientBuilder, @Qualifier("redisVectorStore") VectorStore vectorStore) {
this.chatClient = chatClientBuilder
.defaultSystem("""
你只能根据给定的知识库内容回答问题。
如果知识库中没有相关信息,请直接回答“我不清楚”,不要编造内容。
回答要简洁明了,不要添加无关信息。
""")
.build();
this.vectorStore = vectorStore;
}
@PostMapping("/load")
public List<String> load() {
// 使用 TikaDocumentReader 读取文档
List<Document> documents = extract("rag/companyInfo.txt");
log.info(">> 文档读取完成,共读取 {} 条文档", documents.size());
// 使用 TokenTextSplitter 切分文档
List<Document> chunks = split(documents);
log.info(">> 文档切分完成,共切分 {} 条文档", chunks.size());
// 存入向量数据库,这个过程会自动调用 embeddingModel 将文本变成向量再存入 RedisStack
vectorStore.add(chunks);
// 从 chunks 里直获取 ID 列表
List<String> ids = chunks.stream().map(Document::getId).toList();
System.out.println(">> 知识库添加成功,生成ID:" + ids);
// TODO:将 chunks 的 ID 列表关联到 MySQL 表的字段
// 直接返回所有 ID 列表
return ids;
}
@PostMapping("/add")
public List<String> add(@RequestParam("text") String text) {
// 将传入的文本包装成 Document
Document document = Document.builder().text(text).build();
log.info(">> 文本包装成 Document 完成,文本内容: {}", document.getText());
// 使用 TokenTextSplitter 切分文档
List<Document> chunks = split(List.of(document));
log.info(">> 文档切分完成,共切分 {} 条文档", chunks.size());
// 存入向量数据库
vectorStore.add(chunks);
// 从 chunks 里直获取 ID 列表
List<String> ids = chunks.stream().map(Document::getId).toList();
System.out.println(">> 知识库添加成功,生成ID:" + ids);
// TODO:将 chunks 的 ID 列表关联到 MySQL 表的字段
// 直接返回所有 ID 列表
return ids;
}
@GetMapping("/search")
public List<Document> search(@RequestParam("text") String text) {
// 构建 SearchRequest 对象
SearchRequest searchRequest = SearchRequest.builder()
.query(text) // 搜索文本
.topK(2) // 只返回最相似的 2 条结果
.similarityThreshold(0.1) // 只返回 0.1 以上相似度的文档,0表示完全不相似,1表示完全相似度
.build();
// 相似度搜索(最多找2条)
return vectorStore.similaritySearch(searchRequest);
}
@DeleteMapping("/delete/{id}")
public String delete(@PathVariable("id") String id) {
vectorStore.delete(List.of(id));
return "根据 ID 删除成功:" + id;
}
@GetMapping("/chat")
public String chat(@RequestParam("question") String question) {
// 首先使用 QuestionAnswerAdvisor 将用户消息转为向量
// 然后再检索最相关的文档
// 最后将检索到的内容作为上下文(Context)一起发给大模型
return chatClient.prompt()
.user(question)
.advisors(QuestionAnswerAdvisor.builder(vectorStore).build())
.call()
.content();
}
/**
* 从指定文件路径读取文档
*
* @param filePath 文件路径
* @return 文档列表
*/
private List<Document> extract(String filePath) {
// 使用 TikaDocumentReader 读取文档
Resource resource = new ClassPathResource(filePath);
return new TikaDocumentReader(resource).read();
}
/**
* 对文档列表进行 Token 切分
*
* @param documents 文档列表
* @return 切分后的文档列表
*/
private List<Document> split(List<Document> documents) {
return TokenTextSplitter.builder()
.withChunkSize(50)
.withMinChunkSizeChars(10)
.build().apply(documents);
}
}
- 访问控制器:
### load:"131fd47e-1b51-4e78-8a39-7822e05d845e", "f8f23ec3-7a4b-453d-b323-9df8d8e9d0d1"
POST http://localhost:13902/api/v1/redisVectorStore/load
### add:"f439a73d-5809-47dc-92e3-5fdf2cf5790d"
POST http://localhost:13902/api/v1/redisVectorStore/add?
text=小熊是粉色的
### search
GET http://localhost:13902/api/v1/redisVectorStore/search?
text=小熊是什么颜色的?
### delete
DELETE http://localhost:13902/api/v1/redisVectorStore/delete/f439a73d-5809-47dc-92e3-5fdf2cf5790d
### chat
GET http://localhost:13902/api/v1/redisVectorStore/chat?
question=小熊是什么颜色的?
### chat
GET http://localhost:13902/api/v1/redisVectorStore/chat?
question=小狗是什么颜色的?
### chat
GET http://localhost:13902/api/v1/redisVectorStore/chat?
question=公司什么时间成立的?
S04. 工具调用
E01. 本地工具调用
心法:Tools/Function Calling 是介于基础对话与智能体之间的 AI 功能形态,它打破了 LLM 的静态知识局限,允许 AI 在遇到知识盲区时主动调用外部工具获取实时数据,从而从单纯的聊天机器人(文本生成)进化为能解决实际问题的智能代理(现实执行)。
场景理解:大模型在出厂时,学习了海量的公开互联网知识(比如什么是衬衫,巴黎在哪里等),但无法获取用户私有业务数据、本地实时数据,比如你向大模型提问:“我的 1 号房间中都有哪些衣服?”:
- 未附加 ToolCalling 能力时:面对这种私有领域的问题,模型如果强行回答,就只能靠猜(产生幻觉),比如瞎编一件 “红色的毛衣”,这在实际应用中是灾难性的。
- 已附加 ToolCalling 能力时:模型可识别自身知识边界,检测到项目内已注册
listClothes()工具后(工具需要程序员开发并注册),自动提取入参 “1” 并发起调用,框架执行工具完成数据查询,模型再基于返回的真实结果,整理生成最终答复。
本地工具调用方案:
| 方案 | 描述 | 场景推荐 |
|---|---|---|
| Function Call | Spring AI 早期版本的工具调用实现 现已被官方统一抽象为 Tool Calling,不再作为独立推荐方案 | 已被标记过时 不推荐新项目使用 |
| Tool Calling | 统一了多模型、多类型工具的调用规范 提供更清晰的 @Tool,@ToolParam 等注解 提供了 ToolCallbackResolver,ToolExecutionAgent 等标准组件 支持外部接口、多工具并行调用,多工具链式调用,异常处理等企业级特性 | 目前唯一推荐方案 |
武技:创建 springai-tool-calling 子项目,并完成初始化工作。
- 添加三方依赖:
<dependencies>
<!--spring-boot-starter-web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--spring-ai-alibaba-starter-dashscope-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
</dependencies>
- 开发主配文件:
server:
port: 13903 # 端口号
spring:
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY} # 阿里云百炼 API_KEY
read-timeout: 100000 # 读取超时时间(毫秒)
chat:
options:
model: qwen-plus # 基础对话模型
max-tokens: 1000 # Token 限制
temperature: 0.5 # 采样温度
- 开发启动类:
package com.joezhou;
/** @author 周航宇 */
@SpringBootApplication
public class ToolCallingApp {
public static void main(String[] args) {
SpringApplication.run(ToolCallingApp.class, args);
}
}
1. ToolCalling
心法:SpringAI 框架会自动扫描标记了
@Tool注解的的方法,并生成对应的,包含工具名、描述、入参 Schema 规则等信息的 Tool Definition 对象。
ToolCalling 标准流程:
- 工具注册:定义 Tool Definition 工具方法:
@Tool:用于将方法标记为可被大模型调用的工具。@ToolParam:描述方法参数的含义,帮助大模型理解参数用途。
- 请求发起:ChatRequest 携带 Tool Definition(含工具名、描述、入参 Schema)发送给大模型。
- 模型决策:大模型分析问题,按需生成 “工具调用请求” 并返回给 SpringAI 框架。
- 工具调用:SpringAI 框架通过 DispatchToolCallRequest 调度模块分发请求,执行对应工具。
- 结果回传:工具执行完成,将结果返回给 SpringAI 框架。
- 二次请求:SpringAI 框架将工具结果封装为模型能识别的对话消息,再次发送给大模型。
- 响应返回:大模型基于工具结果生成最终回答,框架封装为 ChatResponse 返回用户。
ToolCalling 标准流程 - 图示:
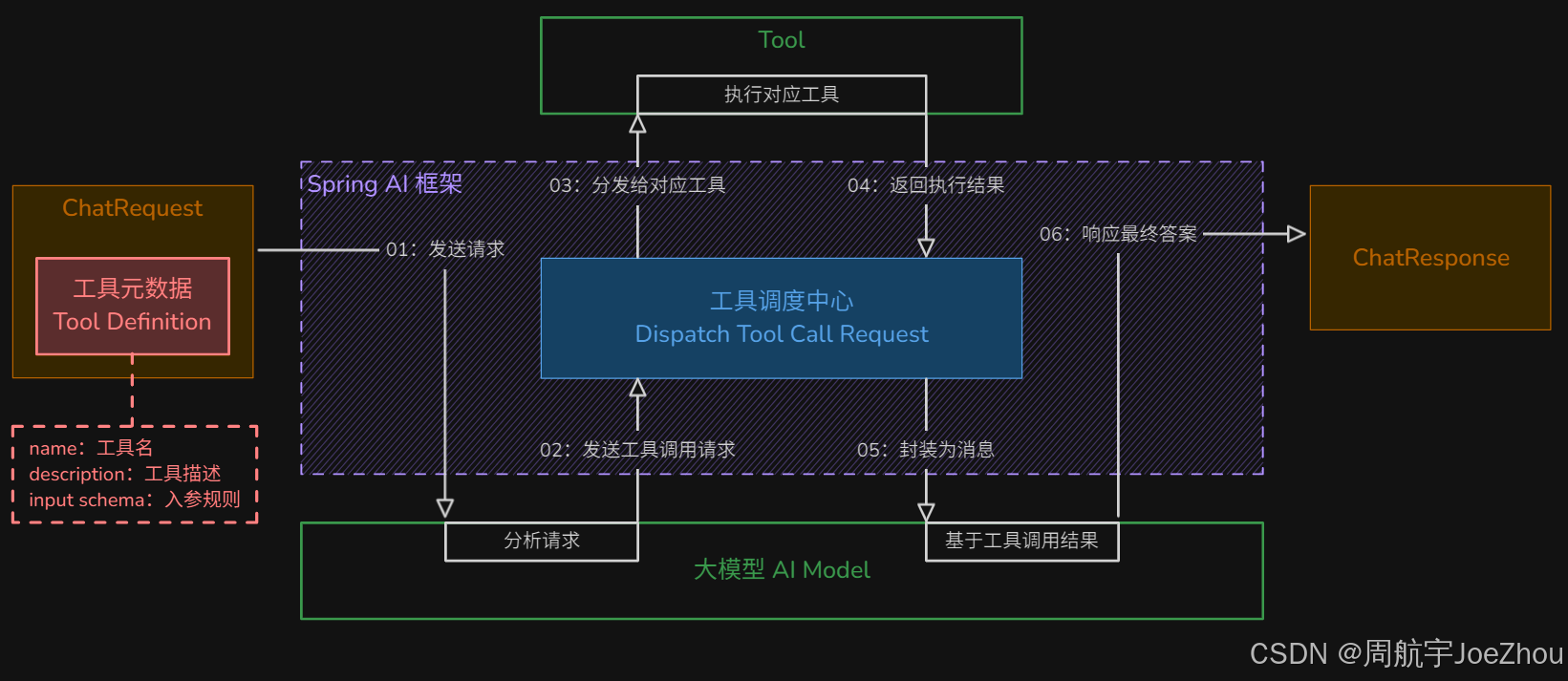
武技:开发并测试一个用于获取今天的天气的工具。
- 开发工具类:
package com.joezhou.tools;
/** @author 周航宇 */
@Slf4j
public class WeatherTool {
@Tool(description = "根据城市名称返回该城市今天的天气")
String getWeather(@ToolParam(description = "城市名称") String cityName) {
String result;
log.info(">> 调用工具:getWeather(" + cityName + ")");
if ("上海".equals(cityName)) {
result = "今天上海的天气是:晴转多云,再转大雨,再转冰雹,1103摄氏度";
} else if ("北京".equals(cityName)) {
result = "今天北京的天气是:多云转晴,再转小雨,再转闪电,1104摄氏度。";
} else {
result = "不知道";
}
log.info(">> 生成结果:" + result);
return result;
}
}
- 开发控制器:
package com.joezhou.controller;
/** @author 周航宇 */
@RequestMapping("/api/v1/toolCalling")
@RestController
@CrossOrigin
public class ToolCallingController {
private final ChatClient chatClient;
public ToolCallingController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
.defaultTools(new WeatherTool())
.build();
}
@GetMapping("call")
public String call(@RequestParam("msg") String msg) {
return chatClient.prompt()
.user(msg)
.call()
.content();
}
}
- 测试控制器:
### call
GET http://localhost:13903/api/v1/toolCalling/call?
msg=上海天气如何
### call
GET http://localhost:13903/api/v1/toolCalling/call?
msg=北京天气如何
### call
GET http://localhost:13903/api/v1/toolCalling/call?
msg=哈尔滨天气如何
E02. 模型上下文协议
心法:MCP 的全称是 Model Context Protocol,模型上下文协议,来自 Anthropic 公司,基于 ToolCalling 技术,旨在标准化 “AI 应用” 和 “外部工具/外部数据源” 之间的交互,彻底解决 “M × N 组合爆炸” 的问题。
M × N 场景示例:假设你是一家跨国公司的 IT 负责人,你需要让公司里的 2 名员工(大模型)A 和 B,分别去和 2 位外部供应商(工具)X 和 Y 洽谈业务,且:
- 员工 A:只会说中文(比如 DeepSeek)
- 员工 B:只会说英文(比如 QWen)
- 供应商 X:只懂法语(比如墨迹天气)
- 供应商 Y:只懂日语(比如高德地图)
不用 MCP 之前:你需要做如下 4 件事(写代码):
- 为了让人 A 和 X 沟通,你得雇一个 “中翻法” 的翻译。
- 为了让人 A 和 Y 沟通,你得雇一个 “中翻日” 的翻译。
- 为了让人 B 和 X 沟通,你得雇一个 “英翻法” 的翻译。
- 为了让人 B 和 Y 沟通,你得雇一个 “英翻日” 的翻译。
你只有 2 个人和 2 个工具,却要维护 2 × 2 = 4 个翻译官(适配代码),若明天来了新员工或新的供应商,则需要瞬间增加 3 个新的翻译官。
使用 MCP 之后:你只需要做如下 2 件事:
- 给所有员工发一个普通话耳机(MCP Client),员工 A 说话时自动翻译为普通话。
- 强制要求所有供应商必须配一个普通话翻译官(MCP Server),翻译官可以将普通话翻译成它们的母语并讲给供应商听。
此后,不管你有 100 个员工还是 100 个供应商,你都不需要再写那些乱七八糟的 “一对一” 翻译代码了。
总结:MCP 就是 AI 世界的通用普通话,让所有大模型和所有外部工具,不用两两学方言,全员说统一语言,自由互通。
1. MCP核心组件
心法:MCP 由三大核心组件构成:主机(Host)、客户端(Client)、服务端(Server),三者各司其职,通过标准协议实现 AI 应用与外部工具的高效互通。
MCP 核心组件:
- 主机 Host:它是基于 MCP 协议来调用工具的应用程序,比如你的 SpringAI 项目,Claude Code 这类的大模型客户端等。
- 客户端 Client:它是主机的 “翻译官”,负责对接主机和服务端,以及按 MCP 协议规范来完成请求封装与响应解析。
- 服务端 Server:它是基于 MCP 协议来对外提供工具的应用程序,比如墨迹天气厂商,本地文件服务,数据库查询服务等。
MCP 工作流程 - 图示:
2. 开发本地MCP服务端
武技:创建 springai-mcp-server 子项目,并改造为 MCP 服务端项目。
- 添加三方依赖:
<dependencies>
<!--spring-ai-starter-mcp-server-webflux-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webflux</artifactId>
</dependency>
</dependencies>
- 开发主配文件:
server:
port: 13904 # 端口号
- 开发启动类:
package com.joezhou;
/** @author 周航宇 */
@SpringBootApplication
public class MCPServerApp {
public static void main(String[] args) {
SpringApplication.run(MCPServerApp.class, args);
}
}
- 开发工具类:
package com.joezhou.tool;
/** @author 周航宇 */
@Slf4j
@Component
public class ClothesTool {
// 模拟数据库中的衣服数据,分别存于 3 个房间
private final static List<Map<String, Object>> CLOTHES = List.of(
Map.of("roomId", 1L, "name", "T恤", "color", "白色"),
Map.of("roomId", 1L, "name", "衬衫", "color", "黑色"),
Map.of("roomId", 1L, "name", "短裤", "color", "白色"),
Map.of("roomId", 1L, "name", "长裤", "color", "白色"),
Map.of("roomId", 1L, "name", "牛仔裤", "color", "白色"),
Map.of("roomId", 2L, "name", "帽衫", "color", "蓝色"),
Map.of("roomId", 2L, "name", "帽衫", "color", "红色"),
Map.of("roomId", 2L, "name", "帽衫", "color", "黄色"),
Map.of("roomId", 2L, "name", "卫衣", "color", "蓝色"),
Map.of("roomId", 2L, "name", "羽绒服", "color", "蓝色"),
Map.of("roomId", 3L, "name", "呢子大衣", "color", "蓝色"),
Map.of("roomId", 3L, "name", "T恤", "color", "绿色"),
Map.of("roomId", 3L, "name", "衬衫", "color", "粉色"),
Map.of("roomId", 3L, "name", "连体裤", "color", "白色"),
Map.of("roomId", 3L, "name", "开衫", "color", "黄色")
);
@Tool(description = "根据房间ID获取该房间内的全部衣服")
public List<Map<String, Object>> listClothesByRoomId(@ToolParam(description = "房间ID") Long roomId) {
log.info("执行工具调用:listClothesByRoomId({})", roomId);
// 查询该房间内的全部衣服数据
List<Map<String, Object>> result = CLOTHES.stream()
.filter(clothes -> clothes.get("roomId").equals(roomId))
.toList();
log.info("工具调用结果:{}", result);
return result;
}
}
- 注册工具类:
package com.joezhou.config;
/** @author 周航宇 */
@Configuration
public class ClothesToolConfig {
@Bean
public ToolCallbackProvider toolCallbackProvider(ClothesTool clothesTool) {
// 注册衣服工具
return MethodToolCallbackProvider.builder()
.toolObjects(clothesTool)
.build();
}
}
- 启动 MCP 服务端项目,查看控制台,工具是否注册成功:
- 通过 curl 访问服务端项目:
curl http://localhost:13904/sse
结果如下:
3. 开发本地MCP客户端
武技:创建 springai-mcp-client 子项目,并改造为 MCP 客户端项目。
- 添加三方依赖:
<dependencies>
<!--spring-boot-starter-web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--spring-ai-alibaba-starter-dashscope-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<!--spring-ai-starter-mcp-client-webflux-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client-webflux</artifactId>
</dependency>
</dependencies>
- 开发主配文件:
server:
port: 13905 # 端口号
servlet:
encoding:
charset: utf-8 # 字符集(解决 stream 中文乱码)
enabled: true # 启用字符编码(解决 stream 中文乱码)
force: true # 强制使用字符编码(解决 stream 中文乱码)
tomcat:
threads:
max: 200 # 默认可能只有 10 或 50,加大到 200
spring:
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY} # 阿里云百炼 API_KEY
read-timeout: 100000 # 读取超时时间(毫秒)
chat:
options:
model: qwen-plus # 基础对话模型
max-tokens: 1000 # Token 限制
temperature: 0.5 # 采样温度
mcp:
client:
enabled: true # 启用 MCP 客户端
request-timeout: 200000 # 请求超时时间(毫秒)
toolcallback:
enabled: true # 启用工具回调
name: springai-mcp-client # 客户端名称
sse:
connections:
my-server01:
url: http://localhost:13904 # MCP 服务器地址
logging:
level:
org.springframework.ai: DEBUG # 调试日志
- 开发启动类:
package com.joezhou;
/** @author 周航宇 */
@SpringBootApplication
public class MCPClientApp {
public static void main(String[] args) {
SpringApplication.run(MCPClientApp.class, args);
}
}
- 开发控制器:
package com.joezhou.controller;
/** @author 周航宇 */
@RequestMapping("/api/v1/mcp")
@RestController
@CrossOrigin
public class MCPController {
private final ChatClient chatClient;
public MCPController(ChatClient.Builder chatClientBuilder, ToolCallbackProvider toolCallbackProvider) {
this.chatClient = chatClientBuilder
// 注册工具回调
.defaultToolCallbacks(toolCallbackProvider.getToolCallbacks())
.build();
}
@GetMapping("call")
public String call(@RequestParam("msg") String msg) {
return chatClient.prompt()
.user(msg)
.call()
.content();
}
}
- 测试控制器:
### call
GET http://localhost:13905/api/v1/mcp/call?
msg=1号房间都有哪些衣服?
- 观察控制台是否成功调用了本地 MCP Server 的工具:

4. 接入高德MCP服务端
心法:高德地图 MCP Server 现已覆盖很多核心服务接口,提供全场景覆盖的地图服务。
高德 MCP 服务端常用接口:
| 服务接口 | 输入内容 | 输出内容 |
|---|---|---|
| 地理编码 | 省市区及完整详细地址 | 精准经纬度坐标 |
| 逆地理编码 | 经纬度坐标 | 省市区层级完整详细地址 |
| IP 定位 | 网络 IP 地址 | 所属省份、城市归属地 |
| 天气查询 | 城市名称 | 城市实时及预报天气数据 |
| 骑行路径规划 | 起点经纬度、终点经纬度 | 出行距离、预计时长、分段骑行路线步骤 |
| 步行路径规划 | 起点经纬度、终点经纬度 | 起止点位信息、完整步行路线详情 |
| 驾车路径规划 | 起点经纬度、终点经纬度 | 起止点位信息、最优驾车出行路线方案 |
| 公交路径规划 | 起点经纬度、终点经纬度、出发城市、目的城市 | 出行距离、起止点位信息、公共交通换乘出行方案 |
| 距离测量 | 起点经纬度、终点经纬度 | 点位基础信息、实际通行距离、出行预估时长 |
| 周边搜索 | 搜索关键词、中心位置经纬度、可选搜索范围半径 | 指定范围内全部兴趣点 POI 相关信息 |
武技:参考 高德开放平台教程,在 springai-mcp-client 子项目中接入高德地图 MCP 服务端。
- 登录 高德开放平台控制台:
- 如果没有开发者账号,请 注册成为开发者,然后重新进入控制台。
- 进入【应用管理】,点击页面右上角【创建新应用】,填写表单即可创建新的应用(随意填写)。
- 进入【应用管理】,在我的应用中选择需要创建 Key 的应用,点击【添加 Key】,表单中的服务平台选择【Web 服务】。
- 创建成功后,可获取 Key 和安全密钥(妥善保存 Key 值)。
- 登录 魔搭 MCP 广场,选择高德地图,在右侧【stido】卡片中复制 JSON 内容,如下:
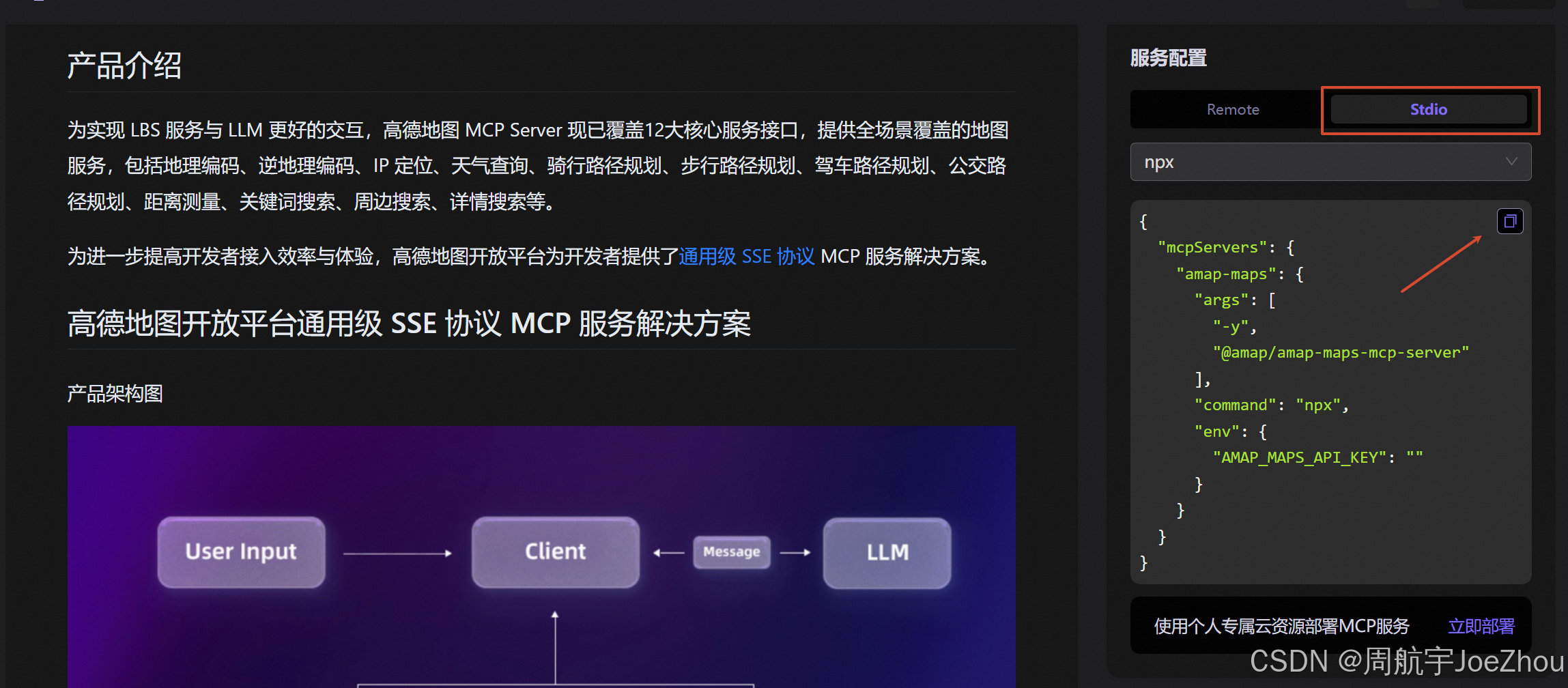
- 在 JSON 中将 “npx” 替换为绝对路径如 “D:\node\nodejs\npx.cmd” 等,若不知道 npx.cmd 安装位置,可以使用如下命令查询(前提是系统中安装了 node 服务器):
# 查询 npx.cmd 安装位置
where npx
- 在 springai-mcp-client 子项目中开发配置文件:
mcp-servers-configuration.json:名称随意:
{
"mcpServers": {
"amap-maps": {
"args": [
"-y",
"@amap/amap-maps-mcp-server"
],
"command": "D:\\node\\nodejs\\npx.cmd",
"env": {
"AMAP_MAPS_API_KEY": "这里需要粘贴你的高德Key值"
}
}
}
}
application.yml:补充一条 spring.ai.mcp.client.stdio.servers-configuration 配置即可:
...
spring:
ai:
dashscope:
...
mcp:
client:
...
stdio:
servers-configuration: classpath:mcp-servers-configuration.json # MCP 服务器配置文件
- 开发控制器:
package com.joezhou.controller;
/** @author 周航宇 */
@RequestMapping("/api/v1/amap")
@RestController
@CrossOrigin
public class AmapController {
private final ChatClient chatClient;
public AmapController(ChatClient.Builder chatClientBuilder, ToolCallbackProvider toolCallbackProvider) {
this.chatClient = chatClientBuilder
// 注册工具回调
.defaultToolCallbacks(toolCallbackProvider.getToolCallbacks())
.build();
}
@GetMapping("call")
public String call(@RequestParam("msg") String msg) {
return chatClient.prompt()
.user(msg)
.call()
.content();
}
}
- 启动项目,观察控制台是否成功接入高德 MCP 工具:
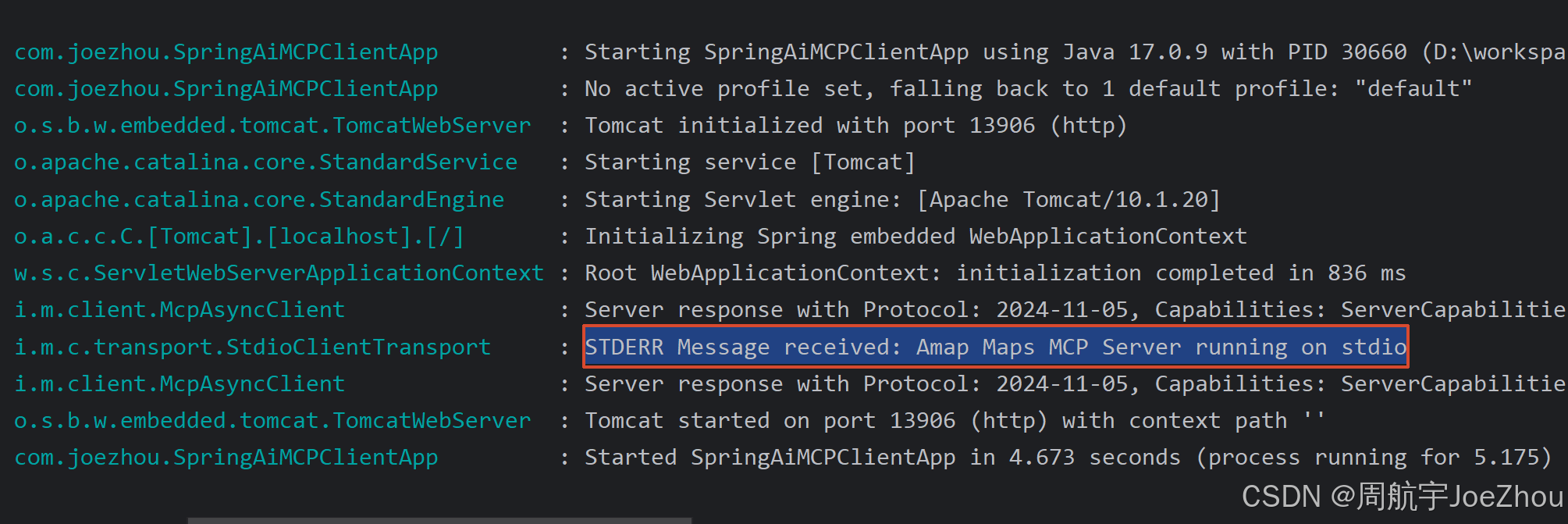
- 测试控制器:
### 测试1:查看控制台日志,是否成功调用 maps_weather 工具
GET http://localhost:13905/api/v1/amap/call?
msg=查询哈尔滨今日的天气?
### 测试2:查看控制台日志,是否成功调用 maps_geo 工具
GET http://localhost:13905/api/v1/amap/call?
msg=哈尔滨恒隆华府小区的经纬度坐标是多少?
- 观察控制台,是否成功调用了高德 MCP Server 的工具:
S05. 任务编排
心法:Spring Ai Alibaba Graph 是一个声明式的工作流编排引擎,就像是 AI 应用的 “流程图工具”,让你不用写一堆代码,就能把复杂的 AI 流程给串起来。
场景示例:假设你希望大模型帮忙规划周末出游计划:
| 步骤 | 简述 | 描述 |
|---|---|---|
| 1 | 发送需求 | 你对大模型说:“周末想带家人出去玩,预算 1000 元,不要太累,最好有吃有玩” |
| 2 | 需求理解 | 大模型将拆解你的需求:包括人数、预算、偏好、时间限制等 大模型将拆解的结果存储到【状态】中 |
| 3 | 地点筛选 | 大模型根据你的偏好,筛选出符合预算和距离的 3 个备选地点(A, B, C) 大模型将筛选的结果更新到【状态】中 |
| 4 | 方案对比 | 大模型分别生成每个地点的行程:几点出发、玩什么、吃什么、预计花费 大模型对比哪个更适合带孩子或老人,给你列好优缺点 |
| 5 | 人工决策 | 大模型把几套方案发给你,你可以直接选择 “方案 A” 或者回复 “想换个海边的选项” 或者回复 “再帮我看看雨天的备选” |
| 6 | 分支执行 | 若你选了方案 A,系统自动帮你查实时路况、生成路线地图,发你一份可直接用的行程单 若你说 “换雨天备选”,流程就会回到 “地点筛选”节点,重新找室内景点,再生成新方案 若你说 “预算不够,改 500 以内”,系统会带着你的新需求,重新跑一遍筛选和对比步骤 |
这整个过程不是一步就能完成的单次对话,而是 多步骤、有状态、可分支、可循环 的流程:
- 中间每一步的结果(比如你选了哪个方案、改了什么需求),都要传递到下一步用。
- 你随时可以修改需求,让流程 “倒回去” 重新执行,甚至根据你的选择走完全不同的分支。
如果不用 Graph,你得写一堆硬编码控制流程跳转、保存中间结果、处理分支逻辑,代码又乱又难维护。
Spring AI Alibaba Graph 三大核心模型:
| 术语 | 中文 | 在工作流中的作用 | 详述 |
|---|---|---|---|
| State | 状态 | 跨节点传递和共享数据的上下文容器 | 统一管理全流程上下文,确保数据在节点间安全一致地流转 |
| Node | 节点 | 一个独立的,原子的执行单元 | 承载具体的业务逻辑,是流程的 “执行者”: 如大模型模型调用,外部 API 调用等 如数据库操作,执行自定义业务代码等 |
| Edge | 边 | 定义节点之间的连接关系 定义节点之间的流转方向 控制某个流程的执行路径 | 是实现分支、循环等复杂流程逻辑的关键,具体分为两类: 直接边:固定顺序流转 条件边:基于 State 数据动态路由(动态决定具体路径) |
对应上文的 “周末出游的场景”:
| 核心概念 | 在出游场景中的角色 | 场景示例 |
|---|---|---|
| State(状态) | 全程跟着你走的 “出游数据档案袋” | 里面装着你的预算、出行偏好、备选地点、最终选定的方案 甚至临时修改的雨天备选需求,全程在各个环节间传递共享 |
| Node(节点) | 流程里的每一个 “办事窗口” | 每个窗口只做一件事:比如 理解你的需求 → 筛选合理地点 → 生成行程方案 → 等待你的确认 → 生成最终行程单 |
| Edge(边) | 决定下一步走哪条路的 “指引箭头” | 若你确认了方案:箭头直接指向 “生成最终行程单” 若你要修改需求:箭头绕回 “重新筛选地点” 若你一直不满意:箭头循环触发 “重新生成行程方案” |
武技:创建 springai-graph 子项目,并完成初始化工作。
- 添加三方依赖:
<dependencies>
<!--spring-boot-starter-web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--spring-ai-alibaba-starter-dashscope-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<!--spring-ai-alibaba-graph-core-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-graph-core</artifactId>
</dependency>
</dependencies>
- 开发主配文件:
server:
port: 13906 # 端口号
servlet:
encoding:
charset: utf-8 # 字符集(解决 stream 中文乱码)
enabled: true # 启用字符编码(解决 stream 中文乱码)
force: true # 强制使用字符编码(解决 stream 中文乱码)
spring:
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY} # 阿里云百炼 API_KEY
read-timeout: 100000 # 读取超时时间(毫秒)
chat:
options:
model: qwen-plus # 基础对话模型
max-tokens: 1000 # Token 限制
temperature: 0.5 # 采样温度
logging:
level:
org.springframework.ai: DEBUG # 调试日志
- 开发启动类:
package com.joezhou;
/** @author 周航宇 */
@SpringBootApplication
public class GraphApp {
public static void main(String[] args) {
SpringApplication.run(GraphApp.class, args);
}
}
E01. Graph基础编排
心法:SpringAiAlibabaGraph 的基础流转过程包括创建 StateGraph 图对象(包括状态策略,状态值,节点,边等),编译图(将 StateGraph 编译为 CompiledGraph 对象)和调用图(invoke)三部分。
基础流转的相关代码:Alibaba 不允许在图中直接使用同步节点,同步节点必须异步包装,避免阻塞主线程:
| 步骤 | 简述 | 描述 | 示例(目标值和初始值均为 Object 类型) |
|---|---|---|---|
| 1 | 创建状态策略 | 支持定义替换,追加或合并三种策略 | KeyStrategy strategy = new ReplaceStrategy() |
| 2 | 创建策略工厂 | 定义状态变量,并绑定对应的更新策略 | KeyStrategyFactory ksf = () -> Map.of("key", strategy) |
| 3 | 创建状态图 | 创建未编译的状态图,支持动态修改 | StateGraph graph = new StateGraph("graphId", ksf) |
| 4 | 创建同步节点 | 创建同步节点并编写节点业务逻辑 | NodeAction n = state -> Map.of("key", 目标值) |
| 5 | 包装异步节点 | 使用异步包装器将同步节点异步化 | AsyncNodeAction aNode = AsyncNodeAction.node_async(n) |
| 6 | 注册异步节点 | 将异步节点注册到状态图中 | graph.addNode("节点ID", asyncNode) |
| 7 | 添加边 | 定义节点之间的执行流向 | graph.addEdge("起始节点ID", "目标节点ID") |
| 8 | 生成编译图 | 编译状态图为可运行但不可修改的对象 | CompiledGraph compiledGraph = graph.compile() |
| 9 | 调用编译图 | 传入初始状态,启动并执行整个图流程 | compiledGraph.invoke(Map.of("键", 初始值)) |
StateGraph 内置节点:钩子不会作用于 START、END、ERROR 节点自身:
| 使用方式 | 值 | 类型 | 简述 |
|---|---|---|---|
| StateGraph.START | __START__ | 接口常量字符串 | 流程默认起点,流程发起首节点,必须使用 |
| StateGraph.END | __END__ | 接口常量字符串 | 正常流程收尾终点,业务链路建议收尾至此 |
| StateGraph.ERROR | __ERROR__ | 接口常量字符串 | 捕获流程异常,统一异常处理入口 |
| StateGraph.NODE_BEFORE | __NODE_BEFORE__ | 接口常量字符串 | 自定义业务节点执行前,自动触发执行的钩子 |
| StateGraph.NODE_AFTER | __NODE_AFTER__ | 接口常量字符串 | 自定义业务节点执行后,自动触发执行的钩子 |
武技:开发一个 Graph 基础流转的测试代码。
- 开发配置类:
package com.joezhou.config;
/** @author 周航宇 */
@Slf4j
@Configuration
public class HelloGraphConfig {
@SneakyThrows
@Bean("helloGraph")
public CompiledGraph helloGraph() {
// 创建状态变量 a,采用替换策略(新值会替换旧值,旧值会被丢弃)
KeyStrategyFactory keyStrategyFactory = () -> Map.of("a", new ReplaceStrategy());
// 创建图,命名为 helloGraph
StateGraph graph = new StateGraph("helloGraph", keyStrategyFactory);
// 创建异步节点 nodeA
graph.addNode("nodeA", AsyncNodeAction.node_async(state -> {
log.info("节点 A 中获取到的全局状态 OverAllState: {}", state);
// 将状态变量 a 设置为 "1"
return Map.of("a", "1");
}));
// 创建异步节点 nodeB
graph.addNode("nodeB", AsyncNodeAction.node_async(state -> {
log.info("节点 B 中获取到的全局状态 OverAllState: {}", state);
// 将状态变量 a 设置为 "2"
return Map.of("a", "2");
}));
// 创建边
graph.addEdge(StateGraph.START, "nodeA");
graph.addEdge("nodeA", "nodeB");
graph.addEdge("nodeB", StateGraph.END);
// 编译图(生成可执行的图,此时图的结构和节点行为会被固定,无法再修改)
CompiledGraph compiledGraph = graph.compile();
// 返回编译后的图
return compiledGraph;
}
}
- 开发控制器:
package com.joezhou.controller;
/** @author 周航宇 */
@Slf4j
@RequestMapping("/api/v1/helloGraph")
@RestController
@CrossOrigin
@SuppressWarnings("all")
public class HelloGraphController {
private final CompiledGraph helloGraph;
public HelloGraphController(@Qualifier("helloGraph") CompiledGraph helloGraph) {
// 注入编译好的 Graph 实例,用于执行流程
this.helloGraph = helloGraph;
}
@GetMapping("exe")
public Map<String, Object> exe() {
// 执行图流程
// Map 参数表示状态变量的起始值,可以为空,如直接传递 Map.of()
Optional<OverAllState> optional = helloGraph.invoke(Map.of("a", "0"));
log.info("最终的全局状态 OverAllState: {}", optional.get());
// 返回数据 Map
return optional.map(OverAllState::data).orElseThrow();
}
}
- 测试控制器:
### exe
GET http://localhost:13906/api/v1/helloGraph/exe
控制台结果如图:

1. SpringAiAlibabaStudio
心法:Spring AI Alibaba Studio 简称 SAA-Studio 是内置 Web UI 的嵌入式本地开发调试工具,引入对应依赖并开启开关后,项目启动即自动托管前端静态资源与配套后端接口,开发者通过浏览器访问内置页面,可视化调试项目内所有注册的 Graph 工作流,Agent、RAG 检索、模型交互流程,大幅降低 AI 智能体迭代调试成本。
SAA-Studio 使用原理:内置 AgentLoader 自动扫描 Spring 容器中所有实现 com.alibaba.cloud.ai.agent.Agent 顶层接口的 Bean:
- 支持官方内置实现:包括 CompiledGraph,ReactAgent,MultiAgent,LlmRoutingAgent 等。
- 支持开发者自定义实现 Agent 接口的业务智能体。
- 原生 ChatClient 不属于 Agent 体系,无法被 Studio 自动识别。
SAA-Studio 注意事项:Spring AI Alibaba Studio 不支持独立分布式部署,仅服务本地开发环境,生产环境建议移除该依赖。
武技:在 springai-graph 子项目中引入 SSA-Studio 工具。
- 添加 SSA-Studio 相关依赖:这里使用 1.1.2.2 版本,1.1.2.0 版本有 BUG:
<!--spring-ai-alibaba-studio-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-studio</artifactId>
<version>${spring-ai-alibaba-studio.version}</version>
</dependency>
- 重新启动 springai-graph 项目。
- 通过 SAA-Studio 查看 Graph 流程:首先选择 helloGraph 进入对话,然后随意输入内容并点击发送,即可看到图流程:
2. KeyStrategyFactory
心法:KeyStrategyFactory 接口是一个函数式接口,用来定义状态变量以及对应的更新策略。
状态更新策略:
| 状态更新策略 | 简述 | 描述 |
|---|---|---|
new ReplaceStrategy() | 替换策略 | 新值替换旧值,适合任何类型的数据,生产环境推荐使用 |
new MergeStrategy() | 合并策略 | 适合 Map 类型的数据,新旧 Map 的数据合并(相同会覆盖) |
new AppendStrategy() | 追加策略 | 适合 List 类型的数据,新 List 的数据追加到旧的 List 中 |
武技:测试 Graph 状态的三种策略。
- 开发配置类:
package com.joezhou.config;
/** @author 周航宇 */
@Slf4j
@Configuration
public class KeyStrategyGraphConfig {
@SneakyThrows
@Bean("keyStrategyGraph")
public CompiledGraph keyStrategyGraph() {
// 创建状态变量 a, b, c,分别采用替换、合并、追加策略
KeyStrategyFactory keyStrategyFactory = () -> {
Map<String, KeyStrategy> map = new HashMap<>(3);
map.put("a", new ReplaceStrategy());
map.put("b", new MergeStrategy());
map.put("c", new AppendStrategy());
return map;
};
// 创建图
StateGraph graph = new StateGraph("keyStrategyGraph", keyStrategyFactory);
// 创建异步节点 nodeA
graph.addNode("nodeA", AsyncNodeAction.node_async(state -> {
log.info("节点 A 中获取到的全局状态 OverAllState: {}", state);
Map<String, Object> map = new HashMap<>(3);
map.put("a", "1");
map.put("b", Map.of("age", 19));
map.put("c", List.of("喝酒"));
return map;
}));
// 创建异步节点 nodeB
graph.addNode("nodeB", AsyncNodeAction.node_async(state -> {
log.info("节点 B 中获取到的全局状态 OverAllState: {}", state);
Map<String, Object> map = new HashMap<>(3);
map.put("a", "2");
map.put("b", Map.of("gender", "男"));
map.put("c", List.of("烫头"));
return map;
}));
// 创建边
graph.addEdge(StateGraph.START, "nodeA");
graph.addEdge("nodeA", "nodeB");
graph.addEdge("nodeB", StateGraph.END);
// 编译图
return graph.compile();
}
}
- 开发控制器:
package com.joezhou.controller;
/** @author 周航宇 */
@Slf4j
@RequestMapping("/api/v1/keyStrategy")
@RestController
@CrossOrigin
@SuppressWarnings("all")
public class KeyStrategyController {
private final CompiledGraph keyStrategyGraph;
public KeyStrategyController(@Qualifier("keyStrategyGraph") CompiledGraph keyStrategyGraph) {
// 注入编译好的 Graph 实例,用于执行流程
this.keyStrategyGraph = keyStrategyGraph;
}
@GetMapping("exe")
public Map<String, Object> exe() {
// 执行图流程
Optional<OverAllState> optional = keyStrategyGraph.invoke(Map.of(
"a", "0",
"b", Map.of("name", "赵四"),
"c", List.of("抽烟")
));
log.info("最终的全局状态 OverAllState: {}", optional.get());
// 返回数据 Map
return optional.map(OverAllState::data).orElseThrow();
}
}
- 测试控制器:
### exe
GET http://localhost:13906/api/v1/keyStrategy/exe
控制台结果如图:

3. NodeAction
心法:NodeAction 是 Spring AI Alibaba Graph 中节点执行逻辑的核心函数式接口,统一约定了流程节点的标准契约:“接收状态变量 → 处理逻辑 → 返回新状态变量”。
AsyncNodeAction:是官方推荐的异步包装器,用于将普通同步逻辑封装为 Graph 可识别的异步节点,事实上官方不推荐也不允许直接添加原生 NodeAction 节点,而是必须通过 AsyncNodeAction.node_async(...) 包装后才能使用。
自定义节点:开发者可通过实现 NodeAction 接口定义可复用的业务节点,实现逻辑解耦与复用,然后再使用 AsyncNodeAction 进行异步包装。
武技:测试自定义节点。
- 开发自定义节点类:
package com.joezhou.node;
/** @author 周航宇 */
@Slf4j
public class MyCustomNode implements NodeAction {
@SneakyThrows
@Override
public Map<String, Object> apply(OverAllState state) {
log.info(">> MyCustomNode:获取到当前状态:{}", state);
// 获取状态变量 username 的值,默认值为空字符串
String username = state.value("username", "");
log.info(">> MyCustomNode:获取到 username 的值:{}", username);
// 执行业务逻辑,将 username 转换为大写
username = username.toUpperCase();
log.info(">> MyCustomNode:修改了 username 的值:{}", username);
// 返回新状态
return Map.of("username", username);
}
}
- 开发配置类:
package com.joezhou.config;
/** @author 周航宇 */
@Slf4j
@Configuration
public class CustomNodeConfig {
@SneakyThrows
@Bean("customNodeGraph")
public CompiledGraph customNodeGraph() {
// 创建状态
KeyStrategyFactory keyStrategyFactory = () -> Map.of("username", new ReplaceStrategy());
// 创建图
return new StateGraph("customNodeGraph", keyStrategyFactory)
.addNode("customNode", AsyncNodeAction.node_async(new MyCustomNode()))
.addEdge(StateGraph.START, "customNode")
.addEdge("customNode", StateGraph.END)
.compile();
}
}
- 开发控制器:
package com.joezhou.controller;
/** @author 周航宇 */
@Slf4j
@RequestMapping("/api/v1/customNode")
@RestController
@CrossOrigin
@SuppressWarnings("all")
public class CustomNodeController {
private final CompiledGraph customNodeGraph;
public CustomNodeController(@Qualifier("customNodeGraph") CompiledGraph customNodeGraph) {
this.customNodeGraph = customNodeGraph;
}
@GetMapping("exe")
public Map<String, Object> exe() {
// 执行图流程
Optional<OverAllState> optional = customNodeGraph.invoke(Map.of("username", "joezhou"));
log.info("最终的全局状态 OverAllState: {}", optional.get());
// 返回数据 Map
return optional.map(OverAllState::data).orElseThrow();
}
}
- 测试控制器:
### exe
GET http://localhost:13906/api/v1/customNode/exe
控制台结果如图:

4. 状态数据隔离
心法:和之前的会话隔离原理一样,状态变量也必须做用户隔离,即每个用户只能查看、修改自己独有的状态数据,不能访问或修改别人的,保证数据安全、互不干扰。
解决方案:
| 步骤 | 描述 |
|---|---|
| 1 | 前端接收会话 ID |
| 2 | 将会话 ID 传入 RunnableConfig 对象 |
| 3 | 调用编译图对象的 invoke() 方法时,传入 RunnableConfig 对象 |
具体实现如下:
// 创建会话配置
RunnableConfig runnableConfig = RunnableConfig.builder()
.threadId(conversationId)
.build();
// 执行图流程
Optional<OverAllState> optional = conversationGraph.invoke(
Map.of(),
runnableConfig);
武技:通过配置不同的 threadId 模拟多个用户,验证各自的状态变量是否独立存储、互不影响,确保隔离功能正常生效。
- 开发配置类:
package com.joezhou.config;
/** @author 周航宇 */
@Slf4j
@Configuration
public class ConversationConfig {
@SneakyThrows
@Bean("conversationGraph")
public CompiledGraph conversationGraph() {
// 创建状态
KeyStrategyFactory keyStrategyFactory = () -> Map.of("a", new ReplaceStrategy());
// 创建图
StateGraph graph = new StateGraph("conversationGraph", keyStrategyFactory)
.addNode("conversationNode", AsyncNodeAction.node_async(state -> {
// 让 a 自增
int a = Integer.parseInt(state.value("a", "0"));
a++;
return Map.of("a", a + "");
}))
.addEdge(StateGraph.START, "conversationNode")
.addEdge("conversationNode", StateGraph.END);
// 编译图
return graph.compile();
}
}
- 开发控制器:
package com.joezhou.controller;
/** @author 周航宇 */
@Slf4j
@RequestMapping("/api/v1/conversation")
@RestController
@CrossOrigin
@SuppressWarnings("all")
public class ConversationController {
private final CompiledGraph conversationGraph;
public ConversationController(@Qualifier("conversationGraph") CompiledGraph conversationGraph) {
this.conversationGraph = conversationGraph;
}
@GetMapping("exe/{conversationId}")
public Map<String, String> exe(@PathVariable("conversationId") String conversationId) {
// 创建会话配置
RunnableConfig runnableConfig = RunnableConfig.builder()
.threadId(conversationId)
.build();
// 执行图流程
Optional<OverAllState> optional = conversationGraph.invoke(
Map.of(),
runnableConfig);
// 获取数据中的 a 值
String value = optional.orElseThrow().value("a", "暂无数据");
// 返回会话 ID 和对应会话中的 a 值
return Map.of(conversationId, value);
}
}
- 测试控制器:
### exe
GET http://localhost:13906/api/v1/conversation/exe/1001
### exe
GET http://localhost:13906/api/v1/conversation/exe/1002
E02. Graph流程走向
心法:搭建 AI 工作流与智能 Agent 时,业务流程并非单一顺序执行,常会依据数据状态、用户反馈、逻辑判定产生分支走向,或是循环往复执行,而 边() 正是实现这类流程逻辑的核心。
- 直接边:按既定顺序串联流程节点,实现任务线性执行。
- 条件边:依托条件判断完成分支跳转与流程分流,根据实际业务场景自动匹配执行路径。
- 循环边:针对重复作业、多轮核验、连续交互等场景,驱动流程循环运行,直至满足终止条件后自动退出。
1. 直接边-智能回复
心法:本案例通过 5 个节点实现商品评价智能分析流水线:提取关键词 → 情感判定 → 生成摘要 → 客服回复 → 最终报告。
业务流程:用户发布一条商品的评价信息,AI 自动完成以下工作:
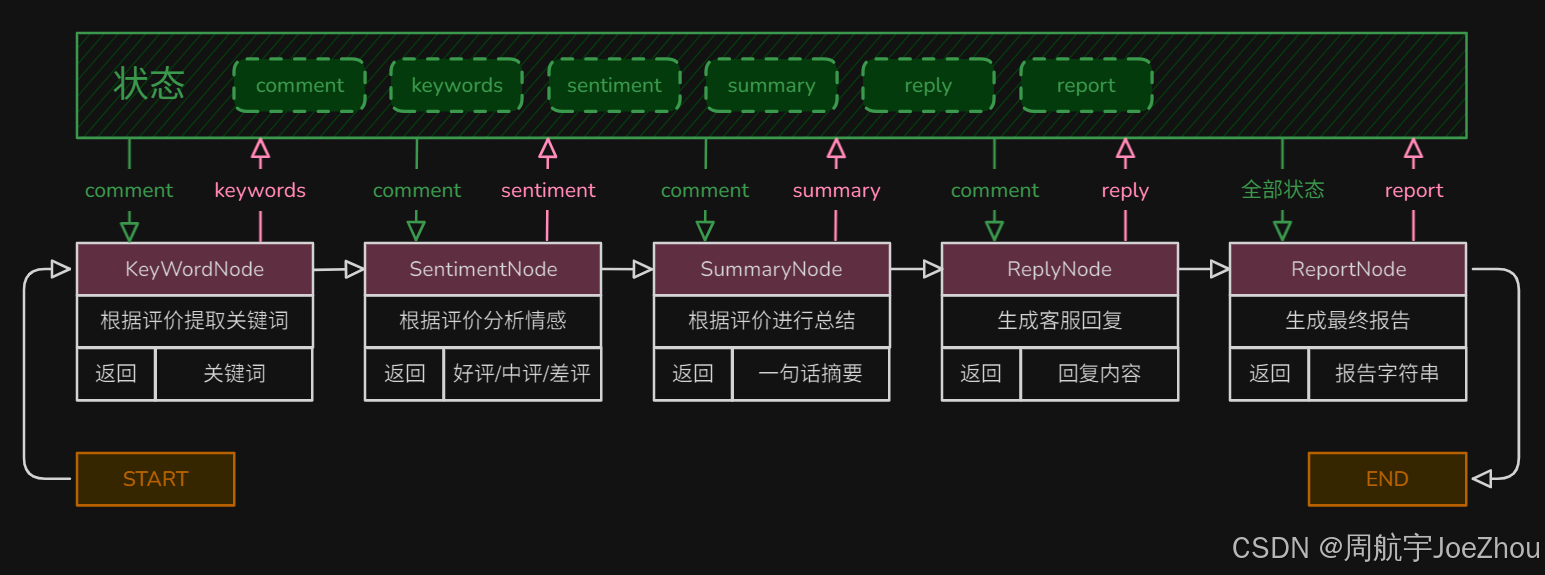
武技:开发智能回复用户评论的案例代码。
- 开发 5 个自定义节点:
KeyWordNode(关键词提取):
package com.joezhou.node;
/** @author 周航宇 */
@Slf4j
public class KeyWordNode implements NodeAction {
private final ChatClient chatClient;
public KeyWordNode(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@Override
public Map<String, Object> apply(OverAllState state) {
// 获取状态变量(默认空串)
String input = state.value("input", "");
// 调用大模型,提取评论的关键词
String content = chatClient.prompt()
.user("""
根据评论内容 %s,提取出关键词,关键词之间用逗号隔开即可;
只返回最终提取的关键词内容即可,不要返回其他无关的内容。
""".formatted(input))
.call()
.content()
.trim();
log.info(">> Node01:提取到评价关键词:{}", content);
// 更新状态变量
return Map.of("keywords", content);
}
}
SentimentNode(情感分析):
package com.joezhou.node;
/** @author 周航宇 */
@Slf4j
public class SentimentNode implements NodeAction {
private final ChatClient chatClient;
public SentimentNode(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@Override
public Map<String, Object> apply(OverAllState state) {
// 获取状态变量(默认空串)
String input = state.value("input", "");
// 调用大模型,判断评论的情感
String content = chatClient.prompt()
.user("""
根据评论内容 %s,判断出评价情感;
只返回 “好评”、“中评”、“差评” 三者之一即可,不要返回其他无关的内容。
""".formatted(input))
.call()
.content()
.trim();
log.info(">> Node02:判断出评价情感:{}", content);
// 更新状态变量
return Map.of("sentiment", content);
}
}
SummaryNode(评价摘要):
package com.joezhou.node;
/** @author 周航宇 */
@Slf4j
public class SummaryNode implements NodeAction {
private final ChatClient chatClient;
public SummaryNode(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@Override
public Map<String, Object> apply(OverAllState state) {
// 获取状态变量(默认空串)
String input = state.value("input", "");
// 调用大模型,生成评论的摘要
String content = chatClient.prompt()
.user("""
根据评论内容 %s,进行一句话的总结;
只返回最终提取的总结内容即可,不要返回其他无关的内容。
""".formatted(input))
.call()
.content()
.trim();
log.info(">> Node03:生成了评价摘要:{}", content);
// 更新状态变量
return Map.of("summary", content);
}
}
ReplyNode(客服回复):
package com.joezhou.node;
/** @author 周航宇 */
@Slf4j
public class ReplyNode implements NodeAction {
private final ChatClient chatClient;
public ReplyNode(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@Override
public Map<String, Object> apply(OverAllState state) {
// 获取状态变量(默认空串)
String input = state.value("input", "");
// 调用大模型,生成客服回复
String content = chatClient.prompt()
.user("""
你是一个专业的客服,负责回复评价;
根据评论内容 %s,生成礼貌回复;
只返回最终回复内容即可,不要返回其他无关的内容。
""".formatted(input))
.call()
.content()
.trim();
log.info(">> Node04:生成了客服回复:{}", content);
// 更新状态变量
return Map.of("reply", content);
}
}
ReportNode(最终报告):
package com.joezhou.node;
/** @author 周航宇 */
@Slf4j
public class ReportNode implements NodeAction {
@Override
public Map<String, Object> apply(OverAllState state) {
// 获取状态变量(默认空串)
String input = state.value("input", "");
String keywords = state.value("keywords", "");
String sentiment = state.value("sentiment", "");
String summary = state.value("summary", "");
String reply = state.value("reply", "");
// 生成评价分析报告
String report = """
====================
【原始评价】:%s
【关键词语】:%s
【情感评级】:%s
【摘要信息】:%s
【建议回复】:%s
====================
""".formatted(input, keywords, sentiment, summary, reply);
log.info(">> Node05:生成了评价分析报告:\n{}", report);
// 更新状态变量
return Map.of("report", report);
}
}
- 开发配置类:
package com.joezhou.config;
/** @author 周航宇 */
@Configuration
public class UserCommentConfig {
@SneakyThrows
@Bean("commentGraph")
public CompiledGraph commentGraph(ChatClient.Builder chatClientBuilder) {
// 创建状态
KeyStrategyFactory keyStrategyFactory = () -> Map.of(
"input", new ReplaceStrategy(),
"keywords", new ReplaceStrategy(),
"sentiment", new ReplaceStrategy(),
"summary", new ReplaceStrategy(),
"reply", new ReplaceStrategy(),
"report", new ReplaceStrategy()
);
// 创建图
return new StateGraph("commentGraph", keyStrategyFactory)
.addNode("keyword", AsyncNodeAction.node_async(new KeyWordNode(chatClientBuilder)))
.addNode("sentiment", AsyncNodeAction.node_async(new SentimentNode(chatClientBuilder)))
.addNode("summary", AsyncNodeAction.node_async(new SummaryNode(chatClientBuilder)))
.addNode("reply", AsyncNodeAction.node_async(new ReplyNode(chatClientBuilder)))
.addNode("report", AsyncNodeAction.node_async(new ReportNode()))
.addEdge(StateGraph.START, "keyword")
.addEdge("keyword", "sentiment")
.addEdge("sentiment", "summary")
.addEdge("summary", "reply")
.addEdge("reply", "report")
.addEdge("report", StateGraph.END)
.compile();
}
}
- 开发控制器:
package com.joezhou.controller;
/** @author 周航宇 */
@Slf4j
@RequestMapping("/api/v1/userComment")
@RestController
@CrossOrigin
public class UserCommentController {
private final CompiledGraph commentGraph;
public UserCommentController(@Qualifier("commentGraph") CompiledGraph commentGraph) {
this.commentGraph = commentGraph;
}
@GetMapping("exe")
public String exe(@RequestParam("input") String input) {
return commentGraph.invoke(Map.of("input", input))
.orElseThrow()
.value("report", "暂无报告");
}
}
- 测试控制器:
### exe
GET http://localhost:13906/api/v1/userComment/exe?
comment=这个手机续航很强,拍照清晰,就是有点重
接口结果如图:
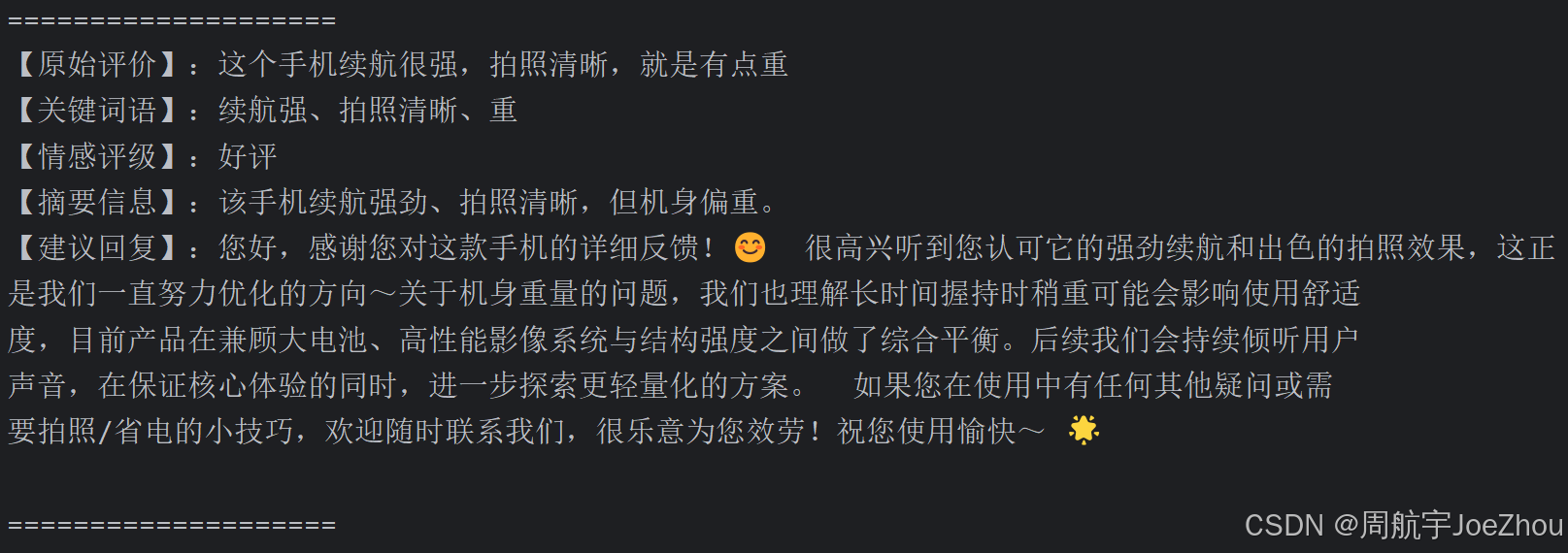
控制台结果如图:
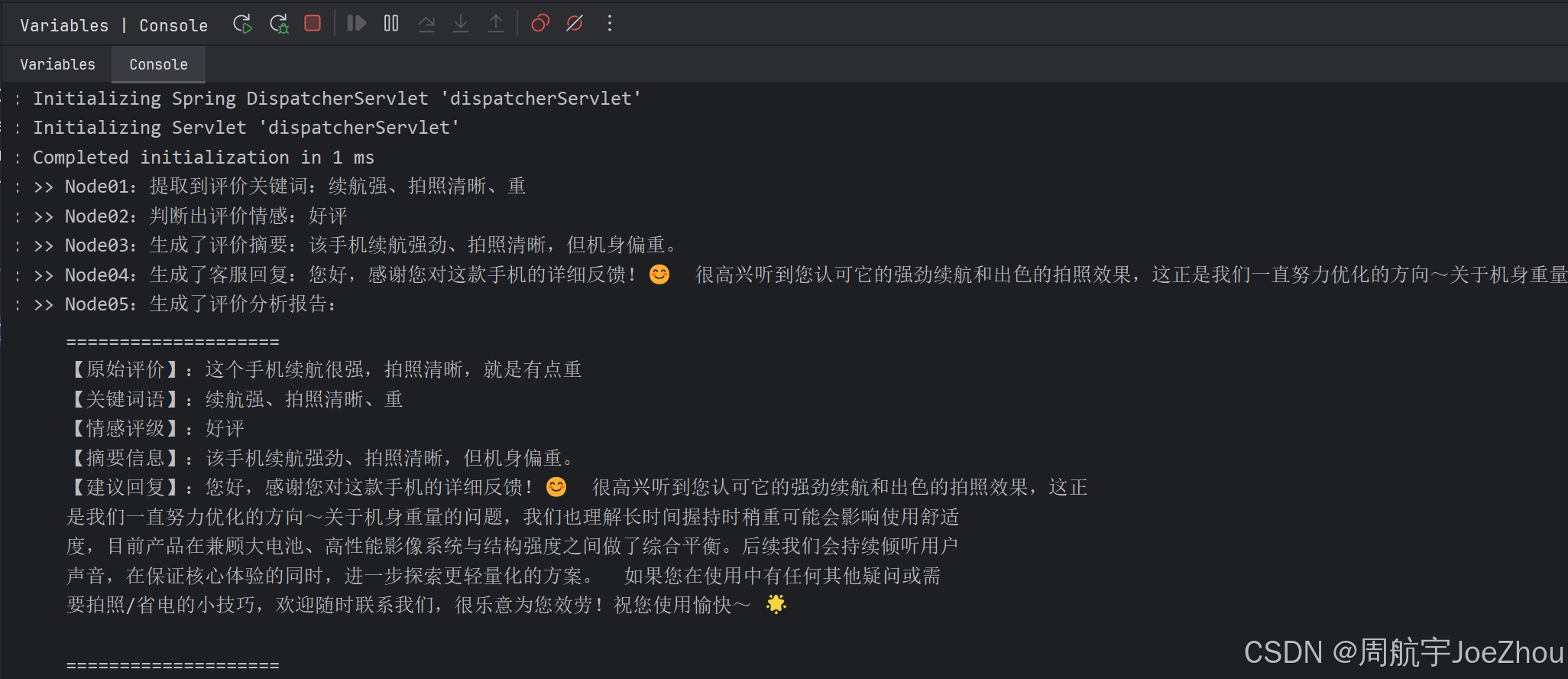
2. 条件边-智能分拣
心法:本案例通过 4 个节点 + 条件边实现售后工单智能分流处理流水线:输入解析 → 风险判定 → 动态分流 → 分支处理,根据风险等级自动走 普通处理 或 紧急处理,真正实现企业级智能路由。
业务流程:用户提交一条售后工单,AI 自动完成以下工作:
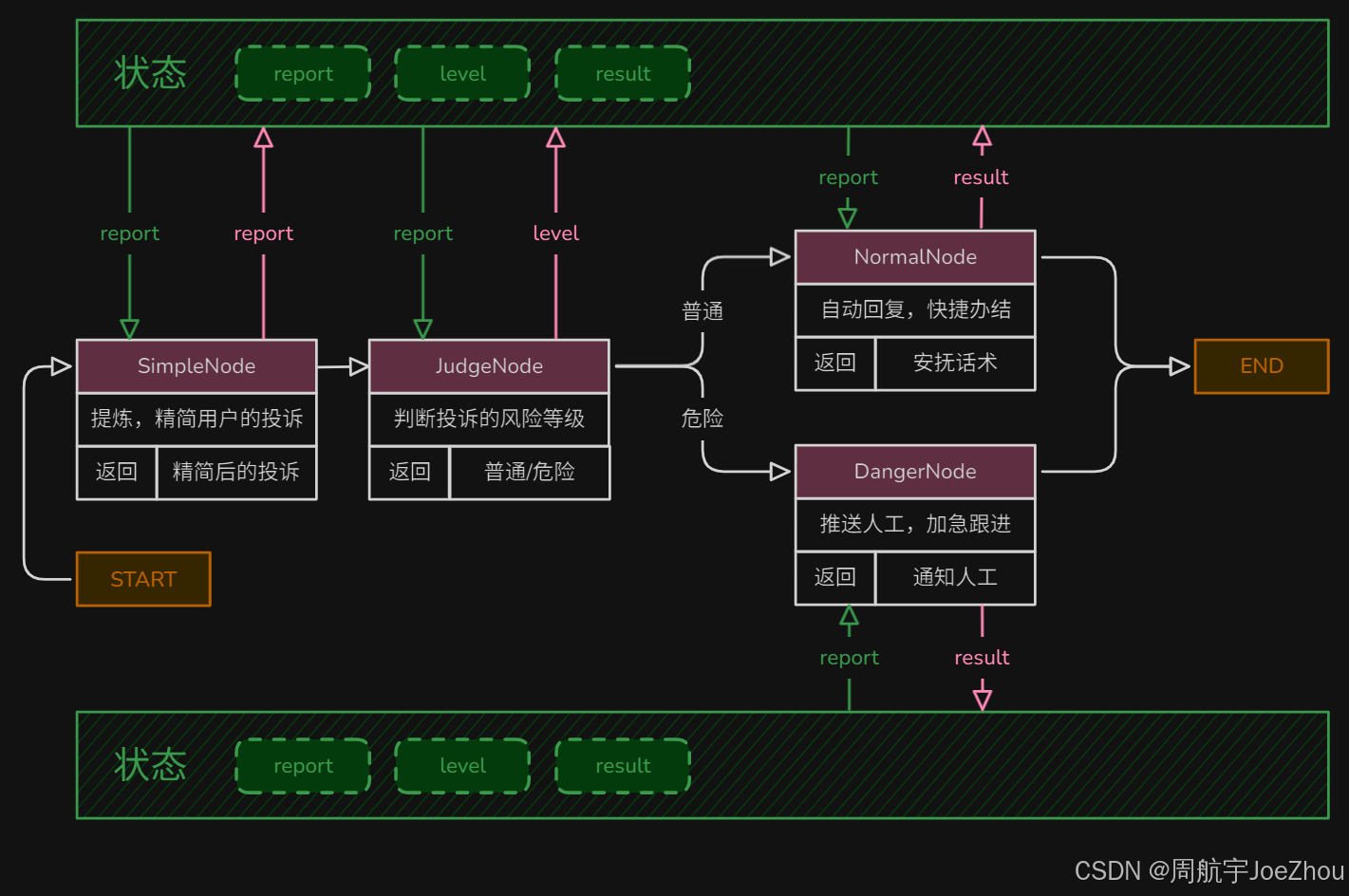
武技:使用条件边开发智能分拣投诉工单的案例代码。
- 开发 5 个自定义节点:
SimpleNode(输入简化):
package com.joezhou.node;
/** @author 周航宇 */
@Slf4j
public class SimpleNode implements NodeAction {
private final ChatClient chatClient;
public SimpleNode(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@Override
public Map<String, Object> apply(OverAllState state) {
// 获取状态变量(默认空串)
String report = state.value("report", "");
// 调用大模型,精简概括用户输入的投诉内容
String content = chatClient.prompt()
.user("""
根据投诉内容 %s,精简概括投诉内容;
只返回最终精简后的内容即可,不要返回其他无关的内容。
""".formatted(report))
.call()
.content()
.trim();
log.info(">> Node01:精简投诉内容:{}", content);
// 更新状态变量
return Map.of("report", content);
}
}
judgeNode(条件判断):
package com.joezhou.node;
/** @author 周航宇 */
@Slf4j
public class JudgeNode implements NodeAction {
private final ChatClient chatClient;
public JudgeNode(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@Override
public Map<String, Object> apply(OverAllState state) {
// 获取状态变量(默认空串)
String report = state.value("report", "");
// 调用大模型,判断风险等级
String content = chatClient.prompt()
.user("""
根据日常经验判断用户举报的内容 %s 的风险等级,
比如包装变形、污渍磕碰、按键卡顿、轻微异响、配件缺失、字迹模糊、轻微掉漆、开合松动等,均视为普通等级的风险(外观、轻微使用瑕疵,无安全威胁),
比如线路老化短路、机身冒烟起火、接口漏电、部件脱落伤人、高温烫手、易燃易爆异味、触电隐患等,均视为危险等级的风险(涉及人身、用电安全隐患),
你只需要只回复 “普通” 或者 “危险” 即可,不要回复其他内容。
""".formatted(report))
.call()
.content()
.trim();
log.info(">> Node02:判断风险等级:{}", content);
// 更新状态变量
return Map.of("level", content);
}
}
NormalNode(普通处理):
package com.joezhou.node;
/** @author 周航宇 */
@Slf4j
public class NormalNode implements NodeAction {
private final ChatClient chatClient;
public NormalNode(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@Override
public Map<String, Object> apply(OverAllState state) {
// 获取状态变量(默认空串)
String report = state.value("report", "");
// 调用大模型,进行安抚处理
String content = chatClient.prompt()
.user("""
你是一个专业的客服,负责处理用户投诉。
根据投诉内容 %s,进行安抚处理,并提示会尽快处理。
""".formatted(report))
.call()
.content()
.trim();
log.info(">> Node03:安抚用户情绪:{}", content);
// 更新状态变量
return Map.of("result", content);
}
}
DangerNode(危险处理):
package com.joezhou.node;
/** @author 周航宇 */
@Slf4j
public class DangerNode implements NodeAction {
@Override
public Map<String, Object> apply(OverAllState state) {
log.info("高危工单,升级处理");
// TODO:联系专员处理
// 更新状态变量
return Map.of("result", "高危问题已升级,专员将立即联系您");
}
}
- 开发配置类:
package com.joezhou.config;
/** @author 周航宇 */
@Configuration
public class UserReportConfig {
@SneakyThrows
@Bean("reportGraph")
public CompiledGraph reportGraph(ChatClient.Builder chatClientBuilder) {
// 创建状态
KeyStrategyFactory keyStrategyFactory = () -> Map.of(
"report", new ReplaceStrategy(),
"level", new ReplaceStrategy(),
"result", new ReplaceStrategy()
);
// 创建图
return new StateGraph("reportGraph", keyStrategyFactory)
.addNode("simpleNode", AsyncNodeAction.node_async(new SimpleNode(chatClientBuilder)))
.addNode("judgeNode", AsyncNodeAction.node_async(new JudgeNode(chatClientBuilder)))
.addNode("normalNode", AsyncNodeAction.node_async(new NormalNode(chatClientBuilder)))
.addNode("dangerNode", AsyncNodeAction.node_async(new DangerNode()))
.addEdge(StateGraph.START, "simpleNode")
.addEdge("simpleNode", "judgeNode")
// 条件边
// p1:从 judgeNode 节点出发
// p2:根据状态变量 level 来判断是否普通或危险
// p3:若 level 是普通,则流向 normalNode 节点,否则流向 dangerNode 节点
.addConditionalEdges(
"judgeNode",
AsyncEdgeAction.edge_async(state -> state.value("level", "普通")),
Map.of("普通", "normalNode", "危险", "dangerNode"))
.addEdge("normalNode", StateGraph.END)
.addEdge("dangerNode", StateGraph.END)
.compile();
}
}
- 开发控制器:
package com.joezhou.controller;
/** @author 周航宇 */
@Slf4j
@RestController
@RequestMapping("/api/v1/userReport")
public class UserReportController {
private final CompiledGraph reportGraph;
public UserReportController(@Qualifier("reportGraph") CompiledGraph reportGraph) {
this.reportGraph = reportGraph;
}
@GetMapping("/exe")
public String exe(@RequestParam("report") String report) {
return reportGraph.invoke(Map.of("report", report))
.orElseThrow()
.value("result", "执行失败");
}
}
- 测试控制器:
### exe普通
GET http://localhost:13906/api/v1/userReport/exe?
report=包装有点破损,特别难看
### exe危险
GET http://localhost:13906/api/v1/userReport/exe?
report=产品漏电,把我的手给烧了
控制台结果如图:


3. 循环边-智能润色
心法:本案例通过 3 个节点 + 循环边实现文本智能润色流水线:输入文本 → 文本润色 → 检查质量 → 循环处理 → 最终汇总,根据检查结果自动走 最终汇总 或回转到 文本润色,真正实现企业级智能路由。
业务流程:传入一段文案,AI 反复迭代优化措辞,每次优化后校验文本通顺度,合格则结束流程,不合格继续循环打磨,最终输出优质文案:
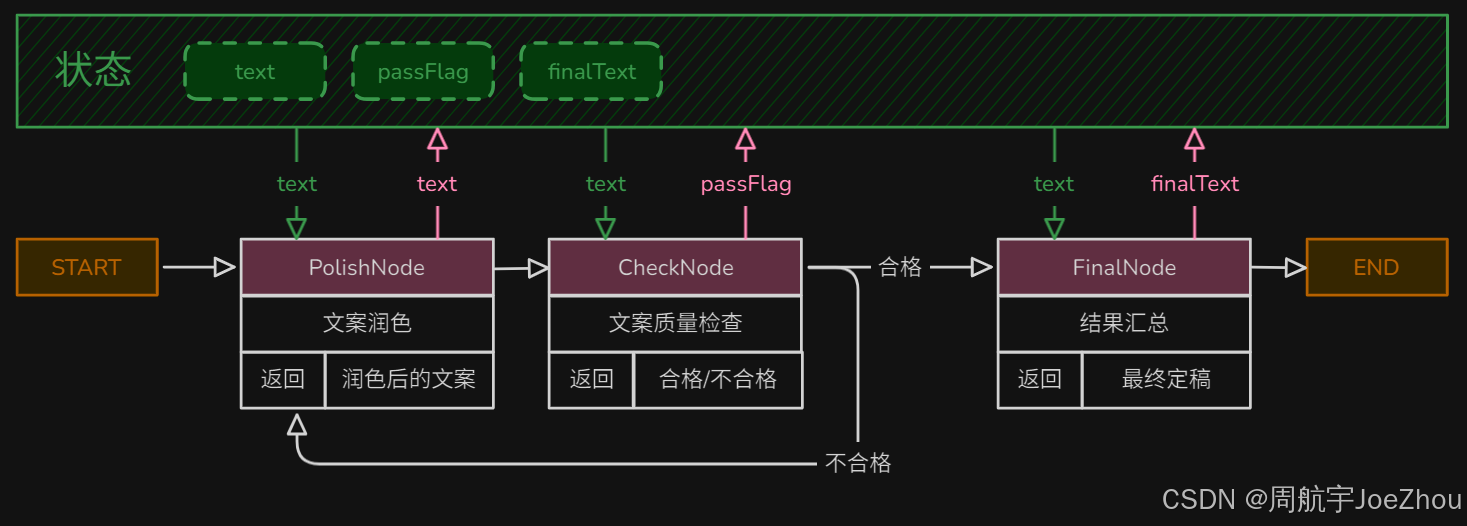
武技:使用循环边开发智能文本润色的案例代码。
- 开发自定义节点:
PolishNode(文案润色节点):
package com.joezhou.node;
/** @author 周航宇 */
@Slf4j
public class PolishNode implements NodeAction {
private final ChatClient chatClient;
public PolishNode(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@Override
public Map<String, Object> apply(OverAllState state) {
// 获取状态变量(默认空串)
String text = state.value("text", "");
log.info("原文:{}", text);
// 调用大模型优化文案
String content = chatClient.prompt()
.user("""
根据用户输入的文案 %s,进行润色和优化:
1. 让语句通顺流畅;
2. 若字数小于100字,则新增 10 - 20个字;
3. 仅返回优化后的内容,不要包含任何解释;
""".formatted(text))
.call()
.content()
.trim();
log.info("优化后的文案:{}", content);
// 更新状态变量
return Map.of("text", content);
}
}
CheckNode(质量校验节点):
package com.joezhou.node;
/** @author 周航宇 */
@Slf4j
public class CheckNode implements NodeAction {
private final ChatClient chatClient;
public CheckNode(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@Override
public Map<String, Object> apply(OverAllState state) {
// 获取状态变量(默认空串)
String text = state.value("text", "");
// 调用大模型判断文案是否通顺合格
String content = chatClient.prompt()
.user("""
根据用户输入的文案 %s,进行判断是否合格:
1. 语句应该通顺且流畅,否则判断为不合格;
2. 字数起码要50字,否则判断为不合格;
3. 内容要有内涵,否则判断为不合格;
4. 仅返回判断结果 “合格” 或 “不合格”,不要包含任何其它内容。
""".formatted(text))
.call()
.content()
.trim();
log.info("文案判断结果:{}", content);
// 更新状态变量
return Map.of("passFlag", content);
}
}
FinalNode(结果汇总节点):
package com.joezhou.node;
/** @author 周航宇 */
@Slf4j
public class FinalNode implements NodeAction {
@Override
public Map<String, Object> apply(OverAllState state) {
// 获取状态变量(默认空串)
String text = state.value("text", "");
// 返回最终文案
log.info("【流程收尾】最终优化文案:{}", text);
return Map.of("finalText", text);
}
}
- 开发配置类:
package com.joezhou.config;
/** @author 周航宇 */
@Slf4j
@Configuration
public class TextConfig {
@SneakyThrows
@Bean("textGraph")
public CompiledGraph textGraph(ChatClient.Builder chatClientBuilder) {
// 创建状态
KeyStrategyFactory keyStrategyFactory = () -> Map.of(
"text", new ReplaceStrategy(),
"passFlag", new ReplaceStrategy(),
"finalText", new ReplaceStrategy()
);
// 创建图
return new StateGraph("textGraph", keyStrategyFactory)
.addNode("polishNode", AsyncNodeAction.node_async(new PolishNode(chatClientBuilder)))
.addNode("checkNode", AsyncNodeAction.node_async(new CheckNode(chatClientBuilder)))
.addNode("finalNode", AsyncNodeAction.node_async(new FinalNode()))
.addEdge(StateGraph.START, "polishNode")
.addEdge("polishNode", "checkNode")
// 循环边:不合格重回润色节点,合格走向收尾
// p1:从 checkNode 节点出发
// p2:根据状态变量 passFlag 来判断是否普通或危险
// p3:若 passFlag 是不合格,则流向 polishNode 节点,否则流向 finalNode 节点
.addConditionalEdges("checkNode",
AsyncEdgeAction.edge_async(state -> state.value("passFlag", "不合格")),
Map.of("合格", "finalNode", "不合格", "polishNode"))
.addEdge("finalNode", StateGraph.END)
.compile();
}
}
- 开发控制器:
package com.joezhou.controller;
/** @author 周航宇 */
@Slf4j
@RestController
@CrossOrigin
@RequestMapping("/api/v1/text")
public class TextController {
private final CompiledGraph textGraph;
public TextController(@Qualifier("textGraph") CompiledGraph textGraph) {
this.textGraph = textGraph;
}
@GetMapping("/exe")
public String exe(@RequestParam("text") String text) {
return textGraph.invoke(Map.of("text", text))
.orElseThrow()
.value("finalText", "文案优化失败");
}
}
- 测试控制器:
### exe
GET http://localhost:13906/api/v1/text/exe?
text=今天天气还行出门玩心情不错就是路有点远
控制台结果如图:
Java道经第3卷 - 第9阶 - SpringAI(一)
传送门:JB3-9-SpringAI(一)
传送门:JB3-9-SpringAI(二)


















&spm=1001.2101.3001.5002&articleId=148280466&d=1&t=3&u=25eeb1557f4b4be7ad64f11bc6d514b4)
 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










