



[1]Vision Pro开售五分钟就挤爆了服务器,半小时内实体店直接售罄。在国内,甚至已经叫价九万一台。

苹果Vision Pro深夜引爆,起价2万5瞬间抢空!7年憋出最强头显,革命空间计算
[2]浙江大学ReLER实验室的研究人员提出SIFU模型,一种侧视图条件隐函数模型用于单张图片3D人体重建。
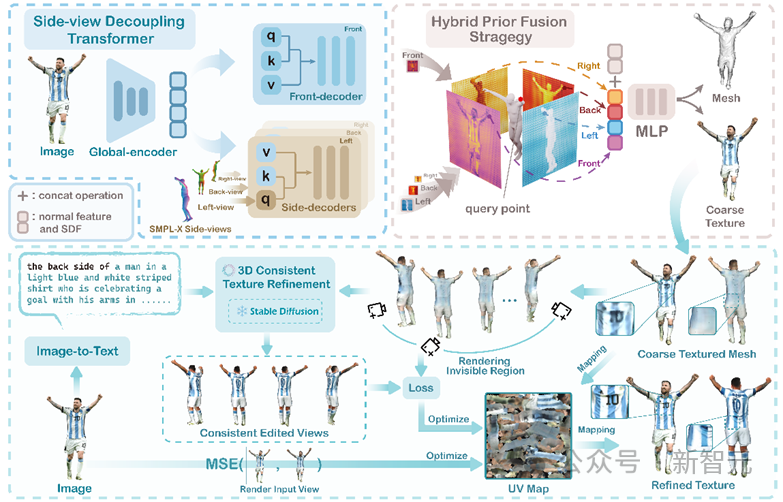
几何纹理重建新SOTA!浙大提出SIFU:单图即可重建高质量3D人体模型
[3]来自 InstantX 团队的研究人员提出了 InstantID,该模型不训练文生图模型的 UNet 部分,仅训练可插拔模块,在推理过程中无需 test-time tuning,在几乎不影响文本控制能力的情况下,实现高保真 ID 保持。

[4]清华系创业团队生数科技开展了系列研究和产品研发,于近期联合清华大学、同济大学等高校推出全球首个基于「骨骼动画」的 4D 动画生成框架「AnimatableDreamer」,能够直接将 2D 视频素材一键转成动态立体模型(即 4D 动画),支持自动提取骨骼动作、一键转换动画效果并可通过文字输入进行个性化角色生成。

一键实景转动画,清华系初创公司全球首发4D骨骼动画框架,还能生成个性化角色
[5]GauHuman框架能够快速进行人体重建 (1~2 分钟) 和实时渲染 (高达 189 帧每秒) 。
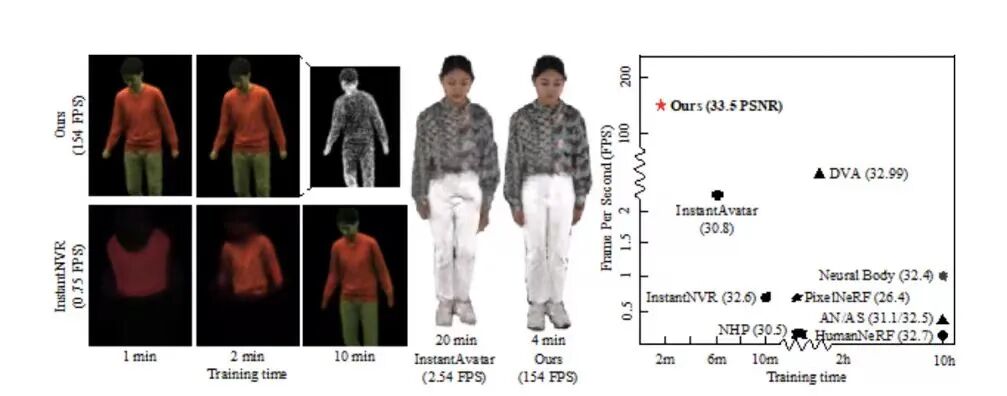
GauHuman开源:基于Gaussian Splatting,高质量3D人体快速重建和实时渲染框架
[6]国内外研究NeRF的顶级团队
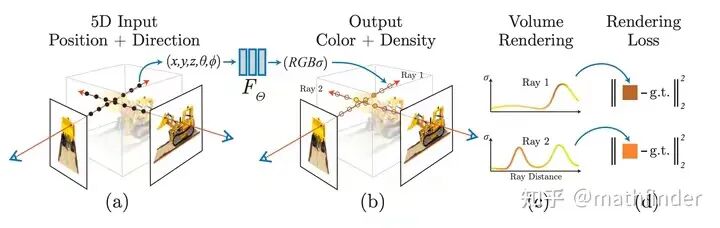
[7]Adobe 研究院和斯坦福大学等机构的研究者利用基于 transformer 的 3D 大型重建模型来对多视图扩散进行去噪,并提出了一种新颖的 3D 生成方法 DMV3D,实现了新的 SOTA 结果。

ICLR'24|Adobe提出DMV3D:3D生成只需30秒!让文本、图像都动起来的新方法!
[8]华为研究了为自动驾驶量身定制的VFMs所面临的关键挑战,同时勾勒了未来的发展方向。
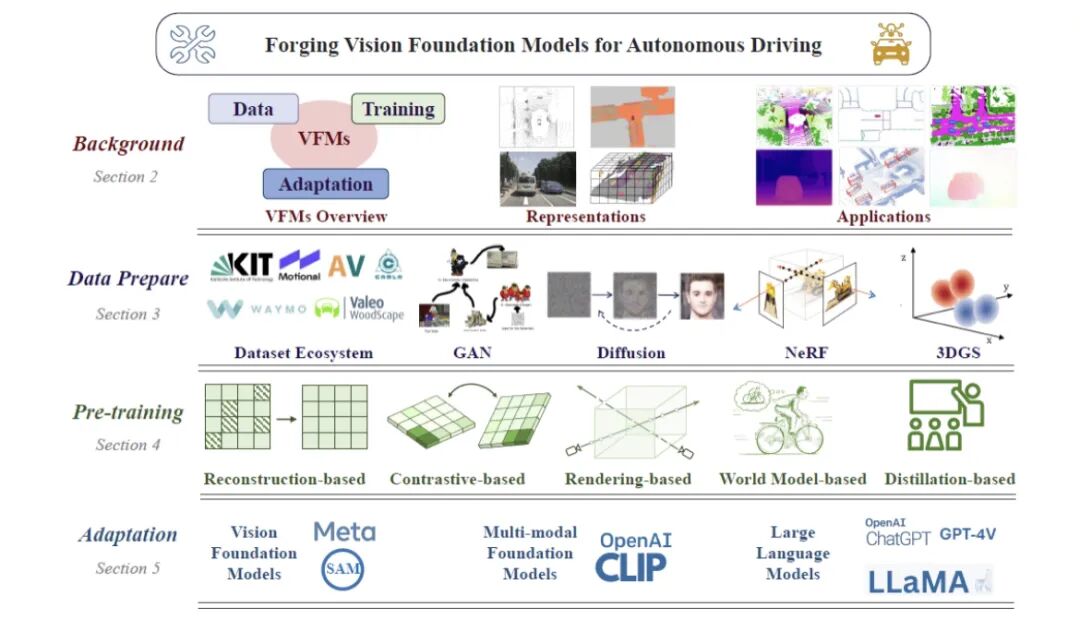
华为诺亚最新综述论文:构建自动驾驶视觉基础模型:挑战、方法和机遇
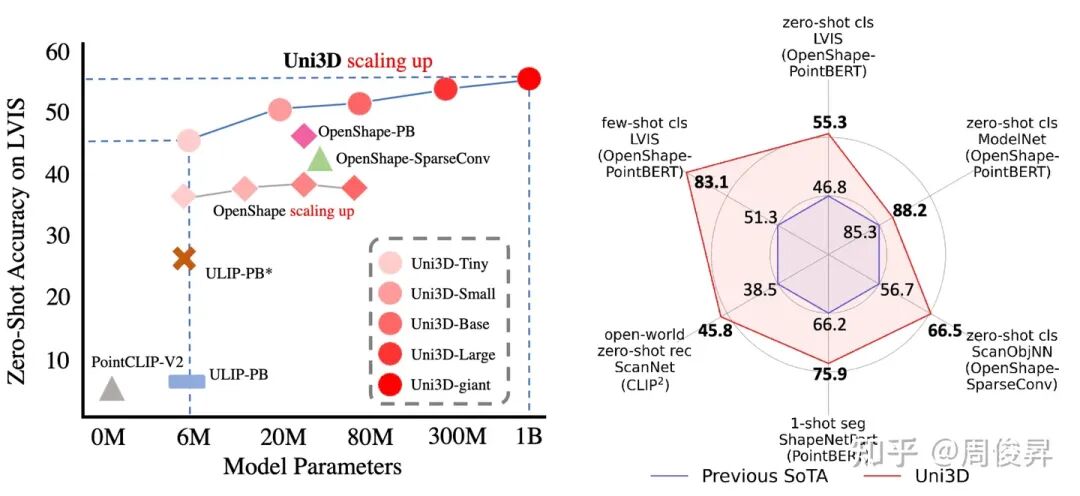
[9]我们第一次将3D基础模型成功scale up到了十亿(1B)级别参数量,并使用一个模型在诸多3D下游应用中取得SoTA结果。


















 585
585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










