




目录
10.3.1.1 强度阈值处理基础(The Basics of Intensity Thresholding)
10.3.1.2 图像阈值处理中噪声的影响(The Role of Noise in Image Thresholding)
10.3.1.3 光照和反射在图像阈值处理中的影响(The Role of Illumination and Reflectance in Image Thresholding)
10.3.2 基本全局阈值处理(Basic Global Thresholding)
10.3.3 籍Otsu法的最优全局阈值处理(Optimum Global Thresholding Using Otsu’s Method)
10.3.4 用图像平滑改善全局阈值处理(using image smoothing to improve global thresholding)
10.3.5 用边缘检测法改善全局阈值处理(using edges smoothing to improve global thresholding)
10.3.6 多阈值处理(Multiple Thresholds)
10.3.7 可变阈值处理(Variable Thresholding)
10.3.7.1 基于局部图像属性的可变阈值处理(Variable Thresholding Based on Local Image Properties)
10.3.7.2 基于移动均值的可变阈值处理(Variable Thresholding Based on Moving Averages)
10.4. 按区域增长及区域拆分和合并的分割(Segmentation by Region Growing and by Region Splitting and Merging)
10.4.2 区域拆分和合并( Region Splitting and Merging)
10.5. 基于聚类和超像素的区域分割(Region Segmentation Using Clustering and Superpixels)
10.5.1 基于k均值聚类的区域分割(Region Segmentation Using k-means Clustering)
10.5.2 基于超像素的区域分割(Region Segmentation Using Superpixels)
10.5.2.1 SLIC超像素算法(SLIC Superpixel Algorithm)
10.5.2.2 指定距离度量(Specifying the Distance Measure)
10.6. 基于切图的区域分割(Region Segmentation Using Graph Cuts)
10.6.1 以图形呈现的图像(Images as Graph)
10.6.2 最小图形剪切(Images minimum graph cuts)
10.6.3 计算最小图形剪切(Computing minimum graph cuts)
10.6.4 图割分割算法(Graph Cut Segmentation Algorithm)
10.7. 基于形态分水岭的分割(Segmentation Using Morphological Watersheds)
10.7.3 分水岭分割算法(Watershed Segmentation Algorithm)
10.8. 运动在分割中的应用(The Use of Motion in Segmentation)
10.8.1 空间域技术(Spatial Techniques)
10.8.1.1 一种基本方法(A Basic Approach)
10.8.1.2 累积差(Accumulative Differences)
10.8.1.3 建立参考图像(Establishing a Reference Image)
10.8.2 频域技术(Frequency Domain Techniques)
10.3. 阈值处理(Thresholding )
由于其直观性、易于实现且计算速度快,因此图像阈值分割在图像分割应用中占据着核心地位。阈值分割已在第3.1节中介绍,此后我们在各种讨论中都用到了它。在本节中,我们将以更正式的方式讨论阈值分割,并开发比目前为止所介绍的技术更具通用性的技术。
10.3.1 基础知识(Foundation)
上一节中,我们首先求得边缘线段,然后尝试将这些线段连接成边界,从而确定区域。本节将讨论基于强度值和/或这些值的属性直接将图像分割成区域的技术。
10.3.1.1 强度阈值处理基础(The Basics of Intensity Thresholding)
假设图 10.32(a) 中的强度直方图对应于一幅图像 f (x, y),该图像由深色背景上的浅色物体组成,物体和背景像素的强度值可以分为两个主要模式。一种显而易见的从背景中提取物体的方法是选择一个阈值 T 来区分这些模式。然后,图像中任何满足 f (x, y) > T 的点 ( x, y ) 都称为物体点。否则,该点称为背景点。换句话说,分割后的图像(记为 g (x, y))为
(10-46)
当 T 为适用于整幅图像的常数时,该公式所示的过程称为全局阈值分割。当 T 的值在图像上变化时,我们称之为可变阈值分割。有时也用局部阈值分割或区域阈值分割来表示可变阈值分割,其中图像中任意点 ( x, y ) 处的 T 值取决于 ( x, y ) 邻域的属性(例如,邻域内像素的平均强度0。如果 T 取决于空间坐标 ( x, y ) 本身,则可变阈值分割通常称为动态阈值分割或自适应阈值分割。这些术语的使用并非普遍适用。
图 10.32(b) 显示了一个更复杂的阈值问题,涉及具有三个主要模式的直方图,例如,对应于深色背景上的两种类型的浅色物体。在此,多阈值处理方法将一个点 ( x, y ) 进 行分类,若 ,将其归为背景,若
,归为一个目标类,而若
,则归为另一个目标类。即,分割图像公式为
(10-47)
其中 a、b 和 c 是任意三个不同的强度值。我们将在本节后面讨论双阈值分割。需要两个以上阈值的分割问题很难(甚至常常不可能)解决,通常使用其他方法可以获得更好的结果,例如可变阈值分割(我们将在本节后面讨论)或区域增长(我们将在 10.4 节讨论)。

--------------------------------图 10.32:强度直方图可以按 (a) 单个阈值进行划分,以及 (b) 按双阈值进行划分。---------------------------------------------------
基于前面的讨论,我们可以直观地推断,强度阈值分割的成功与分隔直方图模式的谷的宽度和深度直接相关。反过来,影响谷特性的关键因素包括:(1) 峰值之间的间隔(峰值之间的间隔越大,模式分离的可能性就越高);(2) 图像中的噪声含量(噪声越大,模式展宽);(3) 物体和背景的相对大小;(4) 照明光源的均匀性;以及 (5) 图像反射特性的均匀性。
10.3.1.2 图像阈值处理中噪声的影响(The Role of Noise in Image Thresholding)
图 10.33(a) 中的简单合成图像不含噪声,因此其直方图由两个“尖峰”模式组成,如图 10.33(d) 所示。将此图像分割成两个区域非常简单:我们只需在两个模式之间的任意位置选择一个阈值即可。图 10.33(b) 显示了原图像被均值为零、标准差为 10 个强度级别的 Gauss噪声污染后的结果。此时模式变宽了 [见图 10.33(e)],但它们之间的距离足够大,使得模式之间的谷值深度足以区分它们。将阈值设置在两个峰值的中间位置即可。图 10.33(c) 显示了用均值为零、标准差为 50 个强度级别的Gauss噪声污染图像的结果。如图 10.33( f ) 的直方图所示,情况现在更加严峻,因为无法区分这两种模式。如果不进行额外的处理(例如本节稍后讨论的方法),我们几乎不可能找到合适的阈值来分割这幅图像。
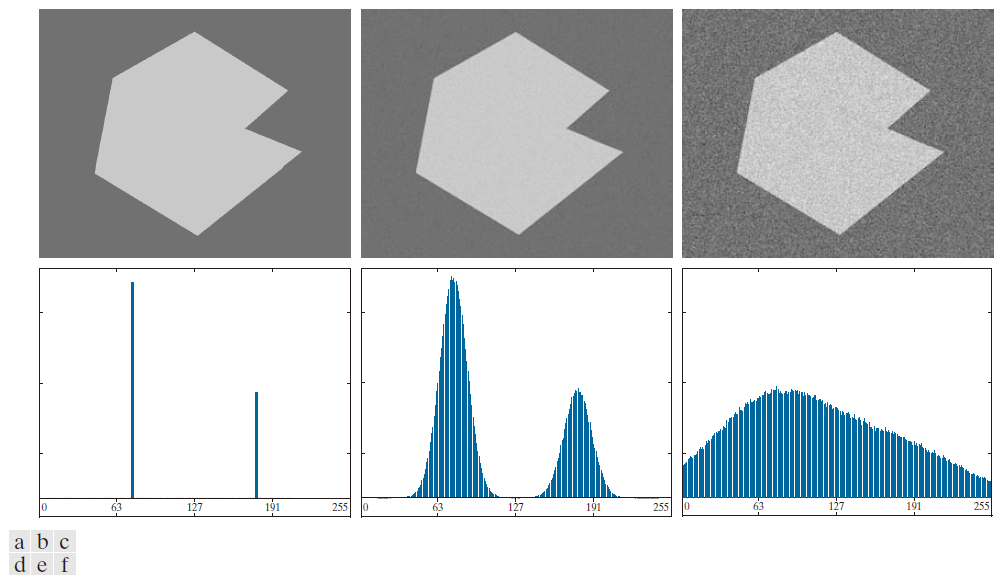
------------------------图 10.33:( a )无噪声的8位图像。( b )添加了均值为0、标准差为10个强度等级的高斯噪声的图像。( c ) 添加了均值为0、标准差为50个强度等级的高斯噪声的图像。( d )至( f )对应的直方图。------------------------------------
10.3.1.3 光照和反射在图像阈值处理中的影响(The Role of Illumination and Reflectance in Image Thresholding)
图 10.34 展示了光照对图像直方图的影响。图 10.34(a) 是图 10.33(b) 中的噪声图像,图 10.34(d) 显示了其直方图。与之前一样,该图像很容易通过单个阈值进行分割。参考 2.3 节讨论的图像形成模型,假设我们将图 10.34(a) 中的图像乘以一个非均匀强度函数,例如图 10.37(b) 中的强度斜坡,其直方图如图 10.34(e) 所示。图 10.34(c) 显示了这两个图像的乘积,图 10.34( f ) 显示了最终的直方图。峰值之间的深谷已被破坏到无法在不进行额外处理(将在本节后面讨论)的情况下分离模式的程度。如果照明完全均匀,但图像的反射率不均匀,例如由于物体表面和/或背景的自然反射率变化,也会得到类似的结果。
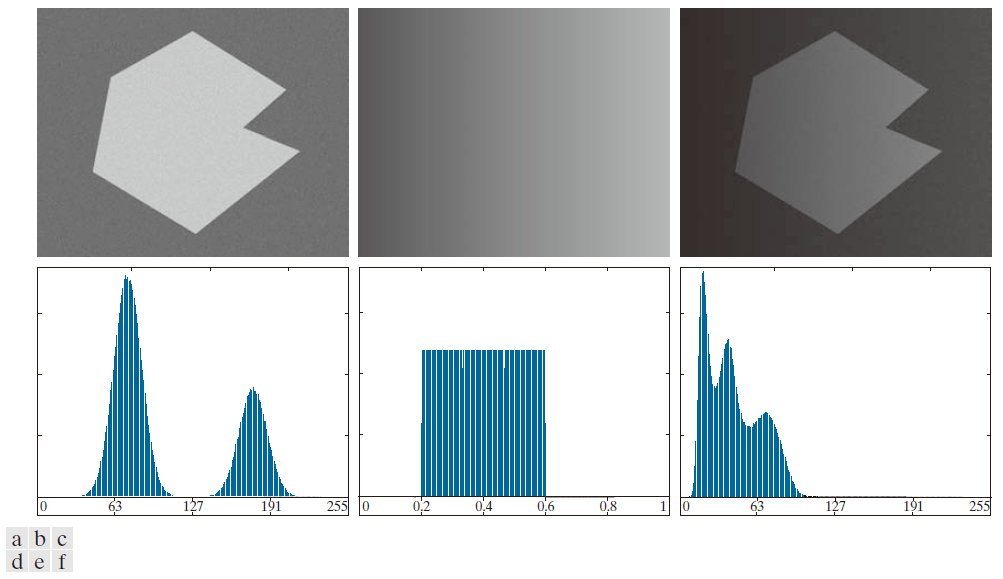
--------------------图 10.34:(a) 含噪图像。(b) 强度梯度变化范围为[0.2, 0.6]。(c) (a)和(b) 的乘积。( d )至( f )对应的直方图。--------------------------------
关键在于,光照和反射率在使用阈值分割或其他分割技术进行图像分割时起着至关重要的作用。因此,在解决分割问题时,尽可能控制这些因素应该是首要考虑的步骤。当无法控制这些因素时,有三种基本方法可以解决该问题。第一种方法是直接校正阴影模式。例如,可以通过将图像乘以模式的倒数来校正非均匀(但固定)的光照,该模式可以通过对恒定强度的平面成像获得。第二种方法是尝试通过处理来校正全局阴影模式,例如,使用第 9.8 节中介绍的顶帽变换。第三种方法是使用可变阈值来“绕过”不均匀性,这将在本节后面讨论。
10.3.2 基本全局阈值处理(Basic Global Thresholding)
当目标像素和背景像素的强度分布差异足够大时,可以使用适用于整幅图像的单个(全局)阈值。但在大多数应用中,图像之间通常存在足够的差异,因此即使全局阈值法是一种合适的方法,也需要一种能够估计每幅图像阈值的算法。以下迭代算法可用于此目的:
(1) 为全局阈值 T 选择一个初始估计值。
(2) 使用 T 按公式(10-46)分割图像。这将产生两组像素:由强度值大于 T 的像素构成的 和强度值小于 T 的像素构成的
。
(3) 分别计算 中像素和
中像素的平均强度值
和
。
(4) 计算
和
中间的新阈值:
(5) 重复步骤 2 至 4,直到连续迭代中 T 值之间的差小于预定义的值 ΔT 。
这里将算法描述为对输入图像进行逐级阈值处理并计算每一步的均值,因为这种方式更直观。然而,也可以通过将所有计算都用图像直方图来表示,从而开发出一种等效(且更高效)的方法,因为图像直方图只需计算一次(参见习题 10.29)。
上述算法适用于直方图上与目标和背景相关的众数之间存在明显分界的情况。参数 T 用于在阈值变化较小时停止迭代。初始阈值必须大于图像中的最小强度值且小于最大强度值(图像的平均强度值是 T 的一个良好初始选择)。如果满足此条件,无论模式是否可分离,算法都能在有限步内收敛(参见习题 10.30)。
例 10.13:全局阈值处理。
图 10.35 展示了使用前述迭代算法进行分割的示例。图 10.35(a) 为原图像,图 10.35(b) 为图像直方图,图中显示出一个明显的谷值。应用基本全局算法,经过三次迭代后,阈值 T 为 125。初始 T 值等于图像的平均强度,迭代次数为 T = 0。图 10.35(c) 展示了使用 T = 125 对原图像进行分割的结果。正如从直方图中清晰的模式分离所预期的那样,目标与背景之间的分割非常理想。
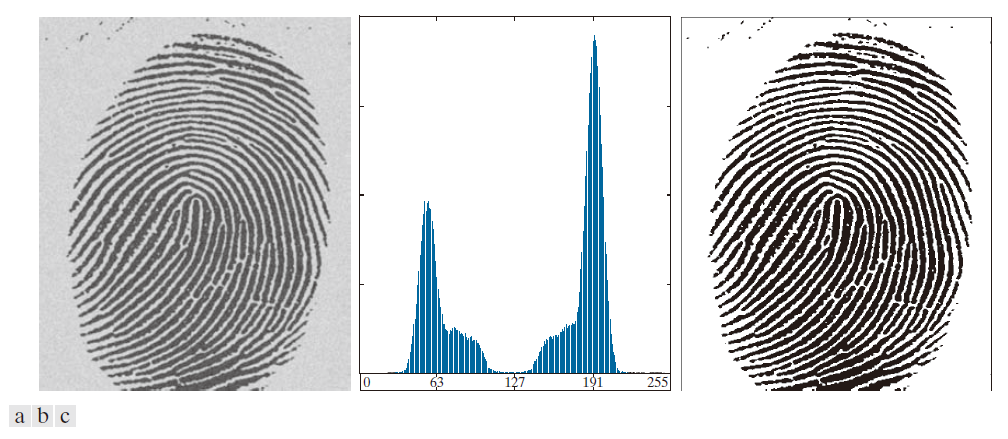
-----------------------------图 10.35:(a) 含噪指纹。(b) 直方图。(c) 使用全局阈值分割的结果(为清晰起见,添加了细图像边框)。(原图像由美国国家标准与技术研究院提供。) ---------------------------------------------------------------------
10.3.3 籍Otsu法的最优全局阈值处理(Optimum Global Thresholding Using Otsu’s Method)
阈值分割可以视为一个统计决策理论问题,其目标是最小化将像素分配到两个或多个组(也称为类别)时产生的平均误差。已知该问题存在一个简洁的闭式解,称为Bayes决策函数(参见第 12.4 节)。该解仅基于两个参数:每一个类别强度级别的概率密度函数 (PDF),和每一个类别在给定应用中出现的概率。然而,估计 PDF 并非易事,因此通常通过对 PDF 的形式做出可行的假设来简化问题,例如假设它们是 Gauss函数。即使进行了简化,使用这些假设实现解决方案的过程也可能很复杂,并且并不总是适合实时应用。
以下讨论的方法称为 Otsu 方法(Otsu [1979]),是一种很有吸引力的替代方案。该方法之所以称为最优方法,是因为它最大化了类间方差(between-class variance),这是统计判别分析中常用的一个指标。其基本思想是,经过适当阈值处理的类别应该在像素强度值上有所区别;反之,在强度值方面能够使类别间分离度最高的阈值就是最佳(最优)阈值。除了最优性之外,Otsu 方法还有一个重要的特性,那就是它完全基于对图像直方图的计算,而图像直方图是一个易于获取的一维数组(参见 3.3 节)。
令 { 0 , 1 ,2 ,.. ,L - 1 } 表示一幅大小为 M × N 像素的图像中 L 个不同整强度级别之集合,并令 表示强度为 i 的像素数。则图像中像素的总数
。正规化直方图(见 3.3 节) 具有分量
,据此可推导出
(10-48)
现在,假设我们选择一个阈值 T(k) = k ( 0 < k < L - 1 ) ,并用其将输入图像阈值化为两个类别 和
,其中,
由图像中强度值位于范围 [ 0 , k ] 中的所有像素构成,而且
由图像中强度值位于范围 [ k + 1 , L - 1] 中的所有像素构成。使用这个阈值,利用这个阈值,将一个元素归类于(即,阈值化为)一个类
的概率
由累加和给出,即
(10-49)
换言之,这是分类 出现的概率。例如,如果我们令 k = 0,则分类
包含任何像素的概率为零。类似地,类别
出现的概率为
(10-50)
根据公式 (3-25), 中像素的平均强度是
(10-51)
其中, 由公式 (10-49) 给出。公式 (10-51) 中项
是强度值 i 的概率( 假设 i 来自类
) 。这个公式第一行中最右边的项可根据 Bayes 公式推导出:
而第二行可根据 ( 已知 i 时
的概率) 是 1 推断出,因为这些我们仅处理来自
中的 i 值。此外,P( i ) 是第 i 个值的概率,其为直方图
的第 i 个分量。最后,
是类
的概率,根据公式 (10-49) , 其等于
。
类似地,归类于 的像素平均强度值是
(10-52)
关于级别 k 的累加均值(平均强度)为
(10-53)
而整幅图像的平均强度为(即,全局均值)为
(10-54)
下列两个等式的有效性可以通过直接代入前面的结果来验证:
(10-55)
和
(10-56)
为了符号清晰起见,我们暂时省略了 k 。
为了计算阈值在等级 k 处的有效性,我们使用归一化的无量纲度量
(10-57)
其中, 是全局方差[即,图像中所有像素的强度方差,如公式 (3-26)],
(10-58)
且 是类间方差,其定义为
(10-59)
这个表达式也可以写成
(10-60)
该公式的第一行由公式 (10-55),(10-56) 和 (10-59) 推导而来。第二行由公式 (10-50) 至 (10-54) 推导而来。这种形式的计算效率略高,因为全局均值 只需计算一次,所以对于任意 k 值,只需计算两个参数
和
即可 。
公式 (10-60) 的第一行表明,两个均值 和
之间的距离越远,
的值就越大,这意味着类间方差是类间可分性(separability)的度量。由于
是一个常数,因此 η 也是可分性的度量,最大化该度量等价于最大化
。因此,目标是确定使类间方差最大化的阈值 k ,如前所述。注意,公式 (10-57) 隐含地假设
。只有当图像中的所有强度级别都相同时,该方差才能为零,这意味着只存在一个像素类别。这反过来意味着,对于一个恒定的图像,有 η = 0 ,因为单个类别与其自身的可分性为零。
重新引入 k ,我们得到最后的结果:
(10-61)
和
(10-62)
则,最优阈值是使得 最大化的值
:
(10-63)
为了求得 ,我们只需对 k ( 约束条件为
) 的所有整数值计算这个公式并选择 k 的产生最大
值的值。若对 k 的一个以上的值都存在这个极大值,则通常的做法是,对使
达到极大值的各个 k 值取平均值。可以证明(参见问题 10.36),在约束条件
下,极大值总是存在的。对所有 k 值,计算公式 (10-62) 和 (10-63) 是一个相对低廉的计算过程,因为 k 可以取的整数值的最大数量为 L ,对于 8 位图像来说,L 仅为 256。
一旦求得了 , 输入图像 f (x, y) 即可按前述方式进行分割:
(10-64)
其中,x = 0 ,1 ,2 , … , M – 1 而 y = 0 ,1 ,2 , … , N – 1 。注意,计算公式 (10-62) 所需的所有量仅使用 f (x, y) 的直方图即可获得。除了最佳阈值之外,还可以从直方图中提取有关分割图像的其他信息。例如,在最佳阈值下计算的类别概率 和
表示阈值化图像中各类别(像素组)所占区域的比例。类似地,均值
和
是对原图像中各类别平均强度的估计。
一般来说,对于范围 [ 0 ,L – 1 ] 内的 k 值,公式 (10-61) 中的度量值具有范围
(10-65)
内的值。当在最优阈值 下进行计算时,该度量是对类别可分性的定量估计,进而使我们能够了解使用阈值
对给定图像进行阈值分割的准确性。公式 (10-65) 中的下界仅适用于具有单一恒定强度级别的图像。上限仅适用于强度分别为 0 和 L - 1 的二值图像( 见习题 10.37 )。
Otsu 算法可以概括如下:
(1) 计算输入图像的归一化直方图。用 ( i = 0 ,1 ,2 ,… , L – 1 )表示直方图的分量 。
(2) 利用公式 (10-49) 计算累加和 ( k = 0 ,1 ,2 ,… , L – 1 ) 。
(3) 利用公式 (10-53) 计算累加均值 m(k ) ( k = 0 ,1 ,2 ,… , L – 1 ) 。
(4) 利用公式 (10-54) 计算全局均值 。
(5) 使用公式 (10-62) 计算类间方差项 ( k = 0 ,1 ,2 ,… , L – 1 ) 。
(6) 求得使 最大的 k 值的 Otsu 阈值的
。若极大值不唯一,通过对检测到的各个极大值对应的 k 值取平均值,得到
。
(7) 使用公式 (10-58) 计算全局方差 ,然后通过携
计算公式 (10-61),从而求得可分离性度量
。
下述例子说明了这个算法过程。
例 10.14:用 Otsu 法行最优全局阈值分割。
图 10.36(a) 显示了聚合物囊泡细胞的光学显微镜图像。这些细胞是利用聚合物人工构建的。它们对人体免疫系统不可见,可用于例如:将药物递送至身体的特定区域。图 10.36(b) 显示了图像直方图。本例的目标是将分子从背景中分割出来。图 10.36(c) 是使用前面讨论的基本全局阈值分割算法的结果。由于直方图没有明显的谷值,且背景和目标之间的强度差异很小,因此该算法未能实现所需的分割效果。图 10.36(d) 显示了使用 Otsu 方法得到的结果。该结果显然优于图 10.36(c)。基本算法计算出的阈值为 169,而 Otsu 方法计算出的阈值为 182,更接近图像中定义细胞的较亮区域。可分离性度量 为 0.467。
值得注意的是,将 Otsu 方法应用于示例 10.13 中的指纹图像,得到的阈值为 125,可分离性度量为 0.944。该阈值与基本算法得到的值(四舍五入到最接近的整数)相同。考虑到直方图的特性,这并不意外。事实上,可分离性度量之所以高,是因为各模式之间的分离度相对较大,且模式之间存在较深的谷值。
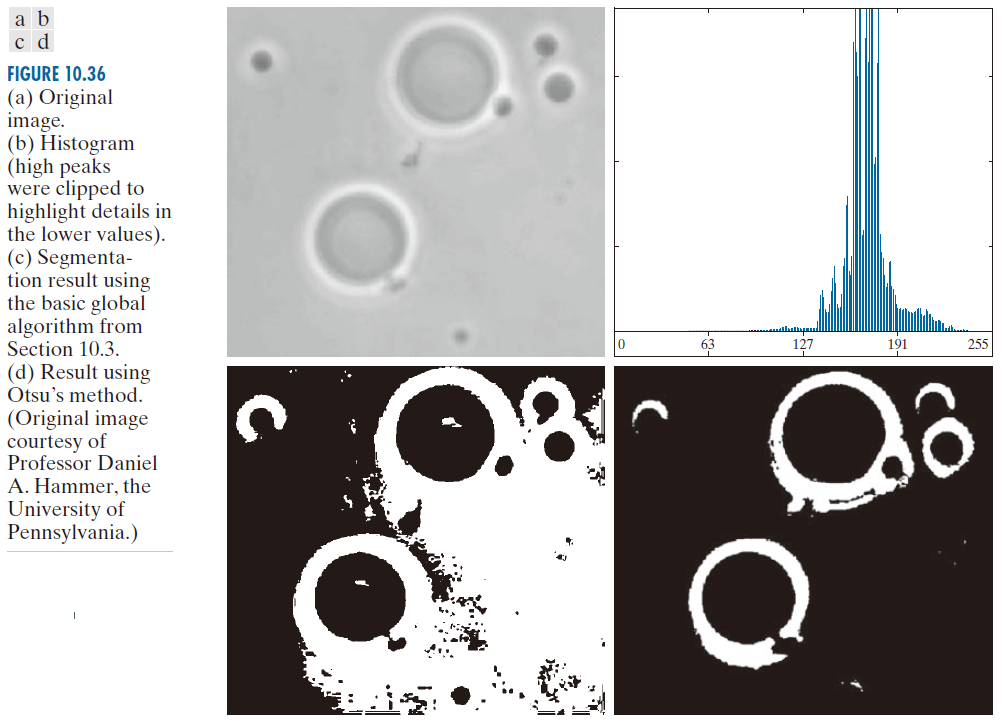
---------------图 10.36:(a) 原始图像。(b)直方图(已裁剪峰值以突出低值区域的细节)。(c) 使用第 10.3 节中的基本全局算法的分割结果。(d) 使用 Otsu 方法的结果。(原始图像由宾夕法尼亚(Pennsylvania)大学的 Daniel A. Hammer 教授提供。)--------
10.3.4 用图像平滑改善全局阈值处理(using image smoothing to improve global thresholding)
如图 10.33 所示,噪声会将简单的阈值分割问题变成无法解决的问题。当无法从源头降低噪声,且阈值分割是首选的分割方法时,一种通常可以提高性能的技术是在阈值分割之前对图像进行平滑处理。我们用一个例子来说明这种方法。
图 10.37(a) 是图 10.33(c) 中的图像,图 10.37(b) 显示了其直方图,图 10.37(c) 是使用 Otsu 阈值分割法分割后的图像。白色区域中的每个黑点和黑色区域中的每个白点都是阈值分割误差,因此分割效果很差。图 10.37(d) 显示了使用 5 × 5 的平均核对噪声图像进行平滑处理的结果(图像大小为 651 × 814 像素),图 10.37(e) 是其直方图。平滑处理后直方图形状明显改善,我们预期平滑后的图像阈值分割效果接近完美。图 10.37( f ) 证实了这一点。分割平滑后的图像中,物体与背景边界的轻微扭曲是由边界模糊造成的。事实上,图像平滑程度越高,分割结果中出现的边界误差就越大。
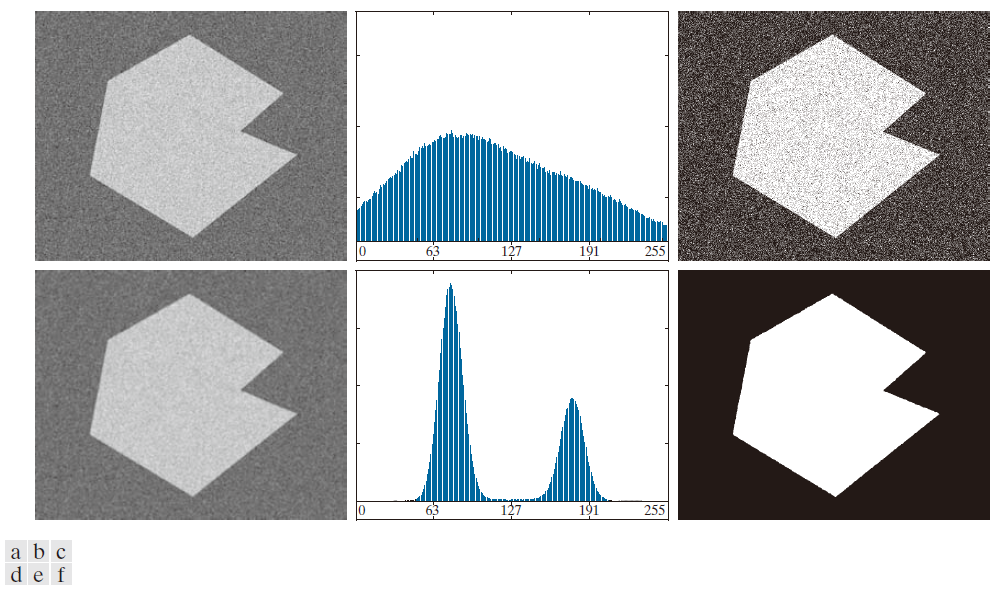
------------------------图 10.37:(a) 图 10.33(c) 中的噪声图像及其(b) 直方图。(c)使用 Otsu 方法得到的结果。(d) 使用 5 × 5 平均核平滑的噪声图像及其 (e)直方图。( f )使用 Otsu 方法进行阈值分割的结果。----------------------------------
接下来,我们研究大幅缩小前景区域相对于背景区域的影响。图 10.38(a) 显示了结果。该图像中的噪声是均值为零、标准差为 10 个强度等级的加性高斯噪声(与前一个例子中的 50 个强度等级相比)。如图 10.38(b) 所示,直方图没有明显的谷值,因此我们预期分割会失败,图 10.38(c) 的结果证实了这一点。图 10.38(d) 显示了使用 5 × 5 大小的平均核进行平滑处理后的图像,图 10.38(e) 是相应的直方图。
正如预期的那样,最终效果是减小了直方图的离散程度,但分布仍然是单峰的。如图 10.38( f ) 所示,分割再次失败。失败的原因可以追溯到该区域太小,以至于它对直方图的贡献与噪声引起的强度扩散相比微不足道。在这种情况下,下一节讨论的方法更有可能成功。
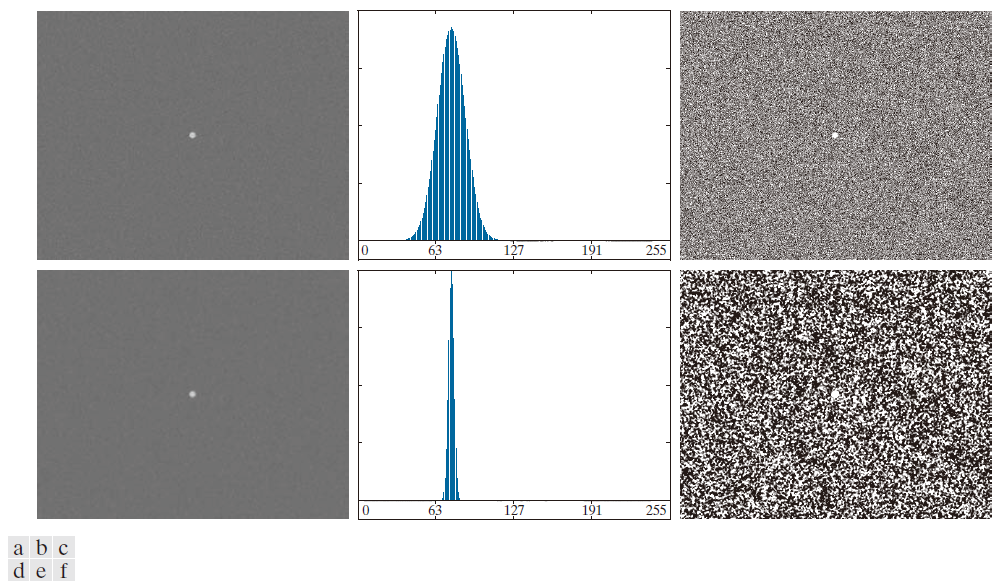
--------------------------图 10.38:(a) 含噪图像及其 (b) 直方图。(c) 使用 Otsu 法得到的结果。(d) 使用 5 × 5 平均核平滑后的含噪图像及其 (e) 直方图。(f) 使用 Otsu 法进行阈值分割的结果。两种情况下阈值分割均未能提取出目标对象。(更好的解决方案请参见图 10.39。)---------------------------------------------------------
10.3.5 用边缘检测法改善全局阈值处理(using edges smoothing to improve global thresholding)
基于目前的讨论,我们得出结论:如果直方图的峰值高而窄、对称,且被深谷隔开,则找到“良好”阈值的概率会显著提高。一种改善直方图形状的方法是仅考虑位于物体与背景边缘或边缘附近的像素。一个直接且显而易见的改进是,直方图对物体和背景相对大小的依赖性会降低。例如,如果图像中一个较小的物体位于较大的背景区域(反之亦然),则由于某种类型像素的高度集中,直方图会呈现一个较大的峰值。我们在图 10.38 中看到,这会导致阈值分割失败。
如果仅使用物体与背景边缘或边缘附近的像素,则得到的直方图峰值高度大致相同。此外,这些像素位于物体上的概率与位于背景的概率大致相等,从而改善直方图模式的对称性。最后,如下段所述,使用满足基于梯度和Laplace算子的某些简单度量的像素往往会加深直方图峰值之间的谷值。
刚才讨论的方法假设物体与背景之间的边缘是已知的。显然,在分割过程中无法获得此信息,因为分割的目的正是找到物体与背景之间的分界线。然而,可以通过计算像素的梯度或Laplace算子来判断该像素是否位于边缘上。例如,在边缘的过渡处,Laplace算子的平均值为 0(参见图 10.10),因此,由Laplace准则选择的像素形成的直方图的谷值预计会比较稀疏。这一特性往往会产生前面讨论的理想深谷。在实践中,使用梯度图像或Laplace图像通常都能获得类似的结果,后者更受青睐,因为它计算量更小,而且也是使用各向同性边缘检测器生成的。
前述讨论总结为下述算法,其中,f ( x ,y ) 是输入图像:
(1) 使用第 10.2 节中的任何方法,将 f ( x ,y ) 的梯度幅值或Laplace算子的绝对值计算为边缘图像。
(2) 指定一个阈值 T 。
(3) 使用步骤 (2) 中的阈值 T 对步骤 1 中的图像进行阈值处理,生成二值图像 。该图像在下一步中用作掩模图像,以从 f ( x ,y ) 中选择与掩模中“强”边缘像素对应的像素。
(4) 仅使用 f ( x ,y ) 中与 中值为 1 的像素位置相对应的像素来计算直方图。
(5) 使用步骤 (4) 中的直方图,例如使用 Otsu 方法,对 f ( x ,y ) 进行全局分割。
如果将 T 设置为小于边缘图像最小值的任何值,则根据公式 (10-46),g ( x ,y ) 将全部由 1 组成,这意味着 f ( x ,y ) 的所有像素都将用于计算图像直方图。在这种情况下,前面的算法就变成了使用原图像直方图的全局阈值分割。通常将 T 的值指定为一个百分位数,该值通常设置得很高(例如,90% 以上),
以便梯度/Laplace图像中只有少数像素用于计算。以下示例说明了刚才讨论的概念。第一个示例使用梯度,第二个示例使用Laplace 。使用这两种方法,两个示例都可以得到类似的结果。关键在于生成合适的导数图像。
例 10.15:用基于梯度的边缘信息来改进全局阈值分割。
图 10.39(a) 和 (b) 分别展示了图 10.38 中的图像和直方图。可以看到,该图像无法通过平滑处理后再进行阈值分割来分割。本例的目标是利用边缘信息解决该问题。图 10.39(c) 是掩模图像 ,它是通过梯度幅度图像在 99.7% 分位数处进行阈值分割得到的。图 10.39(d) 是将掩模图像与输入图像相乘得到的图像。
图 10.39(e) 是图 10.39(d) 中非零元素的直方图。请注意,该直方图具有前面讨论的重要特征;也就是说,它具有相当对称的模式,这些模式被一个深谷分隔开。因此,尽管原噪声图像的直方图表明阈值分割无法成功,但图 10.39(e) 中的直方图表明,从背景中分割出小目标确实是可行的。图 10.39(f) 的结果证实了这一点。该图像是使用 Otsu 方法生成的[基于图 10.42(e) 中的直方图获得阈值],然后将 Otsu 阈值全局应用于图 10.39(a) 中的噪声图像。结果近乎完美。
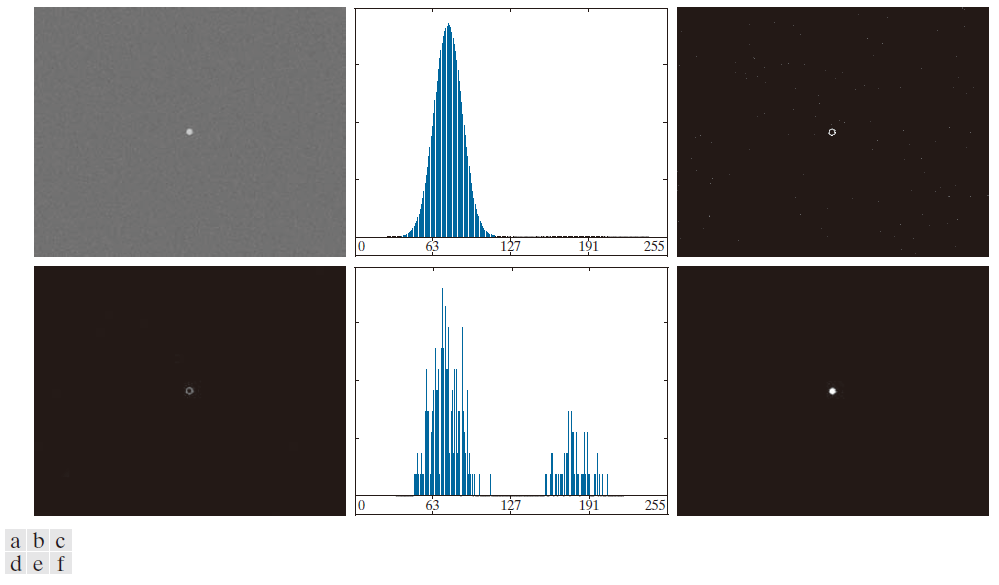
------------图 10.39:(a) 图 10.38(a) 中的噪声图像,以及 (b) 其直方图。(c) 由梯度幅值图像经 99.7% 分位数阈值处理后形成的掩模图像。(d) 由 (a) 和 (c) 相乘得到的图像。(e) (d) 中图像的非零像素直方图。( f ) 基于 (e) 中的直方图,使用 Otsu 阈值分割图像 (a) 的结果。阈值为 134,大约位于该直方图峰值的中间位置。--------------
例 10.16:用基于梯度的边缘信息来改进全局阈值分割。
在本例中,我们考虑一个更复杂的阈值分割问题。图 10.40(a) 显示了一幅 8 位酵母细胞图像,我们希望使用全局阈值分割来提取对应于亮点的区域。图 10.40(b) 显示了图像的直方图,图 10.40(c) 是基于该直方图直接对图像应用 Otsu 方法得到的结果。我们可以看到,Otsu 方法未能实现检测亮点的最初目标。尽管该方法能够分离出一些细胞区域,但右侧的几个分割区域实际上是连在一起的。Otsu 方法计算出的阈值为 42,可分离性度量值为 0.636。
图 10.40(d) 显示了掩模图像 g( x , y ),它是通过计算 Laplace图像的绝对值,然后以 T 设置为 115 的阈值,在 [0, 255] 范围内进行强度标度阈值处理得到的。该 T 值大致对应于绝对拉普拉斯图像中值的 99.5% 分位数,因此在此阈值水平进行阈值处理会得到一组稀疏的像素,如图 10.40(d) 所示。请注意,正如前面讨论所预期的,图像中的点聚集在亮点边缘附近。图 10.40(e) 是 (a) 和 (d) 乘积中非零像素的直方图。最后,图 10.40( f ) 显示了基于图 10.40(e) 中的直方图,使用 Otsu 方法对原图像进行全局分割的结果。该结果与图像中亮点的位置一致。 Otsu 方法计算出的阈值为 115,可分离性度量为 0.762,这两个值都高于使用原始直方图获得的值。
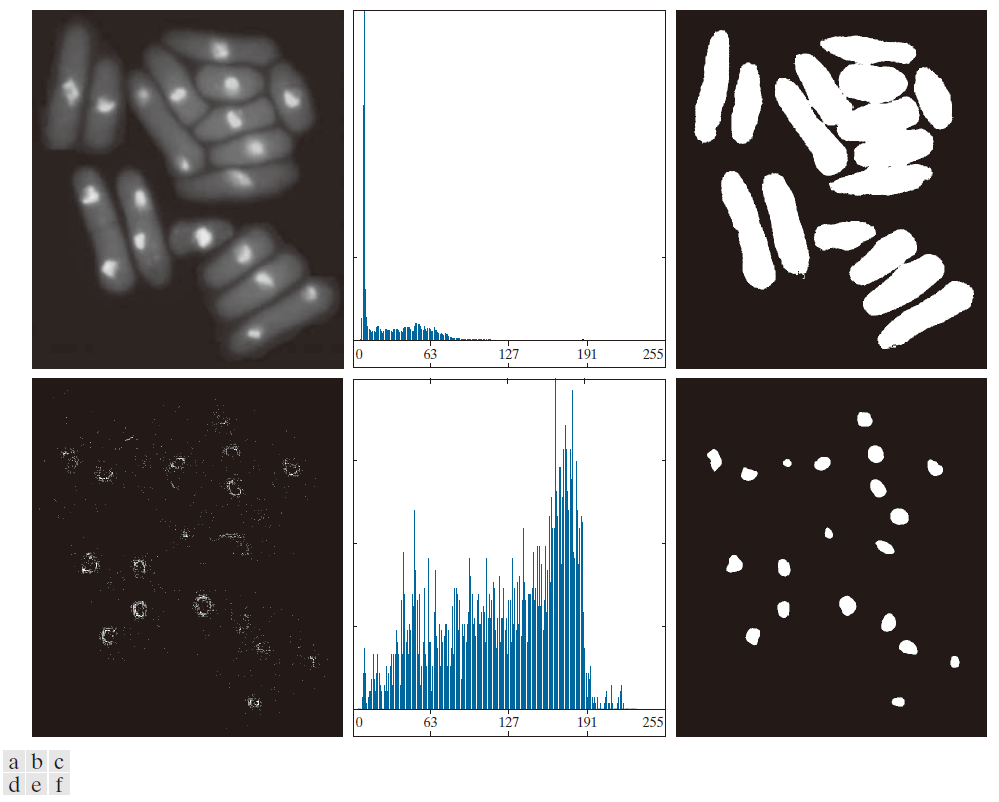
---------------------------图 10.40:(a) 酵母细胞图像。(b) (a) 的直方图。(c) 使用 (b) 中的直方图,通过 Otsu 方法对 (a) 进行分割。(d) 通过对绝对拉普拉斯图像进行阈值分割得到的掩模图像。(e) (a) 和 (d) 乘积中非零像素的直方图。(f) 基于 (e) 中的直方图,使用 Otsu 方法对原始图像进行阈值分割。(原图像由南加州大学 Susan L. Forsburg 教授提供。) ----------------------------------------------------------
通过改变阈值设置的百分位数,我们甚至可以改进整个细胞区域的分割效果。例如,图 10.41 显示了使用与上一段相同步骤但阈值设置为 55 的结果,该值约为绝对Laplace图像最大值的 5% 。该值位于该图像中值的 53.9 百分位数处。显然,该结果优于图 10.40(c) 中使用 Otsu 方法和原图像直方图得到的结果。

----------------图 10.41:图 10.40(a) 中的图像采用与图 10.40(d) 至 ( f ) 中解释的相同程序进行分割,但使用较低的值对绝对Laplace图像进行阈值处理。-------------
10.3.6 多阈值处理(Multiple Thresholds)
到目前为止,我们主要关注的是使用单个全局阈值的图像分割。Otsu 方法可以扩展到任意数量的阈值,因为它所基于的可分离性度量也可以扩展到任意数量的类别(Fukunaga [1972])。在 K 个分类 的情况下,类间方差推广到表达式
(10-66)
其中,
(10-67)
和
(10-68)
如前, 是公式 (10-54) 给出的全局均值。K 个分类由 K – 1 个阈值分隔,其值
是最大化公式 (10-66) 的值:
(10-69)
尽管该结果适用于任意数量的类别,但随着类别数量的增加,其意义开始减弱,因为我们只处理一个变量(强度)。事实上,类间方差通常用多个变量表示,这些变量以向量的形式呈现(Fukunaga [1972])。在实践中,当有理由相信问题可以用两个阈值有效解决时,使用多个全局阈值认为是一种可行的方法。需要两个以上阈值的应用通常不仅仅使用强度值。相反,这种方法是使用额外的描述符(例如颜色),并将应用转化为模式识别问题,正如你将在稍后关于多变量阈值的讨论中了解到的那样。
对于由三个强度区间(由两个阈值分隔)组成的三个类别,类间方差由下式给出:
(10-70)
其中,
(10-71)
和
(10-72)
如公式 (10-55) 和 (10-56) 所示,下列关系成立:
(10-73)
和
(10-74)
我们从公式 (10-71) 和 (10-72) 可以看到,P 和 m ( 从而有 ) 是
和
的函数。这两个最优阈值
和
是最大化
的值。即, 如公式 (10-69) 所表明的那样,我们通过
(10-75)
而求得最优阈值。该过程首先选择 的第一个值(该值为 1,因为在强度为 0 处寻找阈值没有意义;此外,请记住,增量值是整数,因为我们处理的是整数强度值)。接下来,在大于
小于 L – 1 的范围内递增
( 即
)。 然后,
递增到下一个值,且
再次在大于
的范围递增。重复这个过程直到
。这个计算过程的结果是一个二维数组
。最后一步是按这种方式求得极大值。与数组中那个极大值对应的
和
值是那个阈值
和
。若存在几个极大值,则相应的
和
值是所获得的最终阈值的平均。从而阈值计算公式为
(10-76)
其中,a ,b 和 c 是三个不同的强度值。
最后,前面针对一个阈值定义的可分离性度量可以直接推广到多个阈值:
(10-77)
其中, 是来自公式 (10-58) 总图像方差。
例 10.17:多全局阈值处理。
图 10.42(a) 显示了一张冰山图像。本例的目标是将图像分割成三个区域:深色背景、冰山的亮部和阴影部分。从图 10.42(b) 的图像直方图可以看出,需要两个阈值才能解决这个问题。上述步骤得到的阈值为 ,
,如图 10.45(b) 所示,这两个阈值接近直方图两个谷值的中心。图 10.42(c) 是使用公式 (10-76) 中的这两个阈值得到的分割结果。可分离性指标为 0.954。本例效果如此理想的主要原因是直方图具有三个不同的峰值,这些峰值之间由相当宽且深的谷值分隔开来。但是,正如你将在 10.5 节中看到的那样,我们可以使用超像素来获得更好的效果。
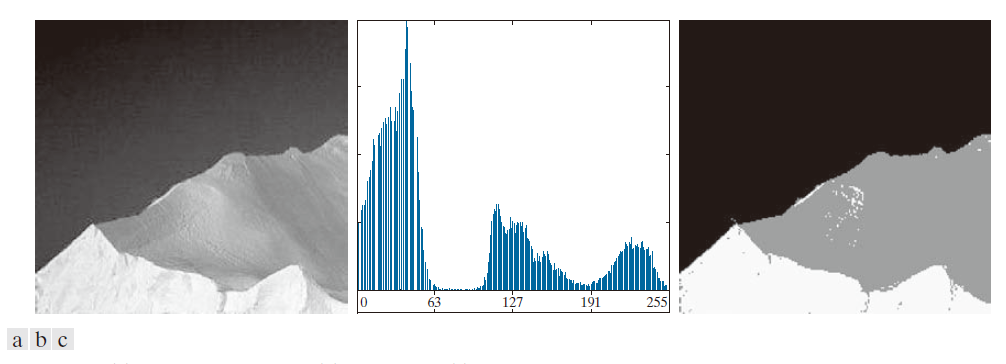
------------------------图 10.42:(a) 冰山图像。(b)直方图。(c) 使用双 Otsu 阈值分割成三个区域的图像。(原图由 NOAA 提供。) --------------------------------
10.3.7 可变阈值处理(Variable Thresholding)
如本节前文所述,噪声和非均匀光照等因素对阈值算法的性能起着至关重要的作用。我们已经证明,图像平滑和边缘信息的利用可以显著改善图像质量。然而,有时这类预处理方法要么不切实际,要么无法有效改善图像质量,以至于目前讨论的任何处理阈值方法都无法解决问题。在这种情况下,我们将采用更高层次的阈值处理方法——可变阈值法,我们将在下文中进行阐述。
10.3.7.1 基于局部图像属性的可变阈值处理(Variable Thresholding Based on Local Image Properties)
我们以图像中每一个点附近像素值的均值和标准差为例来说明这种方法。这两个量对于确定局部阈值非常有用,因为正如你在第三章中所了解的,它们分别描述了平均强度和对比度。令 和
分别表示一幅图像中中心位于坐标 ( x ,y ) 一个领域
中像素值之集合的均值和标准偏差(关于局部均值和标准差的计算,请参见第 3.3 节)。下述公式是基于局部图像属性的可变阈值处理之通式:
(10-78)
其中,a 和 b 是非负常量,和
(10-79)
其中, 是全局图像均值,则分割图像公式为
(10-80)
其中,f (x, y) 是输入图像。这个公式针对图像中所有像素进行计算,而一个不同的阈值利用领域 中的像素在每一个位置 ( x ,y ) 处进行计算。通过使用基于在点 ( x ,y ) 邻域内计算的参数的谓词,可以显著提高变量阈值处理的性能(计算量仅略有增加):
(10-81)

其中,Q是一个谓词(译注:即通过判断得出真假结果的表达式),其基于使用领域 内的像素进行计算的参数。例如,考虑下面的谓词
,其基于局部均值和标准偏差:
(10-82)
注意,公式 (10-80) 是公式 (10-81) 的一种特殊情况,其求取方式为:若 ,令 Q 为 TRUE ,否则,令 Q 为 FALSE 。在这种情况下,谓词仅基于某一点处的强度值。
例 10.18:基于局部图像属性的可变阈值处理。
图 10.43(a) 展示了例 10.16 中的酵母图像。该图像具有三个主要的强度级别,因此可以合理地假设双阈值分割可能是一种有效的分割方法。图 10.43(b) 展示了使用公式 (10-76) 中总结的双阈值分割方法的结果。如图所示,该方法能够将明亮区域与背景分离,但图像右侧的中灰色区域并未被正确分割(即分离)。为了说明局部阈值分割的应用,我们使用 3 × 3 的邻域计算了输入图像中所有 ( x, y ) 的局部标准差 。图 10.43(c) 展示了结果。请注意,较浅的外轮廓线正确地勾勒出了细胞的边界。接下来,我们构建了一个如公式 (10-82) 所示的谓词,但使用全局均值代替了
。当背景几乎恒定且所有物体强度均高于或低于背景强度时,选择全局均值通常能获得更好的结果。使用 a = 30 和 b = 15 这两个值来完成谓词的指定(这些值是通过实验确定的,这在类似应用中很常见)。然后使用公式 (10-82) 对图像进行分割。如图 10.43(d) 所示,分割效果相当不错。尤其值得注意的是,所有外部区域都得到了正确分割,并且大多数内部较亮的区域也得到了正确的分离。
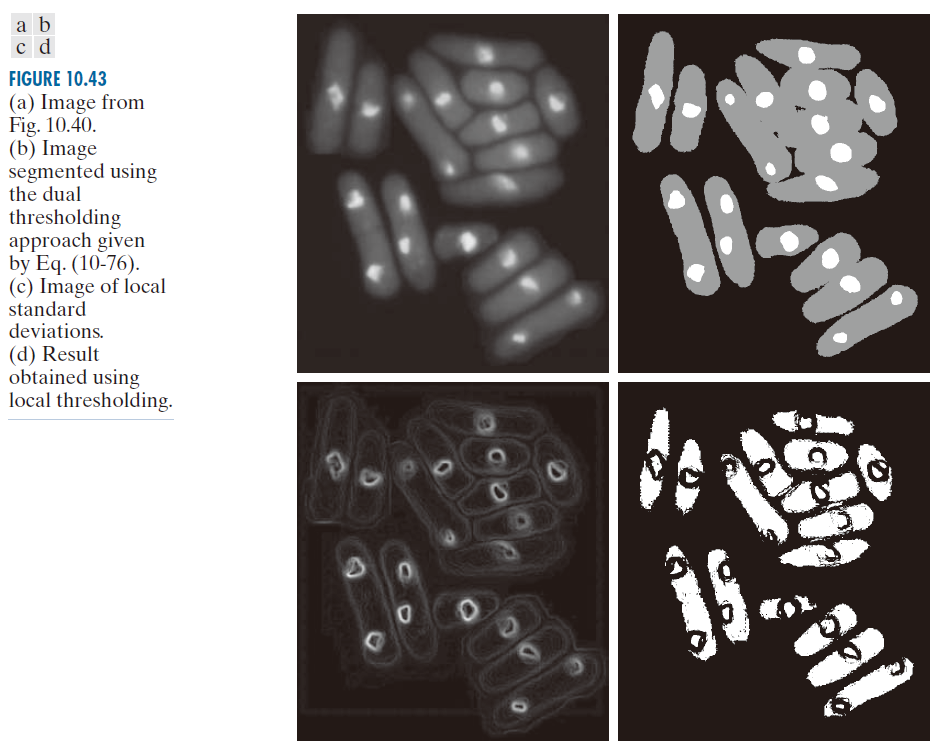
-------------------------图 10.43:(a) 图 10.40 中的图像。(b) 使用公式(10-76)给出的双阈值分割方法分割的图像。(c) 局部标准差图像。(d) 使用局部阈值分割得到的结果。------------------------------------------------------------------------
10.3.7.2 基于移动均值的可变阈值处理(Variable Thresholding Based on Moving Averages)
上一节讨论的可变阈值法的一个特例是基于计算图像扫描线上的移动平均值。这种方法适用于文档处理等对速度要求极高的应用。扫描通常以锯齿形逐行进行,以减少光照偏差。令 表示在 k + 1 步扫描序列中遇到的这个点的强度。则在这个新点处的移动均值(平均强度值)为
(10-83)
其中,n 是用于计算均值的点数,且 。施加到 k 上的条件是使得
的所有下标是正数。这意味着必须有 n 个点可用于计算平均值。当 k 小于所示限值时(这种情况发生在图像边界附近),平均值将使用可用的图像点计算。由于图像中的每一个点都会计算移动平均值,因此分割是使用公式 (10-80) 实现的,其中
,c是一个正标量,而
为使用公式 (10-83) 计算得到的输入图像中点 ( x, y ) 处的移动平均值。
例 10.19:使用移动平均法进行文档阈值处理。
图 10.44(a) 显示了一幅手写文本图像,其阴影由点状强度图案构成。这种强度阴影形式是使用点光源(例如摄影闪光灯)拍摄的图像的典型特征。图 10.44(b) 是使用 Otsu 全局阈值分割法进行分割的结果。全局阈值分割法无法克服强度变化并不意外,因为当感兴趣区域嵌入非均匀照明场中时,该方法通常表现不佳。图 10.44(c) 显示了使用移动平均进行局部阈值分割的成功结果。对于书写材料的图像,一个经验法则是将 n 设置为平均笔画宽度的五倍。在本例中,平均宽度为 4 像素,因此我们在公式 (10-83) 中令 n = 20,并使用 c = 0.5 。

------------------图 10.44:(a) 受局部阴影影响的文本图像。(b)使用 Otsu 方法进行全局阈值分割的结果。(c)使用移动平均法进行局部阈值分割的结果。----------------
为了进一步说明这种分割方法的有效性,我们使用与上一段相同的参数对图 10.45(a) 中的图像进行分割。该图像受到正弦强度变化的影响,这种变化通常是由于文档扫描仪电源接地不良造成的。如图 10.45(b) 和 (c) 所示,分割结果与图 10.44 中的结果相当。

-------------------图 10.45:(a) 受正弦阴影影响的文本图像。(b) 使用 Otsu 方法进行全局阈值分割的结果。(c) 使用移动平均法进行局部阈值分割的结果。------------
值得注意的是,在两种情况下,使用相同的 n 和 c 值均获得了成功的分割结果,这表明该方法具有较强的稳健性(ruggedness)。一般来说,基于移动平均的阈值分割方法在目标对象相对于图像尺寸较小(或较薄)时效果良好,而打印或手写文本图像恰好满足这一条件。
10.4. 按区域增长及区域拆分和合并的分割(Segmentation by Region Growing and by Region Splitting and Merging)
正如我们在第 10.1 节中所讨论的,图像分割的目标是将图像划分成多个区域。在第 10.2 节中,我们尝试基于强度值的不连续性来寻找区域边界,从而解决这个问题;而在第 10.3 节中,我们则通过基于像素属性(例如强度值或颜色)分布的阈值来实现分割。在本节以及第 10.5 节和第 10.6 节中,我们将讨论直接寻找区域的分割技术。在第 10.7 节中,我们将讨论一种同时寻找区域及其边界的方法。
10.4.1 区域增长( Region Growing)
顾名思义,区域增长是一种根据预定义的增长标准将像素或子区域组合成更大区域的过程。基本方法是从一组“种子”点开始,然后通过在每个种子点后添加与其具有相似预定义属性(例如强度或颜色范围)的相邻像素来增长区域。
选择一个或多个起始点通常取决于问题的性质,正如我们在示例 10.20 中所示。当没有先验信息时,该过程是计算每个像素的同一组属性,这些属性最终将用于在增长过程中将像素分配到各个区域。如果这些计算的结果显示出值簇,则可以使用属性值使其靠近这些簇中心的像素作为种子点(seeds)。
相似性准则的选择不仅取决于所考虑的问题,还取决于可用图像数据的类型。例如,土地利用卫星图像的分析很大程度上依赖于彩色图像。如果没有彩色图像中固有的信息,这个问题将变得异常困难,甚至根本无法解决。当图像为单色时,必须使用一组基于强度级别和空间属性(例如矩(moments)或纹理)的描述符来进行区域分析。我们将在第11章讨论用于区域表征的描述符。
如果区域增长过程中不考虑连通性属性,仅使用描述符可能会产生误导性的结果。例如,想象一组随机排列的像素,这些像素具有三个不同的强度值。如果将具有相同强度值的像素分组形成一个“区域”,而不考虑连通性,则得到的分割结果在本讨论的语境下毫无意义。
区域增长算法的另一个问题是制定停止规则。区域增长应在不再有像素满足区域包含条件时停止。诸如强度值、纹理和颜色等条件本质上是局部的,并未考虑区域生长的“历史”。一些可以增强区域生长算法能力的附加条件包括:大小、候选像素与已增长像素之间的相似性(例如,比较候选像素的强度与已增长区域的平均强度)以及正在增长区域的形状。使用这些描述符的前提是,至少部分预期结果的模型是可用的。
令:f ( x, y ) 表示输入图像;S ( x , y ) 表示种子数组,其中种子点位置的元素为 1,其余位置的元素为 0 ;Q 表示要应用于每个位置 ( x , y ) 的谓词。假设数组 f 和 S 的大小相同。基于 8 连通性的基本区域增长算法可以表述如下。
(1) 求得 S ( x , y ) 中的所有连通分量,并将每一个连通分量简化为一个像素;将所有找到的此类像素标记为 1 。S 中的所有其他像素都标记为 0 。
(2) 形成一幅图像 ,其满足:在每一个点 ( x , y ) 处,其输入图像在这些坐标处满足一个已知的谓词 Q ,则
,否则,
。
(3) 令 g 为通过将 S 中的每一个种子点附加到 中所有与该种子点 8 连通的 1 值点而形成的一幅图像。
(4) 将图 g 中的每一个连通分量标记为不同的区域标签(例如,整数或字母)。这是通过区域增长法得到的分割图像。
下面的例子说明了该算法的运行机制。
例 10.20:通过区域增长进行分割。
图 10.46(a) 显示了一张 8 位 X 射线图像,图中显示了一个焊缝(水平暗区),其中包含多条裂纹和气孔(图像中心水平延伸的亮区)。我们通过分割缺陷焊缝区域来展示区域增长法的应用。这些分割区域可用于焊缝检测、历史研究数据库构建或自动化焊接系统控制等应用。
首先,我们需要确定种子点。根据问题的物理特性,我们知道裂纹和孔隙对X射线的衰减远小于实心焊缝,因此我们预期包含这些缺陷的区域会比X射线图像的其他部分明显更亮。我们可以通过对原始图像进行阈值处理来提取种子点,阈值设置在较高的百分位数处。图10.46(b)显示了图像的直方图,图10.46(c)显示了阈值处理后的结果,阈值等于图像强度值的99.9百分位数,在本例中为254(关于百分位数,请参见10.3节)。图10.46(d)显示了将图10.46(c)中的每个连通分量进行形态学腐蚀,最终得到一个点的结果。
接下来,我们需要指定一个谓词。在这个例子中,我们希望将满足以下条件的所有像素附加到每一个种子点:(a) 与该种子点 8 连通的像素;(b) 与该种子点“相似”的像素。使用绝对强度差作为相似度的度量,我们在每个位置 ( x, y ) 上应用的谓词是

其中 T 是指定的阈值。虽然此谓词基于强度差异并使用单一阈值,但我们可以指定更复杂的方案,其中对每个像素应用不同的阈值,并使用除差异之外的其他属性。在这种情况下,前面的谓词足以解决问题,正如本示例的其余部分所示。
从上一段可知,所有种子值均为 255,因为图像的阈值设为 254。图 10.46(e) 显示了种子值 (255) 与图 10.46(a) 之间的差异。图 10.46(e) 中的图像包含了计算每个位置 ( x , y ) 谓词所需的所有差异。图 10.46( f ) 显示了相应的直方图。我们需要一个阈值用于谓词中以建立相似性。直方图有三个主要峰值,因此我们可以首先对差异图像应用 10.3 节中讨论的双阈值技术。在这种情况下,得到的两个阈值分别为 和
,我们可以看到它们与直方图的谷值非常吻合。( 顺便提一下,我们使用这两个阈值对图像进行了分割。图 10.46( g ) 的结果表明,尽管阈值位于直方图的深谷中,但使用双阈值无法实现缺陷分割。)
图 10.46(h) 显示了仅使用 对差图像进行阈值分割的结果。黑色点表示谓词为 TRUE 的像素;其余像素则不符合谓词。这里的重要结果是,焊缝良好区域中的点不符合谓词,因此它们不会被包含在最终结果中。区域生长算法会将外部区域中的点视为候选点。然而,步骤 (3) 会拒绝这些外部点,因为它们与种子点并非 8 连通。事实上,如图 10.46(i) 所示,这一步骤得到了正确的分割结果,表明连通性是本例中的基本要求。最后,请注意,在步骤 (4) 中,我们对算法找到的所有区域使用了相同的值。在这种情况下,这样做在视觉上更可取,因为所有这些区域在本应用中都具有相同的物理意义——它们都代表孔隙。
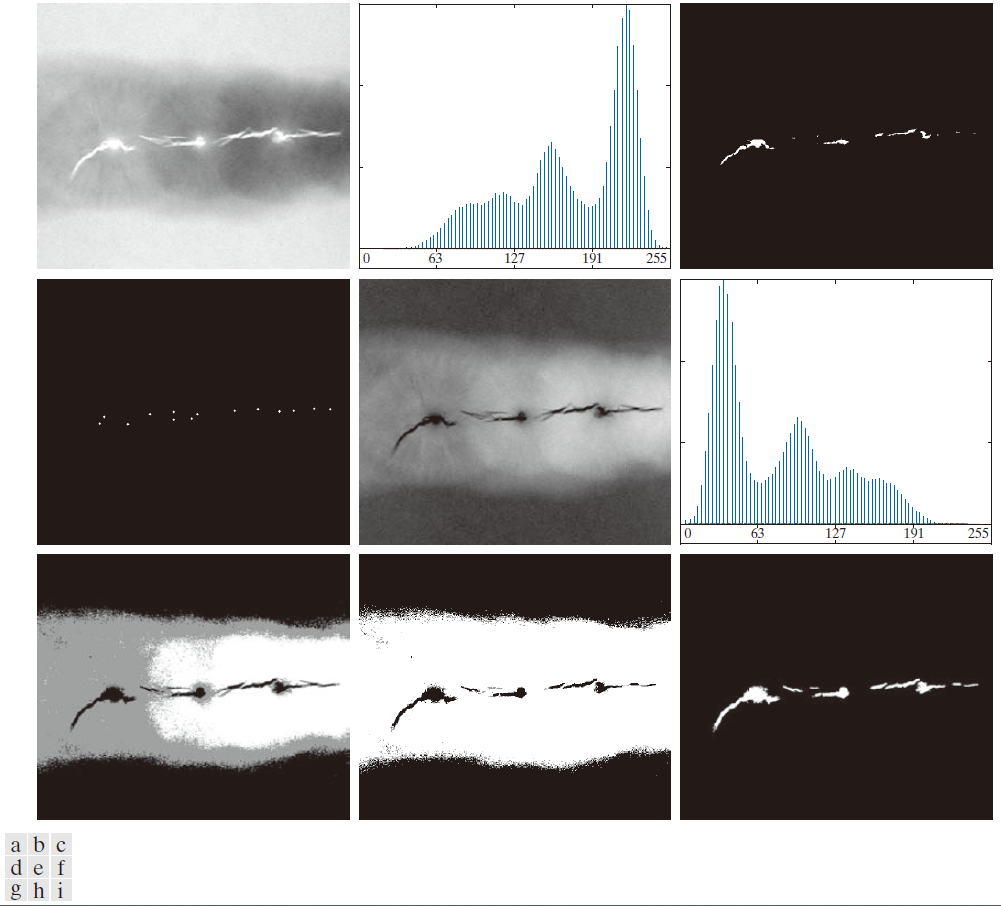
-------------------------图 10.46:(a) 缺陷焊缝的X射线图像。(b) 直方图。(c) 初始种子图像。(d) 最终种子图像(为清晰起见,图中点已放大)。(e) 种子值 (255) 与 (a) 之差的绝对值。(f) (e) 的直方图。(g) 使用双阈值分割的差值图像。(h) 使用双阈值中较小值分割的差值图像。(i) 通过区域生长法获得的分割结果。(原始图像由 X-TEK Systems, Ltd. 提供)-----------------------------------------------------------
10.4.2 区域拆分和合并( Region Splitting and Merging)
刚才讨论的方法是从种子点开始增长区域。另一种方法是先将图像细分为一组不相交的区域,然后合并和/或分割这些区域,以满足第 10.1 节中所述的分割条件。接下来将讨论区域分割和合并的基本原理。
令 R 表示整个图像区域,并选择一个谓词 Q 。分割 R 的一种方法是将其逐步细分为越来越小的象限区域,使得对于任意区域 ,
。我们从整个区域 R 开始。如果 Q(R) = FALSE ,则将图像分割成象限。如果对于任意象限,Q 为 FALSE ,则将该象限进一步细分为子象限,依此类推。这种分割技术可以用所谓的四叉树(quadtrees)来方便地表示;即,四叉树是一种每个节点恰好有四个子节点的树,如图 10.47 所示(四叉树节点对应的图像有时被称为四区域(quadregions)或四图像)。注意,树的根节点对应于整个图像,每个节点对应于一个节点被细分为四个子节点。在本例中,只有
被进一步细分。
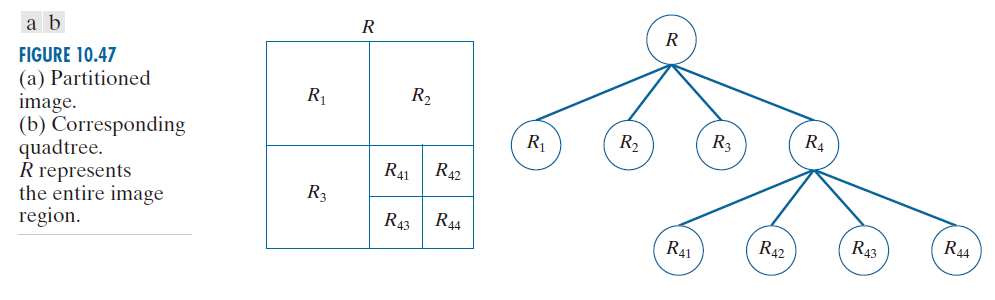
--------图 10.47:(a)分割后的图像。(b)对应的四叉树。R 代表整个图像区域。------
如果仅使用分割,最终划分的结果通常会包含具有相同属性的相邻区域。可以通过允许合并和分割来弥补这一缺陷。为了满足第 10.1 节中概述的分割约束,仅合并像素满足谓词 Q 的相邻区域。即,只有当 时,两个相邻区域
和
才会被合并。
前面的讨论可以概括为以下步骤,其中,在任何步骤中,我们
(1) 将任何区域 分割成四个不相交的象限,使得
。
(2) 当不可能进一步拆分时,合并任意满足 的邻接区域
和
。
(3) 当不可能有进一步合并时终止本过程。
基于此基本主题,可以衍生出许多变体。例如,如果在步骤 (2) 中允许合并任意两个相邻区域 和
(前提是它们各自都满足谓词),则可以显著简化算法。这样一来,算法会变得更简单(也更快),因为谓词的测试仅限于单个四边形区域。如下例所示,这种简化仍然能够产生良好的分割结果。
例 10.21:通过区域拆分和合并进行分割。
图 10.48(a) 显示了天鹅座环超新星的 566 × 566 X 射线图像。本例的目标是从图像中分割(提取)围绕致密内环的低密度物质“环”。感兴趣区域具有一些明显的特征,有助于对其进行分割。首先,我们注意到该区域的数据具有随机性,这意味着其标准差应大于背景(接近于 0 )和平滑的大中心区域的标准差。类似地,包含外环数据的区域的平均值(平均强度)应大于较暗背景的平均值,但小于较亮中心区域的平均值。因此,我们应该能够使用以下谓词来分割感兴趣区域:
其中 和
分别是被处理区域的标准偏差和均值,a 和 b 是非负常数。
对感兴趣区域外围几个区域的分析表明,这些区域像素的平均强度不超过 125,且标准差始终大于 10。图 10.48(b) 至 (d) 显示了使用这些 a 和 b 值,并将四边形区域的最小尺寸从 32 变化到 8 所得到的结果。满足谓词的四边形区域中的像素被设置为白色;该区域中的所有其他像素被设置为黑色。在捕捉外围区域形状方面,使用 16 × 16 大小的四边形区域获得了最佳结果。图 10.48(d) 中的小黑方块是 8 × 8 大小的四边形区域,其像素不满足谓词。使用更小的四边形区域会导致此类黑色区域的数量增加。使用比此处所示更大的区域会导致分割结果更像“块状”。请注意,在所有情况下,分割区域(白色像素)都是连通的,能够将内部较为平滑的区域与背景完全分隔开来。因此,分割有效地将图像划分为三个不同的区域,分别对应于图像中的三个主要特征:背景、密集区域和稀疏区域。使用图 10.48 中的任何白色区域作为掩模,都可以相对轻松地从原始图像中提取这些区域(参见问题 10.43)。与示例 10.20 类似,这些结果无法通过基于边缘或阈值的分割方法获得。
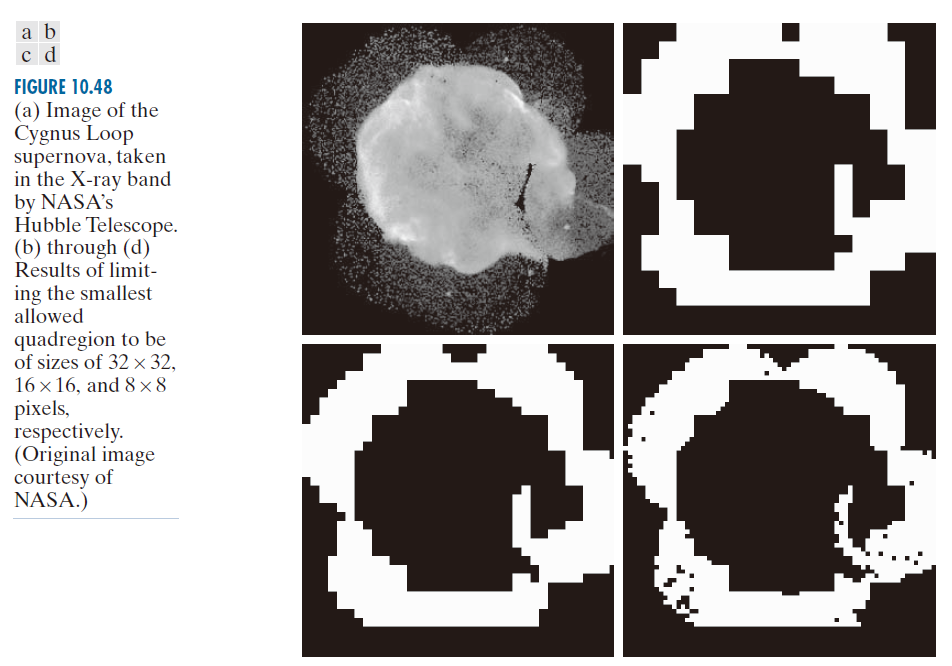
-------------------------图 10.48:(a) 天鹅座环状超新星图像,由美国宇航局哈勃望远镜在X射线波段拍摄。(b) 至 (d) 分别将最小允许四边形区域的尺寸限制为32×32、16×16和8×8像素后得到的结果。(原图由美国宇航局提供。) ---------------------
如前例所示,基于区域内像素强度均值和标准偏差的属性旨在量化该区域的纹理(有关纹理的讨论,请参见第 11.3 节)。纹理分割的概念基于在谓词中使用纹理度量。换言之,我们可以通过本节讨论的任何方法执行纹理分割,只需指定基于纹理内容的谓词即可。
10.5. 基于聚类和超像素的区域分割(Region Segmentation Using Clustering and Superpixels)
本节讨论两种相关的区域分割方法。第一种方法是经典方法,它基于在数据中寻找聚类(clusters),这些聚类与诸如强度和颜色等变量相关。第二种方法则更为现代,它基于聚类从图像中提取“超像素”。
10.5.1 基于k均值聚类的区域分割(Region Segmentation Using k-means Clustering)
本章所用聚类方法的基本思想是将观测数据集 Q 划分成指定数量 k 个簇。在 k 个均值聚类中,每一个观测值都赋予与其均值最近的簇(这也是该方法名称的由来),而每一个均值称为其所在簇的原型(prototype)。k 均值算法(k-means algorithm) 是一个迭代过程,它不断优化均值,直到收敛为止。
令 为观测(样本)向量集,这些向量具有形式
(10-84)
在图像分割中,向量 z 的每一个分量代表一个像素的数值属性。例如,如果分割仅基于灰度强度,则 z = z 是一个标量,表示像素的强度。如果我们分割的是 RGB 彩色图像,则 z 通常是一个三维向量,其每一个分量代表三种原色图像中某个像素的强度,正如我们在第 6 章中所讨论的。k均值聚类的目标是将观测值集合 Q 划分为 k 个不相交的聚类集合 ,使得满足以下最优化准则(注:记住,
是 h 关于 x 的最小值,而
是 x 在 h 最小值时的取值):
(10-85)
其中, 是集合
中样本的均值(或形心(centroid)) ,且
是参数的向量范数。通常使用 Euclid 范数,因此,项
是我们熟悉的集合
中一个样本到一个均值
的 Euclid 距离。一言以蔽之,这个公式指的是,我们感兴趣的是求得一个集合
,其使得集合中每一个点到该集合均值的距离之和最小。
遗憾的是,求得这个最小值是一个 NP 难问题,目前尚无有效的解决方案。因此,多年来人们提出了许多启发式方法来尝试求得最小值的近似值。在本节中,我们将讨论通常认为是“标准”的 k均值算法,该算法基于Euclid距离(参见第 2.6 节)。已知一个向量观察集 和一个具体的 k 值,则算法过程如下:
(1) 初始化算法:指定一个初始均值集合 ( i = 1 , 2 ,… , k ) 。
(2) 将样本赋予聚值集:将每一个样本赋予其均值最接近的这个聚值集(cluster set)(绑定关系(ties)可以任意解决,但样本只能分配到一个聚类(cluster)中)。
(3) 更新聚值中心(均值):
其中, 值是聚值集
中的样本数。
(4) 检测完成与否:计算当前步骤和前一步骤中均值向量之差的Euclid范数。将留数误差 E 计算为 k 范数之和。若 E ≤ T ,则停止,其中,T 是一个具体的非负阈值。否则,回到第 (2) 步。
当 T = 0 时,已知该算法在有限次迭代后收敛到局部最小值。但它并不能保证求得最小化公式 (10-85) 所需的全局最小值。收敛结果取决于初始值 的选择。数据分析中常用的一种方法是,从给定的样本集中随机选取 k 个样本作为初始均值,并使用新的随机初始样本集多次运行该算法。这样做是为了测试解的“稳定性”。在图像分割中,k 的值至关重要,因为它决定了分割区域的数量;因此,很少使用多次迭代。
例 10.22:使用 k 均值聚类进行分割。
图 10.49(a) 显示了一幅 688 × 688 像素的图像,图 10.49(b) 是使用 k 均值算法( k = 3 )得到的分割结果。如图所示,该算法能够高精度地提取出图像中所有有意义的区域。例如,比较两幅图像中字符的质量。需要注意的是,整个分割过程是通过对单个变量(强度)进行聚类实现的。由于 k 均值算法通常处理向量观测值,因此其区分区域的能力会随着公式 (10-84) 中向量 z 的分量数的增加而增强。

-------------------------------图 10.49:(a) 688 × 688 像素。(b)使用 k均值算法 ( k = 3 )分割的图像。-------------------------------------------------------
10.5.2 基于超像素的区域分割(Region Segmentation Using Superpixels)
超像素的基本思想是用像素分组来代替标准的像素网格,这些分组后的像素比单个像素更具感知意义。其目标是降低计算量,并通过减少无关细节来提高分割算法的性能。一个简单的例子将有助于解释超像素表示的基本原理。
图 10.50(a) 显示了一幅 600 × 800 (480,000) 像素的图像,其中包含不同层次的细节,可以用文字描述如下:“这是一幅前景中有两个大型雕刻人物的图像,以及至少三个较小的雕刻人物,它们位于大型人物后面的栅栏上。这些人物位于沙滩上,背景是海洋和天空。” 图 10.50(b) 显示了同一幅图像,该图像由 4,000 个超像素及其边界表示(边界仅供参考,并非数据的一部分),图 10.50(c) 显示了超像素图像。有人可能会认为,超像素图像的细节层次与原始图像的描述相同,但前者仅包含 4,000 个基元单元,而原始图像包含 480,000 个基元单元。超像素表示是否“足够”,取决于具体应用。如果目标是描述上述细节层次的图像,那么答案是肯定的。另一方面,如果目标是检测像素级分辨率下的缺陷,那么答案显然是否定的。在某些应用领域,例如计算机辅助医疗诊断,任何形式的近似表示都是不可接受的。然而,在许多应用领域,例如图像数据库查询、自主导航以及某些机器人技术分支,在图像分割的实现和潜在性能提升方面的成本都远远超过了图像细节的任何明显损失。
任何超像素表示的一个重要要求是保持边界清晰(adherence to boundaries)。这意味着超像素图像中必须保留感兴趣区域之间的边界。我们可以看到,图 10.50(c) 中的图像确实满足了这一要求。例如,请注意图形与背景之间的边界是多么清晰。沙滩与海洋之间、海洋与天空之间的边界也同样清晰。其他重要特性包括拓扑属性的保持以及计算效率。本节讨论的超像素算法满足这些要求。

--------------图 10.50:(a) 尺寸为 600 × 480(480,000)像素的图像。(b) 由 4,000 个超像素组成的图像( 超像素之间的边界(白色)叠加在超像素图像上仅供参考——边界不属于数据本身)。(c) 超像素图像。(原图像由美国国家公园管理局提供。)-------------
作为另一个示例,我们展示了将超像素数量大幅减少至 1000,500 和 250 的结果。图 10.51 的结果显示,与图 10.50(a) 相比,细节损失显著,但前两幅图像包含了与前面讨论的图像描述相关的大部分细节。一个显著的区别是,后方栅栏上的三个小雕刻中的两个消失了。250 像素的超像素图像甚至丢失了第三个雕刻。然而,主要区域之间的边界以及图像的基本拓扑结构都得以保留。

-------------------------图 10.51:上排:分别使用 1000,500 和 250 个超像素表示图 10.50(a) 的结果。与之前一样,为了便于参考,图像上叠加了超像素之间的边界。下排:超像素图像。--------------------------------------------------------------
10.5.2.1 SLIC超像素算法(SLIC Superpixel Algorithm)
本节讨论一种用于生成超像素的算法,称为简单线性迭代聚类(SLIC- simple linear iterative clustering)。该算法由 Achanta 等人 [2012] 开发,概念简单,并且在计算和其他性能方面优于其他超像素技术。SLIC 是上一节讨论的 k均值算法的改进版。SLIC 通常使用(但不限于)包含三个颜色分量和两个空间坐标的 5 维向量。例如,如果我们使用 RGB 颜色系统,则与图像像素关联的 5 维向量具有以下形式
(10-86)
其中,( r , g , b ) 是一个像素的三个颜色分量,而 ( x ,y ) 是其两个空间坐标。令 表示预期的超像素数量,并令
表示图像中像素总数。初始超像素中心
可能过对图像基于一个规则的每 s 单位间距的网格采样而求得。为了生成大小(即,面积)近似相等的超像素,这个网格间距的宽度选为
。为了防止将超像素中心置于图像边缘,并减少从噪声点开始的可能性,初始聚类中心被移动到每一个中心周围 3 × 3 邻域中梯度最低的位置。
SLIC超像素算法包含以下步骤。请注意,超像素通常是向量。在算法中,当我们提到“像素”时,指的是超像素相对于图像的 ( x , y) 坐标。
(1) 初始化算法:通过按规则的网格步长 s 采样图像来计算初始化超像素聚值中心
将聚值中心移到一个 3 × 3 的邻域内最低的梯度位置。对于图像中的每一个像素位置 p ,设置标签 L(p) = -1 和距离 d(p) = ∞ 。
(2) 赋予样本聚值中心:对于每一个聚值中心 , 计算
与围绕
的一个 2s × 2s 的邻域内的每一个像素 p 之间的距离
。则对于每一个
和
,若
,令
并令 L(p) = i 。
(3) 更新聚值中心:令 表示图像中 L(p) = i 的像素集。然后更新
:
其中, 是聚值集
中的像素数,而 z 由公式 (10-86) 给出 。
(4) 验证收敛性:计算当前步骤和前一步骤中均值向量之差的Euclid范数。将留数误差 E 计算为 范数之和。若 E < T (其中,T 是一个具体的非负阈值) 则转到第 (5) 步。否则,回到第 (2) 步。
(5) 后处理超像素区域:将每一个区域中的超像素 替换为其均值
。
注意步骤 (5) 中,超像素最终会形成连续的恒定值区域。平均值并非计算此常数的唯一方法,但却是最常用的方法。对于灰度图像,平均值就是超像素所覆盖区域内所有像素的平均强度。该算法与上一节中的 k均值算法类似,区别在于:距离 并非指定为 Euclid 距离(见下文),并且这些距离是针对 2s × 2s 大小的区域计算的,而不是针对图像中的所有像素计算,从而显著减少了计算时间。实际上,使用相当大的 T 值即可实现 SLIC 算法相对于 E 的收敛。例如,Achanta 等人 [2012] 报告的所有结果均使用 T = 10 获得。
10.5.2.2 指定距离度量(Specifying the Distance Measure)
SLIC 超像素对应于空间中的簇,该空间的坐标由颜色和空间变量构成。在这种情况下,使用单一的 Euclid距离是没有意义的,因为该坐标系中各轴的尺度不同且互不相关。换言之,空间距离和颜色距离必须分开处理。这可以通过对各个分量的距离进行归一化,然后将它们组合成一个单一的度量来实现。令 和
分别表示一个聚值中两个点之间的颜色和空间Euclid距离:
(10-87)
和
(10-88)
然后,我们将 D 定义为组合距离
(10-89)
其中, 和
分别是
和
的最大期望值。这个最大空间距离应当对应采样间距;即,
。 确定最大颜色距离并非易事,因为这些距离在不同的簇之间以及不同的图像之间可能存在显著差异。一种解决方法是将
设置为一个常数 c,从而使公式 (10-89) 变为
(10-90)
我们可以将这个公式写成
(10-91)
(译注:在 (10-90) 公式的两边乘以 , 再令
,即可得到 (10-91) 。)
这是算法中每一个聚类所使用的距离度量。常数 c 可用于衡量颜色相似性和空间邻近性之间的相对重要性。当 c 值较大时,空间邻近性更为重要,生成的超像素更加紧凑。当 c 值较小时,生成的超像素更紧密地贴合图像边界,但大小和形状的规则性较差。
对于灰度图像,如下述例 10.23 所示,我们在公式 (10-91) 中使用
(10-92)
其中,l 是待计算其距离的点之强度等级。
在 3 维情况下,超像素变成超体素(supervoxels),为了处理这种情况,我们定义
(10-93)
其中,z 是第三个空间维度的坐标,此外,我们必须将第三个空间维度的变量 z 加入公式 (10-86) 中的向量中。
由于算法中没有强制连通性的机制,因此收敛后可能仍存在孤立像素。这些孤立像素会使用连通分量算法(参见第 9.6 节)被赋予最近聚类的标签。虽然我们是在 RGB 颜色分量的背景下解释该算法的,但该方法同样适用于其他颜色系统。事实上,公式 (10-86) 中向量 z 的其他分量(空间变量除外)可以是其他实值特征值,前提是能够为它们定义有意义的距离度量。
例 10.23:使用超像素进行区域分割。
图 10.52(a) 显示了一张冰山图像,图 10.52(b) 显示了使用上一节开发的 k均值 算法( k = 3 ) 分割该图像的结果。虽然图像的主要区域已被分割,但在冰山的两个区域以及将其与背景分隔开的边界处都存在大量的分割错误。这些错误表现为孤立的像素(以及小的像素簇)具有错误的色调(例如,白色区域中的黑色像素)。图 10.52(c) 显示了该图像的 100 个超像素表示,并叠加了超像素边界以供参考,图 10.52(d) 显示了同一图像,但没有显示边界。图 10.52(e) 是使用 k = 3 的 k 均值算法对图 10.52(d) 进行分割的结果。注意与图 (b) 相比,结果有了显著改进,这表明原图像包含远超正确分割所需的(无关)细节。就计算优势而言,生成图 10.52(b) 需要单独处理超过 30 万个像素,而图 (e) 仅需处理 100 个像素,且灰度级少得多。

----------------------------------图 10.52:(a) 尺寸为 533 × 566(301,678)像素的图像。(b)使用 k 均值算法分割的图像。(c) 显示边界以供参考的 100 像素超像素图像。(d) 去除边界后的相同图像。(e) 使用 k 均值算法分割的超像素图像(d)。(原始图像由 NOAA 提供。------------------------------------------------------------
10.6. 基于切图的区域分割(Region Segmentation Using Graph Cuts)
在本节中,我们将讨论一种将图像分割成区域的方法,该方法首先将图像的像素表示为图的结点,然后找到图的最佳分割(切),将图分割成结点组。最佳性基于一些准则,这些准则对于同一组(即同一区域)内的成员具有较高的值,而对于不同组的成员则具有较低的值。正如你将在本节后面看到的那样,切图法分割在某些情况下能够获得优于目前研究的任何分割方法的结果。然而,这种潜在优势的代价是增加了实现的复杂性,这通常会导致执行速度变慢。
10.6.1 以图形呈现的图像(Images as Graph)
一个图形是一个数学结构,它由一个结点(nodes)集V和一个连通这些顶点(vertices)的边缘集 E 构成:
(10-94) G = ( V ,E )
其中,V 是一个集合,且
(10-95) E ⊆ V × V
是一个其元素来自 V 的一个有序对集合。若 (u ,v)∈E 意味着 (v ,u)∈E ,反之亦然,则称该图为无向图(undirected);否则,称该图为有向图(directed)。例如,我们可以将街道地图视为一个图,其中结点是街道交叉口,边是连接这些交叉口的街道。如果所有街道都是双向的,则该图是无向图(意味着我们可以从任意两个交叉口沿两个方向行驶)。否则,如果至少有一条街道是单行道,则该图是有向图。
我们感兴趣的图是无向图,其边由一个矩阵 W 进一步表征,矩阵元素 w( i , j ) 表示连接结点 i 和 j 的边的权重。由于图是无向的,w( i , j ) = w( j , i ),这意味着 W 是一个对称矩阵。权重的选择与所有结点对之间的一个或多个相似度成正比。其边缘带有权重的图称为加权图(a weighted graph)。
本节内容的核心是将待分割图像表示为一个加权无向图,其中图的结点是图像中的像素,任意两个结点之间都形成一条边。每条边的权重 w( i , j ) 是节点 i 和 j 之间相似度的函数。然后,我们将图的节点划分为若干个不相交的子集 ,其中,根据某种度量,同一子集内结点之间的相似度较高,而不同子集间结点之间的相似度较低。划分后的子集的结点对应于待分割图像中的区域。
集合 V 通过割图法划分成若干子集。图的割图法是指将 V 划分成两个子集 A 和 B ,使得
(10-96) A∪B = V 和 A∩B = ∅
其中,剪切是通过移除连接子图 A 和 B 的边来实现的。使用切图法进行图像分割有两个关键方面:(1) 如何将图与图像关联起来;(2) 如何以合理的方式切图,从而将图像分割成背景像素和前景(对象)像素。接下来,我们将探讨这两个问题。
图 10.53 展示了一种从图像生成图的简化方法。图的节点对应于图像中的像素,为了便于解释,我们仅允许相邻像素之间建立边,采用 4 连通性,这意味着像素之间不存在对角线。但请注意,通常情况下,每对像素之间都会建立边。边的权重通常由空间关系(例如,到顶点像素的距离)和强度度量(例如,纹理和颜色)构成,这与展现像素之间的相似性相一致。在这个简单的例子中,我们将两个像素之间的相似度定义为它们强度差的倒数。即,对于两个结点(像素) 和
,它们之间边的权重是
,其中,
和
是两个结点(像素)的强度,而 c 是一个常量,将其加入是为了避免除 0 的情况出现。因此,相邻像素之间的强度值越接近,w 的值就越大。
为了便于说明,图 10.53 中每一条边的粗细与其连接的像素之间的相似度成正比(参见问题 10.44)。如图所示,深色像素之间的边比深色像素和浅色像素之间的边更粗,反之亦然。从概念上讲,分割是通过沿着图的弱边切割来实现的,如图 10.53(d) 中的虚线所示。图 10.53(c) 显示了分割后的图像。
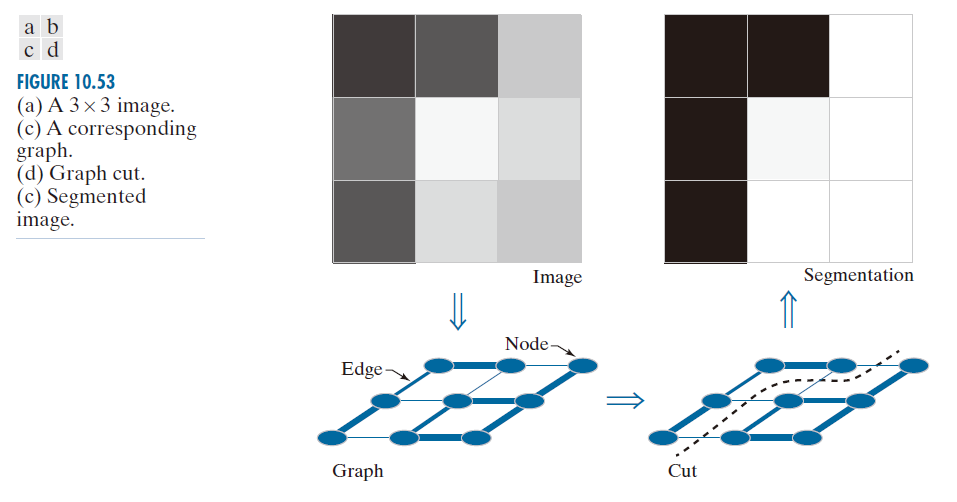
-----------------------------图 10.53:(a) 3×3图像。(c) A对应的图形。(b) 切割。(d) 分割后的图像。--------------------------------------------------------
尽管本节的讨论重点是图 10.53 中的基本结构,但为了完整起见,我们提及另一种构建图像图的常用方法。图 10.54 展示了与我们刚才讨论的相同的图,但这里多了两个结点,分别称为源终端结点和汇终端结点,它们通过称为 t 链的单向链接与图中的所有结点相连。终端结点本身并不属于图像;例如,它们的作用是为每个像素关联一个概率值,表示它是背景像素还是前景(对象)像素。这些概率值就是 t 链 的权重。在图 10.54(c) 和 (d) 中,每个 t链的粗细与其连接的图节点是前景像素还是背景像素的概率值成正比(图中所示的粗细是为了使分割结果与图 10.53 相同)。至于哪个结点被称为背景结点或前景结点,则是任意的。
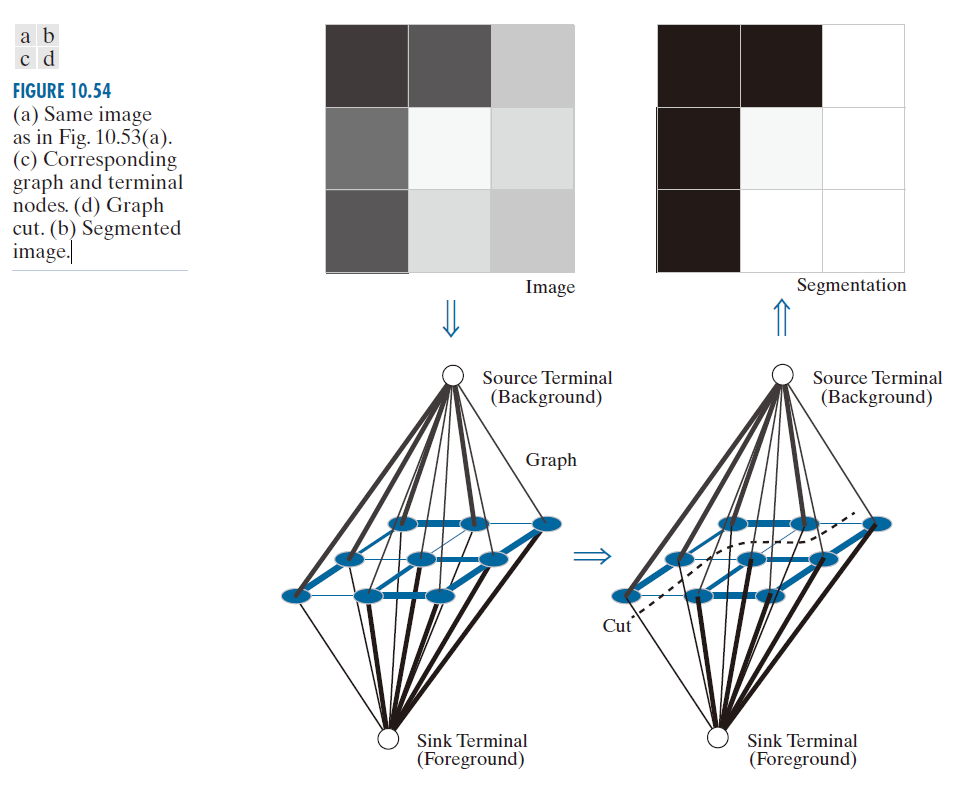
-------------------------图 10.54:(a) 与图 10.53(a)相同的图像。(c) 对应的图和终端节点。(d) 切图。(b)分割后的图像。-----------------------------------------
10.6.2 最小图形剪切(Images minimum graph cuts)
图像表示为图形之后,下一步是将该图形分割成两个或多个子图。每个子图中的结点(像素)对应于分割图像中的一个区域。基于图 10.54 的方法依赖于将图解释为流网络(例如管道网络),并获得通常所说的最小图割(minimun graph cut)。这种方法基于所谓的最大流最小割定理。该定理指出,在流网络中,从源到汇(sink)的最大流量等于最小割。最小割定义为:如果移除所有能够断开源和汇连接的边,则这些边的总权重最小:
(10-97)
其中 A 和 B 满足方程 (10-96)。图的最优划分是使该割值最小化的划分。这样的划分数量呈指数级增长,这将导致难以处理的计算问题。然而,已经开发出高效的算法,这些算法可以在多项式时间内运行,用于解决最大流问题。因此,基于最大流最小割定理,我们可以将这些算法应用于图像分割,前提是我们将分割问题转化为流问题,并选择合适的边和 t链路权重,使得图的最小割能够产生有意义的分割结果。
尽管最小割方法提供了一种简洁的解决方案,但它可能会导致分组结果倾向于切割图中少量孤立的结点,从而导致不恰当的分割。图 10.55 展示了一个例子,其中两个感兴趣的区域的特征在于像素分组的紧密程度。能够反映这一特性的有意义的边权重应该与点对之间的距离成反比。但这会导致孤立点的权重较小,从而产生如图 10.55 所示的最小割结果。事实上,任何将图中左侧的单个点分割出去的割,其在公式 (10-4) 中的割值都会小于根据点的邻近性将点正确划分为两组的割,例如图 10.55 中所示的划分。本节介绍的方法,由 Shi 和 Malik [2000] 提出(另见 Hochbaum [2010]),旨在通过重新定义切割的概念来避免这种行为。
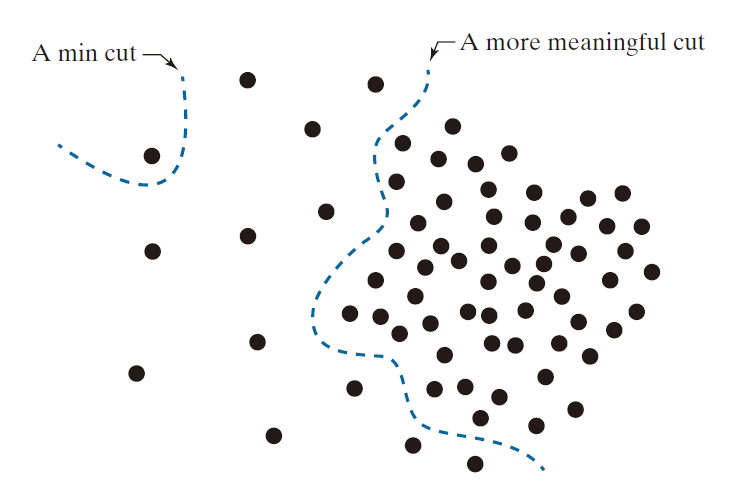
-------------图 10.55:以下示例展示了最小割方法如何导致无意义的分割结果。在本例中,像素间的相似性定义为空间邻近性,从而产生了两个截然不同的区域。------------
与其关注连接两个分区的边的总权重值,不如采用一种“分离度”度量,将成本计算为图中所有节点边连接总数的百分比。这种度量称为归一化割(Normalized cut)(Ncut),其定义如下:
(10-98)
其中, cut ( A , B ) 按公式 (10-97) 计算,而
(10-99)
是从子图 A 的结点到整个图的结点的所有边的权重之和。类似地,
(10-100)
如你所见,assoc ( A , V ) 只是将 A 从图的其余部分中分割出来,assoc ( B , V ) 也是如此。
通过使用 Ncut ( A , B ) 而不是 cut ( A , B ),分割孤立点的割将不再具有较小的值。例如,你可以在图 10.55 中看到这一点:如果 A 是所示的单个节点,则 cut ( A , B ) 和 assoc ( A , V ) 将具有相同的值。因此,无论 cut ( A , B ) 的值有多小,Ncut ( A , B ) 始终大于或等于 1,从而为此类“病态(pathological)”情况提供归一化。
基于类似的概念,我们可以定义图分割范围内总归一化关联的度量为
(10-101)
其中 assoc ( A , A ) 和 assoc ( B , B ) 分别是连接集合 A 和集合 B 内所有节点的总权重。不难证明(参见问题 10.46):
(10-102) Ncut ( A , B ) = 2 - Nassoc ( A , B)
这意味着最小化 Ncut ( A , B ) 同时也最大化了 Nassoc ( A , B) 。
基于前面的讨论,现在使用图割进行图像分割的目标是求得一个使 Ncut ( A , B ) 最小化的划分。遗憾的是,精确地最小化这个量是一个 NP 完全问题,而且我们不能再依赖最大流的现有解,因为目前采用的方法是基于图 10.53 中解释的概念。然而,Shi 和 Malik [2000](另见 Hochbaum [2010])通过将最小化问题表述为一个广义特征值问题,找到了最小化 Ncut ( A , B ) 的一个近似离散解,并且已经存在许多实现。
10.6.3 计算最小图形剪切(Computing minimum graph cuts)
同上,令 V 表示一个图 G 的结点,并令 A 和 B 为 V 的满足公式 (10-96) 的子集。令 K 表示 V 中结点的数量,并定义一个 K 维指示器(indicator)向量 x , 且若 V 的结点 在 A 中,则该向量的元素
,而结点位于 B 中,则其元素
。令
(10-103)
为 V 中从结点 到所有其它结点的权重之和。使用这些定义,我们可以将公式 (10-98) 定义为
(10-104)
目标是求得一个使 Ncut ( A , B ) 最小化的向量 x 。可以求得一个使公式 (10-104) 最小化的闭式解,但前提是 x 的元素可以是实数且连续,而不是被限制为 ±1。Shi 和 Malik [2000] 推导出的解是通过求解广义特征系统表达式
(10-105) ( D – W )y = λDy
得到的。其中,D 是一个 K × K 对角矩阵,其对角元素为 ( i = 1, 2 ,… K ) ,而 W 是一个以 w( i , j )(如早前定义)为元素的权重矩阵。求解方程 (10-105) 就得到 K 个特征值和 K 个特征向量(每一个都对应一个特征值)。我们问题的解就是对应于第二小特征值的特征向量。
我们可以将前面的广义特征值公式转化为标准特征值问题,方法是将式 (10-105) 写成如下形式(参见习题 10.45):
(10-106) Az = λz
其中,
(10-107)
和
(10-108)
据此,可推导出
(10-109)
因此,我们可以使用广义或标准特征值求解器求得对应于第二小特征值的(连续值)特征向量。所需的(离散)向量 x 可以通过从得到的连续值解向量中生成,方法是求得一个分割点,将连续特征向量元素的值分成两部分。我们通过求得使 Ncut( A, B ) 值最小的分割点来实现这一点,因为这是我们试图最小化的量。为了简化搜索,我们将连续向量中的值范围等分为 Q 个均匀分布的值,对每个值计算公式 (10-104),并选择使 Ncut( A, B ) 值最小的分割点。然后,将分割点以上的所有特征向量值赋值为 1;将所有其他值赋值为 -1。结果就是所需的向量 x 。那么,划分 A 是集合 V 中对应于 x 中值为 1 的节点;其余节点对应于划分 B 。只有当满足下一段讨论的稳定性准则时,才会执行此划分。
寻找分割点意味着计算 Ncut( A, B ) 的 Q 个值并选择最小值。如果一个区域无法使用指定的权重清晰地分割成两个子区域,通常会导致许多分割点具有相似的 Ncut( A, B ) 值。尝试分割这样的区域很可能导致无意义的划分。为了避免这种情况,只有当一个区域(即子图)满足稳定性准则时才会进行分割。该准则首先计算特征向量值的直方图,然后计算最小值与最大值的比值。对于“不确定”的特征向量,直方图中的值将保持相对稳定,并且该比值将相对较高。Shi 和 Malik [2000] 通过实验发现,将该比值阈值设为 0.06 是一个有效的准则,可以避免分割目标区域。
10.6.4 图割分割算法(Graph Cut Segmentation Algorithm)
在前面的讨论中,我们展示了两种从图像生成边缘权重的方法。图 10.53 和 10.54 展示了使用图像强度值生成的权重,图 10.55 则展示了基于像素间距离的权重。但这只是众多从图像生成图及其对应权重的方法中的两个例子。例如,我们可以使用颜色、纹理、区域的统计矩(moments)以及其他类型的特征(将在第 11 章中讨论)。总的来说,图可以由图像特征构建,像素强度是其中的一个特例。基于这个概念,我们可以将本节迄今为止的讨论总结为以下算法:
(1) 给定一组特征,定义一个加权图 G = ( V, E ),其中 V 包含特征空间中的点,E 包含图的边。计算边的权重,并用它们构造矩阵 W 和 D 。令 K 表示图的划分数。
(2) 求解特征值系统 (D - W)y = λDy ,求出第二小特征值对应的特征向量。
(3) 利用步骤 2 中的特征向量,通过求解使 Ncut( A ,B ) 最小化的分割点,将图二分。
(4) 如果剪切次数未达到 K ,则通过检查切割的稳定性来决定是否应该细分当前分区。
(5) 如有必要,递归地重新划分分割后的部分。
请注意,该算法通过递归生成双向剪切来实现。分割图像中的组(例如,区域)数量由 K 控制。其他标准,例如每次剪切允许的最大尺寸,可以进一步优化最终分割结果。例如,当使用像素及其强度作为构建图的基础时,我们可以指定每个区域允许的最大和/或最小尺寸。
例 10.24:为图割分割指定权重。
图 10.53 展示了如何使用强度值生成图权重,图 10.55 则简要讨论了如何基于像素间距离生成权重。在本例中,我们将提供一种更实用的方法来生成同时考虑强度和像素距离的权重,从而在图分割中引入邻域的概念。
令 和
表示两个节点(图像像素)。如本节前面所述,权重旨在反映图中节点之间的相似性。在考虑图像分割时,确定图像中两个像素属于同一区域或对象的可能性的主要方法之一是确定它们的强度值差以及像素之间的接近程度。当两个像素的强度和距离非常接近时(即像素“相似”),连接它们的边的权重值应该很大;随着它们强度差和距离的增加,权重值应该减小。即,权重值应该是像素强度和距离相似程度的函数。这两个概念可以通过以下表达式嵌入到一个权重函数中:
其中, 上结点
的强度,而
和
是确定两个似 Gauss 函数之延伸(spread)的常量,
两个结点之间的距离(Euclid 距离),而 r 是一个径向常数,它决定了我们考虑相似性的距离范围。指数项随着强度差的增大以及节点间距离的增大而减小,这符合我们在此情况下对相似性的度量要求。
例 10.25:利用图割进行图像分割。
图割算法非常适合对图像中的主要区域进行粗略分割。图 10.56 展示了一个典型的分割结果。图 10.56(a) 是一张常见的建筑物图像。为了与提取图像主要区域的思路保持一致,图 10.56(b) 展示了使用一个简单的 25 × 25 方框核进行平滑处理后的图像。观察图像的细节是如何被平滑掉的,只留下主要的区域特征,例如建筑物的立面和天空。图 10.56(c) 是使用刚刚开发的图割算法进行分割的结果,权重形式与前面示例中讨论的相同,并且只允许进行两次分割。注意建筑物对应的区域被很好地提取出来,没有出现本章前面讨论的方法所特有的细节。事实上,如果不进行大量的额外处理,使用我们目前讨论的任何方法几乎都无法获得类似的结果。这种结果非常适合用于以下任务:为自主导航提供广泛的线索、搜索图像数据库以及进行低级图像分析。

--------------图 10.56:(a) 尺寸为 600 × 600 像素的图像。(b) 使用 25 × 25 的盒状核进行平滑处理的图像。(c) 通过指定两个区域获得的图割分割结果。-------------
10.7. 基于形态分水岭的分割(Segmentation Using Morphological Watersheds)
到目前为止,我们已经讨论了基于三个主要概念的分割方法:边缘检测、阈值分割和区域提取。每种方法都被发现具有各自的优势(例如,全局阈值分割速度快)和劣势(例如,基于边缘的分割需要进行后处理,如边缘连接)。在本节中,我们将讨论一种基于所谓形态学分水岭概念的方法。分水岭分割融合了其他三种方法的许多概念,因此通常能够产生更稳定的分割结果,包括连通的分割边界。正如我们在本节末尾讨论的那样,该方法还提供了一个简单的框架,用于在分割过程中融入基于知识的约束(参见图 1.23)。
10.7.1 背景(Background)
分水岭的概念基于三维图像可视化,即两个空间坐标与强度的关系,如图 2.18(a) 所示。在这种“地形”解释中,我们考虑三种类型的点:(1) 属于区域最小值的点;(2) 如果将一滴水放置在这些点中的任何一个位置,水滴必定会落入同一个最小值;(3) 水滴落入多个最小值的概率相等的点。对于特定的区域最小值,满足条件 (2) 的点集称为该最小值的集水盆地(catchment basin)或分水岭。满足条件 (3) 的点在地形表面上形成脊线(crest lines),称为分水岭线(divide lines)或分水岭线(watershed lines)。
基于这些概念的分割算法的主要目标是找到分水岭线。图 10.57 可以解释实现这一目标的方法。图 10.57(a) 显示了一幅灰度图像,图 10.57(b) 是一幅地形图,其中“山峰”的高度与输入图像中的强度值成正比。为了便于理解,建筑物的背面被涂上了阴影。这与强度值无关;我们只关注三维表示的整体地形。为了防止上涨的水流从图像边缘溢出,我们设想整个地形(图像)的周边都被高于最高山峰(由输入图像中可能的最高强度值决定)的水坝包围。
假设在每个区域最小值处打孔(如图 10.57(b) 中的深色区域所示),并让水以均匀的速率从孔洞上升,从而从下方淹没整个地形。图 10.57(c) 显示了洪水的第一阶段,此时浅灰色的“水”仅覆盖了图像中与黑色背景对应的区域。在图 10.57(d) 和 (e) 中,我们可以看到水位分别上升到了第一和第二个集水盆地。随着水位继续上升,最终会从一个集水盆地溢出到另一个集水盆地。图 10.57(f) 显示了这种溢出的第一个迹象。图中,左侧集水盆地下部的水溢出到右侧集水盆地,并形成了一个短小的“水坝”(由单个像素组成),以防止水位在此高度处汇合(水坝的数学细节将在下一节中讨论)。如图 10.57(g) 所示,随着水位持续上升,这种效应更加明显。图中显示了两个集水盆地之间的一条较长的堤坝,以及右侧盆地顶部的另一条堤坝。修建后一条堤坝是为了防止该盆地的水与背景区域的水汇合。这一过程持续进行,直至达到最大洪水水位(对应于图像中的最高强度值)。最终的堤坝对应于分水岭,即所需的分割边界。图 10.57(h) 显示了该示例的结果,图中以深色、单像素粗细的路径叠加在原图像上。请注意分水岭形成连通路径这一重要特性,从而在区域之间形成连续边界。
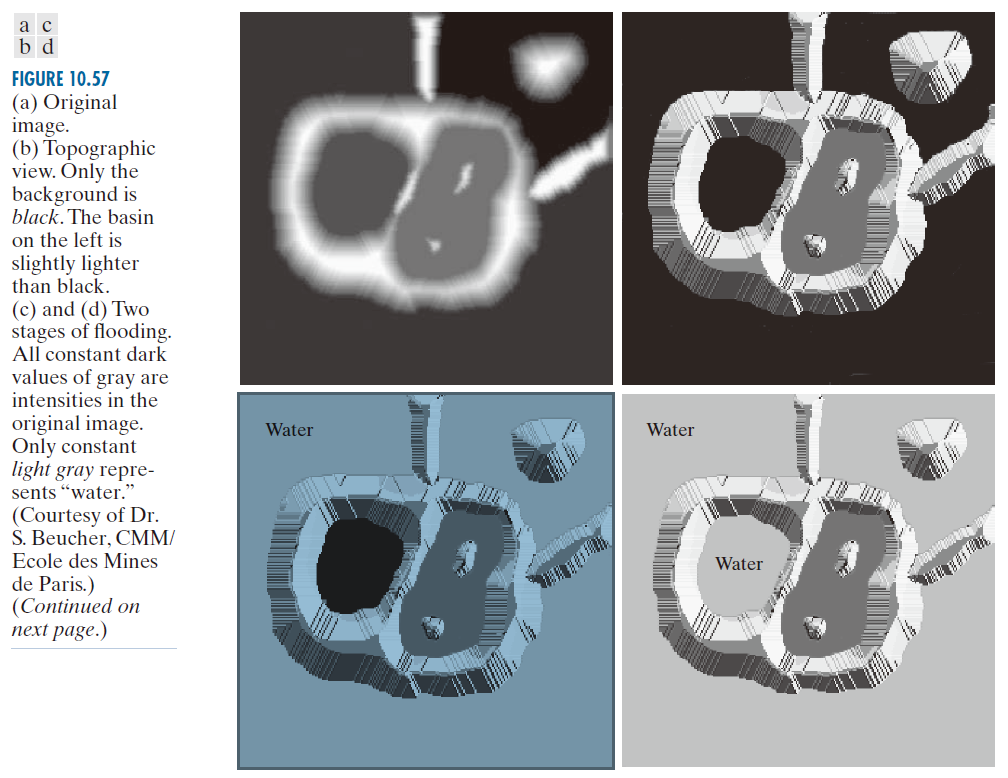
---------------图 10.57:(a) 原图像。(b) 地形图。背景为黑色。左侧盆地颜色略浅于黑色。(c) 和 (d) 洪水的两个阶段。所有深灰色均为原图像中的强度值。只有浅灰色代表“水”。(图片由巴黎矿业学院/CMM的S. Beucher博士提供。)(续下页。)-----------
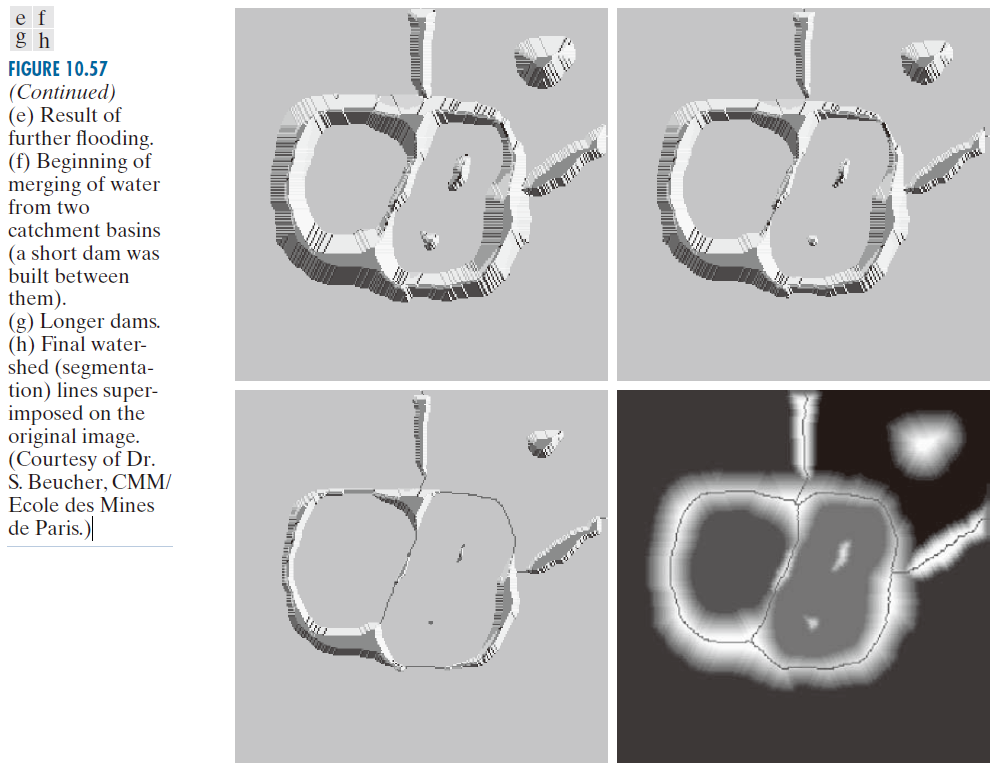
---------------图 10.57(续):(e) 进一步洪水的影响。( f ) 两个流域的水开始汇合(它们之间修建了一座短坝)。( g ) 更长的坝。( h ) 最终分水岭(分割)线叠加在原始图像上。(图片由巴黎矿业学院/CMM的S. Beucher博士提供。)(续下页。)-------------------
分水岭分割的主要应用之一是从背景中提取近乎均匀(斑点状)的目标。强度变化小的区域具有较小的梯度值。因此,在实践中,我们通常看到分水岭分割应用于图像的梯度,而不是图像本身。在这种方法中,流域的区域最小值与感兴趣的目标对应的较小梯度值密切相关。
10.7.2 大坝构造(Dam Construction)
大坝的构造基于二值图像,这些图像属于二维整数空间 (参见第 2.4 节和第 2.6 节)。构建分隔二值点集的大坝的最简单方法是使用形态学膨胀(参见第 9.2 节)。
图 10.58 展示了利用膨胀法构建水坝的基本原理。图 10.58(a) 显示了洪水阶段 n - 1 时两个流域的部分区域,图 10.58(b) 显示了下一个洪水阶段 n 的结果。水已从一个流域溢出到另一个流域,因此必须建造水坝来阻止这种情况发生。为了与稍后将介绍的符号保持一致,令 和
分别表示两个区域最小值点的坐标集合。然后,令洪水阶段 n - 1 时与这两个最小值点相关的流域内的坐标集合分别表示为
和
。这些区域在图 10.58(a) 中以灰色区域表示。
令 C[ n - 1] 表示这两个集合的并集。图 10.58(a) 中有两个连通分量,而图 10.58(b) 中只有一个连通分量。该连通分量包含了之前的两个连通分量(图中以虚线表示)。两个连通分量合并为一个连通分量表明,在洪水步骤 n 时,两个流域之间的水体已经合并。令该连通分量为 q 。注意,步骤 n - 1 中的两个连通分量可以通过对 q 进行逻辑与运算得到,即 q∈C[ n - 1] 。另请注意,属于同一流域的所有点构成一个连通分量。
假设图 10.58(a) 中的每一个连通分量都由图 10.58(c) 中的结构元素进行膨胀,并满足以下两个条件:(1) 膨胀必须限制在 q 内(这意味着结构元素的中心在膨胀过程中只能位于 q 内的点);(2) 膨胀不能在会导致被膨胀集合合并(即变成一个连通分量)的点上进行。图 10.58(d) 显示了第一次膨胀(浅灰色部分)扩展了每个原始连通分量的边界。请注意,膨胀过程中每个点都满足条件 (1),而条件 (2) 在膨胀过程中不适用于任何点;因此,每个区域的边界都被均匀地扩展了。
在图 10.58(d) 中以黑色显示的第二次膨胀中,一些点在满足条件 (2) 的同时不满足条件 (1),导致图中所示的边界断裂。显然,q 中唯一满足这两个条件的点构成了图 10.58(d) 中以交叉阴影线显示的单像素厚连通路径。这条路径是洪水阶段 n 所需的隔离坝。在该洪水阶段,通过将刚刚确定的路径上的所有点的值设置为大于图像最大可能强度值(例如,对于 8 位图像,大于 255)来完成隔离坝的构建。这将防止随着洪水水位的增加,水流越过已完成的隔离坝部分。如前所述,通过此方法构建的隔离坝(即所需的分割边界)是连通分量。换言之,该方法消除了分割线断裂的问题。
尽管刚才描述的步骤是基于一个简单的例子,但对于更复杂的情况,所采用的方法完全相同,包括使用图 10.58(c) 中的 3 × 3 对称结构元素。
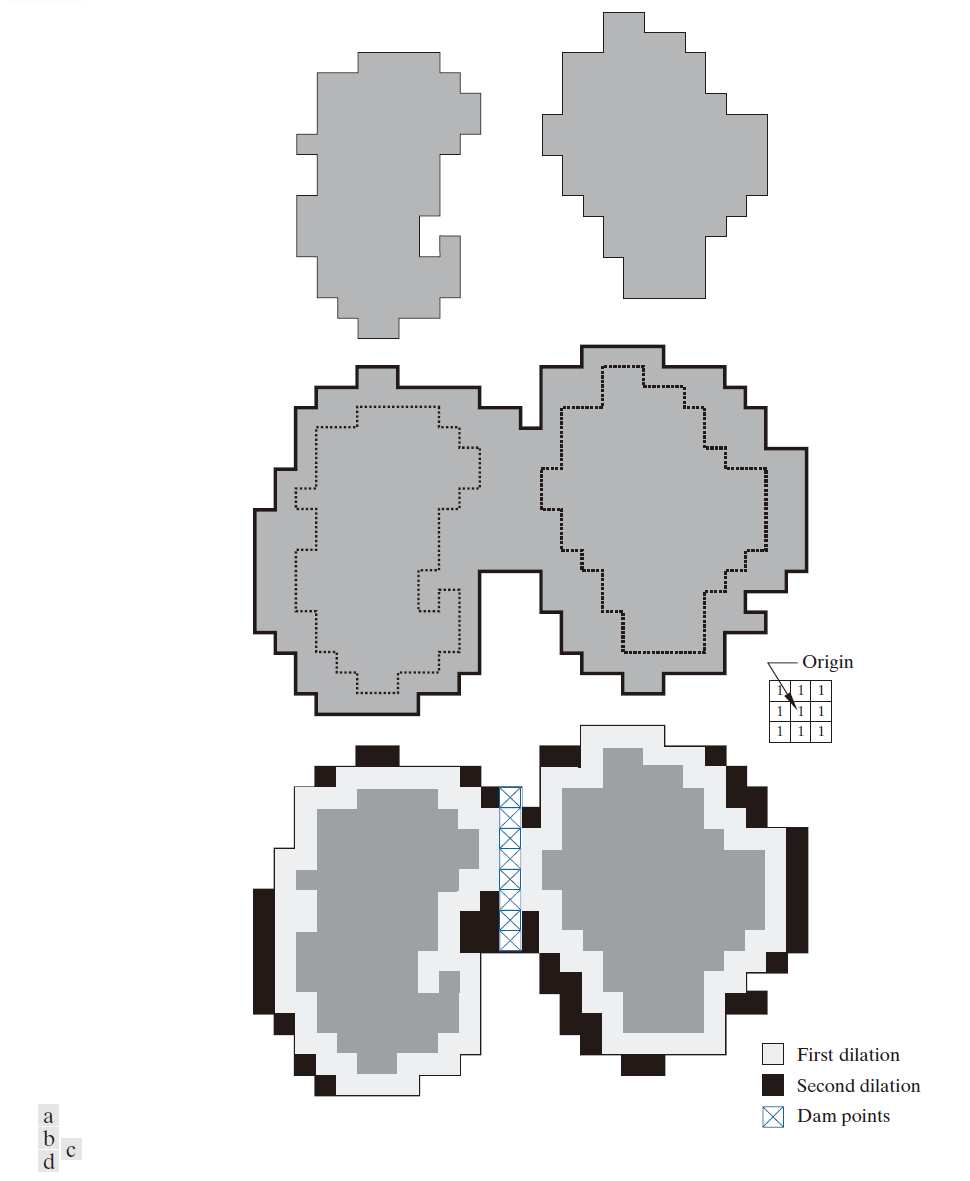
------------------------图 10.58:(a) 洪水阶段 n - 1 时的两个部分淹没的集水盆地。(b) 洪水阶段 n 时的景象,显示水已在盆地之间溢出。(c) 用于膨胀的结构构件。(d) 膨胀和大坝建设的结果。----------------------------------------------------
10.7.3 分水岭分割算法(Watershed Segmentation Algorithm)
令 为表示一幅图像 g( x ,y ) 中区域性最小值的点的坐标集。如前所述,这通常是一幅梯度图像。令
为一个集合,表示流域内与区域最小值
相关的点的坐标(回想一下,任何流域内的点都构成一个连通分量)。符号 min 和 max 将分别表示 g ( x, y ) 的最小值和最大值。最后,令 T(n) 表示满足 g ( s, t ) < n 的坐标 ( s, t ) 之集合,即
(10-110)
在几何上,T(n) 是 g( x ,y ) 中位于平面 g( x ,y ) = n 之下的点的坐标集。
地形将以整数增量进行淹没,从 n = min + 1 到 n = max + 1。在淹没过程的任意步骤 n ,算法需要知道低于淹没深度的点的数量。从概念上讲,假设 T(n) 中位于平面 g( x ,y ) = n 下方的坐标“标记为”黑色,所有其他坐标被标记为白色。那么,当我们在淹没过程的任意增量 n 向下观察 xy 平面时,我们将看到一个二值图像,其中黑点对应于函数中位于平面 g( x ,y ) = n 下方的点。这种解释非常有用,并且有助于理解接下来的讨论。
令 表示流域内与最小水位
相关的点的坐标集合,这些点在水位 n 时被淹没。参考上一段的讨论,我们可以将
视为由公式
(10-111)
计算所得的一幅二值图像。换言之,若 ,则在位置 ( x ,y ) 处有
;否则,
。这个结果的几何解释是很简单。在泛洪阶段 n ,我们只是简单地使用 AND 运算符从图像中分离出 T(n) 中与区域最小值
相关的二值图像部分。
接下来,令 B 表示阶段 n 时被淹没的流域数量,令 C[n] 表示阶段 n 时这些流域的并集:
(10-112)
则 C [ max + 1 ] 就是所有流域的并集
(10-113)
可以证明(见问题10.47), 和 T(n) 中的元素在算法执行期间永远不会被替换,且这两个集合的元素随着 n 的递增要么增长,要么保持不变。因此,可以推导出,C [n – 1 ] 是 C [n] 的一个子集。根据公式 (10-112) 和 (10-112) ,C [n] 是 T(n) 的一个子集,因此可以推导出 C [n – 1 ] 也是 T(n) 的一个子集。由此我们得到一个重要的结论:C [n – 1 ] 的每一个连通分支都恰好包含在 T(n) 的一个连通分支中。
求取分水岭线算法在初始时令 C [min + 1 ] = T [min + 1 ] 。然后,该过程递归地进行,依次计算 C [n],从 C [n – 1 ] 开始,采用以下方法。令 Q 表示 T(n) 中的连通分量集合。那么,对于每一个连通分量 q ∈Q[n],存在三种可能性:
(1) q∩C [n – 1 ] 为空。
(2) q∩C [n – 1 ] 包含 C [n – 1 ] 的一个连通分支 。
(3) q∩C [n – 1 ] 包含C [n – 1 ] 的一个以上连通分支 。
从 C [n – 1 ] 构建 C [n] 取决于这三个条件中的哪一个成立。条件 (1) 为遇到新的最小值时,此时连通分量 q 被并入 C [n – 1 ] 形成 C [n]。条件 (2) 为 q 位于某个区域最小值的集水区内时,此时 q 被并入 C [n – 1 ] 形成 C [n] 。条件 (3) 为遇到分隔两个或多个集水区的山脊(或山脊的一部分)时。进一步的洪水会导致这些集水区的水位合并。因此,必须在 q 内建造水坝(如果涉及两个以上的集水区,则需要建造多个水坝)以防止集水区之间的溢流。如前所述,必要时可以通过对 q ∩ C [n – 1 ] 进行膨胀(使用 3 × 3 的全 1 结构元素),并将膨胀限制在 q 内,来建造一个像素厚的水坝。
通过仅使用与 g(x, y) 中现有强度值相对应的 n 值,可以提高算法效率。我们可以从 g(x, y) 的直方图中确定这些值以及最小值和最大值。
例 10.26:分水岭分割算法示意图。
分别考虑图 10.59(a) 和 (b) 中的图像及其梯度。应用前面描述的分水岭算法,得到如图 10.59(c) 所示的叠加在梯度图像上的分水岭线(白色路径)。这些分割边界叠加在图 10.59(d) 的原始图像上。正如本节开头所述,分割边界具有一个重要的特性,即它们是连通的路径。
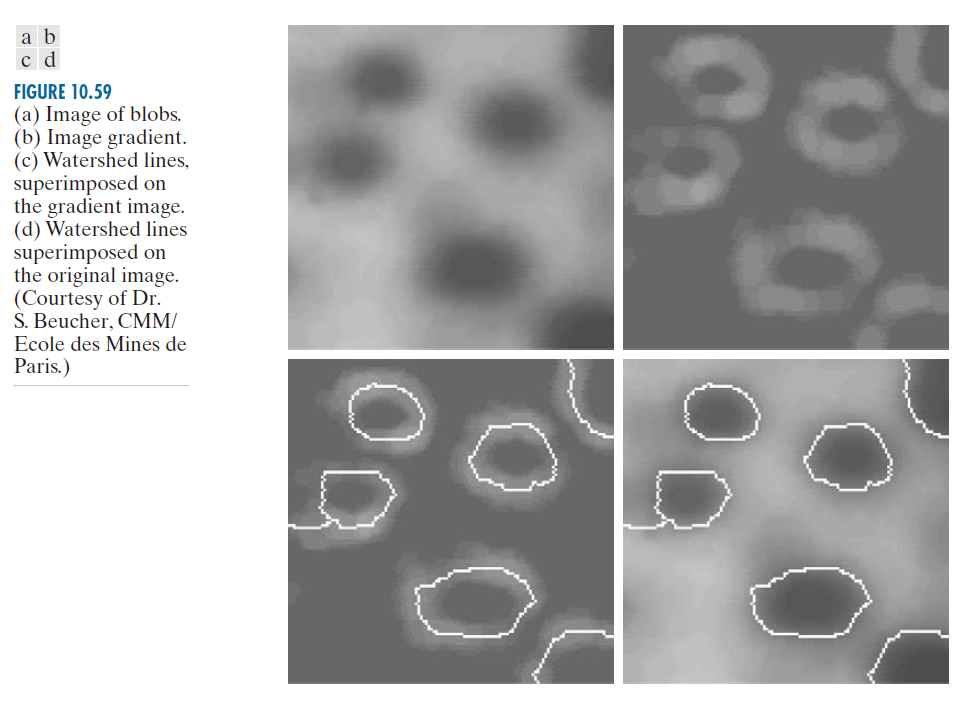
----------------------图 10.59:(a) 斑点图像。(b) 图像梯度。(c) 叠加在梯度图像上的分水岭线。(d) 叠加在原始图像上的分水岭线。(图片由巴黎矿业学院CMM的S. Beucher博士提供。) -----------------------------------------------------------
10.7.4 标记的使用(Use of Markers)
直接应用上一节讨论的分水岭分割算法通常会导致过度分割,这是由噪声和梯度其他局部不规则性造成的。如图 10.60 所示,过度分割可能非常严重,以至于算法结果几乎毫无用处。在这种情况下,这意味着分割区域的数量过多。解决此问题的一个实用方法是通过引入预处理阶段来限制允许分割的区域数量,该预处理阶段旨在将额外的信息引入分割过程。
一种用于控制过度分割的方法基于标记的概念。标记是图像中的一个连通分量。我们有与感兴趣对象相关的内部标记,以及与背景相关的外部标记。标记选择过程通常包含两个主要步骤:(1) 预处理;(2) 定义标记必须满足的一组标准。为了说明这一点,请再次考虑图 10.60(a)。导致图 10.60(b) 中过度分割结果的部分原因是存在大量的潜在极小值。由于这些极小值的尺寸较大,其中许多是无关的细节。正如之前多次讨论中指出的,最小化小空间细节影响的有效方法是使用平滑滤波器对图像进行滤波。这在本例中也是一种合适的预处理方案。

-------------图10.60:(a) 电泳图像。(b)将分水岭分割算法应用于梯度图像的结果。过度分割现象明显。(图片由巴黎矿业学院CMM的S. Beucher博士提供。)----------
假设我们将内部标记定义为:(1) 被更高“高度”点包围的区域;(2) 区域内的点构成一个连通分量;(3) 连通分量内的所有点具有相同的强度值。图像平滑后,根据此定义得到的内部标记在图 10.61(a) 中显示为浅灰色斑点状区域。接下来,在限制条件为这些内部标记是唯一允许的区域最小值的情况下,对平滑后的图像应用分水岭算法。图 10.61(a) 显示了得到的分水岭线。这些分水岭线定义为外部标记。请注意,分水岭线上的点经过相邻标记之间的最高点。
图 10.61(a) 中的外部标记有效地将图像分割成多个区域,每一个区域包含一个内部标记和一部分背景。因此,问题简化为将每一个区域分割成两部分:一个目标对象及其背景。我们可以将本章前面讨论的许多分割技术应用于这个简化的问题。另一种方法是直接对每一个区域应用分水岭分割算法。换言之,我们只需计算平滑图像的梯度(如图 10.59(b) 所示),并将算法限制在包含该特定区域中标记对象的单个分水岭上。图 10.61(b) 显示了使用这种方法得到的结果。与图 10.60(b) 相比,效果明显更好。
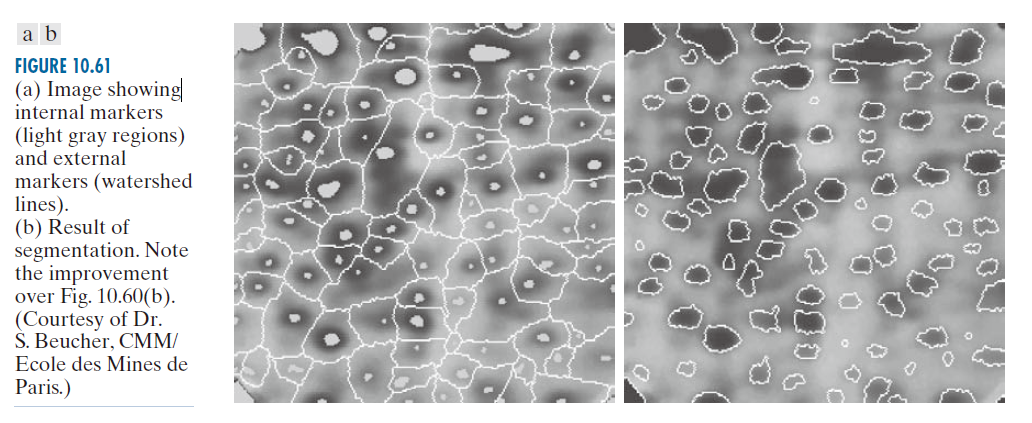
------------------------图 10.61:(a) 图像显示了内部标记(浅灰色区域)和外部标记(分水岭线)。(b) 分割结果。请注意与图 10.60(b) 相比的改进。(图片由巴黎矿业学院 CMM 的 S. Beucher 博士提供。)------------------------------------------------
标记点的选择范围很广,从基于强度值和连通性的简单方法(正如我们刚才演示的),到涉及大小、形状、位置、相对距离、纹理内容等的更复杂的描述(参见第11章关于特征描述符的内容)。关键在于,使用标记点可以将先验知识引入分割问题。请记住,人类在日常视觉中经常利用先验知识来辅助分割和更高级别的任务,其中最常见的方法之一就是利用上下文信息。因此,分水岭分割提供了一个能够有效利用此类知识的框架,这是该方法的一个显著优势。
10.8. 运动在分割中的应用(The Use of Motion in Segmentation)
运动是人类和许多动物用来从无关背景中提取目标物体或感兴趣区域的重要线索。在成像应用中,运动源于传感系统与被观察场景之间的相对位移,例如机器人应用、自主导航和动态场景分析。在接下来的讨论中,我们将探讨运动在空间域和频域分割中的应用。
10.8.1 空间域技术(Spatial Techniques)
接下来,我们将探讨两种直接在空间域中进行运动检测的方法。主要目的是让你了解如何使用一些简单的技术来测量数字图像中的变化。
10.8.1.1 一种基本方法(A Basic Approach)
检测两幅图片帧 和
之间分别在时刻
和
时的变化的最简单的方法之一是逐像素比较这两帧图像。实现这一目标的一种方法是生成差图像。假设我们有一个仅包含静止分量的参考图像。将该图像与同一场景但包含一个或多个运动物体的后续图像进行比较,得到的两幅图像的差会抵消静止分量,只留下对应于运动分量的非零值。
在时刻 和
的(大小相同的)两幅图像的差图像(a difference image)可以定义为
(10-114)
其中,T 是一个非负阈值。注意,仅当这两幅图像之间的强度差在点 ( x ,y ) 处明显不同时, 在这些空间坐标上的值为 1 ,由 T 确定。另请注意,公式 (10-114) 中的坐标 ( x ,y ) 涵盖了两个图像的尺寸,因此差图像与序列中的图像大小相同。
在接下来的讨论中, 中值为1 的所有像素视为目标运动的结果。这种方法仅适用于两幅图像在空间上配准,并且照明在 T 确定的范围内相对恒定的情况。在实践中,
中的 1 元素也可能以噪音的形式出现。通常,这些元素是差图像中的孤点,一种简单的去除方法是在图像
中形成由 4 个或 8 个元素组成的 1 区域,然后忽略元素数量少于预定值的任何区域。虽然这种方法可能会忽略一些小的或移动缓慢的物体,但它提高了差图像中剩余条目确实是运动而非噪声的概率。
虽然刚才描述的方法很简单,但它经常用作成像系统的基础,这些成像系统旨在检测受控环境中的变化,例如对停车场、建筑物和类似固定场所的监控。
10.8.1.2 累积差(Accumulative Differences)
考虑一个图像帧序列 , 并令
为参考图像。累积差图像 (ADI) 的形成方法是将参考图像与序列中的每一幅后续图像进行比较。对于累积图像中每一个像素位置的计数器,每当参考图像与序列中的某一幅图像在该像素位置出现差异时,计数器就会递增。因此,当第 k 帧与参考图像进行比较时,累积图像中给定像素的数值表示该位置的强度值与参考图像中对应像素值不同的次数 [由公式 (10-114) 中的 T 确定]。
假设运动物体的强度值大于背景,我们考虑三种类型的ADI 。令 R( x ,y ) 表示参考图像,且为了简化记法,令 k 表示满足 的
。我们假设 R( x ,y ) = f ( x ,y ,1 ) 。则对任意 k > 1 ,考虑到 ADI 的值是计数,我们为所有相关的 ( x ,y ) 值定义以下累积差:
(10-115)
(10-116)
和
(10-117)
其中, ,
, 和
分别是绝对的、正的、和负的 ADI ,使用序列中的第 k 幅图像计算所得。三个ADI的初始计数均为零,且大小与序列中的图像相同。如果背景像素的强度值大于运动物体的强度值,则公式(10-116)和(10-117)中不等式的顺序和阈值的符号将互换。
例 10.27:计算绝对值、正值和负值累积差图像。
图 10.62 显示了三个 ADI 的强度图像,这些图像对应于一个尺寸为 75 × 50 像素的矩形物体,该物体以每帧 5 像素的速度向东南方向移动。图像大小为 256 × 256 像素。我们注意到以下几点:(1) 正 ADI 的非零区域等于运动物体的尺寸;(2) 正 ADI 的位置对应于运动物体在参考系中的位置;(3) 当运动物体相对于参考系中的同一物体完全位移时,正 ADI 中的计数不再增加;(4) 绝对 ADI 包含正 ADI 和负 ADI 的区域;(5) 运动物体的方向和速度可以根据绝对 ADI 和负 ADI 中的数值确定。
-------------------------图 10.62:矩形物体沿东南方向运动的ADI值。(a) 绝对ADI值。(b) 正ADI值。(c) 负ADI值。-----------------------------------------
10.8.1.3 建立参考图像(Establishing a Reference Image)
刚才讨论的技术成功的关键在于拥有一个参考图像,以便进行后续的对比。在动态成像问题中,两幅图像之间的差往往会抵消所有静止分量,只留下对应于噪声和运动物体的图像元素。
获取仅包含静止元素的参考图像并非总是可行,因此需要从包含一个或多个运动物体的图像集中构建参考图像。这尤其适用于描述复杂场景或需要频繁更新的情况。生成参考图像的一种方法如下:将序列中的第一幅图像视为参考图像。当非静止物体完全移出其在参考图像中的位置时,可以在当前帧中复制该物体在参考图像中原本所在的位置。当所有运动物体都完全移出其原始位置时,即可生成仅包含静止物体的参考图像。如前所述,可以通过监测正ADI值的变化来确定物体位移。以下示例说明了如何使用上述方法构建参考图像。
例 10.28:构建参考图像。
图 10.63(a) 和 (b) 显示了交通路口的两帧图像。第一帧图像作为参考图像,第二帧图像描绘了同一场景一段时间后的景象。目标是从参考图像中移除主要运动物体,从而生成静态图像。尽管还有其他较小的运动物体,但主要的运动物体是路口处从左向右行驶的汽车。为了便于说明,我们重点关注该物体。如上所述,通过监测正向 ADI 值的变化,可以确定运动物体的初始位置。一旦确定了该物体所占据的区域,就可以通过减法将其从图像中移除。通过查看序列中正向 ADI 值停止变化的帧,我们可以从该图像中复制初始帧中运动物体所占据的区域。然后,将该区域粘贴到被移除物体的图像上,从而恢复该区域的背景。如果对所有运动物体都进行此操作,则会得到一幅仅包含静态元素的参考图像,我们可以将其与后续帧进行比较以进行运动检测。图 10.63(c) 显示了移除向东行驶的车辆并恢复背景后得到的参考图像。

--------------图 10.63:构建静态参考图像。(a) 和 (b) 为序列中的两帧。(c) 从 (a) 中减去向东行驶的汽车,并从 (b) 的相应区域恢复背景。( Jain 和 Jain )-----------
10.8.2 频域技术(Frequency Domain Techniques)
在本节中,我们考虑通过 Fourier 变换公式来确定移动的问题。考滤一个由一个固定相机生成的大小为 M × N 像素的 K 个数字图像帧序列 f ( x ,y ,t )( t = 0 , 1 , 2 , … , K - 1 ) 。我们首先假设所有帧都具有均匀的零强度背景。唯一的例外是单个像素大小、强度为1的物体,该物体以恒定速度运动。假设,对于第一帧( t = 0),这个物体位于 处 ,且图像平面投影到 x 轴; 即 ,图像中的像素强度在整个列上求和(对于每一行) 。这一操作就得到了一个具有 M 个0元素(除了在
处,它是单点物体的 x 坐标)的一维数组。若我们现在用量
( x = 0 , 1 , 2 , … , M - 1 ) 乘以一维数组的所有分量,并将结果相加,则我们就获得了单项
,因为在数组中仅有一个非零点。在这种记法中,
是一个正整数。Δt 是帧之间的时间间隔。
假设在第二帧中( t = 1 ) ,物体已被移到坐标 处 ;即,已移动的一个像素移平行于 x 轴。然后,重复前述段落介绍的投影过程,就得到了和
。 若物体在后续每一帧中继续移动 1 个像素,则在任意整的时间常量 t 时刻,计算的结果都奖是
,我们用 Euler 公式可以将其表示为
(10-118)
( t = 0 , 1 , 2 , … , K - 1 ) 。换言之,这个过程得到了一个频率为 的复正弦波函数,若帧之间的物体被移运
个像素(在 x 方向),则正弦波就会有频率
。
由于 t 在 0 和 K - 1 之间按整数递增变动,因此, 被限定到取整数值的情况,从而复正弦波的离散 Fourier 变换有两个尖点—— 一个位于
处,而另一个位于
处,后一个峰值是离散Fourier变换对称性的结果,如第 4.6 节所述,可以忽略。因此,在Fourier频谱中进行尖点搜索将得到一个值为
的尖点。将该值除以
即可得到
,即 x 方向的速度分量(假设帧速率已知)。类似的分析可以得到
,即 y 方向的速度分量。
如果一系列帧中没有发生运动,则会产生相同的指数项,其Fourier变换将由频率为 0 的单个峰值(单个直流项)组成。因此,由于目前讨论的运算都是线性的,因此在任意静态背景下涉及一个或多个运动物体的一般情况下,其Fourier变换将具有一个对应于静态图像分量的直流峰值,以及与物体速度成正比的位置峰值。
这些概念可以概括如下。对于一系列大小为 M × N 像素的 k 个数字图像,在任意整数时刻,它们在 x 轴上的加权投影之和为
(10-119)
( t = 0 , 1 , 2 , … , K - 1 )
类似地,在 x 轴上的加权投影之和为
(10-120)
其中,如前所述, 和
是正整数。
公式 (10-119) 和 (10-120) 的一维 Fourier 变换分别是
(10-121)
( )
和
(10-122)
( )
这些变换是使用 FFT 算法计算的,如第 4.11 节所述。
频率速度关系是
(10-123)
和
(10-124)
在前面的公式中,速度的单位是每帧时间内移动的像素数。例如, 表示在 K 帧内移动了 10 个像素。对于均匀拍摄的帧,实际的物理速度取决于帧速率和像素间距。因此,如果
,帧速率为每秒两帧,像素间距为 0.5 米,则 x 方向上的实际物理速度为
(10 像素)(0.5米/像素)(2 帆/秒)(30帧)
速度的 x 分量符号计算公式为
(10-125)
和
(10-126)
由于 是正弦波,因此可以证明(见问题 10.53),若速度分量
是正数,则
和
在任意时间点 n 处都具有相同的符号。反之,
和
符号相反则表明速度分量为负。若
或
为零,则我们考虑下一个在时间上最接近的点 t = n ± Δt 。类似的讨论也适用于计算
的符号。
例 10.29:利用频域分析法检测小型运动物体。
图 10.64 至 10.66 展示了所提出方法的有效性。图 10.64 显示了通过向参考图像添加白噪声生成的 32 帧 LANDSAT 图像序列中的一帧。该序列包含一个叠加的目标,该目标在 x 方向上以每帧 0.5 像素的速度移动,在 y 方向上以每帧 1 像素的速度移动。该目标(如图 10.65 中圆圈所示)具有Gauss强度分布,分布在一个很小的区域(9 像素)内,肉眼不易辨认。图 10.66 显示了分别使用 和
计算公式 (10-121) 和 (10-122) 的结果。图 10.66(a) 中
处的峰值根据公式 (10-123) 得出
。类似地,图 10.66(b) 中
处的尖点由公式 (10-124) 得出
。
图 10.66 可以解释 和
的选择原则。例如,假设我们使用
而不是
。在这种情况下,图 10.66(b) 中的尖点现在将位于
和 17 处,因为
。这将导致严重的混叠结果。如 4.5 节所述,混叠是由欠采样引起的(在本讨论中,帧数过少,因为 u 的范围由 K 决定)。因为 u = aV ,一种可能是将 a 选为最接近
的整数。其中,
是由 K 确定的混叠频率限制,而
是最大的预期物体移运速度。

-----------图 10.64:LandSat 图像帧。(Cowart, Snyder,和Ruedger。)---------
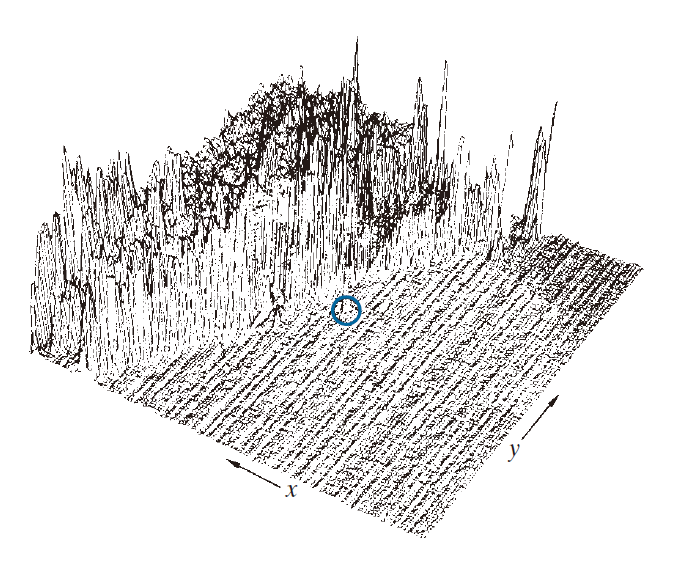
------------------------------图 10.65:图 10.64 中图像的强度图,目标区域已用圆圈标出。(Rajala ,Riddle 和 Snyder。)-----------------------------------------
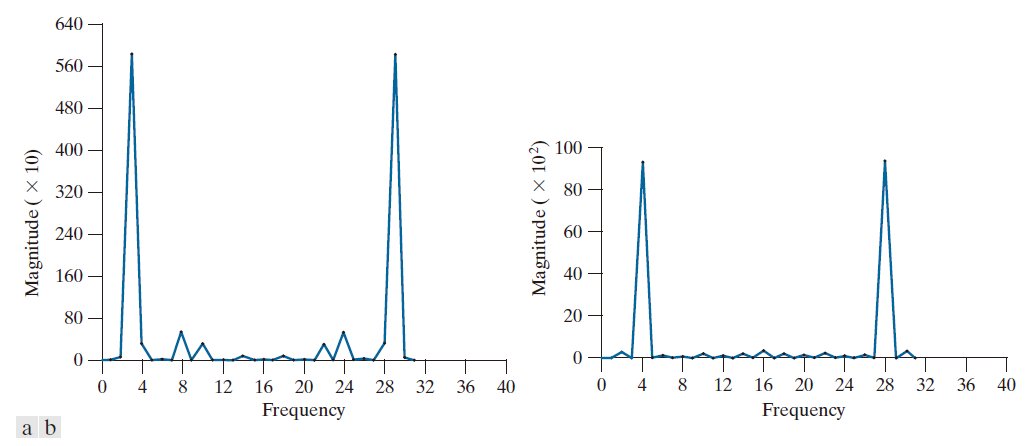
------------------------------图 10.66:图 10.64 中图像的强度图,目标区域已用圆圈标出。(Rajala ,Riddle 和 Snyder。)-----------------------------------------

















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










