




第 11 章 特征提取(Feature Extraction)
目录
11.2 边界预处理(Boundary Preprocessing)
11.2.1 边界跟踪(追踪)(Boundary Following (Tracing))
11.2.2.1 Freeman链码(Freeman Chain Codes)
11.2.2.2 斜率链码(Slope Chain Codes)
11.2.3 利用最小周长多边形进行边界近似(Boundary Approximations Using Minimum-Perimeter Polygons)
11.2.5 骨架,中轴,和距离变换(Skeletons, Medial Axes, and Distance Transforms)
11.3 边界特征描述符(Boundary Feature Descriptors)
11.3.1 一些基本边界描述符(Some Basic Boundary Descriptors)
11.3.3 Fourier描述符(Fourier Descriptors)
11.3.4 统计矩(或统计动差) (Statistical Moments)
11.4 区域特征描述符(Region Feature Descriptors)
11.4.1 一些基本描述符(Some Basic Descriptors)
11.4.2 拓扑描述符(Topological Descriptors)
11.4.3.1 统计法(Statistical Approaches)
11.4.3.2 频谱法(Spectral Approaches)
11.4.3.3 矩不变性(Moment Invariants)
导读(Preview)
使用诸如第10章和第11章中介绍的方法将图像分割成区域或其边界后,通常需要将分割后的像素集转换为适合进一步计算机处理的形式。通常,分割后的步骤是特征提取,包括特征检测和特征描述。特征检测是指在图像、区域或边界中查找特征。特征描述则是为检测到的特征赋予定量属性。例如,我们可以检测区域边界中的角点(corner),并用它们的方位和位置来描述这些角点,这两者都是定量属性。本章讨论的特征处理方法根据其适用范围(边界、区域或整幅图像)分为三大类。某些特征适用于多个类别。特征描述符应尽可能不敏感于尺度、平移、旋转、光照和视角等参数的变化。本章讨论的描述符要么对这些参数中一个或多个的变化不敏感,要么可以通过归一化来补偿这些变化。
11.1 背景(Background)
尽管对于图像特征的构成尚无普遍接受的正式定义,但几乎没有人会否认,在直觉上,我们通常将特征视为我们想要标记或区分的“事物”的独特属性或描述。就本文而言,关键词是“标记(label)”和“区分(differentiate)”。本章所关注的“事物(something)”既可以指单个图像对象,也可以指整个图像或图像集。因此,我们将特征视为有助于我们为图像中的对象分配唯一标签的属性,或者更一般地说,有助于区分整个图像或图像族的属性。
图像特征提取主要包含两个方面:特征检测和特征描述。即,当我们提到特征提取时,我们指的是检测特征并描述它们。为了有效,提取过程必须涵盖这两个方面。在图像处理和分析中,描述特征检测和描述的术语可能有所不同,但一个简单的例子将有助于阐明我们对这些术语的用法。假设我们使用物体角点作为图像处理任务的特征。在本章中,检测指的是在区域或图像中找到角点。而描述则指的是为检测到的特征赋予定量(有时是定性)属性,例如角点的方向以及相对于其他角点的位置。换言之,仅仅知道图像中存在角点是有限的,除非有其他信息可以帮助我们基于角点及其属性来区分图像中的物体或图像。
鉴于我们希望利用特征进行区分,则下一个问题是:在数字图像处理领域,这些特征必须具备哪些重要特性?你可能已经熟悉其中一些特性。一般来说,特征应与位置、旋转和尺度无关。其他因素,例如与光照水平无关以及成像传感器与场景之间的视角变化,也同样重要。尽可能在特征提取之前对输入图像进行预处理以进行归一化。例如,在光照变化剧烈到足以导致特征检测困难的情况下,对图像进行预处理以补偿这些变化是合理的。直方图均衡化或规范化是我们知道在这方面有效的自动技术。其理念是尽可能多地利用先验信息来预处理图像,以提高特征提取的准确性。
在描述特征时,“独立(independent)”一词通常有两种含义:不变性(invariant)或协变性(covariant)。如果特征描述符的值在对被描述实体应用变换族中的任何变换后保持不变,则称该特征描述符对该变换族是不变的。如果对实体应用变换族中的任何变换都会在描述符中产生相同的结果(译注:产生相同的结果,但不是不变),则称该特征描述符对该变换族是协变的。例如,考虑以下仿射(affine)变换集:{平移、反射、旋转}(译注:仿射变换即保持点的共线性(collinarity)(变换后的点任然处于同一线段)和距离比率(即变换后的中点不变)不变的变换,它是射影变换的一个特殊类,故称仿射),并假设我们有一个椭圆区域,我们为其赋予特征描述符“面积(area)”。显然,将这些变换中的任何一种应用于该区域都不会改变其面积。因此,“面积”是给定变换族的不变特征描述符。但是,如果我们在该变换族中添加仿射变换“缩放”,则描述符“面积”不再是扩展变换族的不变特征。现在,描述符相对于族是协变的,因为将区域面积乘以任何因子都会将描述符的值乘以相同的因子。类似地,描述符的方向(区域主轴的方向)也是协变的,因为将区域旋转任意角度都会对描述符的值产生相同的影响。本章中使用的大多数特征描述符通常都是协变的,即,它们可能对某些感兴趣的变换保持不变,但对其他同样重要的变换则不然。正如你稍后将看到的,尽可能多地从协变中归一化相关的不变性是一种良好的实践。例如,我们可以通过计算区域的实际方向并旋转区域,使其主轴指向预定义的方向,以此补偿区域方向的变化。如果我们对图像中检测到的每个区域都这样做,旋转将不再是协变的。
特征的另一个主要分类是局部特征与全局特征。你可能会看到许多不同的尝试,试图将特征归入这两类之一。难点在于,一个特征可能同时属于这两类,具体取决于应用场景。例如,再次考虑描述符“面积”,假设我们将其应用于检测生产线上经过成像传感器的瓶子的液体填充程度。传感器及其配套软件能够同时生成十个瓶子的图像,每个瓶子中的液体在图像中显示为一个亮区,其余部分则显示为暗背景。在这种固定的几何结构中,区域的面积与瓶子中的液体量成正比,如果能够可靠地检测和测量,面积就是我们解决检测问题所需的唯一特征。每幅图像包含十个区域,因此我们将面积视为局部特征,因为它适用于图像中的各个元素(区域)。如果问题是检测图像中液体的总量(面积),那么我们现在会将面积视为全局描述符。但故事并未就此结束。假设我们重新定义液体检测任务,使其计算每天流经成像站的液体总量。我们不再关注单个区域的面积,而是以图像为单位。如果我们知道单张图像的总面积,并且知道图像的数量,那么计算一天的液体总量就非常简单。现在,整张图像的面积是一个局部特征,而一天结束时的总面积则是一个全局特征。显然,我们可以重新定义任务,使一天结束时的总面积成为一个局部特征描述符,而所有装配线的总面积则成为一个全局度量。如此循环往复,无穷无尽。在本章中,我们将适用于某个集合中某个成员的特征称为局部特征,将适用于整个集合的特征称为全局特征,其中“成员”和“集合”的定义取决于具体应用。
除了交互式图像处理等应用(这些并非本书的主要内容),特征本身很少单独生成供人使用。事实上,正如你稍后将看到的,一些特征提取方法会生成数十、数百甚至数千个描述符值,这些值如果仅从视觉上观察,则显得毫无意义。相反,特征描述通常用作更高级别任务的预处理步骤,例如图像配准、用于自动检测的目标识别、在图像数据库中搜索模式(例如,人脸和/或指纹)以及自主应用,例如机器人和车辆导航。对于这些应用,数值特征通常以特征向量(即 1 × n 或 n × 1 矩阵)的形式“打包”,其元素是描述符。RGB 图像是最简单的示例之一。正如你从第 6 章中了解到的,RGB 图像的每一个像素都可以表示为一个三维向量
其中, 是某一个点处的红色图像强度值,而其它的分量分别是红色和蓝色图像在同一点的强度值。如果使用颜色作为特征,那么 RGB 图像中的一个区域将表示为三维空间中的一组特征向量(点)。当使用 n 个描述符时,特征向量变为 n 维,包含这些特征向量的空间被称为 n 维特征空间。你可以将一组 n 维特征向量“可视化”为 n 维Euclid空间中的点云。
在本章中,我们将特征分为三大类:边界特征、区域特征和整幅图像特征。这种划分并非基于我们即将讨论的方法的适用性,而是基于某些类别在描述内容的语境下比其他类别更有意义。例如,当我们提到“边界的长度”时,我们指的是“区域边界的长度”,但提到图像的“长度”则毫无意义。我们将要讨论的许多特征都适用于边界和区域,有些特征也适用于整幅图像。
11.2 边界预处理(Boundary Preprocessing)
前两章讨论的分割技术会生成原始数据,这些数据以边界上的像素或区域内的像素形式存在。通常的做法是使用一些方案将分割后的数据压缩成便于计算描述符的表示形式。本节将讨论适用于此目的的各种边界预处理方法。
11.2.1 边界跟踪(追踪)(Boundary Following (Tracing))
本章讨论的几种算法要求区域边界上的点按顺时针或逆时针方向排序。因此,我们首先介绍一种边界跟随算法,其输出为有序的点序列。我们假设:(1) 我们处理的是二值图像,其中目标点和背景点分别标记为 1 和 0;(2) 图像边缘填充了 0,以避免目标与图像边界重叠。为清晰起见,我们将讨论限制在单个区域。通过分别处理各个区域,该方法可以扩展到多个不相交的区域。
以下算法描绘二值图像中值为 1 的区域 R 的边界。
(1) 令起点 为图像中标为 1 的最左上角点(注:正如你将在本章后面和习题 11.8 中看到的那样,最左上角的1值边界点具有一个重要的性质:该边界的多边形近似在该位置具有凸顶点。此外,该点的左侧和北侧邻域点保证都是背景点。这些性质使其成为边界跟踪算法的良好“标准”起始点)。用
表示
的西邻域[见图 11.1(b)]。很显然,
总是一个背景点。令
表示遇到的值为 1 的第一个邻域,并令
表示序列中恰好位于
前的(背景)点。 存储
的位置以供第 (5) 步使用 。
(2) 令 和
。
(3) 令 b 的 8 邻域为 , 始于 c 点,并按时针方向前进。求得第一个标为 1 的邻域并标为
。
(4) 令 和
。
(5) 重复执行 (3) 和 (4) 直到 。算法停止时求得的 b 点序列就是有序边界点的集合。
注意,第 (4) 步的点 c 总是一个背景点,因为 是按时针方向扫描所发现的第一个 1 值点。这个算法称为 Moore 边界跟踪算法,以Edward F. Moore 的名字命名,他是元胞自动机理论(cellular automata theory)的先驱者之一。
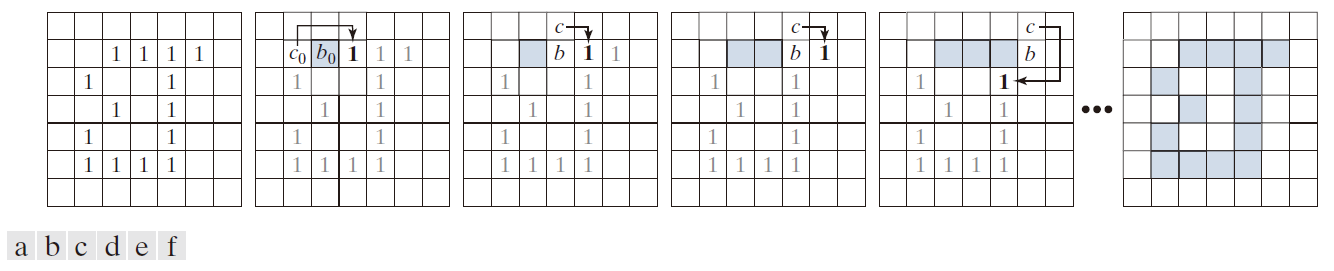
------------------------图 11.1:图示边界跟踪算法的前几个步骤。待处理的点以粗体黑色标记;尚未处理的点以灰色标记;算法找到的点以阴影标记。没有标记的方块被视为背景值(0)。-------------------------------------------------------------------
图 11.1 展示了算法的前几个步骤。不难验证(参见习题 11.1),继续执行此步骤将得到正确的边界,如图 11.1( f ) 所示,其上的点按顺时针顺序排列。该算法同样适用于更复杂的边界,例如图 11.2(a) 中带有附加分支的边界或图 11.2(b) 中的自相交边界。对于多个边界 [图 11.2(c)],则通过一次处理一个边界来处理。
如果我们从一个二值区域而非边界开始,该算法会提取该区域的外边界。通常,得到的边界厚度为一个像素,但并非总是如此[参见问题 11.1(b)]。如果目标是找到区域中孔洞的边界(这些边界被称为区域的内边界),一种直接的方法是提取这些孔洞(参见第 9.6 节),并将它们视为背景为 0 的 1 值区域。将边界跟踪算法应用于这些区域,即可得到原区域的内边界。
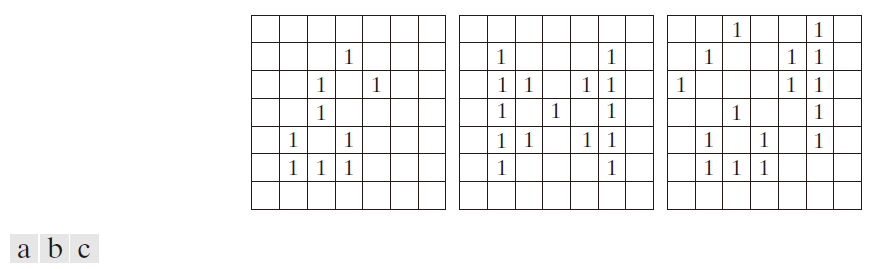
---------------------图 11.2:边界跟踪算法可以处理的边界示例。(a) 带分支的闭合边界。(b) 自相交边界。(c) 多个边界(一次处理一个)。-----------------------------
我们本可以简单地根据逆时针方向的边界来描述算法,但你会发现,只用一个算法,然后反转结果顺序来得到反方向的序列会更容易。在接下来的章节中,我们会交替使用(但保持一致)两种方向,以帮助你熟悉这两种方法。
11.2.2 链码(Chain Codes)
链码用于用一系列具有特定长度和方向的直线段来表示边界。本节假设所有曲线均为闭合简单曲线(即闭合且不自相交的曲线)。
11.2.2.1 Freeman链码(Freeman Chain Codes)
通常,链码表示基于4连通或8连通的链段。每个链段的方向都使用编号方案进行编码,如图11.3所示。由这些方向编号序列构成的边界码称为Freeman链码。
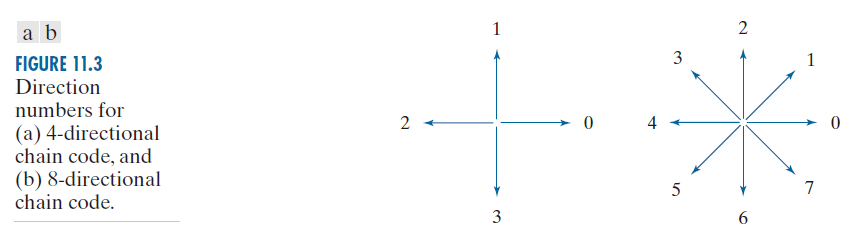
------------图 11.3:(a) 4 方向链码和(b) 8 方向链码的方向编号。---------------
数字图像通常以网格格式采集和处理,x 和 y 方向上的间距相等。因此,可以通过沿着边界(例如顺时针方向)并为连接每对像素的线段分配方向来生成链码。这种细节级别通常不使用,主要有两个原因:(1) 生成的链码会非常长;(2) 由于噪声或分割不完美导致的边界上的任何微小扰动都会导致代码发生变化,而这些变化可能与边界的主要形状特征无关。
解决这些问题的一种方法是选择更大的网格间距来重采样边界,如图 11.4(a) 所示。然后,在遍历边界的过程中,根据原边界点与较粗网格节点的接近程度,将边界点分配给该节点,如图 11.4(b) 所示。以这种方式获得的重采样边界可以用 4 码或 8 码表示。图 11.4(c) 显示了用 8 方向链码表示的较粗边界点。8 码和 4 码之间的转换很简单(参见习题 2.15、9.27 和 9.29)。出于与本节前面讨论边界追踪时相同的原因,我们选择图 11.4(c) 中的起始点为边界的最左上角点,这给出了链码 0766…1212。正如你可能猜到的那样,重采样网格的间距是由链码的应用决定的。
如果用于获取连通数字曲线的采样网格是均匀四边形(见图 2.19),则基于图 11.3 的 Freeman 码的所有点都保证与曲线上的点重合。如果使用相同类型的采样网格对数字曲线进行子采样,如图 11.4(b) 所示,情况也是如此。这是因为使用此类网格生成的曲线样本与图 11.3 中的排列方式相同,因此在沿曲线从一点到下一点生成代码的过程中,所有点都是可达的。
链码的数值取决于起始点。然而,可以通过一个简单的步骤对链码进行归一化:我们将链码视为一个循环的方向数序列,并重新定义起始点,使得得到的数序列构成一个最小整数。我们还可以通过使用链码的一阶差分而非链码本身来对旋转(以图 11.3 中方向的整数倍为单位的角度)进行归一化。该差分是通过计算链码中两个相邻元素之间的方向变化次数(在图 11.3 中为逆时针方向)得到的。如果我们将链码视为一个循环序列并对其进行归一化,则差分的第一个元素可以通过链码的最后一个元素和第一个元素之间的转换来计算。例如,四方向链码 10103322 的一阶差分是 3133030。可以通过改变重采样网格的间距来实现尺寸归一化。
刚才讨论的归一化方法只有在边界本身对旋转(同样,旋转角度必须是图 11.3 中所示方向的整数倍)和尺度变化保持不变时才是精确的,而这在实践中很少发生。例如,同一个物体以两种不同的方向数字化后,其边界形状通常会有所不同,差异程度与图像分辨率成正比。可以通过选择长度与数字化图像中像素间距成正比的链元素来减少这种影响,或者通过以下方式:将重采样网格沿待编码物体的主轴方向放置(如第 11.3 节所述),或沿其特征轴方向放置(如第 11.5 节所述)。
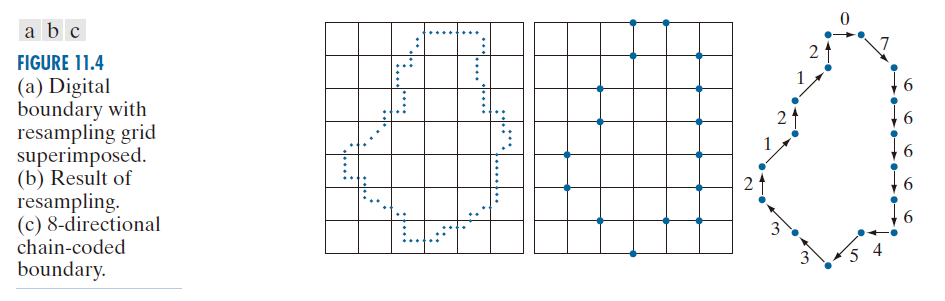
---------------------------图 11.4:(a) 叠加重采样网格的数字边界。(b) 重采样结果。(c) 8方向链式编码边界。---------------------------------------------------
例子 11.1:Freeman链码及其一些变体。
图 11.5(a) 显示了一幅 570 × 570 像素、8 位灰度图像,图像中包含一个嵌入在随机分布的小镜面碎片中的圆形笔画。本例的目标是获得该笔画外边界的 Freeman 链码、对应的最小幅度整数以及一阶差分。由于目标物体嵌入在小碎片中,提取其边界会得到一条噪声曲线,无法准确描述物体的整体形状。如您所知,处理噪声边界时,平滑处理是一种常规方法。图 11.5(b) 显示了使用 9 × 9 像素大小的盒状核进行平滑后的原始图像(有关空间平滑的讨论,请参见第 3.5 节),图 11.5(c) 是使用该图像通过 Otsu 方法获得的全局阈值进行阈值分割的结果。请注意,区域数量已减少到两个(其中一个是点),这大大简化了问题。
图 11.5(d) 是图 11.5(c) 中区域的外边界。直接获取该边界的链码会得到一个很长的序列,其中包含许多细微的变化,无法代表边界的整体形状,因此我们在获取其链码之前对其进行重采样。这可以减少微不足道的变化。图 11.5(e) 是使用节点间距为 50 像素(约占图像宽度的 10% )的重采样网格的结果,图 11.5( f ) 是将采样点用直线连接的结果。这种更简单的近似方法保留了原始边界的主要特征。
简化边界的8方向Freeman链码为
0 0 0 0 6 0 6 6 6 6 6 6 6 6 4 4 4 4 4 4 2 4 2 2 2 2 2 0 2 2 0 2
边界的起始点位于子采样网格中的坐标 ( 2 , 5 ) 处( 回想一下图 2.19,图像的原点位于其左上角)。这对应于图 11.5( f ) 中的最左上角点。在这种情况下,码的最小幅度整数恰好与链码相同:
0 0 0 0 6 0 6 6 6 6 6 6 6 6 4 4 4 4 4 4 2 4 2 2 2 2 2 0 2 2 0 2
码的第一个不同之处在于
0 0 0 6 2 6 0 0 0 0 0 0 0 6 0 0 0 0 0 6 2 6 0 0 0 0 6 2 0 6 2 6
使用此代码表示边界可以显著减少存储边界所需的数据量。此外,如第 11.3 节所述,使用代码编号提供了一种统一的方法来分析边界的形状。最后,请记住,可以从任何前面的代码中恢复欠采样边界。

------------图 11.5:(a) 尺寸为 570 × 570 像素的噪声图像。(b) 使用 9 × 9 方框核平滑后的图像。(c) 使用 Otsu 方法进行阈值分割后的平滑图像。(d)(c) 的最长外边界。(e) 下采样边界(为清晰起见,图中点已放大)。( f ) (e) 中的连接点。----------
11.2.2.2 斜率链码(Slope Chain Codes)
使用Freeman链码通常需要对边界进行重采样以平滑微小变化,这一过程需要定义一个网格,然后将所有边界点分配给网格中与其最近的邻点。另一种方法是使用斜率链码(SCC)(Bribiesca [1992, 2013])。二维曲线的斜率链码是通过在曲线周围放置等长的直线段得到的,这些直线段的端点与曲线相切。
获得SSC需要计算相邻线段之间的斜率变化,并将这些变化归一化到连续(开)区间(-1, 1)。这种方法需要定义线段的长度,而Freeman码则需要定义网格并为其分配曲线点——这是一个更为复杂的过程。与Freeman码类似,SCC与旋转无关,但其斜率变化范围更大,因此在旋转情况下比Freeman码的旋转无关性(仅限于图11.3(b)中的八个方向)提供了更精确的表示。与Freeman码一样,SCC与平移无关,并且可以针对尺度变化进行归一化(参见问题11.8)。
图 11.6 展示了如何生成 SCC。第一步是选择用于生成代码的线段长度[参见图 11.6(b)]。接下来,指定一个起点(原点)(对于一条开曲线,逻辑起点是其端点之一)。如图 11.6(c) 所示,选择原点后,将线段的一端放置在原点,另一端与曲线重合。该点成为下一条线段的起点,重复此过程,直到到达起点(或开放曲线的终点)。如图所示,你可以将此过程视为一系列半径等于线段长度的相同圆,这些圆沿着曲线移动。圆与曲线的交点决定了曲线直线近似的节点。
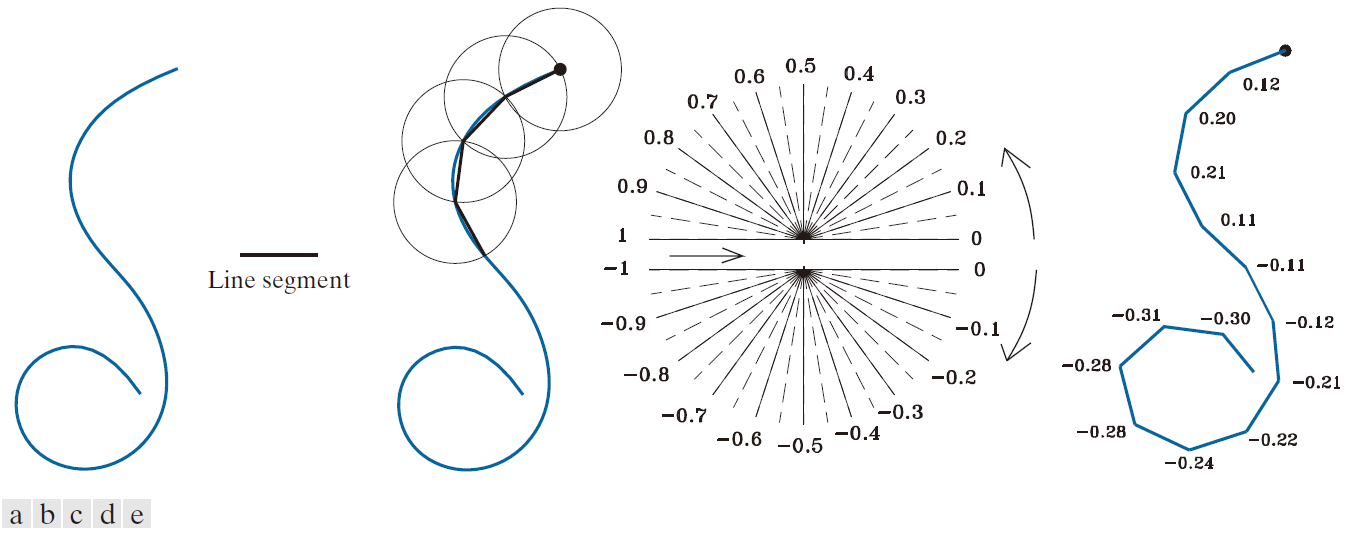
-----------------------图 11.6:(a) 一条开放曲线。(b) 一段直线。(c) 通过测量曲线周长来确定斜率变化;图中的点为原点(起点)。(d) 开放区间 (-1, 1) 内的斜率变化范围(图表中心的箭头指示行进方向)。所示斜率数值之间可以有十个子区间。(e) 生成的编码曲线,显示其对应的斜率变化数值序列。(图片由墨西哥国立自治大学(UNAM)IIMAS研究所的Ernesto Bribiesca教授提供。) ---------------------------
一旦确定了圆的交点,我们就需要计算相邻线段之间的斜率变化。正斜率变化和零斜率变化被归一化到半区间 [0, 1) 内,而负斜率变化则被归一化到半区间 (−1, 0) 内。不允许斜率变化为 ±1 可以避免因处理此类变化而导致的同一条线段方向相反的问题。
斜率变化序列构成了定义原曲线的SCC近似值的链。例如,图11.6(e)中曲线的编码为0.12, 0.20, 0.21, 0.11, -0.11, -0.12, -0.21, -0.22, -0.24, -0.28, -0.28, -0.31, -0.30。图11.6(d)中定义的斜率变化的精度为 ,由此产生了一个包含199个可能符号(斜率变化)的“字母表”。当然,精度是可以改变的。例如,精度为
时,字母表包含19个符号(参见问题11.6)。与 Freeman 码不同,SCC编码曲线的最后一个点不能保证与原曲线的最后一个点重合。然而,缩短线长和/或提高角度分辨率通常可以解决这个问题,因为计算结果会四舍五入到最接近的整数(记住我们使用的是整数坐标)。
短链的逆链是另一条长度相同的链,通过反转符号的顺序和正负号得到。链的镜像可以通过从原点出发并反转符号的正负号得到。最后,我们指出,前面的讨论可以直接应用于闭合曲线。曲线跟踪可以从任意点(例如,曲线最左上角的点)开始,沿顺时针或逆时针方向进行,直到到达起点为止。我们将在例 11.6 中演示短链的应用。
11.2.3 利用最小周长多边形进行边界近似(Boundary Approximations Using Minimum-Perimeter Polygons)
一条数字边界可以用一个多边形以任意精度近似表示。对于闭合曲线,当多边形的线段数等于边界上的点数时,近似结果将达到精确,因此每对相邻的点定义了多边形的一条线段。多边形近似的目标是使用尽可能少的线段来体现给定边界的形状本质。通常,这个问题并不简单,可能会演变成耗时的迭代搜索。然而,复杂度适中的近似技术非常适合图像处理任务。其中,最强大的方法之一是使用最小周长多边形 (MPP) 来表示边界,如下文所述。
11.2.3.1 基础知识(Foundation)
计算最小周长多边形 ( MPP-Minimum-Perimeter Polygon) 的一种直观方法是用一组连接的单元格围成一个边界 [参见图 11.7(a)],如图 11.7(b) 所示。可以将边界想象成一条橡皮筋,它包含在图 11.7(b) 中的灰色单元格内。随着橡皮筋的收缩,它将受到灰色单元格区域内外壁顶点的约束。最终,这种收缩会形成一个周长最小的多边形(相对于这种几何排列),该多边形包围着单元格带围成的区域,如图 11.7(c) 所示。请注意,在此图中,MPP 的所有顶点都与内壁或外壁的角重合。
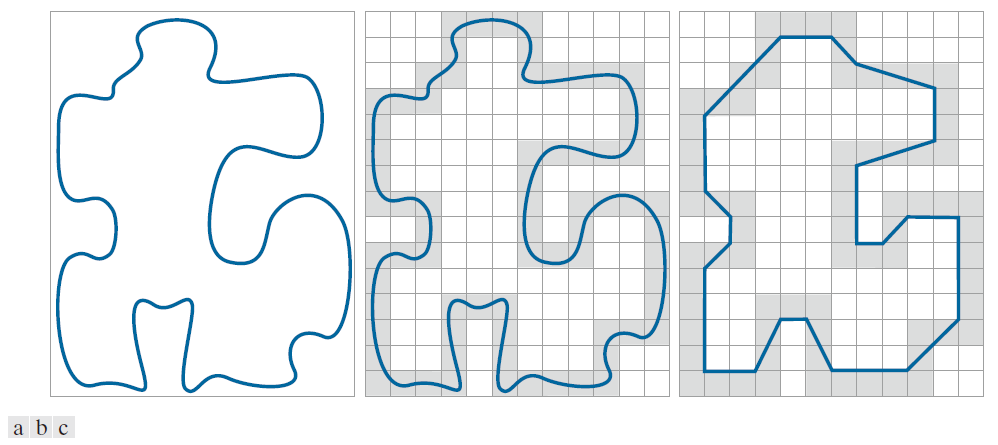
---------图 11.7:(a) 物体边界。(b) 由单元格(阴影部分)围成的边界。(c) 通过边界收缩得到的最小周长多边形。该多边形的顶点由灰色区域内外壁的角点构成。-----------
单元格的大小决定了多边形近似的精度。极限情况下,如果每个(正方形)单元格的大小对应于边界上的一个像素,则每个单元格中边界与 MPP 近似之间的最大误差为 ,其中 d 是像素之间的最小可能距离(即原始采样边界分辨率所确定的像素间距)。通过强制多边形近似中的每一个单元格以其在原边界中对应的像素为中心,可以将此误差减半。目标是在给定的应用范围内使用尽可能大的单元格尺寸,从而生成顶点数最少的 MPP。本节的目标是制定一个寻找这些 MPP 顶点的程序。
刚才描述的单元方法将原边界所包围的物体形状简化为图 11.7(b) 中灰色壁所围成的区域。图 11.8(a) 以深灰色显示了该形状。假设我们沿逆时针方向遍历深灰色区域的边界。遍历过程中遇到的每一个转弯点要么是凸顶点,要么是凹顶点(顶点的角度定义为该顶点处边界的内角)。凸顶点和凹顶点分别在图 11.8(b) 中用白色和蓝色圆点表示。请注意,这些顶点是图 11.8(b) 中浅灰色边界区域内壁的顶点,并且深灰色区域中的每个凹(蓝色)顶点在浅灰色壁上都有一个对应的凹“镜像”顶点,该顶点位于其对角线的对角位置。图 11.8(c) 展示了所有凹顶点的镜像,并叠加了图 11.7(c) 中的 MPP 作为参考。我们可以看到,MPP 的顶点要么与内壁的凸顶点(白点)重合,要么与外壁凹顶点的镜像(蓝点)重合。只有内壁的凸顶点和外壁的凹顶点才能成为 MPP 的顶点。因此,我们的算法只需关注这些顶点即可。
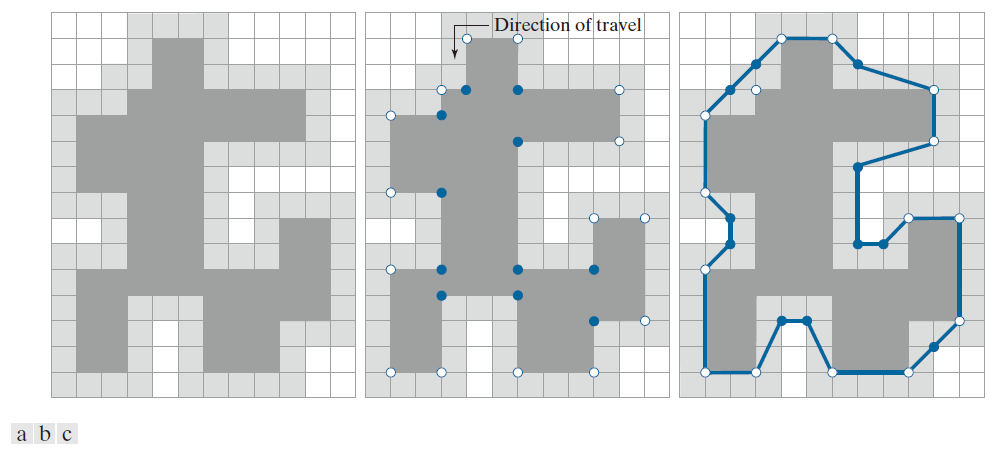
-------------------------图 11.8:(a) 由单元格包围原边界所形成的区域(深灰色)(参见图 11.7)。(b) 沿深灰色区域边界逆时针方向移动所得到的凸顶点(白点)和凹顶点(蓝点)。(c) 将凹顶点(蓝点)移动到包围区域外壁的对角镜像位置;凸顶点位置不变。图中叠加了 MPP(实线边界)作为参考。-------------------------------------------------
11.2.3.2 MPP算法(MPP Algorithm)
包含数字边界的单元格集合(例如,图 11.7(b) 中的灰色单元格)称为胞腔复合体。我们假设胞腔复合体是单连通的,即它们所包含的边界不自相交。基于此假设,并令白色 (W) 表示凸顶点,蓝色 (B) 表示镜像凹顶点,我们得出以下结论:
(1) 由单连通胞状复合体围成的MPP不是自相交的。
(2) MPP 的每个凸顶点都是 W 顶点,但边界上的每个 W 顶点并非都是 MPP 的顶点。
(3) MPP 的每一个镜像(mirrored concave)凹顶点都是 B 顶点,但边界的每一个 B 顶点并非都是 MPP 的顶点。
(4) 在细胞复合体中包含的顶点序列中,最左上角的顶点始终是 MPP 的 W 顶点(参见问题 11.8)。
这些断言可以从形式上证明(Sklansky 等人 [1972],Sloboda 等人 [1998] 以及 Klette 和 Rosenfeld [2004])。然而,就我们的目的而言,它们的正确性显而易见(见图 11.8),因此我们在此不再赘述证明过程。与图 11.8 中深灰色区域顶点的角度不同,MPP 顶点的角度不一定是 90°的倍数。
在随后的讨论中,我们将需计算三点集的方向。考虑一个三点集(triplet)( a , b ,c ) , 并令这些点的坐标分别为 ,
, 和
。若我们将这些点重排为矩阵行
(11-1)
然后,根据矩阵分析可推导出
(11-2)

其中 det(A) 是 A 的行列式。根据该公式,逆时针或顺时针方向的运动是相对于右手坐标系而言的(参见图 2.19 讨论中的脚注)。例如,使用图 2.19 中的图像坐标系(原点位于左上角,x 轴正方向垂直向下,y 轴正方向水平向右),序列 a = (3,4), b = (2,3) 和 c = (3 ,2 ) 为逆时针方向。将其代入方程 (11-2) 可得 det(A) > 0。在描述算法时,定义
(11-3)
会很方便,因此,对于一个逆时针序列,有 sgn( a , b ,c ) > 0 , 而对于一个顺时针序列,sgn( a , b ,c ) < 0 , 当点共线时,有 sgn( a , b ,c ) = 0 。从几何角度来看,sgn( a , b ,c ) > 0 表示点 c 位于点对 (a , b) 的正侧 ( 即 c 位于经过点 a 和 b 的直线的正侧)。类似地,如果 sgn( a , b ,c ) < 0,则点 c 位于该直线的负侧。如果使用序列 (c, a, b) 或 ( b , c , a ),则公式 (11-2) 和 (11-3) 的结果相同,因为序列中的行进方向与 ( a , b ,c ) 相同。然而,几何解释却有所不同。例如,sgn( a , b ,c ) > 0 表示点 b 位于经过点 c 和 a 的直线的正侧。
为了准备 MPP 算法所需的数据,我们构建一个三元组列表,每一个三元组包含一个顶点标签( 例如 ,
等 );每一个顶点的坐标;以及一个附加元素,用于指示该顶点是 W 还是 B 。重要的是,凹顶点必须镜像对称,如图 11.8(c) 所示,并且顶点必须按顺序排列(注:可以通过使用前面讨论过的边界跟踪算法跟踪边界,从而对边界的顶点进行排序),第一个顶点是最左上角的顶点,根据性质 5 可知,它是 MPP 的一个 W 顶点。令
表示该顶点。我们假设顶点按逆时针方向排列。求得 MPP 的算法使用两个“爬行(crawler)”点:白色爬行点
和蓝色爬行点
。
沿凸顶点 ( W ) 爬行,
沿凹顶点 ( B ) 爬行。这两个爬行点、求得的最后一个 MPP 顶点以及正在检查的顶点是实现该算法所需的全部信息。
对于此算法,首先令 ( 回顾一下,
是一个MPP 顶点 )。则在算法的任一步,令
表示求得的最后一个 MPP 顶点,并令
表示当前待检查的当前顶点。
,
和两个爬行点之间可能存在以下三种情况之一:
(a) 位于经过点对
的直线的正侧,在这种情况下, sgn( a , b ,c ) > 0 。
(b) 位于经过点对
的直线的负侧或与其共线,在这种情况下, sgn( a , b ,c ) < 0 。同时,
位于经过点对
的直线的负侧或与其共线;即
。
(c) 位于经过点对
的直线的负侧,在这种情况下,
。
若条件 (a) 成立,则下一个 MPP 顶点是 ,我们令
;则我们重新初始化算法,设
,在重新改变
后,我们从下一个顶点开始计算。
若条件 (b) 成立,则 成为一个候选的MPP 顶点。在这情况下,若
是一个顶点(即,其为一个 W 顶点),则我们设
;否则,我们设
。则我们用列表中的下一个顶点继续。
若条件 (c) 成立,则下一个 MPP 顶点是 ,我们令
;则我们重新初始化算法,令
,在重新改变
后,我们从下一个顶点开始计算。
当算法再次到达第一个顶点时停止,从而处理了多边形中的所有顶点。算法求得的 顶点即为MPP的顶点。Klette和Rosenfeld [2004] 证明了该算法能够找求得由单连通胞腔复合体包围的多边形的所有MPP顶点。
例子 11.2 :以下数值示例详细展示了 MPP 算法的工作原理。
一个简单的例子,我们可以逐步演示算法,这将有助于阐明前面的概念。考虑图 11.8(c) 中的顶点。在我们的图像坐标系中,网格的左上角点位于坐标 (0,0)。假设网格间距为 1,则前几个(逆时针方向)顶点为:
其中三元组之间用垂直线分隔,并且 B 顶点被镜像,这是算法的要求。
最左上角的顶点始终是 MPP 的第一个顶点。因此,我们首先令 和
相等,即
,并初始化其它变量:
。
下一个顶点是 。在这种情况下,我们有
且
, 因此,条件 (b) 成立。因为
是一个 B (凹形)顶点,我们更新了蓝色爬行点:
。在这个阶段,我们有
,
而
。
接下来,我们考察 。在这种情况下,
而
,因此条件 (b) 成立。由于
是 W ,因此我们更新白色爬行点:
。
下一个顶点是 。在这一节点,我们有
,
和
。则
而
,因此,条件 (b) 同样成立。由于
是 B ,我们令
并考察下一个顶点 。
下一个顶点是 。我们使用
,
和
。sgn 的值是
和
。因此,条件 (b) 仍然同样成立。且我们令
, 因为
是一个 W 顶点。
下一个顶点是 。使用前一步的值我们求得
,因此,条件 (a) 得以满足。因此,我们令
( 这是
) 并且重新初始化:
。再次注意,我们知道
,我们没有计算另一个 sgn 表达式。此外,重新初始化意味着我们从头开始,检查新求得的 MPP 顶点之后的下一个顶点。在本例中,下一个顶点是
,因此我们再次访问它。
携 并利用
,
和
的新值 ,可推导出
和
,因此,条件 (b) 成立。从而,我们令
,因为
是一个 W 顶点。
下一个顶点是 ,且
,因此条件 (a) 成立。从而我们令
并重新初始化算法, 设
。
因为该算法在 处重新初始化,从而下一个顶点又是
。使用前一步计算的结果得到
和
,因此这一步条件 (b) 成立。因为
是 B , 我们令
。
综上所述,到目前为止,我们已经求得了 MPP 的三个顶点: ,
, 和
。继续以上述方法处理剩余的顶点,即可得到图 11.8(c) 中的 MPP 顶点(参见问题 11.9)。镜像的 B 顶点 (2, 3),(3, 2) 以及右下角的 (13, 10) 位于 MPP 的边界上。然而,它们共线,因此不视为 MPP 的顶点。算法也确实没有将它们识别为顶点。
例子 11.3 :应用MPP 算法。
图 11.9(a) 是枫叶的 566 × 566 二值图像,图 11.9(b) 是其 8 连通边界。图 11.9(c) 至 (h) 分别展示了使用边长为 2、4、6、8、16 和 32 的方形复合体单元对该边界进行 MMP 表示的结果(图中各顶点均用直线连接形成闭合边界)。该叶片具有两个主要特征:叶柄和三个主叶。如图 11.9(e) 所示,当单元尺寸大于 4 × 4 时,叶柄开始消失。如图 11.9(g) 所示,即使单元尺寸达到 16 × 16,三个主叶也保留得相当完整。然而,从图 11.8(h) 可以看出,当单元格尺寸增加到 32 × 32 时,这一显著特征几乎消失了。
原边界[图11.9(b)]中的点数为1900。图11.9(c)至(h)中的顶点数分别为206、127、92、66、32和13。图11.9(e)包含127个顶点,在保留原始边界所有主要特征的同时,实现了超过90% 的数据缩减。由此可见,MMP在表示边界方面具有显著优势。另一个重要优势是MPP能够进行边界平滑处理。如前所述,这是使用链码表示边界时的常见要求。

------------图 11.9:(a) 566 × 566 二值图像。(b) 8 连通边界。(c) 至 (h) 分别为使用边长为 2、4、6、8、16 和 32 的正方形单元格获得的 MMP(顶点用直线段连接以方便显示)。(b) 中的边界点数为 1900。(c) 至 (h) 中的顶点数分别为 206、127、92、66、32 和 13。图像 (b) 至 (h) 以负片形式显示,以便更清晰地显示边界。----------
11.2.4 特征(Signatures)
一条特征线是一个二维边界的一维函数表示,可以通过多种方式生成。最简单的方法之一是绘制质心到边界的距离随角度变化的曲线,如图 11.10 所示。使用特征线的基本思想是将边界表示简化为一维函数,这样描述起来就比描述原二维边界更容易。
基于两个轴上尺度均匀的假设,以及采样间隔为 θ 的等距采样,形状尺寸的变化会导致相应特征的振幅值发生变化。一种归一化方法是对所有函数进行缩放,使其始终覆盖相同的取值范围,例如 [0,1]。这种方法的主要优点是简单,但缺点是整个函数的缩放仅取决于两个值:最小值和最大值。如果形状存在噪声,这可能会导致不同对象之间出现显著误差。一种更稳健(但也更耗费计算资源)的方法是将每一个样本除以特征的方差,假设方差不为零(如图 11.10(a) 所示),或者不小到会造成计算困难。使用方差可以得到一个可变的缩放因子,该因子与尺寸变化成反比,其工作原理与自动音量控制类似。无论采用何种方法,其核心思想都是在保持波形基本形状的同时,消除对尺寸的依赖性。
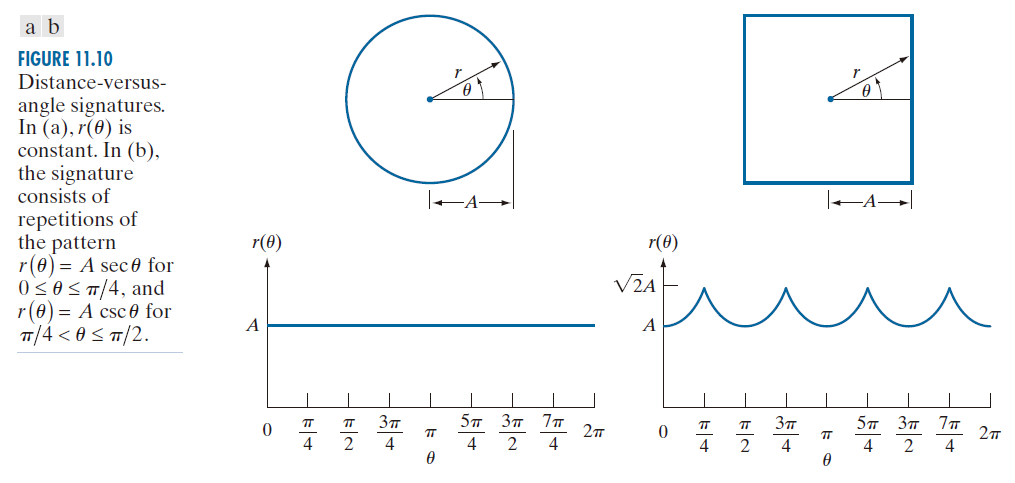
------------------------图 11.10:距离对比角度特征:在(a) 中,r (θ)是常量,而在 (b) 中 ,特征由图案的 r(θ) = Asec θ ( 0 ≤ θ ≤ π/4) 和 r(θ) = Acsc θ ( π/4 < θ ≤ π/2) 的重复构成。----------------------------------------------------------
距离与角度并非生成特征的唯一方法。例如,另一种方法是遍历边界,并针对边界上的每个点,绘制该点处边界切线与参考线之间的夹角。由此得到的特征虽然与图 11.10 中的 r(θ) 曲线截然不同,但却包含了关于基本形状特征的信息。例如,曲线中的水平段对应于边界上的直线,因为这些直线的切线角是恒定的。这种方法的变体是使用所谓的斜率密度函数作为特征。该函数是切线角值的直方图。由于直方图衡量的是值的集中程度,因此斜率密度函数对边界上切线角恒定的部分(直线或近似直线段)响应强烈,而在产生快速变化角度的部分(拐角或其他尖锐拐点)则呈现深谷。
例子 11.4 :两个区域的特征。
图 11.11( a ) 和 ( d ) 显示了两个二元物体,图 11.11(b) 和 (e) 显示了它们的边界。图 11.11( c ) 和 ( f ) 中对应的 r (θ) 特征范围从 0°到 360°,步长为 1°。特征中显著尖点的数量足以区分这两个物体的形状。
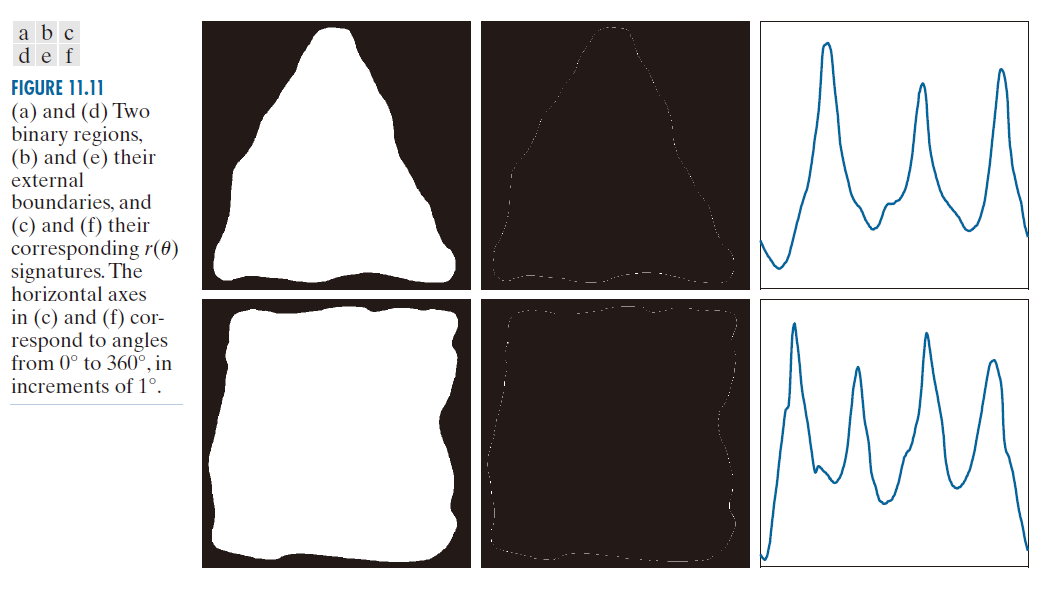
---------------------图 11.11:(a) 和 (d) 为两个二元区域,(b) 和 (e) 为它们的外部边界,( c ) 和 ( f ) 为它们对应的 r(θ) 特征。图 (c) 和 ( f ) 中的横轴对应于 0° 到 360° 的角度,增量为 1°。------------------------------------------------
11.2.5 骨架,中轴,和距离变换(Skeletons, Medial Axes, and Distance Transforms)
与边界类似,骨架也与区域的形状相关。骨架可以通过填充边界所包围的区域(用前景值填充)并把结果视为二值区域来计算。换言之,骨架是利用整个区域(包括其边界)中点的坐标来计算的。其思想是通过计算骨架将区域简化为树或图。正如我们在9.5节(见图9.25)中所解释的,区域的骨架是区域中与边界等距的所有点之集合。
骨架的获取主要有两种方法:(1) 通过逐步薄化区域(例如,使用形态学腐蚀),同时保持端点和线连通性(这称为保拓扑薄化(topology-preserving thinning));或(2)通过高效实现Blum [1967] 提出的中轴变换 (MAT-Medial Axis Transform) 来计算区域的中轴。我们在9.5节讨论了薄化方法。边界为B的区域R的MAT如下:对于R中的每一个点p ,我们找到它在B中的最近邻点。如果p有多个这样的最近邻点,则称p属于R的中轴。“最近”的概念(以及由此产生的MAT)取决于距离度量的定义(参见2.5节)。图11.12展示了一些使用Euclid距离的示例。如果使用Euclid距离,则得到的骨架与使用9.5节中的最大圆盘方法得到的骨架相同。一个区域的骨架定义为它的中轴线。
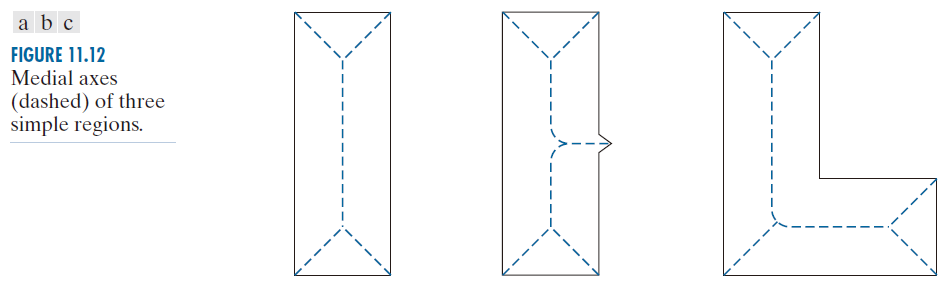
-------------------图 11.12:三个简单区域的中轴线(虚线)。----------------------
区域的MAT值可以根据11.3节讨论的“草原火灾”概念进行直观解释(见图11.15)。将图像区域视为一片均匀干燥的草原,并假设在其边界上的所有点同时着火。所有火线将以相同的速度向该区域推进。该区域的MAT值是指多个火线同时到达的点的集合。
一般来说,MAT 比薄化方法更接近于生成“合理”的骨架。然而,计算区域的 MAT 需要计算区域内每一个点到边界上每一个点的距离——这在大多数应用中是不切实际的。因此,通常的做法是利用距离变换来等效地获得骨架,而这方面已经存在许多高效的算法。
前景像素区域在全零背景中的距离变换是指每一个像素到其最近的非零像素的距离。图 11.13(a) 显示了一个小的二值图像,图 11.13(b) 是它的距离变换。注意,每一个值为 1 的像素的距离变换值为 0,因为其最近的非零像素是它自身。为了找到与 MAT 等效的骨架,我们关注的是前景(白色)像素区域内像素到其最近的背景(零)像素的距离,这些背景像素构成了该区域的边界。因此,我们计算图像补集的距离变换,如图 11.13(c) 和 (d) 所示。通过比较图 11.13(a) 和 (d),我们可以发现,前景(白色)像素区域与其最近的背景(零)像素之间的距离变换值与背景像素之间的距离变换值相同。图 11.13(d) 和 11.12(a) 中,我们可以看到,在前者中,MAT(骨架)等价于距离变换的脊线[即图 11.13(d) 图像中的脊线]。该脊线是局部极大值的集合[在图 11.13(d) 中以粗体显示]。图 11.13(e) 和 ( f ) 显示了在更大的 (414 × 708) 二值图像上相同的效果。
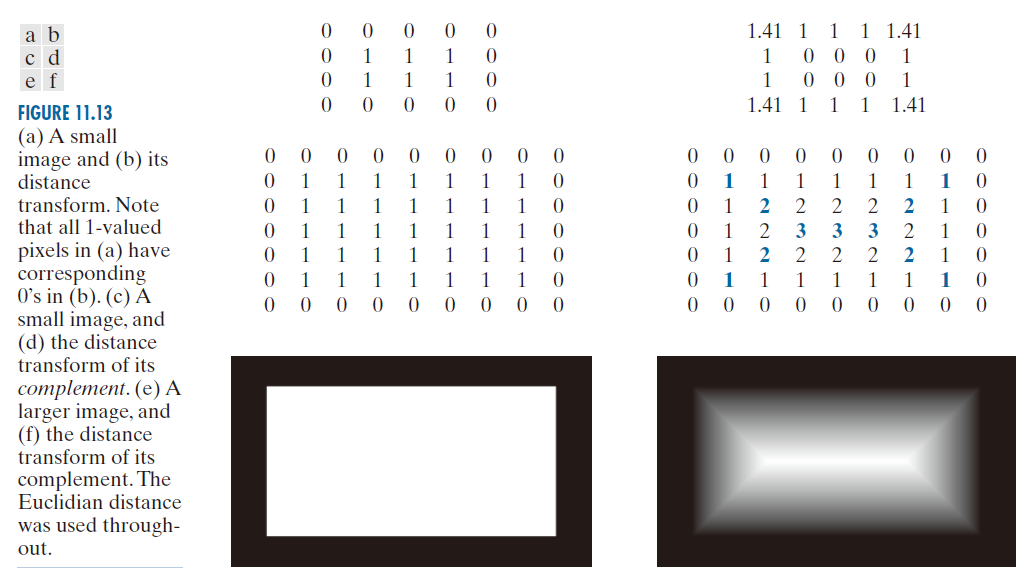
-----------------图 11.13:(a) 一幅小图像和 (b) 其距离变换。注意,(a) 中所有值为 1 的像素在 (b) 中都有对应的值为 0。(c) 一幅小图像和 (d) 其补图像的距离变换。(e) 一幅大图像和 ( f ) 其补图像的距离变换。所有计算均采用Euclid距离。----------
多年来,如何高效地计算距离变换一直是研究课题。目前已有许多方法可以以线性时间复杂度 O(K ) 计算具有 K 个像素的二值图像的距离变换。例如,Maurer 等人 [2003] 提出的算法不仅可以在 O(K ) 内计算距离变换,而且可以使用 P 个处理器在 O(K/P) 内计算。
例子 11.5 :籍薄化和裁剪法求得的骨架对比籍距离变换法求得的骨架。
图 11.14(a) 显示了血管的分割图像,图 11.14(b) 显示了使用形态学薄化方法得到的骨架。正如我们在第 9 章中讨论的,薄化通常会产生分支,这里的情况也确实如此。图 11.14(c) 显示了经过 40 次分支去除后的结果。除了图像左下角可见的几个小分支外,裁剪对清理骨架的效果相当不错。薄化的一个缺点是会丢失一些潜在的重要特征。这里并没有出现这种情况,只是裁剪后的骨架没有覆盖图像的全部区域。图 11.14(c) 显示了使用基于快速行进的距离变换计算得到的骨架(参见 Lee 等人 [2005] 和 Shi 和 Karl [2008])。我们使用的算法在实现分支生成时能够自动处理分支等歧义。
图 11.14(d) 的结果略优于图 11.14(c) 的结果,但两种骨架都很好地捕捉到了图像的重要特征。薄化方法的一个关键优势是实现简单,这在特定应用中至关重要。总体而言,距离变换公式往往能生成不易出现不连续性的骨架,但克服距离变换的计算负担会导致实现过程比薄化方法复杂得多。

--------------图 11.14:(a) 血管阈值化图像。(b)通过细化得到的骨架,叠加在图像上(注意毛刺)。(c)去除毛刺40次后的结果。(d) 使用距离变换得到的骨架。-----------
11.3 边界特征描述符(Boundary Feature Descriptors)
我们首先讨论特征描述符,然后考虑描述区域边界的几种基本方法。
11.3.1 一些基本边界描述符(Some Basic Boundary Descriptors)
边界的长度是描述边界最简单的指标之一。边界上的像素数可以近似表示其长度。对于双向间距均为单位间距的链式编码曲线,垂直分量数和水平分量数之和加上
乘以对角分量数,即可得到其精确长度。如果边界由折线表示,则其长度等于各折线段长度之和。
一条边界 B 的直径定义为
(11-4)
其中,D 是一个距离度量(见 2.5 节),且 和
是边界上的点。直径的值以及连接两个端点构成该直径的线段之方向称为边界的主轴(长轴)(或最长弦)。即,若主轴由
和
定义,则主轴的长度和方向为
(11-5)
和
边界的次轴(短轴)(minor)(也称最长垂直弦)定义为垂直于长轴的直线,其长度使得穿过边界与两个坐标轴的四个交点的矩形能够完全包围该边界。上述矩形称为基本矩形或边界框,长轴与短轴之比称为边界的偏心率(eccentricity)。我们将在 11.4 节中给出一些该描述符的示例。
边界的曲率定义为斜率的变化率。通常,由于原数字边界往往局部“不规则”,因此很难获得该点的可靠曲率测量值。平滑处理可以有所帮助,但更粗略的曲率测量方法是使用相邻边界线段(已表示为直线)斜率之间的差异。多边形近似非常适合这种方法[参见图 11.8(c)],在这种情况下,我们只关注顶点处的曲率。当我们沿顺时针方向遍历多边形时,如果顶点 p 处的斜率变化为非负值,则称 p 为凸点(convex);否则,称 p 为凹点(concave)。通过使用斜率变化范围,可以进一步细化描述。例如,如果点 p 处的斜率绝对变化小于 10°,则可将其标记为“近似直线段的一部分”;如果绝对变化在 90° 到 ±30° 的范围内,则可将其标记为“角状”点。
基于斜率变化的描述符可以通过将边界表示为斜率链码 (SSC) 的形式轻松构建,如前所述(参见图 11.6)。一个特别有用且易于用 SSC 实现的边界描述符是曲折度(tortuosity),它是衡量曲线弯曲程度的指标。由 SCC 表示的曲线的曲折度 τ 定义为链元素绝对值的总和:
(11-6)
中 n 是 SCC 中的元素数量, 是代码中元素的值(斜率变化)。下一个示例说明了此描述符的一种用法。
例子 11.6 :使用斜率链代码描述曲折度。
血管形态学的一个重要指标是血管迂曲度。该指标可辅助计算机辅助诊断早产儿视网膜病变(ROP),这是一种影响早产儿的眼部疾病(Bribiesca [2013])。ROP会导致视网膜内异常血管增生(参见2.1节)。这种增生可能导致视网膜从眼球后部脱离,最终可能导致失明。
图 11.15(a) 显示了一张新生儿视网膜图像(称为眼底图像)。眼科医生根据视网膜血管的形态来诊断早产儿视网膜病变 (ROP) 并制定初始治疗方案。视网膜血管扩张和迂曲度增加是 ROP 的极有可能征象。图 11.15 中标记为 A ,B 和 C 的血管被选中,以展示 SCC 在量化血管迂曲度方面的鉴别能力(图中所示的每条血管都是一个细长的区域,而不是一条线段)。
提取每条血管的边界,并计算其长度(像素数)P 。为了使SCC比较有意义,将三个边界进行归一化处理,使每一个边界都具有相同数量的直线段,记为m 。然后,根据公式 L = m/P 计算线段长度L 。由此可知,每个SCC的元素数量为m - 1。SCC所表示曲线的曲折度τ 定义为链元素绝对值的总和,如公式(11-6)所示。
图 11.15(b) 中的表格显示了基于 51 个直线段(如上所述,n = m – 1 )的血管 A ,B 和 C 的 τ 值。这些迂曲度值与我们对这三条血管的视觉分析结果一致,表明 B 比 A 略微“复杂”,而 C 的弯曲和转弯最少。
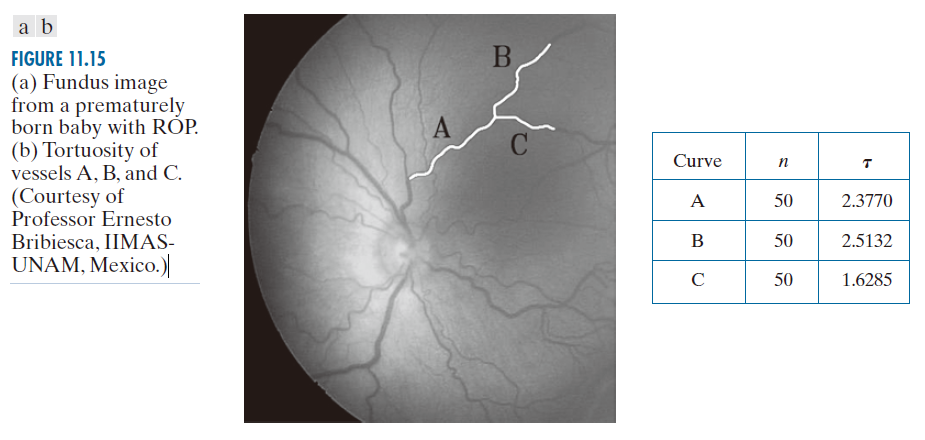
--------------图 11.15:(a) 早产儿视网膜病变(ROP)的眼底图像。(b) 血管A ,B 和 C 的迂曲。( 图片由墨西哥IIMASUNAM的Ernesto Bribiesca教授提供。)------------
11.3.2 形状编号(Shape Numbers)
基于图 11.3(a) 所示的四向编码,Freeman 链码边界的形状数定义为最小幅度的一阶差分。形状编号的阶数 n 定义为其表示中的数字位数。此外,对于闭合边界,n 为偶数,其值限制了可能的不同形状的数量。图 11.16 显示了所有阶数为 4,6 和 8 的形状,以及它们的链码表示、一阶差分和相应的形状编号。虽然四向链码的一阶差分与旋转无关(以 90°为增量),但编码边界通常取决于网格的方向。一种归一化网格方向的方法是将链码网格与上一节中定义的基本矩形的边对齐。
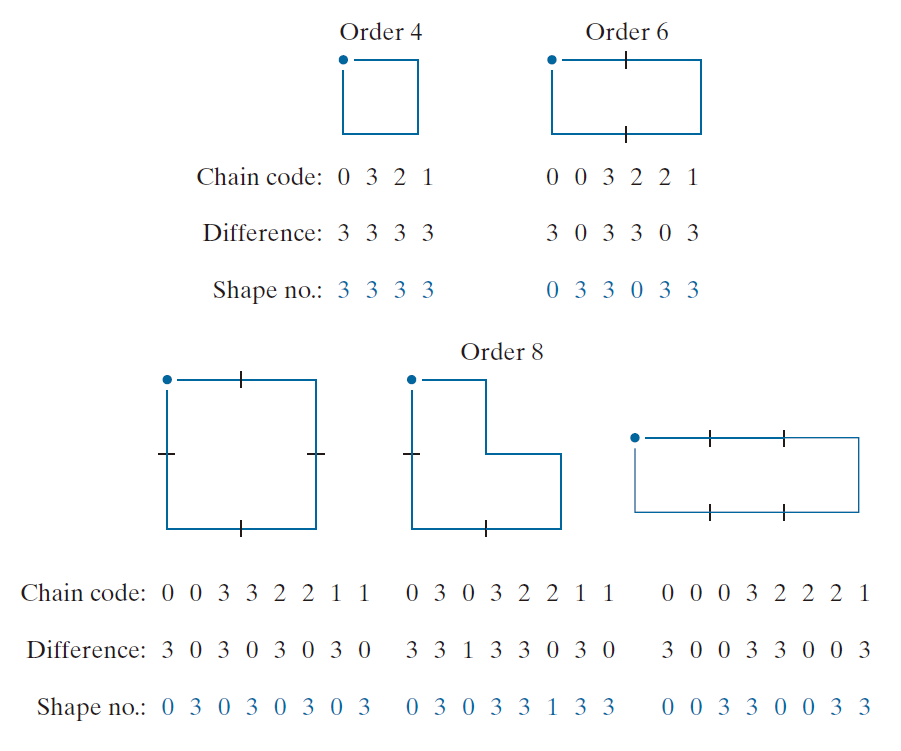
--------------------------------图 11.16:所有 4 阶,6 阶和 8 阶形状。方向来自图 11.3(a),点表示起点。-------------------------------------------------------
在实践中,对于所需的形状阶数,我们求得阶数为 n 的矩形,使其偏心率(定义见 11.4 节)与基本矩形的偏心率最接近,并使用该新矩形来确定网格尺寸。例如,如果 n = 12,则所有阶数为 12 的矩形(即周长为 12 的矩形)的尺寸分别为 2 × 4 , 3 × 3 和 1 × 5。如果对于给定的边界,2 × 4 矩形的偏心率与基本矩形的偏心率最匹配,则我们建立一个以基本矩形为中心的 2 × 4 网格,并使用 11.2 节中概述的步骤来获得Freeman链码。形状数由该链码的一阶差分得出。虽然由于网格间距的选择方式,所得形状编号的阶数通常等于 n ,但具有与此间距相当的凹陷的边界有时会产生阶数大于 n 的形状编号。在这种情况下,我们指定一个阶数小于 n 的矩形,并重复此过程,直到得到的形状数达到 n 阶。形状数的阶数从 4 开始,且始终为偶数,因为我们处理的是 4 连通性,并且要求边界是闭合的。
例子 11.7 :计算形状数。
假设图 11.17(a) 中边界的 n 值指定为 18。为了获得此阶的形状数,我们遵循前面讨论的步骤。首先,我们找到基本矩形,如图 11.17(b) 所示。接下来,我们找到最接近的阶数为 18 的矩形。这是一个 3 × 6 的矩形,需要对图 11.17(c) 中所示的基本矩形进行细分。链码方向与所得网格对齐。最后一步是获得链码并使用其一阶差分来计算形状编码,如图 11.17(d) 所示。
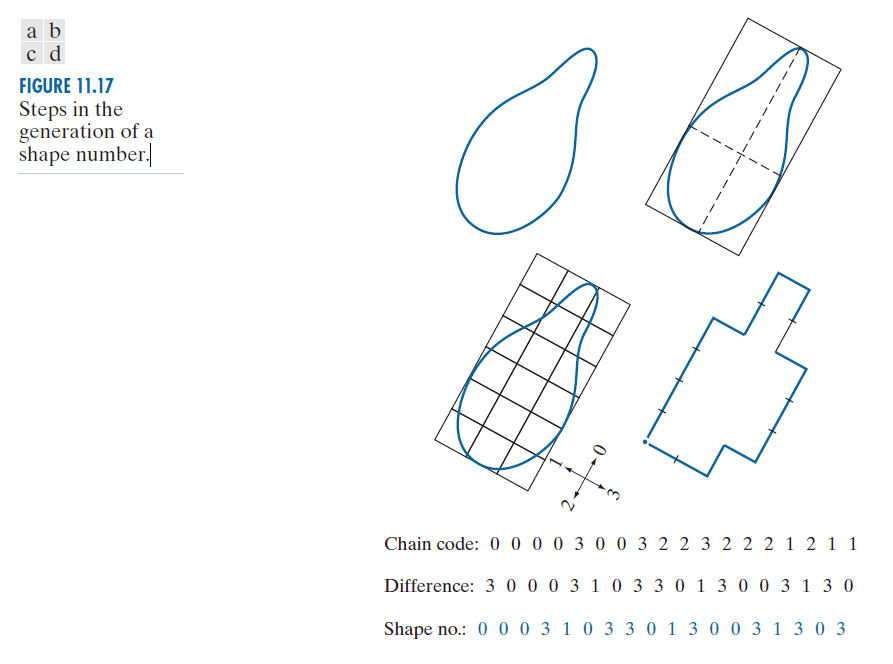
------------------------图 11.17:生成形状编号的步骤。------------------------
11.3.3 Fourier描述符(Fourier Descriptors)
图 11.18 表明,xy平面中的一个数字边界由 K 个点构成。从任一点 开始,坐标对
(例如) 在逆时针方向穿越边界时会遇到这种情况。这些坐标可以表述为
和
。使用这种记法,边界本身也可以表示成坐标序列 s(k) = [ x(k ) , y(k ) ] ( k = 0 , 1 ,2 , … , K - 1 ) 。此外,每一个坐标对都可以视为一个复数,其满足
(11-7)
即,x 轴被视为复数序列的实轴,y 轴被视为虚轴。虽然序列的解释被重新表述,但边界本身的性质并未改变。当然,这种表示方法有一个很大的优点:它将二维描述问题简化为一维描述问题。
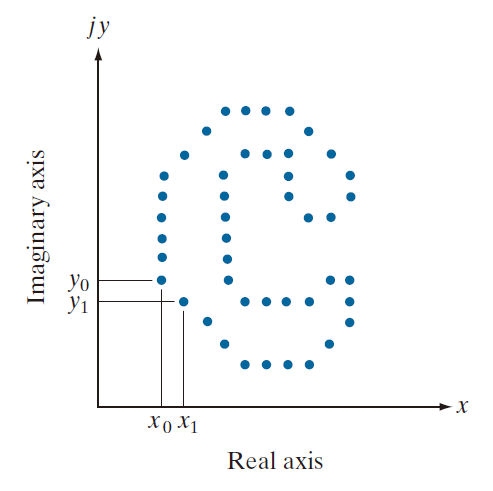
--------------------图 11.18:数字边界及其复数序列表示。点 和
是该序列中的(任意)前两个点。--------------------------------------------
从公式 (4-44) 我们知道,s(k) 的离散 Fourier 变换(DFT)是
(11-8)
复系数 a(u) 称为边界的 Fourier 描述符。这些系数的逆 Fourier 变换恢复 s(k) 。即,根据公式 (4-45),
(11-9)
我们从第四章可知,只要在式 (11-9) 中使用所有Fourier系数,逆变换就与原输入相同。然而,假设我们只使用前 P 个Fourier 系数,而不是所有 Fourier 系数。这与公式 (11-9) 中的 a(u) = 0 ( u > P - 1 ) 等价。结果是下述近似于 s(k) 的值:
(11-10)
尽管只使用了 P 项来获得 的每一个分量,但参数 k 的取值范围仍从 0 到 K – 1 。即,近似边界中存在的点的数量相同,但是每一个点的重建中使用的项数却减少了。
删除高频系数相当于使用理想低通滤波器对变换进行滤波。你在第 4 章中了解到,DFT 的周期性要求我们在滤波之前将其乘以 进行中心化。因此,我们在实现公式 (11-8) 时使用此方法,并在计算公式 (11-10) 中的逆变换时再次使用此方法反转中心化。由于 DFT 的对称性,边界及其逆变换中的点数必须为偶数。这意味着在计算逆变换之前移除(设为 0)的系数个数也必须为偶数。由于变换已中心化,为了保持对称性,我们将变换两端系数个数的一半设为 0。当然,DFT 及其逆变换是使用 FFT 算法计算的。
回顾第四章关于 Fourier 变换的讨论,高频分量负责精细的细节,而低频分量决定整体形状。因此,在公式(11-10)中,P 的值越小,边界上丢失的细节就越多,如下例所示。
例子 11.8 :使用 Fourier 描述符。
图 11.19(a) 显示了一条人类染色体的边界,该边界由 2868 个点组成。相应的 2868 个傅里叶描述符是使用公式 (11-8) 计算得到的。本例的目的是检验使用较少的傅里叶描述符重建边界的效果。图 11.19(b) 显示了使用公式 (11-10) 中 2868 个描述符的一半重建的边界。可以看出,该边界与原始边界之间没有明显的差异。图 11.19(c) 至 (h) 分别显示了使用 2868 个 Fourier描述符的 10% ,5% , 2.5% , 1.25% , 0.63% 和 0.28% 重建的边界。四舍五入到最接近的偶数后,这些百分比分别为 286 ,144 , 72 , 36 , 18 和 8 个描述符。关键在于,仅用 18 个描述符(相当于原始 2868 个描述符的 0.6% ) 就足以保留原始边界的主要形状特征:四个长凸起和两个深凹陷。使用 8 个描述符得到的图 11.19(h) 是不可接受的,因为主要特征丢失了。进一步减少到 4 个和 2 个描述符将分别导致椭圆和圆(参见问题 11.18 ) 。

-------------------图 11.19:(a) 人类染色体边界(2868 个点)。(b)-(h) 分别使用 1434 , 286 ,144 ,72 , 36 , 18 和 8 个Fourier描述符重建的边界。这些数字分别约为 2868 个点的 50% ,10% ,5% ,2.5% ,1.25% ,0.63% 和 0.28% 。图像 (b)-(h) 以负片形式显示,以便更清晰地显示边界。-------------------------------------------------
如前例所示,几个Fourier描述符即可捕捉边界的本质特征。这一特性十分宝贵,因为这些系数蕴含着形状信息。因此,我们可以利用这些系数构建特征向量,从而区分不同的边界形状,这将在第12章中详细讨论。
我们曾多次强调,描述符应尽可能对平移、旋转和缩放不敏感。在结果取决于点处理顺序的情况下,描述符还应对起点不敏感。Fourier 描述符并非直接对这些几何变化不敏感,但这些参数的变化可以与描述符上的简单变换相关联。例如,考虑旋转,并回顾基本的数学分析,将复平面上的一个点绕原点旋转角度 θ ,可以通过将该点乘以 来实现。对 s(k) 的每一个点都进行这样的操作就围绕原点旋转了整个序列。这个旋转序列
, 其 Fourier 描述符是
(11-11)
因此,通过乘以一个常量 实现的旋转对所有系数的影响是相同的。
表 11.1总结了经历了旋转、平移、缩放和起始点变化的边界序列 s(k ) 的Fourier描述符。符号 , 因此,旋转
表明,重定义(平移)这个序列为
(11-12)
注意,平移对描述符无影响,只不过对于 u = 0 ,描述符值为 δ(0) 。最后,表达式 意味着,重定义序列为
(11-13)
其将序列的起点从 k = 0 改变到 。表 11.1 的最后一项表明,起点的变化以一种不同(但已知)的方式影响描述符,即,乘以 a(u) 的项取决于 u 。

11.3.4 统计矩(或统计动差) (Statistical Moments)
单变量统计矩是适用于二维边界的一维表示的有用描述符,例如特征线。为了了解如何实现这一点,请考虑图 11.20,该图显示了图 11.10(b) 中的特征线的采样,并将其视为单变量 r 的普通离散函数 g(r)。
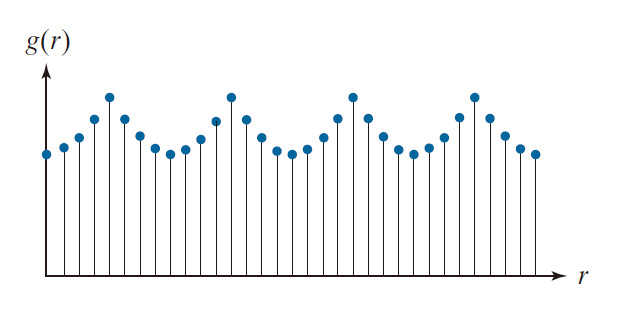
-----------------------------图 11.20:从图 11.10(b) 中采样的特征视为一个单变量的普通离散函数。-------------------------------------------------------------
假设我们将 g 的幅度(amplitude) 视为一个离散随机变量 z 并构成一个幅度直方图 ( i = 0 ,1 ,2 ,… , A – 1 ) ,其中 A 是划分幅值尺度的离散振幅增量的数量。若 p 是正规化的,因此,其元素和等于 1 ,则
是所出现的强度值
的一个概率估计。然后从公式 (3-24) 可推导出 z 的关于其均值的第 n 个矩是
(11-14)
其中,
(11-15)
在这些公式中,K 都是边界上点的数量。而 直接与特征 g(r) 的形状相关。例如,第二个统计矩
度量了曲线关于 r 的均值的离散性,第二个统计矩
度量了曲线关于 r 的均值的对称性。
尽管统计矩常用于表征特征,但它们并非唯一用于此用途的描述符。例如,另一种方法是计算 g(r) 的一维离散 Fourier变换,得到其频谱,并使用前几个分量作为描述符。统计矩相对于其他技术的优势在于其实现简单直接,并且能够对特征(以及由此推断的边界)形状进行“物理”解释。这种方法对旋转不敏感,是因为只要边界上的起始点始终相同,特征就与旋转无关。可以通过缩放 g 和 r 的值来实现尺寸归一化(正规化)。
11.4 区域特征描述符(Region Feature Descriptors)
就像我们讨论边界一样,我们首先从一些基本的区域描述符开始讨论区域特征。
11.4.1 一些基本描述符(Some Basic Descriptors)
区域的长轴和短轴,以及边界框(bounding box)的概念,与之前对边的这些概念定义相同。一个区域的面积定义为区域内的像素数。一个区域的周长(perimeter)是其边界的长度。当面积和周长用作描述符时,通常只有在归一化后才有意义(例 11.9 展示了这种用法)。这两个描述符更常见的用途是度量区域的紧致度(compactness),紧致度定义为周长的平方除以面积:
(11-18) 紧致度 =
这是一个无量纲的度量,对于圆来说为 4π(其最小值),对于正方形来说为 16 。类似的无量纲度量是圆度(circularity)(也称圆形度(roundness)),定义为
(11-19) 圆度 =
对于圆,该描述符的值为 1(最大值);对于正方形,该描述符的值为 π/4。请注意,这两个度量值与大小、方向和平移无关。另一个基于圆的度量是有效直径(effective diameter):
(11-20)
这是与待处理区域面积 A 相同的圆的直径。该度量既非无量纲,也与区域大小无关,但它与方向和平移无关。可以通过将其除以给定应用中预期的最大直径来对其进行归一化并使其无量纲化。
类似于我们定义紧致度和圆度相对于圆的方式,我们将区域相对于椭圆的离心率或偏心率(eccentricity)定义为与该区域具有相同二阶中心矩的椭圆的离心率。对于一维数据,二阶中心矩即为方差。对于二维离散数据,我们需要考虑每个变量的方差以及它们之间的协方差。这些是协方差矩阵的组成部分,该矩阵使用以下公式 (11-21) 从样本中估计得出,其中样本是表示数据坐标的二维向量。
图 11.21(a) 显示了一个标准形式的椭圆(即长轴和短轴与坐标轴对齐的椭圆)。这种椭圆的离心率定义为焦点之间的距离(图 11.21 中的 2c)与其长轴长度(2a)之比,即 2c/2a = c/a 。即,
离心率 =
然而,我们感兴趣的是与给定二维区域具有相同二阶中心矩的椭圆的离心率,这意味着我们的椭圆可以具有任意方向。直观地说,我们试图做的是用一个椭圆区域来近似我们的二维数据,该椭圆区域的轴线与数据的主轴对齐,如图 11.21(b) 所示。正如你将在 11.5 节(参见例 11.17)中了解到的,主轴是数据的协方差(covariance)矩阵 C 的特征向量,该协方差矩阵由下式给出:
(11-21)
其中 是一个二维向量,其元素是区域中一个点的两个空间坐标,K 是点的总数,z 是均值向量:
(11-22)
C 的主对角线元素是该区域中各点坐标值的方差,非对角线元素是它们的协方差。
与区域主轴方向相同的椭圆可以解释为二维 Gauss函数与 xy 平面的交线。椭圆的轴线方向也与协方差矩阵的特征向量方向一致,并且椭圆中心到其长轴和短轴交点的距离分别等于协方差矩阵的最大特征值和最小特征值,如图 11.21(b) 所示。参考图 11.21 以及上述椭圆的离心率公式,我们可以类比得出,与区域具有相同二阶矩的椭圆的离心率为
(11-23) 离心率 =
对开圆形区域, 而离心率是 0 。对于一条直线,
而离心率是1 。因此,这个描述符的取值范围是 [ 0 ,1 ] 。
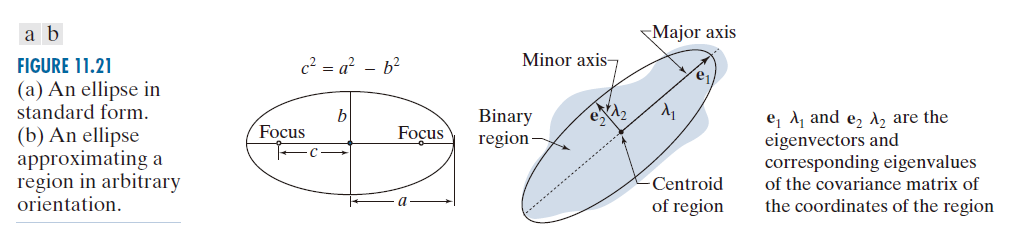
译注:
centroid——形心
eigenvector ——特征向量
eigenvalue ——特征值
covariance——协方差
-----------图 11.21:(a)标准型椭圆。(b) 在任意方向上近似区域的椭圆。---------
例子 11.9 :特征描述符之比较。
图 11.22 显示了几个区域形状的上述描述符的值。由于数字化圆会引入计算误差,并且我们将边界长度近似为其元素数量,因此圆的描述符均未完全等于其理论值。正方形的离心率恰好为 0,因为未旋转的正方形与采样网格完美对齐。正方形的其他两个描述符也接近其理论值。
图 11.22 前两行列出的数值包含相同的信息。例如,我们可以看出,与其他形状相比,星形区域的紧致度和圆度都较低。同样,从列出的数值很容易看出,泪滴状区域的离心率最大,但很难通过紧致度或圆度来将其与其他形状区分开来。
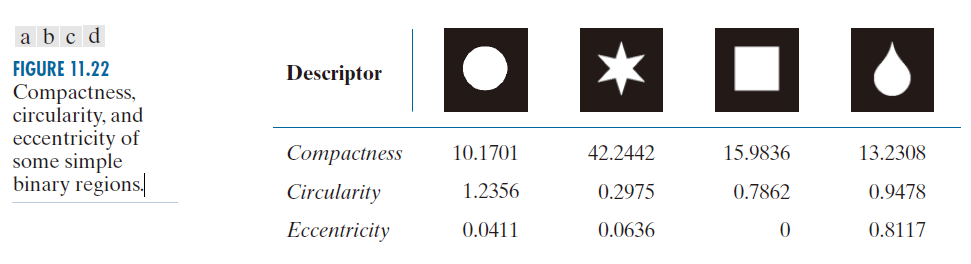
译注:
Compactness —— 紧致度
Circularity —— 圆度
Eccentricity —— 离心率
---------------图 11.22:一些简单双星区域的紧致度、圆度和离心率。------------
正如我们在11.1节中讨论的,特征描述符通常以特征向量的形式排列,以便进行后续处理。图11.23展示了图11.22中描述符的特征空间。特征空间中的每个点都“封装”了每个对象的三个描述符值。虽然我们可以从图中的描述符值看出,圆形和正方形比其他两个对象更相似,但请注意,在特征空间中,这一事实更加清晰。你可以想象,如果我们有多个受噪声污染的样本,区分对应于正方形或圆形的向量(点)可能会变得很困难。相比之下,星形和泪滴形对象彼此之间以及与圆形和正方形都相距甚远,因此它们在噪声存在的情况下不太可能被错误分类。特征空间将在第12章讨论图像模式分类时发挥重要作用。
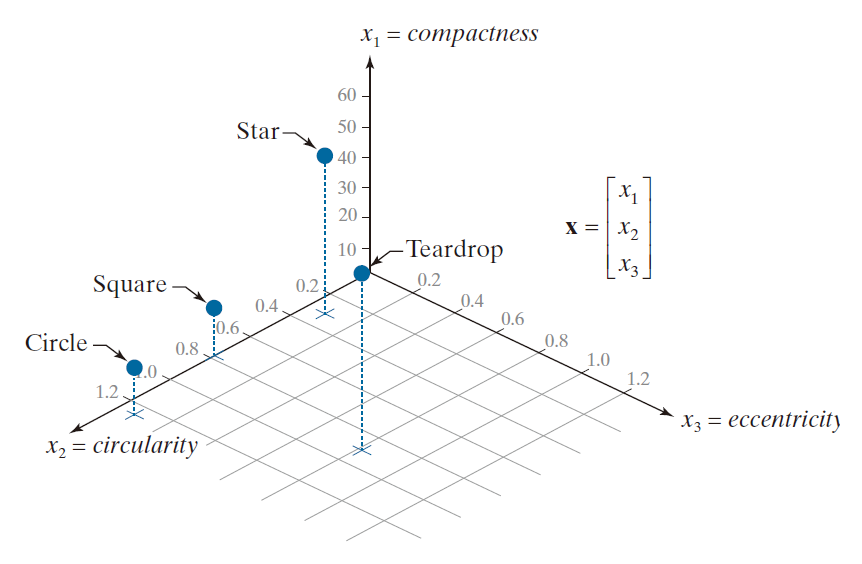
--------------------------------图 11.23:图 11.22 中的描述符在三维特征空间中的表示。图中所示的每一个点对应于一个特征向量,该特征向量的三个分量分别是图 11.22 中对应的三个描述符。-----------------------------------------------------------
例子 11.10 :使用区域特征。
即使是像归一化面积这样简单的描述符,对于从图像中提取信息也十分有用。例如,图 11.24 显示了一张美洲的夜间卫星红外图像。正如我们在 1.3 节中讨论的,这类图像提供了全球人类居住地的概览。用于采集这些图像的成像传感器能够探测可见光和近红外辐射,例如灯光、火灾和火炬。图像旁边的表格显示了(从上到下按区域排列)所有四个区域中白色区域(灯光)占总光照面积的比例。像这样的简单测量可以提供例如各区域电力消耗的相对估计值。可以通过按各区域的陆地面积、人口数量等进行归一化来优化数据。
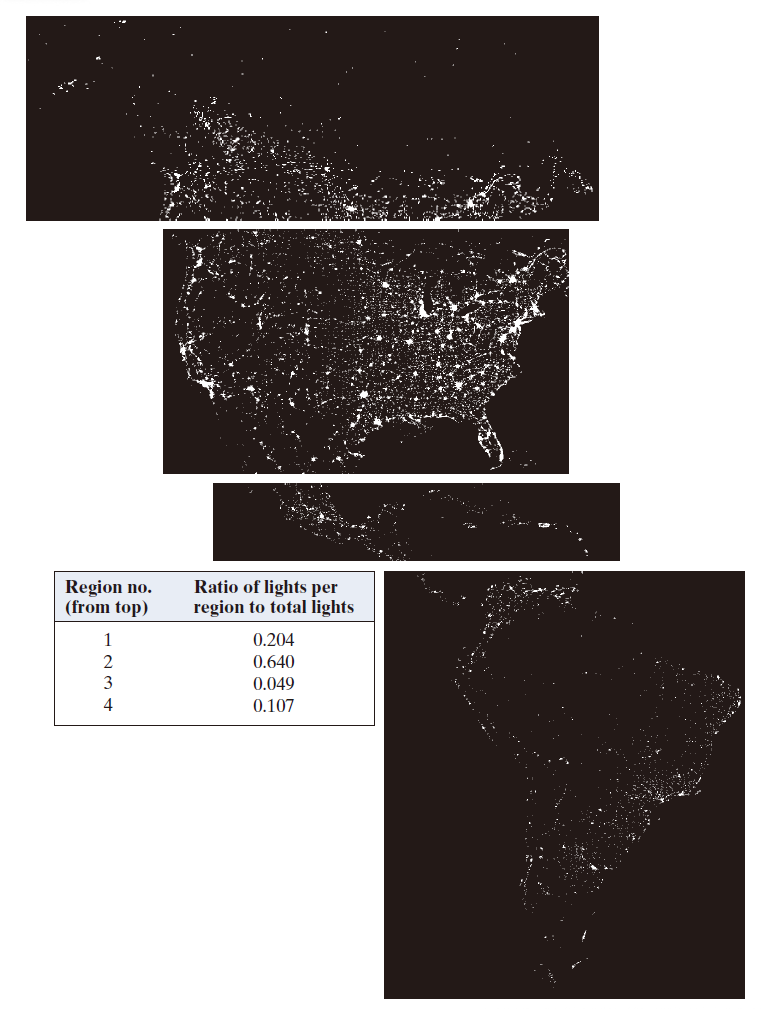
-----------------------------图 11.24:美洲夜间红外图像。(图片由美国国家海洋和大气管理局提供。)-------------------------------------------------------------
11.4.2 拓扑描述符(Topological Descriptors)
拓扑学研究的是图形在不受任何形变影响时的性质,前提是图形没有撕裂或连接(有时也称为橡皮膜变形(rubber-sheet distortions))。例如,图 11.25(a) 显示了一个有两个孔的区域。显然,定义为区域中孔数量(即拓扑描述符)的拓扑描述符不会受到拉伸或旋转变换的影响。然而,如果该区域撕裂或折叠,孔的数量就会发生变化。由于拉伸会影响距离,因此拓扑性质不依赖于距离的概念或任何隐含地基于距离度量概念的性质。
另一个可用于区域描述的拓扑性质是图像或区域的连通分量数。图 11.25(b) 显示了一个具有三个连通分量的区域。图中孔洞数 H 和连通分量数 C 可用于定义 Euler 数 E :
(11-24) E = C – H
Euler数也是一种拓扑性质。例如,图 11.26 中所示的区域,其Euler数分别为 0 和 -1,因为“A”有一个连通分支和一个孔,“B”有一个连通分支但有两个孔。
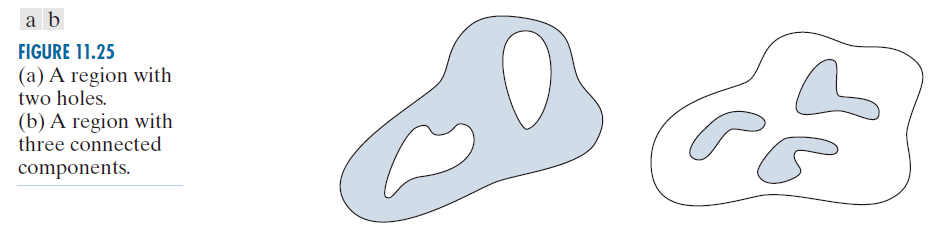
-----------------------------图 11.25:(a) 一个有两个孔的区域。(b) 一个由三个连通部分组成的区域。-----------------------------------------------------------
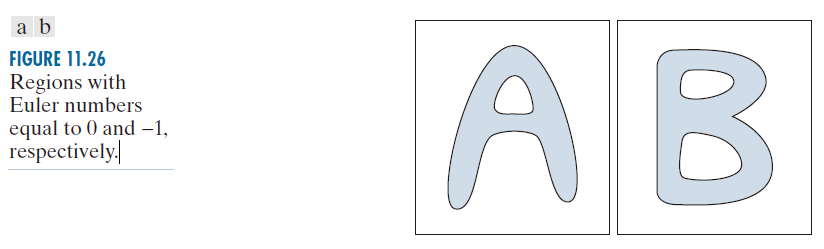
---------------------图 11.26:Euler数分别为 0 和 -1 的区域。-----------------
由直线段表示的区域(称为多边形网络)在Euler数方面具有特别简单的解释。图 11.27 显示了一个多边形网络。将此类网络的内部区域分类为面和孔通常很重要。用 V 表示顶点数,Q 表示边数,F 表示面数,可以得到以下关系,称为 Euler 公式:
(11-25) V – Q + F = C – H
根据公式 (11-24),可以将其表示为
(11-26) V – Q + F = E
图 11.27 中的网络有 7 个顶点、11 条边、2 个面、1 个连通区域和 3 个孔;因此Euler数为 –2 ( 即 7 – 11 + 2 = 1 – 3 = –2 ) 。
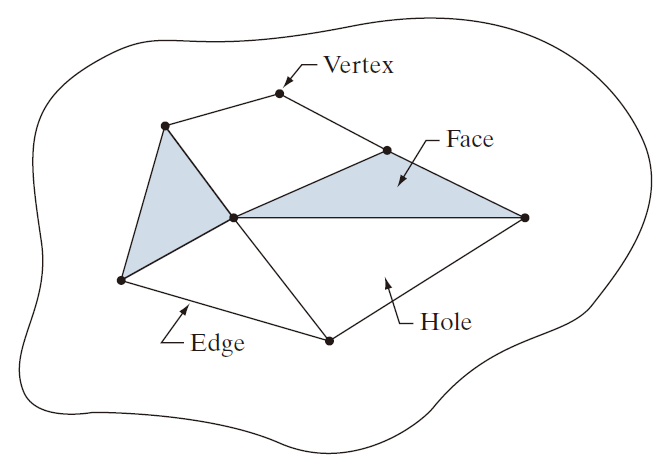
---------------------图 11.27:图 11.27 包含多边形网络的区域。-----------------
例子 11.11 :提取并表征一巾分割图像中的最大特征。
图 11.28(a) 显示了一张由 NASA LANDSAT 卫星拍摄的华盛顿特区 512 × 512 像素、8 位图像。该图像位于近红外波段(详见图 1.10)。假设我们想要仅使用这张图像来分割河流(而不是使用多张多光谱图像,后者会简化任务,你将在本章后面看到)。由于河流相对于图像的其他部分而言是一个较暗且均匀的区域,因此阈值分割显然是一种可行的方法。图 11.28(b) 显示了使用河流分割成不连续区域之前的最高阈值对图像进行阈值分割的结果。该阈值是手动选择的,目的是为了说明在这种情况下,如果不将图像的其他区域也包含在阈值分割结果中,就无法单独分割出河流。
图 11.28(b) 中的图像有 1591 个连通分量(使用 8 连通性获得),其Euler数为 1552,由此我们推断孔洞的数量为 39 。图 11.28(c) 显示了像素数最多的连通分量(8479)。这正是我们想要的结果,我们已经知道它无法通过阈值分割从图像中单独提取出来。请注意这个结果的清晰度。刚刚找到的连通分量所定义的区域内的孔洞数量可以得出河流中陆地的数量。如果我们想要进行一些测量,例如测量河流每条支流的长度,我们可以使用连通分量的骨架 [图 11.28(d)] 来进行测量。
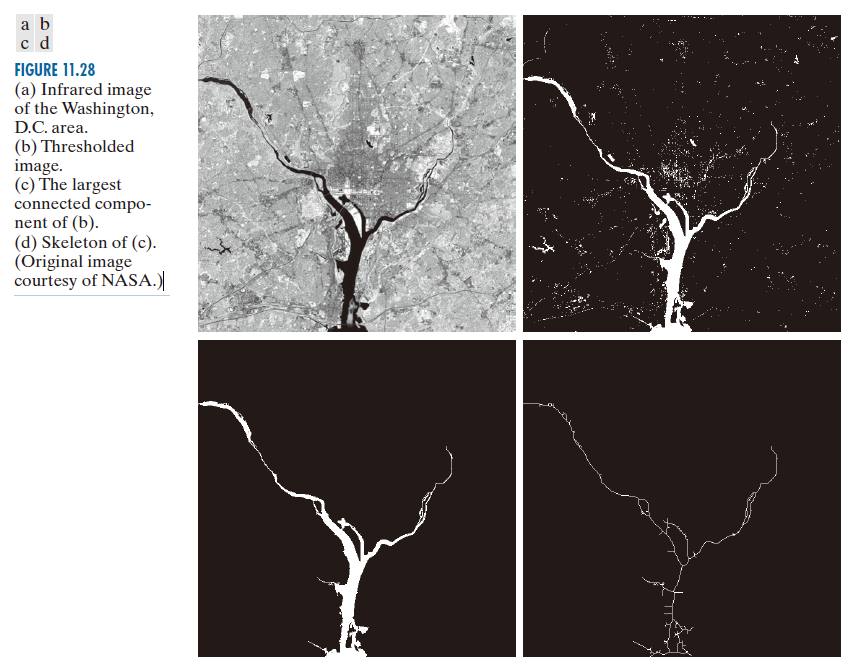
-------------------图 11.28:(a)华盛顿特区地区的红外图像。(b) 阈值处理后的图像。(c) (b)的最大连通分量。(d) (c)的骨架图。(原图由NASA提供。)------------------
11.4.3 纹理(Texture)
区域描述的一个重要方法是量化其纹理成分。虽然纹理没有正式的定义,但直观上,这种描述符可以衡量诸如平滑度、粗糙度和规则性等属性(图 11.29 展示了一些示例)。本节将讨论用于描述区域纹理的统计方法和频谱方法。统计方法可以将纹理表征为平滑、粗糙、颗粒状等等。频谱技术基于Fourier频谱的特性,主要用于通过识别频谱中的高能窄峰来检测图像中的全局周期性。

---------------------------图11.29:白色方块从左至右分别标记了光滑、粗糙和规则的纹理。这些是超导体、人体胆固醇和微处理器的光学显微镜图像。(图片由佛罗里达州立大学Michael W. Davidson博士提供。)--------------------------------------------
11.4.3.1 统计法(Statistical Approaches)
描述纹理的最简单方法之一是使用图像或区域强度直方图的统计矩。设 z 为表示强度的随机变量,并令 ( i = 0 , 1 , 2 , … ,L – 1 ) 为相应的正规直方图,其中,L 是不同的强度等级数。根据公式 (3-24) , z 关于均值第 n 个矩是
(11-27)
其中,m 是 z 的均值(即,图像或区域的平均强度):
(11-28)
由公式(11-27)可知, 和
。这第二个统计矩 [ 方差
] 在纹理表征中特别重要。它是一种强度对比度度量,可用于建立相对强度平滑度的描述符。例如,该度量
(11-29)
对于常强度(在这些区域方差是 0 )区域是 0 ,而对于较大的 值其接近于 1 。由于灰度图像(例如,取值范围为 0 到 255 的图像)的方差值往往较大,因此最好将方差归一化到 [0, 1] 区间,以便在公式 (11-29) 中使用。仅需在公式(11-29)中用
除
即可实现归一化。标准偏差 σ(z) 也经常用于度量纹理,因为其值更加直观。
正如 2.6 节所讨论,第三个统计矩 是直方图倾斜度(skewness)的一个度量,而第四个统计矩
是其相对平坦性的一个度量,五阶及更高阶矩与直方图形状的关联性并不强,但它们确实能进一步定量区分纹理成分。一些基于直方图的有用纹理度量包括一致性(uniformity)度量,其定义为
(11-30)
以及平均熵(average entropy)的度量(正如你可能从信息论中了解到的那样)定义为
(11-31)
由于 p 的值在 [0, 1] 范围内且它们的总和等于 1,因此描述符 U 的值在所有强度级别相等(最大一致)的图像中最大,并在此基础上递减。熵(entropy)是变化性(variability)的度量,对于一致的图像,熵为 0 。
例子 11.12 :基于直方图的纹理描述符。
表 11.2 列出了图 11.29 中三种纹理类型对应的上述描述符的值。均值仅描述每一个区域的平均强度,只能粗略地表示强度,而不能反映纹理。标准差则更具信息量;数值清晰地表明,第一种纹理的强度变化明显小于其他两种纹理(更平滑)。粗糙纹理在该指标中表现得尤为明显。正如预期的那样,R 值也适用同样的结论,因为它本质上与标准差衡量的是相同的内容。三阶矩可用于确定直方图的对称性,以及直方图是向左偏(负值)还是向右偏(正值)。这可以表明强度水平是偏向均值的暗侧还是亮侧。就纹理而言,从三阶矩获得的信息仅在测量值之间的差异较大时才有用。观察一致性度量,我们再次得出结论:第一个子图像更平滑(比其他子图像更一致),而最随机的子图像(一致性最低)对应于粗糙纹理。最后,我们发现熵值随着一致性的降低而增加,这使我们得出与一致性度量相同的关于区域纹理的结论。第一个子图像的强度变化最小,而粗糙图像的强度变化最大。规则纹理在这两个度量方面都介于两者之间。

------------------------表 11.2:图 11.29 中子图像的统计纹理测量。------------
仅使用直方图计算纹理特征无法提供像素间空间关系的信息,而这对于描述纹理至关重要。将此类信息融入纹理分析过程的一种方法,是不仅考虑强度分布,还要考虑图像中像素的相对位置。
令 Q 为一个算子,它定义了两个元素之间的相对位置,并考虑一幅具有 L 个可能强度级别的图像 f 。令 G 为一个矩阵,其元素 为出现在 f 中由 Q 所指定的位置处强度为
和
的像素对的次数,其中 , 1 ≤ i , j ≤ L 。按这种方式所构成的一个矩阵称为一个灰度级(或强度级)共现矩阵(co-occurrence matrix),在意义明确的情况下,G可简称为 共现矩阵 。
图 11.30 展示了如何使用 L = 8 和位置算子 Q 构建共现矩阵的示例,其中 Q 定义为“紧邻右侧的一个像素”(即,像素的邻域定义为其右侧的像素)。左侧数组是一个小图像,右侧数组是矩阵 G 。我们可以看到,G 的元素 (1,1) 为 1,因为在 f 中,值为 1 的像素在其右侧紧邻的像素也为 1 的情况只出现一次。类似地,G 的元素 (6,2) 为 3,因为在 f 中,值为 6 的像素在其右侧紧邻的像素为 2 的情况出现了三次。G 的其他元素也以类似的方式计算。如果我们把 Q 定义为“向右移动一个像素,向上移动一个像素”,那么 G 中的位置 (1,1) 就应该是 0 ,因为 f 中不存在一个像素值 1 且其相邻像素值也为 1 的情况,且该位置由 Q 定义。另一方面,G 中的位置 (1,3),(1,5) 和 (1,7) 都应该是 1,因为 f 中存在一个像素值 1,其相邻像素值分别为 3 , 5 和 7,且该位置由 Q 定义——每种情况各出现一次。作为练习,你应该使用 Q 的这个定义来计算 G 的所有元素。
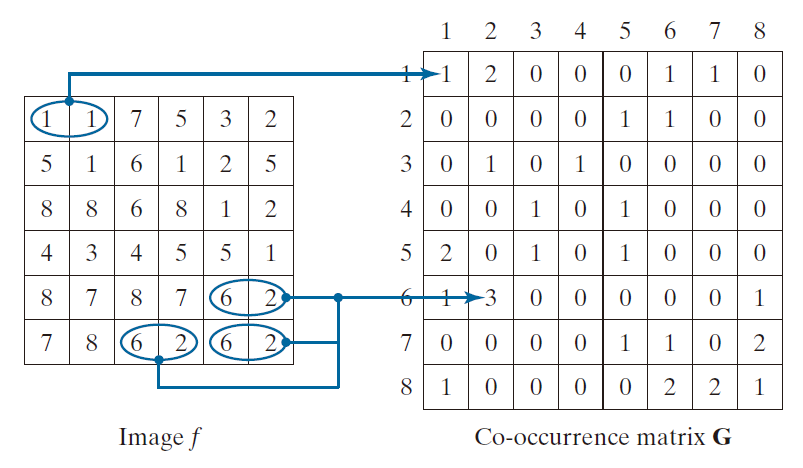
-----------------------图 11.30:构建共现矩阵。------------------------------
图像中可能的强度级别数量决定了矩阵 G 的大小。对于 8 位图像( 256 个可能的强度级别),G 的大小为 256 × 256。当只处理一个矩阵时,这不成问题,但正如你将在示例 11.13 中看到的那样,共现矩阵有时会在序列中使用。一种减少计算量的方法是将强度量化为几个频段,以保持 G 的大小在可控范围内。例如,对于 256 个强度级别,我们可以将前 32 个强度级别设为 1,接下来的 32 个设为 2,依此类推。这将得到一个 8 × 8 大小的共现矩阵。
满足 Q 的像素对总数 n 等于图 G 中所有元素的总和(在图 11.30 的示例中,n = 30 )。则,量
是一个满足 Q 将有值 的点对之概率估计。这些概率值范为是 [ 0 ,1 ] 而其和为 1 :
其中,其中,K 是方阵 G 的行维数和列维数。
由于 G 依赖 Q ,通过选择合适的定位算子并分析 G 的元素,可以检测强度纹理模式的存在。表 11.3 列出了一组可用于表征 G 内容的描述符。相关性描述符(第二行)中使用的量定义如下:
和
若我们令
和
则前述公式可以写成
和
和
参考公式 (11-27),(11-28) 及其解释,我们可以看出, 是沿归一化图 G 的行计算的均值,
是沿列计算的均值。类似地,
和
分别是沿行和列计算的标准差(方差的平方根)。这些项均为标量,与图 G 的大小无关。
谨记,在研究表 11.3 时,“邻域”的概念取决于 Q 的定义方式(即,邻域不一定是相邻的),并且 仅仅是强度为
和
的像素在 f 中相对于 Q 指定位置出现的次数的归一化计数。因此,我们在这里所做的只是试图在这些计数中寻找图案(纹理)。
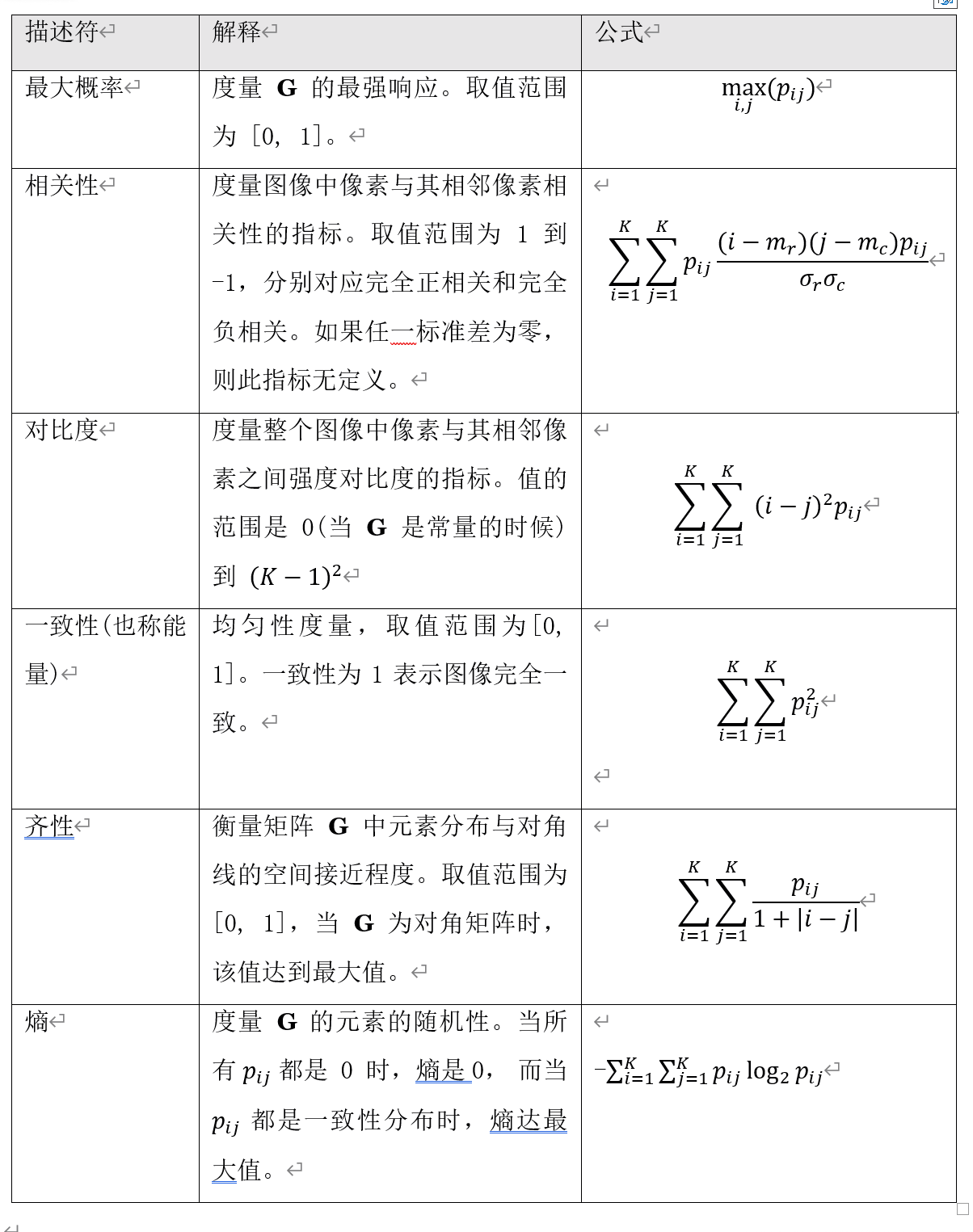
-------------------表 11.3:用于描述大小为 K × K 的共现矩阵的描述符。项 是 G 的第 ij 项除以 G 的元素之和。-----------------------------------------------
例子 11.13 :使用描述符表征共现矩阵。
图 11.31(a) 至 (c) 分别展示了由随机像素图案、水平周期性(正弦)像素图案和混合像素图案构成的图像。本例有两个目的:(1) 展示表 11.3 中描述符在三个共现矩阵 ,
和
中的值,这三个矩阵(从上到下)分别对应于上述图像;(2) 说明如何使用共现矩阵序列来检测图像中的纹理图案。

-----------------------图 11.31:图像的像素分别具有(a)随机, (b)周期性和(c)混合纹理图案。每幅图像的大小为263×800像素。--------------------------------
图 11.32 显示了以图像形式呈现的共现矩阵 ,
,和
。这些矩阵是使用 L = 256 和位置运算符“紧邻右侧一个像素”获得的。这些图像中坐标 ( i, j ) 处的值表示强度为
和
的像素对在 f 中由 Q 指定的位置出现的次数。因此,考虑到图 11.32(a) 的来源图像的性质,它是一张随机图像也就不足为奇了。
图 11.32(b) 更有趣。首先,它具有关于主对角线的对称性。由于正弦波的对称性,像素对 的计数与像素对
的计数相同,从而形成对称的共现矩阵。
的非零元素是稀疏的,因为水平正弦波中水平相邻像素之间的值差异相对较小。理解这些概念时,记住数字化正弦波是一个阶梯,每个阶梯的高度和宽度取决于正弦波的频率以及用于表示该函数的振幅级数,这一点会有所帮助。
图 11.32(c) 中共现矩阵 的结构更为复杂。高计数值也聚集在主对角线上,但它们的分布比
更为密集,这表明图像的强度值变化丰富,但相邻像素之间的强度突变较少。观察图 11.32(c),我们发现存在大片强度变化较小的区域。强度突变出现在物体边界处,但相对于大片区域的中等强度突变而言,这些突变的计数较低,因此被图像显示器同时显示高值和低值的能力所掩盖,正如我们在第 3 章中所讨论的。
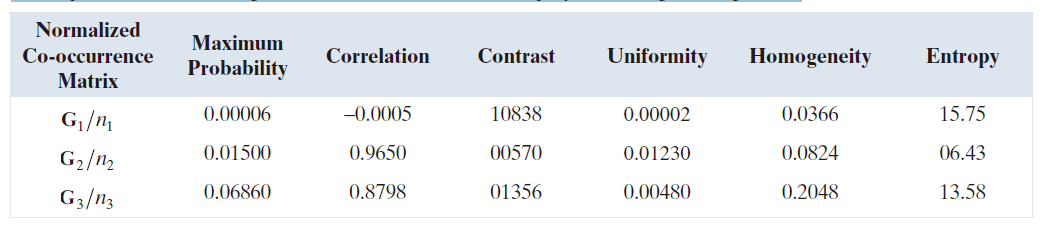
上述观察是定性的。为了量化共现矩阵的“内容”,我们需要表 11.3 中所示的描述符。表 11.4 显示了针对图 11.32 中的三个共现矩阵计算的这些描述符的值。为了使用这些描述符,必须对共现矩阵进行归一化,即将其元素之和除以归一化系数,如前所述。表 11.4 中的条目与图 11.31 中的图像及其在图 11.32 中对应的共现矩阵的预期结果一致。例如,考虑表 11.4 中的“最大概率”列。最高概率对应于第三个共现矩阵,这表明该矩阵的计数(相对于 Q 中的位置,图像中出现的像素对数量最多)高于其他两个矩阵。这与我们对 的分析结果一致。第二列表明,相关性最高的是
,这说明第二幅图像中的强度值高度相关。图11.31(b)中正弦图案的重复性解释了这一现象。值得注意的是,
的相关性几乎为零,表明相邻像素之间几乎没有相关性,这是随机图像 ( 例如图11.31(a)中的图像) 的特征 。

----------------------图 11.32:256 × 256 共现矩阵 ,
和
,从左到右分别对应于图 11.31 中的图像。------------------------------------------------
译注:
Homogeneity —— 齐性
Entropy —— 熵
---------表 11.4:使用图 11.32 中以图像形式显示的共现矩阵计算描述符。----------
的对比度描述符最高,
的对比度描述符最低。由此可见,图像的随机性越低,其对比度往往越低。我们可以通过研究图 11.32 中的矩阵来理解其原因。
项是 1 ≤ I , j ≤ L 的整数差,因此对于任何 G 都相同。因此,归一化共现矩阵元素的概率是决定对比度值的因素。尽管
的最大概率最低,但其他两个矩阵的零概率或接近零的概率却多得多(图 11.32 中的暗区)。由于 G/n 的值之和为 1,很容易理解为什么对比度描述符会随着随机性的增加而增加。
其余三个描述符的解释方式类似。一致性随概率平方值的增加而增加。因此,图像中的随机性越低,一致性描述符的值就越高,如表 11.4 的第五列所示。齐性度量 G 值相对于主对角线的集中程度。分母项 (1 + |i - j|) 的值对于所有三个共现矩阵都相同,并且随着 i 和 j 的值越来越接近(即越来越接近主对角线),分母项的值会减小。因此,主对角线附近概率值(分子项)最高的矩阵将具有最高的齐性值。正如我们之前讨论的,这样的矩阵对应于具有“丰富”灰度级内容和强度值缓慢变化区域的图像。表 11.4 的第六列中的条目与这种解释一致。
表格最后一列的数值是共现矩阵中随机性的度量,进而可以转化为对应图像中随机性的度量。正如预期的那样, 的值最高,因为它源自完全随机的图像。其他两个数值的含义显而易见。值得注意的是,
的熵值接近理论最大值 16 (
) 。图 11.31(a) 中的图像由一致性噪声组成,因此每一个强度级别的出现概率大致相等,这符合表 11.3 中最大熵的条件。
到目前为止,我们处理的都是单幅图像及其共现矩阵。假设我们想要“发现”(无需查看图像)这些图像中是否存在包含重复成分(即周期性纹理)的区域。实现这一目标的一种方法是检查从这些图像中通过增加相邻矩阵之间的距离而得到的共现矩阵序列的相关性描述符。如前所述,在处理共现矩阵序列时,通常会对强度值进行量化,以减小矩阵大小和相应的计算量。以下结果是使用 L = 8 得到的。
图 11.33 显示了相关性描述符随水平“偏移量”(即相邻像素之间的水平距离)变化的曲线图,偏移量从 1(相邻像素)到 50。图 11.33(a) 显示所有相关性值都接近于 0,表明在随机图像中未发现此类模式。图 11.33(b) 中相关性的形状清晰地表明输入图像在水平方向上呈正弦曲线。请注意,相关函数值初始较高,然后随着相邻像素之间距离的增加而减小,之后又重复出现。
图 11.33(c) 显示,与电路板图像相关的相关性描述符最初呈下降趋势,但在偏移距离为 16 像素处出现一个强峰值。对图 11.31(c) 中的图像进行分析表明,上部焊点形成一个重复图案,间距约为 16 像素(见图 11.34)。下一个主要峰值出现在偏移距离为 32 像素处,由相同的图案引起,但峰值幅度较低,因为该距离处的重复次数少于 16 像素处。类似的观察结果解释了偏移距离为 48 像素处出现的更小的峰值。
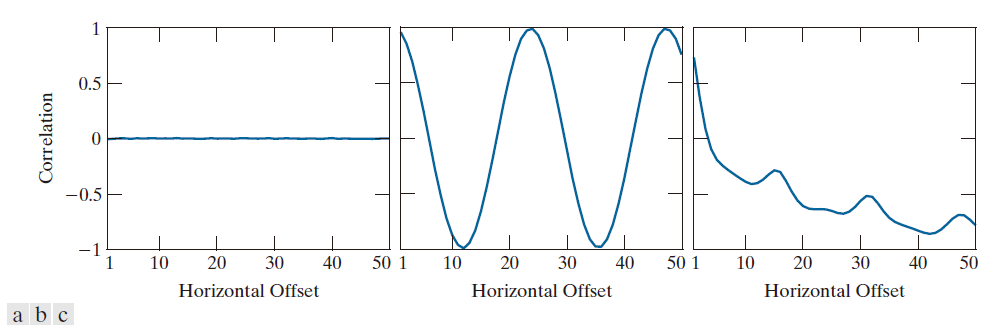
----------------图 11.33:图 11.31 中,(a) 噪声图像,(b) 正弦图像和 (c) 电路板图像对应的相关性描述符的值作为偏移量(“相邻”像素之间的距离)的函数。-----------
----------------图 11.34:电路板图像的放大区域,显示了元件的周期性。----------
11.4.3.2 频谱法(Spectral Approaches)
正如我们在 5.4 节中所讨论的,Fourier频谱非常适合描述图像中周期性或半周期性二维图案的方向性。这些全局纹理图案很容易识别为频谱中高能脉冲的集中区域。这里,我们考虑Fourier频谱中三个对纹理描述有用的特征:(1) 频谱中的显著峰值给出了纹理图案的主要方向;(2) 峰值在频域中的位置给出了图案的基本空间周期;(3) 通过滤波消除任何周期性分量后,剩下的是非周期性图像元素,这些元素随后可以用统计技术进行描述。回顾一下,频谱关于原点对称,因此只需要考虑频域的一半即可。因此,为了便于分析,每一个周期性图案都只与频谱中的一个峰值相关联,而不是两个。
通过对这些函数进行积分(对于离散变量求和)可以得到更全面的描述:
(11-32)
和
(11-33)
其中, 是中心位于原点的圆之半径。对于每一对坐标 ( r , θ ) , 公式 (11-32) 和 (11-33) 构成了一对值 [ S ( r ) , S (θ ) ] 。通过改变这些坐标值,我们就可以生成两个一维函数 S( r ) 和 S (θ ) ,对于一同完整图像或考虑的区域,这构成了一个谱能量表征。此外,还可以计算这些函数自身的描述符,以便定量地表征它们的行为。可用于此目的的描述符包括最大值的位置、振幅和轴向变化的均值和方差,以及函数均值与最大值之间的距离。
例子 11.14 :基于直方图的纹理描述符。
图 11.35(a) 显示了一幅包含随机分布物体的图像,图 11.35(b) 显示了一幅物体呈周期性排列的图像。图 11.35(c) 和 (d) 显示了相应的Fourier频谱。在两个Fourier频谱中,沿二维四边形延伸的周期性能量爆发是由物体所处的粗糙背景材料的周期性纹理造成的。图 11.35(c) 频谱中的其他主要成分是由图 11.35(a) 中物体边缘的随机取向引起的。另一方面,图 11.35(d) 中与背景无关的主要能量沿水平轴分布,对应于图 11.35(b) 中强烈的垂直边缘。

---------------------图 11.35:(a) 和(b)随机物体和有序物体的图像。(c)和(d)对应的Fourier频谱。所有图像的大小均为 600 × 600 像素。-----------------------
图 11.36 (a) 和 (b) 分别绘制了随机物体的 S(r) 和 S(θ) 曲线,图 (c) 和 (d) 则绘制了有序物体的相应曲线。随机物体的 S(r) 曲线没有明显的周期性成分(即,除了原点处的峰值(直流分量)外,频谱中没有其他主要峰值)。相反,有序物体的 S(r) 曲线在 r = 15 附近有一个强峰,在 r = 25 附近有一个较小的峰,这与图 11.35(b) 中亮区(物体)和暗区(背景)的周期性水平重复相对应。类似地,图 11.35(c) 中能量爆发的随机性在图 11.36(b) 的 S(θ) 曲线中也清晰可见。相比之下,图 11.36(d) 中的曲线显示,在原点附近以及 90° 和 180° 处存在较强的能量成分。这与图 11.35(d) 中光谱的能量分布一致。
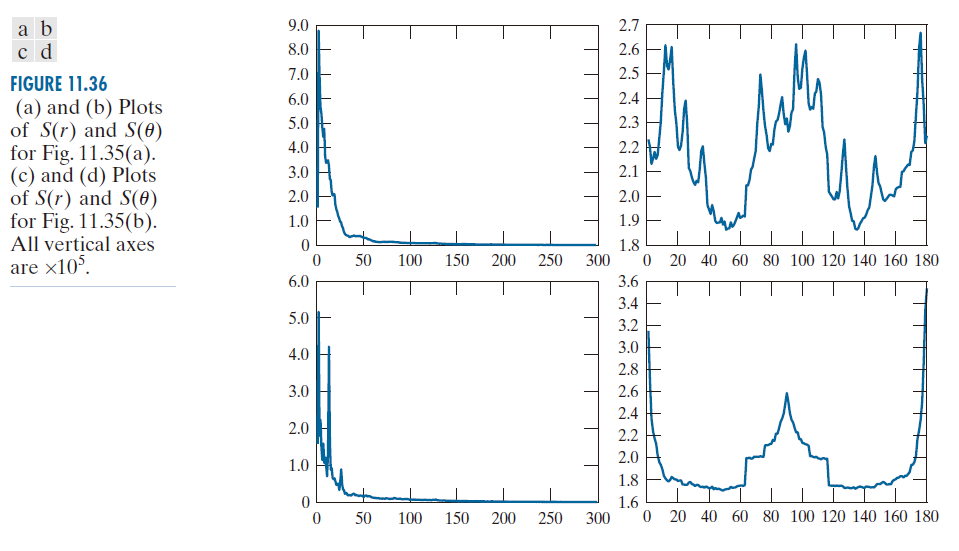
----------图 11.36:(a) 和 (b) 分别为图 11.35(a) 中 S(r ) 和S(θ ) 的图像。(c) 和 (d) 分别为图 11.35(b) 中 S(r ) 和S(θ ) 的图像。所有纵坐标均为 ×105。----------
11.4.3.3 矩不变性(Moment Invariants)
一幅 M × N 数字图像 f ( x , y ) 的二维 ( p + q ) 阶矩定义为
(11-34)
其中,p = 0 ,1 ,2 ,… 和 q = 0 ,1 ,2 ,… 是整数。相应的( p + q ) 阶谱矩定义为
(11-35)
( p = 0 ,1 ,2 ,… 和 q = 0 ,1 ,2 ,… ) ,其中
(11-36) 和
( p + q ) 阶 归一化中心矩( 表示为 ) 定义为
(11-37)
其中,
(11-38)
可以从二阶和三阶归一化中心矩导出七个二维矩不变量( 注:这些结果的推导涉及一些超出本文讨论范围的概念。Bell [1965]的著作和Hu [1962]( Ming-Kuei Hu ) 的论文对这些概念进行了详细讨论。关于生成七阶以上的矩不变量,请参见Flusser [2000]。矩不变量可以推广到n维(参见Mamistvalov [1998]):
(11-39)
(11-40)
(11-41)
(11-42)
(11-43)
(11-44)
(11-45)
这组矩对平移、缩放变换、镜像(在负号范围内)和旋转保持不变。我们可以赋予一些低阶矩不变量以物理意义。例如, 是两个关于数据离散主轴的二阶矩之和,因此该矩可以解释为数据离散程度的度量。类似地,
是二阶矩之差,可以解释为“细长度(slenderness)”的度量。然而,随着矩不变量阶数的增加,其公式的复杂性导致物理意义的丧失。公式 (11-39) 至 (11-45) 的重要性在于它们的不变性,而非它们的物理意义。
例子 11.15 :矩不变性。
本例的目标是利用图 11.37(a) 中的图像计算并比较前面提到的矩不变量。添加黑色 (0) 边框是为了使本例中的所有图像大小相同;这些零值不影响矩不变量的计算。图 11.37( b ) 至 ( f ) 分别显示了原图像的平移、在两个空间维度上缩放 0.5 倍、镜像、旋转 45° 和旋转 90° 后的图像。表 11.5 总结了这六幅图像的七个矩不变量的值。为了减小动态范围并简化解释,所示值使用表达式 进行缩放。绝对值用于处理任何可能为负数的数值。
项保留了
的符号,前面的负号用于处理对数计算中的小数部分。这样做的目的是使数值更易于解释。本例的重点在于矩的不变性和相对符号,而非其具体数值。表 11.5 中的两个关键点是:(1) 矩的数值非常接近,不受平移、缩放、镜像和旋转的影响;(2) 镜像图像的
符号与原图像不同。
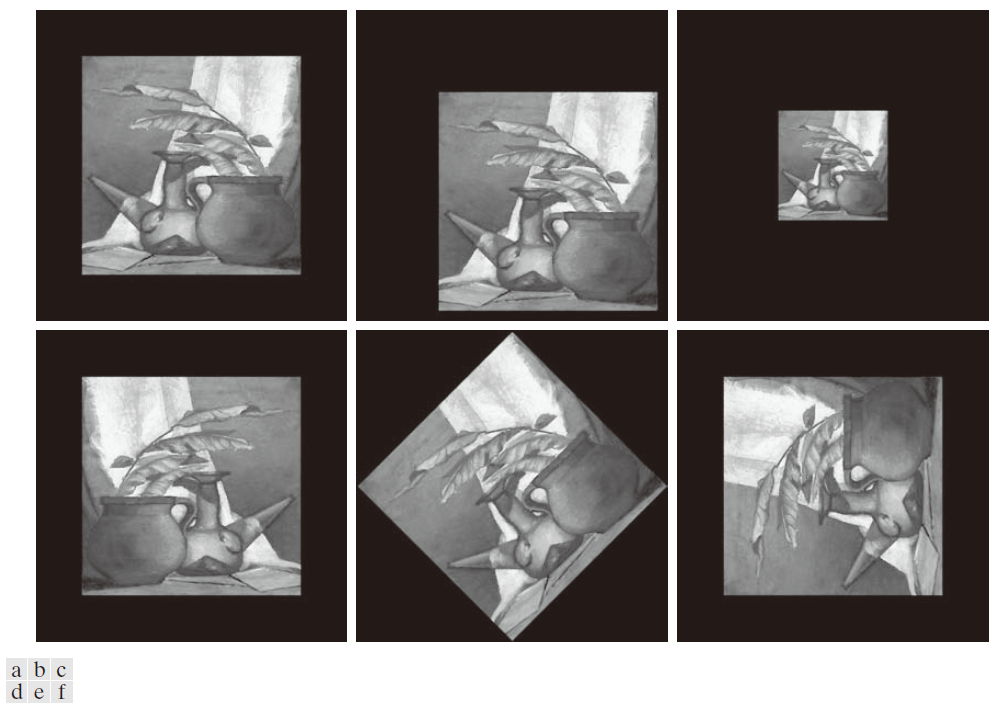 ---------------------图 11.37:(a) 原始图像。( a )–( f )分别平移、缩放一半、镜像、旋转 45° 和旋转 90° 后的图像。-------------------------------------------
---------------------图 11.37:(a) 原始图像。( a )–( f )分别平移、缩放一半、镜像、旋转 45° 和旋转 90° 后的图像。-------------------------------------------
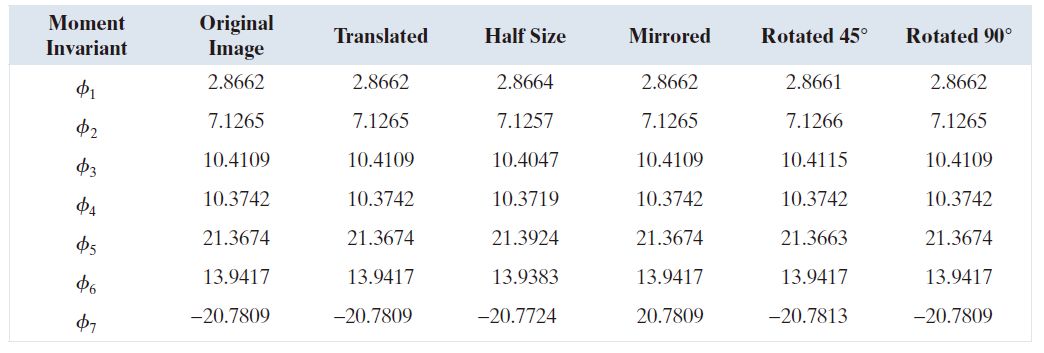
---------------------表 11.5:图 11.37 中图像的矩不变量。--------------------


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










