




图像模式分类
(Image Pattern Classification)
目录
12.2 模式和模式分类(Patterns and Pattern Classes)
12.2.1 模式和模式分类(Patterns and Pattern Classes)
12.2.2 结构模式(Structural Patterns)
12.3 籍原型匹配的模式分类(Pattern Classification by Prototype Matching)
12.3.1 最小距离分类器(Minimum-Distance Classifier)
12.3.2 利用相关性进行二维原型匹配(Using Correlation for 2-D Prototype Matching)
12.3.3 SIFT特征匹配(Matching SIFT Features)
12.3.4 结构原型匹配(Matching Structural Prototypes)
12.3.4.1 匹配形状数(Matching Shape Numbers)
12.3.4.2 字符串匹配(String Matching)
12.4 最优(Bayes)统计分类器(Optimum (Bayes) Statistical Classifiers)
12.4.1 Bayes分类器的推导(Derivation of the Bayes Classifier)
12.4.2 Gauss模式类的Bayes分类器 (Bayes Classifier for Gaussian Pattern Classes)
12.5 神经网络和深度学习(Neural Networks and Deep Learning)
12.5.3 多层前馈神经网络(Multilayer Feedforward Neural Networks)
12.5.3.1 一个神经网络模型(Model of an Artificial Neuron)
12.5.3.2 互连神经元以构建全连接神经网络(Interconnecting Neurons to Form a Fully Connected Neural Network)
12.5.4 前馈神经网络的前向传播(Forward Pass Through a Feedforward Neural Network)
12.5.4.1 前向传输公式(The Equations of a Forward Pass)
12.5.4.2 矩阵公式(Matrix Formulation)
12.5.5 利用反向传播训练深度神经网络(Using Backpropagation to Train Deep Neural Networks)
12.5.5.1 反向传播公式(The Equations of Backpropagation)
12.5.5.2 矩阵公式(Matrix Formulation)
导读(Preview)
我们以图像模式分类技术的介绍来结束对数字图像处理的讲解。本章介绍的方法主要分为三类:基于原型匹配的分类、基于最优统计公式的分类以及基于神经网络的分类。前两种方法广泛应用于数据性质明确的应用场景,从而能够有效地匹配特征并设计分类器。这些方法通常需要大量的工程设计来定义特征和分类器元素。基于神经网络的方法对这类知识的依赖性较低,更适合于模式类别特征(例如特征)由系统学习而非由人工设计者预先指定的应用场景。本章重点介绍相关原理,以及它们在图像模式分类中的具体应用。
12.1 背景(Background)
人类拥有已知生物界中最精密的模式识别能力。相比之下,当前机器的识别能力与人类日常执行的任务相比相形见绌,例如解读复杂图像的含义,以及概括大脑中存储的知识。然而,机器在日常生活中扮演着重要甚至至关重要的角色。试想一下,如果没有机器读取条形码、处理银行支票、检验产品质量、读取指纹、分拣邮件和识别语音,现代生活将会是什么样子。
在图像模式识别中,我们将模式视为特征的空间排列。模式类是指一组具有某些共同属性的模式。机器模式识别包含将模式自动分配到其各自类别的技术。即,给定一个或多个类别未知的模式,模式识别系统的任务是为每个输入模式分配一个类别标签。
图像识别主要包含四个阶段:(1) 感知,(2) 预处理,(3) 特征提取,以及 (4) 分类。就图像处理而言,感知是指生成空间(二维)或更高维度格式的信号。我们在第一章中已经介绍了图像感知的诸多方面。预处理涉及噪声抑制、增强、复原和分割等任务的技术,这些内容在前面的章节中已经讨论过。你在第十一章中学习了特征提取。分类是本章的重点,它涉及使用一组特征作为基础,为未知的输入图像模式分配类别标签。
以下章节将讨论图像模式分类的三种基本方法:(1) 基于未知模式与指定原型匹配的分类;(2) 最优统计分类器;(3) 神经网络。区分这些方法的一个方法是看将原数据转换为适合计算机处理的格式所需的“工程”程度。最终,识别性能取决于所用特征的区分能力。
在基于原型的分类中,目标是使特征足够独特且易于检测,从而使分类本身变得简单。一个很好的例子是银行支票处理器,它使用风格化的字体样式来简化机器处理(我们将在 12.3 节讨论此应用)。
第二类分类方法采用决策理论和统计学术语,其分类策略基于选择能够从统计学意义上证明可获得最佳分类性能的参数。这种方法强调所使用的特征以及分类器的设计。我们将在12.4节中通过推导Bayes模式分类器来阐述这种方法,并从基本原理出发。
第三类方法是使用神经网络进行分类。正如你将在 12.5 节和 12.6 节中了解到的,神经网络也可以使用人工设计的特征,但它们具有独特的能力,能够自主生成适合识别的特征表示。这些系统无需人工设计的特征,即可利用原数据实现这一目标。
前三种方法的一个共同特点是,它们都基于必须预先指定或从代表待解决识别问题的模式中学习到的参数。这些模式可以是带标签的,即我们知道每个模式的类别;也可以是无标签的,即已知数据是模式,但每个模式的类别未知。带标签数据的一个经典例子是字符识别问题,其中收集一组字符样本,并将每个字符的身份记录为 0 到 9 以及 a 到 z 的标签。无标签数据的例子是,当我们试图在数据集中寻找聚类时,目的是利用得到的聚类中心作为数据中包含的模式类别的原型。
处理已标注数据时,通常将已知的数据集划分为三个子集:训练集、验证集和测试集(典型的划分方式可能是 50% 用于训练,验证集和测试集各占 25% )。使用训练集生成分类器参数的过程称为训练。在此模式下,分类器会获得每个模式的类别标签,其目标是在分类器错误识别给定模式的类别时调整参数。此时,我们可能已经有了几个候选设计方案。训练结束后,我们使用验证集将各种设计方案与性能目标进行比较。通常,需要多次训练/验证迭代才能确定最接近预期目标的设计方案。一旦选定了设计方案,最后一步是确定其“实际应用”性能。为此,我们使用测试集,其中包含系统从未见过的模式。如果训练集和验证集能够真正代表系统在实际应用中遇到的数据,那么训练/验证的结果应该与使用测试集得到的性能接近。如果训练/验证结果可以接受,但测试结果却不尽如人意,我们就说训练/验证导致系统参数“过拟合”到现有数据上,在这种情况下,需要对系统架构进行进一步改进。当然,所有这些都基于一个前提:给定的数据能够真正代表我们想要解决的问题,并且该问题确实可以通过现有技术解决。
使用训练数据设计的系统称为进行监督学习。如果我们处理的是未标记的数据,系统会在无监督学习模式下自行学习模式类别。本章仅讨论监督学习。正如你将在本章和下一章中看到的那样,监督学习涵盖了广泛的方法,从系统学习由设计者预先设定的特征参数的应用,到利用深度学习和大型原始数据集自主学习分类所需特征的系统。这些系统无需人工设计者预先指定特征即可完成此任务。
在下一节简要讨论模式的形成方式以及模式类别的性质之后,我们将在 12.3 节讨论基于原型分类的各种方法。在 12.4 节中,我们将从基本原理出发,推导出Bayes分类器的公式。Bayes分类器是一种以平均分类性能为特征的方法。我们还将讨论基于多元Gauss分布假设的Bayes分类器的监督训练。从 12.5 节开始,我们将用本章剩余的时间讨论神经网络。我们将首先简要介绍感知器以及机器学习的一些历史背景。然后,我们将介绍深度神经网络的概念,并推导出反向传播的公式。反向传播是训练深度神经网络的首选方法。这些网络非常适合输入模式为向量的应用。在第 12.6 节中,我们将介绍深度卷积神经网络,它是目前处理数字图像时首选的方法。在推导用于训练卷积神经网络的反向传播公式之后,我们将给出几个应用示例,这些示例涉及各种复杂度的图像类别。除了直接处理图像输入之外,深度卷积神经网络还能够自主学习适合分类的图像特征。这是从原始图像数据开始实现的,这与第 12.3 节和第 12.4 节中讨论的其他分类方法不同,后者依赖于“人工设计”的特征,如前所述,这些特征的形式是由人工设计者预先指定的。
12.2 模式和模式分类(Patterns and Pattern Classes)
在图像模式分类中,模式排列主要分为定量模式和结构模式两种。定量模式(Quantitative patterns)以模式向量(pattern vectors)的形式排列。结构模式通常由符号组成,这些符号以字符串、树状结构或(较少见)图状结构排列。本章的大部分内容都基于模式向量,但我们将在本节末尾简要讨论结构模式,并在12.3节末尾给出一个示例。
12.2.1 模式和模式分类(Patterns and Pattern Classes)
模式向量用小写字母(如x ,y 和 z )表示,其行式为
(12-1)
其中,每一个特征分量 表示第 i 个特征描述符,而 n 是这样的描述符的总数。我们可以将一个向量表示为列的形式(如公式 (12-1) 中那样),或者表示为等价的行形式
,其中,T 表示转置。一个模式向量可以“视为”n 维Euclid 空间中的一个点,而一个模式类可以被解释为该模式空间中的点的一个“超云(hypercloud)”。为了便于识别,我们希望模式类紧密聚集(grouped),并且彼此之间尽可能远离。
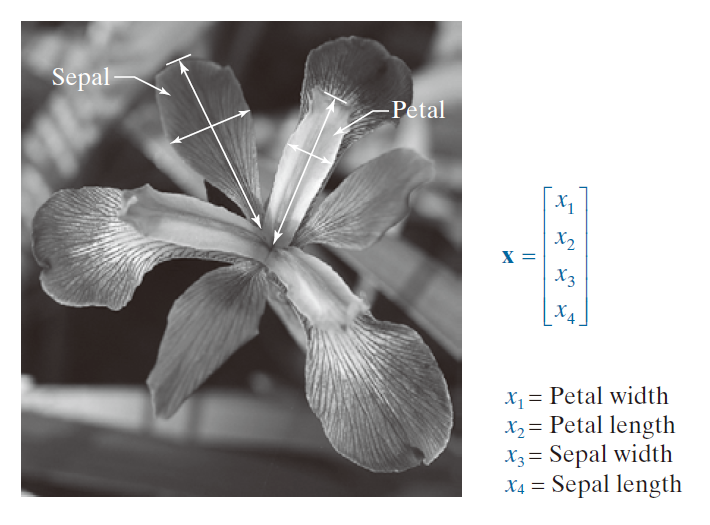
模式向量可以直接从图像像素强度形成,例如通过线性索引对图像进行向量化,如图 12.1 所示。更常见的方法是将模式元素作为特征。一个早期的例子是 Fisher [1936] 的工作。近一个世纪前,他报道了使用当时一种称为判别分析的新技术来识别三种鸢(yuān)尾花(山鸢尾、维吉尼亚鸢尾和变色鸢尾)。Fisher 使用四个特征来描述每朵花:花瓣的长度和宽度,以及萼片的类似特征(见图 12.2)。这产生了图中所示的 4 维向量。对每种性别的 50 个样本获得的这些向量构成了著名的三种 Fisher 鸢尾花模式类别。如果 Fisher 生活在今天,他可能会在他的测量中添加光谱颜色和形状特征,从而得到更高维度的向量。我们将在本章后面使用原始的鸢尾花数据集。
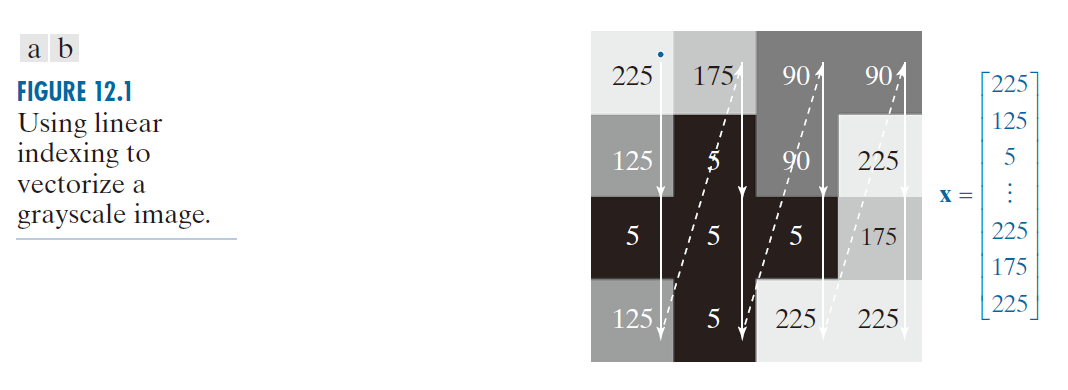
-------------------图 12.1:使用线性索引将灰度图像向量化。---------------------
译注:
Petal width——花瓣宽度
--------------------图 12.2:为了进行数据分类,对鸢尾花进行了花瓣和萼片的宽度和长度测量(见箭头所示)。图中所示为弗吉尼亚鸢尾(Iris virginica)的花朵。(图片由美国农业部提供。)-------------------------------------------------------------
更高层次的模式表示基于你在第 11 章中学习到的特征描述符。例如,由边界形状描述符构成的模式向量非常适合受控环境中的应用,例如工业检测。图 12.3 展示了这一概念。这里,我们感兴趣的是对不同类型的噪声形状进行分类,图中显示了一个示例。如果我们用对象的特征来表示它,我们将得到如图 12.3(b) 所示的一维信号。我们可以通过以 θ 为增量对特征的幅度进行采样,然后通过令 来形成向量,其中 i = 0, 1, 2,…, n 。与其使用“原始”采样特征,更常见的方法是计算特征样本的某个函数
,并用它们来形成向量。你在 11.3 节中学习了几种实现此目的的方法,例如统计矩。
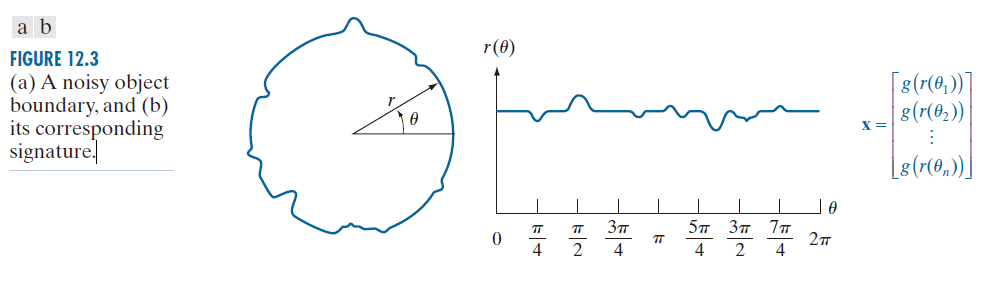
---------------图 12.3:(a) 噪声物体边界,以及 (b) 其对应的特征。-------------
向量也可以由边界和区域的特征构成。例如,图 12.4 中的对象可以用三维向量表示,这些向量的分量体现了与单个二值对象的边界和区域属性相关的形状信息。模式向量也可以用来表示图像区域的属性。例如,图 12.5 中的六维向量的元素是基于表 11.3 中特征描述符的纹理度量。图 12.6 显示了一个示例,其中模式向量的元素是变换不变的特征,例如图像旋转和缩放(参见 11.4 节)。

--------------图 12.4:模式向量,其组成部分同时体现边界和区域特征。------------
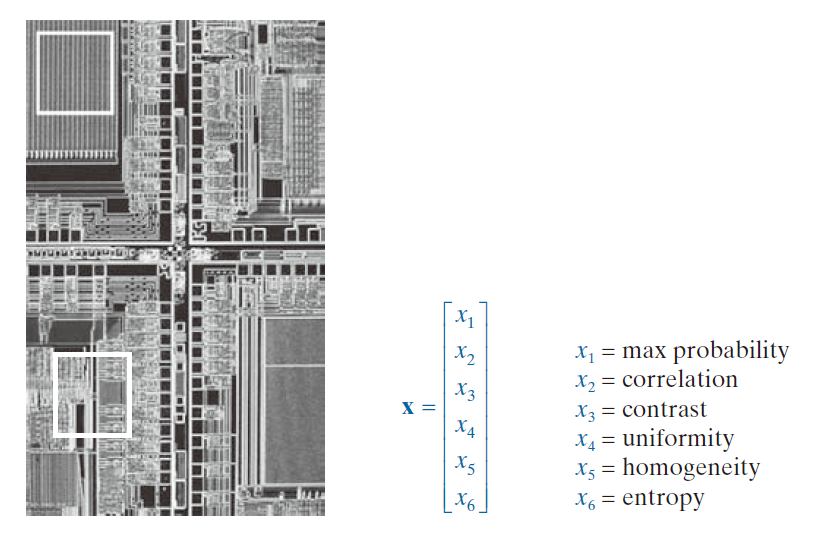
------------------------------图 12.5:基于子图像属性的模式向量示例。有关 x 分量的解释,请参见表 11.3。------------------------------------------------------

------------------------------图 12.6:特征向量的各分量对旋转、缩放和平移等变换保持不变。这些向量分量是矩不变量。---------------------------------------------
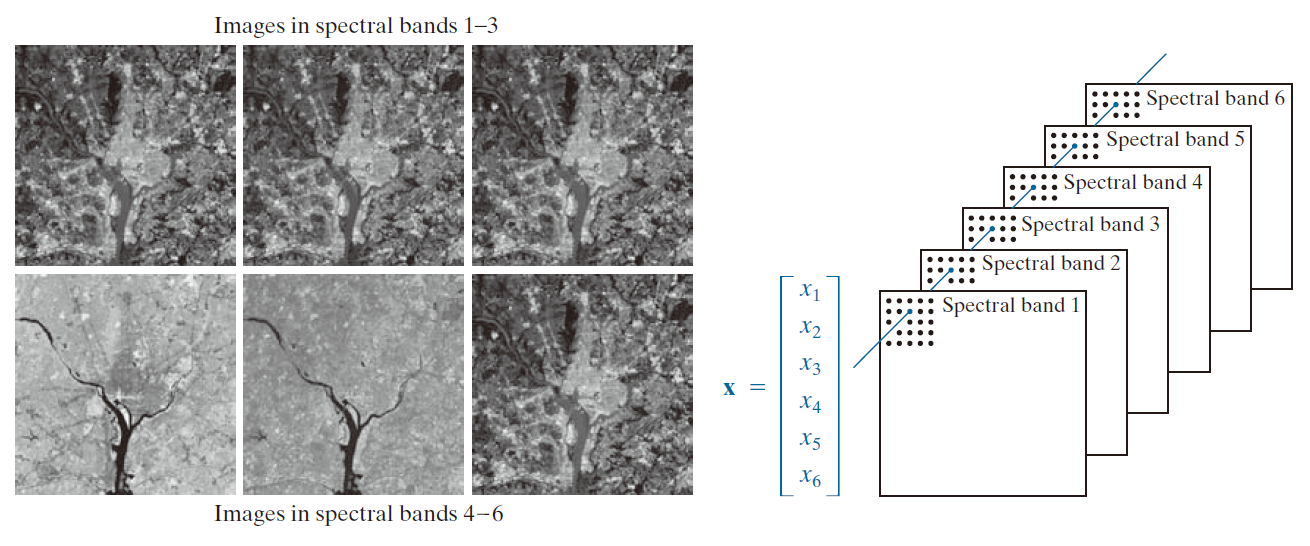
------------------------------图 12.7:由一组已配准图像中对应像素连接而成的模式(特征)向量。(原始图像由NASA提供。)------------------------------------------
12.2.2 结构模式(Structural Patterns)
模式向量不适用于对象由结构特征(例如符号串)表示的应用。尽管在图像处理应用中,模式向量的使用频率远低于向量,但在关注形状的应用中,包含对象结构描述的模式却至关重要。图 12.8展示了一个示例。瓶子的边界使用 11.2 节中解释的方法用多边形近似表示。边界被细分为线段(图中用 β 表示),并在每两条线段的交点处计算内角 θ 。如图所示,沿逆时针方向遍历边界时,会生成一个连续的符号串。这种形式的字符串就是结构模式,正如你将在 12.3 节中看到的那样,其目标是将给定的字符串与存储的字符串原型进行匹配。
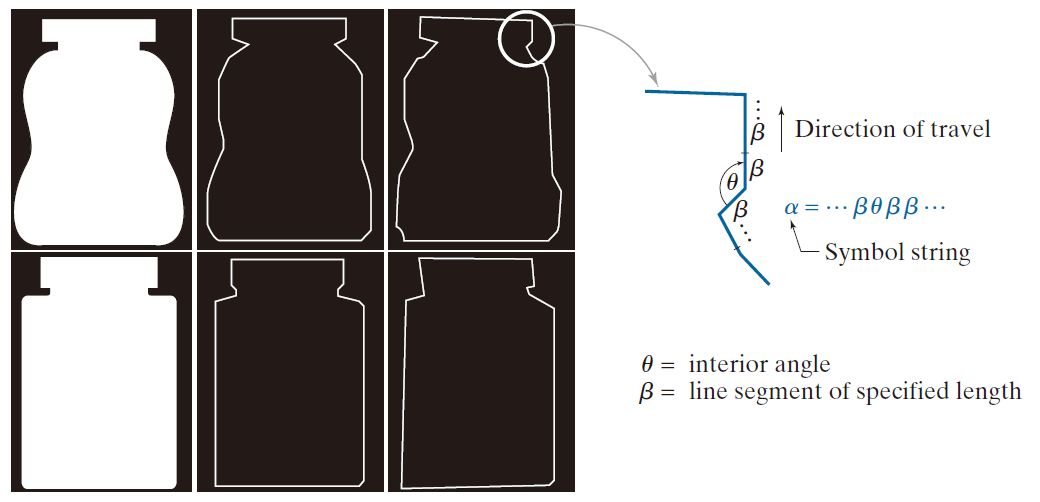
θ —— 内角
β —— 指定长度的线段
--------------图 12.8:由药瓶边界的多边形近似值生成的符号字符串。-------------
树状图是另一种结构表示方法,适用于从更高层次描述图像的各个组成区域。基本上,大多数层级排序方案都会生成树状结构。例如,图 12.9 显示了一幅卫星图像,图像内容为人口密集的市中心区域及其周边的住宅区。用符号 $ 表示树的根节点。图中所示的(倒置的)树状图是利用“由……组成”的结构关系构建的。因此,树的根节点代表了整幅图像。下一层表示图像由市中心区域和住宅区组成。住宅区又由房屋、高速公路和购物中心组成。树状图的下一层进一步描述了房屋和高速公路。我们可以继续进行这种细分,直到达到我们能够分辨图像中不同区域的极限。
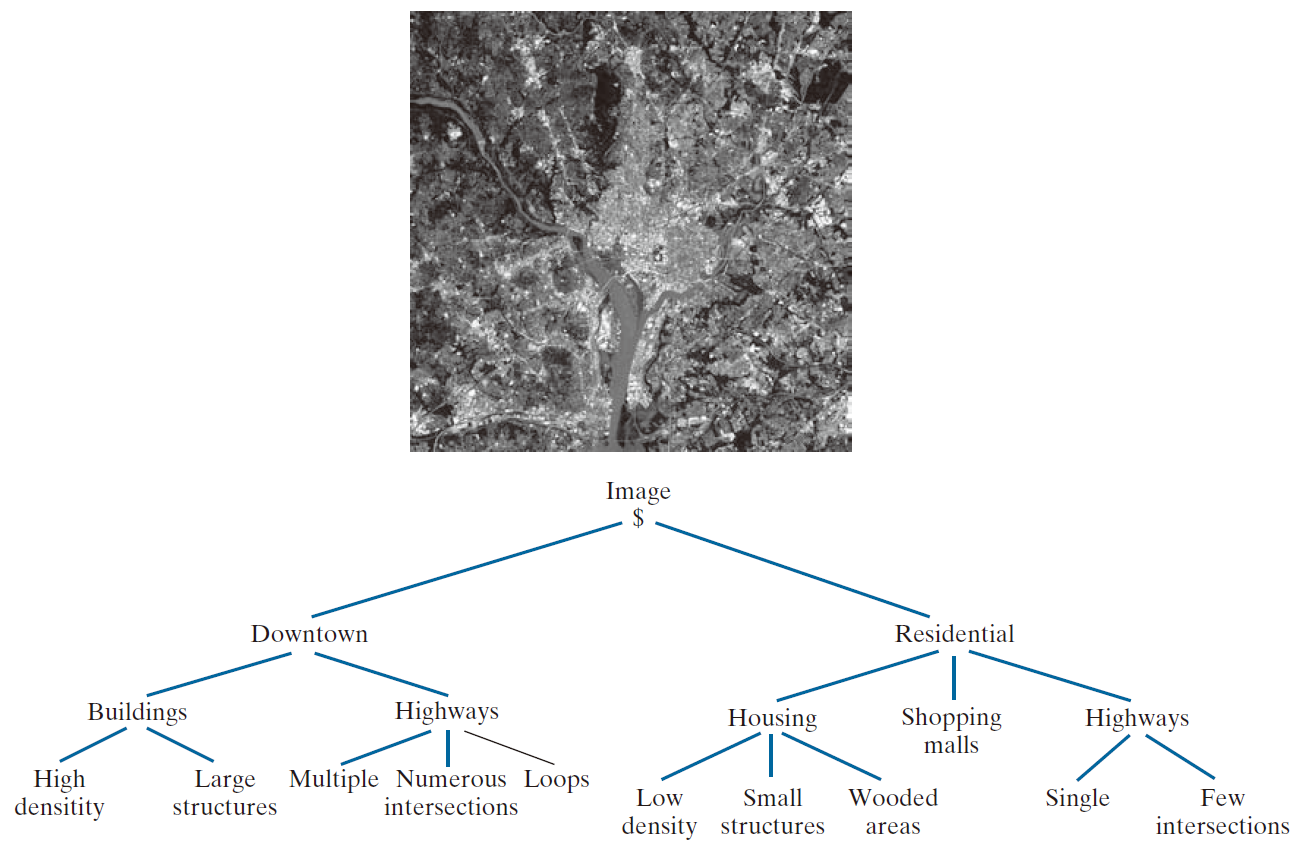
----------------------图 12.9:这张卫星图像以树状图的形式展现了华盛顿特区市中心高楼林立的区域及其周边居民区。(原图由美国国家航空航天局提供。)-----------------
12.3 籍原型匹配的模式分类(Pattern Classification by Prototype Matching)
原型匹配是指将未知模式与一组原型进行比较,并将与未知模式“最相似”的原型类别分配给未知模式。每一个原型代表一个唯一的模式类别,但每一个类别可能对应多个原型。不同匹配方法之间的区别在于用于确定相似性的度量标准。
12.3.1 最小距离分类器(Minimum-Distance Classifier)
最简单且应用最广泛的原型匹配方法之一是最小距离分类器。顾名思义,它计算未知模式向量与每个类别原型之间的距离度量,然后将未知模式分配到与其距离最近的原型所属的类别。最小距离分类器的原型向量通常是各个模式类别的均值向量:
(12-2)
其中, 是用于计算第 j 个均值向量模式向量的数量,
是第 j 个模式类,而
是类的数量。若我们使用 Euclid 距离来确定相似性,最小距离分类器计算距离
(12-3)
其中, 是 Euclid 范数,若
(
且
) ,则分类器将一个未知的模式 x 分配给类
。结(ties) [ 即,
] 可以任意解决。
不难证明,(见问题 12.2)选择最小距离相当于计算函数
(12-4)
并将一个未知的模式 x 分配给其原型类由d的最大值生成的类。即,x 归于类 ,若
(12-5)
当用于识别的时候,这种形式的函数称为决策函数(decision functions)或判别函数(discriminant functions)。
将 从
分离出来的决策边界(decision boundary)由 x 的值求得,即
(12-6)
或等价记法,由满足
(12-7)
的 x 的值求得。最小距离分类器的决策边界可直接由该公式及式 (12-4) 得出:
(12-8)
由公式 (12-8) 给出的边界是连接 和
的线段的垂直平分线( 见问题 12.3 )。在2维的情况下(即,n = 2 ),垂直平分线是一条直线,对于n = 3 ,它是一个平面,而对于 n > 3 , 其称为超平面 (hyperplane)。
例 12.1:二维两类最小距离分类器示意图。
图 12.10 展示了鸢尾属中的变色鸢尾(Iris versicolor)和山鸢尾(Iris setosa)这两个类别的花瓣宽度与长度数值的散点图。正如上一节所述,鸢尾花数据库中的模式向量由每朵花的四项测量数据组成。此处我们仅展示其中的两项,以便你能够直观地观察这些模式类别及其之间的决策边界。在本章稍后的部分,我们将对完整的数据库进行处理。
我们将变色鸢尾和山鸢尾的数据分别记为类别 和
。这两个类的均值分别是
和
。 则根据公式 (12-4) 可推导出
和
根据公式 (12-8) ,这个边界的公式是
图 12.10 显示了这个边界的一段图像。将来自 的任意模式向量代入这个公式就会得到
。反之,任意来自
的模式都会给出
。因此,给予一个属于这两种类型之一的未知模式 x ,
的符号足以确定那个属式属于哪一个类。
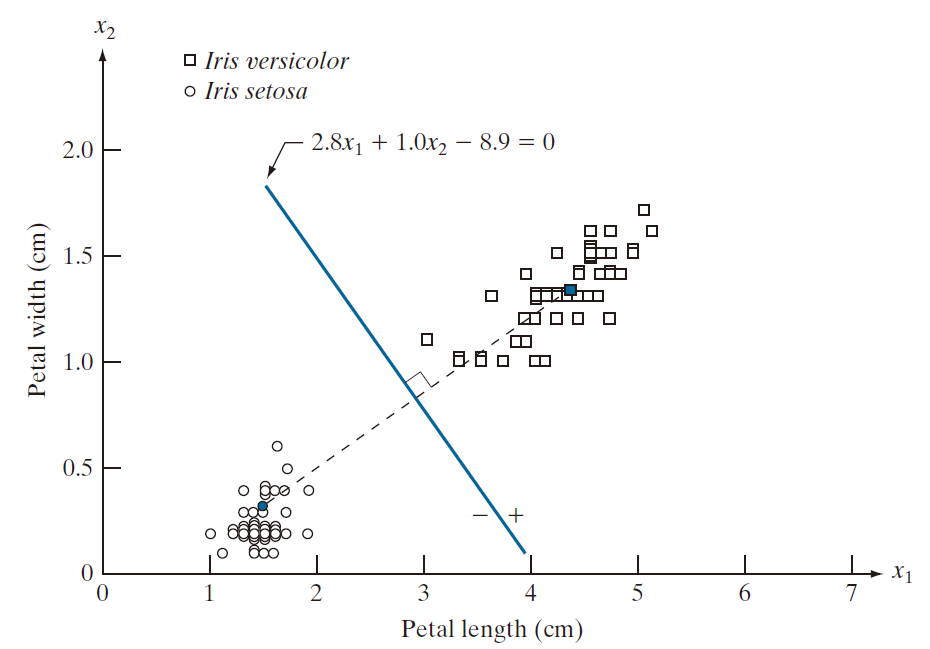
-----------------------图 12.10:基于两项测量的、针对变色鸢尾和刚毛鸢尾类别的最小距离分类器决策边界。深色圆点和方块分别代表这两个类别的均值。-----------------
当各类别均值之间的距离相对于各类别围绕其均值的离散程度或随机性而言较大时,最小距离分类器能够取得良好的效果。在第12.4节中,我们将证明,若各类别围绕其均值的分布在n维模式空间中呈现为球形的“超云”形态,则最小距离分类器能够实现最优性能(即在最小化平均误分类损失方面达到最优)。
正如前文所述,实现准确识别性能的关键之一,在于选取能够有效区分不同类别的特征。通常而言,特征在满足这一目标方面的表现越出色,其识别性能也就越优异。对于最小距离分类器而言,这意味着各类别均值之间应保持较大的间隔,且各类别内部的数据应呈现紧密的聚类分布。
基于银行家协会 E-13B 字体字符的系统,是一个典型的范例,展示了如何将高度精巧的特征工程与简单的分类器相结合,从而实现卓越的性能。20世纪40年代中期,银行支票的处理工作主要依靠人工完成;这一过程不仅费时费力、成本高昂,且极易发生差错。随着20世纪50年代初支票签发量的激增,各家银行对实现这项任务的自动化产生了浓厚的兴趣。到了20世纪50年代中期,E-13B 字体及其配套的读取系统,已成为解决这一难题的标准方案。如图 12.11 所示,这套字体集由14个字符组成,其布局基于一个 9 × 7 的网格。这些字符经过了高度风格化的设计,旨在最大程度地拉开字符间的视觉差异。该字体的设计初衷是使其既紧凑又便于人类肉眼辨识;然而,其首要且压倒一切的设计目标,是确保这些字符能够被机器快速、且以极高的准确率进行读取。
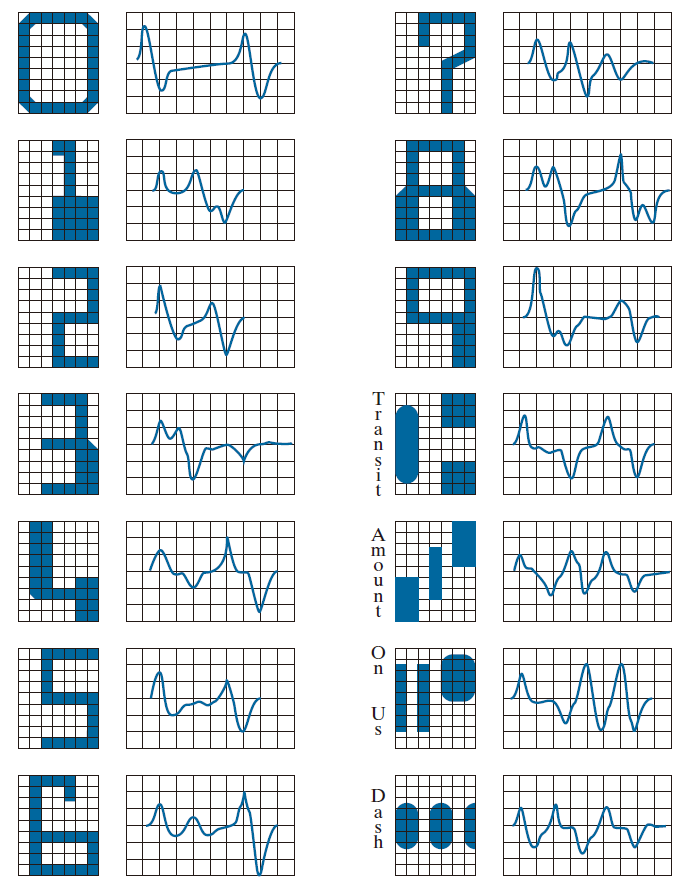
-------------图 12.11:美国银行家协会 E-13B 字体字符集及相应的波形。-----------
除了采用风格化的字体设计外,该阅读系统的运行性能还通过一种特殊墨水得到了进一步提升——这种墨水含有经过精细研磨的磁性材料,用于印制每一个字符。为了提高待读取支票上字符的可检测性,该墨水会置于磁场作用下,从而使每一个字符在背景衬托下显得更为突出。这种风格化的字体设计进一步增强了字符的可检测性。字符通过一个单狭缝读取头进行水平方向扫描;该读取头的宽度窄于字符,但高度高于字符。当支票经过读取头时,传感器会产生一个一维电信号(即一种“特征波形”);该信号经过调理后,其幅值与读取头下方字符覆盖面积的增加或减少速率成正比。例如,请观察图 12.11 中数字“0”的波形。当支票向右移动并经过读取头时,传感器所感测到的字符覆盖面积开始增大,从而产生正导数(即正的变化率)。当字符的右侧笔画开始经过读取头下方时,传感器感测到的字符覆盖面积开始减小,从而产生负导数。当读取头位于字符的中部区域时,字符覆盖面积基本保持恒定,从而产生零导数。当字符的另一侧笔画进入读取头下方时,上述波形变化过程会再次重复。这种字体设计确保了每一个字符所对应的波形都具有独特性,从而有别于其他所有字符的波形。此外,该设计还确保了每一个波形的峰值点和零点大致落在背景网格的纵向格线上(如图所示);这些波形正是显示在该背景网格之上的。E-13B 字体具有这样一种特性:只需在上述(九个)特定点位上对波形进行采样,便足以获取对字符进行准确分类所需的全部信息。而磁性墨水的使用,则进一步优化了这些经过高度工程化设计的特征的实际效能,从而生成了波形清晰、几乎没有任何离散杂波的理想波形信号。
针对此应用设计最小距离分类器是一项直截了当的任务。我们只需存储每个波形在网格垂直线处的采样值,并将由此得到的每组采样表示为一个9维原型向量 (其中 j = 1, 2, … ,14 )。当需要对未知字符进行分类时,其处理流程如下:首先,按照前述方式对该字符进行扫描;接着,将其波形的网格采样表示为一个9维向量 x ;最后,通过选取那个能在公式 (12-4) 中产生最大值的原型向量所对应的类别,来确定该未知字符的归属类别。完成这一任务甚至无需借助计算机;事实上,利用由电阻阵列构成的模拟电路,即可实现极高的分类速度(参见习题 12.4)。
本例中最重要的一课是:如果我们能够控制生成模式的环境,那么原本棘手的识别问题往往就能变得轻而易举。E13-B 字体识别系统的开发与实现,正是这一事实的一个绝佳例证。另一方面,如果我们要增加一项要求——即该系统必须能够识别每张支票上书写的文本内容及签名——那么现有的系统便显得力不从心了。为此,我们需要构建复杂度显著更高的系统,例如我们将在第 12.6 节中探讨的卷积神经网络。
12.3.2 利用相关性进行二维原型匹配(Using Correlation for 2-D Prototype Matching)
我们在第3.4节中介绍了空间相关与卷积的基本概念,并在第3章中广泛运用这些概念进行空间滤波。根据公式 (3-34),一个核 w 与一幅图像 f ( x ,y )的相关性计算公式为
(12-9) (w ☆ f )( x, y) =
其中求和的上下限取自 w 与 f 的重叠区域。该公式需针对位移变量 x 和 y 的所有取值进行计算,从而确保 w 的所有元素都能遍历 f 的每一个像素。众所周知,相关函数会在 f 与 w 相等或近似相等的区域(或位置)处取得其最大值。换言之,公式 (12-9) 的作用在于找出 w 与 f 局部区域相匹配的位置。然而,该公式存在一个弊端,即其计算结果对任一函数幅度的变化都十分敏感。为了使相关运算能够针对一个或两个函数的幅度变化进行归一化处理,我们转而利用相关系数来进行匹配:
(12-10)
其中,求和极限取于 w 与 f 共享的 区域, 核(仅计算一次)的平均值,而
这个区域中与 w 共现的 f 的均值。在图像相关性工作中,w 通常称为模板(template)(即,原型子图像)而相关性称为模板匹配(template matching)。 可以证明(参见问题 12.5),函数 g( x, y) 的取值范围位于 [−1, 1] 区间内;因此,它已针对 w 与 f 的振幅变化进行了归一化处理。当归一化后的 w 与 f 中对应的归一化区域完全一致时,g 的取值达到最大。这表明两者之间具有最大的相关性(即实现了最佳匹配)。而当这两组归一化函数在公式 (12-10) 所定义的意义上表现出最低的相似度时,g 的取值达到最小值。
图 12.12 演示了上述过程的运作机制。图像 f 周围的边界即为填充(padding),这一点已在第 3.4 节中有所阐述。在模板匹配中,当模板中心越过图像边界时,其相关值通常不具参考意义;因此,填充的范围通常仅限于核宽度的半值。
图 12.12 所示的模板尺寸为 m × n ,图中其中心位于任意位置 ( x, y ) 处。该点的相关系数数值利用公式 (12-10) 进行计算。随后,将模板中心移动至相邻位置,并重复上述过程。通过移动模板中心(即递增 x 和 y 的数值),使模板 w 的中心遍历图像 f 中的每一个像素,从而获得各点的相关系数 γ( x, y)。当该过程结束后,我们查找 γ( x, y) 中的最大值,以确定最佳匹配发生的位置。值得注意的是,γ(x, y) 中可能存在多个位置具有相同的最大值,这表明模板 w 与图像 f 之间存在多处匹配。
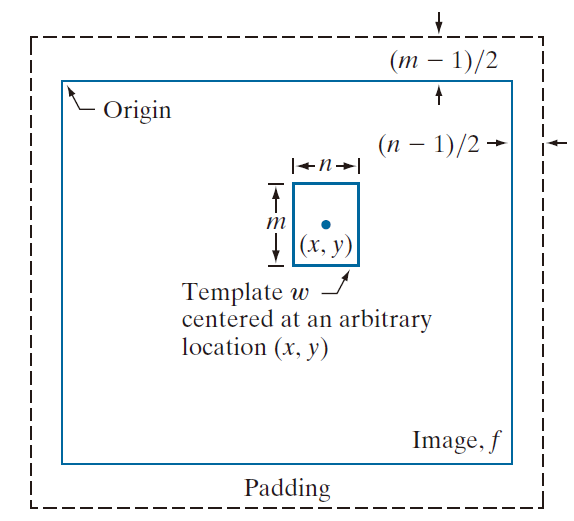
译注:padding——内边距
--------------------图 12.12:模板匹配的机制------------------------------
例 12.2:基于相关性的匹配。
图 12.13(a) 展示了一幅 913 × 913 像素的 1992 年安德鲁飓风卫星图像,其中风眼清晰可见。我们希望利用相关运算,在图 12.13(a) 所示的原始图像中,找到与图 12.13(b) 所示模板的最佳匹配位置;该模板是一幅大小为 31 × 31 像素的风眼局部图像。图 12.13(c) 展示了对原始图像中所有 ( x, y ) 坐标点计算相关系数(如公式 (12-10) 所示)所得的结果。由于进行了填充处理(参见图 12.12),该结果图像的实际尺寸为 943 × 943 像素,但为了便于显示,我们将其裁剪回了与原始图像相同的尺寸。该图像中的亮度值与相关系数值成正比;为了简化图像的视觉分析,所有负相关系数值均被截断为 0(显示为黑色)。相关系数值最高的区域在该图像中呈现为一个微小的白色斑块。该区域内最明亮的点所对应的位置,即为风眼的中心。图 12.13(d) 以一个白色圆点的形式,标示出了这一最大相关系数值所对应的位置(在本例中,仅存在一个唯一的最佳匹配点,其最大相关系数值为 1);我们可以看出,该位置与图 12.13(a) 中风眼的位置高度吻合。

------------------------图 12.13:(a) 安德鲁飓风的 913 × 913 卫星图像。(b) 风眼区域的 31 × 31 模板。(c) 以图像形式呈现的相关系数(请留意由箭头指示的最亮点)。(d) 最佳匹配位置(由箭头标示)。该点实际上仅为一个像素,但为便于观察,其尺寸已放大。(原图像由 NOAA 提供。)------------------------------------------------
12.3.3 SIFT特征匹配(Matching SIFT Features)
我们在第11.7节中讨论了缩放不变特征变换(SIFT)。SIFT能够计算出一组不变特征,可用于在已知图像(即原型)与未知图像之间进行匹配。第11.7节中实现的SIFT算法,针对图像中的每一个局部区域,均生成一个128维的特征向量。SIFT通过在已存储的特征向量原型集与针对未知图像计算出的特征向量集之间寻找对应关系,从而实现匹配。鉴于涉及的特征数量庞大,若要搜寻精确匹配项,其计算开销将十分巨大。因此,实际采用的方法是“最佳桶优先”(Best-Bin-First)策略;该策略仅需有限的计算量,便能识别出高概率的最近邻域(参见 Lowe [1999], [2004])。此外,通过利用 Ballard [1981] 提出的广义Hough变换来搜寻潜在解的聚类,整个搜索过程得以进一步简化。根据第10.2节中的讨论我们可知,Hough变换通过引入“桶”(bins)的概念,降低了对数据集进行观察时的细节粒度,从而简化了数据模式的搜寻工作。我们已在第11.7节中对SIFT算法进行了探讨;本节的重点在于进一步阐释SIFT在原型匹配任务中所展现出的强大能力。
图 12.14 显示了我们之前多次使用的电路板图像。大图顶部最右侧连接器周围的小矩形框标出了连接器图像的提取区域。为了清晰起见,小图已放大显示。大图和小图的尺寸在图注中注明。图 12.15 显示了 SIFT 算法找到的关键点,如第 11.7 节所述。这些关键点在两幅图像中均以细线形式可见。子图的放大视图使它们显示得更清晰一些。需要注意的是,图像和子图像的关键点是由 SIFT 算法独立找到的。大图有 2714 个关键点,小图有 35 个关键点。
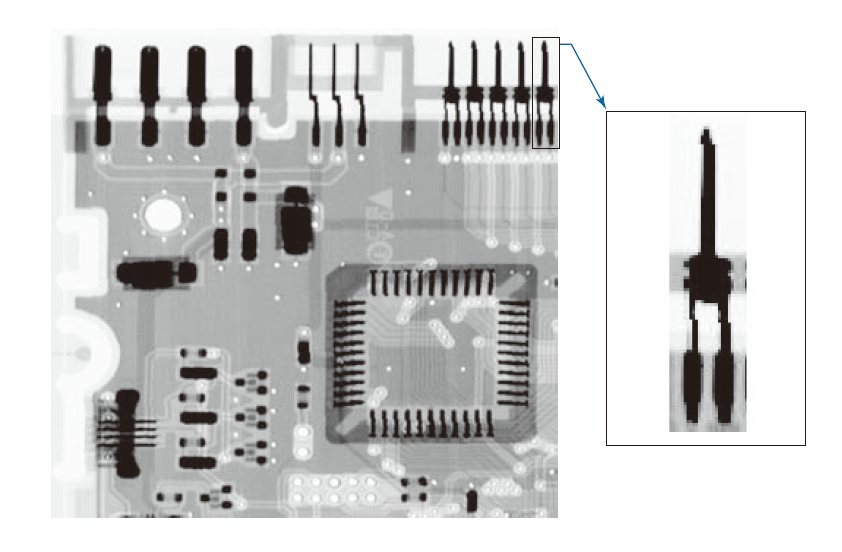
-----------------图12.14:一张尺寸为 948 × 915 像素的电路板图像,以及其中一个连接器的局部图像。该局部图像尺寸为 212 × 128 像素,为便于清晰观察,已在右侧放大显示。(原图像由 Lixi 公司的 Joseph E.Pascente 先生提供。)--------------------
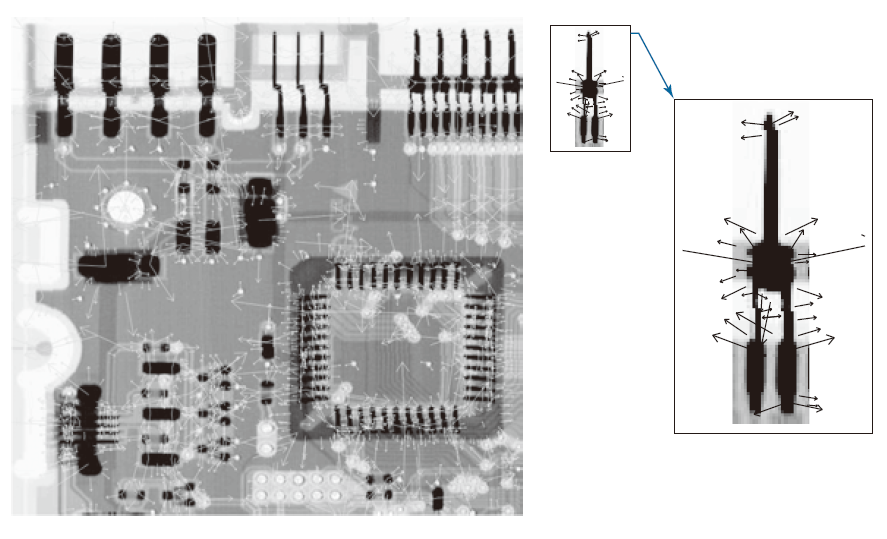
-------------图 12.15:由 SIFT 检测到的关键点。大图中包含 2714 个关键点(显示为淡淡的灰色线条);子图中包含 35 个关键点。这是一幅独立的图像,SIFT 对其关键点的检测是独立于大图进行的。此处展示了放大后的局部区域,以使细节更加清晰。---------
图 12.16 展示了 SIFT 算法检测到的关键点之间的匹配结果。在这两幅图像之间,共检测到了 41 对匹配点。由于小图中仅包含 35 个关键点,显然,其中至少有 6 对匹配是错误的,或者是重复匹配。在这 6 处错误中,有 3 处显得尤为明显,即那些与大图中央连接器相匹配的点对。然而,若仔细比对大图中央连接器的形状,你会发现它们与大图右侧连接器的局部特征几乎完全一致。因此,基于这一事实,这些所谓的“错误”匹配便得到了合理解释。至于另外 3 对多余的匹配,其成因则更为简单明了。电路板右上角的所有连接器均呈完全相同的形态,而我们当前的操作正是将其中某一个连接器与其余的连接器进行比对。对于任何系统而言,都无法分辨出这些连接器之间的细微差异。事实上,通过观察连接线,我们可以清楚地看到:这些匹配关系实际上是介于该局部图像(子图)与那全部 5 个连接器之间。从本质上讲,这些匹配并非错误,而是该局部图像与其余那些形态完全一致的连接器之间所建立的正确匹配关系。
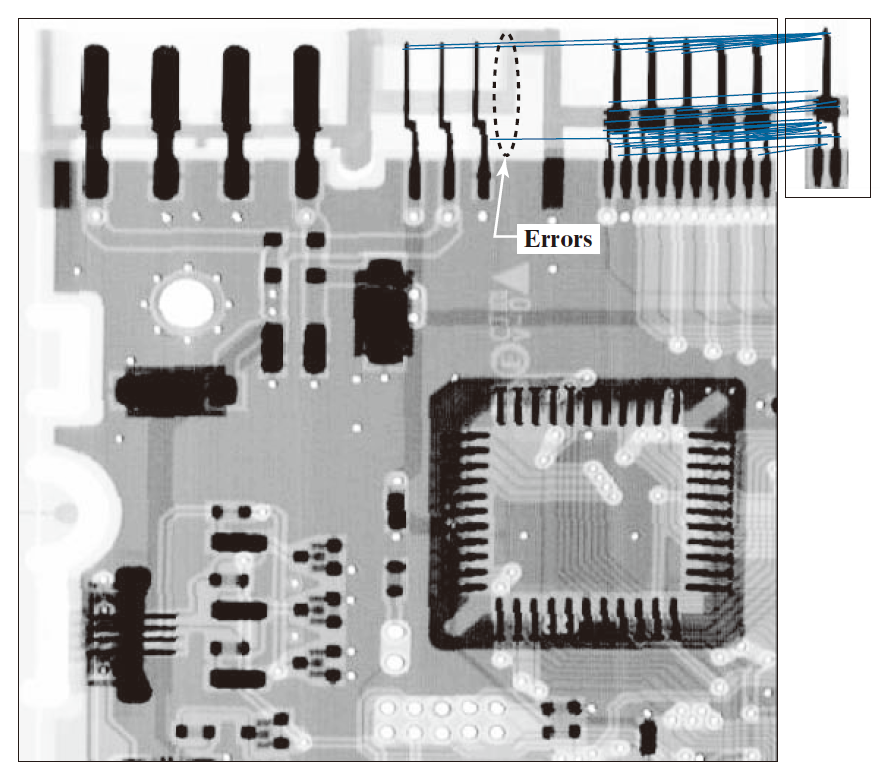
---------------------图 12.16:SIFT 算法在大小图像之间检测到的匹配点对。共检测到 41 对匹配。图中通过直线将这些匹配点连接起来予以展示。其中仅有三对匹配属于“真正的”误匹配(在图中标记为“Errors”)。------------------------------------
12.3.4 结构原型匹配(Matching Structural Prototypes)
迄今为止所讨论的技术主要从定量的角度处理模式,而在很大程度上忽略了模式形状本身所固有的结构关系。本节所探讨的方法旨在通过充分利用这类结构关系,来实现模式识别。在本节中,我们将介绍两种基于字符串表示的边界形状识别基本方法;在结构模式识别领域中,这正是最为实用的一种方法。
12.3.4.1 匹配形状数(Matching Shape Numbers)
针对此前为模式向量引入的“最小距离分类器”概念,我们可以构建一套类似的程序,用于比较那些由“形状数”描述的区域边界。参照第11.3节中的讨论,两个区域边界之间的相似度 k 定义为:两者形状数仍保持一致的最高阶数。例如,设 a 和 b 分别表示由4方向链码所表征的闭合边界的形状数。若
(12-11)
和
(其中,s 表示形状编号,下标表示形状次序)
则这两个形状具有相似度 k 。形状 a 与形状 b 之间的距离定义为其相似度的倒数:
(12-12)
这个表达式满足下列属性:
(12-13) D ( a , b ) ≥ 0
D( a , b ) = 0 (当且仅当 a = b )
D( a , c ) ≤ max[D( a , b ) , D( b , c )]
可以使用 k 或 D 来比较两个形状。若采用相似度作为衡量标准,则 k 值越大,形状越相似(需注意,对于完全相同的形状,k 值为无穷大)。若采用式 (12-12) 进行比较,则情况恰好相反。
例 12.3:匹配形状数。
假设我们有一个形状 f ,并希望从一组包含五个原型形状(分别记作 a ,b ,c ,d 和 e )的集合中,找出与 f 最匹配的那一个,如图 12.17(a) 所示。借助图 12.17(b) 中的相似性树,我们可以直观地展现这一搜索过程。该树的根节点对应于最低的相似度等级,即 4 。假设除形状 a 之外,其余形状在等级 8 之前均保持一致;而形状 a 与所有其他形状的相似度等级均为 6 。沿着树向下逐层探究,我们会发现形状 d 与所有其他形状的相似度等级均为 8,依此类推。形状 f 与形状 c 之间呈现出独特的匹配关系,其相似度等级高于任意其他两个形状之间的相似度。反之,若将形状 a 视为待识别的未知形状,那么依据此方法,我们所能得出的结论仅是:形状 a 与其余五个形状的相似度等级均为 6。上述信息亦可归纳呈现为图 12.17(c) 所示的相似性矩阵形式。
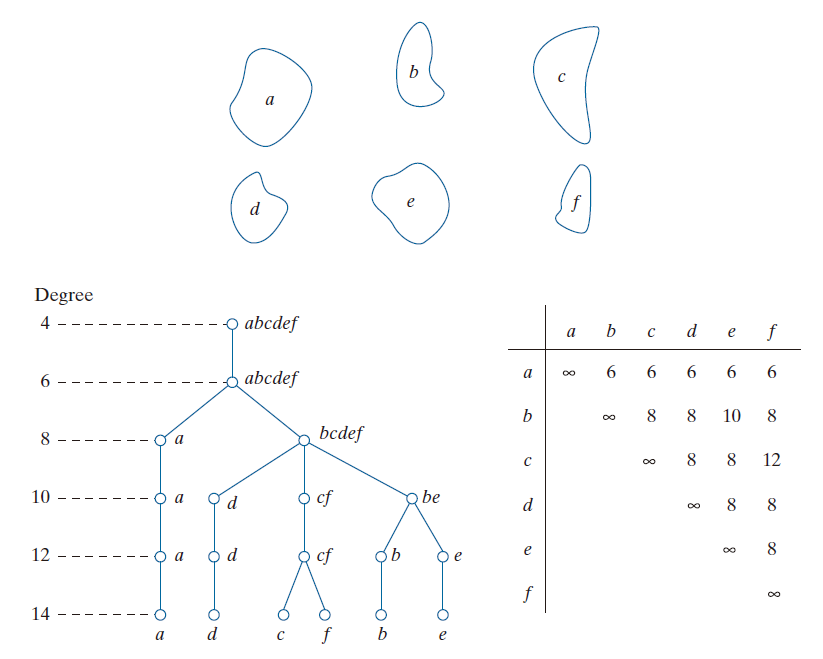
----------------------图 12.17:(a) 形状。(b) 相似性树。(c) 相似性矩阵。(Bribiesca 和 Guzman)--------------------------------------------------------
12.3.4.2 字符串匹配(String Matching)
假设两个边界 a 和b 编码成符号字符串,分别用 和
表示。令 α 表示这两个字符串之间的匹配数,其中,若
,则一个匹配出现在第 k 个位置。不匹配的符号数是
(12-14)
其中,|arg| 是参数中字符串的长度(符号数)。可以证明,当且仅当 a 和 b 相等时(见问题 12.7 ),β = 0 。
一个有效的相似度测度是比率
(12-15)
我们观察到,在完美匹配的情况下,R 的取值为无穷大;而在 a 和 b 中没有任何对应符号匹配时(此时 a = 0),R 的取值为 0 。由于匹配过程是逐符号进行的,因此,确定各边界上的起始点对于减少匹配所需的计算量至关重要。任何能够将起始点归一化至同一位置(或相近位置)的方法,只要其在计算效率上优于“穷举匹配法”,便具有实用价值。所谓穷举匹配法,是指从每条字符串的任意位置开始匹配,随后对其中一条字符串进行移位操作(采用循环移位方式),并在每一次移位后计算公式 (12-15) 的数值。R 值达到最大时,即对应着最佳的匹配结果。
例 12.4:字符串匹配。
图 12.18(a) 和 (b) 展示了来自两个不同物体类别的边界样本,这些边界均通过多边形拟合方法进行了近似处理( 参见第 11.2 节 )。图 12.18(c) 和 (d) 则分别展示了与图 12.18(a) 和 (b) 中边界相对应的多边形近似结果。通过在顺时针遍历每个多边形的过程中计算相邻线段间的内角 θ ,从而将这些多边形转化为相应的字符串序列。这些角度编码为八种可能的符号之一,分别对应于 45° 的整数倍;即, ;
;… ;
。
图12.18(e)展示了针对对象1的六个样本进行自身比对(即样本内部比对)时,所计算出的度量值R的结果。表中的条目即为R的数值;例如,标记1.c指的是来自对象类别1的第三个字符串。图12.18( f )展示了针对第二个对象类别的字符串进行自身比对的结果。最后,图12.18(g)展示了通过将某一类别的字符串与另一类别的字符串进行交叉比对所获得的R值。这些R值显著小于前两个表格中的任何条目。这表明,R 度量在区分这两个对象类别方面实现了高度的辨识能力。例如,假设字符串1.a所属的类别尚不明确,那么将其与类别1的样本(原型)字符串进行比对时,所产生的R值最小值将为4.7 [参见图12.18(e)]。相比之下,将其与类别2的字符串进行比对时,所产生的R值最大值仅为1.24 [参见图12.18(g)]。基于这一结果,便可得出结论:字符串1.a属于对象类别1 。这种分类方法与此前介绍的“最小距离分类器”具有异曲同工之妙。
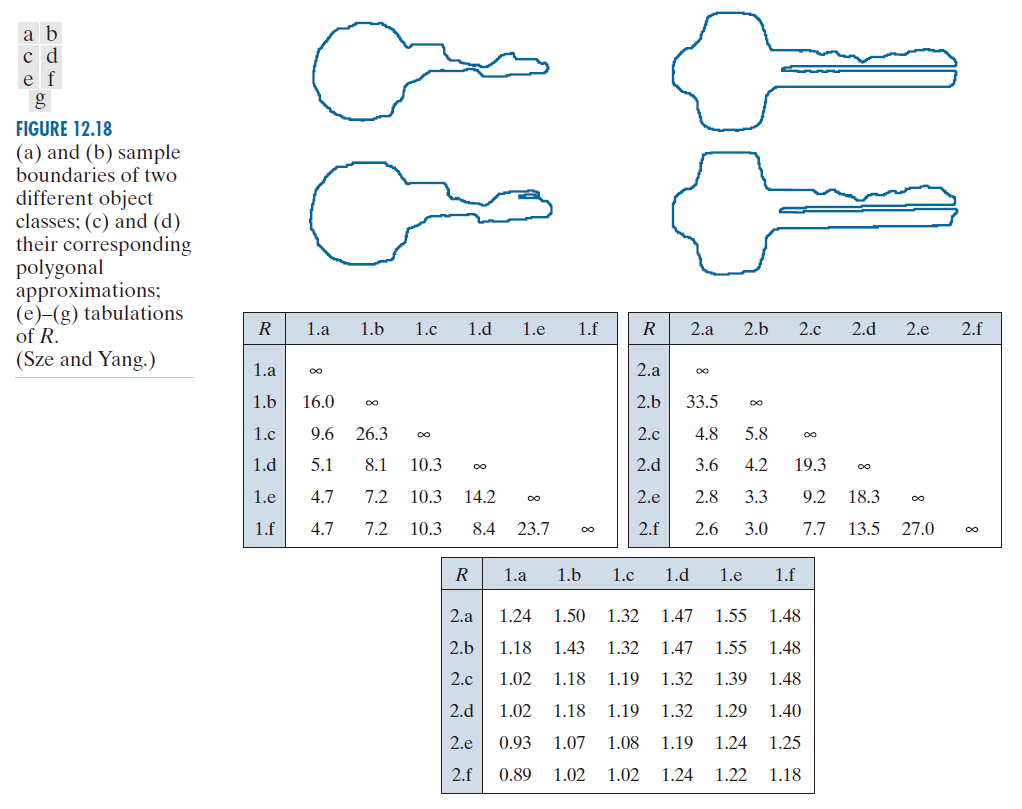
------------------图 12.18:(a) 和 (b) 示例了两种不同物体类别的边界;(c) 和 (d) 为其对应的多边形逼近;(e)–(g) 为 R 值的列表。(Sze 和 Yang)-------------------
12.4 最优(Bayes)统计分类器(Optimum (Bayes) Statistical Classifiers)
在本节中,我们将构建一种用于模式分类的概率方法。正如在大多数涉及物理事件测量与解读的领域中所见,概率考量在模式识别中显得尤为重要,其原因在于模式类别通常是在随机性的作用下产生的。正如随后的讨论所示,我们能够推导出一套分类方法,该方法在某种意义上是“最优”的——即从平均意义上讲,它能使分类错误的概率达到最低(参见习题 12.12)。
12.4.1 Bayes分类器的推导(Derivation of the Bayes Classifier)
一个模式向量 x 出自类别 的概率表示为
。若模式分类器确定 x 来自
而其实际上来自
时,就出现了一个丢失(很快将定义),表示为
。 由于模式 x 可以属于
个可能类别中的任意一个类, 因此,将 x 分配给类
所出现的平均丢失是
(12-16)
用决策论术语来说,量 称为条件平均风险(conditional average risk)或丢失(loss)。
根据 Bayes 法则我们可知,p(a/b) = [p(a)p(a/b)]/p(b) ,因此,我们可以将公式 (12-16) 写成
(12-17)
其中, 来自类
的模型之概率密度函数(PDF),而
是类
出现的概率( 有时候 ,
称为一个先验(priori)概率,或简称先验)。由于 1/ p(x) 是正的,且对于所有
是公有的,因此可以从公式 (12-17) 中删除而不会影响这些函数从最大到最大值的顺序。从而平均丢失表达式则简化为
(12-18)
给定一个未知模型,分类器有 种供选择的可能类。若分类器对每一个 x 计算
,并根据最小丢失将其模式分配给类。则针对所有决策的总平均丢失将最小。最小化总平均丢失的分类器称为Bayes 分类器。若
(
且
) 这个分类器将一个未知的模式分配给类
。换言之,若
(12-19) ( 对所有 j 且 j ≠ i )
则 x 分配给类 。对于正确决策,损失通常被赋予0的值;对于错误决策,损失通常被赋予1的值。则,丢失函数成为
(12-20)
其中,若 i = j , , 而若 i ≠ j ,
。公式 (12-20) 表明,对于错误决策 决策,丢失为1 ,对于正确决策,丢失为0 。将公式 (12-20) 代入公式 (12-18)得到
(12-21)
则,若对于所有的 i ≠ j ,有
(12-22)
或者,等价地,若
(12-23) ( j = 1 ,2 , … ,
且 j ≠ i )
则Bayes 分类器将一个模式 x 分配给类 。因此,若对于所有 j ≠ i ,有
,则一个 0-1 丢失函数的 Bayes 分类器计算形如
(12-24)
的决策函数,并将一个模式分配给 。这正是公式 (12-5) 中所描述的同一过程,但我们当前处理的是那些已被证明为最优的决策函数——其最优性体现在它们能够使误分类的平均损失最小化。
为了使Bayes决策函数最优,必须知道每一类模式的概率密度函数以及每一类出现的概率。后一个要求通常不是问题。例如,若所有的类都具有相同的出现可能,则 。即使这一条件不成立,这些概率通常仍可根据对问题的了解推断出来。估计概率密度函数
更为困难。若模式向量是 n 维的,则
是一个 n 变量函数。若
的形式未知,则估计它要求使用多变量估计方法。这些方法在实际应用中往往难以实施,尤其是当各类别的代表性模式数量较少,或者概率密度函数表现不规则时。鉴于这些原因,Bayes分类器的应用通常基于这样一种假设:即概率密度函数具有某种解析表达式。如此一来,该问题便转化为利用各类别的训练模式样本,来估计所需的各项参数。迄今为止,对于
所采用的最普遍形式是Gauss概率密度函数。这一假设越接近现实,Bayes分类器在分类中就越接近最小平均损失。
12.4.2 Gauss模式类的Bayes分类器 (Bayes Classifier for Gaussian Pattern Classes)
首先,我们考虑一个一维情况( n = 1 ),其涉及两个模式类 ( ) (其符合 Gauss 密度,且均值分别为
和
, 标准偏差分别为
和
)。根据公式 (12-24),其Bayes 决策函数具有形式
(12-25)
其中,现在的模式是标量,用 x 表示。图 12.19 显示了这两个类的概率密度函数的一段图示。这两个类的边界是一个单点 ,其使得
。若这两个类具有相同的出现概率,则
,决策边界是满足
的
值 。这个点是这两个概率密度函数的交点,如图 12.19 所示。
的右侧任意模式(点)都归属于
类 。类似地,
的左侧任意模式(点)都归属于
类 。当这些类不具有相同的出现概率时,若
出现概率更高,则
移到左边,或,反之,若
出现概率更高,则
移到右边。这一结果是符合预期的,因为分类器旨在最小化误分类损失。例如,在极端情况下,如果类别
从未出现,那么分类器永远都不会出错,所有模式一律归类为
(即
将趋向于负无穷大)。
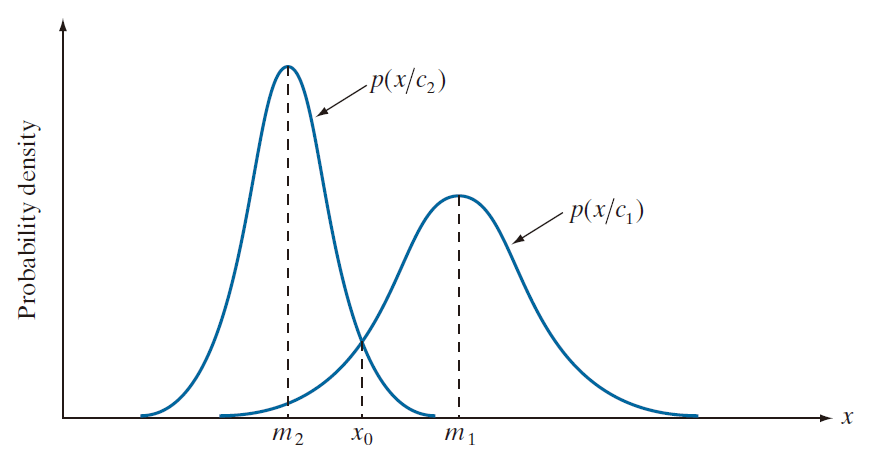
---------------------图 12.19:两个一维模式类的概率密度函数。若这两个类出现的概率相等,则点 (位于两条曲线的交点处)即为Bayes决策边界。-------------------
在 n 维的情况下,在第 j 个模式类中的向量之 Gauss 密度具形式
(12-26)
其中,每一个密度都完全由其均值向量 和协方差矩阵
,其定义为
(12-27)
和
(12-28)
其中, 是类
的模式上的预期参数值。在公式 (12-26) 中,n 是模式向量的维数,而
是矩阵
的行列式。通过采样平均对预期值
进行近似,就得到了一个均值向量估计值和协方差矩阵:
(12-29)
和
(12-30)
其中, 是来自类
的采样模式向量的数量,且求和在这些向量之上计算所得。在本节稍后部分,我们将举例说明如何使用这两个表达式。
协方差矩阵是对称且半正定的。其第 k 个对角线元素即为模式向量中第 k 个元素的方差。第 ( k , j ) 个非对角线元素则表示这些向量中元素 和
之间的协方差。当协方差矩阵的非对角线元素均为零时——这种情况发生于向量元素
与
互不相关之时——多元Gauss密度函数便简化为向量 x 中各元素的一元Gauss密度函数的乘积。
根据公式 (12-24) , 的Bayes 决策函数是
。然而,Gauss函数的指数形式使我们能够处理该判别函数的自然对数,这更为便捷。换言之,我们可以采用形式
(12-31)
就分类性能而言,该表达式等价于公式 (12-24),因为对数函数是一个单调递增函数。即,公式 (12-24) 与公式 (12-31) 中判别函数的数值排序是相同的。将公式 (12-26) 代入公式 (12-31),可得
(12-32)
项 对于所有类都相同,因此可以从公式 (12-32) 中消除,然后成了
(12-33)
( ) 。该公式给出了在 0-1 损失函数条件下,Gauss模式类的Bayes判决函数。
公式 (12-33) 中的判决函数均为超二次曲面( 即 n 维空间中的二次函数 ),因为该公式中未出现关于向量 x 各分量的次数高于二次的项。显然,对于针对Gauss模式的Bayes分类器而言,其所能达到的最佳效果,便是在每一对模式类别之间建立一个二次判决边界。若模式总体确实服从Gauss分布,则没有任何其他类型的边界能够在分类过程中产生更低的平均损失。
若所有协方差矩阵都是相等的,则 。展开公式 (12-33)并删去所有不依赖 j 的项,我们求得
(12-34)
这是一个线性决策函数(超平面) ( 对于 ) 。
此外,若 C = I ,其中,I是单位矩阵(identity matrix) ,同样,若类是等概率出现的(即,对于所有的 j ,有 ), 则我们可以删去项
,因为对于 j的所有可能值,其都将会是相同的。则公式 (12-34) 成为
(12-35) ( 对于
)
我们将这些公式识别为最小距离分类器决策函数 [参见公式(12-4)]。因此,正如前文所述,若满足以下条件,则最小距离分类器在Bayes意义上是最优的:(1) 模式类别服从Gauss分布;(2) 所有的协方差矩阵均等于单位矩阵;(3) 所有类别的先验概率均相等。满足这些条件的Gauss模式类别在 n 维空间中表现为形状完全相同的球形点云(称为超球体)。最小距离分类器在每一对类别之间建立一个超平面,该超平面具有如下特性:它是连接这对超球体中心点的线段的垂直平分面。在二维空间中,模式点分布于圆形区域内,此时的分类边界退化为直线,这些直线垂直平分连接每一对此类圆形区域中心点的线段。
例 12.5:三维模式 Bayes 分类器。
我们利用图 12.20 中的简单模式,来阐释前述推导过程的机理。我们假设这些模式是从两个Gauss总体中抽取的样本,且各类别的出现概率均等。应用公式 (12-29)于图中的模式得到
,
且根据公式 (12-30),有
此矩阵之逆矩阵为
接下来,我们推导出决策函数。由于协方差矩阵相等,且我们假设各类别具有等概率,因此公式 (12-34) 适用:
执行这个向量矩阵展式,我们就得到两个决策函数:
和
则分离两个类的决策边界是
图 12.20 展示了该平面曲面的一个截面。请注意,各类别已得到有效分离。
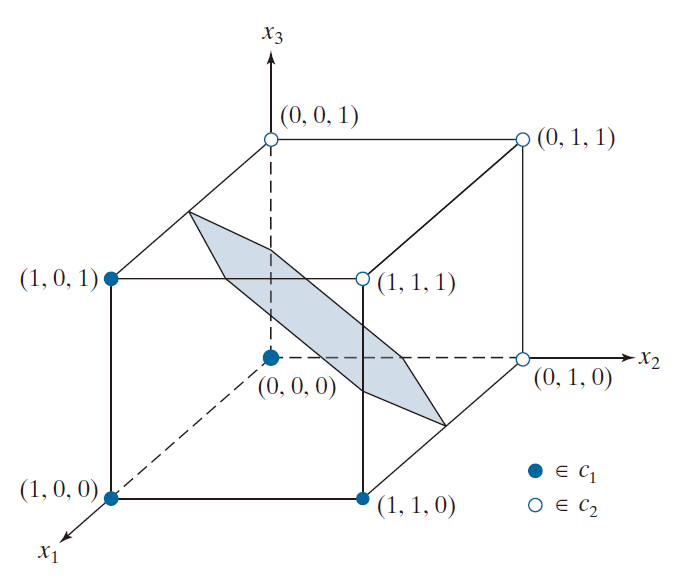
--------------------------图 12.20:两个简单的模式类别,及其与立方体相交的Bayes决策边界部分(阴影区域)。---------------------------------------------------
例 12.6:基于Bayes分类器的多光谱数据分类。
如第 1.3 节和第 11.5 节所述,多光谱扫描仪对电磁波谱的特定波段有响应,例如:0.45–0.52 微米、0.53–0.61 微米、0.63–0.69 微米和 0.78–0.90 微米波段。这些波段分别位于可见光蓝光、可见光绿光、可见光红光和近红外波段。使用这些多光谱波段扫描地面区域,可以生成该区域的四幅数字图像。
每一个波段对应一个。如果这些图像在空间上已完成配准,便可将其视为彼此堆叠在一起,如图 12.7 所示。正如我们在该图中解释的那样,在本例中,地面上的每一个点均可用一个形如 的四维模式向量来表示,其中,
是蓝色阴影 ,
是绿色阴影,等等 。
若图像尺寸为 512 × 512 像素,则每组由四幅多光谱图像构成的栈,可用 266,144 个四维模式向量来表示。正如前文所述,针对Gauss模式的Bayes分类器,需要对每一类别的均值向量和协方差矩阵进行估计。在遥感应用中,这些估计值是通过利用来自各感兴趣区域的训练用多光谱数据来获取的;这些训练数据的类别信息是已知的(这种已知信息有时被称为“基础真相或真实目标值(ground truth)”)。随后,利用由此得到的向量来估计所需的均值向量和协方差矩阵,具体过程参见示例 12.5。
图 12.21(a) 至 (d) 展示了四幅华盛顿特区周边的 512 × 512 多光谱图像,这些图像是在上一段落提及的波段下获取的。我们的目标是将这些图像中的像素归类为以下三种模式类别之一:水体、城市开发区或植被。图 12.21(e) 中的掩模被叠加到图像上,用于提取代表这三种类别的样本。其中一半样本用于训练(即用于估计均值向量和协方差矩阵),另一半样本则用于独立测试,以评估分类器的性能。我们假设先验概率相等,即 (其中 j = 1 , 2 , 3 ) 。
表 12.1 总结了我们利用训练集和测试集所获得的分类结果。在这两个数据集中,被正确识别的训练模式向量和测试模式向量所占的百分比大致相同,这表明所学习的参数并未对训练数据产生过拟合。在这两种情况下,最大的误差均出现在源自城市区域的模式上。这一结果并不出人意料,因为该区域同时也存在植被(值得注意的是,植被区域或城市区域中的模式均未被误分类为水体)。图 12.21( f ) 中,黑点表示被误分类的训练和测试模式,白点则表示被正确分类的模式。在区域 1 中未见黑点,这是因为那七个被误分类的点距离白色区域的边界非常近。根据表中的数据计算可知,训练模式的正确识别率为 96.4%,测试模式的正确识别率为 96.1% 。
表 12.1:多光谱图像数据的Bayes分类。类别1、2和3分别为水体、城区和植被。
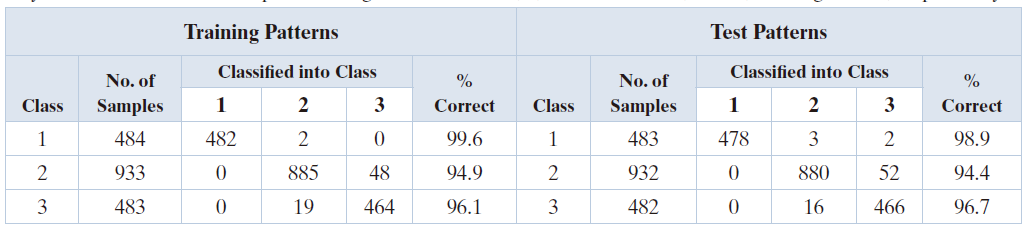
图 12.21(g) 至 (i) 呈现了更为有趣的结果。在此,我们让系统将图像中的所有像素归入三个类别之一。图 12.21(g) 以白色显示了所有被归类为“水体”的像素;未被归类为水体的像素则以黑色显示。由此可见,Bayes分类器在判定图像中哪些部分属于水体方面表现得非常出色。图 12.21(h) 以白色显示了所有被归类为“城市开发区”的像素;请留意系统在识别桥梁、高速公路等城市地貌特征时的优异表现。图 12.21(i) 则显示了被归类为“植被”的像素。观察图 12.21(h) 的中心区域可以发现,白色像素在市中心地带高度密集,且其密度随距图像中心距离的增加而逐渐降低。图 12.21(i) 则呈现出截然相反的现象:图像中心区域(即城市开发最密集的区域)所显示的植被量最少。
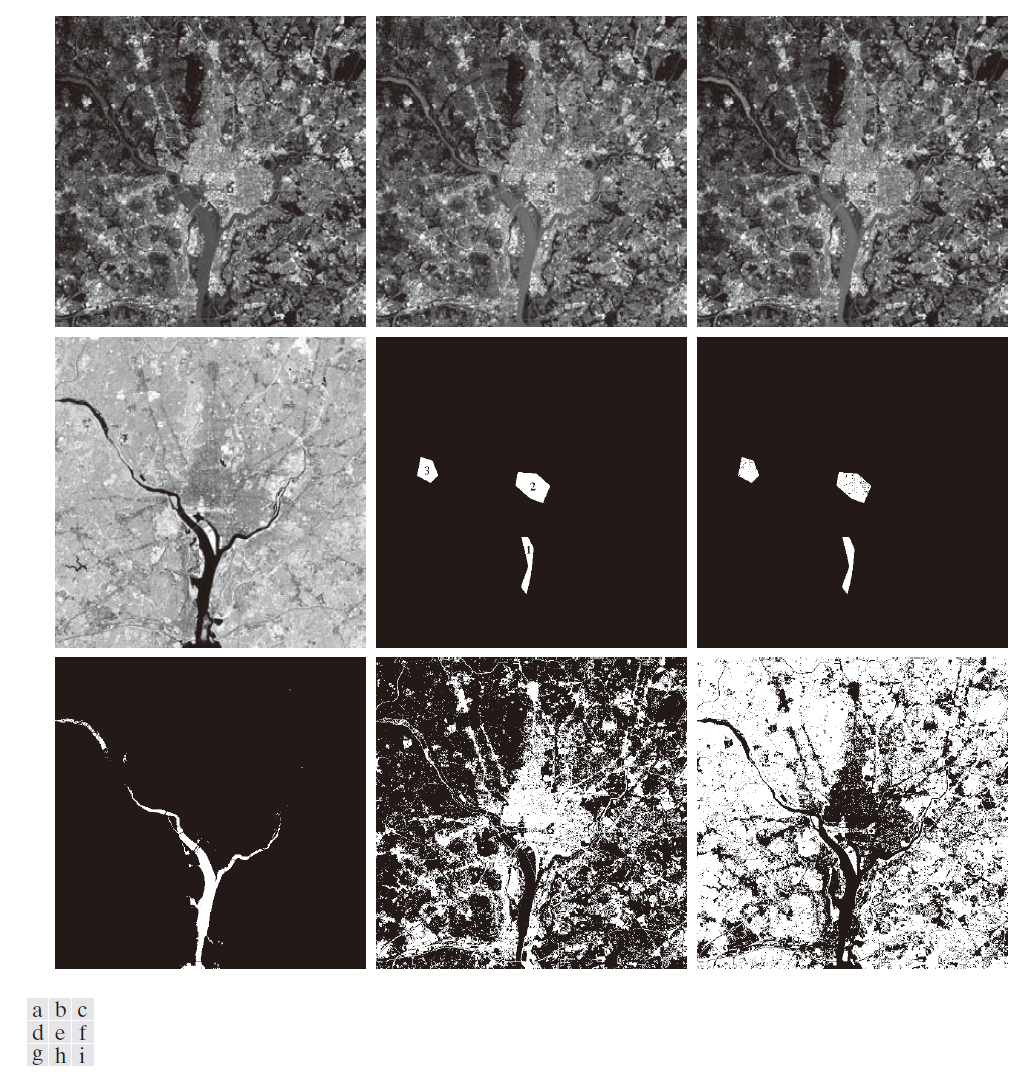
---------------------图 12.21:多光谱数据的Bayes分类。(a)–(d) 分别对应可见光蓝波段、可见光绿波段、可见光红波段以及近红外波段的图像。(e) 水域(标记为1)、城市开发区(标记为 2)和植被区(标记为 3)的掩模。( f ) 分类结果;黑色点表示被错误分类的点。其余(白色)点均被正确分类。( f ) 所有被分类为水域的图像像素(以白色显示)。( h ) 所有被分类为城市开发区的图像像素(以白色显示)。(i) 所有被分类为植被的图像像素(以白色显示)。-------------------------------------------------------------------
我们在第10.3节讨论Otsu方法时曾提到,阈值化可被视为一种Bayes分类问题,其目标是将模式最优地归入两个或多个类别中。事实上,正如前文的示例所示,逐像素分类可被视为一种图像分割过程,即将图像划分为两种或多种不同类型的区域。如果仅采用单一变量(例如像素强度)作为分类依据,则公式(12-24)便转化为一个最优函数,该函数同样是基于像素强度对图像进行分割,正如我们在第10.3节中所做的那样。值得注意的是,若要实现这种“最优性”,前提是必须已知各类别的概率密度函数(PDF)及其先验概率。正如我们此前指出的那样,对这些概率密度进行估计绝非易事。如果不得不引入某些假设(例如假定概率密度符合Gauss分布),那么最终分类结果所能达到的“最优”程度,将取决于这些假设与实际情况的吻合程度。
12.5 神经网络和深度学习(Neural Networks and Deep Learning)
本节及第12.6节内容的宗旨主要在于:对深度神经网络进行入门介绍,并推导构成深度学习理论基石的各类公式。我们将探讨两类不同类型的神经网络。在本节中,我们将重点聚焦于多层全连接神经网络;此类网络的输入为第12.2节中所介绍的那种形式的模式向量。而在第12.6节中,我们将转而探讨卷积神经网络,此类网络具备直接接收图像作为输入的能力。在呈现这两节内容时,我们沿用了同一套基本的方法论。具体而言,我们首先着手推导相关公式,用以描述输入信号如何在网络内部逐层映射,最终生成用于对该输入进行分类的输出结果。随后,我们进一步推导出反向传播算法的公式;这些公式正是用于训练上述两类神经网络的核心工具。在这两节内容中,我们均辅以具体的实例,旨在生动地展示深度神经网络与深度学习在解决复杂模式分类问题方面所展现出的强大效能。
12.5.1 背景(Background)
下文所述内容的本质在于利用大量基本的非线性计算单元(称为“人工神经元(artificial neurons)”)将其组织成网络;这些网络内部的互连方式,在某些方面类似于哺乳动物视觉皮层中神经元相互连接的方式。由此构建的模型有多种称谓,包括神经网络(neural networks)、神经计算机(neurocomputers)、并行分布式处理模型(parallel distributed
processing models)、神经形态系统(neuromorphic systems)、分层自适应网络(layered self-adaptive networks)以及联结主义模型(connectionist models)。在此,我们统一采用“神经网络(neural networks)”这一名称,简称“神经网(neural nets)”。我们利用这些网络作为载体,通过反复呈现训练样本,以自适应的方式学习决策函数的参数。
人们对神经网络的兴趣可追溯至20世纪40年代初,McCulloch 和 Pitts [1943] 的工作便是其中的典型代表;他们提出了以二元阈值器件(binary thresholding devices)形式呈现的神经元模型,以及涉及状态在 0-1 和 1-0 之间骤变的随机算法,并将其作为构建神经系统模型的基础。随后,Hebb [1949] 的研究工作基于一系列数学模型,旨在尝试体现通过强化或联想进行学习这一概念。
在 20 世纪 50 年代中期至 60 年代初,一类由 Rosenblatt (Rosenblatt [1959, 1962]) 首创的所谓“学习机”,在模式识别领域的研究人员和从业者中引发了极大的热潮。人们之所以对这类被称为“感知机”(perceptrons )的机器产生浓厚兴趣,是因为当时出现了一些数学证明,表明感知机若利用线性可分离训练集(即可通过超平面进行分割的训练集)进行训练,便能在有限次迭代步骤内收敛于一个解。该解的形式表现为超平面的参数(系数),而这些超平面能够正确地将训练集中各类模式所代表的类别区分开来。
遗憾的是,在发现了一个看似基础扎实的学习理论模型之后,人们随之产生的种种期望很快便化为了泡影。基础感知机及其某些推广形式,对于大多数具有实际意义的模式识别任务而言,显得力不从心。随后,人们曾试图通过引入多层结构来增强这类感知机式机器的功能,但这些尝试却苦于缺乏有效的训练算法——而正是这类算法,曾一度激发了人们对感知机本身的浓厚兴趣。Nilsson [1965] 对20世纪60年代中期“学习机器”这一领域的发展状况进行了总结。数年之后,Minsky 和 Papert [1969] 发表了一篇令人沮丧的分析文章,揭示了感知机式机器的种种局限性。这种观点一直延续到了20世纪80年代中期,Simon [1986] 的相关评论便印证了这一点。在这部最初于1984年以法语出版的著作中,Simon 在题为《神话的诞生与终结》( Birth and Death of a Myth )的章节里,对感知机给予了彻底的否定。
Rumelhart、Hinton 和 Williams [1986] 近期取得的成果,涉及针对类感知器单元多层结构的全新训练算法的开发,极大地改变了这一领域的局面。他们的基本方法称为“反向传播”(简称 backprop),为多层网络提供了一种行之有效的训练手段。尽管从单层感知器证明的意义上讲,尚无法证明该训练算法必然收敛至某一解,但反向传播算法所产生的成果,已彻底革新了模式识别这一领域。
迄今为止我们所研究的模式识别方法,均依赖于人工设计的技术,将原始数据转化为适合计算机处理的格式。我们在第11章中探讨的特征提取方法,便是此类技术的典型范例。与上述方法截然不同的是,神经网络能够利用反向传播机制,直接从原始数据出发,自动学习出适合进行模式识别的表征。网络中的每一层都会对数据表征进行逐层“提炼”,将其转化为更为抽象的层次。这种多层次的学习模式通常被称为“深度学习”;而正是得益于这一核心能力,神经网络在各类应用领域中才取得了如此巨大的成功。正如我们在本节开篇所指出的那样,深度学习在实际应用中,通常需要依赖大规模的数据集作为支撑。
当然,这些并非能够自动构建自身的“神奇”系统。人类的干预依然必不可少,需要人工设定诸如层数、每层人工神经元的数量,以及各种取决于具体问题的系数等参数。教会复杂的层级神经网络进行准确识别并非一门纯粹的科学;相反,它更像是一门艺术,要求设计者具备渊博的知识并进行大量的实验探索。在无数的模式识别应用场景中——特别是在受限的环境下——采用更为“传统”的方法往往是最佳选择。风格化字体识别便是一个极佳的例证。若要专门开发一个神经网络来识别我们在图 12.11 中探讨过的 E-13B 字体,那将是毫无意义之举。如果应用需求仅限于读取印制在银行支票上的 E-13B 字体,那么基于硬连线架构实现的最小距离分类器便是解决该问题的理想方案。然而,若将应用范围扩展至要求高精度地读取支票上的所有相关文本(包括手写草书),那么神经网络便证实为理想的解决方案。
深度学习在解决那些传统方法束手无策的应用难题方面,展现出了非凡的成效。自反向传播算法问世以来的二十年间,神经网络已成功应用于广泛的领域。其中一些应用——例如语音识别——甚至已成为我们日常生活中不可或缺的一部分。当你对着智能手机说话时,那近乎完美的识别功能,正是由神经网络所实现的。而就在短短几年前,这种级别的性能还是遥不可及的。你可能在不经意间就已经从中受益的其他应用还包括:能够学习用户偏好、从而将垃圾邮件及其他冗余信息从收件箱中自动分流的“智能过滤器”;以及能够自动识别信件上邮政编码的系统。此外,你经常会在电视片段中看到自动驾驶车辆在道路上穿梭,或是能够与周围环境进行交互的各类机器人。而这些应用方案,绝大多数都是基于神经网络构建的。至于那些相对不那么为人熟知的应用,则涵盖了新药的自动化研发、DNA 研究中对基因突变的预测,以及自然语言理解领域的各项前沿突破。
尽管神经网络的实际应用清单可谓洋洋大观,但这项技术在图像模式分类领域的应用普及速度相对较慢。正如你稍后将要了解到的那样,在图像处理中运用神经网络,主要依赖于一种被称为“卷积神经网络”(简称 CNN 或 ConvNet)的架构。CNN 最早且广为人知的应用之一,当属 LeCun 等人 [1989] 所开展的用于识别美国手写邮政编码的研究工作。此后不久,又涌现出了许多其他的应用实例;然而,直到 2012 年 ImageNet 挑战赛的结果公布之后(参见 Krizhevsky, Sutskever 和 Hinton [2012] 等人的研究),CNN 才真正在图像模式识别领域得到了广泛的应用。如今,它已成为解决复杂图像识别任务的首选方法。
神经网络领域的文献浩如烟海,且正处于飞速演变之中;因此,照例,我们的策略是专注于基础知识。在本节及随后的章节中,我们将奠定坚实的基础,阐明神经网络的训练机制及其在训练完成后的运作原理。首先,我们将简要探讨“感知机”(Perceptrons)。尽管作为独立的计算元件,感知机在当今的神经网络架构中已不再直接采用,但其所执行的运算功能与“人工神经元”——即神经网络最基本的计算单元——几乎如出一辙。事实上,若不提及感知机,任何关于神经网络的入门介绍都将显得不够完整。在完成这一探讨之后,我们将深入细致地阐述“反向传播”(Backpropagation)算法的理论基础。在推导出反向传播的基本公式后,我们将其转化为矩阵形式;这一转化使得神经网络的训练与运行过程得以简化为一系列简单、直接的矩阵乘法级联运算。
在研习了几个全连接神经网络的实例之后,我们将采用类似的方法来构建卷积神经网络(CNN)的基础,具体涵盖其与全连接神经网络的异同,以及两者在训练方式上的差异。随后,我们将通过若干实例,展示如何利用 CNN 进行图像模式分类。
12.5.2 感知机(The Perceptron)
单个感知机单元能够学习出介于两个线性可分离模式类之间的一条线性边界。图 12.22(a) 展示了二维空间中最简单的示例:包含两个模式类,且每一个类仅由一个模式组成。在二维空间中,线性边界即为一条直线,其公式为 y = ax + b ,其中系数 a 表示斜率,b 表示 y 轴截距。值得注意的是,若 b = 0,则该直线将穿过原点。因此,参数 b 的作用在于使直线相对于原点发生平移,而不会改变其斜率。正因如此,这个未与任何坐标变量相乘的“浮动”系数,通常称为“偏置”(bias)、“偏置系数”或“偏置权重”。
我们关注的是图 12.22 中将这两个类别分离开的一条直线。这条直线的定位方式是:来自类别 的样本点
位于该直线的一侧,而来自类别
的样本点
则位于另一侧。位于该直线上的点 ( x , y ) 的轨迹,满足公式 y - ax - b = 0 。由此可知,若将直线上某一侧的点的坐标代入该公式,所得结果将为正值;反之,若代入另一侧的点的坐标,所得结果则为负值。
通常,我们处理的是远高于二维的模式,因此我们需要更为通用的记法。n 维空间中的点即为向量。一个向量的分量 是点的坐标。对于分离两个类的边界系数,我们使用记号
,其中,
是偏置系数。利用这种记法,我们的直线一般公式是
( 我们可以利用斜截形式将该公式表示为
)。图 12.22(b) 与 (a) 相同,只是使用了这种符号。通过比较这两个图,我们可以看到,
,和
。根据我们更多的一般记法,我们称,若
,则任意点
位于一条直线的正侧,反之,位于这条直线的负侧。对于三维中的点,我们使用平面公式
,但会执行完全相同的测试,以确定一个点位于平面的正侧还是负侧。对于 n 维空间中的点,该测试将针对超平面进行,其公式为
(12-36)
用求和表达式,该公式表示为
(12-37)
或者表示为向量形式
(12-38)
其中, w 和 x 是 n 维列向量,而 是两个向量的点(内)积。因为内积是可交换的,因此,公式 (12-38) 的等价形式为
。同上,我们称 w 为权重向量,而称
为偏置系数。由于偏置系数是一个始终与 1 相乘的权重,因此为了避免重复,我们在统称偏置系数及权重向量中的各元素时,有时会使用“权重”、“系数”或“参数”等术语。
现在我们使用一般形式来表述分离问题,我们称,给定来自某一向量总体的任意模式向量 x ,我们希望找到一组具有以下性质的权值:
(12-39)
在二维空间中,若两个模式类别是线性可分离的,则通过目视检查即可求得一条将它们分离开来的直线。在三维空间中,通过目视检查来求得分离平面虽然难度较大,但也并非不可行。然而,当维度 n > 3 时,通常便无法再通过目视检查来求得分离超平面了;此时,我们必须转而借助算法来求解。感知机正是此类算法的一种具体实现。它通过迭代遍历两个类别中的每一个模式,试图寻得一个解。该算法始于任意选定的权重向量和偏置系数;若已知的类别确实是线性可分离的,则该算法保证能在有限次迭代内收敛。
感知机算法很简单。令 α > 0 表示一个校正增量(correction increment)(也称为学习增量或学习率),令 w(1) 表示一个任意值的向量,并令 表示任意常量。则对 k = 2 , 3 , … 做下列运算:对于一个模式向量 x(k) ,在第 k 步 ,
(1) 若 且
,令
(12-40)
(2) 若 且
,令
(12-41)
(3) 否则,令
(12-42)
当模式属于类别 且公式 (12-39) 未给出正响应时,应用公式 (12-40) 中的修正。同理,当模式属于类别
且公式 (12-39) 未给出负响应时,应用公式 (12-41) 中的修正。正如公式 (12-42) 所示,当公式 (12-39) 给出正确响应时,不作任何更改。
如果我们在每个模式向量的末尾添加 1,并将偏置包含在权重向量中,则可以简化公式 (12-40) 至 (12-42) 中的符号。即,我们定义 和
。则公式 (12-39)成为
(12-40)
其中,两个向量均为 ( n + 1 ) 的。在这个公式中,w 和 x 分别参为增广模式和权重向量。而 (12-40) 到 (12-42) 中的算法则成为:对于任意模式向量 x(k) ,在第 k 步 ,
若
且
,令
(12-44)
若
且
,令
(12-45)
否则,令
(12-46)
其中,初始权重向量 w(1) 是任意的,并且如上所述,α 是一个正常数。由公式 (12-40)–(12-42) 或 (12-44)–(12-46) 实现的过程称为感知器训练算法(perceptron training algorithm)。感知器收敛定理(perceptron training algorithm)指出,如果两个模式类别是线性可分离的(参见问题 12.15),则该算法保证在有限步内收敛到解(即分离超平面)。通常,公式 (12-44)–(12-46) 是实现感知器训练算法的基础,我们将在本节的后续段落中使用它。然而,公式 (12-40)–(12-42) 中的符号(即将偏置项单独列出)在神经网络领域更为普遍,因此你也需要熟悉这种记法。
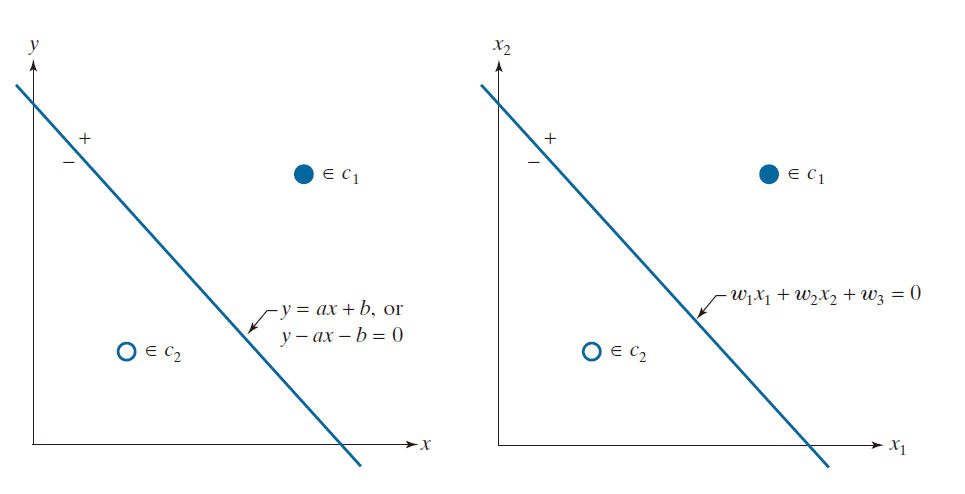
-----------------图 12.22:(a) 二维空间中最简单的两类示例,展示了无限条此类决策边界中的一条可能边界。(b) 同 (a),但决策边界采用更通用的记法表示。------------
图 12.23 展示了感知机的示意图。正如你所见,这台简单的“机器”所做的全部工作,就是利用在训练阶段确定的权重和偏置,对输入模式进行加权求和。该运算的输出是一个标量值,随后该值会通过一个激活函数,产生该单元的最终输出。对于感知机而言,其激活函数是一种阈值函数(在探讨神经网络时,我们将介绍其他形式的激活函数)。如果经过阈值处理后的输出为 +1,我们便判定该模式属于类别 ;反之,若输出为 -1,则表明该模式属于类别
。有时,人们也会使用 1 和 0 这两个数值来表示输出的这两种可能状态。
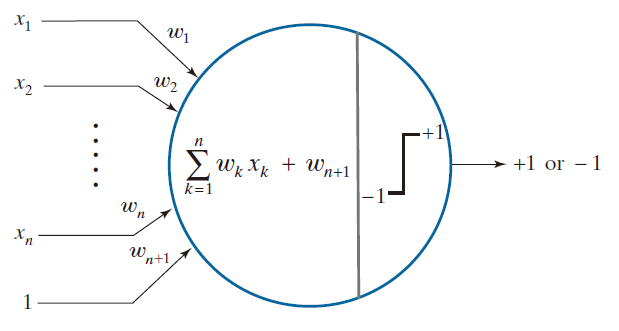
---------------------图 12.23:感知机示意图,展示其执行的操作------------------
例 12.6:利用感知机算法学习决策边界。
我们通过求解图 12.22 中的小型问题来说明感知器学习线性边界系数的步骤。为了简化手动计算,设距离原点最远的模式向量为 ,其它向量为
,, 在此,我们如前所述,通过在向量末尾追加一个 1 对其进行了增广。为了与附图相对应,我们假定这两个模式分别属于类
和
。此外,假设在训练过程中,这些模式按此顺序“循环”通过感知机(对所有训练模式进行一次完整的遍历被称为一个“周期(epoch)”)。首先,我们令 α = 1 且
;则
对于 k = 1 , , 且
,其内积是零,
因此,训练算法的的第二个版本的第 步适用于此:
对于 k = 2 , , 且
。其内积是
结果本应为负,却呈正值。因此,第 步适用于此:
我们已完成了一个完整的训练周期,且至少进行了一次修正,因此我们将再次遍历训练集。
对于 k = 3 , , 且
。 当其内积应当是正值时其内积是正值(即,6 ),因为
。因此,第
步适用于此,且权值向量未变:
对于 k = 4 , 且
。 其内积为正(即,4),而其本该为负,因此第
步适用于此:
由于至少进行了一次修正,因此我们再次循环遍历训练模式。对于 k = 5 ,我们有 ,且利用 w(5) ,我们计算其内积为 5 ,当其应当为正值时为正的,因此,第
步适用于此,我们令
。遵循刚刚讨论的这一步骤,你可以证明(参见问题 12.13),该算法收敛于解权重向量
其给出了决策边界
图 12.24(a) 显示了由该公式定义的边界。如图所示,它清晰地分隔了两个类别的模式。用我们上一节中使用的术语来说,感知机学习到的决策曲面是 ,这是一个平面。如前,决策边界是满足
的点的轨迹,这是一条直线。可视化这个边界的另一种方式是,决策曲面(平面,即
平面 ) 如图 12.24(b) 所示。满足
的所有点在边界的正侧,反之,满足
的所有点在边界的负侧。
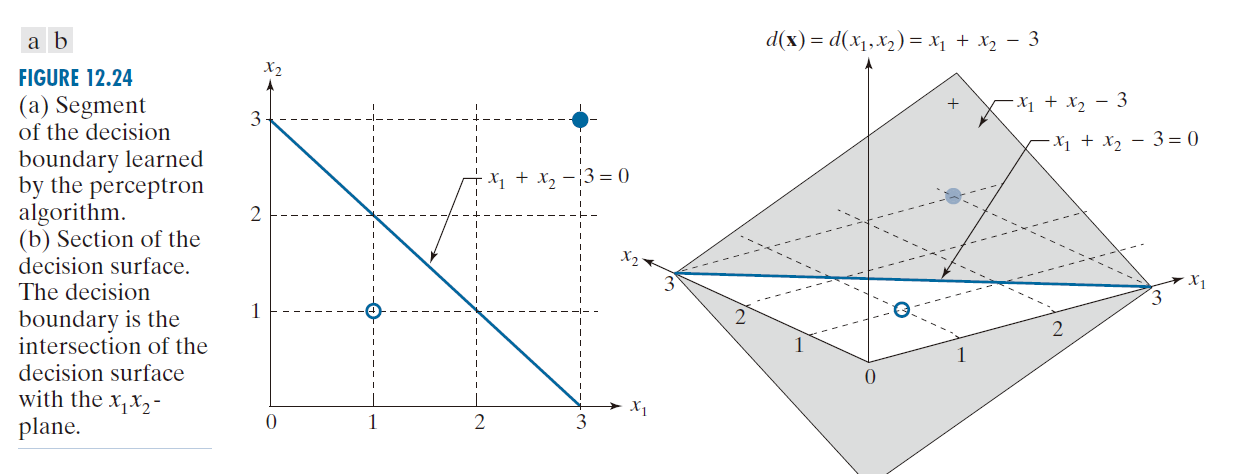
-----------------------图 12.24:(a) 感知机算法所学得的决策边界片段。(b) 决策曲面截面。该决策边界即为决策曲面与 平面的交线。-----------------------
例 12.8:利用感知机对两组鸢尾花数据测量值进行分类。
在图 12.10 中,我们展示了鸢尾花数据库的一个二维简化子集,并提到在其中唯一能与其他类别区分开来的,是山鸢尾(Iris setosa)这一类别。作为感知机算法的又一示例,我们现在将求出山鸢尾与变色鸢尾(Iris versicolor)这两个类别之间的完整决策边界。正如我们在讨论图 12.10 时所提到的,这些数据实际上是四维数据集。设定学习率 α = 0.5,并令所有参数的初始值均为零,该感知机仅经过四个迭代周期(epochs)便收敛,得到了最终的权向量解 ,其中,最后一个元素是
。
在实践中,线性可分离的模式类实属罕见;因此,20 世纪 60 至 70 年代的大量研究精力,均投入到了开发用于处理不可分离模式类的技术之中。随着近年来神经网络领域的飞速发展,上述许多方法如今已沦为仅具历史意义的陈迹,故在此我们不再对其详加赘述。不过,我们仍将简要提及其中的一种方法,因为它与下一节关于神经网络的讨论密切相关。该方法的基本原理在于:在训练过程的每一个步骤中,通过最小化实际响应与期望响应之间的误差来实现目标。令 r 表示我们在训练过程中希望感知机针对任意模式产生的响应。由于我们感知机的输出仅为 +1 或 -1,因此 r 的取值也仅限于这两个数值。我们的目标是寻得一个增广权向量 w ,以使感知机的期望响应与实际响应之间的均方误差(MSE) 达到最小。用于此目的的函数应当是可微的,且具有唯一的最小值。通常选用的函数形式为如下所示的二次函数:
(12-47)
其中,E 是我们的误差测度,w 是我们正在寻找的权值向量,x 是来自训练集的任意模式,且 r 是我们对那个模式的预期响应。w 和 x 均是增广向量。
我们使用迭代梯度下降算法求得 E(w) 的最小值,其形式为
(12-48)
其中,开始的权值向量是任意的,且 α > 0 。
图 12.25(a) 展示了 w 和 x 的标量值 w 和 x 的误差函数 E 曲线图。我们的目标是逐步调整 w 的取值,使 E(w) 趋近于最小值;这意味着 E 的数值应停止变化,或者等价地说,即 ∂E(w)/∂w = 0 。公式 (12-48) 所执行的正是这一操作。若 ∂E(w)/∂w > 0,则会将该导数值的一部分(其大小由“学习增量”α 的取值决定)从当前的权值 w( k ) 中减去,从而得到更新后的新权值 w( k + 1) 。若 ∂E(w)/∂w < 0,则会发生相反的操作。若 ∂E(w)/∂w = 0,则权值保持不变;这意味着我们已抵达误差函数的最小值点,而这正是我们所寻求的解。参数 α 的取值决定了权值修正量的相对大小。如图 12.25(a) 所示,若 α 的取值过小,则每次调整的步长也会相应地较小,导致权值向收敛点移动的速度十分缓慢。另一方面,如图 12.25(b) 所示,若 α 的取值过大,可能会导致权值在最小值点两侧产生剧烈的震荡,甚至引发系统的不稳定性。目前尚无通用的准则来指导参数 α 的选取。不过,一种合乎逻辑的策略是:先设定一个较小的初始值,随后通过逐步增大 α 的取值进行实验,以此来探究该参数对特定训练样本集所产生的影响。图 12.25(c) 展示了包含两个变量时的误差函数曲面形态。
由于误差函数是解析且可微的,我们可以将公式 (12-48) 表示为无需在每一步显式计算梯度的形式。E(w) 对 w 的偏导数为
(12-49)
将此结果代入公式 (12-48) 得到
(12-50)
即以已知项或易于计算的项来表示。同前,w( 1 ) 是任意的。
Widrow 和 Stearns [1985] 指出,对于式 (12-50) 中的算法而言,参数 α 处于 0 < α < 2 的范围内是其收敛的必要条件(但非充分条件)。α 的典型取值范围通常为 0.1 < α < 1.0 。尽管此处未给出证明,但该算法最终会收敛于一个解,该解能够使训练集样本上的均方误差达到最小值。正因如此,该算法常称为“最小均方误差”(LMSE- least-mean-squared-error)算法。在实际应用中,当误差值下降至某一预设阈值以下时,我们便认为该算法已经收敛。算法收敛时所得到的解,未必是一个能够将两个线性可分类别完全分隔开来的超平面。换言之,基于均方误差准则得到的解,并不等同于感知机训练定理意义下的解。这种不确定性,正是采用一种其收敛性不受模式类别线性可分性约束的算法所必须付出的代价。
例 12.9:使用 LMSE 算法。
对比 LMSE 算法在处理与例 12.8 中相同的可分离鸢尾花数据集时的性能,将是一件很有趣的事情。图 12.26(a) 绘制了误差 [见公式 (12-47)] 随迭代轮次(epoch)变化的曲线,共进行了 50 个迭代轮次;其中,权重的计算采用了公式 (12-50)(设定参数 α = 0.001),且初始权重设定为 w(1) = 0 。每一个训练迭代轮次均包含一系列顺序更新权重的操作:每次针对一个模式进行更新,并依据公式 (12-47) 计算该权重与对应模式所产生的误差。在迭代轮次结束时,将所有误差值求和并除以 100 (即模式的总数),从而得到均方误差(MSE)。由此计算出的数值构成了图 12.26(a) 曲线上的一个数据点。误差值在经历了先上升后迅速下降的过程后,大约在第 20 个迭代轮次之后便不再发生显著变化。例如,在第 50 个迭代轮次结束时,误差值为 0.02;而在第 1000 个迭代轮次结束时,误差值变为 0.0192。虽然通过进一步减小参数 α 的取值,确实有可能获得更小的误差值,但正如图 12.25 所指出的那样,这样做是以减缓误差收敛速度为代价的。此外还需注意,均方误差(MSE)与正确识别率之间并非呈直接正比关系。
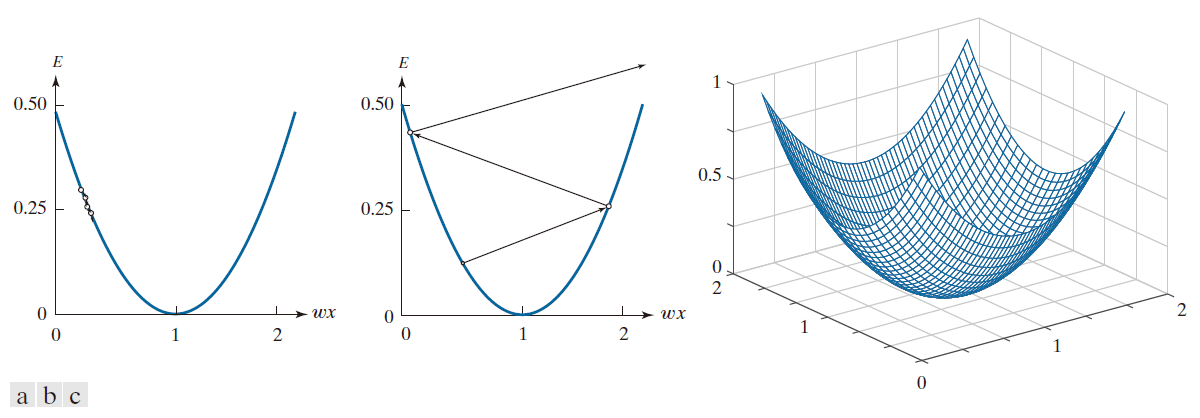
-----------------------------------图 12.25:当 r = 1 时,E 随 wx 变化的曲线图。(a) α 值过小可能导致收敛变慢。(b) 若 α 值过大,可能会出现剧烈振荡或发散。(c) 误差函数在二维空间中的形态。-----------------------------------------------
经过50个训练周期后,权重向量为 。利用该向量,所有模式均正确归类至其各自所属的两个类别中。即,尽管均方误差(MSE)并未降至零,但由此得到的权向量依然能够对所有模式进行正确分类。不过请务必注意,LMSE 算法并非总能对线性可分离类别实现 100% 的正确识别。
如前所述,仅鸢尾属中的刚毛鸢尾(Iris setosa)样本与其他样本是线性可分的;而变色鸢尾(Iris versicolor)和弗吉尼亚鸢尾(Iris virginica)样本则不然。当面对这些数据时,感知机算法将无法收敛,而 LMSE 算法却能收敛。图 12.26(b) 展示了针对这两组数据集,均方误差(MSE)随训练迭代次数( epoch )变化的曲线;该结果是在沿用图 (a) 中所设定的 w(1) 和 α 的相同取值下获得的。这一次,均方误差耗费了 900 个迭代周期才最终稳定在 0.09 这一数值上,这远高于此前所得的数值。最重所得权重向量为 。使用该向量对 100 个模式进行分类,产生了 7 处误分类错误,识别率为 93% 。
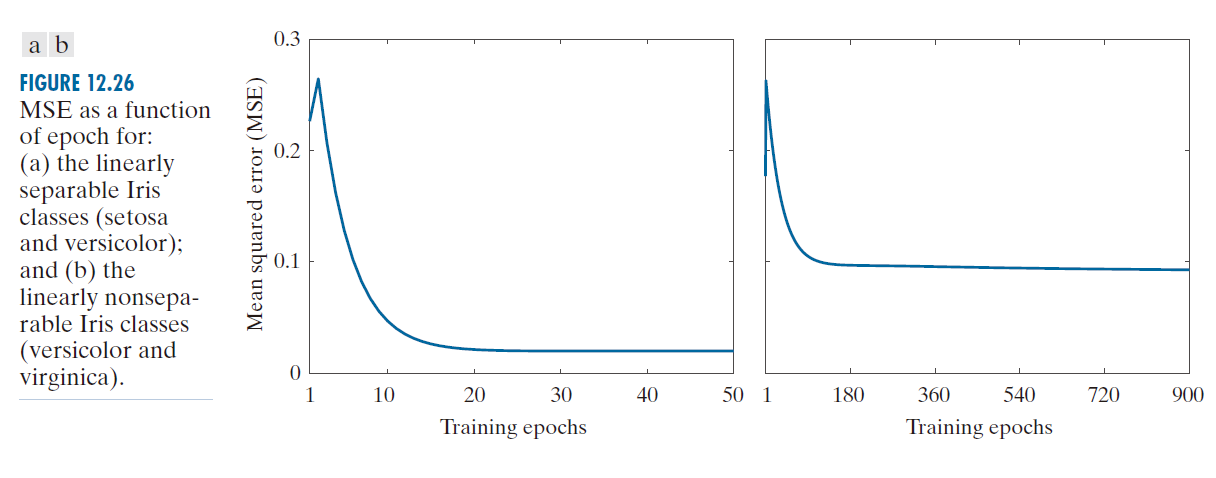
----------------------------图 12.26:MSE 随 epoch 的变化曲线,分别对应:(a) 线性可分的 Iris 类别(setosa 和 versicolor);以及 (b) 线性不可分的 Iris 类别(versicolor 和 virginica)。-------------------------------------------------
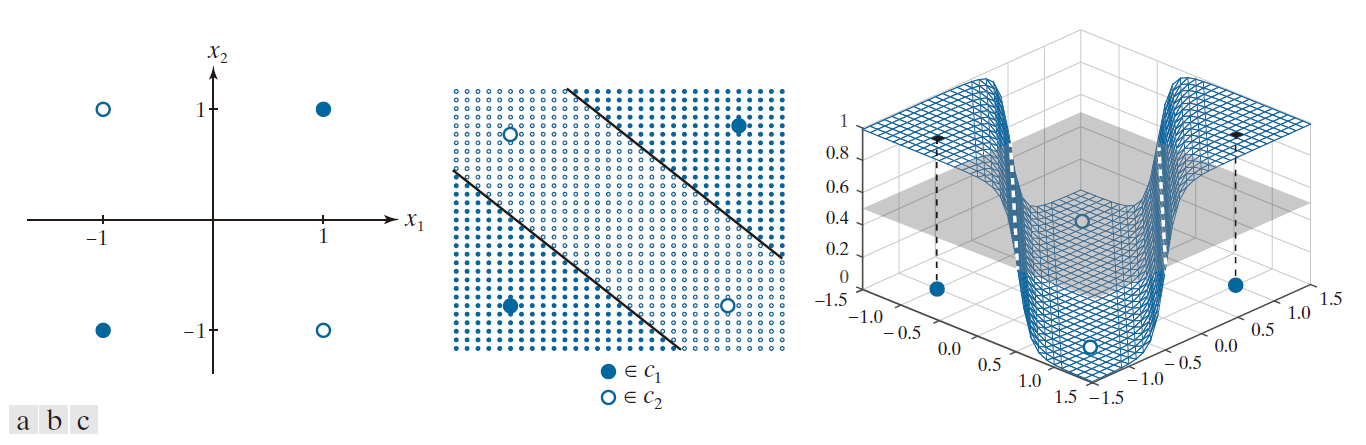
一个常用于展示单一线性决策边界(进而也包括单一感知机单元)局限性的经典示例,便是 XOR (异或)分类问题。图 12.27(a) 中的表格展示了针对两个变量定义的 XOR 运算规则。正如你所见,当两个变量中仅有一个(而非两者同时)取值为“真”(1) 时,XOR运算的结果为逻辑“真”(1) ;否则,结果为“假”(0)。XOR 二分类模式识别问题的设定方式如下:将每一对变量值 A 和 B 视为二维空间中的一个点;将 XOR 运算结果为“真”(1) 的点归为一类,将结果为“假”(0) 的点归为另一类。在本例中,我们将类别标签 分配给模式集 {(0, 0), (1, 1)},并将标签
分配给模式集 {(1, 0), (0, 1)}。一个能够解决 XOR 问题的分类器必须具备这样的响应能力:当输入模式属于类别
时,输出一个特定值( 例如 1 );而当输入模式属于类别
时,则输出另一个不同的值( 例如 0 或 -1 )。通过观察图 12.27(b),你可以直观地看出,单一的线性决策边界(即一条直线)无法正确地将这两个类别区分开来。这意味着我们无法仅凭一个单一的感知机来解决这一问题。如图 12.27(b) 所示,最简单的线性边界实际上是由两条直线构成的。而若采用更为复杂、非线性的边界,则可利用二次函数来实现对该问题的求解,如图 12.27(c) 所示。
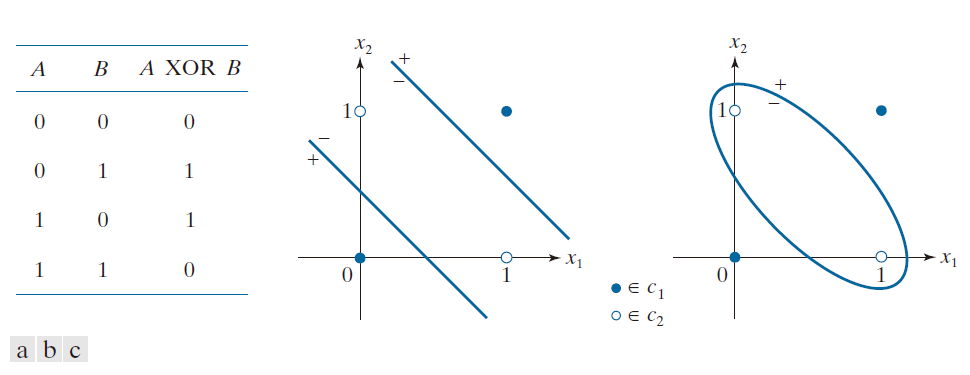
-----------------------图 12.27:二维 XOR 分类问题。(a) XOR 算子的真值表定义。(b) 通过将 XOR 真值 (1) 归属于某一模式类、将假值 (0) 归属于另一模式类所形成的二维模式类。分隔这两个类别的最简单决策边界由两条直线构成。(c) 分隔这两个类别的非线性(二次)边界。-----------------------------------------------------
此时自然会产生这样的疑问:是否可以通过不止一个感知机来解决 XOR 问题?如果是的话,所需的最小单元数量是多少?我们已知单个感知机只能实现一条直线,而我们要解决的问题需要实现两条直线,因此显而易见的答案是:第一个问题的答案是肯定的(能解决),而第二个问题的答案是需要两个单元。图 12.28(a) 展示了针对两个变量的解决方案;由于我们需要实现两条直线,因此总共需要六个系数。这些解系数的设定方式是:对于属于类别 的两个模式中的任意一个,其中一个输出为真(1),另一个输出为假(0)。而对于属于类别
的任意一个模式,则必须满足相反的条件。该解决方案要求我们对两个输出进行分析。如果我们希望完全实现该真值表——即仅通过一个输出就能产生与 XOR 函数完全一致的响应 [如图 12.27(a) 中的第三列所示]——那么我们就还需要额外增加一个感知机。图 12.28(b) 展示了实现这一解决方案的网络架构。在该架构中,第一层的一个感知机负责将属于某一类别的任意输入映射为 1,而另一个感知机则负责将属于另一类别的模式映射为 0。这一过程将四种可能的输入归约为两种输出,从而将原问题转化为一个“两点分类”问题。正如你在图 12.24 中所见,单个感知机便足以解决此类问题。因此,若要完整实现异或真值表(如图 12.28(b) 所示),我们总共需要三个感知机。
稍加推演,我们便可通过目测确定实现图 12.28 中任一解所需的系数。然而,与其在此详加赘述,我们将在下一节中将重点转向一种更为通用的分层架构——而上述的 XOR 解法,不过是该架构中一个微不足道的特例罢了。
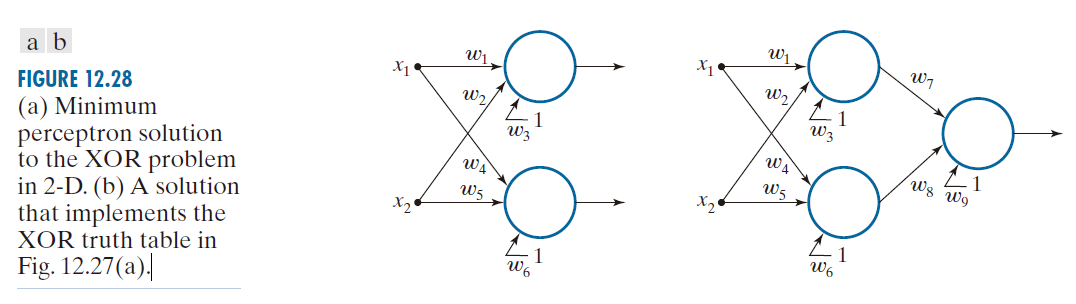
--------------------图 12.28:(a) 二维空间中 XOR 问题的最小感知机解。(b) 一个实现了图 12.27(a) 所示 XOR 真值表的解。-------------------------------------
12.5.3 多层前馈神经网络(Multilayer Feedforward Neural Networks)
在本节中,我们将探讨多层神经网络的架构与运作机制,并推导出用于训练此类网络的反向传播公式。随后,我们将给出若干示例,以展示神经网络的能力。
12.5.3.1 一个神经网络模型(Model of an Artificial Neuron)
神经网络由相互连接的、类似于感知机的计算单元组成,这些单元称为“人工神经元”。这些神经元执行的计算任务与感知机相同,但在处理计算结果的方式上与感知机有所不同。如图 12.23 所示,感知机采用一种“硬”阈值函数来进行分类,该函数仅输出两个离散值(例如 +1 和 -1 )。试想在一个由感知机组成的网络中,若某感知机在进行阈值处理前的输出值仅比零略大(即大了一个无穷小量),那么经过阈值处理后,这一微弱的信号将转化为 +1。然而,若出现一个数值大小相近但符号相反的微弱信号,其输出值便会发生剧烈震荡,从 +1 骤变为 -1。神经网络通常由层层堆叠的计算单元构成,其中前一单元的输出会影响其后所有单元的运作状态。感知机对微弱信号符号的这种高度敏感性,极易在由此类单元构成的互联系统中引发严重的稳定性问题,从而使得感知机不适用于构建分层架构的神经网络。
解决方案在于将激活函数的特性从硬限幅器改为平滑函数。图 12.29 展示了一个基于使用激活函数
(12-51)
的示例。其中 z 是该神经元执行计算所得的结果,如图 12.29 所示。除了采用了更为复杂的记号,以及用平滑函数取代了硬阈值之外,该模型执行的“求和乘积”运算与感知机模型中的式 (12-36) 完全一致。请注意,此处的偏置项记作 b ,而非像在感知机模型中那样记作 。在神经网络领域,习惯上使用不同的记号( 通常为 b )来表示偏置项,因此我们在此沿用了这一惯例。图 12.29 中所采用的较为复杂的记号(我们稍后将对其进行解释)之所以是必要的,是因为接下来我们将要处理的是包含多个层级、且每层包含多个神经元的多层网络结构。我们使用符号 𝓁 来表示层级。
正如通过对比图 12.29 和图 12.23 所见,我们使用变量 z 来表示该神经元所计算的“乘积之和”。该单元的输出(记为 a )是通过将 z 输入至函数 h 中而得到的。我们将 h 称为“激活函数”,并将其输出 a = h(z) 称为该单元的“激活值”。请注意图 12.29 所示,神经元的输入实际上是来自前一层的神经元的激活值。图 12.30(a) 绘制了由公式 (12-51) 所定义的函数 h(z) 的图像。由于该函数呈现出 Sigmoid 函数的形状,因此图 12.29 中的单元有时被称为“人工 Sigmoid 神经元”,或简称为“Sigmoid 神经元”。其导数形式非常简洁,可根据 h(z) 来表示 [参见习题 12.16(a)]:
(12-52)
图 12.30(b) 和 (c) 展示了另外两种常用的 h(z) 形式。双曲正切函数同样呈现出 Sigmoid 函数的形状,但它关于两个坐标轴均呈对称。这一特性有助于改善我们稍后将要讨论的反向传播算法的收敛性。图 12.30(c) 所示的函数被称为“整流函数”( Rectifier Function),采用该函数的单元则称为“整流线性单元”(ReLU)。通常,人们也直接将该函数本身称为“ReLU 激活函数(activation function)”。实验结果表明,在深度神经网络中,该函数的表现往往优于前述两种函数。
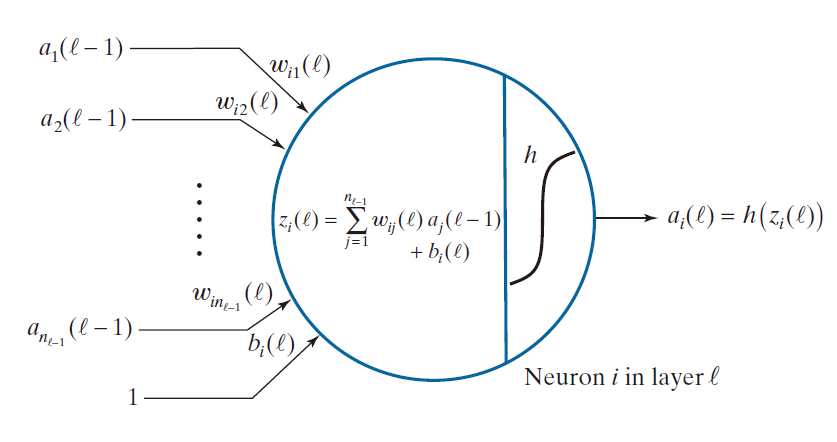
--------------------图 12.29:人工神经元模型,展示了其执行的所有运算。符号“𝓁”用于表示分层网络中的特定层。---------------------------------------
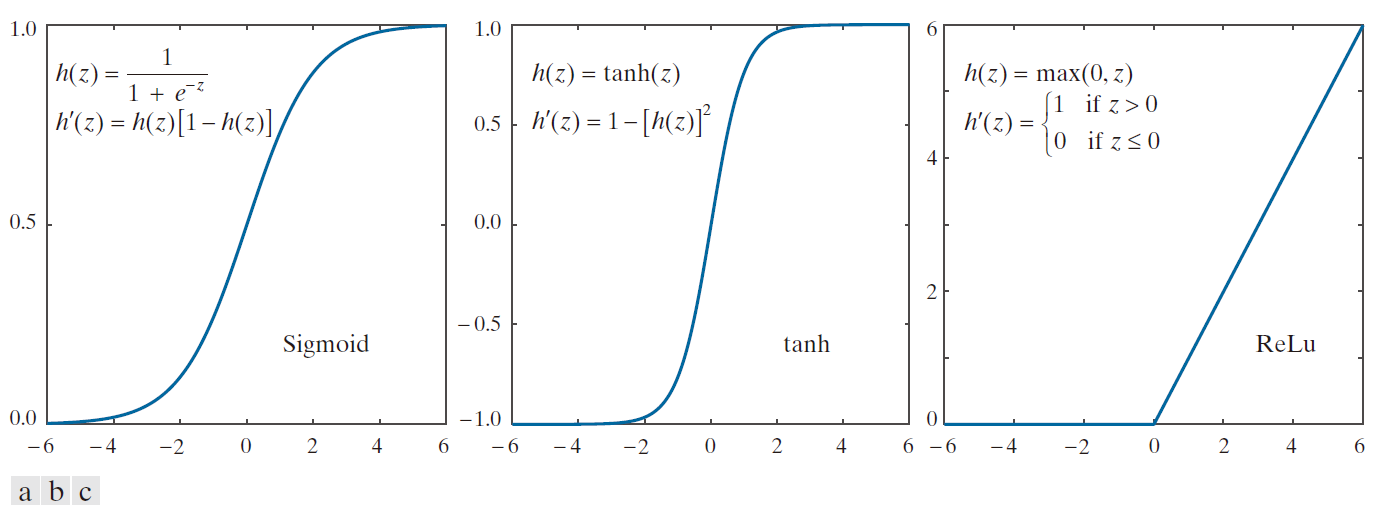
----------------图 12.30:各种激活函数。(a) Sigmoid。(b) 双曲正切(同样呈 Sigmoid 形状,但在两个维度上均以 0 为中心)。(c) 整流线性单元(ReLU)。--------
12.5.3.2 互连神经元以构建全连接神经网络(Interconnecting Neurons to Form a Fully Connected Neural Network)
图 12.31 展示了多层神经网络的通用示意图。网络中的“层”是指位于网络某一列的所有节点(神经元)的集合。如图 12.31 中放大的节点所示,网络中的所有节点均为图 12.29 所示形式的人工神经元;唯一的例外是输入层,其节点即为输入模式向量 x 的各个分量。因此,第一层的输出(即激活值)实际上就是向量 x 中各元素的值。而其余所有节点的输出,则对应于特定层中神经元的激活值。网络中的每一层所包含的节点数量可以各不相同,但每一个节点均仅产生一个输出。图 12.31 中神经元输出端所绘示的多条连线表明:每一个节点的输出均与下一层的所有节点的输入相连接,从而构成了一个全连接网络。此外,我们还要求网络中不得存在环路。此类网络称为前馈网络(feedforward networks)。在本节中,我们所探讨的网络类型仅限于全连接前馈神经网络。
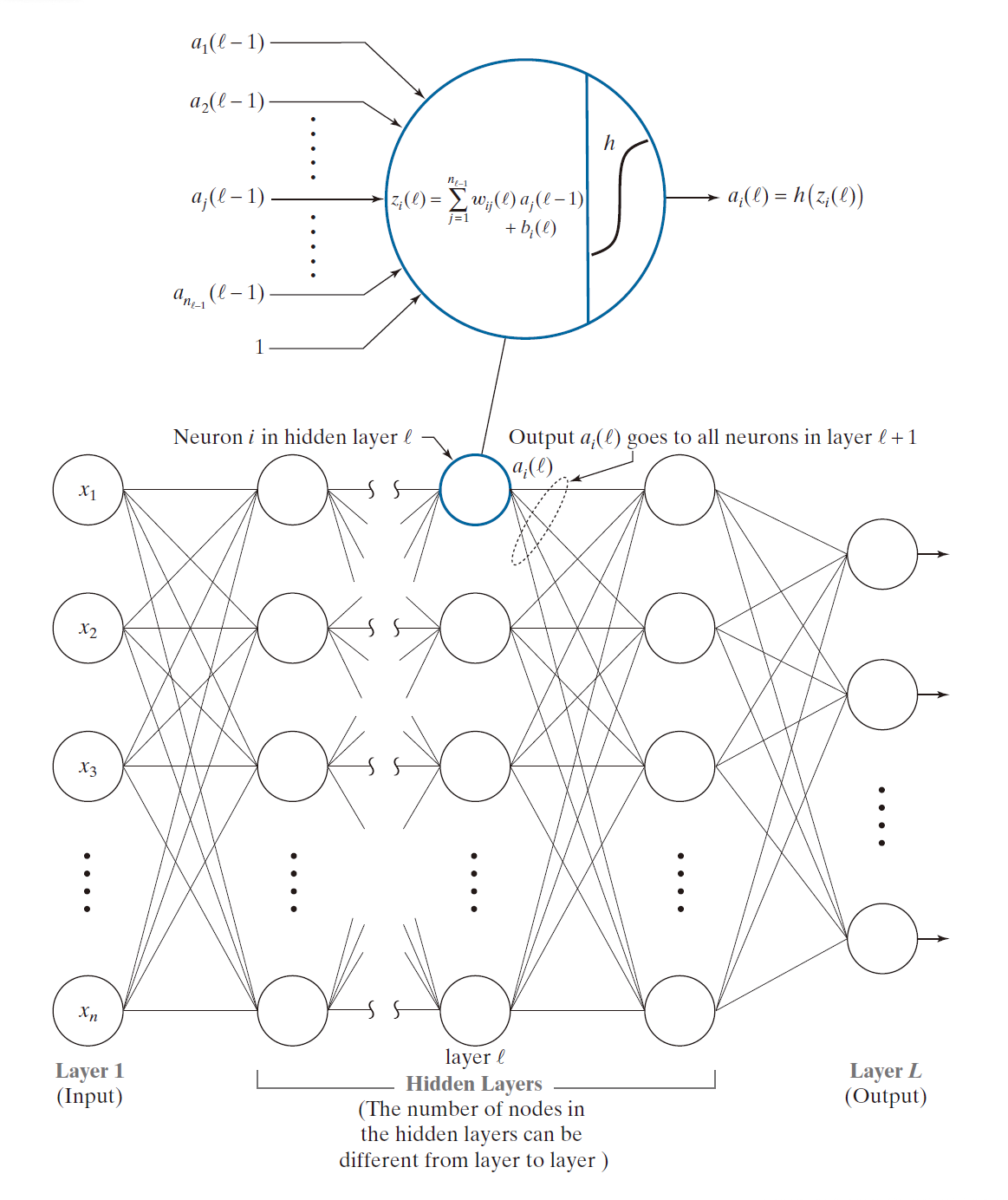
-----------------------图 12.31:前馈全连接神经网络的通用模型。其中的神经元结构与图 12.29 所示相同。请留意,每一个神经元的输出是如何连接至下一层所有神经元的输入端的——正因如此,此类架构才得名为“全连接”。-----------------------
显然,我们已知第一层节点的值,同时也能够观测到输出神经元的值。其余所有神经元均为隐神经元(hidden neurons),而包含它们的层则称为隐层(hidden layers)。通常,我们将仅含有一个隐层的神经网络称为“浅层神经网络(a shallow neural network)”,而将拥有两个或更多隐层的网络称为“深层神经网络(a deep neural network)”。不过,这种术语划分并非放之四海而皆准;有时你会发现,“浅层(shallow)”与“深层”这两个词会被主观地使用,分别用来泛指层数“较少”和层数“较多”的网络。
我们在公式 (12-37) 中采用了特定的记号,以此来标记感知机的所有输入和权重。而在神经网络中,记号体系则更为复杂,因为我们不仅需要顾及同一层内部神经元的权重、输入和输出,还需要兼顾层与层之间的连接关系。若暂且忽略层级标记,我们用 来表示连接神经元 j 的输出端与神经元 i 的输入端之间的那条链路所对应的权重。具体而言,第一个下标 i 指代接收信号的神经元,而第二个下标 j 则指代发送信号的神经元。鉴于字母表中 i 排在 j 之前,若规定由 i 发送信号、由 j 接收信号,似乎在直觉上更为合理。然而,我们之所以采用上述这种记号约定,是为了在描述信号于网络中传播的公式里,避免出现矩阵转置运算。尽管这种记号约定已成惯例,但毫无疑问,它确实容易引发混淆;因此,在实际应用中必须格外留心,以确保对这些记号的理解准确无误。
由于偏置项仅取决于其所在的神经元,因此只需使用一个下标,便足以将该偏置项与特定的神经元关联起来。例如,我们使用 来表示网络中某一特定层内第 i 个神经元所对应的偏置值。此处我们选用符号 b 而非
(正如我们在讨论感知机时所做的那样),是为了遵循神经网络领域通行的符号表示惯例。权重、偏置项以及激活函数共同构成了对一个神经网络的完整定义。尽管神经网络中任意神经元的激活函数在理论上可以各不相同,但目前尚无确凿证据表明,采取这种做法能带来任何实质性的收益。因此,在随后的所有讨论中,我们均假定网络中的所有神经元均采用同一种形式的激活函数。
令 𝓁 表示网络中的层级,即 𝓁 = 1 ,2 ,… , L 。参见图 12.31 , 𝓁 = 1 是输入层,𝓁 = L 是输出层,𝓁 的其它层表示隐层。层 𝓁 中的神经元数量表示为 。我们有两种方案将层索引纳入神经网络的参数中。我们可以将其表示为上标,例如,
和
;或者使用记号
或
。在有关神经网络的文献中,第一种方案更为普遍。我们采用第二种方案,原因在于它与本书描述迭代表达式的方式更为一致,同时也因为你可能会觉得这种表示法更容易理解。采用这种记法,第 ℓ 层的神经元 k 的输出(即激活值)记作
。
请记住,我们使用神经网络的目标与使用感知机时的目标是一致的:即确定未知输入模式的类别归属。利用神经网络进行模式分类最常用的方法,是为每一个输出神经元指定一个类别标签。因此,一个具有 个输出的神经网络可以将一个未知模式归入
个类之一中 。若输入的神经元 k 具有最大的激活值,即,若
,则网络将一个未知模式向量 x 分配给类
。 ( 注:有时,最终输出层不会使用 sigmoid 或类似函数,而是使用 softmax 函数。其概念与我们之前解释的相同,但一个 softmax 函数实现中的激活值计算公式为
,其中求和运算针对所有输出进行。在此表述中,所有激活值的总和为 1,从而赋予了输出以概率学的解释。)
在本节及后续章节中,我们神经网络的输出数量将始终与类别数量相等。但这并非一项强制要求。例如,一个用于对两种模式类别进行分类的网络,其结构完全可以只包含一个输出(问题 12.17 便展示了这样一个案例);这是因为针对此类任务,我们仅需区分两种状态,而单个神经元便足以胜任这一需求。若涉及三个或四个类别,我们则分别需要区分三种或四种状态,而通过两个输出神经元即可实现这一目标。当然,这种做法的弊端在于,我们需要额外设计逻辑来对输出组合进行解码。相比之下,为每个类别分配一个神经元,并由输出值最高的那个神经元来判定输入所属的类别,显然是一种更为实用的做法。
12.5.4 前馈神经网络的前向传播(Forward Pass Through a Feedforward Neural Network)
神经网络中的前向传播过程,将输入层(即 x 的取值)映射至输出层。输出层中的数值用于判定输入向量所属的类别。本节所推导的公式阐释了前馈神经网络究竟是如何执行计算,从而得出其最终输出结果的。本节讨论的一个隐含前提是:网络参数(即权重与偏置)均已处于已知状态。本节的重要结论将在讨论结束时汇总于表 12.2 中;不过,鉴于下一节我们将探讨神经网络的训练问题,透彻理解推导出这些结论所涉及的理论内容,将显得尤为重要。
12.5.4.1 前向传输公式(The Equations of a Forward Pass)
第 1 层的输出是输入向量 x 的分量:
(12-53)
其中, 是 x 的维数。如图 12.29 和 12.31 所示,𝓁 层上的神经元 i 执行的计算公式为
(12-54)
( 和 𝓁 = 2 ,… ,L ) 。量
称为 𝓁 层的神经元 i 的净(或总)输入(net input),有时候用
表示。使用这个术语的原因在于,
是由所有来自层 𝓁 – 1 的输出所构成。𝓁 层上的神经元 i 之计算公式为
(12-55)
其中,h 是一个激活函数。网络输出节点 i 的值是
(12-56)
公式 (12-53) 至 (12-56) 描述了将全连接前馈网络的输入映射至其输出所需的所有运算。
例 12.10:例释全连接神经网络前向传输。
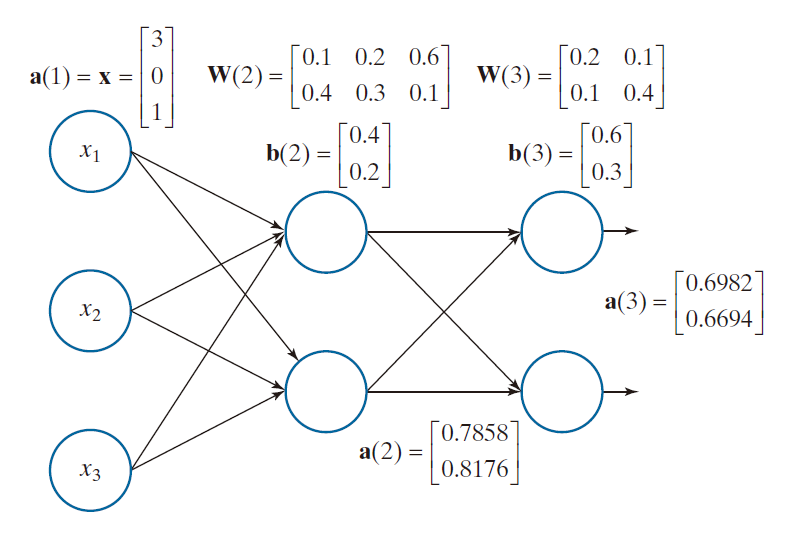
考虑一个简单的数值示例将会有所助益。图 12.32 展示了一个由输入层、一个隐层和输出层组成的三层神经网络。该网络接收三个输入,并产生两个输出。因此,该网络能够将三维模式归类为两个类别之一。

-----------------------图 11.32:一个带有标注权重、偏置和输出的小型全连接前馈网络。其激活函数为 Sigmoid 函数。-----------------------------------------------
显示在指向某个节点的各输入箭头上方的数值,即为该节点与前一层节点输出相对应的权重。同样地,显示在每个节点输出端的数值,即为该节点的激活值 a 。正如前文所述,每一个节点仅产生一个输出值,但该值会传输至下一层中每一个节点的输入端。那些与数值“1”相关联的输入,即为偏置值。
让我们来考察在每一个节点上执行的计算,首先从第 2 层的第一个(顶部)节点开始。我们利用公式 (12-54) 来计算该节点的净输入 :
我们用公式 (12-51) 和 (12-55) 求该节点的输出:
一个类似的计算得出了第二层中第二个节点的输出值,
和
这个神经元的输出是
类似地,
和
若我们使用这个网格来分类输入,则我们会称模式 x 属于类 ,因为,在这种情况下有
,其中,L = 3 ,而
。
12.5.4.2 矩阵公式(Matrix Formulation)
前述示例的细节表明,在神经网络的一次正向传播过程中,涉及大量的独立计算。如果你编写计算机程序来自动执行我们刚刚讨论的步骤,就会发现代码效率极低,原因在于其中包含了大量必要的循环计算、繁琐的节点与层级索引操作,诸如此类。通过运用矩阵运算,我们可以实现一种更为优雅(且计算速度更快)的实现方案。具体而言,这意味着将公式 (12-53) 至 (12-55) 改写如下。
首先请注意,第1层的输出数量总是与输入模式 x 具有相同的维数,因此其矩阵(向量)形式十分简洁:
(12-57) a(1) = x
接下来,我们考察式 (12-54)。我们知道,其中的求和项实际上就是两个向量的内积 [参见公式 (12-37) 和 (12-38)]。然而,对于除第一层以外的每一层,我们都必须对该公式中的所有节点进行求值计算。这意味着,如果采用逐节点计算的方式,就必须引入循环结构。其解决方案是构建一个矩阵 W(𝓁) ,用于包含第 𝓁 层的所有权重。该矩阵的结构十分简单——其每一行对应于第 𝓁 层中某一个节点的权重:
(12-58)
则我们可以同时获得 𝓁 层中所有乘积和之计算 :
(12-59)
其中,a(𝓁 –1 ) 是包含 𝓁 –1 层的输出的 列向量 ,b(𝓁 ) 是包含 𝓁 层中所有神经元的偏置值的
列向量,而 z(𝓁) 是包含 𝓁 层中所有节点净输入值
( i = 1 , 2 , … ,
) 的
列向量。你不难验证,公式 (12-59) 在维数上是正确的。
由于激活函数是独立地应用于每一个网络输入的,因此网络在任意层的输出均可表示为如下向量形式:
(12-60)
实现公式 (12-57) 到公式 (12-60) 仅要求一系列矩阵运算,而没有循环。
例 12.11:利用矩阵运算重做例 12.10 。
图 12.33 展示了与图 12.32 相同的神经网络,但其所有参数均以矩阵形式呈现。正如你所见,图 12.33 中的表示形式更为紧凑。首先,
可推导出
则,
用 a(2) 作为下一层的输入,我们求得
且,同前,
矩阵形式相较于例 12.10 中所用的索引记法,其清晰性显而易见。
----------------------图 12.33:同图 12.32,但采用矩阵标记。-------------------
公式 (12-57) 至 (12-60) 相较于逐节点计算而言是一项显著的改进,但它们仅适用于单一模式。若要对多个模式向量进行分类,我们不得不通过循环逐一处理每一个模式,且在每一次循环迭代中均需应用同一组矩阵公式。我们真正追求的,是一组能够通过单次前向传播便处理所有模式的矩阵公式。将公式 (12-57) 至 (12-60) 扩展至这种更为通用的形式,是一件相当直截了当的事情。首先,我们将我们的所有输入模式向量重排为一个 单矩阵 X ,其中,同前,n 是向量的维数,
是模式向量的数量,从公式 (12-57) 可以推导出
(12-61) A(1) = X
其中矩阵 A(1) 的每一列包含一个模式的初始激活值(即向量值)。这是公式 (12-57) 的直接扩展。只不过我们现在处理的是 矩阵,而不是 n × 1 矩阵。
一个网络的参数不会变化, 因为我们正在处理的是多个模式向量,因此权值矩阵同公式 (12-58) 。这个公式的在在小是 。当 𝓁 = 2 时,W(2) 的大小是
,因为
总是等于 n 。 然后扩展公式 (12-59) 的乘积项,用 A(2) 代替 a(2),就得到矩阵乘积 W(2)A(2) ,其大小为
。为此,我们必须加上第二层的偏置向量( 其大小为
)。然而,同权重矩阵一样,偏置向量不会变化,因为我们正在处理多模式向量。我们只需为每个输入向量考虑一个相同的偏置向量 b(2)。为此,我们通过水平拼接向量 b(2)
次来创建一个大小为
的矩阵 B(2)。则用矩阵形式表示的公式 (12-59) 就成为 Z(2) = W(2)A(1) + B(2) 。矩阵 Z(2) 之大小为
;它包含了由公式 (12-59) 所执行的计算,但涵盖了所有的输入模式。即,Z(2) 的每一列恰好对应于公式 (12-59) 针对某一个输入模式所执行的计算。
刚才讨论的概念适用于神经网络中任意层到下一层的过渡,前提是我们使用适用于网络中特定位置的权重和偏置。因此,公式 (12-59) 的完整矩阵形式为
(12-62) Z(𝓁) = W(𝓁)A(𝓁 - 1) + B(𝓁 )
其中,W(𝓁) 由公式 (12-58) 计算所得,而 B(𝓁 ) 是一个 矩阵,其列是 b(𝓁 ) ( 包含 𝓁 层中神经元的偏置项的偏置向量)的重复。
剩下的就是层 𝓁 的输出矩阵公式。如公式 (12-60) 所示,激活函数独立地应用于向量 z(𝓁) 的每一个元素。由于 Z(𝓁) 的每一列都只是将公式 (12-60) 应用于特定的输入向量,因此可推导出
(12-63)
其中,激活函数应用于 Z(𝓁) 的每一个元素。
概括一下我们的矩阵公式中的维数,我们有: X 和 A(1) 的维数是 ,Z(𝓁) 的维数是
,W(𝓁) 的大小是
,A(𝓁 - 1 ) 之大小是
,B(𝓁) 的大小是
, A(𝓁) 的大小是
。表 12.2 总结了针对所有模式向量,在全连接前馈神经网络中执行前向传播时的矩阵化表述。若使用 MATLAB 这种面向矩阵的语言来实现这些运算,将是一项轻而易举的任务。此外,通过利用专用硬件(例如一个或多个图形处理单元,即 GPU ),其运行性能可得到显著提升。
表 12.2 中的公式用于将一组模式中的每一个归类至 个模式类别之一。输出矩阵 W(L) 的每一列均包含针对特定模式向量的
个输出神经元的激活值。该模式所属的类别由具有最高激活值的输出神经元的位置所决定。当然,这一判定过程的前提是我们已知网络的权重与偏置。正如我们接下来将要阐述的那样,这些权重与偏置是在训练阶段利用反向传播算法获得的。
表 12.2:全连接前馈多层神经网络前向传播过程中的矩阵计算步骤。

12.5.5 利用反向传播训练深度神经网络(Using Backpropagation to Train Deep Neural Networks)
神经网络完全由其权重、偏置和激活函数所定义。训练神经网络,即是指利用一组或多组训练样本来估算这些参数。在训练过程中,对于多层神经网络中的每一个输出神经元,我们均已知其期望的响应值;然而,对于隐层神经元的输出值究竟应当为何,我们却无从知晓。在本节中,我们将推导反向传播算法的相关公式——这正是用于确定多层神经网络中权重与偏置值的首选工具。基于反向传播的训练过程主要包含四个基本步骤:(1) 输入模式向量;(2) 进行网络正向传播,对训练集中的所有模式进行分类并确定分类误差;(3) 进行反向(即反向传播)传递,将输出误差沿网络反向回馈,以计算更新参数所需的调整量;(4) 更新网络中的权重与偏置。上述步骤将反复执行,直至误差降至可接受的水平为止。在本节讨论结束之际,我们将对本节推导出的所有主要结论进行归纳总结(参见表 12.3)。正如你稍后即将看到的,推导反向传播公式所需的主要数学工具,正是源自基础微积分学的“链式法则”。
12.5.5.1 反向传播公式(The Equations of Backpropagation)
已知一组训练样本及一种多层前馈神经网络架构,本文后续讨论所采用的方法旨在寻得一组网络参数,以使某个误差函数(error function) (亦称为代价(cost)函数或目标(objective)函数)达到最小值。鉴于我们关注的核心在于分类性能,我们将神经网络的误差函数定义为期望响应与实际响应之间差异的平均值。令 r 表示给定模式向量 x 所对应的期望响应,令 a(L) 表示该网络针对此输入所产生的实际响应。例如,在涉及十个类别的识别应用中,r 和 a(L) 均为十维列向量。其中,a(L) 的十个分量即为神经网络的十个输出值;而 r 的分量除对应于模式向量 x 所属类别的那一分量取值为 1 之外,其余分量均为 0。例如,若输入的训练样本属于第 6 类,则向量 r 的第 6 个分量取值为 1,其余分量则均为 0。
输出层中神经元 j 的激活值是 。我们定那个神经元的误差为
(12-64)
其中, 是输出神经元
对已知模型 x 的响应。针对单个 x 的输出误差,为所有输出神经元针对该向量的误差之和:
(12-65)
其中第二行是根据 Euclid 向量范数的定义得出的。针对所有训练样本,网络的总输出误差被定义为各个样本误差之和。我们的目标是求得能够使这一总误差最小化的权重。正如我们在处理 LMSE 感知机时所做的那样,我们将利用梯度下降法来求解。然而,与感知机不同的是,我们无法直接计算隐层节点权重的梯度。反向传播算法的精妙之处在于,通过将输出误差反向传回网络内部,我们能够获得等效的计算结果。
关键目标是求利益一种利用训练模式调整网络中所有权重的方案。为此,我们需要知道 E 如何随网络中的权重变化。权重包含在每一个节点的净输入表达式中[参见公式 (12-54)]。因此,我们寻找的量是 ,其中,同公式 (12-54) 中的定义,
是层 𝓁 中节点 j 的净输入。为了在随后应用中简化此记法,我们用
表示
。因为反向传播始于输出端,从输出端开始计算,因此我们首先求得
(12-66)
我们可以利用链式法则,根据输出 来表示该公式:
(12-67)
其中我们使用公式 (12-56) 得到了第一行中的最后一个表达式。该公式给出了 的值,该值可以用可观测或可计算的量来表示。例如,如果我们使用公式 (12-64) 作为误差度量,并使用公式 (12-52) 来表示
,则
(12-68)
其中,我们交换了换的次序。 按前向传输计算,在网络的输出端可以观察到
,而
随 x 在训练过程中一并给出。因此,我们对
进行计算 。
由于任何层(除第一层外)中任意神经元的净输入与输出之间的关系均相同,因此公式 (12-66) 的形式适用于任何隐层中的任意节点 j :
(12-69)
该公式揭示了 E 随网络中任意神经元净输入变化而变化的规律。接上来我们想做的事情是根据 来表达
。因为我们将在网络中反向进行,这意味着,若我们有这种关系,则我们可以从
开始而求得
。进而我们可以用这个结果来求得
,如此等等,直到我们到达第 2 层。我们利用链式法则来求得预期的表达式( 见问题 12.25 ):
(12-70)
( 对于 𝓁 = L – 1 ,L – 2 ,…,2 ),其中,我们利用公式 (12-55) 和 (12-69) 得到了中间一行,并利用公式 (12-54) 辅以适当整理,得到了最后一行。
上述推导向我们展示了如何从输出端的误差(这是我们可以计算得出的)出发,进而求得该误差随网络中各节点净输入变化的关系。这是通向我们最后目标的中间步骤,这是为了根据 求得
和
的表达式。为此,我们再次使用链式法则:
(12-71)
其中我们使用了公式(12-54)和公式(12-69),并交换了结果的顺序,以便在后续讨论中更清晰地阐述矩阵公式。类似地(见问题12.26),
(12-72)
至此,我们已得到了 E 相对于网络权重和偏置的变化率,并将其表示为可计算的量。最后一步是利用这些结果,通过梯度下降法来更新网络参数:
(12-73)
和
(12-74)
( 对于 𝓁 = L - 1 ,L - 2 ,… ,2 ) 其中,a 值是在前向传播过程中计算得出的,而 δ 值则是在反向传播过程中计算的。正如感知机模型一样,α 代表了梯度下降算法中所使用的常数学习率。尽管目前存在许多旨在求解最优学习率的方法,但归根结底,这是一个高度依赖具体问题情境的参数,往往需要通过实验探索来确定。一种较为合理的策略是:首先设定一个较小的 α(例如 0.01 ),随后利用训练集中的样本数据进行实验,从而针对特定的应用场景确定一个合适的取值。谨记,α 仅在训练阶段发挥作用,因此它对模型在训练完成后的实际运行性能没有任何影响。
12.5.5.2 矩阵公式(Matrix Formulation)
正如描述神经网络前向传播过程的公式一样,我们在前文讨论中推导出的反向传播公式,虽然在从根本层面阐释该方法的运作原理方面表现出色,但在涉及具体实现时却显得颇为繁琐。在本节中,我们将沿用类似于前向传播推导过程的步骤,来构建反向传播的矩阵公式。
同前,我们将所有的模式向量排列为矩阵 X 的列,并将第 𝓁 层的权重打包为矩阵 W(𝓁)。我们使用 D(𝓁) 来表示 δ(𝓁) (包含第 𝓁 层误差的向量) 的矩阵形式。我们的第一步是推导出 D(L) 的表达式。我们将像以往一样,从输出层开始,反向进行推导。根据公式 (12-67),
(12-75)
(译注:符号 “ ⨀ ” 的 Unicode 编码是:02A00 ,LaTex 语法是:\bigodot , N-ARY 圆点运算符)
其中,同 2.6 节中之定义,符号 “⨀” 表示(在这种情况下的两个向量之)逐元素相乘。我们可以将该符号左侧的部分写成 ∂E/∂a(L) ,而将其右侧的部分写成 。从而我们可以将公式 (12-75) 写成
(12-76)
这个 列向量包含单个模式向量的所有输出神经元的激活值。在本章中我们所使用的唯一误差函数都是二次函数,在公式 (12-65) 中其以向量的形式呈现。这个二次函数关于 a(L) 的偏微分是 ( a(L) - r ) ,将其代入公式 (12-76),得到
(12-77)
列向量 δ(L) 对应单个模式向量。为了同时对应所有 个模式,我们构成一个矩阵 D(𝓁) ,其列是来自公式 (12-77) 的 δ(L) ,针对一个具体的模式向量计算。这等价于将公式 (12-77) 直接按矩阵写成
(12-78)
A(L) 的每一列是单模式的网络输出。类似地,R 的每一列都是一个二值向量,与一个特定的模式向量类对应的位置为 1 ,在其它位置为 0 ,如先前所解释。差值 ( A(L) - R ) 的每一列包含 的分量。因此,对某一列的元素进行平方、求和并除以 2 ,等同于计算针对单个模式在公式(12-65)中所定义的误差度量。将所有列的计算结果相加,即可得出针对所有模式的平均误差度量。类似地,矩阵
的列是所有输出神经元的净输入值,其每一列对应单个模式向量。公式 (12-78) 中的所有矩阵的大小均是
。
按类似的推理思路,我们可以按矩阵形式将公式 (12-78) 表示成
(12-79)
通过维数分析,不难确认矩阵 D(𝓁) 的维数为
( 见问题 12.27 )。请注意,公式 (12-79) 中使用的是权重矩阵的转置。这反映了这样一个事实:第 𝓁 层的输入实际上源自第 𝓁 + 1 层,因为在反向传播过程中,我们是沿着与前向传播相反的方向进行运算的。
我们将权重和偏置的更新公式表示为矩阵形式,从而完成了矩阵化表述。首先考察权重矩阵,从公式 (12-70) 和 (12-73) 可以看出,我们将需要矩阵 W( 𝓁 ),D( 𝓁 ) 和 A( 𝓁 - 1)。我们已经知道,W( 𝓁 ) 的大小为 ,而 D(𝓁) 的大小为
。矩阵 A( 𝓁 - 1) 的每一列都是第 𝓁 - 1 层上的神经元针对单个模式向量的输出集合。共有
个模式,因此 A( 𝓁 - 1) 的大小为
。根据公式 (12-73) ,我们推断 A 后乘 D ,因此我们将需要
,其大小为
。最后,回顾一下用矩阵表示的公式,我们构建一个大小为
的矩阵 B( 𝓁 ) ,其列是向量 b( 𝓁 ) 之副本,其包括所有 𝓁 层中的偏置系数。
接下来,我们来看如何更新偏置。从公式 (12-74) 我们可知,b( 𝓁 ) 的每一个元素 以
的形式更新 。 因此,b( 𝓁 ) = b( 𝓁 ) - αδ(𝓁) 。当这是针对单模式,而 D(𝓁) 的列是训练集中对所有模式的 δ(𝓁) 。这是用一个矩阵公式处理的,即用 D(𝓁) 的列之均值(这是所有模式上的均值误差)来更新 b( 𝓁 ) 。
综合上述各项,便得到了用于更新网络参数的以下两个公式:
(12-80)
和
(12-81)
其中, 是矩阵 D(𝓁) 的第 k 列。同前,我们通过将 b( 𝓁 ) 在水平方连接
次来构成一个大小为
的矩阵 B( 𝓁 ):
(12-82)
正如我们此前所述,反向传播主要包含四个步骤:(1) 输入模式,(2) 前向传播,(3) 反向传播,以及 (4) 参数更新。该过程始于将初始权重和偏置设定为(较小的)随机数。表 12.3 归纳了这四个步骤的矩阵形式。在训练过程中,这些步骤会重复执行预定的迭代次数(epochs),或者直至预先定义的误差指标被判定为足够小为止。
表 12.3 :基于反向传播算法训练前馈全连接多层神经网络的矩阵化表述。步骤 1 至 4 对应于一个训练周期(epoch)。输入数据 X、目标输出 R 以及学习率参数 α 提供给网络用于训练。网络的初始化通过将权重 W(1) 和偏置 B(1) 设定为较小的随机数来完成。

我们关注的误差主要有两种类型。第一种是分类误差,其计算方法是:统计被错误分类的模式数量,并将其除以训练集中的模式总数。将所得结果乘以 100,即可得到被错误分类模式的百分比;若用 1 减去该结果再乘以 100,则可得到正确识别率。第二种是均方误差(MSE),它是基于误差向量 E 的实际数值来定义的。对于公式 (12-65) 中所定义的误差,其数值(针对单个模式而言)的计算方法是:将矩阵 ( A(L) – R ) 中某一列的元素逐一平方、求和,最后将总和除以 2 (见习题 12.28)。对所有列重复上述操作,并将所得结果除以数据集 X 中的模式总数,即可得到整个训练集上的均方误差(MSE)。
例 12.12:利用全连接神经网络解决异或(XOR)问题。
图 12.34(a) 展示了前文讨论过的 XOR 分类问题(为便于索引,此处选取的坐标将模式置于中心位置,但其空间关系保持不变)。模式矩阵 X 和类别归属矩阵 R 如下所示:
;
;
我们指定了一个包含三层、每层各有两个节点的神经网络(参见图 12.35)。这是与图 12.31 所示架构相一致的最小网络。将其与图 12.28(a) 中的最小感知机配置进行对比,我们发现该神经网络执行着相同的基础功能——具体而言,即它具有两个输入和两个输出。
---------------图 12.34:XOR 问题的神经网络解。(a) 呈 XOR 排列的四个模式。(b) 对位于 -1.5 至 1.5 范围内(步长为 0.1)的额外点进行分类所得的结果。所有实心点均归类为属于类别 ,所有空心圆均归类为属于类别
。这两条区域分隔线共同构成了决策边界 [参见图 12.27(b)]。(c) 决策曲面(以网格形式显示)。决策边界即为曲面与某一平面相交处的那对白色虚线;该平面垂直于纵轴,且与纵轴相交于 0.5 处。(图 (c) 采用了与图 (b) 不同的视角,旨在使所有四个模式均清晰可见。)---------------
我们设定 α =1.0,采用均值为零、标准差为 0.02 的一组初始 Gauss 随机权重,并使用了公式 (12-51) 中的激活函数。随后,我们对网络进行了 10,000 个周期的训练(我们之所以采用如此大的周期数,是为了使结果值尽可能接近参考值 R ;关于采用较少周期数的解法,我们将在下文进行讨论)。最终得到的权重和偏置如下:
;
;
;
图 12.35 展示了基于这些数值的神经网络。
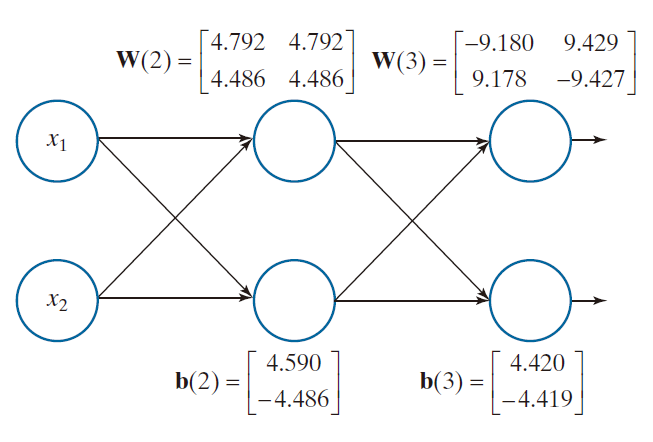
-------------------------图 12.35:用于解决 XOR 问题的神经网络,展示了通过利用表 12.3 中的公式进行训练所学得的权重与偏置。--------------------------------
在训练完成后,当输入那四种训练模式时,两个输出端的数值本应与 R 中的数值相等。然而实际上,所得数值仅是接近:
这些权重和偏置,结合 Sigmoid 激活函数,完整地定义了我们训练好的神经网络。为了测试该网络在训练样本之外的数据上的表现——我们已知它能正确分类这些训练样本——我们构建了一组二维测试样本。具体做法是将模式空间在两个维度上均以 0.1 为步长进行细分( 范围从 -1.5 到 1.5 ),随后通过网络的前向传播过程对由此产生的离散点进行分类。若输出节点 1 的激活值大于输出节点 2 的激活值,则该模式归类为 类;反之,则被归类为
类。图 12.34(b) 展示了这一分类结果的绘图。图中的实心点代表被归类为
类的点,空心点(白点)则代表被归类为
类的点。这两个区域之间的边界(图中以黑色实线标示)与图 12.27(b) 中的边界完全吻合。由此可见,我们构建的这一小型神经网络成功找到了区分这两个类别的最简边界,从而实现了与图 12.28(a) 所示的感知机结构完全相同的功能。
图 12.34(c) 展示了决策曲面。该图与图 12.24(b) 类似,但由于样本模式并非线性可分,该曲面与平面相交了两次。我们的决策边界即为决策曲面与某一平面的交线;该平面垂直于纵轴,且与纵轴相交于 0.5 处。之所以如此设定,是因为输出节点的取值范围介于 [0, 1] 之间,而我们将样本模式归属于两个输出值中取值较大的那一类所对应的类别。图中以阴影区域标示了该平面,决策边界则以白色虚线表示。我们调整了图 12.34(c) 的观察视角,以便您能清晰地看到所有的 XOR 样本点。
由于本例中的分类是基于选取最大输出值进行的,因此我们无需像上文所示那样,要求输出值必须非常接近 1 和 0;只要对于属于类别 的模式,其输出值较大,而对于属于类别
的模式,其输出值较小(反之亦然),便已足够。这意味着我们可以通过较少的训练迭代次数(epochs)来训练网络,却依然能够实现正确的识别。例如,仅利用经过 150 次迭代所学得的参数,便足以实现对 XOR 模式的正确分类。图 12.36 阐释了这一现象之所以可能的原因。截至第 1000 次迭代结束时,均方误差已趋近于零;因此可以预见,在随后的 10,000 次迭代过程中,误差值将仅发生微乎其微的进一步下降。根据前文所得的结果我们已知,若采用经过 10,000 次迭代所学得的权重,该神经网络能够实现完美无瑕的性能表现。鉴于经过 1,000 次迭代与 10,000 次迭代后所得的误差值已十分接近,我们有理由推断,在这两种情况下所学得的权重值亦应十分相近。而在仅经过 150 次迭代时,误差值便已从其最大值处下降了近 90%;因此,此时所学得的权重能够实现良好性能的概率理应相当高——而事实也确实证明了这一点。
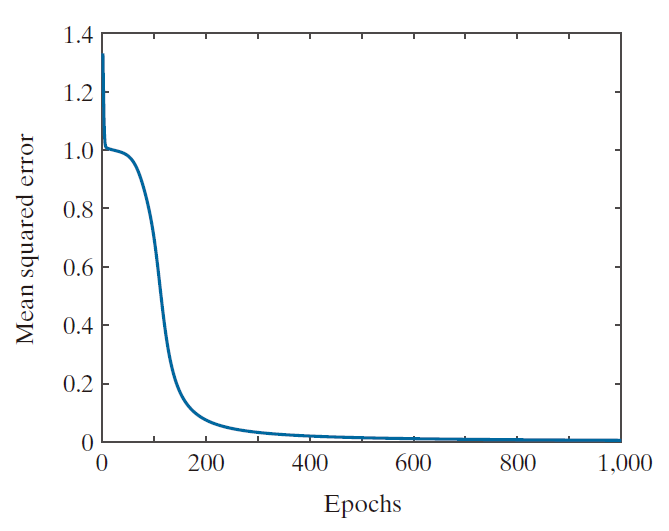
--------------图 13.36:XOR 模式排列下,MSE 随训练轮数的变化曲线。----------
例 12.13:利用神经网络对多光谱图像数据进行分类。
在本例中,我们对比了第 12.4 节讨论的 Bayes 分类器与本节讨论的多层神经网络的识别性能。本例的目标与例 12.6 相同:将多光谱图像数据中的像素归类为水体、城区和植被这三种模式类别。图 12.37 展示了实验中所用的四幅多光谱图像、用于提取训练样本和测试样本的掩模,以及用于生成四维模式向量的方法。

----------------------图 12.37:(a) 从最左侧图像开始依次为:蓝色、绿色、红色、近红外图像以及二值掩模图像。在掩模图中,下方区域代表水体,中央区域代表城区,左侧掩模区域则对应植被。所有图像的尺寸均为 512 × 512 像素。(b) 用于从这四幅多光谱图像栈中生成四维模式向量的方法。(多光谱图像由 NASA 提供。)---------------
正如示例 12.6 所示,我们共提取了 1900 个训练模式向量和 1887 个测试模式向量(按类别列出的向量详情见表 12.1)。在利用训练数据进行初步运行,并确认均方误差确实随训练轮次(epoch)的增加而呈下降趋势后,我们确定:当学习率 α = 0.001 且训练轮次为 1000 时,一个包含单隐层(含两个节点)的神经网络能够实现稳定的学习。在保持这两个参数不变的前提下,我们调整了中间层(隐层)的节点数量,具体设置如表 12.4 所示。这些初步运行的目的是为了确定能够实现最佳识别率的最小规模神经网络架构。从表中的结果可以看出,在本例中,[4 3 3] 显然是最佳的架构选择。图 12.38 展示了该神经网络的结构,并附带了其在训练过程中所学得的各项参数。
表 12.4:在 α = 0.001 且训练周期为 1000 次时,识别率随神经网络架构的变化曲线。网络架构由括号内的数字定义。每个括号内的首尾数字分别代表输入节点数和输出节点数;中间的数字则表示各隐层中的节点数量。

在确定了基本架构之后,我们将学习率固定为 α = 0.001,并通过调整迭代次数(epochs) 来确定图 12.38 所示架构下的最佳识别率。表 12.5 展示了所得结果。正如所见,识别率随迭代次数的增加而缓慢提升,并在迭代次数达到 50,000 次左右时趋于平稳。事实上,如图 12.39 所示,均方误差 (MSE) 在训练迭代次数达到约 800 次之前迅速下降,此后则下降缓慢;这解释了为何在迭代次数超过约 2,000 次之后,正确识别率的变化幅度变得如此微小。当学习率设定为 a = 0.01 时,也得到了类似的结果;但若将该参数下调至 a = 0.1,最佳正确识别率便会随之下降至 49.1%。基于上述结果,我们最终选定 α = 0.001 且迭代次数为 50,000 次的参数配置来对网络进行训练。
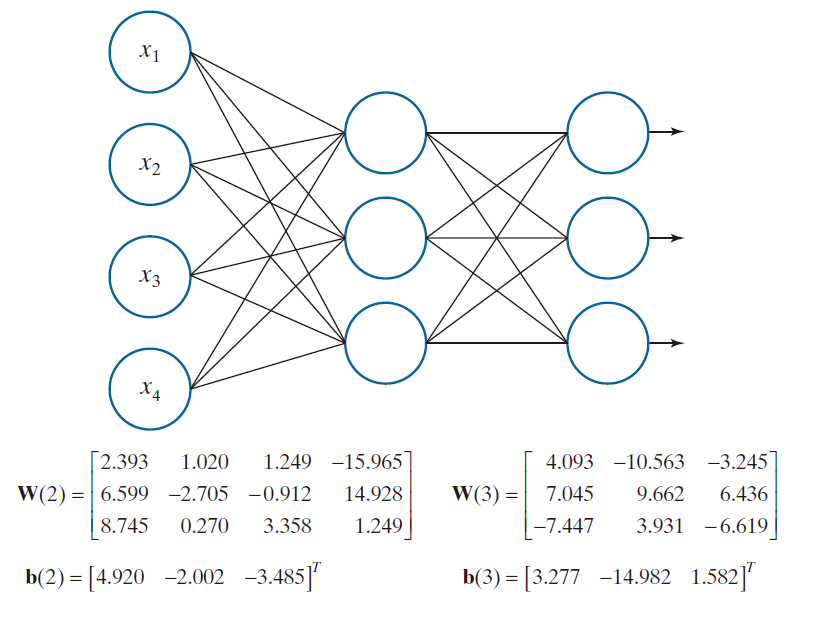
------------------图 12.38:用于将图 12.37 中的多光谱图像数据归类为水体、城区和植被这三个类别的神经网络架构。图中所示的参数,是在设置 α = 0.001 的条件下,经过 50,000 个训练周期后获得的。-------------------------------------------------
表 12.5:训练集上的识别性能随训练轮次的变化曲线。在所有情况下,学习率常数均为 α = 0.001。

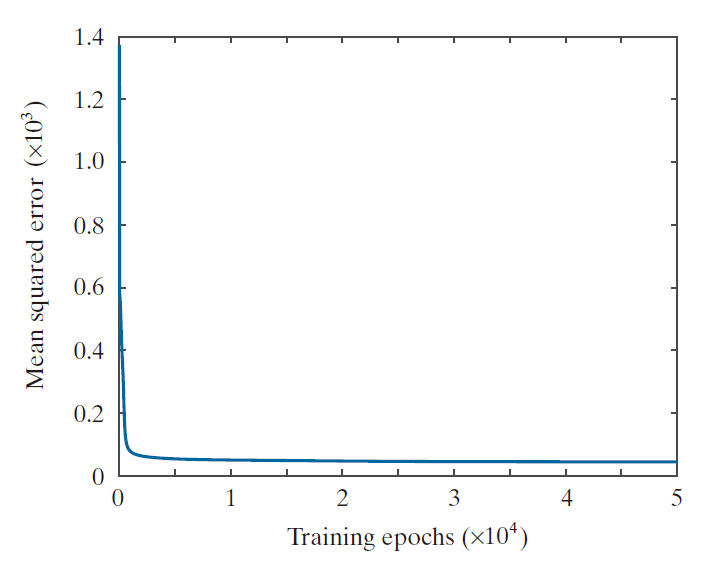
----------------------图 12.39:图 12.38 所示网络架构的 MSE 随训练轮数的变化曲线。在所有情况下,学习率参数均设为 α = 0.001。-----------------------------
图 12.38 中的参数是训练所得的结果。利用这些参数对训练数据进行识别时,识别率达到了 97% 。而在测试集上使用相同的参数进行识别,我们获得了 95.6% 的识别率。上述两项数值,以及利用贝叶斯分类器对同一数据所得出的 96.4% 和 96.2% ( 见例 12.6 ),在统计学上均无显著差异。
我们的神经网络所取得的结果能够与 Bayes 分类器所得结果相媲美,这一事实并不令人意外。正如 Duda、Hart 和 Stork [2001] 所指出的,当训练样本数量趋于无穷大时,采用误差平方和准则并通过反向传播算法进行训练的三层神经网络,在极限情况下能够逼近 Bayes 决策函数。尽管我们的训练集规模较小,但数据本身的特性良好,足以产生出与理论预测结果相近的成果。

















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










