



如何使用Python和一些地理信息处理库来加载、分析和可视化这些数据。
如何对北京市POI数据集进行有效的分析和可视化 如何使用Python和一些地理信息处理库来加载、分析和可视化这些数据。北京市poi数据2025年高德兴趣点
文章目录
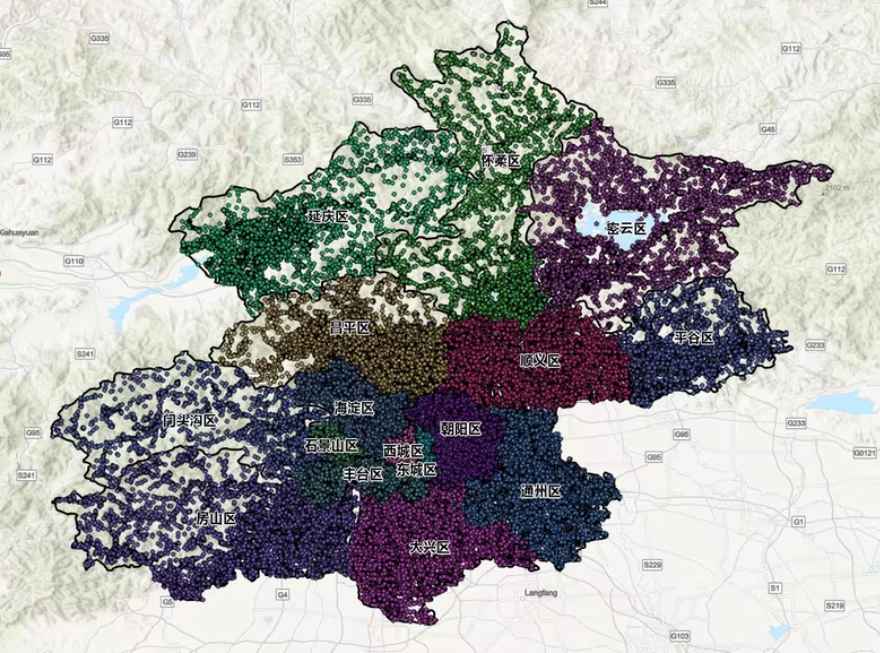
北京市poi数据最新2025年高德兴趣点
数据信息详情:
1.数据范围:北京市及各下辖区
2.数据来源和采集时间:高德(2025年1月)
3.数据格式:shp、csv
4.坐标系:原为gcj02,已转换为wgs84
5.数据量:共126w+(各市数据量见图2)
6.数据分类:包含汽车服务、餐饮、购物、生活服务、商务住宅、体育休闲、医疗保健、住宿服务、科教文化、风景名胜等20余个大类及数百个中小类
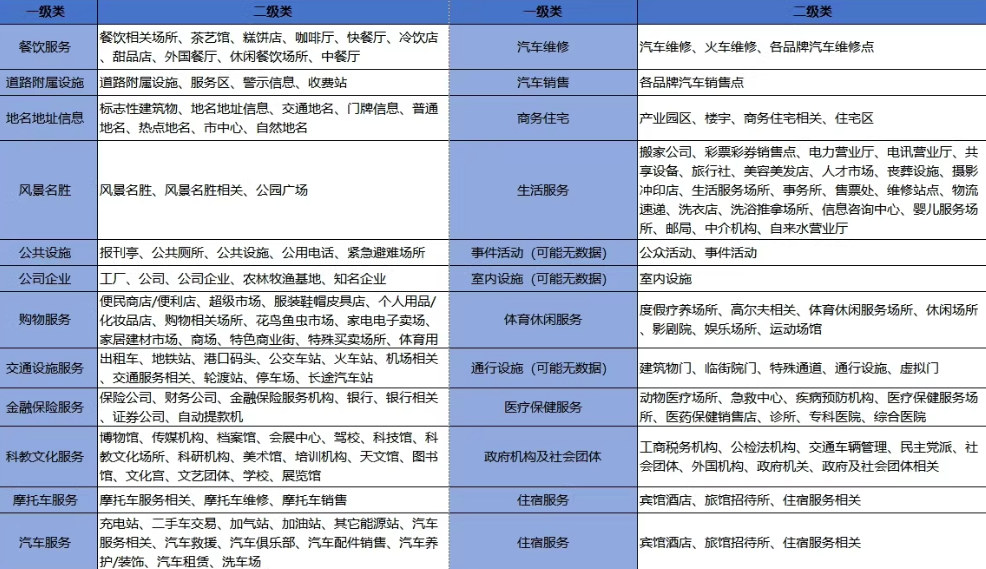
,可导入Arcgis、QGIS等软件直接使用。
朝阳区poi、海淀区poi、丰台区poi、昌平区poi、大兴区poi、通州区poi、顺义区poi、西城区poi、房山区poi、东城区poi、密云区poi、怀柔区poi、平谷区poi、延庆区poi、石景山区poi、门头沟区poi
哇,这个北京市POI数据集听起来非常丰富和详细!我们可以用它来做很多有趣的事情,比如分析不同区域的商业分布、规划旅游路线、研究城市功能区等。下面我将详细介绍如何使用Python和一些地理信息处理库来加载、分析和可视化这些数据。
第一步:导入必要的库
首先,我们需要导入一些常用的Python库来帮助我们进行数据分析和地理信息处理。
import geopandas as gpd
import pandas as pd
import matplotlib.pyplot as plt
from shapely.geometry import Point
第二步:加载数据
假设你的数据文件名为beijing_poi.shp和beijing_poi.csv,我们可以使用GeoPandas来加载shp文件,并查看前几行以了解数据的基本情况。
# 加载shp文件
poi_gdf = gpd.read_file('beijing_poi.shp')
# 查看前几行数据
print(poi_gdf.head())
# 检查数据基本信息
print(poi_gdf.info())
第三步:数据预处理
我们需要对数据进行一些预处理,以便更好地进行分析和可视化。
# 选择特定区域的数据(例如朝阳区)
chaoyang_poi = poi_gdf[poi_gdf['district'] == '朝阳区']
# 选择特定类别的数据(例如餐饮)
restaurant_poi = poi_gdf[poi_gdf['category'] == '餐饮']
# 统计各类别POI的数量
category_counts = poi_gdf['category'].value_counts()
print(category_counts)
第四步:数据可视化
我们可以使用Matplotlib和GeoPandas来进行数据可视化。
# 绘制北京市所有POI的分布图
fig, ax = plt.subplots(figsize=(12, 8))
poi_gdf.plot(ax=ax, markersize=0.5, color='blue')
plt.title('Beijing POI Distribution')
plt.show()
# 绘制朝阳区POI的分布图
fig, ax = plt.subplots(figsize=(12, 8))
chaoyang_poi.plot(ax=ax, markersize=0.5, color='red')
plt.title('Chaoyang District POI Distribution')
plt.show()
# 绘制餐饮类POI的分布图
fig, ax = plt.subplots(figsize=(12, 8))
restaurant_poi.plot(ax=ax, markersize=0.5, color='green')
plt.title('Restaurant POI Distribution')
plt.show()
第五步:进一步分析
我们可以进行更深入的分析,比如计算不同区域的POI密度、分析各类别POI的空间分布特征等。
# 计算各区域的POI数量
district_counts = poi_gdf.groupby('district').size().reset_index(name='count')
print(district_counts)
# 分析各类别POI的空间分布特征
for category in poi_gdf['category'].unique():
category_poi = poi_gdf[poi_gdf['category'] == category]
fig, ax = plt.subplots(figsize=(12, 8))
category_poi.plot(ax=ax, markersize=0.5)
plt.title(f'{category} POI Distribution')
plt.show()
第六步:导出结果
最后,我们可以将分析结果导出为新的shp文件或csv文件,以便后续使用。
# 导出朝阳区POI数据为新的shp文件
chaoyang_poi.to_file('chaoyang_poi.shp', driver='ESRI Shapefile')
# 导出餐饮类POI数据为csv文件
restaurant_poi.to_csv('restaurant_poi.csv', index=False)
通过以上步骤,你可以对北京市POI数据集进行有效的分析和可视化。
利用这些地理信息系统(GIS)软件的强大功能进行数据分析、可视化和空间分析。以下是如何在ArcGIS和QGIS中使用这个数据集的指南。
在ArcGIS中使用
1. 加载数据
- 打开ArcGIS软件(例如ArcMap或ArcGIS Pro)。
- 点击“Catalog”窗口,然后右键点击你想要添加数据的文件夹连接,选择“Add Data…”。
- 浏览并选择你的
.shp文件(本例中为北京市POI数据),然后点击“Add”。这将把数据加载到地图视图中。
2. 数据查看与探索
- 使用“Identify”工具可以点击地图上的任意点以查看其属性信息。
- 利用“Table”按钮打开所选图层的属性表,检查每个POI的具体信息。
3. 数据分析
- 空间查询:通过“Select by Location”或者“Select by Attributes”来过滤出满足特定条件的数据。
- 缓冲区分析:对于某个兴趣点,创建一定距离的缓冲区,以便分析周边环境。
- 热点分析:使用“Hot Spot Analysis (Getis-Ord Gi*)”工具来识别POI分布的热点区域。
4. 数据可视化
- 根据属性值调整符号化方式,比如按照POI类型设置不同的颜色。
- 创建专题地图,如密度图、分类图等,帮助理解数据的空间分布特征。
在QGIS中使用
1. 加载数据
- 打开QGIS软件。
- 点击左上角的“Layer”菜单,选择“Add Layer” -> “Add Vector Layer…”。
- 浏览并选择你的
.shp文件,然后点击“Open”。
2. 数据查看与探索
- 使用“Identify Features”工具可以在地图上点击任何要素查看其详细信息。
- 双击图层面板中的图层名称,进入“Layer Properties”,选择“Information”标签页查看元数据,或选择“Attributes Form”查看和编辑属性。
3. 数据分析
- SQL查询:使用“DB Manager”插件执行SQL查询筛选数据。
- 几何处理:利用“Processing Toolbox”中的各种算法(如Buffer, Clip等)进行空间分析。
- 统计分析:通过“Statistics by Categories”工具计算各类别POI的数量分布。
4. 数据可视化
- 在“Layer Styling”面板中,根据需要设置颜色、大小、透明度等样式。
- 尝试使用热力图插件生成热度图,直观展现POI密集程度。

















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










