




|
欢迎各位同学关注我哦~
在这个 AI 喧嚣的时代 不忘初心,戒骄戒躁,认真沉淀 |  |
在前面几篇介绍到Redis的事件驱动机制中,有两类时间一直贯穿始终:时间事件(Time Event)是与上一篇文章介绍的文件事件。这些事件在前文中也多多少少的介绍到一点。时间事件用于处理定时任务,如服务器定时维护、客户端超时检测、AOF持久化、主从复制心跳等。Redis通过时间事件实现了一个轻量级的定时器机制,在单线程中高效地管理各类周期性任务。
在下面的内容中,我们将由浅入深的去了解Redis时间事件的实现原理,从数据结构到核心API,再到实际应用场景。准备好了的话,我们就开始咯~
二、核心数据结构
2.1 时间事件结构体 aeTimeEvent
先来简单过一过时间事件的结构体:
// src/ae.h:79-88
typedef struct aeTimeEvent {
long long id; // 时间事件唯一标识符,全局递增
long when_sec; // 触发时间的秒数部分(绝对时间)
long when_ms; // 触发时间的毫秒数部分(绝对时间)
aeTimeProc *timeProc; // 时间事件回调函数
aeEventFinalizerProc *finalizerProc; // 事件销毁时的清理函数(可选)
void *clientData; // 用户自定义数据,传递给回调函数
struct aeTimeEvent *prev; // 指向前一个时间事件
struct aeTimeEvent *next; // 指向下一个时间事件,形成双向链表
} aeTimeEvent;
2.2 事件循环中的时间事件
在事件循环中也有几个字段适合时间事件是紧密相关的:
// src/ae.h:97-109
typedef struct aeEventLoop {
int maxfd; // 当前注册的最大文件描述符
int setsize; // 事件表容量上限
long long timeEventNextId; // 下一个时间事件的 ID(全局递增计数器)
time_t lastTime; // 上次处理时间事件的时间,用于检测时钟偏移
aeFileEvent *events; // 注册的文件事件表
aeFiredEvent *fired; // 已触发的文件事件表
aeTimeEvent *timeEventHead; // 时间事件链表头节点
int stop; // 停止标志
void *apidata; // 多路复用 API 的私有数据
aeBeforeSleepProc *beforesleep; // 事件循环前回调
aeBeforeSleepProc *aftersleep; // 事件循环后回调
} aeEventLoop;
其中有一下几个字段和时间事件的关系紧密:
timeEventNextId:全局递增的事件ID计数器timeEventHead:时间事件链表的头节点,所有时间事件通过链表串联lastTime:记录上次处理时间事件的时间,用于检测系统时钟偏移
那么为什么事件循环中要包含时间事件?
Redis 采用统一的事件驱动模型,将文件事件(网络 I/O)和时间事件(定时任务)放在同一个事件循环中处理。这种设计有以下原因:
- 统一的处理入口:
aeProcessEvents函数同时处理文件事件和时间事件,简化了主循环逻辑 - 精确的超时控制:时间事件决定了
aeApiPoll的阻塞时长,避免阻塞过久而延迟定时任务 - 资源共享:时间事件和文件事件共享同一个事件循环上下文,便于在定时任务中操作网络连接
- 单线程架构:Redis主线程只有一个事件循环,时间事件必须融入其中,否则需要额外的线程或信号机制
简单来说,aeEventLoop 是 Redis 事件驱动模型的核心容器,它需要同时管理文件事件和时间事件,才能实现高效的 I/O 多路复用与定时任务调度。
三、时间事件的类型
Redis 的时间事件主要分为两大类:一次性时间事件,周期性时间事件。
3.1 一次性时间事件
只执行一次,事件触发执行后自动删除,不再重复执行。通过回调函数返回 AE_NOMORE 实现:
// src/ae.h:51
#define AE_NOMORE -1
3.2 周期性时间事件
顾名思义,事件触发执行后,根据回调函数的返回值重新计算下次触发时间,实现周期执行。返回值为距离下次触发的毫秒数。
Redis 中最典型的周期性时间事件是 serverCron,默认每100ms执行一次。
四、核心 API 实现
4.1 创建时间事件 aeCreateTimeEvent
// src/ae.c:208-228
long long aeCreateTimeEvent(aeEventLoop *eventLoop, long long milliseconds,
aeTimeProc *proc, void *clientData,
aeEventFinalizerProc *finalizerProc)
{
long long id = eventLoop->timeEventNextId++; // 分配全局唯一ID
aeTimeEvent *te;
te = zmalloc(sizeof(*te)); // 分配时间事件结构体内存
if (te == NULL) return AE_ERR;
te->id = id;
// 计算触发的绝对时间:当前时间+延迟毫秒数
aeAddMillisecondsToNow(milliseconds,&te->when_sec,&te->when_ms);
te->timeProc = proc; // 设置时间事件回调函数
te->finalizerProc = finalizerProc; // 设置销毁时的清理函数
te->clientData = clientData; // 设置用户自定义数据
// 头插法插入双向链表:新事件插入到链表头部
te->prev = NULL;
te->next = eventLoop->timeEventHead;
if (te->next)
te->next->prev = te;
eventLoop->timeEventHead = te;
return id; // 返回事件ID,用于后续删除操作
}
有的同学可能会有这样的疑问:为什么使用头插法而不是按触发时间有序插入?
如果按触发时间有序插入,aeSearchNearestTimer 查找最近事件就只需要取链表头部,复杂度从O(n)降为O(1)。但Redis选择了无序链表 + 头插法,原因是:
- 插入效率优先:有序插入需要O(n)找到插入位置,而头插法只需O(1)
- 时间事件极少:Redis 通常只有1-2个时间事件(主要是
serverCron),遍历开销几乎为零
在实际场景中时间事件数量远少于文件事件,优化时间事件的查找收益甚微,简单来说,当n很小时,O(n)和O(1)的差距可以忽略,简单的实现更优。
创建时间事件的步骤可以简单概述如下:
- 分配全局唯一的事件ID
- 分配并初始化时间事件结构体
- 计算事件触发的绝对时间
- 将事件插入双向链表头部
- 返回事件ID
4.2 删除时间事件 aeDeleteTimeEvent
// src/ae.c:230-241
int aeDeleteTimeEvent(aeEventLoop *eventLoop, long long id)
{
aeTimeEvent *te = eventLoop->timeEventHead;
while(te) {
if (te->id == id) {
te->id = AE_DELETED_EVENT_ID; // 标记为已删除
return AE_OK;
}
te = te->next;
}
return AE_ERR;
}
删除的时间事件的时候,并不是直接删除的,而是采用了延迟删除,先通过修改时间的id为(AE_DELETED_EVENT_ID),将该事件标记为已删除的状态,然后实际释放内存的操作是在processTimeEvents 中进行,尽量避免了在遍历链表的时候修改链表的结构而导致的一些不可预料的问题。
4.3 查找最近的时间事件 aeSearchNearestTimer
// src/ae.c:254-267
static aeTimeEvent *aeSearchNearestTimer(aeEventLoop *eventLoop)
{
aeTimeEvent *te = eventLoop->timeEventHead; // 从链表头开始遍历
aeTimeEvent *nearest = NULL; // 记录最近的时间事件
// 遍历整个链表,找到触发时间最早的事件
while(te) {
// 比较when_sec和when_ms,找到最小的时间
if (!nearest || te->when_sec < nearest->when_sec ||
(te->when_sec == nearest->when_sec &&
te->when_ms < nearest->when_ms))
nearest = te; // 更新最近事件
te = te->next;
}
return nearest; // 返回最近的时间事件,可能为NULL
}
时间事件链表是无序的,需要遍历查找最早触发的事件,该函数用于计算 aeApiPoll 的超时时间,确保不会错过时间事件,时间复杂度O(n),但Redis通常只有1个时间事件,开销可忽略
4.4 处理时间事件 processTimeEvents
// src/ae.c:270-342
static int processTimeEvents(aeEventLoop *eventLoop) {
int processed = 0; // 统计已处理的事件数量
aeTimeEvent *te;
long long maxId;
time_t now = time(NULL); // 获取当前时间(秒)
// 检测系统时钟是否被向后调整(时钟回退)
if (now < eventLoop->lastTime) {
// 时钟被向后调整,立即触发所有时间事件
// 将所有事件的触发时间设为0,使其立即执行
te = eventLoop->timeEventHead;
while(te) {
// 直接从链表头遍历到链表尾
te->when_sec = 0; // 设置为立即触发
te = te->next;
}
}
eventLoop->lastTime = now; // 更新上次处理时间
// 遍历处理所有到期的时间事件
te = eventLoop->timeEventHead;
maxId = eventLoop->timeEventNextId-1; // 记录当前最大ID
while(te) {
long now_sec, now_ms;
long long id;
// 处理被标记删除的事件:从链表中移除并释放
if (te->id == AE_DELETED_EVENT_ID) {
aeTimeEvent *next = te->next;
if (te->prev)
te->prev->next = te->next;
else
eventLoop->timeEventHead = te->next;
if (te->next)
te->next->prev = te->prev;
if (te->finalizerProc)
te->finalizerProc(eventLoop, te->clientData);
zfree(te);
te = next;
continue;
}
// 跳过在本次处理过程中新创建的事件(ID > maxId)
// 防止新事件在本次循环中被立即处理
if (te->id > maxId) {
te = te->next;
continue;
}
// 获取当前精确时间(秒 + 毫秒)
aeGetTime(&now_sec, &now_ms);
// 检查事件是否已到期:触发时间 <= 当前时间
if (now_sec > te->when_sec ||
(now_sec == te->when_sec && now_ms >= te->when_ms))
{
int retval;
id = te->id;
// 调用时间事件回调函数
retval = te->timeProc(eventLoop, id, te->clientData);
processed++; // 统计已处理的事件数
// 根据返回值决定事件是否继续
if (retval != AE_NOMORE) {
// 周期事件:重新计算下次触发时间
// retval 为距离下次触发的毫秒数
aeAddMillisecondsToNow(retval,&te->when_sec,&te->when_ms);
} else {
// 一次性事件:返回AE_NOMORE,标记为删除
te->id = AE_DELETED_EVENT_ID;
}
}
te = te->next; // 继续处理下一个事件
}
return processed; // 返回已处理的事件数量
}
在上面的方法中我们也终于看到了前文中出现的被标记为删除节点的删除过程。简单过一遍上面的这个方法后,不知道大家有没有想过下面的两个问题?
1. 为什么用 maxId 跳过新创建的事件?
在遍历处理过程中,回调函数 timeProc 可能会创建新的时间事件(如 serverCron 中可能触发新的定时任务)。新事件会被头插到链表头部,如果继续处理可能导致同一轮循环中重复处理新事件,这样就进入了无限循环(新事件又创建新事件)。实用maxId 记录遍历开始前的最大事件 ID,跳过ID更大的新事件,确保每轮循环只处理已存在的事件。
2. 时钟回退检测的意义
系统时钟被向后调整(如NTP同步、手动修改)会导致定时任务延迟执行。当检测到时钟回退后,强制所有时间事件立即触发,确保关键任务(如过期键清理、主从心跳)不被无限推迟。
梳理一下processTimeEvents的主要执行流程:
- 检测系统时钟偏移,处理时钟回退情况
- 遍历时间事件链表
- 清理被标记删除的事件
- 检查每个事件是否已到期
- 到期事件:调用回调函数,根据返回值决定是否继续
- 返回处理的事件数量
4.5 计算超时时间
在 aeProcessEvents 中,会根据最近的时间事件计算 aeApiPoll 的超时时间:
// src/ae.c:369-407
// ......
// ......
// 判断是否需要计算超时时间
if (eventLoop->maxfd != -1 ||
((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
int j;
aeTimeEvent *shortest = NULL; // 最近的时间事件
struct timeval tv, *tvp;
// 查找最近的时间事件
if (flags & AE_TIME_EVENTS && !(flags & AE_DONT_WAIT))
shortest = aeSearchNearestTimer(eventLoop);
if (shortest) {
// 存在时间事件,计算超时时间
long now_sec, now_ms;
aeGetTime(&now_sec, &now_ms); // 获取当前时间
tvp = &tv;
// 计算距离最近时间事件还有多少毫秒
long long ms =
(shortest->when_sec - now_sec)*1000 +
shortest->when_ms - now_ms;
if (ms > 0) {
// 还有剩余时间,设置为超时值
tvp->tv_sec = ms/1000; // 秒部分
tvp->tv_usec = (ms % 1000)*1000; // 微秒部分
} else {
// 时间已到,立即返回不阻塞
tvp->tv_sec = 0;
tvp->tv_usec = 0;
}
} else {
// 没有时间事件
if (flags & AE_DONT_WAIT) {
// 设置了不等待标志,立即返回
tv.tv_sec = tv.tv_usec = 0;
tvp = &tv;
} else {
// 没有时间事件且允许等待,无限阻塞直到有文件事件
tvp = NULL; /* wait forever */
}
}
// 调用 I/O 多路复用,等待文件事件或超时
numevents = aeApiPoll(eventLoop, tvp);
// ......
// ......
说明:
- 如果有时间事件,计算最近事件的剩余时间作为超时值
- 如果没有时间事件,可能无限等待(直到有文件事件)
- 如果设置了
AE_DONT_WAIT,超时为0,立即返回
五、时间事件在 Redis 中的应用
5.1 serverCron 的注册
Redis启动时,会在 initServer 中注册 serverCron 时间事件:
// src/server.c:2122-2124
// 创建定时器回调,这是处理后台任务的核心机制
// 包括客户端超时、过期键清理等
if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
serverPanic("Can't create event loop timers.");
exit(1);
}
serverCron 是Redis的核心定时任务,负责:
- 更新服务器时间缓存
- 处理客户端超时
- 执行过期键清理
- 触发 AOF 重写/RDB 保存
- 主从复制心跳
- 集群心跳
- 等等…
5.2 serverCron 的实现
// src/server.c:1090-1352
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
int j;
UNUSED(eventLoop);
UNUSED(id);
UNUSED(clientData);
// 软件看门狗:如果serverCron执行超时,发送SIGALRM信号
if (server.watchdog_period > 0) watchdogScheduleSignal(server.watchdog_period);
updateCachedTime(1); // 更新服务器时间缓存,避免频繁调用time()
server.lruclock = getLRUClock(); // 更新LRU时钟,用于键淘汰
// 记录峰值内存使用量
if (zmalloc_used_memory() > server.stat_peak_memory)
server.stat_peak_memory = zmalloc_used_memory();
server.resident_set_size = zmalloc_get_rss(); // 获取进程实际物理内存
// 处理 SIGTERM 信号,安全关闭服务器
if (server.shutdown_asap) {
if (prepareForShutdown(SHUTDOWN_NOFLAGS) == C_OK) exit(0);
serverLog(LL_WARNING,"SIGTERM received but errors trying to shut down the server, check the logs for more information");
server.shutdown_asap = 0;
}
// 每5秒打印一次数据库统计信息
run_with_period(5000) {
for (j = 0; j < server.dbnum; j++) {
long long size, used, vkeys;
size = dictSlots(server.db[j].dict); // 哈希表槽位数
used = dictSize(server.db[j].dict); // 已使用键数量
vkeys = dictSize(server.db[j].expires); // 设置过期时间的键数量
if (used || vkeys) {
serverLog(LL_VERBOSE,"DB %d: %lld keys (%lld volatile) in %lld slots HT.",j,used,vkeys,size);
}
}
}
// 每 5 秒打印一次客户端连接信息
if (!server.sentinel_mode) {
run_with_period(5000) {
serverLog(LL_VERBOSE,
"%lu clients connected (%lu replicas), %zu bytes in use",
listLength(server.clients)-listLength(server.slaves),
listLength(server.slaves),
zmalloc_used_memory());
}
}
clientsCron(); // 异步处理客户端相关任务:超时检测、输入输出缓冲区检查
databasesCron(); // 数据库后台任务:过期键清理、字典rehash
// 如果AOF重写被延迟(因为当时有BGSAVE),现在尝试执行
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1 &&
server.aof_rewrite_scheduled)
{
rewriteAppendOnlyFileBackground();
}
// 检查后台子进程是否结束(RDB或AOF)
if (server.rdb_child_pid != -1 || server.aof_child_pid != -1 ||
ldbPendingChildren())
{
int statloc;
pid_t pid;
// 非阻塞等待子进程结束
if ((pid = wait3(&statloc,WNOHANG,NULL)) != 0) {
int exitcode = WEXITSTATUS(statloc); // 退出码
int bysignal = 0;
if (WIFSIGNALED(statloc)) bysignal = WTERMSIG(statloc); // 终止信号
if (pid == -1) {
// wait3 出错
serverLog(LL_WARNING,"wait3() returned an error: %s. "
"rdb_child_pid = %d, aof_child_pid = %d",
strerror(errno),
(int) server.rdb_child_pid,
(int) server.aof_child_pid);
} else if (pid == server.rdb_child_pid) {
// RDB 后台保存完成
backgroundSaveDoneHandler(exitcode,bysignal);
} else if (pid == server.aof_child_pid) {
// AOF 后台重写完成
backgroundRewriteDoneHandler(exitcode,bysignal);
} else {
if (!ldbPendingChildren()) {
serverLog(LL_WARNING,
"Warning, detected child with unmatched pid: %ld",
(long)pid);
}
}
updateDictResizePolicy(); // 根据是否有子进程调整字典rehash策略
}
} else {
// 没有后台任务,检查是否需要执行RDB保存
for (j = 0; j < server.saveparamslen; j++) {
struct saveparam *sp = server.saveparams+j;
// 检查 save 配置条件:变更数 >= sp->changes 且时间 >= sp->seconds
if (server.dirty >= sp->changes &&
server.unixtime-server.lastsave > sp->seconds) {
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...",
sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
rdbSaveBackground(server.rdb_filename,rsiptr);
break;
}
}
// 检查是否需要触发AOF重写
if (server.rdb_child_pid == -1 &&
server.aof_child_pid == -1 &&
server.aof_rewrite_perc &&
server.aof_current_size > server.aof_rewrite_min_size)
{
// AOF文件增长率超过阈值时触发重写
long long baseline = server.aof_rewrite_base_size ?
server.aof_rewrite_base_size : 1;
long long growth = (server.aof_current_size*100/baseline) - 100;
if (growth >= server.aof_rewrite_perc) {
serverLog(LL_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth);
rewriteAppendOnlyFileBackground();
}
}
}
// ... 更多任务
}
5.3 serverCron的返回值
serverCron 返回下次执行的间隔时间(毫秒):
// src/server.c:1351-1352
server.cronloops++; // 增加循环计数器,用于run_with_period宏
return 1000/server.hz; // 返回下次执行的毫秒数
server.hz默认值为10,表示每秒执行10次- 返回
1000/10 = 100,即每100ms执行一次 - 可通过配置文件调整
hz参数,影响定时任务的执行频率
5.4 run_with_period宏
serverCron 中大量使用 run_with_period 宏来控制任务执行频率:
// src/server.h:452
#define run_with_period(_ms_) if ((_ms_ <= 1000/server.hz) || !(server.cronloops%((_ms_)/(1000/server.hz))))
宏解析:
- 如果
_ms_ <= 1000/server.hz,则每次serverCron都执行 - 否则,每隔
_ms_/(1000/server.hz)次循环执行一次
用法示例:
// 每5秒打印一次数据库信息
run_with_period(5000) {
// 打印数据库统计信息
}
// 每100ms执行一次集群心跳
run_with_period(100) {
if (server.cluster_enabled) clusterCron();
}
六、时间事件处理流程图
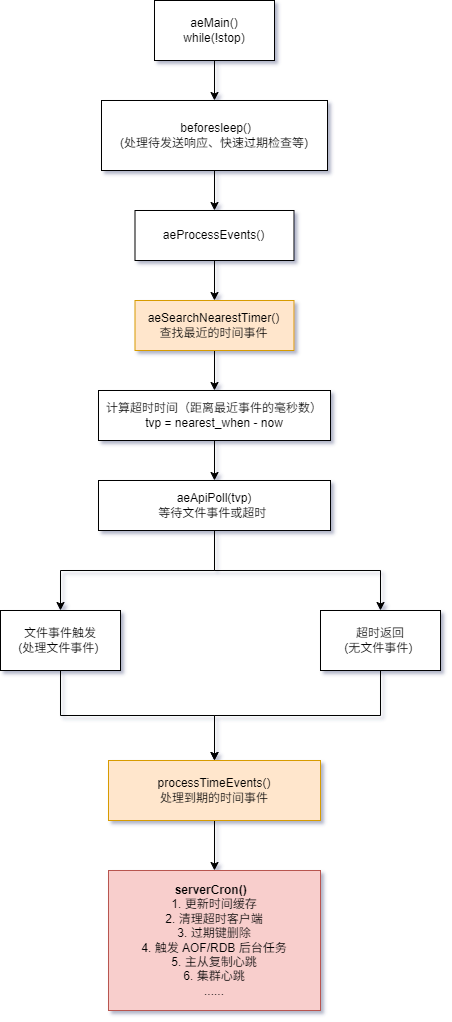
时间事件是 Redis 实现定时任务的核心机制,serverCron 作为唯一的时间事件,承载了服务器的大部分后台维护工作。
|
欢迎各位同学关注我哦~
在这个 AI 喧嚣的时代 不忘初心,戒骄戒躁,认真沉淀 | |


















源码详解&spm=1001.2101.3001.5002&articleId=160058396&d=1&t=3&u=f0c5bd8e74804583a878886791d6a9e2)
 3202
3202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










