




零、神经网络
神经网络的作用:特征提取
一、算法
1.随机梯度下降算法
(1)梯度下降算法 GD
梯度下降算法 (Gradient Descent,GD)。是深度学习最核心的算法之一。
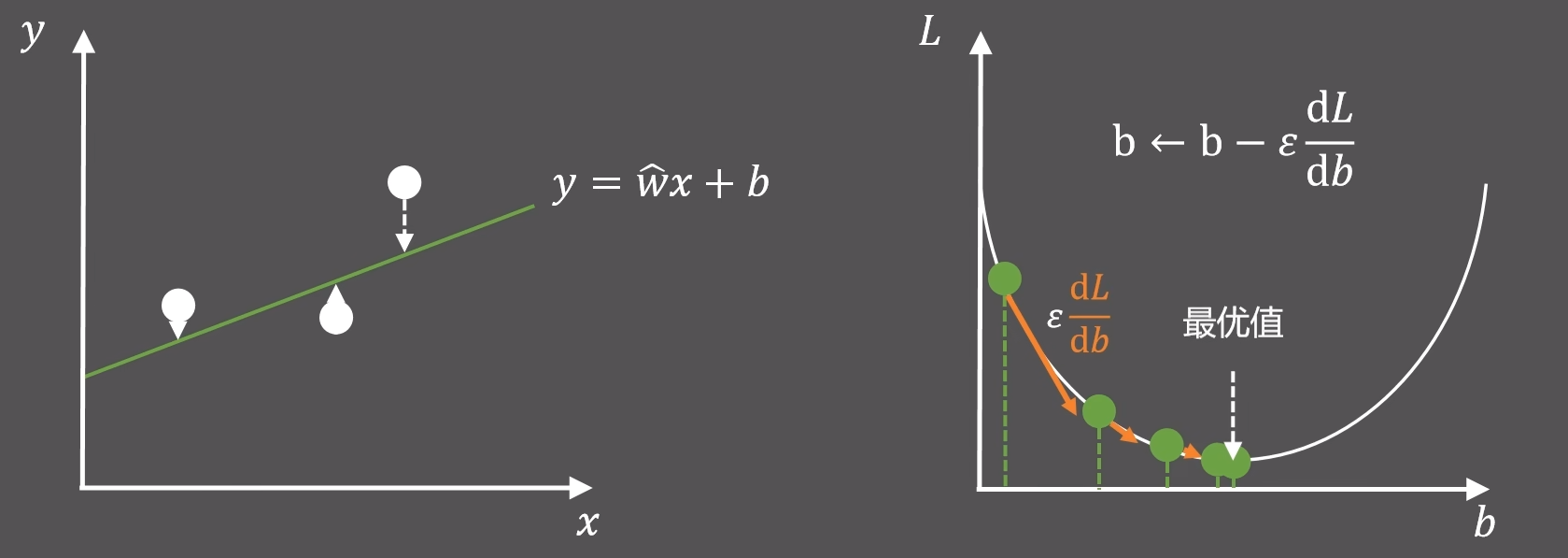
(2)随机梯度下降算法 SGD
考虑到内存限制和迭代速度,我们每次只抽取部分样本优化,所以将其改进为随机梯度下降。
随机梯度下降算法 (Stochastic Gradient Descent,SGD)
(3)损失函数

(4)学习率

(5)动量

2.反向传播算法
对于y=wx+b:
计算梯度值,也就是偏导数,然后再沿着梯度的反方向,更新两个参数w和b
从后向前计算参数梯度值,降低损失函数的方法,就是反向传播算法。

二、深度学习常用Python库介绍
1.Numpy库:数值计算,多维数组和矩阵运算
Numpy:用于数值计算,例如数组操作和数据类型转换,主要用于处理多维数组(ndarray)和矩阵运算。
Numpy 是一个强大的科学计算库,它提供了高效的多维数组对象和相关工具,用于处理大量数据。在强化学习中, numpy 可以用来存储和处理观察结果、奖励值、动作概率等数据。
NumPy(Numerical Python)是一个开源的 Python 数值计算库,提供支持大型、多维数组和矩阵的操作,具有高效的数学函数库。它广泛应用于数据分析、机器学习、科学计算、工程计算等领域。NumPy 是许多科学计算和数据分析库的基础,比如 Pandas、SciPy、Matplotlib 等
1.NumPy 库
①np.save()函数可以将数组保存为.npy文件
②np.load()可以加载.npy文件并将其恢复为数组。
2.npy文件的优点:
①节省存储空间:由于 .npy 文件是二进制格式,存储效率更高,特别适合于存储大规模数据。
②保留数组信息:在存储时,数组的形状、数据类型等信息都会被保留下来,加载时会完整恢复,便于继续使用。
③读取速度快:相比于文本格式,.npy 文件的读取速度更快,适合机器学习和科学计算任务中的数据加载需求。
3.代码示例
import numpy as np
# 创建一个10x10的二维数组(矩阵)
matrix = np.random.rand(10, 10)
# NumPy数组操作示例
sum_of_columns = np.sum(matrix, axis=0) # 每列元素的和
product_of_rows = np.prod(matrix, axis=1) # 每行元素的乘积
2.Pandas
Pandas 是基于 NumPy 构建的数据分析库,专注于结构化数据处理。
核心特点:
- 提供两种核心数据结构:Series(一维带标签数组)和 DataFrame(二维表格数据)
- 强大的数据清洗、转换、过滤和聚合功能
- 支持多种文件格式读写(CSV、Excel、JSON、SQL 等)
- 时间序列数据处理能力强
3.gym / gymnasium:智能体与强化学习
1.概念介绍
gym 是OpenAI推出的一个用于开发和比较强化学习算法的工具包,它为研究者提供了一个简单的标准接口来测试他们的算法。 gym 环境支持各种类型的模拟环境,从简单的经典控制问题到复杂的3D机器人仿真。
gym 是 OpenAI 开发的一个开源 Python 库,主要用于开发和比较强化学习算法。它提供了一系列标准化的环境(如游戏、物理模拟等),让研究者和开发者可以专注于算法本身,而不必花费精力构建复杂的环境。
2.安装
pip install gym
3.gym的核心概念
(1)环境(Environment):这是 gym 的核心,代表强化学习中的任务或问题。每个环境都有统一的接口。
(2)智能体(Agent):在环境中行动的实体,通过与环境交互学习最优策略。
(3)状态(State):环境的当前情况,智能体根据状态做出决策。
(4)动作(Action):智能体在特定状态下可以执行的操作。
(5)奖励(Reward):智能体执行动作后得到的反馈,用于评估动作的好坏。
4.基本使用流程
gym 的环境使用遵循一个简单统一的接口,主要步骤如下:
(1)创建环境
(2)重置环境获取初始状态
(3)智能体根据状态选择动作
(4)执行动作,获取新状态、奖励和是否结束的标志
(5)重复步骤 3-4 直到 episode 结束
5.代码
import gym
# 创建环境实例
env = gym.make('CartPole-v1')
# 获取环境的观察空间和动作空间
print(env.observation_space)
print(env.action_space)
# 重置环境
obs = env.reset()
done = False
while not done:
# 显示观察结果
print(obs)
# 采取随机动作
action = env.action_space.sample()
# 执行动作,并观察结果
obs, reward, done, info = env.step(action)
env.close()
4.Matplotlib:数据可视化工具
Matplotlib是一个用于创建静态、动画和交互式可视化的库。在强化学习中,可视化可以帮助我们更好地理解算法的工作原理和学习过程。
matplotlib 是 Python 中最流行的可视化库之一,由 John D. Hunter 于 2003 年发起开发,旨在为 Python 提供类似 MATLAB 的绘图能力。它支持各种静态、动态和交互式的图表绘制,广泛应用于数据分析、科学计算、工程可视化等领域。
核心特点:
1.丰富的图表类型
支持线图、散点图、柱状图、直方图、饼图、热力图、3D 图形等几乎所有常见图表类型,满足不同场景的可视化需求。
2.高度可定制
从坐标轴、标签、图例到颜色、字体、线条样式,几乎所有图表元素都可以精细调整,实现个性化的可视化效果。
3.跨平台兼容性
可在 Windows、macOS、Linux 等系统上运行,支持多种输出格式(PNG、PDF、SVG、EPS 等)。
4.集成性强
与 NumPy、Pandas 等数据处理库无缝协作,也可嵌入到 Jupyter Notebook、Web 应用(如 Flask/Django)或 GUI 工具(如 Tkinter)中。
import matplotlib.pyplot as plt
# 假设这是强化学习过程中的累积奖励数据
cumulative_rewards = [0, 0, 1, 2, 3, 5, 7, 10, 13, 16]
# 绘制累积奖励随时间变化的图表
plt.plot(cumulative_rewards, label='Cumulative Rewards')
plt.xlabel('Episode')
plt.ylabel('Cumulative Reward')
plt.title('Cumulative Rewards Over Time')
plt.legend()
plt.show()
5.Scikit-learn:机器学习库的使用
Scikit-learn是一个广泛使用的机器学习库,它提供了简单有效的数据挖掘和数据分析工具。虽然Scikit-learn主要用于监督学习,但其数据预处理和模型评估功能也可用于强化学习。
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 使用Scikit-learn进行数据集分割
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]])
y = np.array([1, 0, 1, 0, 1])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# 训练模型并计算准确率
# 假设这里使用逻辑回归模型作为示例
model = LinearRegression()
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print(accuracy_score(y_test, predictions))
5.常见计算机视觉库
(1)OpenCV
官网网址:https://opencv.org/
(2)skimage:即scikit-image
官网API:https://scikit-image.org/docs/stable/api/skimage.feature.html#skimage.feature.graycomatrix
(3)PIL库 (Pillow)
PIL:以及其分支Pillow库
PIL(Python Imaging Library)是 Python 中用于图像处理的经典库,而 PIL 图像 就是由这个库的 Image 模块创建和操作的图像对象。通过 PIL 库,用户可以轻松加载、修改、保存图像,并对图像进行各种处理。
虽然PIL是一个老牌库,但目前已不再更新,社区开发了一个兼容且扩展版的库叫Pillow。Pillow是 PIL的分支,支持更多的图像格式和功能。现在的 Pillow 库也使用相同的模块名称(即 PIL),所以大家仍然习惯称其为PIL图像。
三、炼丹:深度学习模型训练全过程
在这个过程中,你(算法工程师)就是炼丹师,你的显卡(GPU)就是丹炉。
1.第一步:准备药材(数据准备 Data Preparation)
这是最枯燥但最重要的一步。炼丹界有名言:“Garbage In, Garbage Out”(如果你放进去的是垃圾,炼出来的也是垃圾)。
1.采药(数据收集):
你需要大量的图片、文本或语音。比如你想炼一个“识别猫”的丹药,你就需要找几万张猫的照片。
2.洗药(数据清洗):
去掉那些模糊的、错误的、标错的数据。
3.切药(数据预处理):
(1)归一化 (Normalization): 把像素值从 0-255 压缩到 0-1 之间,方便丹炉消化。
(2)数据增强 (Data Augmentation): 如果药材不够,就通过旋转、裁剪、调色,把一张图变出十张来,防止丹炉“死记硬背”(过拟合)。
4.分药(数据集划分):
(1)训练集 (Training Set): 真正丢进炉子里练的(70%-80%)。
(2)验证集 (Validation Set): 炼到一半拿出来尝尝咸淡的,用来调整火候(10%-20%)。
(3)测试集 (Test Set): 炼成之后最后给客户吃的,绝对不能在训练时偷看(10%)。
2.第二步:选丹炉(模型架构 Model Architecture)
你要决定用什么样的结构来炼丹。
1.现成的炉子: 大多数时候我们不需要自己造炉子,而是用大佬们设计好的经典架构,比如 ResNet, YOLO (适合你的物体检测), Transformer (适合大语言模型)。
2.魔改炉子: 高级炼丹师会根据任务特点,修改神经网络的层数、连接方式。
3.第三步:控制火候(超参数设置 Hyperparameters)
这是最像“玄学”的地方。你需要设置一些在训练开始前手动设定的参数,这些参数决定了炼丹的成败。
1.学习率 (Learning Rate): 最重要的火候。
(1)火太大(LR太大):模型学得太快,会在最优解附近反复横跳,甚至直接“炸炉”(Loss不降反升)。
(2)火太小(LR太小):炼个七七四十九天还没炼好,收敛极慢。
2.批大小 (Batch Size): 一次往炉子里铲多少药材。
你的 GTX 1650 显存比较小(通常4GB),如果 Batch Size 设得太大(比如64或128),显存直接溢出(OOM),炉子就炸了。通常你可能要设为 8, 16 或 32。
3.迭代轮数 (Epochs): 所有的药材反复炼多少遍。
4.第四步:开炉烧制(训练循环 Training Loop)
一切准备就绪,按下 python train.py,风扇狂转,丹炉开始工作。这个过程主要发生四件事:
1.前向传播 (Forward Propagation):
数据输入网络,网络给出一个预测结果(比如:它觉得这张图 80% 是猫)。
2.计算损失 (Loss Calculation):
拿预测结果和真实答案(Label)对比。网络说是猫,标签说是狗,误差(Loss)就很大。
3.反向传播 (Back Propagation):
这是炼丹的精髓。 根据误差,运用链式法则(Chain Rule),算出网络中每一层、每一个神经元到底错哪了。
4.权重更新 (Optimizer Step):
根据算出来的错,稍微调整一下神经元的连接权重(Weights)。
这四步每循环一次,模型就变聪明一点点。
5.第五步:试丹与出炉(验证与测试 Evaluation)
在炼的过程中,你需要盯着屏幕上的 Loss 曲线。
1.理想情况: 训练集Loss下降,验证集Loss也下降,最后趋于平稳。丹成!
2.走火入魔(过拟合 Overfitting): 训练集Loss一直在降(它背下了所有答案),但验证集Loss反而升高(遇到新题就不会了)。
解决办法: 早点停火(Early Stopping),或者加点正则化(DropOut)。
3.火候不够(欠拟合 Underfitting): 两个Loss都降不下去,说明炉子太简陋(模型太简单)或者药材太少。
6.总结
总结:在这个过程中,你在做什么?
作为炼丹师(开发者),大部分时间你不是在写核心算法(那是科学家做的事),而是在:
1.洗药材(写脚本处理数据)。
2.守在炉子边看曲线(用 TensorBoard 或 WandB 监控训练)。
3.因为显存不够而把 Batch Size 改小(Debug)。
4.因为效果不好而在这个参数上改改,那个参数上改改(调参)。
这就是为什么我们自嘲是“炼丹”,因为有时候你改了个参数,模型突然神了,你也不知道为什么,只能感叹一句:“这丹炉有灵性!”
四、炼丹实战
1.租算力平台:AutoDL
1.AutoDL网址:autodl.com
2.选择一张 RTX 4090 GPU显卡。费用为 ¥2.5/小时
2.VSCode + Remote-SSH
IDE用VSCode,安装插件Remote-SSH




















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












