




(发现自己太菜了,写个博客多动动笔,多动动脑子。。。)
0 前言
在观察一张图片,想要表达图片内容的时候,我们会搜索图片里有什么关键特征点,根据他们确定并传达出这些有效信息。深度学习中的注意力,就是网络在寻找label对应信息时候,将特征打上标签,认为它们重要或者不重要。
1 注意力机制
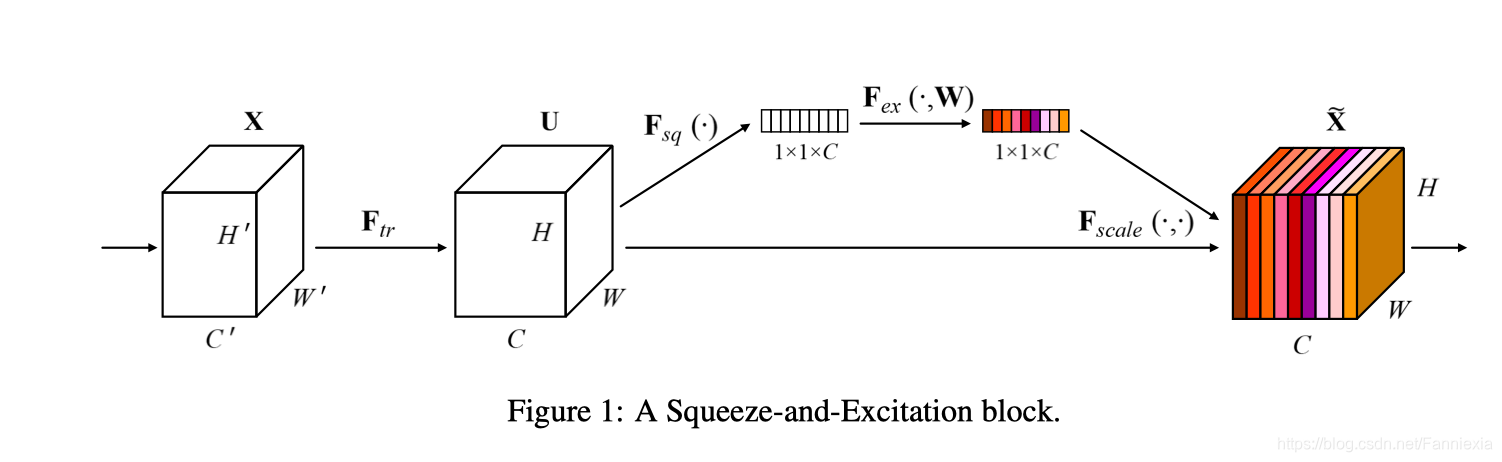
(1)SE模块 Squeeze(压缩)-and-Excitation(激发) Block
认为每个通道的重要程度是不一样的,通过调整每个通道的权重,增强网络特征提取能力。
代码:
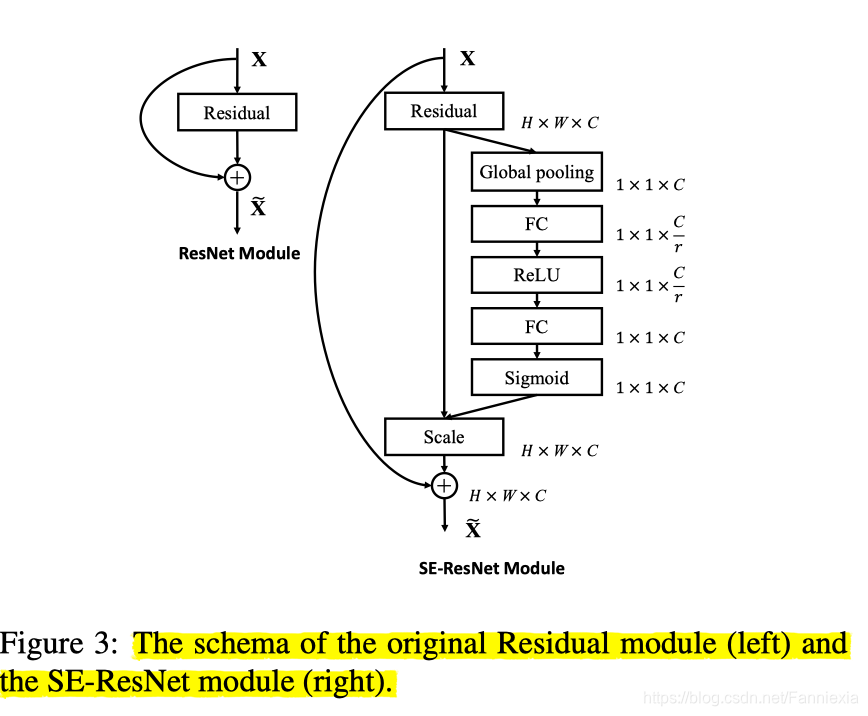
feature map先是经过一个average pooling层,将每个通道特征压缩到1*1,再通过全连接层,进一步压缩向量长度,随后恢复到原有长度,最后经过sigmoid层激发,给出每个通道的重要性权重。最后将该权重乘以feature map实现通道attention目的。
这里fc层这样做的意义在于增加网络的非线性。
import torch
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(



















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










