




 本文深入解析聚合模型原理,探讨模型融合提升性能之道。从简单平均到条件加权,揭示算法如Bagging、AdaBoost如何利用数据多样性增强预测力。
本文深入解析聚合模型原理,探讨模型融合提升性能之道。从简单平均到条件加权,揭示算法如Bagging、AdaBoost如何利用数据多样性增强预测力。
聚合模型实际上就是将许多模型聚合在一起,从而使其分类性能更佳。
aggregation models: mix or combine hypotheses (for better performance)
下面举个例子:
你有 TTT 朋友,他们对于股票涨停的预测表现为 g1,⋯ ,gTg_1,\cdots ,g_Tg1,⋯,gT。 常见的聚合(aggregation)方法有:
- select the most trust-worthy friend from their usual performance
根据他们的平常表现,选出最值得信任的朋友
G(x)=gt∗(x) with t∗=argmint∈{ 1,2,…,T}Eval (gt−) G(\mathbf{x})=g_{t_{*}}(\mathbf{x}) \text { with } t_{*}=\operatorname{argmin}_{t \in\{1,2, \ldots, T\}} E_{\text {val }}\left(g_{t}^{-}\right) G(x)=gt∗(x) with t∗=argmint∈{ 1,2,…,T}Eval (gt−) - mix the predictions from all your friends uniformly
将所有朋友的预测取平均值
G(x)=sign(∑t=1T1⋅gt(x)) G(\mathbf{x})=\operatorname{sign}\left(\sum_{t=1}^{T} 1 \cdot g_{t}(\mathbf{x})\right) G(x)=sign(t=1∑T1⋅gt(x)) - mix the predictions from all your friends non-uniformly
将所有朋友的预测值取加权平均值
G(x)=sign(∑t=1Tαt⋅gt(x)) with αt≥0 G(\mathbf{x})=\operatorname{sign}\left(\sum_{t=1}^{T} \alpha_{t} \cdot g_{t}(\mathbf{x})\right) \text { with } \alpha_{t} \geq 0 G(x)=sign(t=1∑Tαt⋅gt(x)) with αt≥0 - combine the predictions conditionally
根据当前状态 x\mathbf{x}x 确定权重后结合。
G(x)=sign(∑t=1Tqt(x)⋅gt(x)) with qt(x)≥0G(\mathbf{x})=\operatorname{sign}\left(\sum_{t=1}^{T} q_{t}(\mathbf{x}) \cdot g_{t}(\mathbf{x})\right) \text { with } q_{t}(\mathbf{x}) \geq 0G(x)=sign(t=1∑Tqt(x)⋅gt(x)) with qt(x)≥0
学到这里,可能有一种感觉,与模型选择比较相近,并根据直观印象,取平均获得是分类器一定比最好的差,比最差的好。所以会感觉 aggregation 用处不大,那现在看一下, aggregation 的真正的用处是什么?
以下图为例:
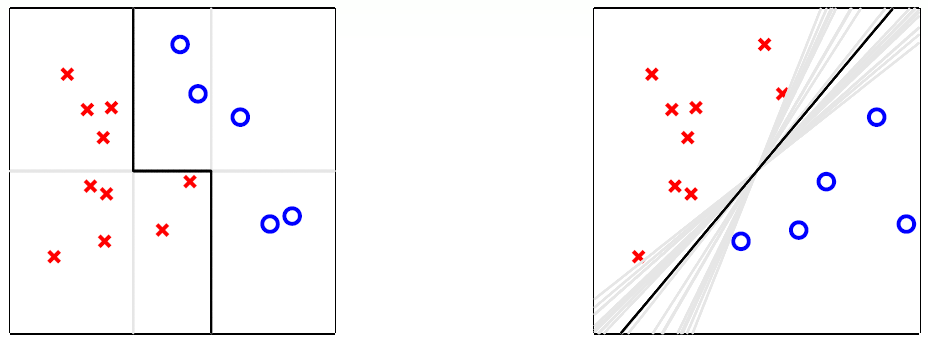
左侧第一个图中,实际上是使用三条竖线或横线实现了二分类,虽然竖线或横线是很弱的一种分类器,但是如此结合便获得了一个较强的分类器,其分类效果好于任何一个分类器独自分类的结果。
右侧第一个图中,是许多直线的取平均值获得的,这种状态存在于数据样本较少时,可以获取一种与SVM类似的效果,虽然这么多直线对于训练样本(采样数据)的分类效果一样,但是对于测试样本(全局数据)可能有更好的分类效果。
所以说真正的 aggregation 并不只是单纯的取平均而已,其可能是为了弥补当前分类器的不足(分类器分类性能较弱,分类器的泛化能力较弱)。即合理的聚合(aggregation)代表了更好的性能(performance)。
Blending
均值融合(uniform blending)
用于分类:
数学表达如下:
G(x)=sign(∑t=1Tgt(x)) G(\mathbf{x})=\operatorname{sign} \left( \sum_{t=1}^{T} g_{t}(\mathbf{x}) \right) G(x)=sign(t=1∑Tgt(x))
有 TTT 个人,每人一票。当 gtg_{t}gt 预测值相近,那么性能不变。当 gtg_{t}gt 多样民主时,少数服从多数(majority can correct minority)
在多分类中的数学表达为:
G(x)=argmax1≤k≤K∑t=1T[[gt(x)=k]] G(\mathbf{x})=\underset{1 \leq k \leq K}{\operatorname{argmax}} \sum_{t=1}^{T}\left[\kern-0.15em\left[g_{t}(\mathbf{x})=k\right]\kern-0.15em\right] G(x)=1≤k≤Kargmaxt=1∑T[[gt(x)=k]]
用于回归:
G(x)=1T∑t=1Tgt(x) G(\mathbf{x})=\frac{1}{T} \sum_{t=1}^{T} g_{t}(\mathbf{x}) G(x)=T1t=1∑Tgt(x)
当 gtg_{t}gt 预测值相近,那么性能不变。当 gtg_{t}gt 多样民主时,一些分类结果 gt(x)>f(x)g_{t}(\mathbf{x})>f(\mathbf{x})gt(x)>f(x) ,另一些分类结果 gt(x)<f(x)g_{t}(\mathbf{x})<f(\mathbf{x})gt(x)<f(x),那么理想状态取平均可以获得最佳解。
综合上述两种需求,多样性的 hypotheses 更容易使得融合模型性能更佳。
现在进行理论分析,其性能是否改善,这里以回归模型为例:
这里的取平均是针对全部的 hypothesis 或者说 TTT 个 gtg_tgt 进行的,并针对的是随机的单个样本。
avg((gt(x)−f(x))2)=avg(gt2−2gtf+f2)=avg(gt2)−2Gf+f2=avg(gt2)−G2+(G−f)2=avg(gt2)−2G2+G2+(G−f)2=avg(gt2)−2avg(gt)G+G2+(G−f)2=avg(gt2−2gtG+G2)+(G−f)2=avg((gt−G)2)+(G−f)2 \begin{aligned} \operatorname{avg}\left(\left(g_{t}(\mathrm{x})-f(\mathrm{x})\right)^{2}\right) &=\operatorname{avg}\left(g_{t}^{2}-2 g_{t} f+f^{2}\right) \\ &=\operatorname{avg}\left(g_{t}^{2}\right)-2 G f+f^{2} \\ &=\operatorname{avg}\left(g_{t}^{2}\right)-G^{2}+(G-f)^{2} \\ &=\operatorname{avg}\left(g_{t}^{2}\right)-2 G^{2}+G^{2}+(G-f)^{2} \\ &=\operatorname{avg}\left(g_{t}^{2}\right)-2\operatorname{avg}\left(g_{t}\right)G+G^{2}+(G-f)^{2} \\ &=\operatorname{avg}\left(g_{t}^{2}-2 g_{t} G+G^{2}\right)+(G-f)^{2} \\ &=\operatorname{avg}\left(\left(g_{t}-G\right)^{2}\right)+(G-f)^{2} \end{aligned} avg((gt(x)−f(x))2)=avg(gt2−2gtf+f2)=avg(gt2)−2Gf+f2=avg(gt2)−G2+(G−f)2=avg(gt2)−2G2+G2+(G−f)2=avg(gt2)−2avg(gt)G+G2+(G−f)2=avg(gt2−2gtG+G2)+(G−f)2=avg((gt−G)2)+(G−f)2
也就是说,在对全部训练样本 xn\mathbf{x}_nxn 进行分析取全部误差的平均值。这里 用E\mathcal{E}E 表示平均值。举个例子:1N∑n=1N(gt(xn)−f(xn))2=E(gt−f)2\frac{1}{N}\sum_{n = 1}^{N}\left(g_{t}(\mathrm{x}_n)-f(\mathrm{x}_n)\right)^{2} = \mathcal{E}\left(g_{t}-f\right)^{2}N1∑n=1N(gt(xn)−f(xn))2=E(gt−f)2。
avg(E(gt−f)2)=avg(E(gt−G)2)+E(G−f)2avg(Eout (gt))=avg(E(gt−G)2)+Eout (G)≥+Eout (G) \begin{aligned} \operatorname{avg}\left(\mathcal{E}\left(g_{t}-f\right)^{2}\right) &=\operatorname{avg}\left(\mathcal{E}\left(g_{t}-G\right)^{2}\right) & +\mathcal{E}(G-f)^{2}\\ \operatorname{avg}\left(E_{\text {out }}\left(g_{t}\right)\right) &=\operatorname{avg}\left(\mathcal{E}\left(g_{t}-G\right)^{2}\right) &+E_{\text {out }}(G) \\ & \geq & +E_{\text {out }}(G) \end{aligned} avg(E(gt−f)2)avg(Eout (gt))=avg(E(gt−G)2)=avg(E(




















&spm=1001.2101.3001.5002&articleId=105700743&d=1&t=3&u=87234319a9214515853af542c8520dc3)
 1954
1954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












