




 本文详细介绍了如何使用Pandas库处理缺失值,包括删除全部为NaN的行和列、删除含有NaN的行和列、定位并删除特定列的NaN值,以及筛选和替换NaN数据的方法。通过实例展示了每种操作的代码实现和输出结果,是数据预处理的重要参考。
本文详细介绍了如何使用Pandas库处理缺失值,包括删除全部为NaN的行和列、删除含有NaN的行和列、定位并删除特定列的NaN值,以及筛选和替换NaN数据的方法。通过实例展示了每种操作的代码实现和输出结果,是数据预处理的重要参考。

在处理缺失值的时候,总会遇到各种问题
目录
5.删除指定某一列有nan,这样即可定位到所在行的index,然后对该index进行drop操作即可df[np.isnan(df[‘open’])].index #定位某一列是否有nan
直接drop对应indx即可删除该行df.drop(df[np.isnan(df[‘open’])].index, inplace=True)
6. df1 = df.dropna(axis=0, how=‘all’, subset=[‘d’, ‘c’]) #删除指定的两列都是空的行
import pandas as pd
data = pd.read_excel(r'测试数据.xlsx')
print(data)
先看看如下数据
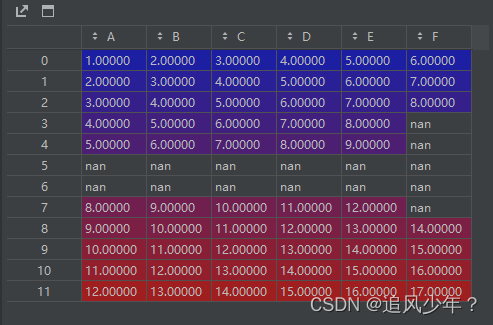
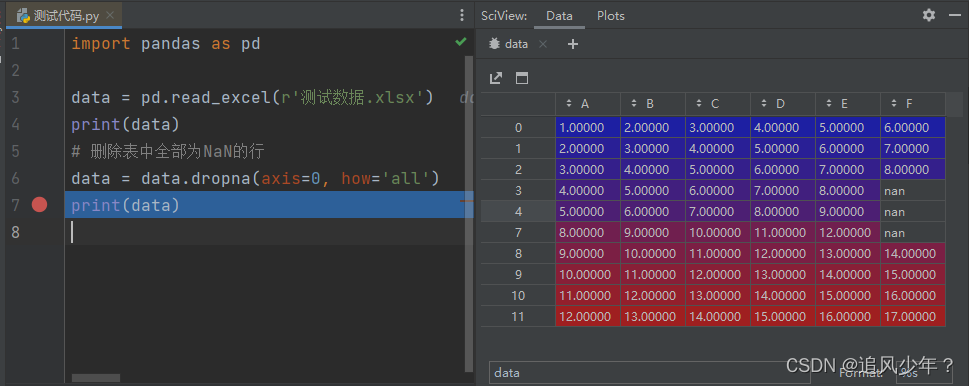
1.删除全部为nan的行
import pandas as pd
data = pd.read_excel(r'测试数据.xlsx')
print(data)
# 删除表中全部为NaN的行
data = data.dropna(axis=0, how='all')
print(data)
输出:
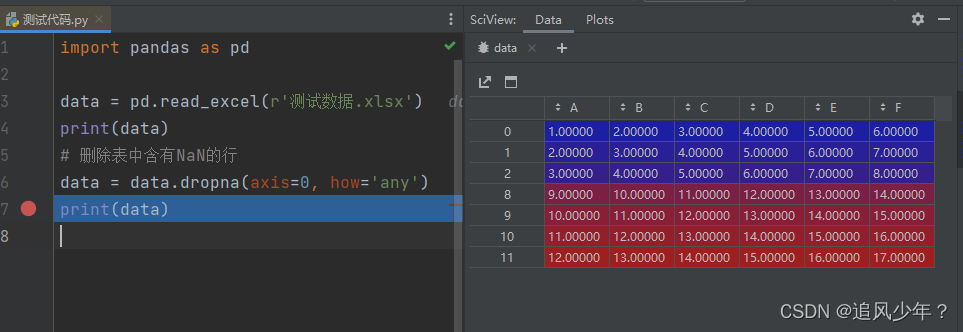
2.删除含有nan的行
import pandas as pd
data = pd.read_excel(r'测试数据.xlsx')
print(data)
# 删除表中含有NaN的行
data = data.dropna(axis=0, how='any')
print(data)
输出:
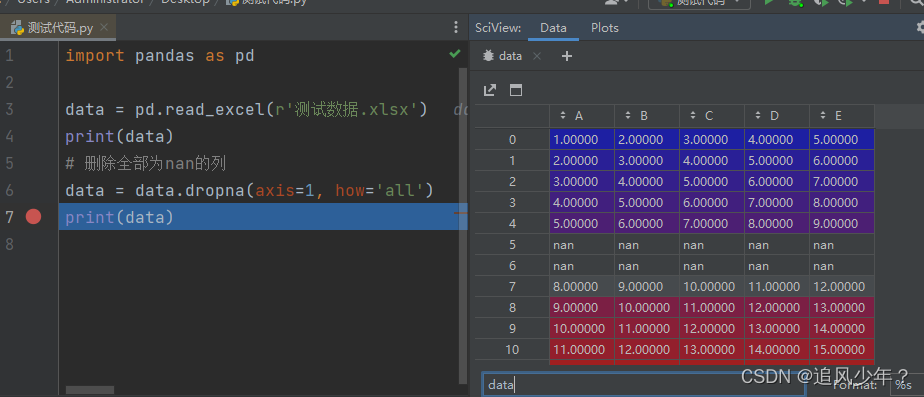
3.删除全部为nan的列
# 删除全部为nan的列
data = data.dropna(axis=1, how='all')数据如下:
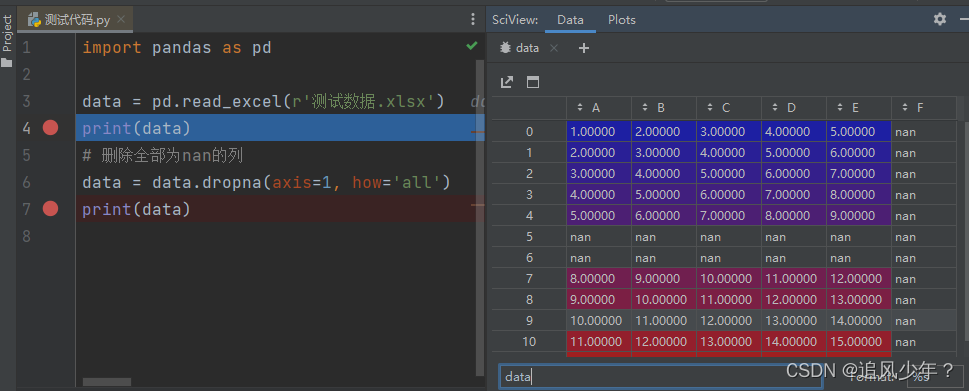
输出:
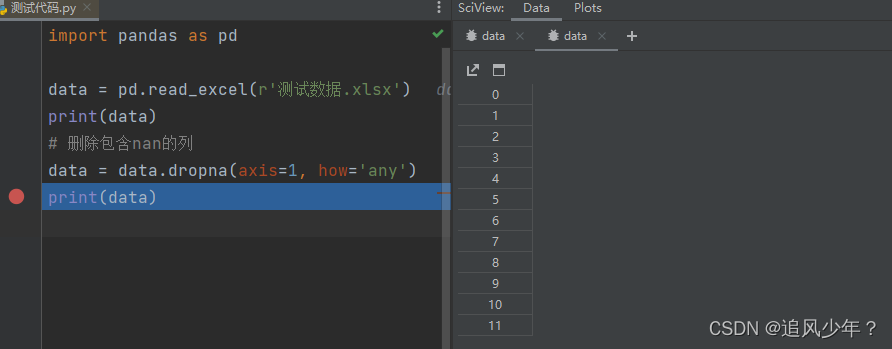
4. 删除包含nan的列
# 删除包含nan的列
data = data.dropna(axis=1, how='any')数据如下
输出:
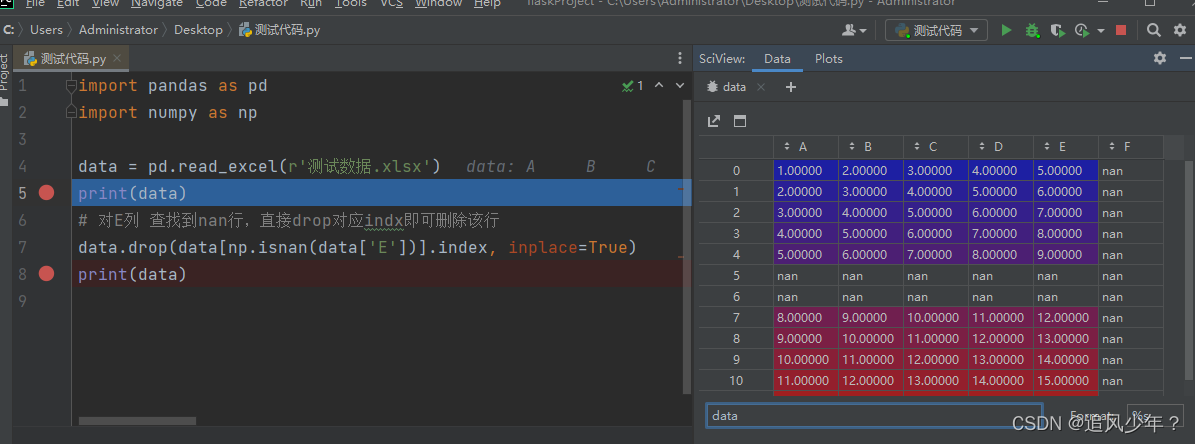
5.删除指定某一列有nan,这样即可定位到所在行的index,然后对该index进行drop操作即可
df[np.isnan(df[‘open’])].index #定位某一列是否有nan
直接drop对应indx即可删除该行
df.drop(df[np.isnan(df[‘open’])].index, inplace=True)
数据如下:
输出: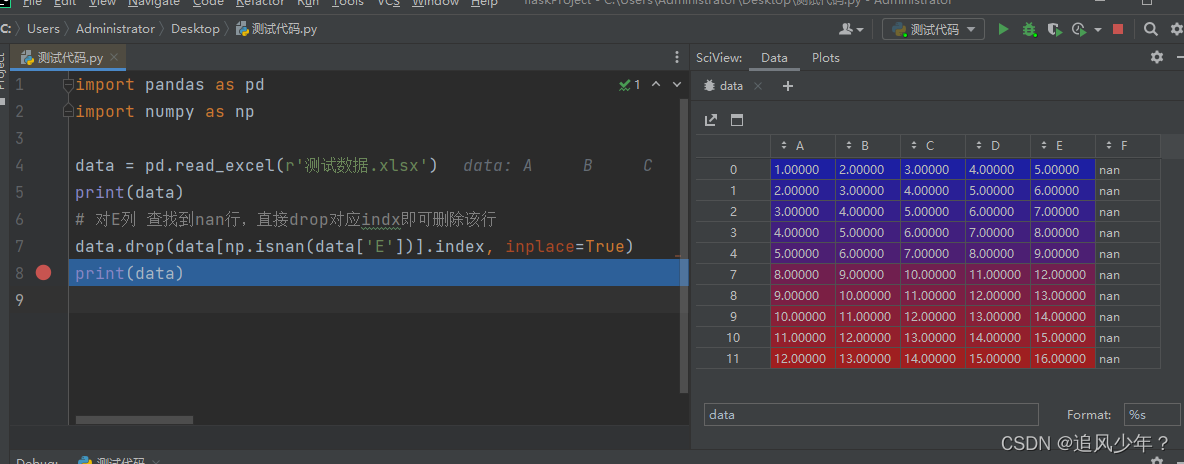
6. df1 = df.dropna(axis=0, how=‘all’, subset=[‘d’, ‘c’]) #删除指定的两列都是空的行
7.筛选出nan的数据
df_nan = df[df['往来单位编号'].isna()]
8.筛选出非nan的数据
df_notnan = df[~df['往来单位编号'].isna()]
9.替换nan值
df.fillna('', inplace=True) # 将nan替换为'',否则无法保存到MySQL
10.有时候是空字符串的情况
nan_df = df[(df['xxx'].str.len() <= 5) | (df['xxx'].isna())]



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










