



 文章介绍了多层感知机如何解决线性不可分问题如XOR,通过加入隐藏层来实现更复杂的函数表示。BP算法作为多层前馈网络的反向传播学习方法,通过梯度下降法调整权重以减小误差。在反向传播中,误差从输出层反向传播到输入层,更新权值以优化网络性能。
文章介绍了多层感知机如何解决线性不可分问题如XOR,通过加入隐藏层来实现更复杂的函数表示。BP算法作为多层前馈网络的反向传播学习方法,通过梯度下降法调整权重以减小误差。在反向传播中,误差从输出层反向传播到输入层,更新权值以优化网络性能。
深度学习2:BP网络
多层感知机
XOR问题
| x1x_1x1 | x2x_2x2 | yyy |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
| 对于以上异或情况,感知机无法进行线性分类,因此引入多层感知机 |
多层感知机
在输入和输出层之间加入一或多层隐单元,构成多层感知器(多层前馈神经网络)
加入一层可解决异或问题
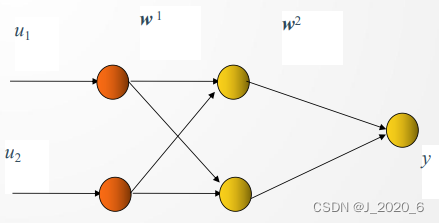
三层感知器可识别任一凸多边形或无界的凸区域。
更多层感知器网络,可识别更为复杂的图形。
多层感知器网络,有如下定理:
定理1 若隐层节点(单元)可任意设置,用三层阈值节点的网络,可以实现任意的二值逻辑函数。
定理2 若隐层节点(单元)可任意设置,用三层S型非线性特性节点的网络,可以一致逼近紧集上的连续函数或按 范数逼近紧集上的平方可积函数
多层前馈网络及BP算法概述
多层前馈网络的反向传播 (BP)学习算法,简称BP算法,是有导师的学习,它是梯度下降法在多层前馈网中的应用。
已知网络的输入/输出样本,即导师信号。
BP学习算法由正向传播和反向传播组成:
- 正向传播是输入信号从输入层经隐层,传向输出层,若输出层得到了期望的输出,
则学习算法结束;否则,转至反向传播。 - 反向传播是将误差(样本输出与网络输出之差)按原联接通路反向计算,由梯度下降法调整各层节点的权值和阈值,使误差减小
BP算法
记号
- 层:上标[l][l][l],共L层,输入为第0层,输出为第LLL层。
- 输出:y^=a[L]=a\hat{y}=a^{\left[ L \right]}=ay^=a[L]=a;输出a[0]=xa^{\left[ 0 \right]}=xa[0]=x。
- lll层输出a[l]=f(z[l])a^{\left[ l \right]}=f\left( z^{\left[ l \right]} \right)a[l]=f(z[l])。
- 权值:第lll层第i个节点和l−1l-1l−1层第j个节点间权值wij[l]w_{ij}^{\left[ l \right]}wij[l]。
基本思想
权值更新采用Δwk=−αdJdw\varDelta w_k=-\alpha \frac{dJ}{dw}Δwk=−αdwdJ
-
若只有一层隐含层:
∂J∂wij[2]=[∂J∂e]T∂e∂wij[2]∂J∂e=e∂e∂wij[2]=[0,⋯ ,∂ei∂wij[2],⋯ ,0]T \frac{\partial J}{\partial w_{ij}^{\left[ 2 \right]}}=\left[ \frac{\partial J}{\partial e} \right] ^T\frac{\partial e}{\partial w_{ij}^{\left[ 2 \right]}} \\ \frac{\partial J}{\partial e}=e \\ \frac{\partial e}{\partial w_{ij}^{\left[ 2 \right]}}=\left[ 0,\cdots ,\frac{\partial e_i}{\partial w_{ij}^{\left[ 2 \right]}},\cdots ,0 \right] ^T ∂wij[2]∂J=[∂e∂J]T∂wij[2]∂e∂e∂J=e∂wij[2]∂e=[0,⋯,∂wij[2]∂ei,⋯,0]T
从而
∂wij[2](k)=−α∂J∂wij[2]=α⋅ai(1−ai)ei⋅aj[1]=α⋅δi[2]⋅aj[1] \partial w_{ij}^{\left[ 2 \right]}\left( k \right) =-\alpha \frac{\partial J}{\partial w_{ij}^{\left[ 2 \right]}}=\alpha \cdot a_i\left( 1-a_i \right) e_i\cdot a_{j}^{\left[ 1 \right]}=\alpha \cdot \delta _{i}^{\left[ 2 \right]}\cdot a_{j}^{\left[ 1 \right]} ∂wij[2](k)=−α∂wij[2]∂J=α⋅ai(1−ai)ei⋅aj[1]=α⋅δi[2]⋅aj[1] -
由1推至多层隐含层有:
若当前是输出层δi[L]=ai(1−ai)ei\delta _{i}^{\left[ L \right]}=a_i\left( 1-a_i \right) e_iδi[L]=ai(1−ai)ei若当前是隐含层δi[l]=[∑j=1mwji[l+1]δj[l+1]](ai[l])′\delta _{i}^{\left[ l \right]}=\left[ \sum_{j=1}^m{w_{ji}^{\left[ l+1 \right]}}\delta _{j}^{\left[ l+1 \right]} \right] \left( a_{i}^{\left[ l \right]} \right) \primeδi[l]=[∑j=1mwji[l+1]δj[l+1]](ai[l])′
更新权值Δwij[l](k)=α⋅δi[l]⋅aj[l−1]\varDelta w_{ij}^{\left[ l \right]}\left( k \right) =\alpha \cdot \delta _{i}^{\left[ l \right]}\cdot a_{j}^{\left[ l-1 \right]}Δwij[l](k)=α⋅δi[l]⋅aj[l−1]


















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










