



1. 引言
随着全球对大模型持续的高度关注,国外的OpenAI、Google以及国内的百度、阿里等都在大模型领域中不断地探索前进。由于模型的参数量和计算量的不断增大,大模型的推理部署成本也“水涨船高”,对模型推理的优化成为研究热点。
基于Transformer Decoder的大(语言)模型在进行推理时,不同于训练过程,推理时我们并不能知道下一个字是什么,只能进行串行的预测,将预测到的下一个词,连同之前的句子,一起作为输入,继续预测下一个词,这样每生成一个token,都需要将所有参数从内存传输到缓存中。也就是说,我们的答案有几个字,模型就要跑几次,而大模型的参数量巨大,这个过程受内存带宽(memory bound)的限制,这就是大模型推理的瓶颈。
当前业内一直在致力于研究大模型推理的优化技术。当前已有的大语言模型推理提速的方式,包括低精度计算、模型量化、适配器微调、模型剪枝、批量推理、多GPU并行和其他推理优化工具等方法,这些方法需要对模型架构、训练过程等做出修改,模型的输出分布也会发生变化,但“投机采样”避免了这些变化,通过引入一个“小模型”辅助解码,使部署的大模型能够进行“并行”解码,从而提高推理速度。
 推理提速
推理提速
2. 投机采样原理
投机采样(Speculative Sampling)引入小模型的关键在于,许多常见的单词和句子是很容易被预测出来的,可以用更简单的模型来近似。在自回归解码中加入投机采样,其原理简单来说就是:使用两个模型,一个是原始目标模型,另一个是比目标模型小得多的近似模型。近似模型用于进行自回归的串行采样,大模型对采样的结果进行评估,决定是否接受近似模型的采样结果,这样大模型只需要处理小模型无法处理的复杂部分,这个方法不需要修改大模型的结构,也不需要重新训练模型,降低推理成本的同时,实现推理提速。
标准的自回归采样算法如下,其实现过程是在while循环中,模型生成下一个元素,并将生成的元素添加到序列中,循环执行直到序列达到目标长度。

投机采样算法,实现过程如下:

在整个推理过程的while循环(多次投机采样)中:
步骤一:小模型进行自回归采样,得到小模型概率p,最终生成小模型预测的初始输出序列X;
步骤二:并行前向传播,将前缀和小模型生成的输出序列X拼接输入大模型进行前向传播,得到大模型的概率q;
步骤三:评估结果,如果p当前索引对应的q索引的概率为1,则接受当前的token,得到最终输出x;如果p当前索引对应的q索引的概率为0,则拒绝当前的字,并取q概率为1的字,得到最终输出x后退出循环和本次的投机采样;
步骤四:返回生成的结果,如果当次投机采样接受了所有初始输出X,则选择q最后一个序列位置概率为1的字,得到最终输出x。重复步骤1,直到结束循环。
“Transformers是如何实现大模型的投机采样的” 这篇文章通过图解的方式讲解了投机编码过程,推荐大家看一下,很清晰!
接下来通过参考文献[2]论文中的一个例子来解释投机采样的过程:
说明:图中的每一行都表示一次迭代,其中,绿色的tokens表示大模型接受小模型给出的结果,红色tokens表示被拒绝的小模型的结果,蓝色tokens表示对被拒绝的tokens进行修正后的结果,每个词或字母下面的下划线表示这是一个完整的token。
在第一次迭代中,小模型生成了五个tokens,分别为“japan”、“'”、“s”、“benchmark”、“bond”,将前缀和小模型生成的5个tokens一起作为输入,进行一次推理,可以看到,最后一个token“bond”被目标模型拒绝,并重新进行采样,生成token “n”;在第二次迭代中,目标模型接受了小模型生成了5个tokens,并拒绝了最后一个token,以此类推,在第九次迭代结束后,生成了完整的句子,共38个tokens。可以看出,投机采样的方式比只用大模型进行自回归采样进行推理要更加高效。
3. 提速效果
论文[2]中使用T5-XXL(11B)作为原始模型,测试了近似模型分别为T5-small(77M)、T5-base(250M)、T5-large(800M),在单个 TPU-v4 上,使用不同抽样方法(argmax 和标准抽样),来评估两个任务,分别为:(1) 在 WMT EnDe 数据集上进行的英语到德语翻译微调;(2) 在 CCN/DM 数据集上进行的文本摘要微调。
测试结果如下表所示:
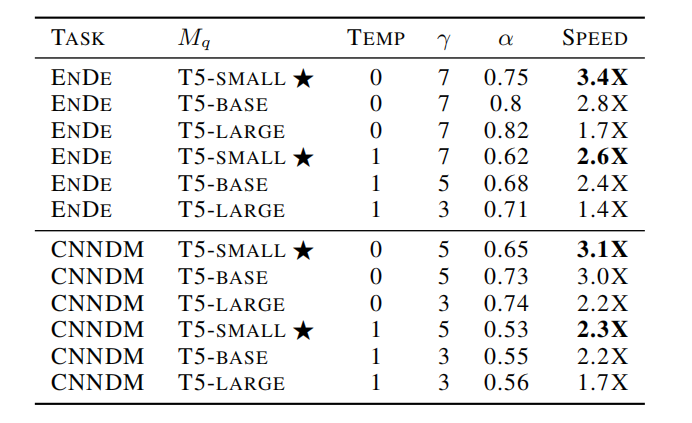
表中,task为任务,Mq为近似模型,temp为抽样方式,γ为小模型一次生成的tokens数,α为衡量目标模型和近似模型的近似程度。可以看出,T5-XXL在不同的近似模型下,有2~3倍的提速效果。
当然,投机采样的推理方式并不适用于所有的应用场景,例如,文学艺术类的诗词等,大小模型生成的tokens差异可能较大,但对于代码生成类问题,投机采样就比较适合。投机采样的推理方式并不是完美的,主要考虑两个方面,首先是小模型的选择,要求与大模型接口统一、概率分布接近,其生成质量也不能比大模型差太多;另一方面就是相比单个模型的部署,两个模型的部署更加复杂。
4. 总结
虽然投机采样的方式有缺陷,但明显优点远大于缺点,它能够实现将大模型直接跑在终端桌面上,不再依赖服务器,大大降低成本预算,根据OpenAI泄露的消息,GPT-4可能也在使用投机采样进行推理加速,这对于成本的节约,无疑是更好的选择。
参考
[1] https://zhuanlan.zhihu.com/p/666452391
[2] https://arxiv.org/pdf/2302.01318.pdf
[3] https://proceedings.mlr.press/v202/leviathan23a/leviathan23a.pdf
[4] 壁仞科技:https://www.birentech.com/Research_nstitute_details/24.html





















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












