



代码:
import re
# 1. 匹配陕西省区号 029-12345
def match_phone(s):
pattern = r'^029-\d+$'
return re.fullmatch(pattern, s) is not None
# 2. 匹配邮政编码 745100
def match_zip(s):
pattern = r'^\d{6}$'
return re.fullmatch(pattern, s) is not None
# 3. 匹配邮箱 lijian@xianoupeng.com
def match_email(s):
pattern = r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$'
return re.fullmatch(pattern, s) is not None
# 4. 匹配身份证号 62282519960504337X
def match_id_card(s):
pattern = r'^\d{17}[\dXx]$'
return re.fullmatch(pattern, s) is not None
if __name__ == "__main__":
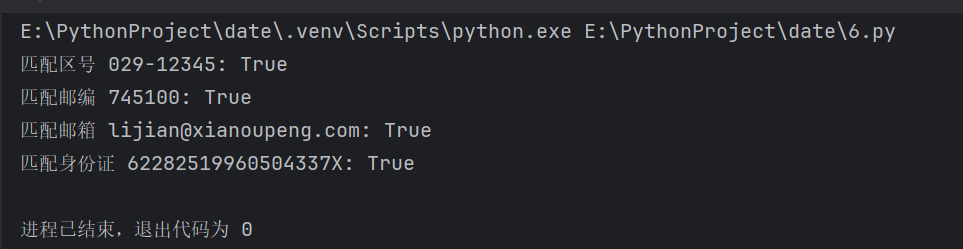
print("匹配区号 029-12345:", match_phone("029-12345"))
print("匹配邮编 745100:", match_zip("745100"))
print("匹配邮箱 lijian@xianoupeng.com:", match_email("lijian@xianoupeng.com"))
print("匹配身份证 62282519960504337X:", match_id_card("62282519960504337X"))
运行结果
代码:
import urllib.request
import re
import functools
import time
# 装饰器:记录函数执行日志
def log_decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] 开始执行函数: {func.__name__}")
print(f"参数: args={args}, kwargs={kwargs}")
try:
result = func(*args, **kwargs)
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] 函数 {func.__name__} 执行成功")
return result
except Exception as e:
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] 函数 {func.__name__} 执行失败: {str(e)}")
raise
return wrapper
@log_decorator
def crawl_school_images(url, output_file="image_paths.txt"):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
try:
req = urllib.request.Request(url, headers=headers)
with urllib.request.urlopen(req) as response:
html = response.read().decode(response.headers.get_content_charset() or 'utf-8')
img_pattern = re.compile(r'<img[^>]*src=["\']([^"\']+)["\'][^>]*>')
img_urls = img_pattern.findall(html)
from urllib.parse import urljoin
full_img_urls = []
for src in img_urls:
if not src.startswith(("http://", "https://")):
src = urljoin(url, src)
full_img_urls.append(src)
#保存到文件
with open(output_file, "w", encoding="utf-8") as f:
for img_url in full_img_urls:
f.write(img_url + "\n")
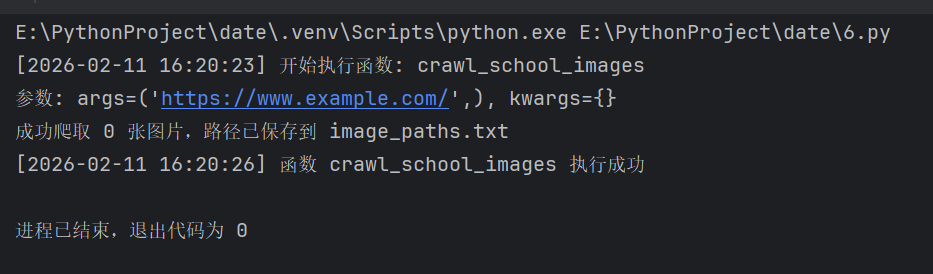
print(f"成功爬取 {len(full_img_urls)} 张图片,路径已保存到 {output_file}")
return full_img_urls
except Exception as e:
print(f"执行失败: {e}")
return []
# 调用
if __name__ == "__main__":
crawl_school_images("https://www.example.com/")
运行结果:
列表


















 259
259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










