




 本文详细介绍了CS231n课程作业中的knn分类器实现,包括计算L2距离的不同方法,如两层循环、单层循环和无循环实现。接着讨论了交叉验证在选择最佳k值中的应用。此外,还涵盖了SVM的损失函数和梯度计算,以及softmax的损失函数实现。最后提到了超参数调优的过程。
本文详细介绍了CS231n课程作业中的knn分类器实现,包括计算L2距离的不同方法,如两层循环、单层循环和无循环实现。接着讨论了交叉验证在选择最佳k值中的应用。此外,还涵盖了SVM的损失函数和梯度计算,以及softmax的损失函数实现。最后提到了超参数调优的过程。
前言 嫌啰嗦直接看源码
请先看课程,作业地址。
有两种做作业的方法,一种是在google Colab上做 (需魔法),另一种就是下载到本地,但是我懒得在本地配置环境,太麻烦了,还得修改一些基础代码,我就直接在google colab上做了
google colab 配置环境只需要跟着教程走就好了
作业一内容

同时配置colab环境的教程也在这个页面https://cs231n.github.io/assignments2023/assignment1/#setup
Q1 knn分类器
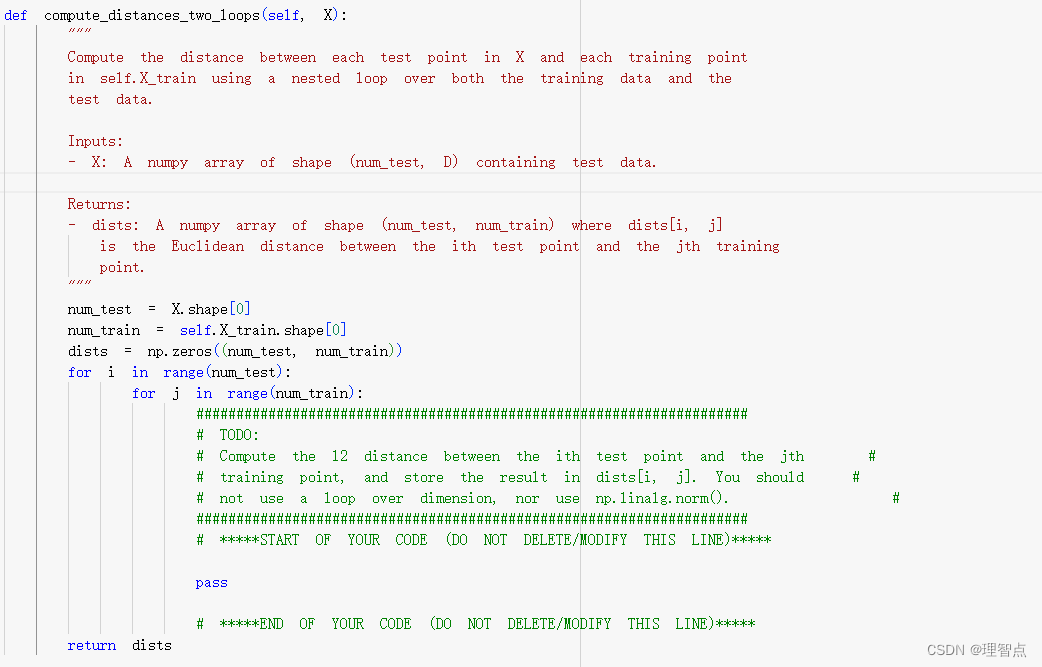
compute_distance_two_loops
题面
解析
打开文件可以看到这里
让我们计算X_test 和 X_train之间图像之间的l2距离,第i个X_test的图像和第J个X_train的图像的距离存放在dists[i,j]中
L1距离和L2距离的解释
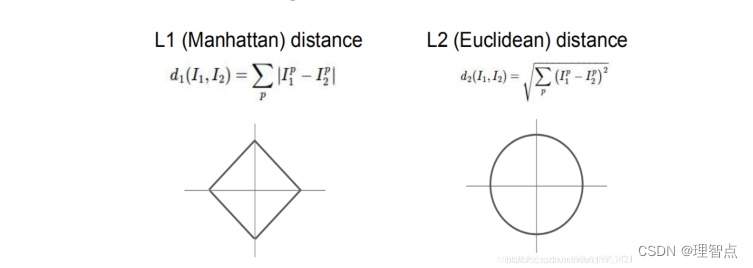
有了上面那个公式,我们实现起来就很简单了
用np.sqrt(np.sum(np.power()))的方法就好了,这个主要是考察对np的几个库函数的熟悉程度
但是因为这个方法的时间复杂的大概是50005003072,所以我跑了大概五分钟!!
代码
def compute_distances_two_loops(self, X):
"""
Compute the distance between each test point in X and each training point
in self.X_train using a nested loop over both the training data and the
test data.
Inputs:
- X: A numpy array of shape (num_test, D) containing test data.
Returns:
- dists: A numpy array of shape (num_test, num_train) where dists[i, j]
is the Euclidean distance between the ith test point and the jth training
point.
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
for j in range(num_train):
#####################################################################
# TODO: #
# Compute the l2 distance between the ith test point and the jth #
# training point, and store the result in dists[i, j]. You should #
# not use a loop over dimension, nor use np.linalg.norm(). #
#####################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
dists[i,j] = np.sqrt(np.sum(np.power(X[i] - self.X_train[j],2)))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return dists
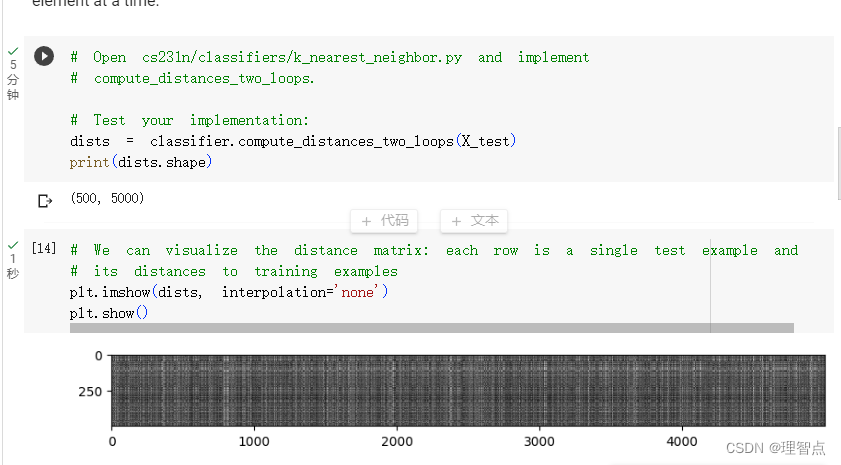
输出
Inline Question 1
题面

请注意距离矩阵中的结构化图案,其中一些行或列明显更亮。(请注意,在默认配色方案中,黑色表示低距离,而白色表示高距离。)
解答
-
是什么导致了一行中的数据明亮
从图像中我们可以看到这个图像是500 * 5000的一个图像,对于第 i 行而言,就等于第 i 个测试图像,与所有训练图像的L2距离,而明亮就说明他的L2距离比较大,也就是偏差比较大
-
是什么导致了一列中的数据明亮
同上,只不是这次是对于第 j 个训练数据而言,与500个测试数据的L2距离比较大
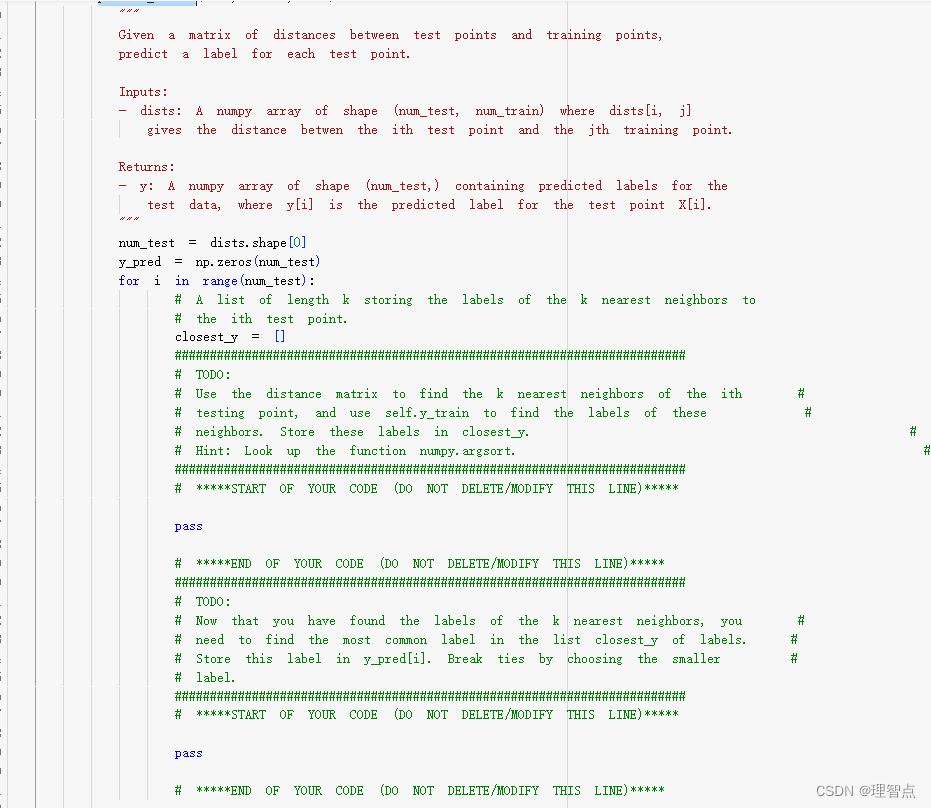
predict_labels
题面
解析
让我们用上一个函数求得的dist来算出对于每一个测试数据而言,L2距离最小的训练数据对应的标签
并且题目中已经给了我们提示,让我们使用numpy.argsort来实现
- numpy.argsort() 函数用于使用关键字kind指定的算法沿给定轴执行间接排序。 它返回一个与 arr 形状相同的索引数组,用于对数组进行排序,按升序排列
- 函数原型
numpy.argsort(arr, axis=-1, kind=’quicksort’, order=None)
- 参数
- arr:[array_like],输入数组
- axis:[int or None],排序的轴, 如果没有,数组在排序前被展平。 默认值为 -1,即沿最后一个轴排序。
- kind:[‘quicksort’, ‘mergesort’, ‘heapsort’],选择算法, 默认为“快速排序”。
- order : [str or list of str] ,当 arr 是一个定义了字段的数组时,这个参数指定首先比较哪些字段,第二个等等。
- return: [index_array, ndarray] ,沿指定轴对 arr 排序的索引数组。如果 arr 是一维的,则 arr[index_array] 返回排序后的 arr。
实例代码
# get two largest value from numpy array
x=np.array([12,43,2,100,54,5,68])
print(x)
# using argsort get indices of value of arranged in ascending order
print(np.argsort(x))
#get two highest value index of array
print(np.argsort(x)[-2:])
# to arrange in ascending order of index
print(np.argsort(x)[-2:][::-1])
# to get highest 2 values from array
x[np.argsort(x)[-2:][::-1]]
输出
[ 12 43 2 100 54 5 68]
[2 5 0 1 4 6 3]
[6 3]
[3 6]
[100 68]
因此我们只要用一行代码就可以实现获取目标的下标
closest_y = self.y_train[np.argsort(dists[i])[:k]]
# np.argsort(dists[i])[:k] 就是最小的k个值的下标
# 这样子代码是已经获取到了最小的k个值对应的label了
之后让我们取出最为普遍的标签,也就是出现的最多的标签
接下来我们只需要使用np.bincount 和 np.argmax两个函数
np.bincount() 是一个用于计算整数数组中每个值出现次数的函数。它返回一个数组,其长度等于a中元素最大值加1,每个元素值则是它当前索引值在a中出现的次数。下面是一些示例代码和输出:
import numpy as np
a = np.array([0, 1, 2, 3, 2, 1, 5])
print(np.bincount(a)) # [1 2 2 1 0 1]
b = np.array([0,0,1,2,2])
print(np.bincount(b)) # [2 1 2]
np.argmax() 是一个用于返回数组中最大值的索引的函数。下面是一些示例代码和输出:
import numpy as np
a = np.array([1, 2, 3, 2, 1])
print(np.argmax(a)) # 2
b = np.array([5, 7, 3, 2], [8, 6, 4, 9])
print(np.argmax(b)) # 7
其实如果严谨的来说的话不应该用np.bincount的,因为如果k=3,但是我们选出来的前3个标签各不相同,那么应该选择最小的那个标签,但是使用Bincount的话无法保证这个情况,不过我懒得写复杂的方法了,而且对于分类算法而言,这点误差可以忽略不计,因为出现上面这种情况的话,就是分类效果不好 ^_^
代码
def predict_labels(self, dists, k=1):
"""
Given a matrix of distances between test points and training points,
predict a label for each test point.
Inputs:
- dists: A numpy array of shape (num_test, num_train) where dists[i, j]
gives the distance betwen the ith test point and the jth training point.
Returns:
- y: A numpy array of shape (num_test,) containing predicted labels for the
test data, where y[i] is the predicted label for the test point X[i].
"""
num_test = dists.shape[0]
y_pred = np.zeros(num_test)
for i in range(num_test):
# A list of length k storing the labels of the k nearest neighbors to
# the ith test point.
closest_y = []
#########################################################################
# TODO: #
# Use the distance matrix to find the k nearest neighbors of the ith #
# testing point, and use self.y_train to find the labels of these #
# neighbors. Store these labels in closest_y. #
# Hint: Look up the function numpy.argsort. #
#########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
closest_y = self.y_train[np.argsort(dists[i])[:k]]
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
#########################################################################
# TODO: #
# Now that you have found the labels of the k nearest neighbors, you #
# need to find the most common label in the list closest_y of labels. #
# Store this label in y_pred[i]. Break ties by choosing the smaller #
# label. #
#########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
y_pred[i] = np.argmax(np.bincount(closest_y))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return y_pred
结果
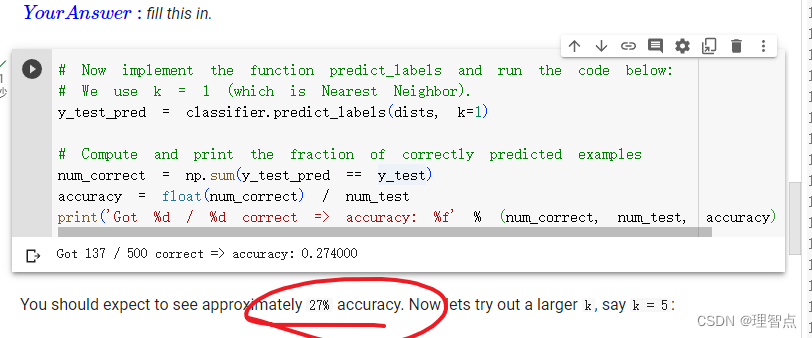
跟要求的也差不多,27%
Inline Question 2
题面

就是说
以下哪一个预处理步骤不会改变使用L1距离的最近邻分类器的性能?选择所有适用的选项。为了澄清,训练和测试示例都以相同的方式进行了预处理。
- 减去平均值μ(p~(k)ij=p(k)ij-μ。)
- 减去每像素平均值μij(p~(k)ij=p(k)ij-μij.)
- 减去平均值μ,除以标准偏差σ。
- 减去像素平均值μij,除以像素标准偏差σij。
- 旋转数据的坐标轴,这意味着将所有图像旋转相同的角度。图像中由旋转引起的空区域用相同的像素值填充,并且不执行插值。
解答
这个问题恕鄙人不才,因为我也不是特别理解这段,我一开始觉得答案是1、2、3、4,但是网上的答案五花八门(可恶啊不是斯坦福的学生不能享受人家的解答),后来我找到一个比较官方的解答,我直接把他的回答粘贴过来了(英文的,我就不翻译了,怕产生歧义)























 3337
3337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












