



不少企业的AI采购流程是这样的:IT部门调研大模型,选一家供应商,签合同,部署,然后发现用不起来。
问题出在哪?大模型能力没问题,回答通用问题很溜。但一问企业自己的业务,它就开始胡说八道。你问它公司去年的质量事故报告在哪,它不知道。你问它某个产品的技术参数,它编一个。你问它项目交付流程第三步该做什么,它拿通用模板糊弄你。
大模型不知道你公司的事,因为你的知识没有喂给它。
这就是知识库的价值。它不是文档管理系统换个名字。它是企业大模型应用的"知识供给线"。
鸿翼OpenContent™智能知识库的做法是用RAG技术挂接企业知识库与大模型。RAG是Retrieval-Augmented Generation,检索增强生成。原理不复杂:用户提问后,系统先在知识库里检索相关内容,把检索到的内容连同问题一起发给大模型,大模型基于这些内容生成回答。模型不靠自己的记忆编,而是根据你给的材料答。
这个机制解决了一个核心矛盾:大模型是通用的,企业知识是私有的。你不可能把公司所有文档塞进模型训练集里,成本太高,更新太慢。RAG让你不用重新训练模型,只需要把知识库准备好,模型随用随调。
但"把知识库准备好"这六个字,比想象中难得多。
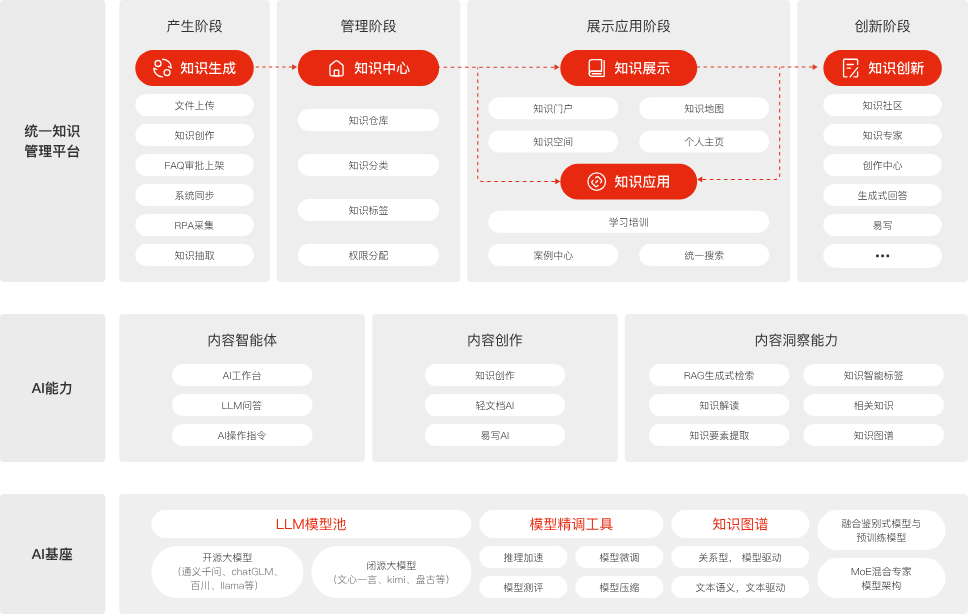
鸿翼把知识库建设拆成了四个环节:知识采集生成、知识资产管理、知识组装展示、知识应用创新。每个环节都有具体的功能支撑。
采集环节,提供在线编写、文档上传、海量API配置化采集、基于流程的知识上架。企业的知识来源五花八门,有的在OA系统里,有的在个人电脑里,有的在工程师脑子里。采集环节要做的就是把它们统一入库。
资产管理环节,构建知识中心、知识库、知识标签、知识阅读。卡片式展示方便查找,目录结构清晰,标签体系精准分类,阅读体验做到书本级。知识进来之后得有地方放、有方法找。
组装展示环节,提供知识门户、知识搜索、知识地图、学习中心。低代码平台构建个性化入口,多种搜索手段覆盖不同查找场景,知识地图用图形化方式呈现知识脉络,学习中心把知识打包成课程用于培训。
应用创新环节,建设知识社区、专家库、案例中心、创作中心。让知识在交流中增值,让专家被发现,让案例被萃取,让创作有工具支撑。
四个环节跑通之后,知识库才具备喂给大模型的条件。RAG检索的准确率,直接取决于知识库里内容的质量和结构化程度。垃圾进,垃圾出。知识库做不好,大模型的表现就好不了。
鸿翼还提供了私有化部署选项。内部私有化部署语言模型,企业数据不出域。自研InWise平台和易慧大模型,接入和微调过程全程可控。对于国央企这类对数据安全要求极高的客户,私有化是硬需求。
买大模型只是第一步。知识库才是企业AI落地真正要啃的硬骨头。


















 209
209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










