



Gartner的研究指出,组织中70%到90%的数据是非结构化的。
这个数字意味着什么?你公司花大价钱建的数据仓库、BI系统、ERP系统,管的是剩下那10%到30%的数据。大部分知识藏在文档、图纸、邮件、聊天记录、扫描件里,没有进入任何管理系统。
它们在沉睡。
传统的文档管理系统解决了一个问题:文件有地方放了,不会丢了。但它没有解决另一个问题:这些文件里的知识,能用吗?
一份工程图纸,存进系统之后,你能搜索到它的文件名,能按目录找到它,能在线打开看。但你想知道图纸里画了什么、涉及哪些技术参数、跟哪些其他图纸有关联,系统答不上来。文件被存了,知识还在睡。
鸿翼OpenContent™智能知识库要做的事,就是把这些沉睡的知识叫醒。
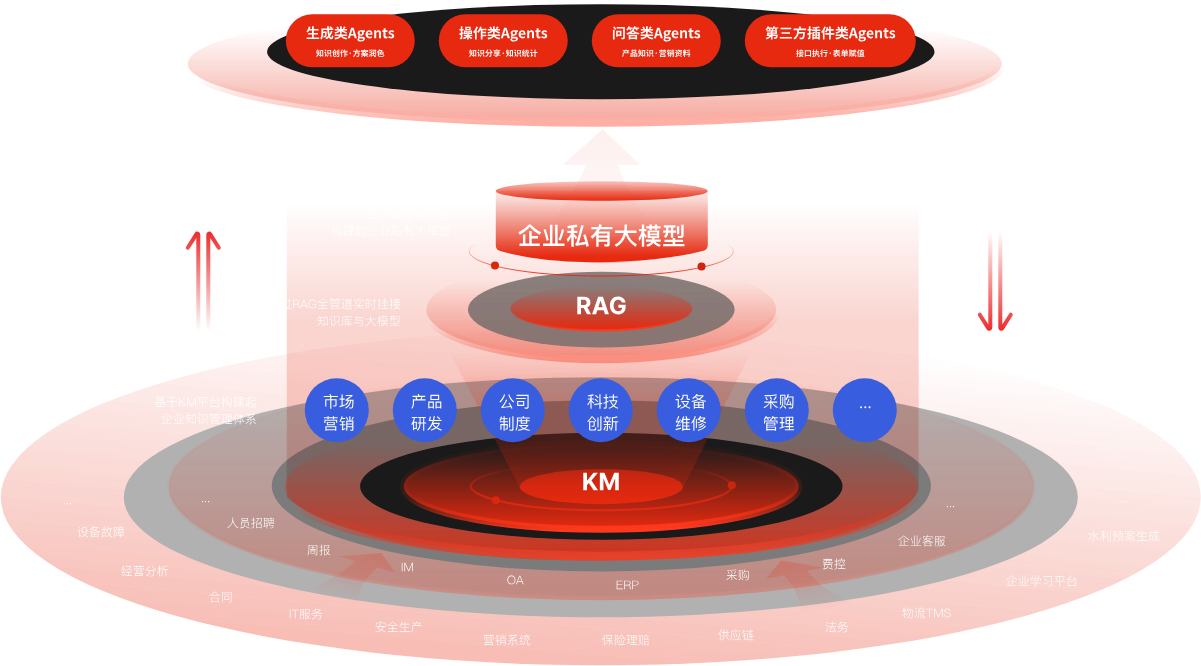
叫醒的第一步是结构化。鸿翼的多模态数据智能解析引擎能跨模态提取信息。文档、音视频、图像,统统可以解析。图纸里的尺寸标注能被识别,合同里的条款能被提取,视频里的关键画面能被抽帧。万物皆可结构化,这是鸿翼的提法。结构化之后,非结构化内容变成机器可理解的语义单元。
第二步是关联。基于内容向量,系统自动生成知识之间的关联关系。一份技术文档引用了某项标准,系统会建立关联。一份案例涉及某个产品,系统会建立关联。基于统一KG Schema,系统从文档内容中智能抽取节点和边信息,生成知识图谱。企业从"文件集合"走向"知识网络"。
第三步是检索。传统的文件搜索靠文件名和关键词,命中率低。知识库的检索基于语义理解。你问"去年那个质量事故怎么处理的",系统能找到相关的分析报告、处理方案、复盘记录,哪怕这些文档的标题里没有"质量事故"这四个字。
第四步是应用。知识被结构化、被关联、可检索之后,应用场景就打开了。智能问答让员工用对话方式获取知识。摘要总结帮人快速理解长文档。智能标签自动分类,降低运营成本。相似推荐发现关联知识。知识图谱让用户在可视化网络中探索发现。
某能源集团的实践给出了量化结果:通过鸿翼构建统一非结构化数据平台,整合35个业务系统数据,管理超10亿份文件,存储成本降低40%,检索效率提升10倍。
10倍检索效率提升的背后,是90%沉睡数据被叫醒后的价值释放。
知识管理这件事喊了很多年,大部分企业的知识库建了又废、废了又建,核心原因就是停在"存文件"这个层面。文件存了,知识没醒。AI时代的知识管理,必须让文件里的知识变得可理解、可关联、可检索、可应用。做不到这四点,知识库就是一个更大的文件废墟。


















 209
209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










