



题目:今年暑假不 AC
问题描述
“今年暑假不 AC?”
“是的。”
“那你干什么呢?”
“看世界杯呀,笨蛋!”
“@#$%^&*%...”
确实如此,世界杯来了,球迷的节日也来了,估计很多 ACMer 也会抛开电脑,奔向电视了。
作为球迷,一定想看尽量多的完整的比赛,当然,作为新时代的好青年,你一定还会看一些其它的节目,比如新闻联播(永远不要忘记关心国家大事)、非常 6+7、超级女生,以及王小丫的《开心辞典》等等。假设你已经知道了所有你喜欢看的电视节目的转播时间表,你会合理安排吗?(目标是能看尽量多的完整节目)
输入
输入数据包含多个测试实例,每个测试实例的第一行只有一个整数 n(n≤100),表示你喜欢看的节目的总数;然后是 n 行数据,每行包括两个正整数 Ti_s、Ti_e(1≤i≤n),分别表示第 i 个节目的开始和结束时间。n=0 表示输入结束,不做处理。
输出
对于每个测试实例,输出能完整看到的电视节目的个数,每个测试实例的输出占一行。
输入示例:
12
1 3
3 4
0 7
3 8
15 19
15 20
10 15
8 18
6 12
5 10
4 14
2 9
输出:
5
学习目标:熟悉结构体数组的使用与冒泡排序。
思路:题目中既然说需要按照时间安排,给出的输入又这么混乱,那么肯定离不开排序。
讲解:我们还是先把这些数据写下来,然后去思考要怎么处理这些数据。

这些数据一眼看上去,杂乱无章。不过根据题意,我们是要按照时间排,既然是时间嘛,肯定要有一个顺序,毫无疑问我们要对这些数据进行排列。
我们先定义一个结构体数组来存储这些数。
struct Ti
{
int s;
int e;
}g[100];
那么现在问题来了,我们要怎么排序呢?排Ti_s?还是排Ti_e?
其实这一题排Ti_s和排Ti_e都能解决问题。不过本题的经典解法是对Ti_e进行排序。
排序的方式有很多,本题要求我们学会练习使用冒泡排序。冒泡排序的原理我会专门出文章进行讲解。
排序就要设计交换嘛,我们先来敲一个交换函数Swap:
void Swap(int *a,int *b)
{
int tmp;
tmp =*a;
*a = *b;
*b = tmp;
}
下面我们来敲一个冒泡排序的函数:
void BubbleSort(int n)
{
for(int i=1;i<n-1;i++) //定义i=1,因为要和i-1相比较,不能从0开始
{
for(int j=1;j<n-1;j++)
{
if(g[j].e<g[j-1].e)//如果e相同就比较s
{
Swap(&g[j].e,&g[j-1].e);
Swap(&g[j].s,&g[j-1].s);//保证信息一一对应
}
}
}
}
冒泡排序敲完了,我们可以正式进入解题阶段了。我们先写出排序后的结果,观察一下有没有思路。

我们已经按照结束时间排序好了,其实到这里思路已经比较明确了。
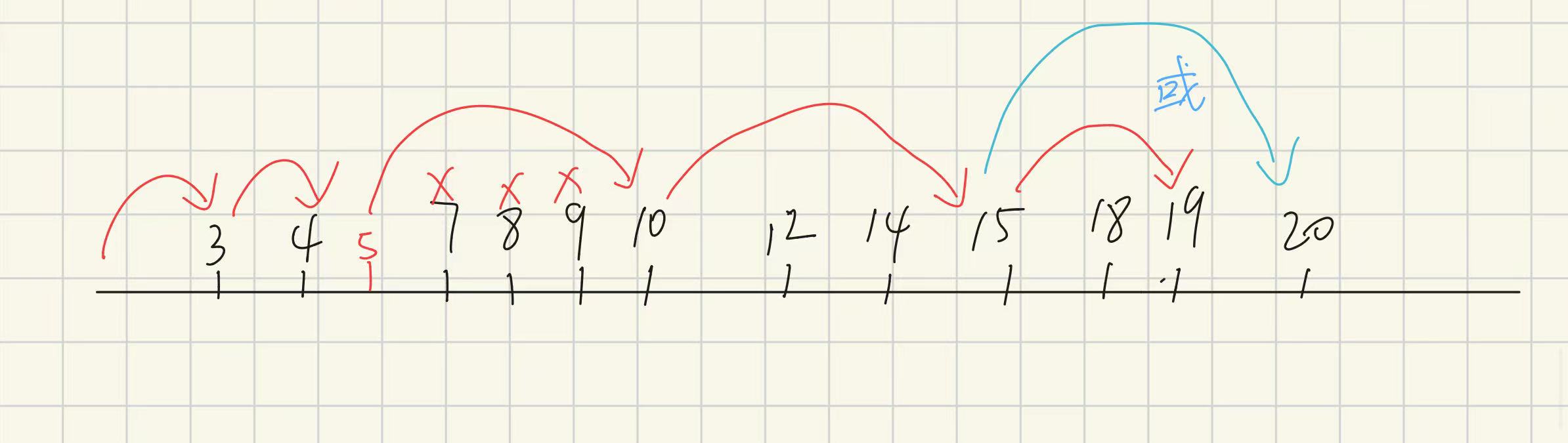
1.越早结束的越好。(也是我们排序的目的之一)
(从15不管是到19还是20都一样,因为它们都不能继续往后走了。但是根据我们越早结束越好的原则应该是走到19结束,同样也是我们从3走到4而不是8的原因)
2.结束时间对应的起始时间必须要在上一个结束时间之后。
然后我们可以一一实现我们的想法。首先是越早结束越好,我们在排序的过程中其实已经实现了最早结束的在前面,我们只需要在保证2的前提下遍历结构体数组并统计符合条件的数量即可。(n是节目总数)。
int begin_time=0,ans=0;
BubbleSort(n);//排序输入的结构体数组
for(int i=0;i<n;i++)
{
if(g[i].s>=begin_time)
{
ans+=1;
begin_time=g[i].e
}
}
然后我们就可以得到本题的答案ans了。
最终代码:
#include<iostream>
using namespace std;
struct Ti
{
int s;
int e;
}g[100];
void Swap(int* a, int* b)
{
int tmp;
tmp = *a;
*a = *b;
*b = tmp;
}
void BubbleSort(int n)
{
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
if (g[j].e < g[j - 1].e)
{
Swap(&g[j].e, &g[j - 1].e);
Swap(&g[j].s, &g[j - 1].s);//保证信息一一对应
}
}
}
}
int main()
{
int n;
cin >> n;
while (cin >> n)
{
if (n == 0) break;
for (int i = 0; i < n; i++)
{
cin >> g[i].s >> g[i].e;
}
for (int i = 0; i < n; i++)
{
cin >> g[i].s >> g[i].e;
}
int begin_time = 0, ans = 0;
BubbleSort(n);
for (int i = 0; i < n; i++)
{
if (g[i].s >= begin_time)
{
ans += 1;
begin_time = g[i].e;
}
}
cout << ans;
}
return 0;
}
这..就完了??
我们不妨再来看看更简单的排序代码:
bool cmp(const Ti& a,const Ti& b)
{
return a.e<b.e;
}
这里定义了一个cmp比较函数,类型为bool,也就是返回True或False。
参数部分定义了Ti类型的两个变量a 和 b,Ti后面加上一个&表示的是“引用传递”而非“值传递”防止函数调用时对Ti对象的拷贝(一般的值传递就是拷贝一份相同的值嘛),尤其是在数据量极大的时候直接引用而非拷贝能显著提升效率。
const是一种安全机制,可以防止在函数调用时不会意外修改原始对象。(对于C++学习不深的我就了解即可啦哈哈哈)
然后我们还需要用到sort函数,这个函数在C++的algorithm库中.
#include<algorithm>
sort(g,g+n,cmp)
这里sort的用法是sort(起始迭代器,终止迭代器,比较规则)。因为我们比较的g到g+n是我们自定义的Ti类型,因此需要一个自定义一个布尔类型的cmp函数告诉sort比较规则,如果cmp返回True,那么cmp不进行交换,反之则交换正在比较的两个数。
最终代码:
#include<iostream>
#include<algorithm>
using namespace std;
struct Ti
{
int s;
int e;
}g[100];
bool cmp(const Ti& a, const Ti& b)
{
return a.e < b.e;
}
int main()
{
int n;
while (cin >> n)
{
if (n == 0) break;
for (int i = 0; i < n; i++)
{
cin >> g[i].s >> g[i].e;
}
int begin_time = 0, ans = 0;
sort(g, g + n, cmp);
for (int i = 0; i < n; i++)
{
if (g[i].s >= begin_time)
{
ans += 1;
begin_time = g[i].e;
}
}
cout << ans << endl;
}
return 0;
}

















&spm=1001.2101.3001.5002&articleId=151863532&d=1&t=3&u=4f35c1cb687f44a38267566f44a2bd8b)
 1687
1687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










