




本文是对VSI技术的代码讲解,原文解读请看VSI文章讲解,代码参考IQA-pytorch。
1、原文概要
VSI借助视觉显著特征、梯度特征以及颜色特征实现了一个IQA方案。整体流程如下所示。
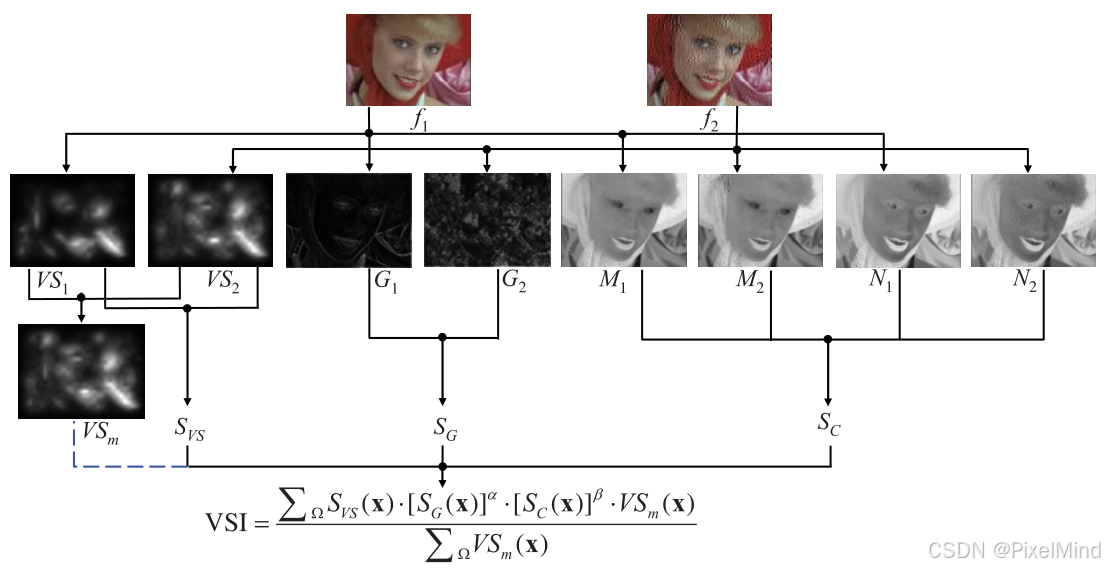
视觉显著图(VS map)对常见退化比较有效,但显著图对于对比度失真和颜色失真的评估不佳,为了解决这个问题,额外引入了梯度特征GM和颜色特征。
2、代码结构
代码整体结构如下:
代码实现位于pyiqa/archs/vsi_arch.py中。
3 、核心代码模块
vsi_arch.py 文件
1. VSI类
这里是VSI类的定义,传入参数比较多,跟计算显著图、梯度、颜色特征相似度相关。
class VSI(nn.Module):
def __init__(
self,
c1: float = 1.27,
c2: float = 386.0,
c3: float = 130.0,
alpha: float = 0.4,
beta: float = 0.02,
data_range: Union[int, float] = 1.0,
omega_0: float = 0.021,
sigma_f: float = 1.34,
sigma_d: float = 145.0,
sigma_c: float = 0.001,
) -> None:
super().__init__()
self.data_range = data_range
self.vsi = functools.partial(
vsi,
c1=c1,
c2=c2,
c3=c3,
alpha=alpha,
beta=beta,
omega_0=omega_0,
sigma_f=sigma_f,
sigma_d=sigma_d,
sigma_c=sigma_c,
data_range=data_range,
)
def forward(self, x, y):
return self.vsi(x=x, y=y)
2. vsi函数
vsi实际计算的过程。
def vsi(
x: torch.Tensor,
y: torch.Tensor,
data_range: Union[int, float] = 1.0,
c1: float = 1.27,
c2: float = 386.0,
c3: float = 130.0,
alpha: float = 0.4,
beta: float = 0.02,
omega_0: float = 0.021,
sigma_f: float = 1.34,
sigma_d: float = 145.0,
sigma_c: float = 0.001,
) -> torch.Tensor:
x, y = x.double(), y.double()
if x.size(1) == 1:
x = x.repeat(1, 3, 1, 1)
y = y.repeat(1, 3, 1, 1)
# Scale to [0, 255] range to match scale of constant
x = x * 255.0 / data_range
y = y * 255.0 / data_range
vs_x = sdsp(
x,
data_range=255,
omega_0=omega_0,
sigma_f=sigma_f,
sigma_d=sigma_d,
sigma_c=sigma_c,
)
vs_y = sdsp(
y,
data_range=255,
omega_0=omega_0,
sigma_f=sigma_f,
sigma_d=sigma_d,
sigma_c=sigma_c,
)
# Convert to LMN colour space
x_lmn = rgb2lmn(x)
y_lmn = rgb2lmn(y)
# Averaging image if the size is large enough
kernel_size = max(1, round(min(vs_x.size()[-2:]) / 256))
padding = kernel_size // 2
if padding:
upper_pad = padding
bottom_pad = (kernel_size - 1) // 2
pad_to_use = [upper_pad, bottom_pad, upper_pad, bottom_pad]
mode = 'replicate'
vs_x = pad(vs_x, pad=pad_to_use, mode=mode)
vs_y = pad(vs_y, pad=pad_to_use, mode=mode)
x_lmn = pad(x_lmn, pad=pad_to_use, mode=mode)
y_lmn = pad(y_lmn, pad=pad_to_use, mode=mode)
vs_x = avg_pool2d(vs_x, kernel_size=kernel_size)
vs_y = avg_pool2d(vs_y, kernel_size=kernel_size)
x_lmn = avg_pool2d(x_lmn, kernel_size=kernel_size)
y_lmn = avg_pool2d(y_lmn, kernel_size=kernel_size)
# Calculate gradient map
kernels = torch.stack([scharr_filter(), scharr_filter().transpose(1, 2)]).to(x_lmn)
gm_x = gradient_map(x_lmn[:, :1], kernels)
gm_y = gradient_map(y_lmn[:, :1], kernels)
# Calculate all similarity maps
s_vs = similarity_map(vs_x, vs_y, c1)
s_gm = similarity_map(gm_x, gm_y, c2)
s_m = similarity_map(x_lmn[:, 1:2], y_lmn[:, 1:2], c3)
s_n = similarity_map(x_lmn[:, 2:], y_lmn[:, 2:], c3)
s_c = s_m * s_n
s_c_complex = [s_c.abs(), torch.atan2(torch.zeros_like(s_c), s_c)]
s_c_complex_pow = [s_c_complex[0] ** beta, s_c_complex[1] * beta]
s_c_real_pow = s_c_complex_pow[0] * torch.cos(s_c_complex_pow[1])
s = s_vs * s_gm.pow(alpha) * s_c_real_pow
vs_max = torch.max(vs_x, vs_y)
eps = torch.finfo(vs_max.dtype).eps
output = s * vs_max
output = (
(output.sum(dim=(-1, -2)) + eps) / (vs_max.sum(dim=(-1, -2)) + eps)
).squeeze(-1)
return output
计算过程中,首先会利用sdsp方法计算比较图像的VS图得到vs_x和vs_y,然后利用rgb2lmn转换2幅比较图像得到x_lmn和y_lmn,转换后取出其中的l通道计算梯度图作为梯度相关特征存在,mn通道作为颜色特征存在,各项特征计算相似度,最后进行合并得到VSI结果。
3. sdsp函数
视觉显著图计算过程。
def sdsp(
x: torch.Tensor,
data_range: Union[int, float] = 255,
omega_0: float = 0.021,
sigma_f: float = 1.34,
sigma_d: float = 145.0,
sigma_c: float = 0.001,
) -> torch.Tensor:
x = x / data_range * 255
size = x.size()
size_to_use = (256, 256)
x = interpolate(input=x, size=size_to_use, mode='bilinear', align_corners=False)
x_lab = rgb2lab(x, data_range=255)
lg = _log_gabor(size_to_use, omega_0, sigma_f).to(x).view(1, 1, *size_to_use)
# torch version >= '1.8.0'
x_fft = torch.fft.fft2(x_lab)
x_ifft_real = torch.fft.ifft2(x_fft * lg).real
s_f = safe_sqrt(x_ifft_real.pow(2).sum(dim=1, keepdim=True))
coordinates = torch.stack(get_meshgrid(size_to_use), dim=0).to(x)
coordinates = coordinates * size_to_use[0] + 1
s_d = torch.exp(-torch.sum(coordinates**2, dim=0) / sigma_d**2).view(
1, 1, *size_to_use
)
eps = torch.finfo(x_lab.dtype).eps
min_x = x_lab.min(dim=-1, keepdim=True).values.min(dim=-2, keepdim=True).values
max_x = x_lab.max(dim=-1, keepdim=True).values.max(dim=-2, keepdim=True).values
normalized = (x_lab - min_x) / (max_x - min_x + eps)
norm = normalized[:, 1:].pow(2).sum(dim=1, keepdim=True)
s_c = 1 - torch.exp(-norm / sigma_c**2)
vs_m = s_f * s_d * s_c
vs_m = interpolate(vs_m, size[-2:], mode='bilinear', align_corners=True)
min_vs_m = vs_m.min(dim=-1, keepdim=True).values.min(dim=-2, keepdim=True).values
max_vs_m = vs_m.max(dim=-1, keepdim=True).values.max(dim=-2, keepdim=True).values
return (vs_m - min_vs_m) / (max_vs_m - min_vs_m + eps)
sdsp首先将图像转换到lab空间,Lab(又称CIELAB)是国际照明委员会(CIE)于1976年提出的基于人眼视觉感知的色彩模型,它有几个关键特性:
1)均匀性:ΔE=1时人眼可感知色差(优于RGB的非线性感知)ΔE = √(ΔL² + Δa² + Δb²) 越大色差越大。
2)宽色域:可表示比RGB更广的颜色范围(包含部分CMYK色域)
3)与光照解耦:L通道独立于颜色信息,适合光照变化场景。
然后使用log_gabor滤波器对图像进行处理,Log-Gabor滤波器是计算机视觉和图像处理中常用的频域滤波器,相比传统Gabor滤波器具有以下优势:无直流分量干扰;高频带更宽,适合多尺度分析;对数频率响应更符合生物视觉特性。简单来说是提取边缘和纹理特征的,例如提取指纹、织物等周期性结构的特征,提取不同粗细的边缘。最后结合坐标和图像对特征进行加权,得到VS的最终结果。
4. gradient_map函数
实际只是一个卷积的过程。
def gradient_map(x: torch.Tensor, kernels: torch.Tensor) -> torch.Tensor:
r"""Compute gradient map for a given tensor and stack of kernels.
Args:
x: Tensor with shape (N, C, H, W).
kernels: Stack of tensors for gradient computation with shape (k_N, k_H, k_W)
Returns:
Gradients of x per-channel with shape (N, C, H, W)
"""
padding = kernels.size(-1) // 2
grads = torch.nn.functional.conv2d(x, kernels.to(x), padding=padding)
return safe_sqrt(torch.sum(grads**2, dim=-3, keepdim=True))
使用到的kernel是:
# Gradient operator kernels
def scharr_filter() -> torch.Tensor:
r"""Utility function that returns a normalized 3x3 Scharr kernel in X direction
Returns:
kernel: Tensor with shape (1, 3, 3)
"""
return torch.tensor([[[-3.0, 0.0, 3.0], [-10.0, 0.0, 10.0], [-3.0, 0.0, 3.0]]]) / 16
kernels = torch.stack([scharr_filter(), scharr_filter().transpose(1, 2)]).to(x_lmn)
这跟我们在讲解中讲到的kernel形式是对应的。
5. similarity_map函数
计算相似图的过程跟公式也是相对应的,本质上是一个相关系数的计算。
def similarity_map(
map_x: torch.Tensor, map_y: torch.Tensor, constant: float, alpha: float = 0.0
) -> torch.Tensor:
r"""Compute similarity_map between two tensors using Dice-like equation.
Args:
map_x: Tensor with map to be compared
map_y: Tensor with map to be compared
constant: Used for numerical stability
alpha: Masking coefficient. Subtracts - `alpha` * map_x * map_y from denominator and nominator
"""
return (2.0 * map_x * map_y - alpha * map_x * map_y + constant) / (
map_x**2 + map_y**2 - alpha * map_x * map_y + constant + EPS
)
3、总结
代码实现核心的部分讲解完毕,VSI作为一个传统的IQA指标,解决问题的思路是我们可以参考的,通过提取合适的、具有判别性的特征来对图像进行特征提取,此时比较特征相似度可以完成IQA任务,在解释性上会比深度学习的方法高不少。
感谢阅读,欢迎留言或私信,一起探讨和交流。
如果对你有帮助的话,也希望可以给博主点一个关注,感谢。


















 5658
5658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










