



 本文介绍了如何使用Linux Shell脚本实现多进程下载,从串行执行到并行执行,再到控制进程数量和实现生产者消费者模型。通过创建管道和使用文件描述符,限制了同时运行的子进程数量,解决了资源消耗问题。然而,在多进程读取同一管道时出现了线程安全问题,通过引入锁文件来解决。最终推荐使用控制进程数量的方案,避免了线程安全问题。
本文介绍了如何使用Linux Shell脚本实现多进程下载,从串行执行到并行执行,再到控制进程数量和实现生产者消费者模型。通过创建管道和使用文件描述符,限制了同时运行的子进程数量,解决了资源消耗问题。然而,在多进程读取同一管道时出现了线程安全问题,通过引入锁文件来解决。最终推荐使用控制进程数量的方案,避免了线程安全问题。
Linux shell实现多进程(进程池)
参考文档:
https://zhuanlan.zhihu.com/p/546235448
https://seekstar.github.io/2023/09/25/linux-shell向named-pipe写入时不自动eof/
备注:这里只是用下载举一个耗时任务的例子,真正的下载还受到带宽的影响,带宽慢一个进程就吃满了,进程多也未必管用
假设要从一个给定的 img.txt 文本下载一批文件,文本中每一行都是一个文件下载链接,样式如下:
http://www.test.com/download/a.zip
http://www.test.com/download/b.zip
http://www.test.com/download/c.zip
...
1、串行执行
for循环单线程串行执行,效率低,同一时间只能执行一个任务。
#!/bin/bash
for url in $(cat img.txt); do
echo "download: ${url}"
# wget ${url}
sleep 1s
done
echo "you have download all files"
2、并行执行(不控制进程数量)
将一堆语句用{}括起来,在末尾加一个 &,shell就会启动一个子进程去执行{}里面的内容,使用 wait 命令可以阻塞当前线程,等待这些子进程全部执行完之后再执行剩下的语句。
每循环一次都会开启一个子进程,如果下载链接特别多,短时间内会创建大量的子进程,每个进程都需要分配内存,会消耗服务器大量资源。进程太多,CPU大量时间都花在进程调度上面,真正用于执行任务的时间片占比很少。任务少能用,任务多不推荐。
#!/bin/bash
for url in $(cat img.txt); do
# 这里的 & 会开启一个子进程执行
{
echo "download: ${url}"
# wget ${url}
sleep 1s
} &
done
# 使用 wait 命令阻塞当前进程,直到所有子进程全部执行完
wait
echo "you have download all files"
3、使用命名管道控制子进程数量
mkfifo 命令创建命名管道,命名管道可以实现多个进程之间的通信,特点:管道缓冲区(一般是64KB)没满时进程可正常写入,缓冲区满了进程写入会被阻塞;缓冲区非空进程可正常读取,缓冲区空了进程再读取会被阻塞(阻塞队列)。
- 如果关闭了一个管道的所有写fd,则操作系统会给管道的所有reader发送一个EOF信号,可以使用 exec 命令给管道分配一个写fd,保证至少存在一个写fd,防止系统给reader发送EOF信号。

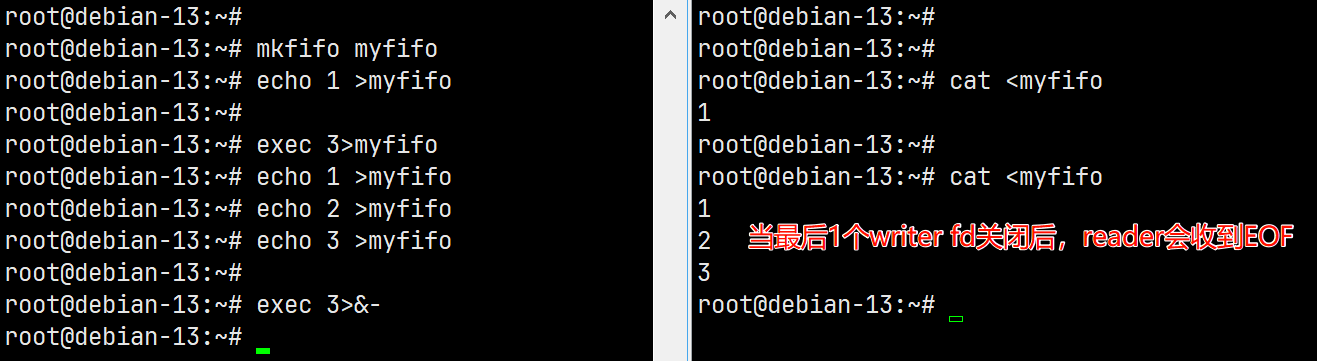
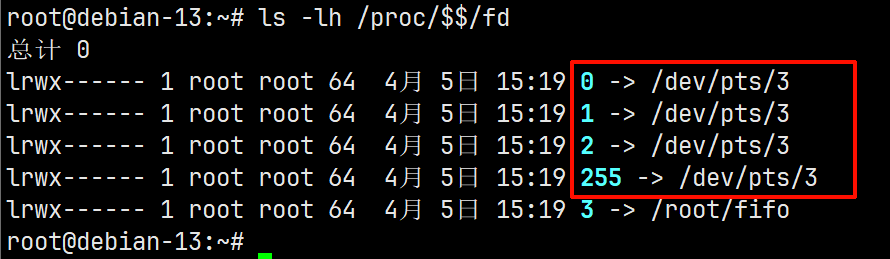
- 分配fd时不要使用0 1 2 255,这4个fd已经被操作系统使用,分别对应stdin、stdout、stderr、系统保留fd,可使用命令 ls -lh /proc/$$/fd 查看进程已分配的fd。
- 使用多个read命令读取同一个管道时,可能会发生字符截断错位的情况。read命令按字符读取,一直读取到换行符为止,一行字符可能会被几个read命令获取到,比如abcdefg是一行,a进程read命令获取到ace三个字符,b进程read命令获取到bd两个字符,c进程获取到fg两个字符,导致每个read命令都不能获取到完整的一行字符(使用多个read命令时要加锁)。
利用管道阻塞队列的特性来控制进程数量:往管道中放入固定个数的令牌,主进程每从管道中取走一个令牌就可以开启一个子进程,令牌取完后主进程会被阻塞。子进程结束前再将令牌归还到管道,管道中有了令牌后主进程又可以取走令牌开启子进程,这样就可以控制开启的子进程的数量了,子进程数量和CPU核心数量相等时,效率最高。
#!/bin/bash
# 创建一个管道
mkfifo mylist
# 给管道分配读写fd,写fd防止操作系统发送EOF,如果只分配写fd,则必须在读管道后执行否则阻塞
exec 4<>mylist
# 管道中放入4个令牌(回车符)
for i in {1..4}; do
echo >mylist
done
for url in $(cat img.txt); do
# 创建子进程前先从管道中取走一个令牌(回车符),当循环4次后管道空了,主进程就会被阻塞
# 一直等到管道中又有令牌(回车符)了主进程才被唤醒继续执行
read <mylist
# 这里的 & 会开启一个子进程执行
{
echo "download: ${url}"
# wget ${url}
sleep 1s
# 子进程结束前归还令牌(回车符)
echo >mylist
} &
done
# 使用 wait 命令阻塞当前进程,直到所有子进程全部执行完
wait
echo "you have download all files"
# 全部结束后删除fd和管道
exec 4>&-
exec 4<&-
rm -f mylist
4、参考进程池实现多进程
直接使用管道传递任务参数,开启固定个数的子进程,每个子进程内部使用 read 命令不断从管道中读取数据,直到管道为空读取不到数据了再关闭子进程。相比上面的分配令牌的实现方式省去创建子进程的开销,性能更高。注意多个read命令读取同一个管道会字符错乱,需要加锁。其他队列都可以按照此方式实现多进程,redis,rabbitmq,kafka之类的都可以
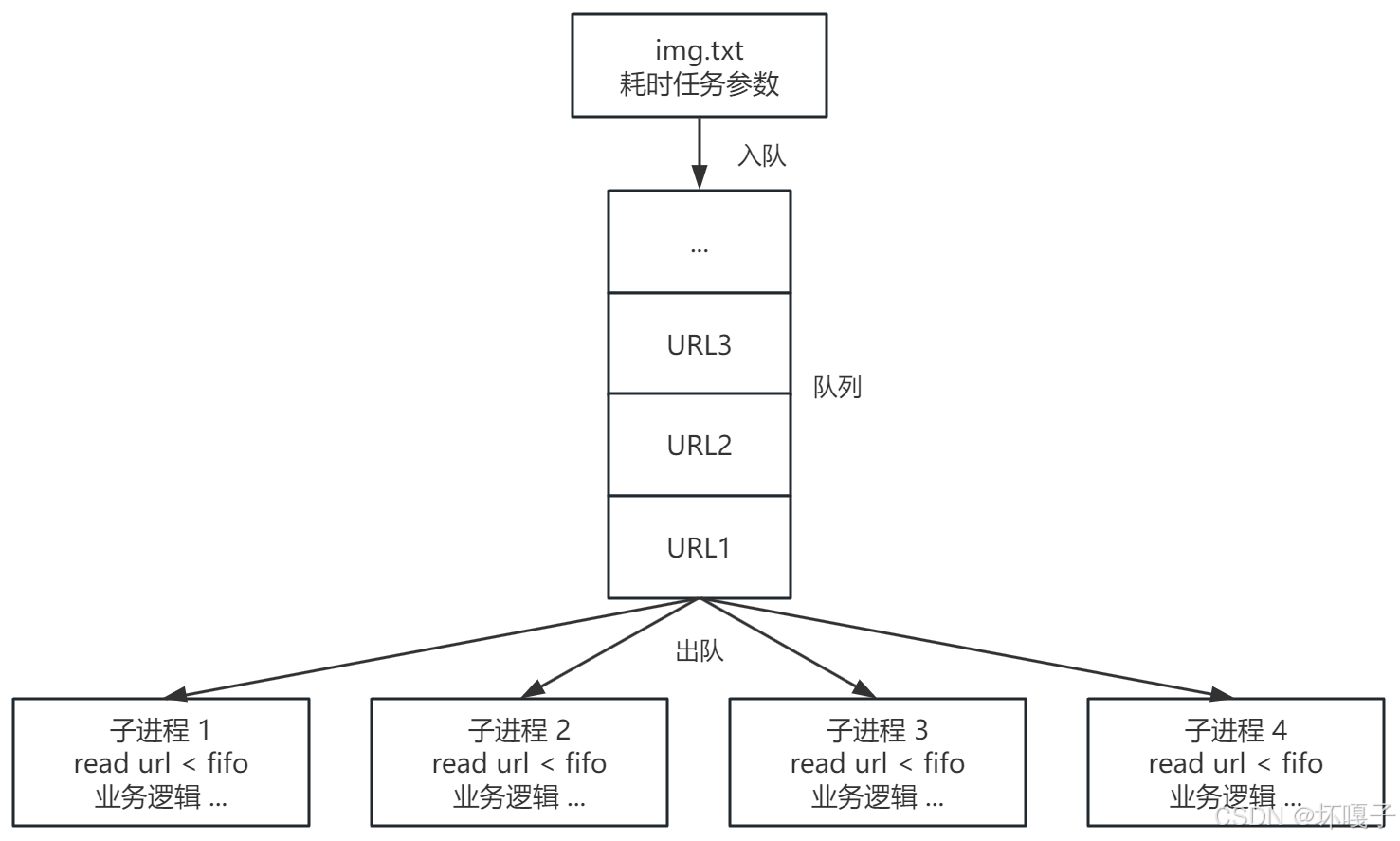
另外要注意必须先开启子进程,然后再将数据写入到管道。防止写满管道缓冲区导致主进程被一直阻塞,先开启子进程,再向管道文件中写入数据,数据一写入管道缓冲区马上就被子进程取走,不会出现主进程被阻塞的问题。
#!/bin/bash
# 创建一个管道(传递任务参数)
mkfifo mylist
# 给管道分配fd
exec 4<>mylist
# 再创建一个管道(锁文件),用于多个read命令加解锁
mkfifo mylock
# 给管道分配fd
exec 5<>mylock
# 事先向锁文件中放入1条数据(解锁)
echo >mylock
# 开启4个子进程
for i in {1..4}; do
# 这里的 & 会开启一个子进程执行
{
# 先读取锁文件(加锁),由于锁文件中只有1条数据,读取完之后锁文件空了其他子进程再读取时只能等待
# 不要使用 read -t,无法保证原子操作
while read <mylock && read data <mylist; do
# 读取到业务数据后立即写入1条数据到锁文件(解锁),让其他子进程继续读取数据
echo >mylock
# 判断是否是进程结束标志,如果是则结束进程
if [[ "PROCESS_END" == ${data} ]]; then
break
fi
# 子进程会复制父进程的数据,可以使用分配的fd来操作管道
# 正常应该通过 exec 4>&- 关闭写fd,系统发送EOF来结束read命令
# 这里用不了这种方式,read命令阻塞执行不到 exec 4>&-
# 只能通过上面这种进程内部判断的方式结束进程
echo "download: ${data}"
# wget ${data}
sleep 1s
done
} &
done
# 将img.txt中的链接全部插入到管道中
for url in $(cat img.txt); do
echo ${url} >mylist
done
# 插入完业务数据后,再插入对应进程数量的进程结束标志(注意区别业务数据)
for i in {1..4}; do
echo "PROCESS_END" >mylist
done
# 使用 wait 命令阻塞当前进程,直到所有子进程全部执行完
wait
echo "you have download all files"
# 全部结束后解绑文件描述符并删除管道
exec 4>&-
exec 4<&-
rm -f mylist
exec 5>&-
exec 5<&-
rm -f mylock

















&spm=1001.2101.3001.5002&articleId=121268072&d=1&t=3&u=4472e1bbe36446f794d80a74bf6ebbdf)
 4409
4409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










