




 本文介绍使用PostgreSQL伪列ctid进行数据去重的方法,包括直接删除重复数据的SQL语句及针对大数据量场景的高效去重策略,通过创建临时表保留干净数据,提升去重效率。
本文介绍使用PostgreSQL伪列ctid进行数据去重的方法,包括直接删除重复数据的SQL语句及针对大数据量场景的高效去重策略,通过创建临时表保留干净数据,提升去重效率。
PostgreSQL删除重复数据通常会用到伪列ctid,其表示的是数据记录的物理行信息,指的是一条记录位于哪个数据块的哪个位移上面--与oracle中伪列 rowid 的意义是相同的,但是形式不同;
1、删除重复数据一般可用语句:
DELETE FROM table_name WHERE ctid NOT IN (SELECT MIN(ctid) FROM table_name GROUP BY ${id});
其中:${id}为区分不同数据条目的字段,即为记录除ctid外的唯一标识列。
2、如果没有唯一标识字段,可根据表数据特点,通过多列进行数据重复度匹配。
比如一张醉驾测试数据表(),含被测试人(detected)、测试时间(detect_time)、测试结果(detect_result),测试人员编号(detector),测试设备编号(machine_num)等字段,数据如下所示:
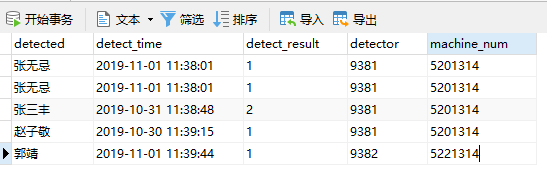
因为同一个测试人员、测试设备在同一个测试时间下只能测试出一条结果,所以完全可以通过这三个字段进行数据重复性匹配,删除语句可写为:
DELETE FROM drunkdriver_detect WHERE ctid NOT IN (SELECT MIN(ctid) FROM drunkdriver_detect GROUP BY detector,machine_num,detect_time);
3、但是,如果这张表数据量较大,比如数据量为50万,SQL中的NOT IN带来的低效率将会极大的影响删除效率。
仔细分析SQL语句,会发现,如果重复数据越少,那么NOT IN后面的子句匹配出来的干净数据的ctid个数就会越多,NOT IN匹配的记录越多,整个SQL的执行效率就变得越慢。
想到这里,不如换一种思路,最终目的不就是去重嘛,倒不如把这些要删的数据留下,把原本想要留下的数据生成、插入到另一张新表,然后直接DROP旧表或者改掉它的名字,再将新表改名为正式使用的表,比如以上,SQL为:
CREATE TABLE drunkdriver_detect_tmp AS SELECT * FROM drunkdriver_detect WHERE ctid IN (SELECT MIN(ctid) FROM drunkdriver_detect GROUP BY detector,machine_num,detect_time);
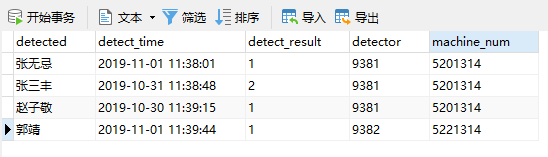
去重之后的表名为drunkdriver_detect_tmp,删除旧表或改掉旧表名,将新表改名为旧表的表名就可以了,
这个效率就高多啦!!!



















 1858
1858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












