




接下来大概总结一下每一章考的概率比较大的知识点。
还是那句话,想好好学考高分就认真看学在吉大录课听老师讲,只想及格突击学的话把这篇全背下来且会用能保你及格,有很多更细节的知识点和证明过程就不写在这里了,可能后续会再出有更多细节的复习资料吧,也可能懒了就不会再出了。整门课学下来感觉不是很难,但是需要理解记忆的东西挺多的,死记硬背不可取,理解了自然就记住了。
除了EM那一章大部分从PPT里抓取原图,其他全是手打的,可能会有笔误之处,欢迎评论留言捉虫,如果看到有哪些和PPT、和老师讲的不一样的,以PPT为准,因为大概率是我这个笨蛋打错了
2.2 线性同余发生器
混合同余发生器:c>0
乘同余发生器:c=0
同余性质:①i≡j(mod M)j≡i(mod M)
②若i≡j(mod M),j≡k(mod M) 则i≡k(mod M)
③若i1≡j1(mod M),i2≡j2(mod M) 则i1±i2≡j1±j2(mod M);i1i2≡j1j2(mod M)
④若ik≡jk(mod M)(k为正整数),则i≡j(mod ),其中gcd(M,k)表示M和k的最大公约数
2.3 非均匀随机数的产生
逆变换法
离散型:推导密度函数,由此
。
连续型:已知密度函数p(x),求分布函数,求分布函数逆函数
,随机取U~U(0,1),解F(x)=U,即
舍选法I
已知密度函数p(x),求导数p'(x),令导数p'(x)=0解出x,代入求maxp(x),则M=maxp(x),求M(b-a)即为算法所需迭代次数
复合法
①U1~U(0,1),根据U1的值选择子分布
②U2~U(0,1),根据①选择的子分布代入U2,用逆变换法之类的方法生成随机数
2.4 随机向量的产生
条件分布法
步骤:①生成X1
②由已知X1的值服从条件分布p(X2|X1),产生X2
③由已知X1,X2的值服从条件分布p(X3|X1,X2),产生X3
④重复,直到产生Xr
多项分布
步骤:①由X1~B(n,p1),产生X1=x1
②由X2~B(n-x1,),产生X2=x2
③由X3~B(n-x1-x2,),产生X3=x3
④重复,直到产生Xr
3.2 随机模拟积分 均匀抽样
双期望定理
方差分解公式
条件方差公式
随机投点法
平均值法
高维定积分 
随机投点法
平均值法
(V(C)即积分区域体积)
由 可知,平均值法比随机投点法精度更高
随机投点法和平均值法的误差都是,与维度d是线性关系不是指数关系,因此可以避免维度爆炸
3.3&3.4 非均匀抽样
重要抽样法
分层抽样法
分层后,在每一层分别用平均值法或随机投点法,再把每一层的加起来(一般都是用平均值法,如果有要求会专门说的,不说就默认用平均值法),公式的话PPT上的太麻烦了我简单总结一下,举个例子比如分成了A,B两层,即
,则
分多层也是一样的,注意一下,就把每一层都单独当成一个I来求,公式还是那些,灵活应变,U变成对应区间上的数就行,PPT上的例题会做就差不多了
3.5 方差缩减技术
两件事:①E(Z)=E(X)
②Var(Z)≤Var(X)
控制变量法
,
,
①,
②由,必有
,达到方差缩减目的
对立变量法
,
,
①,由XY同分布得
②由定理14.1,必有Cov(X,Y)≤0,即必有,达到方差缩减目的
条件期望法
①由双期望定理,
②由Var(X|Y)≥0,则E(Var(X|Y))≥0,必有,达到方差缩减目的
3.7 bootstrap
标准误差的bootstrap估计:

把这道作业题的过程记住就ok了,学习通作业在批改后会显示老师上传的标准答案,由于我在写这篇博文的时候学习通这门课已经无了所以找不到答案的图了......
大致过程:
根据给出的随机数生成bootstrap样本,注意这里给的随机数指的是在总体的样本中的位置,比如样本1(5,2,4,4,2,3),其中第一个随机数5表示样本中的第5个数,也就是2,9,5,7,3,8中的3,以此类推得到B个bootstrap样本(这道题里B=5)
样本1:3,9,7,7,9,5 均值(3+9+7+7+9+5)÷6=6.67
样本2:7,9,3,9,3,7 均值(7+9+3+9+3+7)÷6=6.33
样本3:3,3,3,2,2,8 均值(3+3+3+2+2+8)÷6=3.50
样本4:9,2,7,8,7,5 均值(9+2+7+8+7+5)÷6=6.33
样本5:8,9,5,3,5,8 均值(8+9+5+3+5+8)÷6=6.33
bootstrap样本均值(6.67+6.33+3.50+6.33+6.33)÷5=5.83,即=5.83
代入公式得
(注意:题目可能会把求均值换成求中位数之类的,那么相应的就把换成求每个样本的中位数就行,比如样本1中位数就是7,同理得到5个bootstrap样本的5个中位数后相加求平均值
,SE公式不变直接代入即可)
3.6 随机服务系统模拟
(这章我们23级没细讲,排队系统压根没讲,往年都讲也考了,这部分我真不会,如果后续你们讲了且老师把它列到考试范围里了那就自己学一下吧,我只能说2324年都考了,目测是学了就必考的)
3.8 MCMC蒙特卡洛马尔科夫链
细致平稳
MCMC抽样
接受率
状态转移矩阵
因此,,即
满足细致平稳性
MCMC抽样步骤:
①输入我们任意选定的状态转移矩阵Q,平稳分布π(x),设定状态转移次数阈值n1,需要的样本个数n2
②从任意简单概率分布抽样得到初始状态值x0
③for t=0 to n1+n2-1:
a)从条件概率分布Q(x|xt)中抽样得到样本
b)从均匀分布抽样u~U(0,1)
c)如果,则接收转移
→
,即
d)否则不接受转移,即
样本集即为我们需要的平稳分布对应的样本集
MH抽样
接受率
状态转移矩阵
当时,
,此时必有
,即
因此,,即
满足细致平稳性
MH抽样步骤:
(和MCMC基本一样,只有c)这一步换成这个,其他不变)
Gibbs抽样
第一维相同的两个点满足细致平稳性证明:
和
,由条件分布
得
由此,对两个式子分别乘不同的部分,得到
可见两个式子右边相等,即有
第二维相同的两个点A、C同理
一个技巧:把相同的那一维提出来,也就是把相同的那一个维度放到|后面,互相乘的时候竖线|前面是对方的、后面是两个点相同的,自己推导几遍就会了,还是很有趣的。死记硬背不可取!
状态转移矩阵P:
if
if
else
二维Gibbs抽样步骤:
①输入平稳分布π(x1,x2),设定状态转移次数阈值n1,需要的样本个数n2
②随机初始化初始状态值和
③for t=0 to n1+n2-1:
a)从条件概率分布中抽样得到样本
b)从条件概率分布中抽样得到样本
样本集即为平稳分布对应的样本集
4 最大似然和EM算法
总共就三道例题,全背下来吧,23年双因素模型,24年三硬币模型,25年AB硬币,三道例题考了一轮了,猜猜26年考哪道?
双因素模型
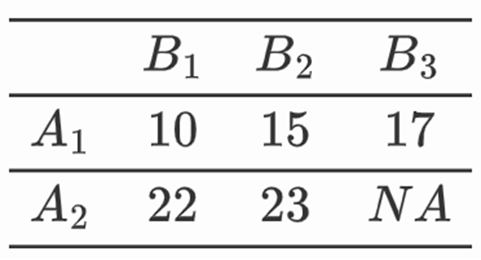
设双因素模型,则
~N(μ+αi+βj,σ^2)
(1)最大似然估计:
似然函数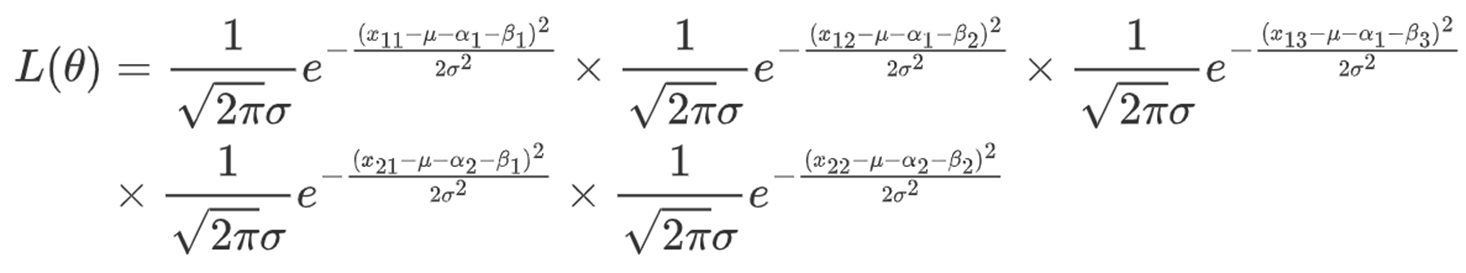
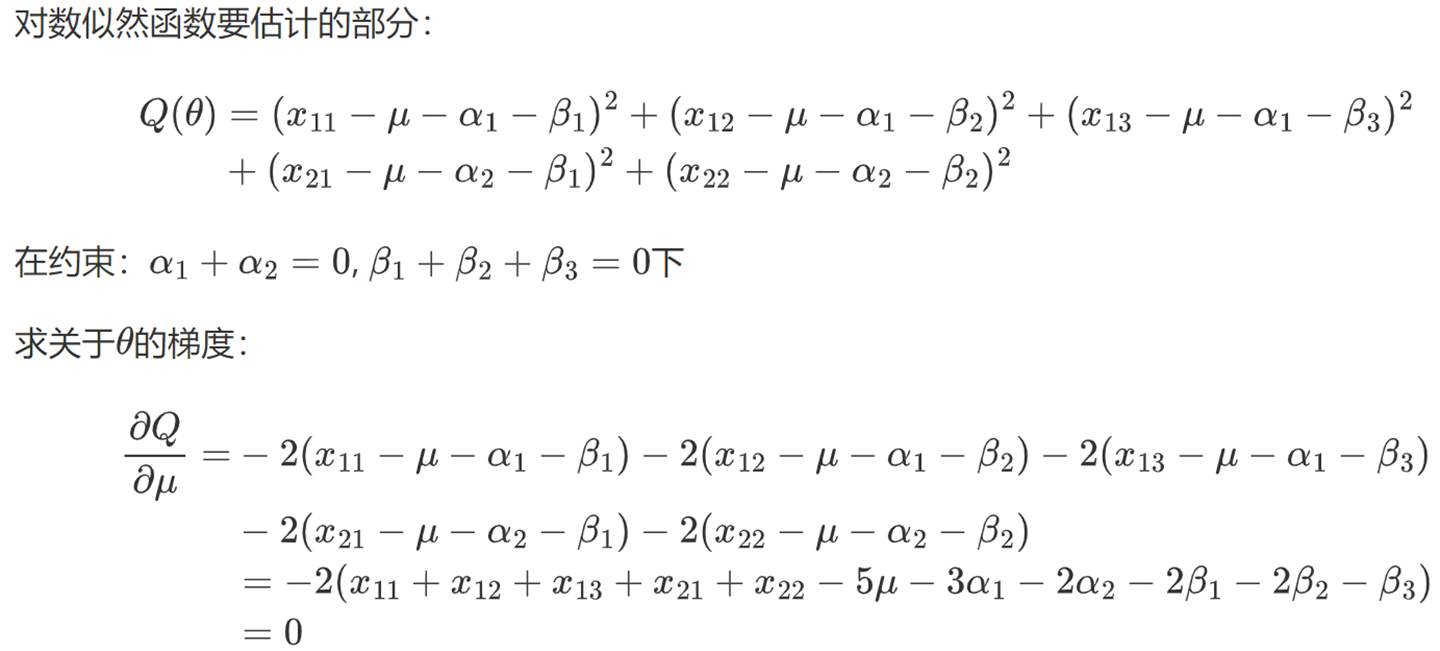
![]()
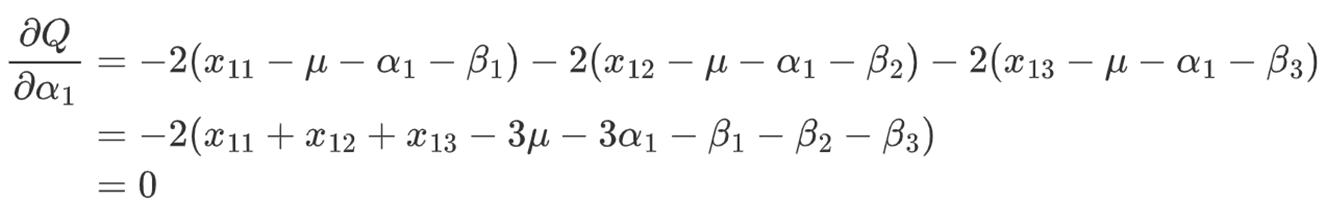
![]()
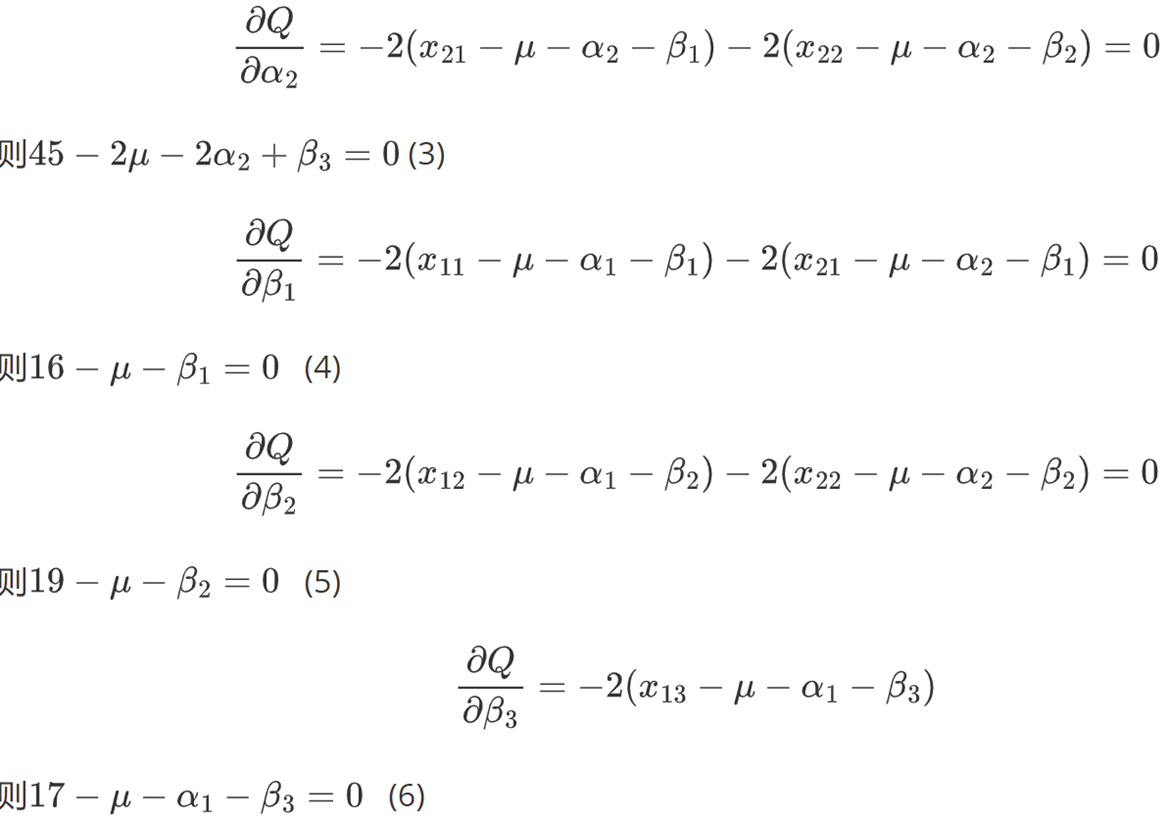

(2)EM(题目会告诉你,假设有初值,迭代一步,此时可以当成完全数据,用EM算法迭代)

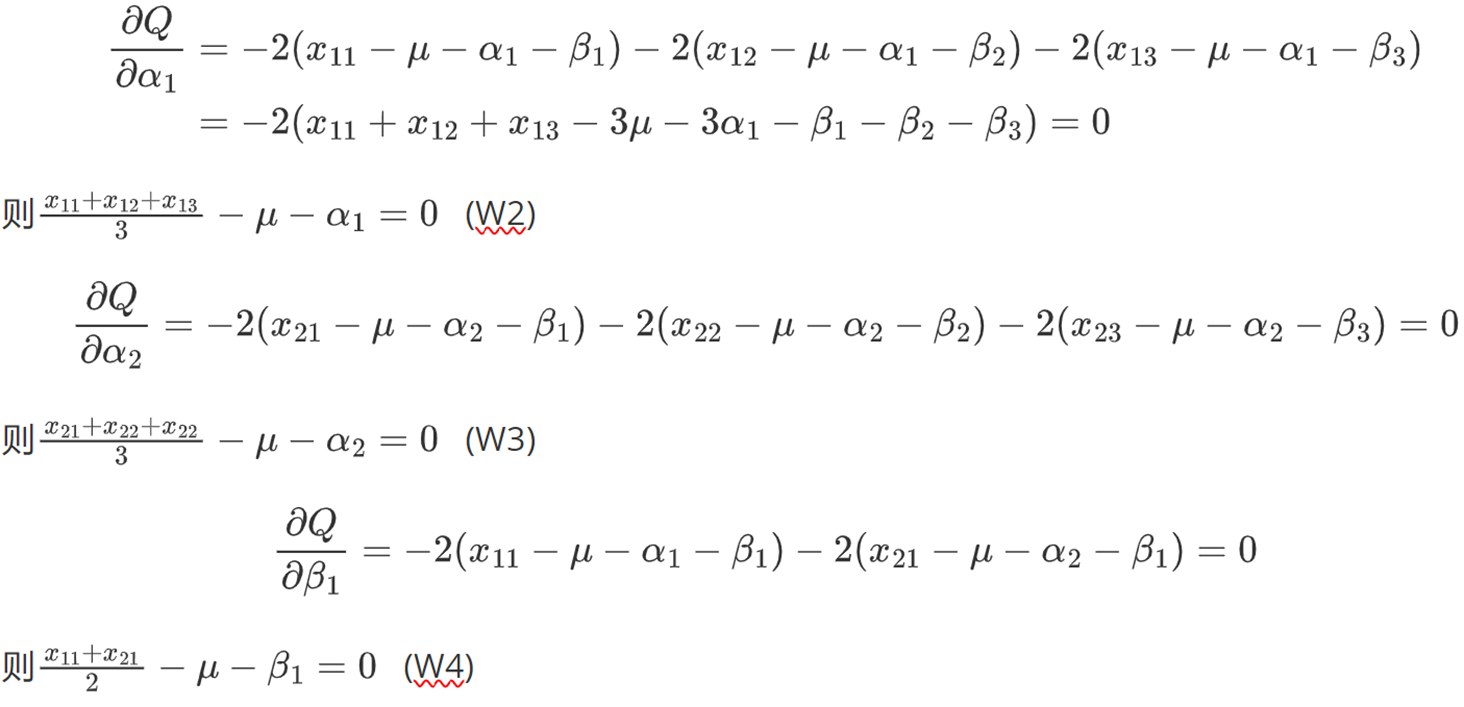
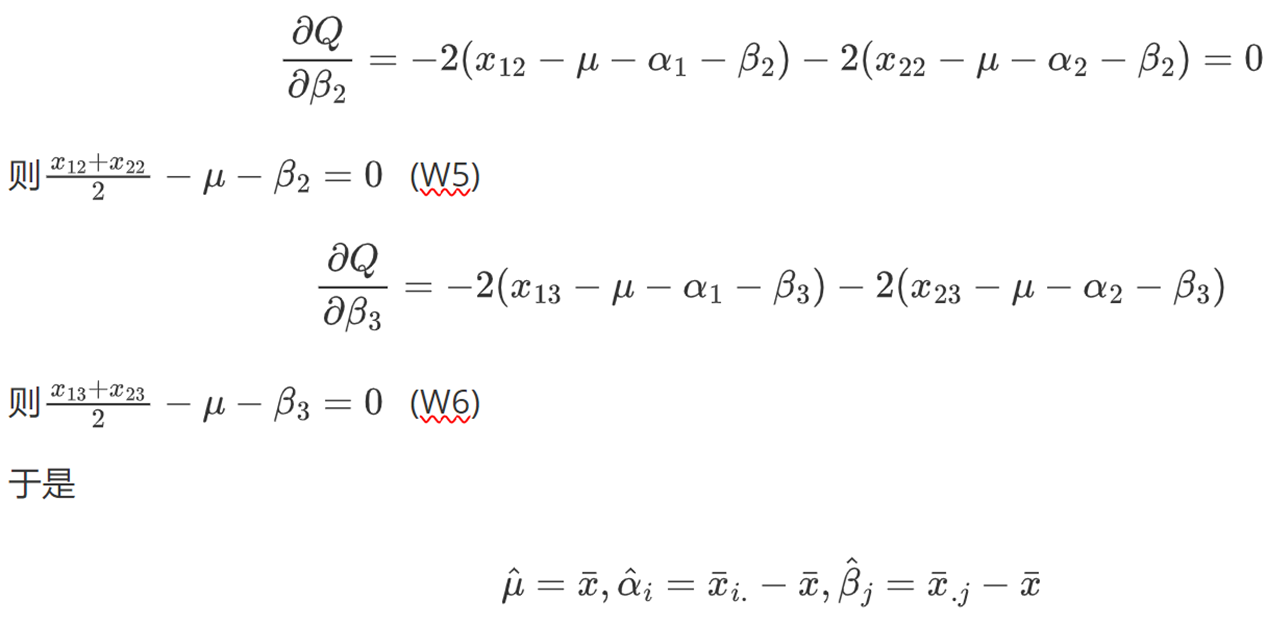
①给定初始
②用完全数据的公式,求得,
,
,以此计算新的
,这就是迭代一步
AB硬币
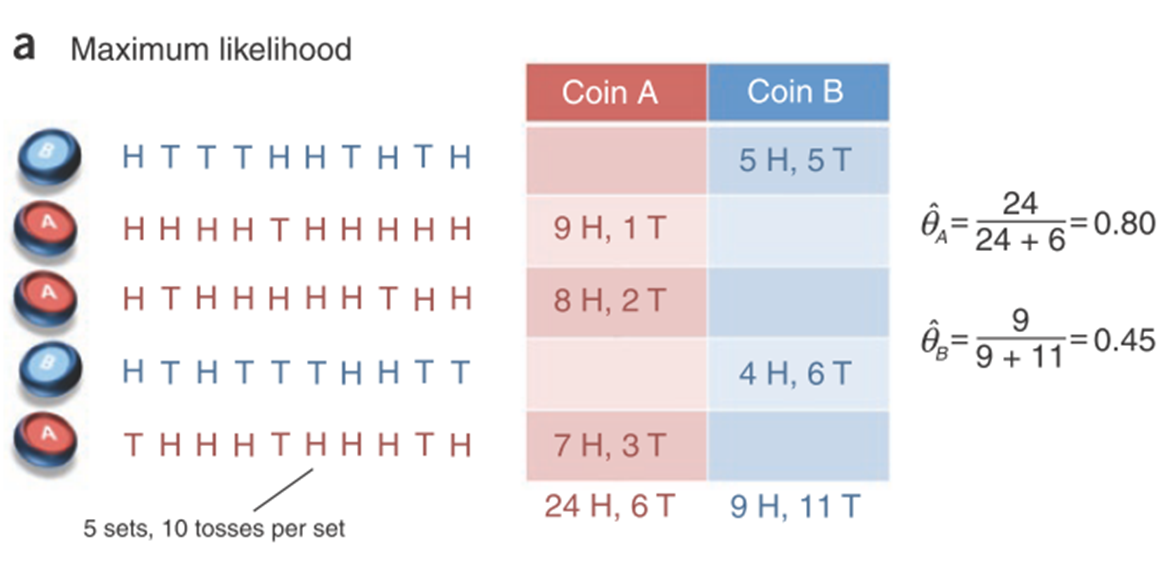
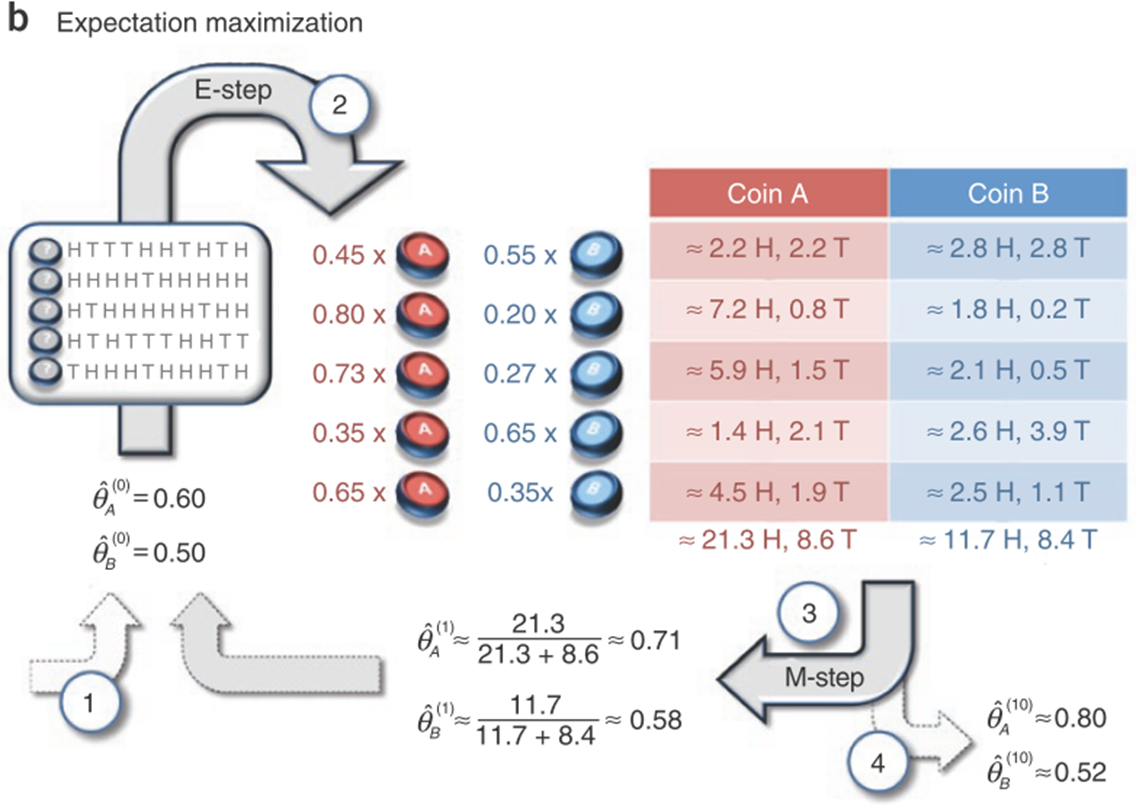
(1)图a,即知道是哪个硬币、且知道正反面次数,直接用最大似然估计求θA、θB即可
,即正面次数÷总次数
(2)图b,即不知道是哪个硬币,只知道正反面次数,用EM算法
①给定随机初始值θA,θB
②E步:对每个样本,用初始值θA、θB分别计算其由A、B硬币抛出的概率,公式为,
,同时P(B|H)=1-P(A|H),其中H、T分别表示正面、背面的次数
计算期望,A:正面H:,反面T:
B:正面H:,反面T:
③M步:
④和上一步的θ比较,接近则停,差得多就继续回到②再次迭代(考试一般只迭代一步就行)
结合PPT题目图片的样本数据带大家解一遍,记住计算过程碰到新的数也会算就行,前面的那些式子都是我自己总结的非官方不用背:
样本H1:5H5T
样本H2:9H1T
样本H3:8H2T
样本H4:4H6T
样本H5:7H3T
①初始值,
,则
,
②E步:
样本H1:
样本H2:
样本H3:
样本H4:
样本H5:
A:正面H:0.45×5+0.80×9+0.73×8+0.35×4+0.65×7=21.3
反面T:0.45×5+0.80×1+0.73×2+0.35×6+0.65×3=8.6
B:正面H:0.55×5+0.20×9+0.27×8+0.65×4+0.35×7=11.7
反面T:0.55×5+0.20×1+0.27×2+0.65×6+0.35×3=8.4
③M步:
④和上一步得到的θ比较,接近则停止,差得多则继续迭代(考试只要求迭代一步的话就不用比较,直接结束就行)
三硬币模型


![]()
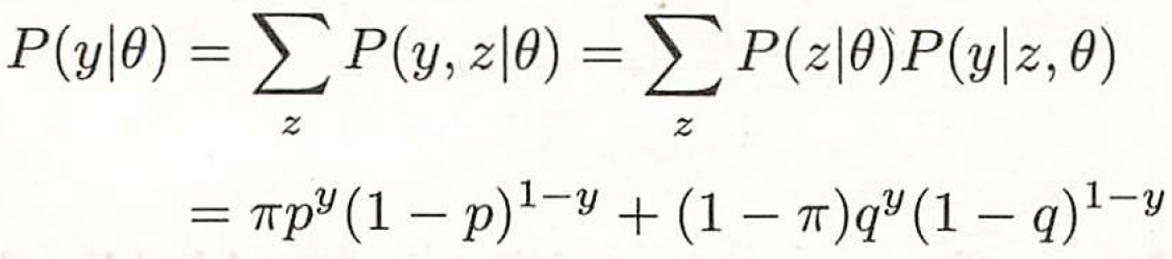
观测数据Y,未观测数据Z
似然函数
即:
极大似然估计:
该问题没有解析解,使用EM迭代法:
选取初值:
第i步的估计值:
EM算法第i+1次迭代:
E步:计算在模型参数下观测数据yj来自掷硬币B的概率:
M步: 计算模型参数的新估计值
以上,就是统计计算这学科必会知识点总结,注意,这一篇的内容不可能覆盖全部考点,尤其是简答题老师总能找到一些以为大家都会的小问题来考一考,当年自以为什么细节都看到过的我拿到卷子就被25年简答第一题的EDA单防住了哈哈......
bootstrap大概率作业原题形式,改个数,把均值换成中位数之类的,有平方和开放记得带计算器
最后一题EM大概率就是三道例题里面随机出一道,把上面列的过程全背下来,带好计算器多验算几遍,过程写满至少能给你一半分吧?答案都给你了,想要分就背下来考场上默写稳拿过程分,想要分高就要会用,不止能背下来还要能做对,多看录课,不会做的题、做完不确定对不对的,请记住现在AI很发达
可能之后会出按章节更细节讲解的内容,也可能不会再出了,第一次尝试写课程复习材料,真的要老眼昏花了,纯粹是刚放假几天闲来无事,过几天可能就要去为生活奋斗了,也就不会再写了。相信我,把录课从头到尾看下来学明白,你会受益匪浅的
感谢看到这里的所有人,祝看完这篇的同学们全都能考到自己理想的分数!


















 1337
1337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










