




上一篇笔记:python数据分析2 Pandas基础版简单易懂教程+案例
目录
前言
本文介绍了Pandas数据分析基础操作,主要包括三部分内容:1)数据读写操作,演示了如何读取CSV/TSV文件并指定列和索引;2)数据操作技巧,包括行列索引获取、列赋值/增删、排序等,详细说明了loc/iloc索引方法;3)基本运算与统计,涵盖数值运算、逻辑筛选、统计函数应用等。每个操作都配有完整代码和详细注释,特别说明了DataFrame与Series的运算差异、多条件筛选以及常用统计函数的使用方法。这些基础操作是进行数据分析的重要前提,适合Python数据分析初学者快速掌握Pandas核心功能。
数据读写
pandas 是 Python 数据分析核心库,提供了简洁高效的数据读写接口,支持多种常见文件格式。读写表格类文件(如 CSV)最常用read_csv()(读取)和to_csv()(写入);操作 Excel 文件需依赖 openpyxl/xlsxwriter 库,对应read_excel()和to_excel()。此外,它还支持 JSON、SQL、Parquet 等格式的读写。读写时可通过参数指定编码、分隔符、列名、索引是否保存等,能快速将外部数据导入为 DataFrame 进行分析,也能将处理后的结果导出持久化存储。
完整代码+详细注释:
import pandas as pd
# 加载指定列的数据
df = pd.read_csv('./data/stock_day.csv', usecols=['open', 'high', 'close', 'low'])
# 写出数据到文件, 包括:数据
df.head(10).to_csv('./data/stock_day_head10_03.csv', index=False, header=False)
print("写出成功")
# mode:表示追加还是覆盖, w->write(覆盖), 默认的 a->append(追加)
df.head(10).to_csv('./data/stock_day_head10_02.tsv', sep='\t', columns=['open', 'close'], mode='a') # 导出所有列, sep是分隔符, 默认是逗号
print("写出成功")
# 参1:数据源文件的路径
# 参2: sep:分隔符, 默认是逗号, 如果是tsv文件, 要写成'\t'
# 参3: index_col:表示把第0列(第1列)设置为行索引
df = pd.read_csv('./data/stock_day_head10_02.tsv', sep='\t', index_col=0)数据操作
pandas 数据操作围绕核心数据结构 DataFrame 和 Series 展开,是数据分析的核心环节。常用操作包括数据查看(head()看前几行、info()查数据信息、describe()做统计摘要);数据筛选(按列名选取、按行索引或布尔条件过滤行数据);数据清洗(dropna()删除缺失值、fillna()填充缺失值、drop_duplicates()去重);还有数据变换(新增计算列、sort_values()排序、分组聚合等),这些操作简洁高效,能快速实现数据的整理与预处理,为后续分析奠定基础。
根据行列索引获取数据
直接使用行列索引,必须先列后行
print(f'数据1:{df['open']['2018-02-27']}')
print(f'数据2:{df['high']['2018-02-23']}')运行结果:
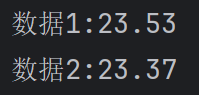
通过loc属性获取,先行后列
print(f'数据1:{df.loc['2018-02-23', 'high']}')
# 需求: 获取从2018-02-27 - 2018-02-22的open列数据
print(f'数据2:{df.loc['2018-02-27':'2018-02-22', 'open']}')
# 需求:获取从2018-02-27 - 2018-02-22的open, high, close, low列数据
print(f'数据3:{df.loc['2018-02-27':'2018-02-22', ['open', 'high', 'close', 'low']]}')
# 需求:获取从2018-02-27 - 2018-02-22的所有列数据
print(f'数据4:{df.loc['2018-02-27':'2018-02-22', :]}') # 这里的:代表所有列输出:
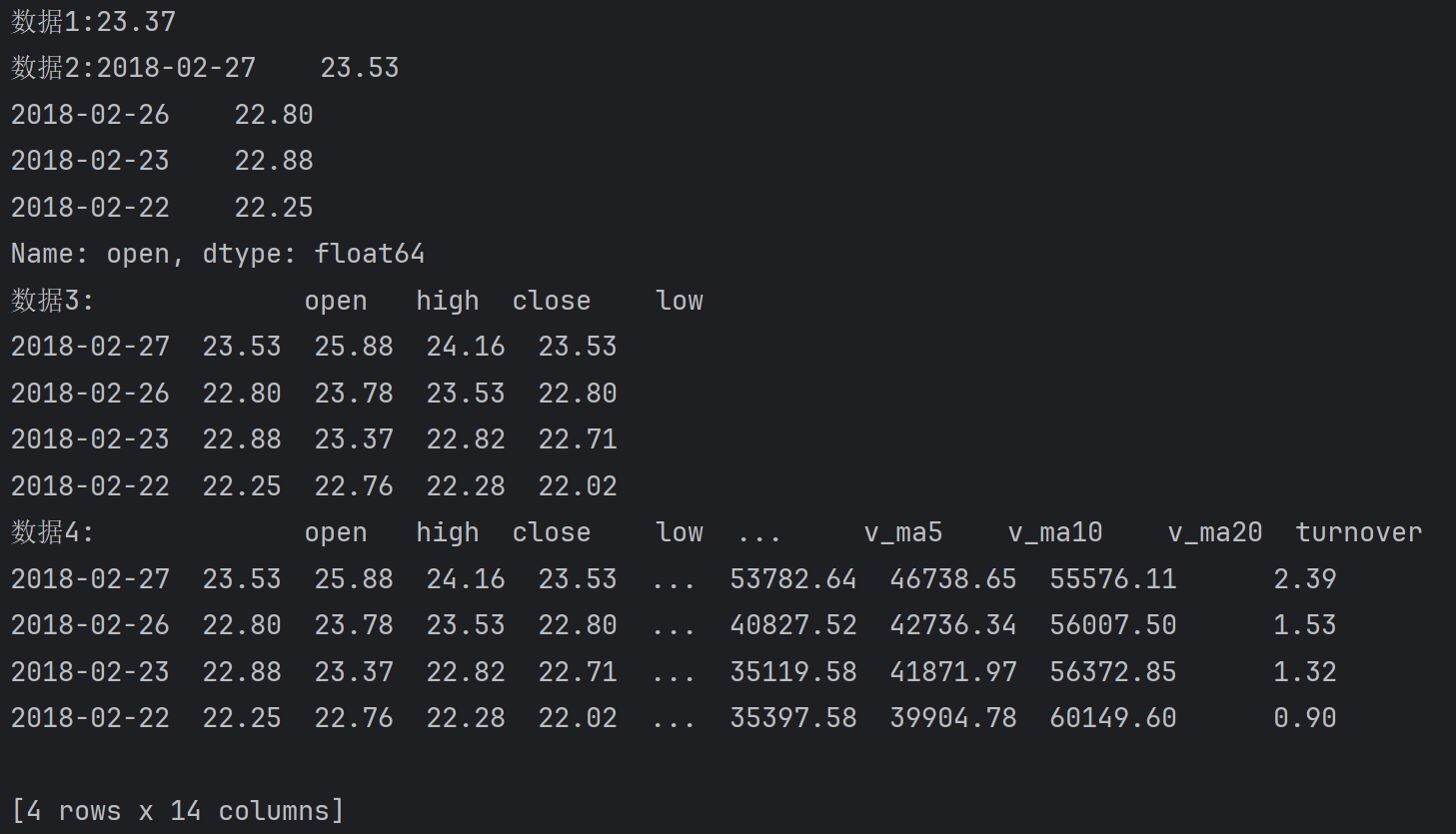
直接打印df对象,获得所有数据
print(f'数据5:{df}')
print(f'等价于:{df.loc[:, :]}')输出:
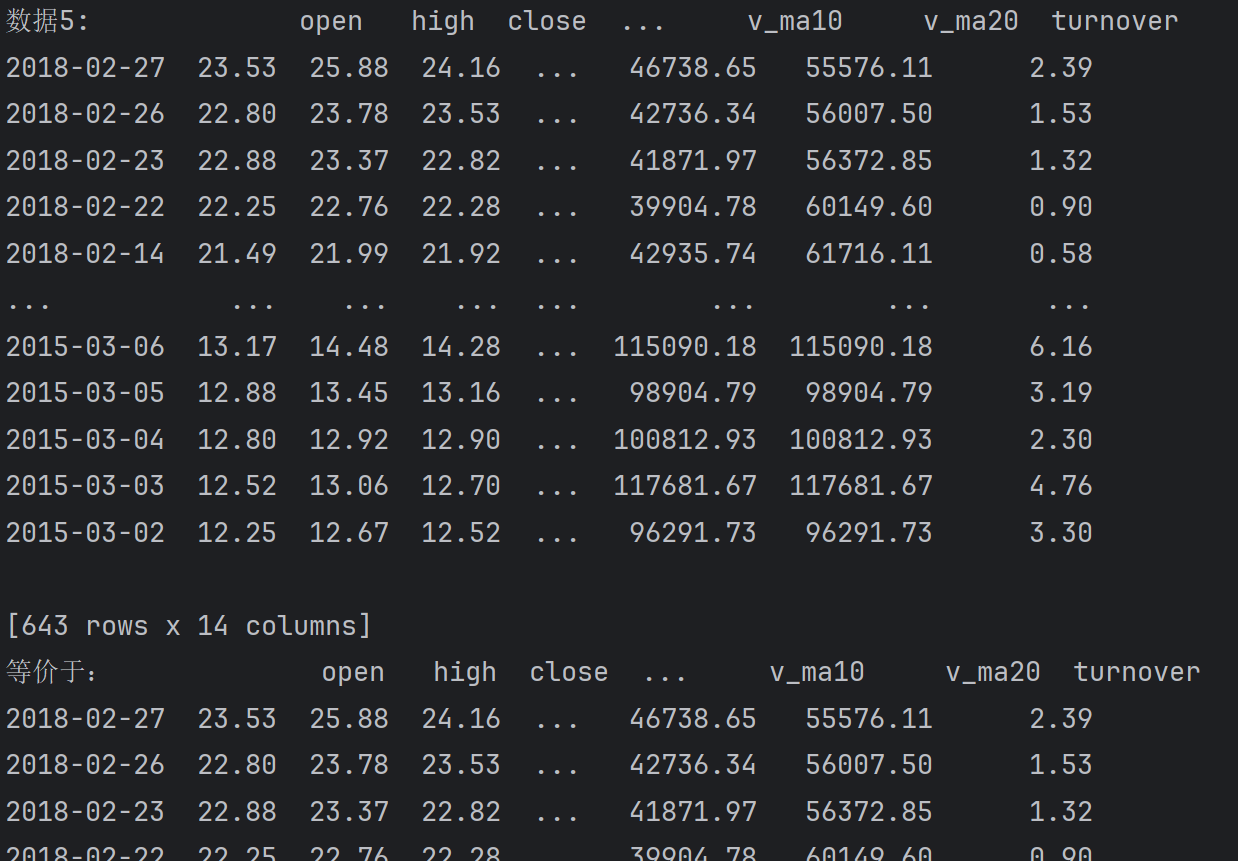
通过iloc属性获取,先行后列,只能通过行号+列号获取
格式:df.iloc[行号, 列号]
print(f'数据6:{df.iloc[0, 0]}')
# 需求:获取从2018-02-27 - 2018-02-22的open列数据
print(f'数据7:{df.iloc[:4, 0]}')
# 需求:获取从2018-02-27 - 2018-02-22的open, high, close, low列数据
print(f'数据8:{df.iloc[:4, :4]}')
# 需求:获取从2018-02-27 - 2018-02-22的所有列数据
print(f'数据9:{df.iloc[:4, :]}')
# 需求:获取所有列数据
print(f'数据10:{df.iloc[:, :]}')输出:
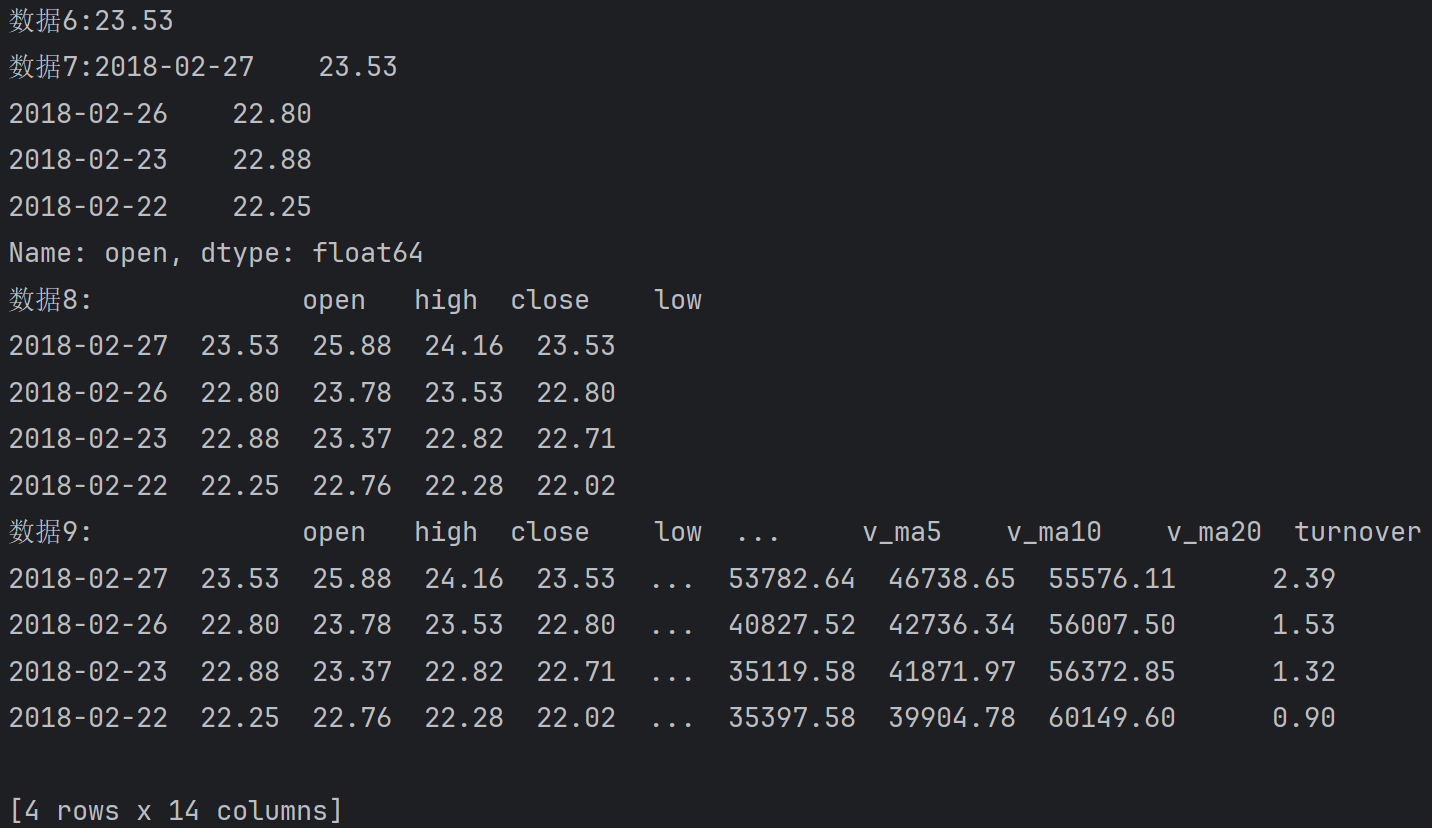
给列赋值,增加列,删除列
删除列, axis=1表示删除列, axis=0表示删除行
print(f'删除列后数据:\n{df.drop(['ma5', 'ma10', 'ma20', 'v_ma5', 'v_ma10', 'v_ma20'], axis=1)}')输出:
获取所有行的open,high列
print(f'获取所有行的open,high列:\n{df.loc[:, ['open', 'high']]}')输出:
修改列值,增加列
# 列名存在就是修改列值,列名不存在就是增加列
df['price_change']=1
print(f'修改列值:\n{df['price_change']}')
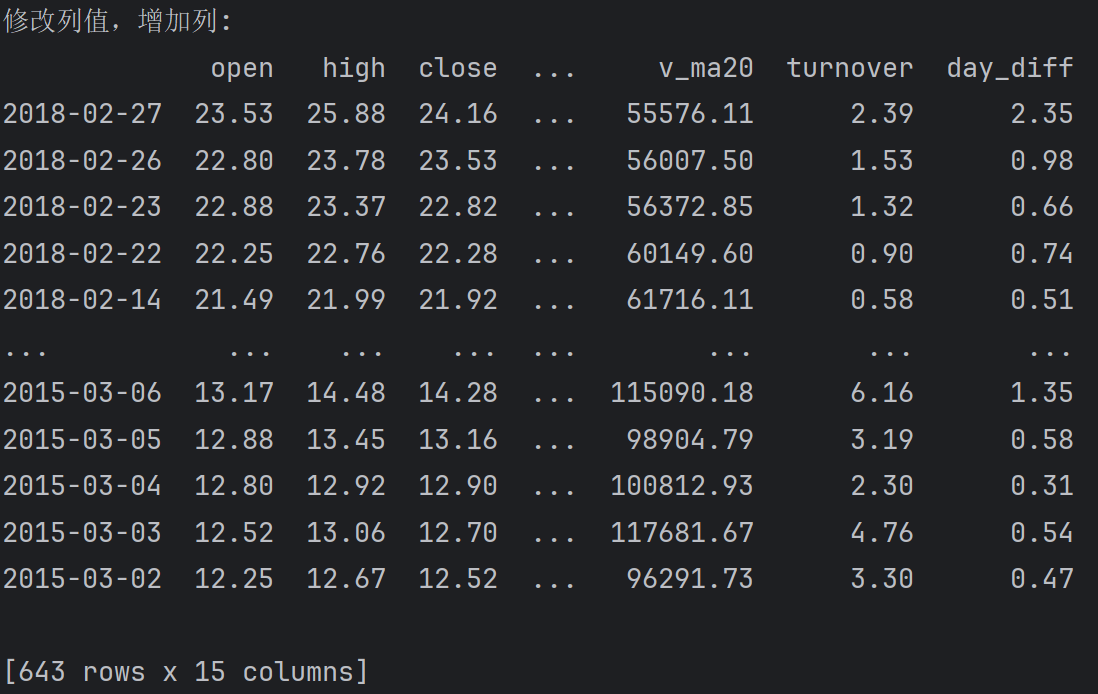
df['day_diff'] = df['high'] - df['low']
print(f'修改列值,增加列:\n{df}')
# 会改变源数据df['列名']和df.列名的区别, 如果是操作无特殊符号的列名,它们没区别.如果是有特殊符号(例如空格)的列名时, df['列名']是正确的
输出:
DataFrame和Series的排序操作
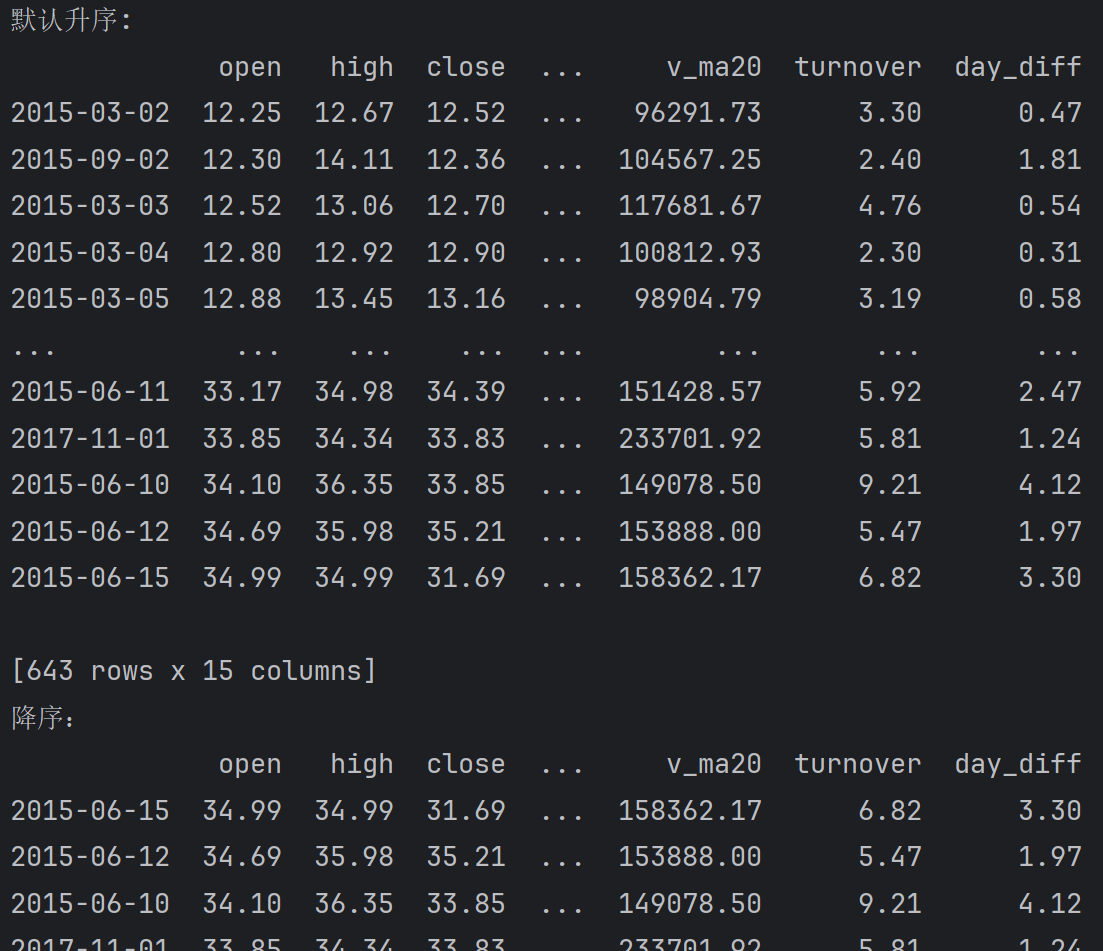
根据单列值进行排序, 例如根据open列(开盘价)升序排序
print(f'默认升序:\n{df.sort_values('open')}')
print(f'降序:\n{df.sort_values('open', ascending=False)}')
# 默认的是升序,ascending=True输出:
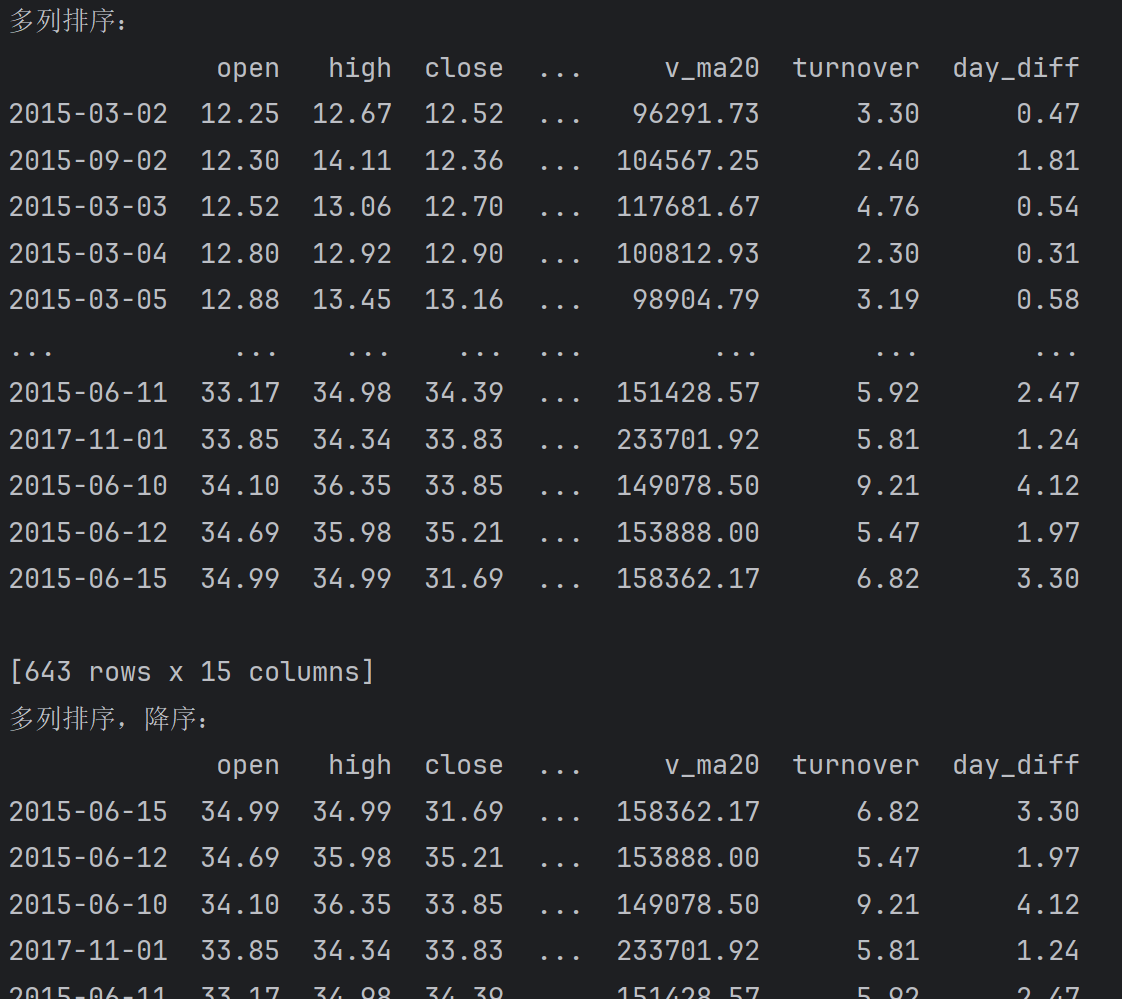
根据多列值进行排序, 例如根据open列(开盘价)和high列(最高价)升序排序, 如果open相同,则按照high升序排序
print(f'多列排序:\n{df.sort_values(['open', 'high'])}')
print(f'多列排序,降序:\n{df.sort_values(['open', 'high'], ascending=False)}')输出:
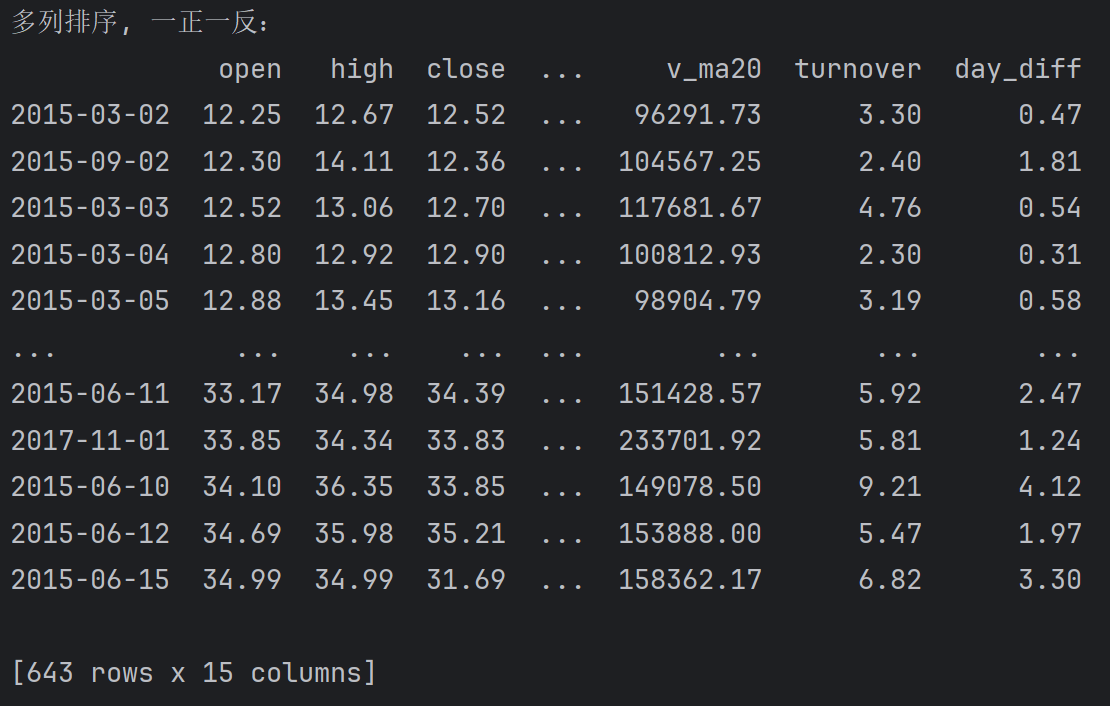
多列值排序规则一样, 例如:按照open升序, open一样,按照high降序
print(f'多列排序, 一正一反:\n{df.sort_values(['open', 'high'], ascending=[True, False])}')输出:
索引排序
print(f'索引排序:\n{df.sort_index()}') # 默认升序
print(f'索引排序,降序:\n{df.sort_index(ascending=False)}')输出:
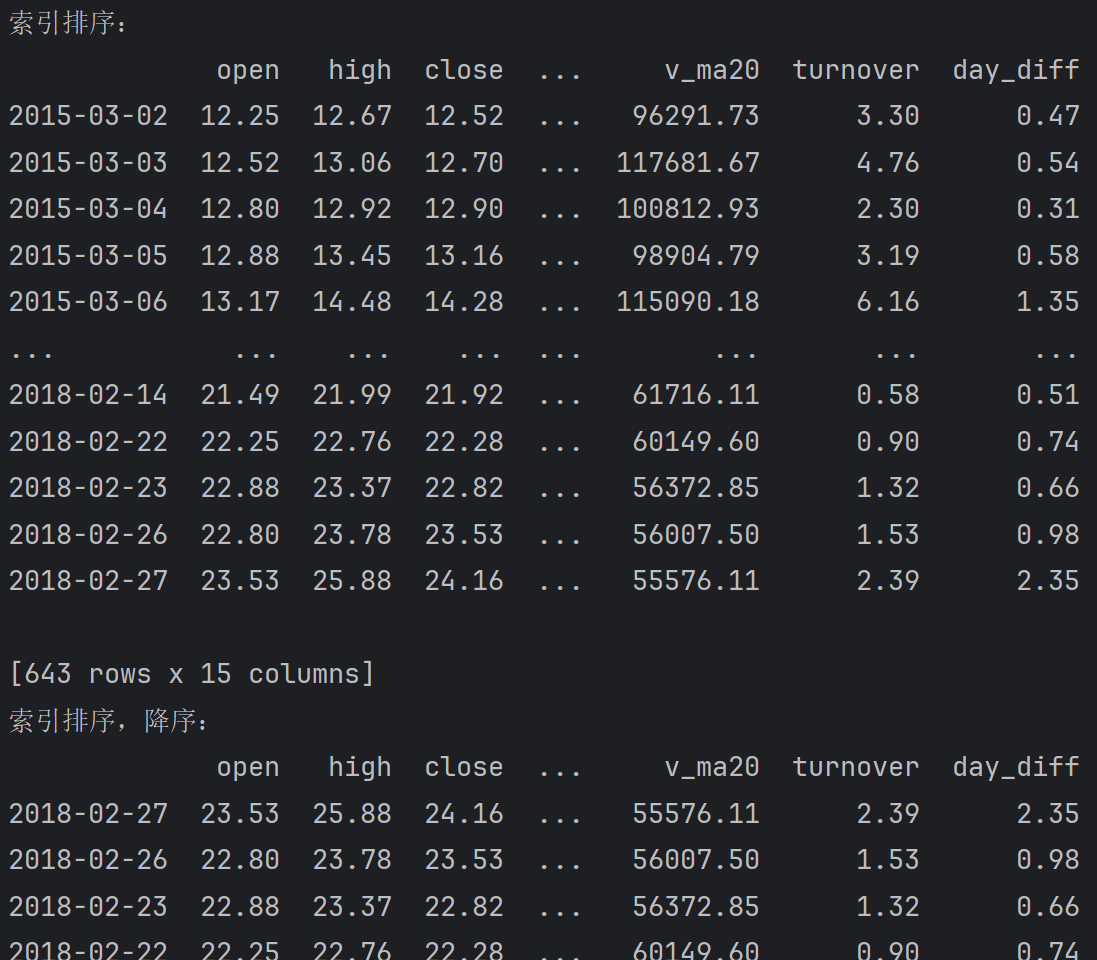
无论是上述的根据值排序,还是根据行索引排序, 默认都是按照axis=0进行排序的
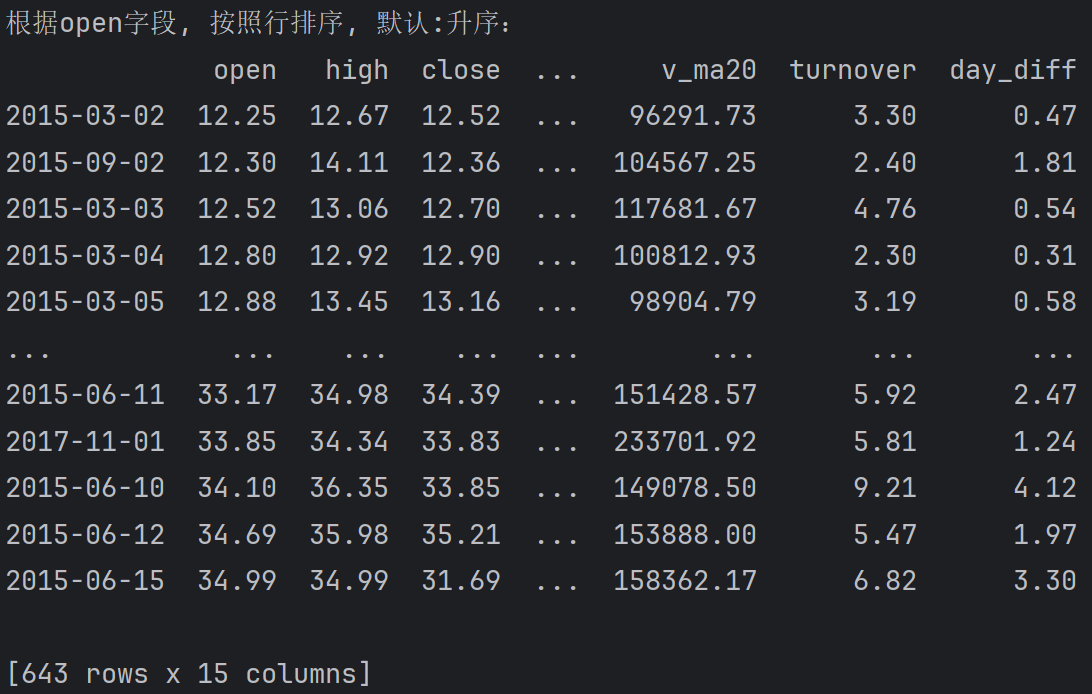
根据open字段, 按照行排序, 默认:升序
print(f'根据open字段, 按照行排序, 默认:升序:\n{df.sort_values('open', axis=0)}')
# print(f'根据open字段, 按照行排序, 默认:升序:\n{df.sort_values('open', axis='rows')}') # 效果同上输出:
数据操作的完整代码+详细注释
import pandas as pd
# 数据准备
df = pd.read_csv(r'换成你自己的文件路径!!!')
print(f'准备数据:\n{df}')
print('-'*30)
# 1. 根据行列索引获取数据
# 直接使用行列索引,必须先列后行
print(f'数据1:{df['open']['2018-02-27']}')
print(f'数据2:{df['high']['2018-02-23']}')
print('-'*30)
# 通过loc属性获取,先行后列
print(f'数据1:{df.loc['2018-02-23', 'high']}')
# 需求: 获取从2018-02-27 - 2018-02-22的open列数据
print(f'数据2:{df.loc['2018-02-27':'2018-02-22', 'open']}')
# 需求:获取从2018-02-27 - 2018-02-22的open, high, close, low列数据
print(f'数据3:{df.loc['2018-02-27':'2018-02-22', ['open', 'high', 'close', 'low']]}')
# 需求:获取从2018-02-27 - 2018-02-22的所有列数据
print(f'数据4:{df.loc['2018-02-27':'2018-02-22', :]}') # 这里的:代表所有列
# 直接打印df对象,获得所有数据
print(f'数据5:{df}')
print(f'等价于:{df.loc[:, :]}')
print('-'*30)
# 通过iloc属性获取,先行后列,只能通过行号+列号获取
# 格式:df.iloc[行号, 列号]
print(f'数据6:{df.iloc[0, 0]}')
# 需求:获取从2018-02-27 - 2018-02-22的open列数据
print(f'数据7:{df.iloc[:4, 0]}')
# 需求:获取从2018-02-27 - 2018-02-22的open, high, close, low列数据
print(f'数据8:{df.iloc[:4, :4]}')
# 需求:获取从2018-02-27 - 2018-02-22的所有列数据
print(f'数据9:{df.iloc[:4, :]}')
# 需求:获取所有列数据
print(f'数据10:{df.iloc[:, :]}')
print('-'*30)
# 2. 给列赋值,增加列,删除列
# 源数据
print(f'源数据:\n{df}')
# 删除列, axis=1表示删除列, axis=0表示删除行
print(f'删除列后数据:\n{df.drop(['ma5', 'ma10', 'ma20', 'v_ma5', 'v_ma10', 'v_ma20'], axis=1)}')
# 不会改变源文件
print('-'*30)
# 获取所有行的open,high列
print(f'获取所有行的open,high列:\n{df.loc[:, ['open', 'high']]}')
print('-'*30)
# 修改列值,增加列
# 列名存在就是修改列值,列名不存在就是增加列
df['price_change']=1
print(f'修改列值:\n{df['price_change']}')
df['day_diff'] = df['high'] - df['low']
print(f'修改列值,增加列:\n{df}')
# 会改变源数据
print('-'*30)
# df['列名']和df.列名的区别, 如果是操作无特殊符号的列名,它们没区别.如果是有特殊符号(例如空格)的列名时, df['列名']是正确的
# 3. DataFrame和Series的排序操作
print(f'源数据:\n{df}')
print('-'*30)
# 根据单列值进行排序, 例如根据open列(开盘价)升序排序
print(f'默认升序:\n{df.sort_values('open')}')
print(f'降序:\n{df.sort_values('open', ascending=False)}')
# 默认的是升序,ascending=True
print('-'*30)
# 根据多列值进行排序, 例如根据open列(开盘价)和high列(最高价)升序排序, 如果open相同,则按照high升序排序
print(f'多列排序:\n{df.sort_values(['open', 'high'])}')
print(f'多列排序,降序:\n{df.sort_values(['open', 'high'], ascending=False)}')
print('-'*30)
# 多列值排序规则一样, 例如:按照open升序, open一样,按照high降序
print(f'多列排序, 一正一反:\n{df.sort_values(['open', 'high'], ascending=[True, False])}')
print('-'*30)
# 索引排序
print(f'索引排序:\n{df.sort_index()}') # 默认升序
print(f'索引排序,降序:\n{df.sort_index(ascending=False)}')
print('-'*30)
# 无论是上述的根据值排序,还是根据行索引排序, 默认都是按照axis=0进行排序的
# 根据open字段, 按照行排序, 默认:升序
print(f'根据open字段, 按照行排序, 默认:升序:\n{df.sort_values('open', axis=0)}')
# print(f'根据open字段, 按照行排序, 默认:升序:\n{df.sort_values('open', axis='rows')}') # 效果同上
print('-'*30)
基本运算
pandas 的基本运算围绕 DataFrame 和 Series 两种核心结构展开,支持高效的批量运算。首先是元素级运算,直接使用 +、-、*、/ 等运算符即可实现逐元素计算,还支持广播机制,能实现标量与数据集的快速运算。其次是统计运算,常用sum()、mean()、max()、min()等方法,可指定轴(行 / 列)计算聚合结果。此外,还支持相关系数(corr())、协方差(cov())及排名(rank())等特殊运算,运算时会自动按索引对齐数据,大幅简化数据分析中的数值计算工作。
基础运算
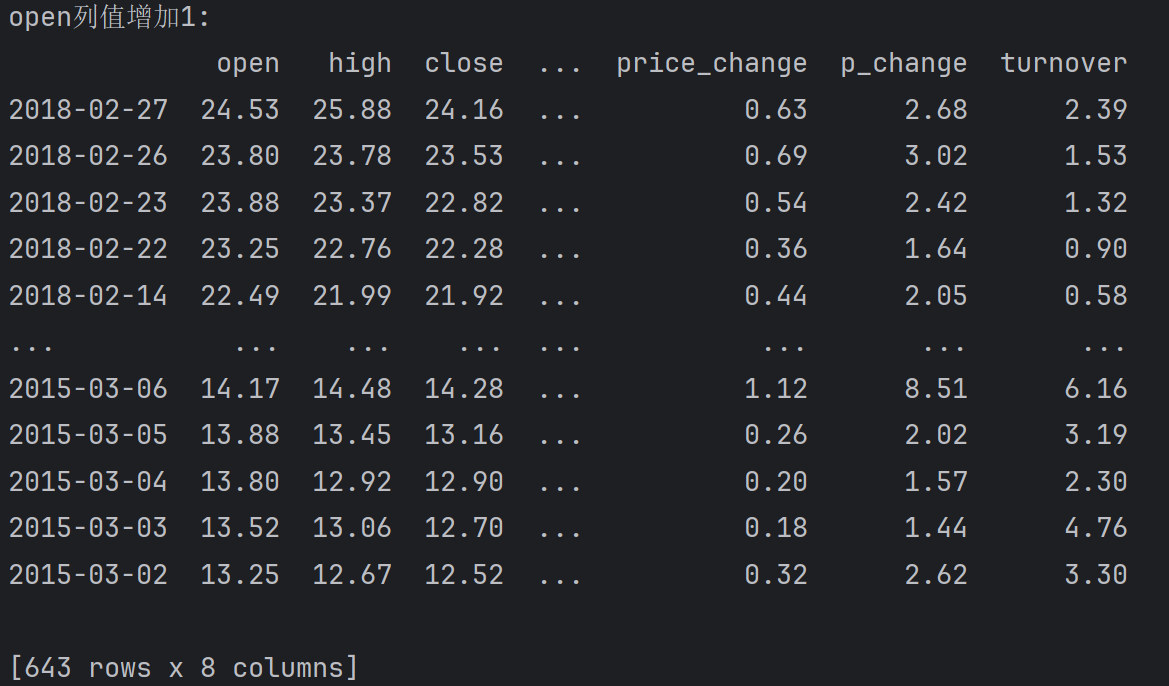
给open的列值增加 1, Series的运算, 发现:数值会和Series中的每个元素进行运算
# df.open+1 # 临时+1, 不修改源数据
df.open.add(1) # 效果同上,临时+1, 不修改源数据
# 修改源数据
df.open+=1
print(f'open列值增加1:\n{df}')输出:
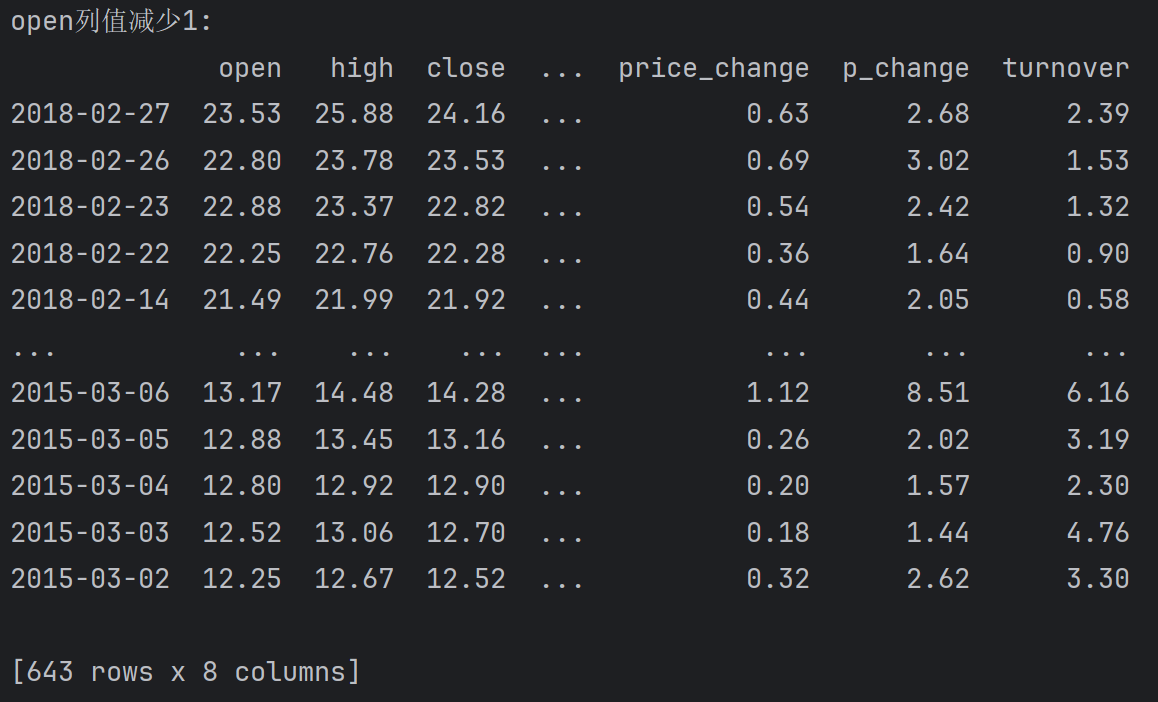
给open的列值减少 1
df.open -= 1
print(f'open列值减少1:\n{df}')
# df.open - 1
# df.open.sub(1)输出:
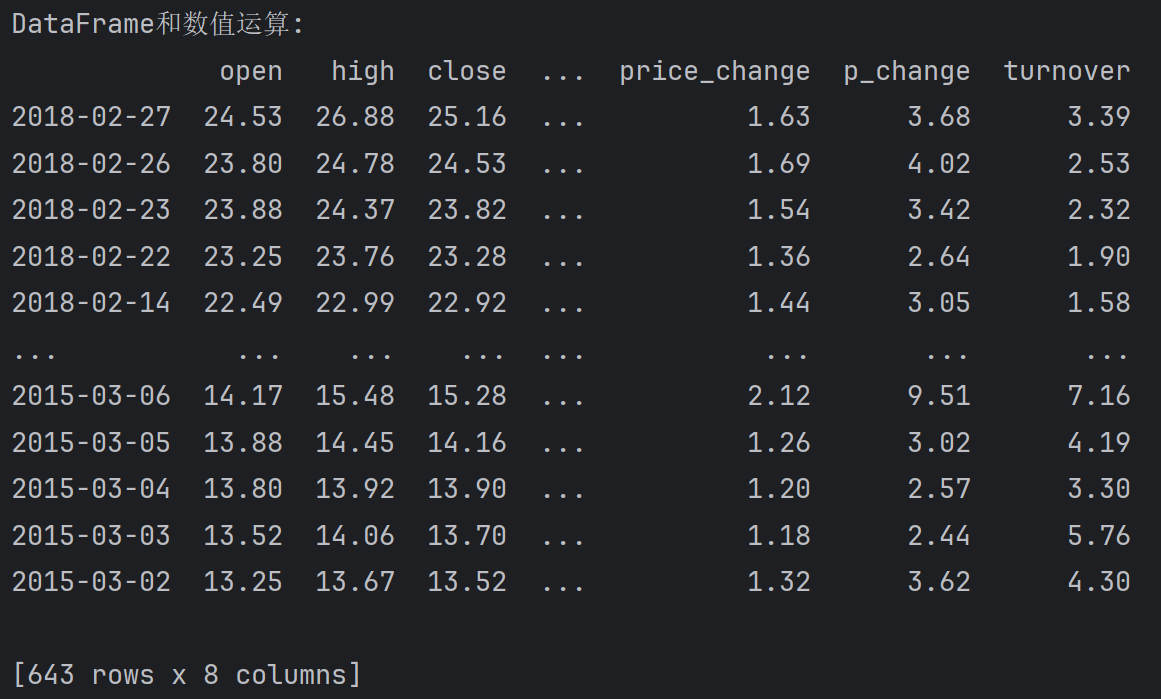
DataFrame和数值运算. DataFrame和数值运算, 发现: 数值会和DataFrame中的每个元素进行运算.
print(f'DataFrame和数值运算:\n{df + 1}')输出:
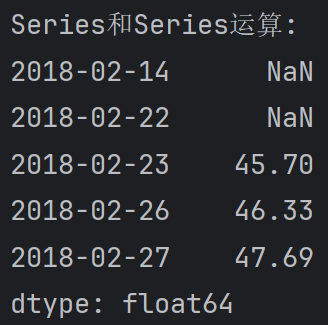
Series和Series运算, 对应元素进行计算, 不匹配的用NaN填充
# df.open
# df.close
# df.open + df.close
print(f'Series和Series运算:\n{df.open.head(5) + df.close.head(3)}')输出:
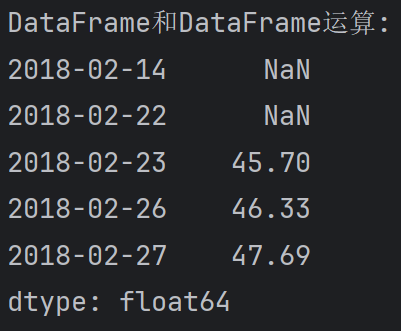
DataFrame和DataFrame运算, 对应元素进行计算, 不匹配的用NaN填充
print(f'DataFrame和DataFrame运算:\n{df.open.head(5) + df.close.head(3)}')输出:
逻辑运算符
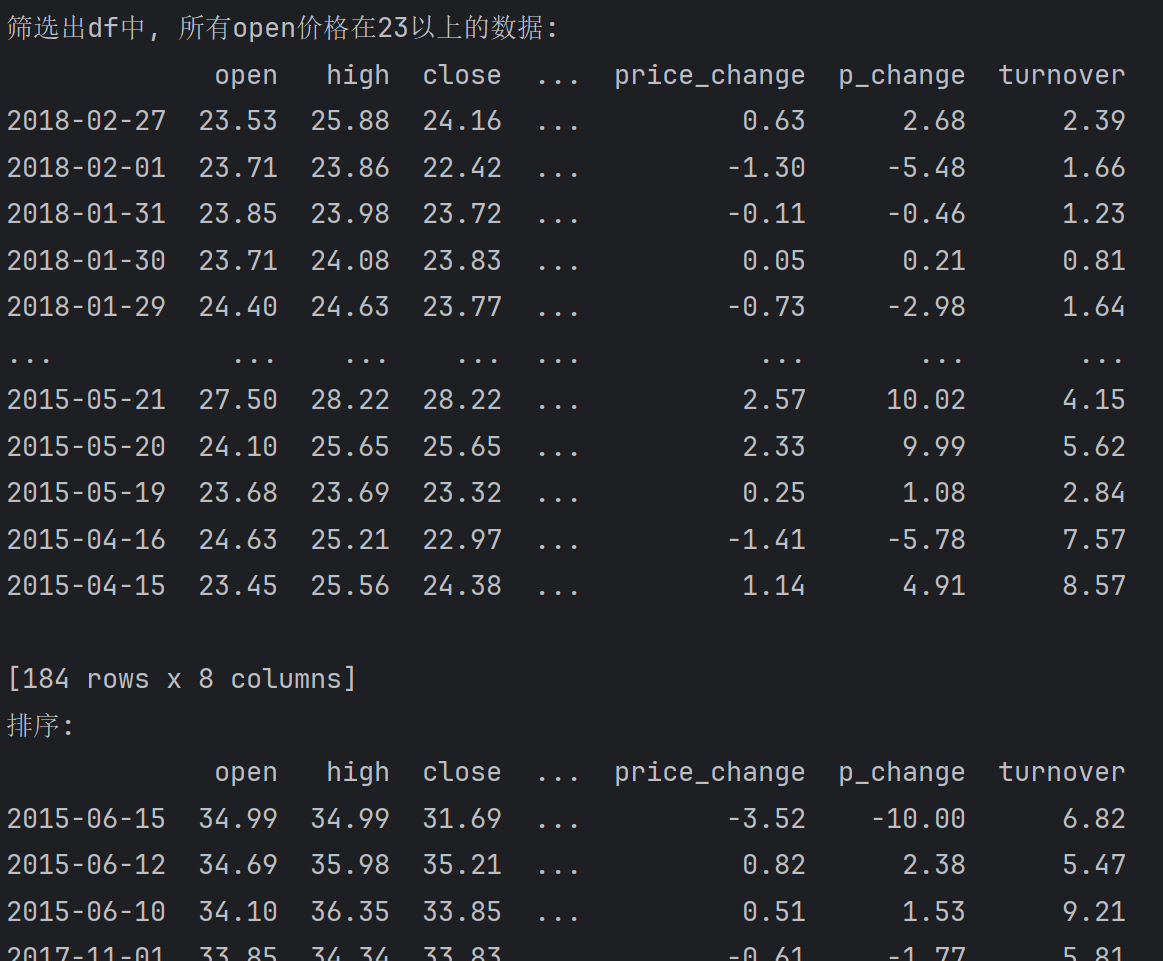
筛选出df中, 所有open价格在23以上的数据
print(f'筛选出df中, 所有open价格在23以上的数据:\n{df[df.open > 23]}')
# 排序
print(f'排序:\n{df[df.open>23].sort_values('open', ascending=False)}')
print(f'排序:\n{df[df.open>23].sort_values('open', ascending=True)}')输出:
筛选出df中, 所有open价格在[23, 24]之间的数据
print(f'筛选出df中, 所有open价格在[23, 24]之间的数据:\n{df[(df.open >= 23) & (df.open <= 24)]}')
# print(f'筛选出df中, 所有open价格在[23, 24]之间的数据:\n{df[(df['open'] >= 23) & (df['open'] <= 24)]}') # 效果同上输出:
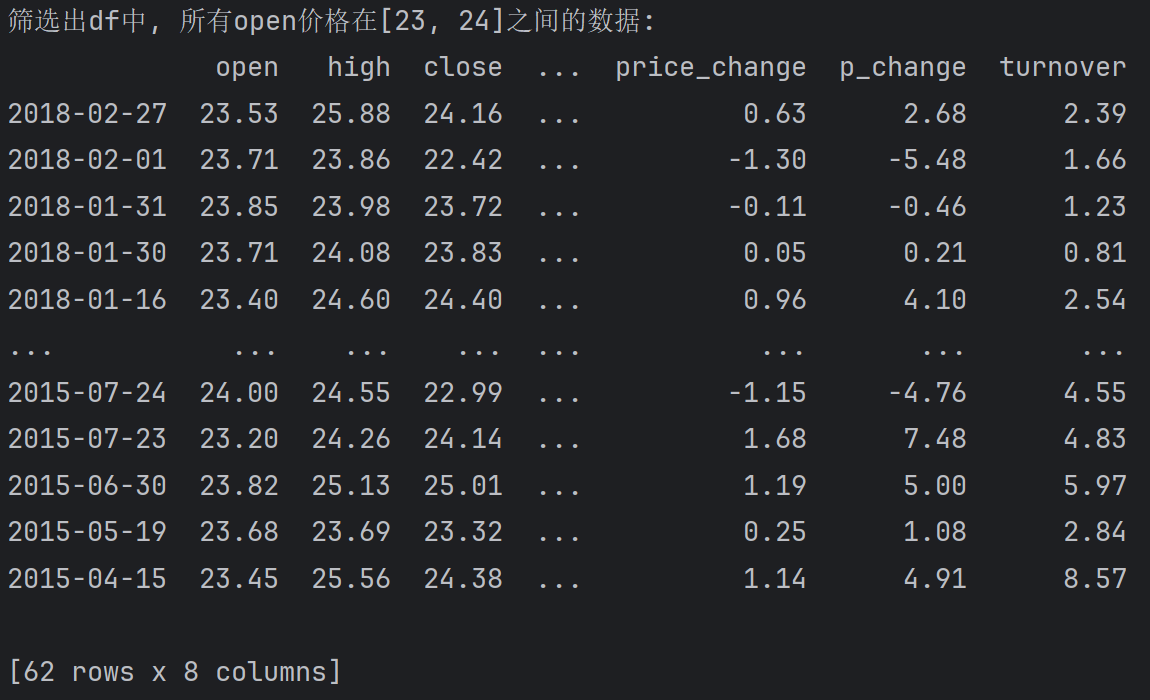
query(直接写比较表达式即可.)
筛选出df中, 所有open价格在[23, 24]之间的数据
print(f'筛选数据:\n{df.query('open>=23 & open<=24')}')
# print(f'筛选数据:\n{df.query('open>=23 and open<=24')}')输出:
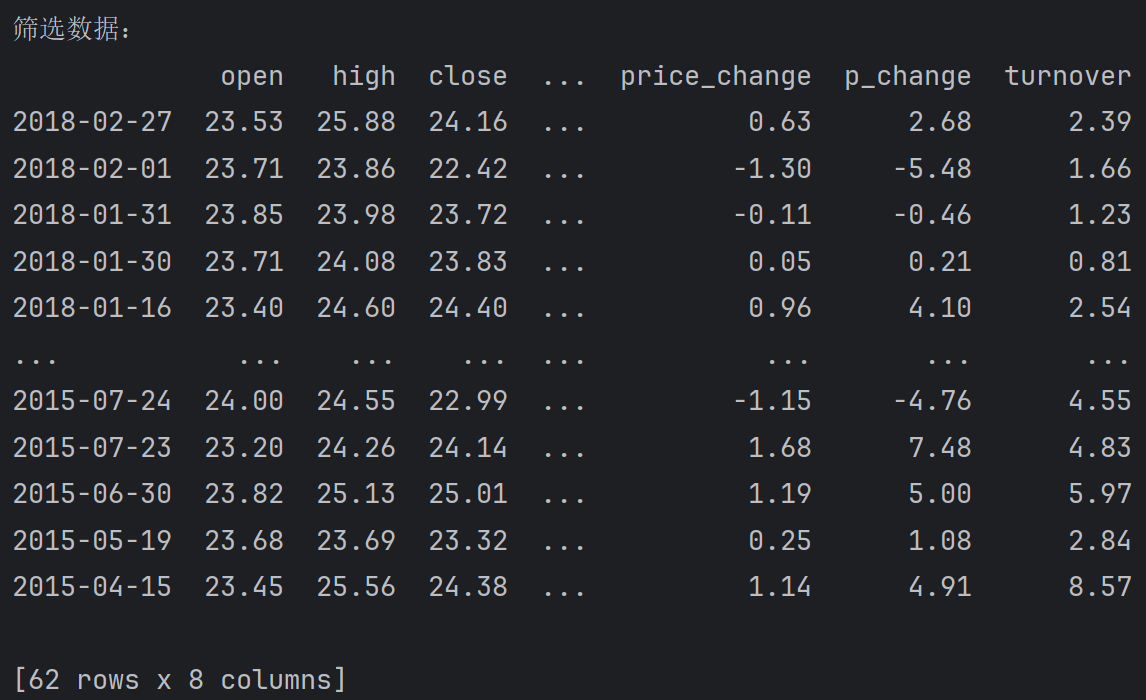
isin([值1, 值2....]) 判断是否是其中的任意1个值
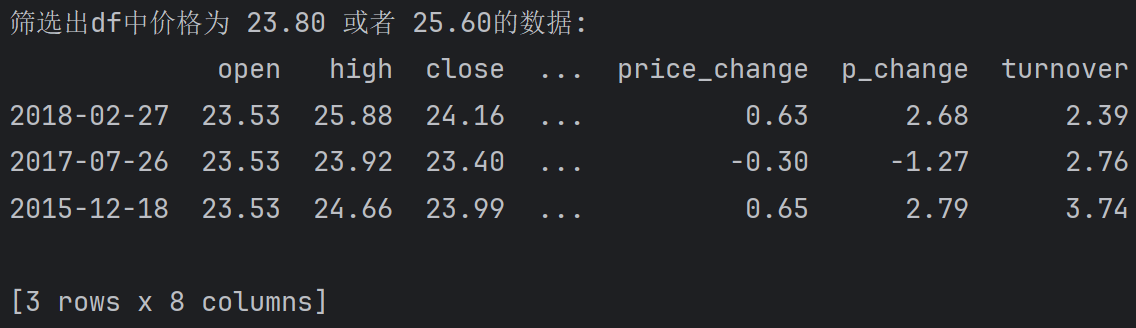
筛选出df中价格为 23.80 或者 25.60的数据.
print(f'筛选出df中价格为 23.80 或者 25.60的数据:\n{df[(df.open == 23.53) | (df.open == 25.60)]}')输出:
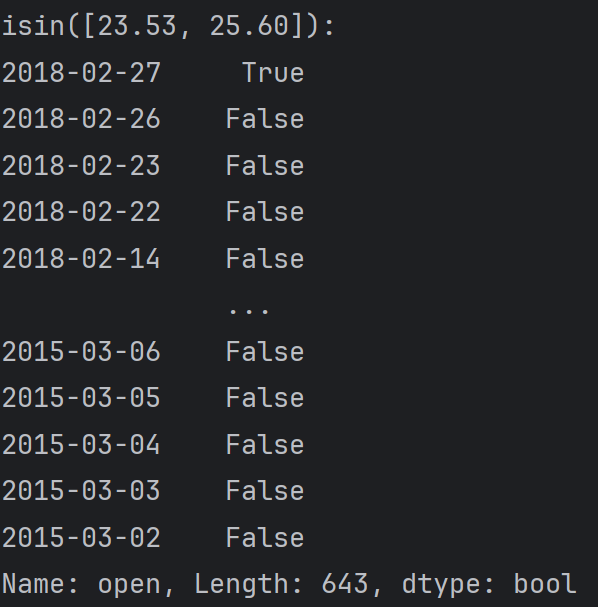
isin([值1, 值2....]) 是否是其中的任意某个值, 是:True 否:False
print(f'isin([23.53, 25.60]):\n{df.open.isin([23.53, 25.60])}')输出:
统计函数
print(f'统计函数:\n{df.describe()}')
print('-'*30)
print(f'详细信息:\n{df.info()}')
print('-'*30)
print(f'每列数据总条数:\n{df.count()}')
# print(f'每列数据总条数:\n{df.count(axis=0)}') # 效果同上
print('-'*30)
print(f'统计每行有多少列:\n{df.count(axis='columns')}')
print('-'*30)
print(f'统计每行有多少列:\n{df.count(axis=1)}')
# print(f'统计每行有多少列:\n{df.count(axis='rows')}')
print('-'*30)
# 查看每列最大值
print(f'查看每列最大值:\n{df.max()}')
# df.max(0) # 效果同上, 0->按列统计每列的最大值
# df.max(1) # 1->按行统计每行的最大值
# 查看每列平均值
print(f'查看每列平均值:\n{df.mean()}')
print('-'*30)
# df.std() # 标准差
# df.var() # 方差求中位数, 把数据从小到大排列, 取中间的那个数.->中位数, 如果没有中间数->取中间两个数的平均数
df = pd.DataFrame({
'col1': [2, 3, 4, 5, 4, 2], # 排序后是: 2,2,3,4,4,5
'col2': [0, 1, 2, 3, 4, 2] # 排序后是: 0,1,2,2,3,4
})
print(f'中位数:\n{df.median()}')
print('-'*30)
# 求最大值的位置
print(f'最大值位置:\n{df.idxmax(0)}') # 按列 统计每列的最大值所在的位置(即:行索引)
print(f'最大值位置:\n{df.idxmax(1)}') # 按行 统计每行的最大值所在的位置(即:列索引)
print('-'*30)
# 计算每列数据的累加和
print(f'计算每列数据的累加和:\n{df.cumsum()}')基本运算的完整代码+详细注释
import pandas as pd
df=pd.read_csv(r'C:\Users\victo\Desktop\人工智能学习 视频笔记\代码 阶段3 数据处理与统计分析\复现代码\U6 numpy与pandas基础\pandas\数据\stock_day.csv')
df.drop(['ma5', 'ma10', 'ma20', 'v_ma5', 'v_ma10', 'v_ma20'], axis=1, inplace=True)
print(f'数据准备:\n{df}')
print('-'*30)
# 1. 基础运算
# 需求1: 给open的列值增加 1, Series的运算, 发现:数值会和Series中的每个元素进行运算
# df.open+1 # 临时+1, 不修改源数据
df.open.add(1) # 效果同上,临时+1, 不修改源数据
# 修改源数据
df.open+=1
print(f'open列值增加1:\n{df}')
print('-'*30)
# 需求2: 给open的列值减少 1
df.open -= 1
print(f'open列值减少1:\n{df}')
# df.open - 1
# df.open.sub(1)
print('-'*30)
# 需求3: DataFrame和数值运算. DataFrame和数值运算, 发现: 数值会和DataFrame中的每个元素进行运算.
print(f'DataFrame和数值运算:\n{df + 1}')
print('-'*30)
# 需求4: Series和Series运算, 对应元素进行计算, 不匹配的用NaN填充
# df.open
# df.close
# df.open + df.close
print(f'Series和Series运算:\n{df.open.head(5) + df.close.head(3)}')
print('-'*30)
# 需求5: DataFrame和DataFrame运算, 对应元素进行计算, 不匹配的用NaN填充
print(f'DataFrame和DataFrame运算:\n{df.open.head(5) + df.close.head(3)}')
print('-'*30)
# 2. 逻辑运算符
# 需求1: 筛选出df中, 所有open价格在23以上的数据
print(f'筛选出df中, 所有open价格在23以上的数据:\n{df[df.open > 23]}')
# 排序
print(f'排序:\n{df[df.open>23].sort_values('open', ascending=False)}')
print(f'排序:\n{df[df.open>23].sort_values('open', ascending=True)}')
print('-'*30)
# 需求2: 筛选出df中, 所有open价格在[23, 24]之间的数据
print(f'筛选出df中, 所有open价格在[23, 24]之间的数据:\n{df[(df.open >= 23) & (df.open <= 24)]}')
# print(f'筛选出df中, 所有open价格在[23, 24]之间的数据:\n{df[(df['open'] >= 23) & (df['open'] <= 24)]}') # 效果同上
print('-'*30)
# query(直接写比较表达式即可.)
# 需求: 筛选出df中, 所有open价格在[23, 24]之间的数据
print(f'筛选数据:\n{df.query('open>=23 & open<=24')}')
# print(f'筛选数据:\n{df.query('open>=23 and open<=24')}')
print('-'*30)
# isin([值1, 值2....]) 判断是否是其中的任意1个值
# 需求: 筛选出df中价格为 23.80 或者 25.60的数据.
print(f'筛选出df中价格为 23.80 或者 25.60的数据:\n{df[(df.open == 23.53) | (df.open == 25.60)]}')
print('-'*30)
# isin([值1, 值2....]) 是否是其中的任意某个值, 是:True 否:False
print(f'isin([23.53, 25.60]):\n{df.open.isin([23.53, 25.60])}')
print('-'*30)
# 3. 统计函数
print(f'统计函数:\n{df.describe()}')
print('-'*30)
print(f'详细信息:\n{df.info()}')
print('-'*30)
print(f'每列数据总条数:\n{df.count()}')
# print(f'每列数据总条数:\n{df.count(axis=0)}') # 效果同上
print('-'*30)
print(f'统计每行有多少列:\n{df.count(axis='columns')}')
print('-'*30)
print(f'统计每行有多少列:\n{df.count(axis=1)}')
# print(f'统计每行有多少列:\n{df.count(axis='rows')}')
print('-'*30)
# 查看每列最大值
print(f'查看每列最大值:\n{df.max()}')
# df.max(0) # 效果同上, 0->按列统计每列的最大值
# df.max(1) # 1->按行统计每行的最大值
# 查看每列平均值
print(f'查看每列平均值:\n{df.mean()}')
print('-'*30)
# df.std() # 标准差
# df.var() # 方差
# 求中位数, 把数据从小到大排列, 取中间的那个数.->中位数, 如果没有中间数->取中间两个数的平均数
df = pd.DataFrame({
'col1': [2, 3, 4, 5, 4, 2], # 排序后是: 2,2,3,4,4,5
'col2': [0, 1, 2, 3, 4, 2] # 排序后是: 0,1,2,2,3,4
})
print(f'中位数:\n{df.median()}')
print('-'*30)
# 求最大值的位置
print(f'最大值位置:\n{df.idxmax(0)}') # 按列 统计每列的最大值所在的位置(即:行索引)
print(f'最大值位置:\n{df.idxmax(1)}') # 按行 统计每行的最大值所在的位置(即:列索引)
print('-'*30)
# 计算每列数据的累加和
print(f'计算每列数据的累加和:\n{df.cumsum()}')
print('-'*30)
本文围绕Pandas核心基础操作展开,系统梳理了数据读写、数据操作及基本运算三大核心模块,通过带详细注释的实例,直观呈现了关键功能的实现逻辑。数据读写部分掌握CSV/TSV等格式的读写参数配置,可实现数据的高效导入导出;数据操作聚焦loc/iloc索引、行列增删改及排序等核心技巧,是数据筛选与整理的核心能力;基本运算则涵盖元素级运算、逻辑筛选与统计分析,为数值计算与数据洞察提供支撑。这些操作是Pandas数据分析的基石,初学者通过实操本文案例,能快速掌握DataFrame与Series的核心用法。后续可基于这些基础,深入学习分组聚合、数据透视表等进阶功能,逐步提升数据分析实战能力,应对更复杂的业务场景。




















 7455
7455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












