




 该博客介绍了如何使用Hadoop MapReduce解决实际问题,通过案例展示了如何找出每个学生的最高分和平均分。在最高分的计算中,详细解释了map、reduce函数及驱动类的实现。在平均分的计算部分,利用KeyValueTextInputFormat处理数据,同样展示了map、reduce函数的运用及其运行结果。
该博客介绍了如何使用Hadoop MapReduce解决实际问题,通过案例展示了如何找出每个学生的最高分和平均分。在最高分的计算中,详细解释了map、reduce函数及驱动类的实现。在平均分的计算部分,利用KeyValueTextInputFormat处理数据,同样展示了map、reduce函数的运用及其运行结果。
案例一
现有三个文件,分别放置五个学生三门学科成绩
如下图所示,需要通过mapreduce程序,找出每一个学生的最高分和平均分
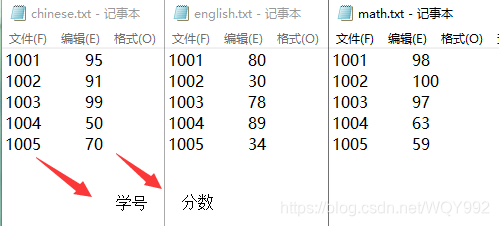
最高分
map函数
public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
StringTokenizer st = new StringTokenizer(value.toString());
while(st.hasMoreTokens()){
Text sid = new Text(st.nextToken());
IntWritable score = new IntWritable(Integer.parseInt(st.nextToken()));
context.write(sid, score);
}
}
}
reduce函数
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritab


















(找最高分,平均分)&spm=1001.2101.3001.5002&articleId=90552653&d=1&t=3&u=8359763582ee4ae6b3dd66e49cebdd54)
 2691
2691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










