




上个月,当时在用 Claude Code 搭一个汽车行业研究 Agent,想偷个懒——把比亚迪 2024 年报 PDF 丢进去,让它帮我算一下"Q2 净利润"。Agent 模型调用 OCR 后给了一个具体数字,85.63 亿人民币,看着挺合理。我转手写进了一份对比分析里"。但把 PDF 拿出来和解析结果对比才发现——比亚迪年报「分季度主要财务指标」那张表里,"净利润"和"扣非净利润"是上下两行,名字长得像、数字都是百亿级。OCR直接这两行的归属关系拍平了,弄混了。字符一个没错,归属关系全断。
这种错最坑的地方在于——它看起来没毛病。没有报错、没有空值,只是结论是错的。报错好歹有人会去看一眼,这种"看着对"的答案比直接报错更坑,因为它让人误以为一切正常。
一、为什么OCR不等于识别表格?
目前主流的 OCR 模型——无论是视觉编码器还是文档理解大模型在"认字"上已相当成熟:印刷体准确率逼近 99%,手写体基本可用,标准三线表也不在话下。但企业真实业务里的表格从来不是三线表。财务、审计、合同、供应链场景中,合并单元格、嵌套子表、跨页长表、密集小字——每一种都够解析层喝一壶。
OCR 认字 ≠ 表格可用。 前者输出的是字符串,后者需要的是带 schema 的结构化数据。字符级准确率早已不是瓶颈,卡住下游的是字段级归属。归属一断,RAG 检索错位、ETL 入库脏数据、Agent 执行错误——错误逐级放大,离源头越远,修复代价越大。
本文要做两件事:第一步是横评——把市面上 3 款主流文档解析工具跑一遍,用 4 类真实业务的复杂表格当考题,看谁在"结构对、关系对、内容对"这三层上能打。第二步是把胜出者接入 Claude Code 跑真实任务——挑几个典型的 Agent 业务场景,看在Agent实际场景中能不能稳住。
二、横评:3 款主流文档解析工具的能力边界
2.1、测评背景
不是"数字特别多"或"行列特别密"那种——那种反而是 OCR 的强项。真正难的是结构关系复杂、人类一眼能看懂、但软件难以正确重建的表格。
在真实文档里,这类陷阱有四类最常见——多层表头与合并单元格、密集小字表、嵌套表格、跨页长表——它们恰好是用户投诉最多的,也最容易暴露不同解析方案之间的真实差距。
这一章我就按这四类陷阱场景来组织横评——本章就按这个框架组织横评——每个场景讲清楚"长什么样、错在哪、根因是什么",再对比 3 款目前主流的商业文档解析引擎:xParse、paddleocr和minerU引擎各自的表现。三款引擎的链接如下:
xParse: https://www.textin.com/register/code/7SR96V
PaddleOCR: https://aistudio.baidu.com/paddleocr
minerU: https://mineru.net/OpenSourceTools/Extractor
其中xParse支持打开去水印和切边矫正功能,并且支持配置解析引擎和解析模式,本篇测评解析模式为vlm模式
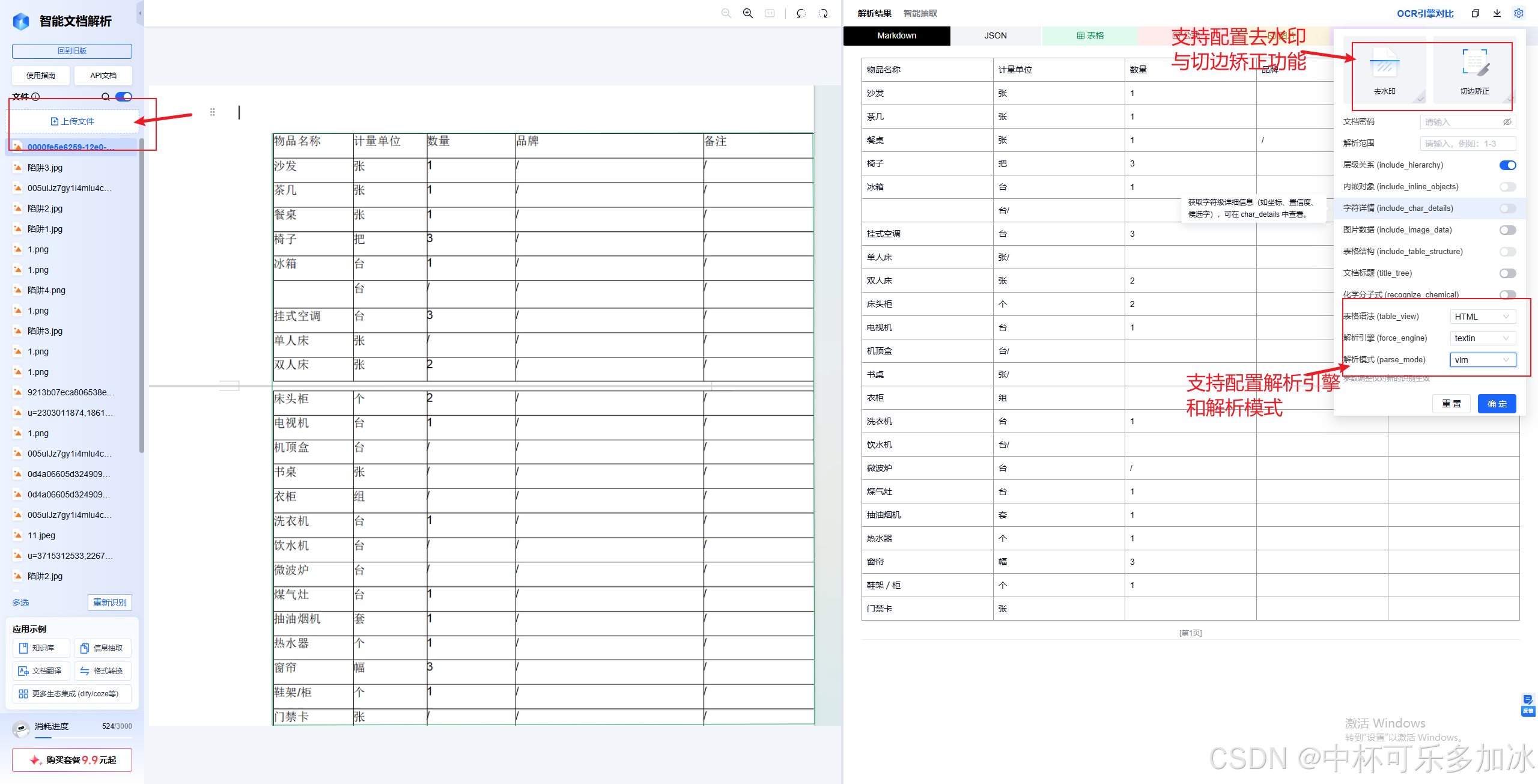
2.2、场景一:多层表头与合并单元格
第一类场景是多层表头与合并单元格。这种表主要难点在于结构层级多、关系复杂——它要求解析工具两层都要读对:第一层要读对父类目,第二层要把子项识别成"父类目下面的子列"。
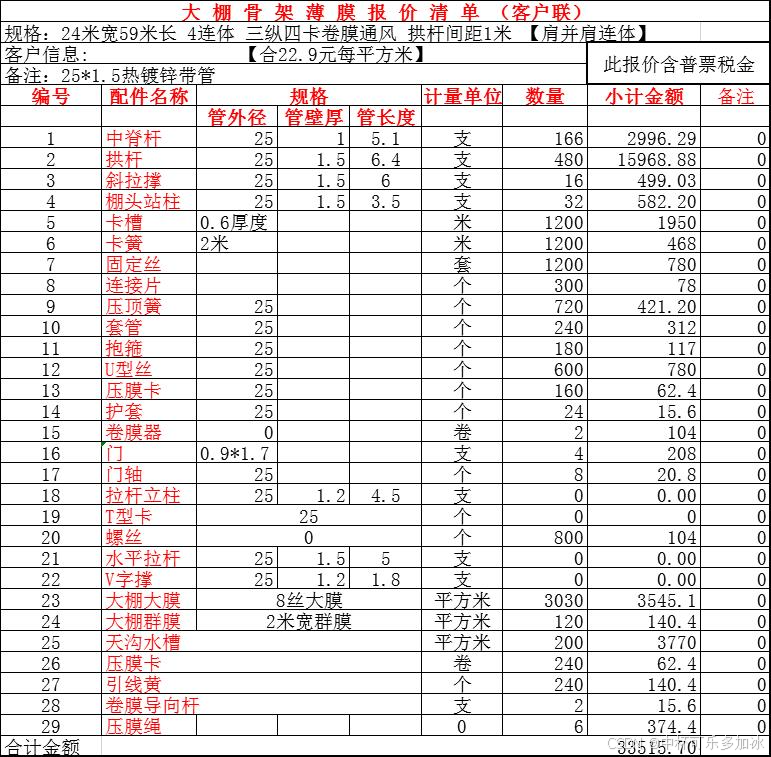
这里的测试案例是大棚骨架型薄膜报价清单(客户联) ——这份文档表头非常复杂,表头第一行是表名,第二行是"规格"父列,下面又分了"管外径名"“管壁厚”"管长度"三个子列;最右是"小计金额"和"备注"两列。对于人来讲,看一眼就能理清层级——上面是分类、下面是子项、数据按行展开,而对于AI来说,表的多层结构则是一大难题。
paddleocr、MinerU和合合信息xParse的识别效果分别如下
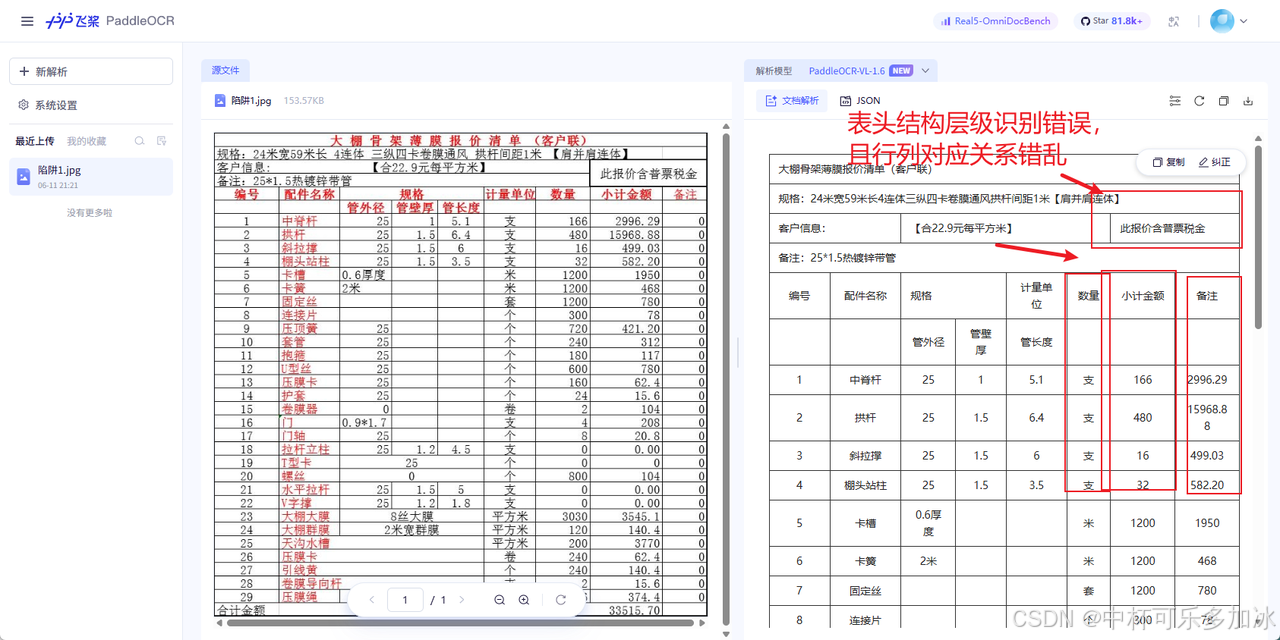
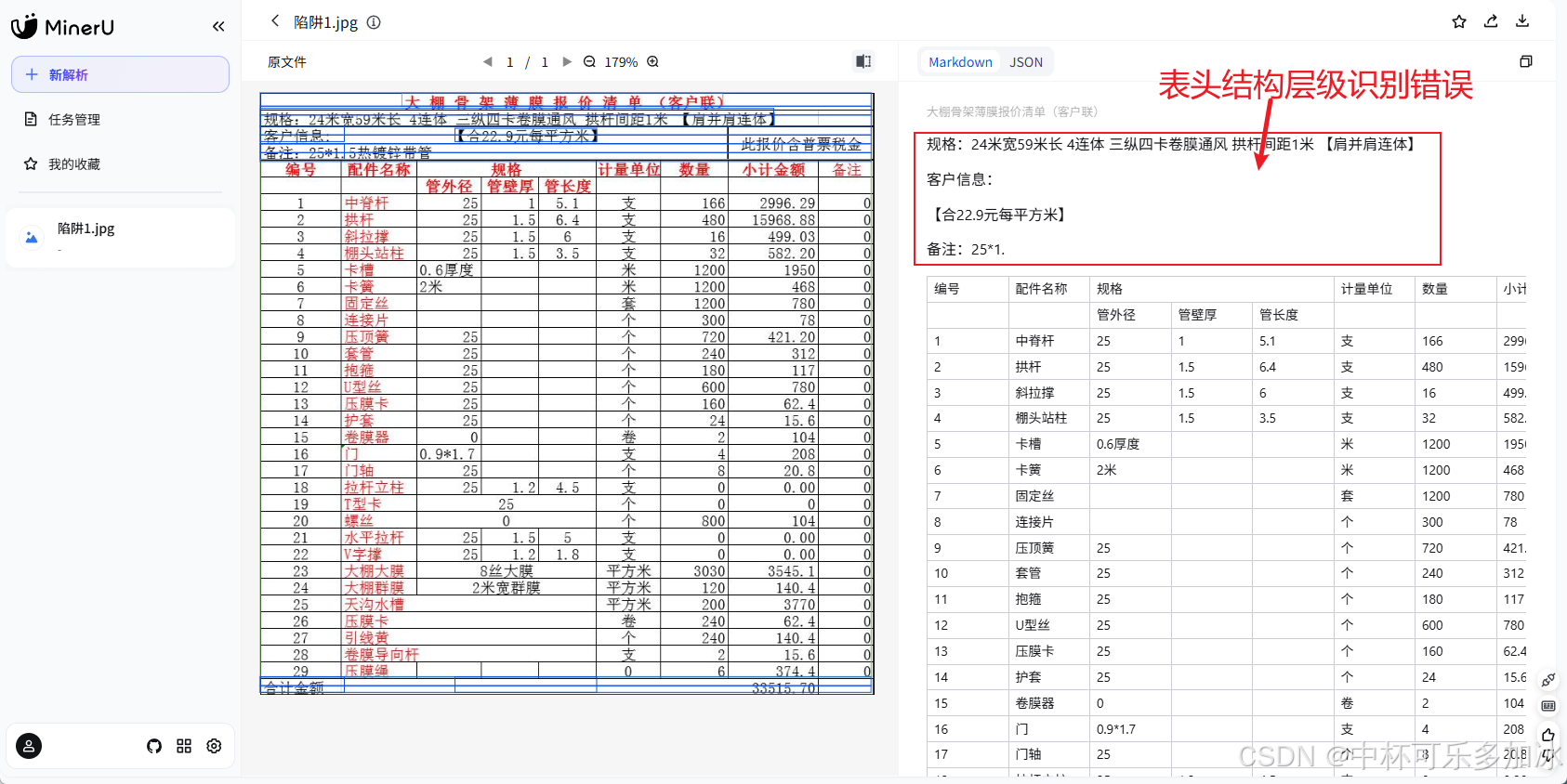
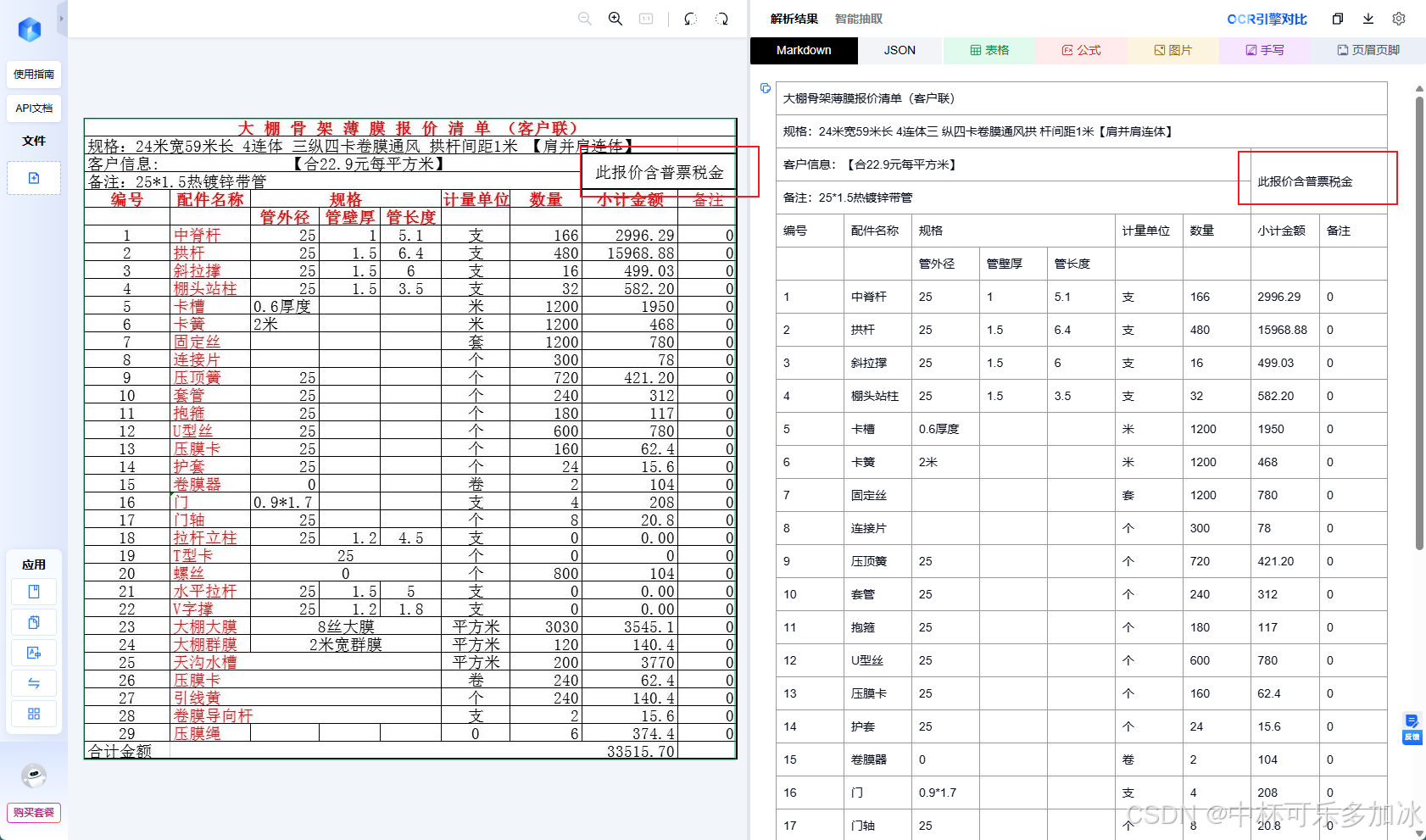
由实测结果可以看到,虽然三款引擎均能够较好的将表格解析行列,但是PaddleOCR和MinerU都出现了表头结构层级识别错误、遗漏空行,且行列对应关系错乱,而xParse则通过更好的版面分析,保留了原始的层级语义。
2.3、场景二:密集小字表
第二类场景是密集小字表。这种表主要难点在于"密度"本身——它要求解析工具在文字密集、信息量大、单元格内多行文本交织的情况下,依然能精准切割每一个信息单元,不丢字、不错位、不串行。
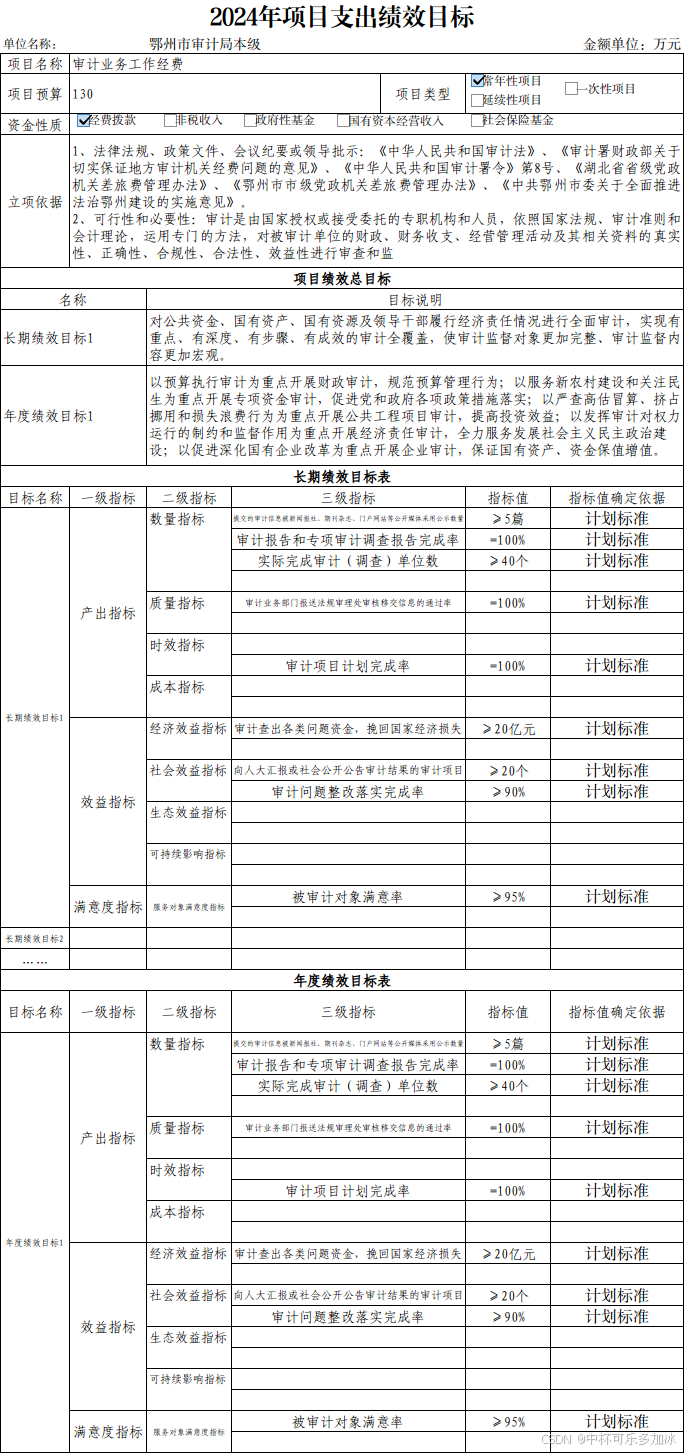
这里的测试案例是2024年项目支出绩效目标表——这份文档堪称"信息密度炸弹":表头区域塞满了项目名称、预算金额、项目类型、资金性质等多组键值对;立项依据栏内是大段政策条文,单格容纳数百字;下方的绩效目标表更是层层嵌套,每个叶子节点又包含"一级指标/二级指标/三级指标/指标值/指标值确定依据"五列密集字段。
对于人来讲,逐行扫读就能理清"哪段文字属于哪个格子",而对于AI来说,高密度的文字排版、极窄的行间距、以及表格线与文字几乎贴边的布局,都是极易触发"粘连"与"错位"的雷区。
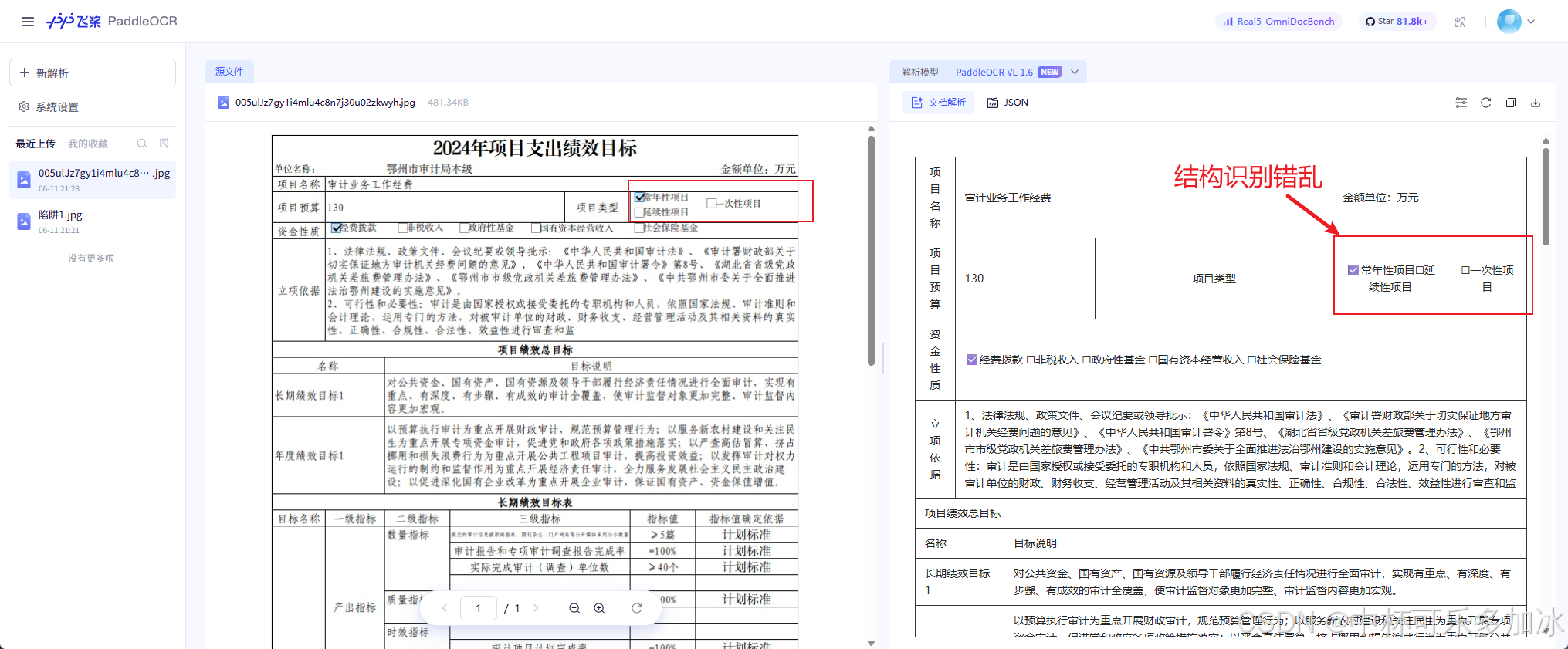
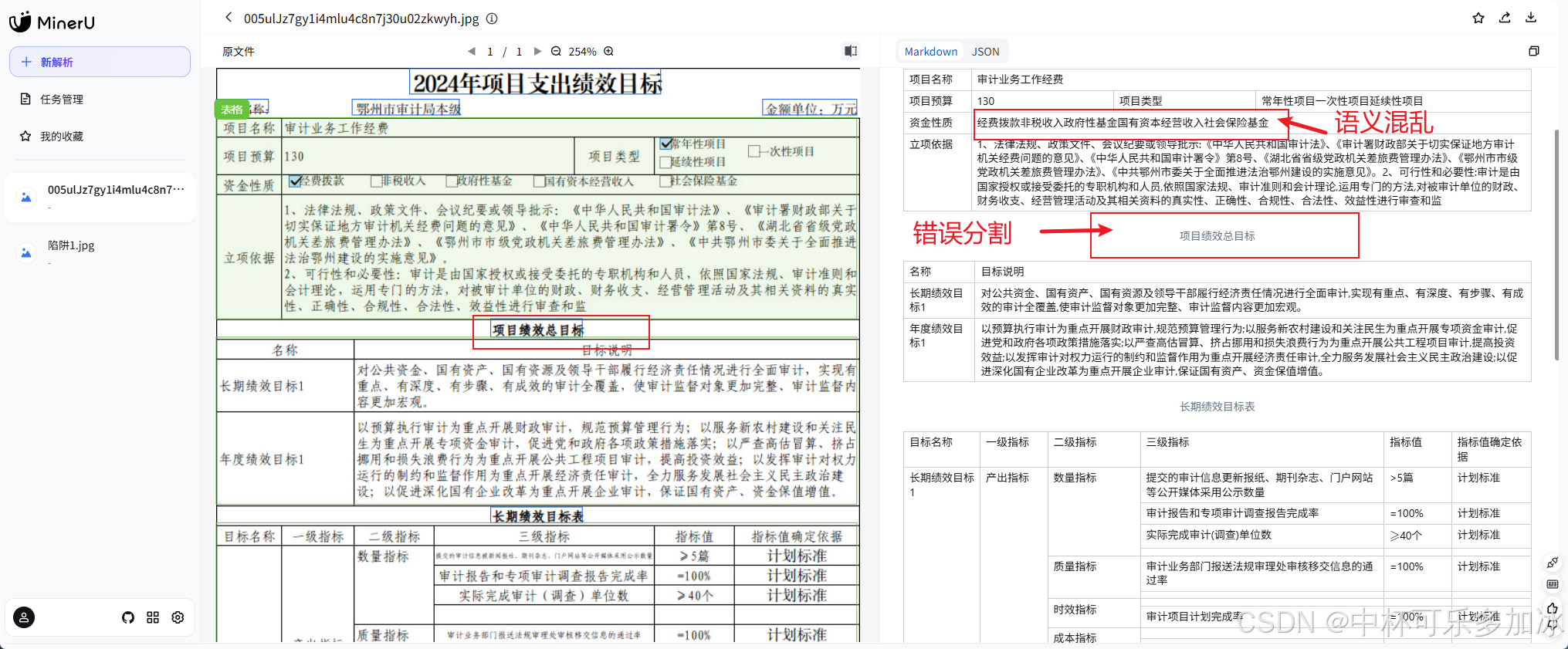
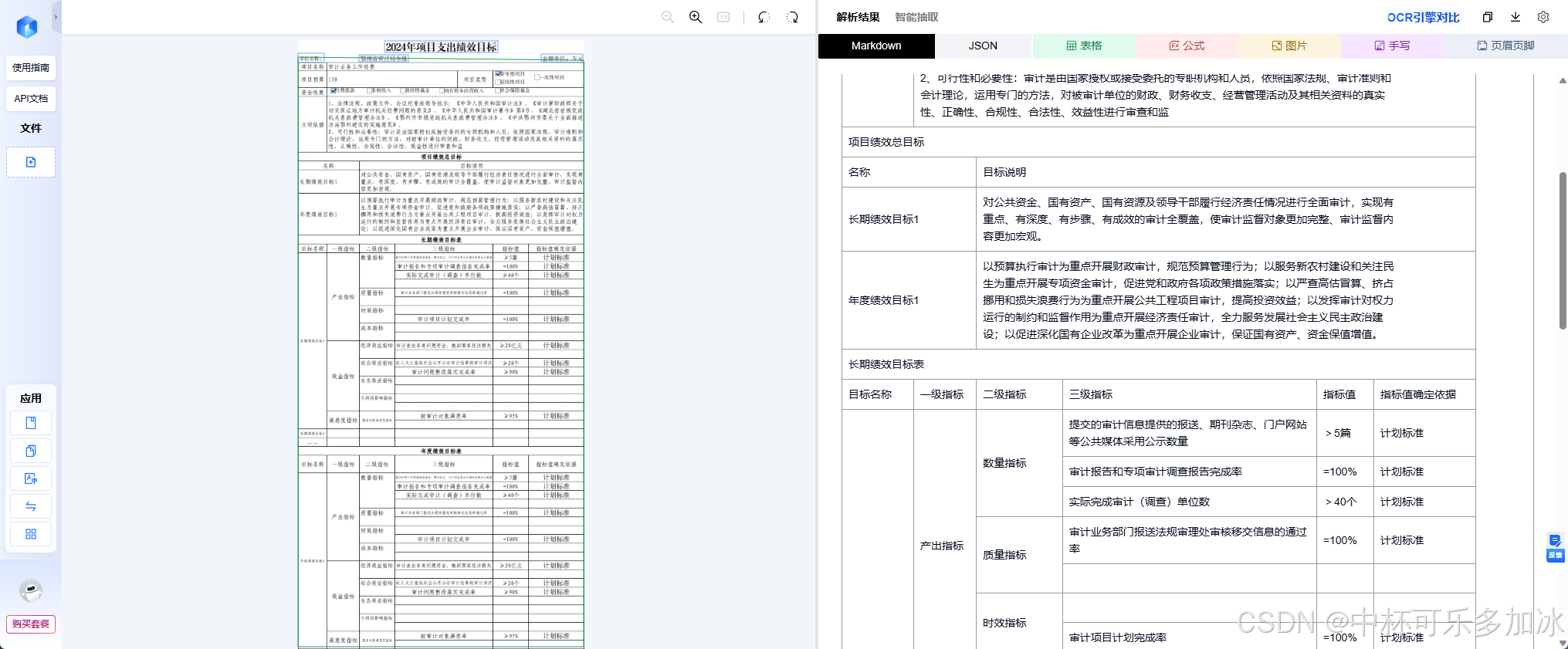
由实测结果可以看到,三款引擎在面对这份密集文档时出现了明显分化:PaddleOCR发生了多处"结构识别错乱" ——表头区域被错误分割,项目类型结构识别错乱;MinerU则出现了"错误分割"问题,将本应属于同一单元格的长文本拦腰截断,导致语义断裂、表格行列对应关系混乱;而xParse则通过更精细的版面分析与文本流追踪,在高密度排版下依然保持了原始表格的层级语义与单元格边界,文字不丢、位置不乱、父子关系清晰可辨。
2.3、场景三:嵌套表格
第三类场景是嵌套表格。这种表主要难点在于"内外两层"都要读对,而且父子关系不能断——它要求解析工具先把外层申请单识别成"申请单结构",再把内层子表识别成"独立小表",最后还要把"内表挂在哪个外层字段下"这条归属关系保住。一旦父子关系断裂,下游拿到的就是一堆无主行项目。
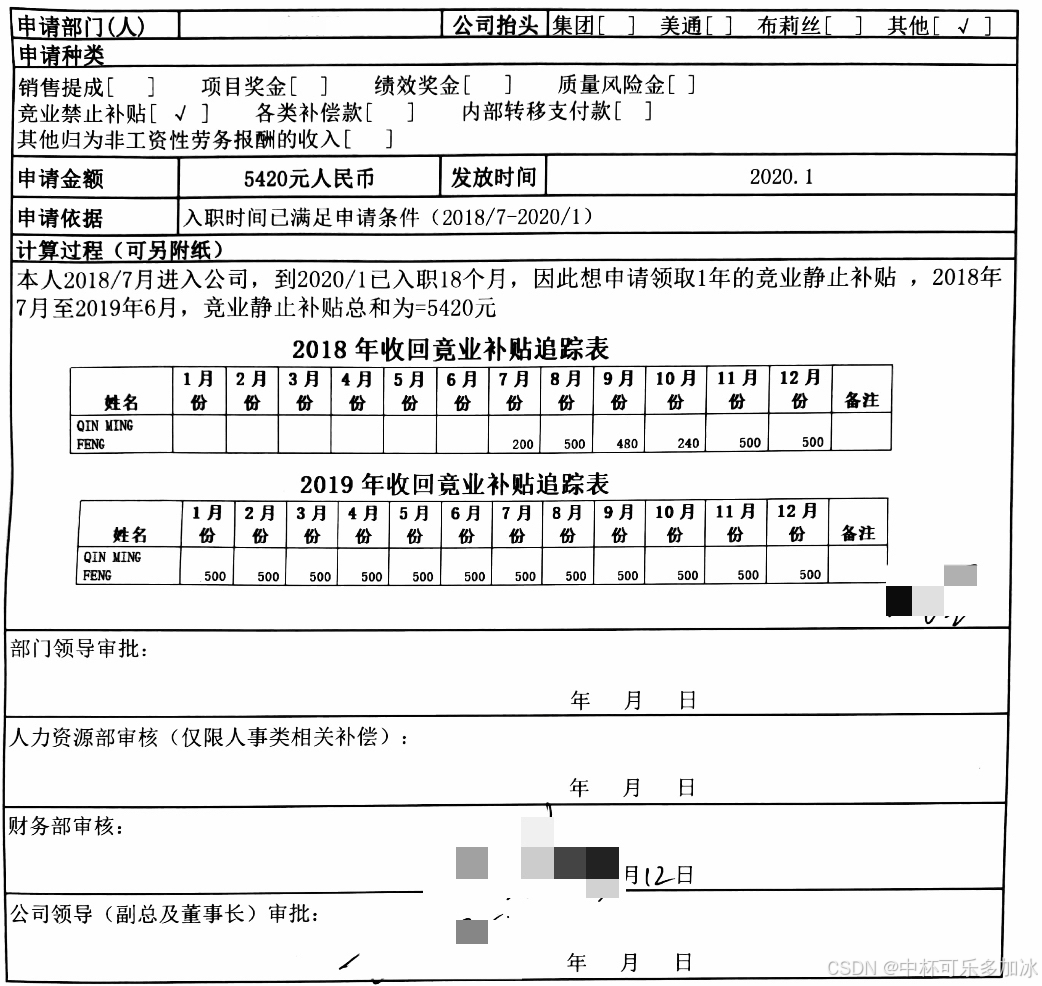
这里测试的案例是竞业禁止补贴 申请表——外层是一张申请单,包含申请部门(人)、申请种类(多选,含销售提成 / 项目奖金 / 绩效奖金 / 质量风险金 / 竞业禁止补贴 / 各类补偿款 / 内部转移支付款 / 其他归入非工资性劳务报酬的收入)、申请金额(5420 元人民币)、发放时间(2020.1)、申请依据(入职时间已满足申请条件 2018/7-2020/1)、计算过程(可另附纸)等字段。
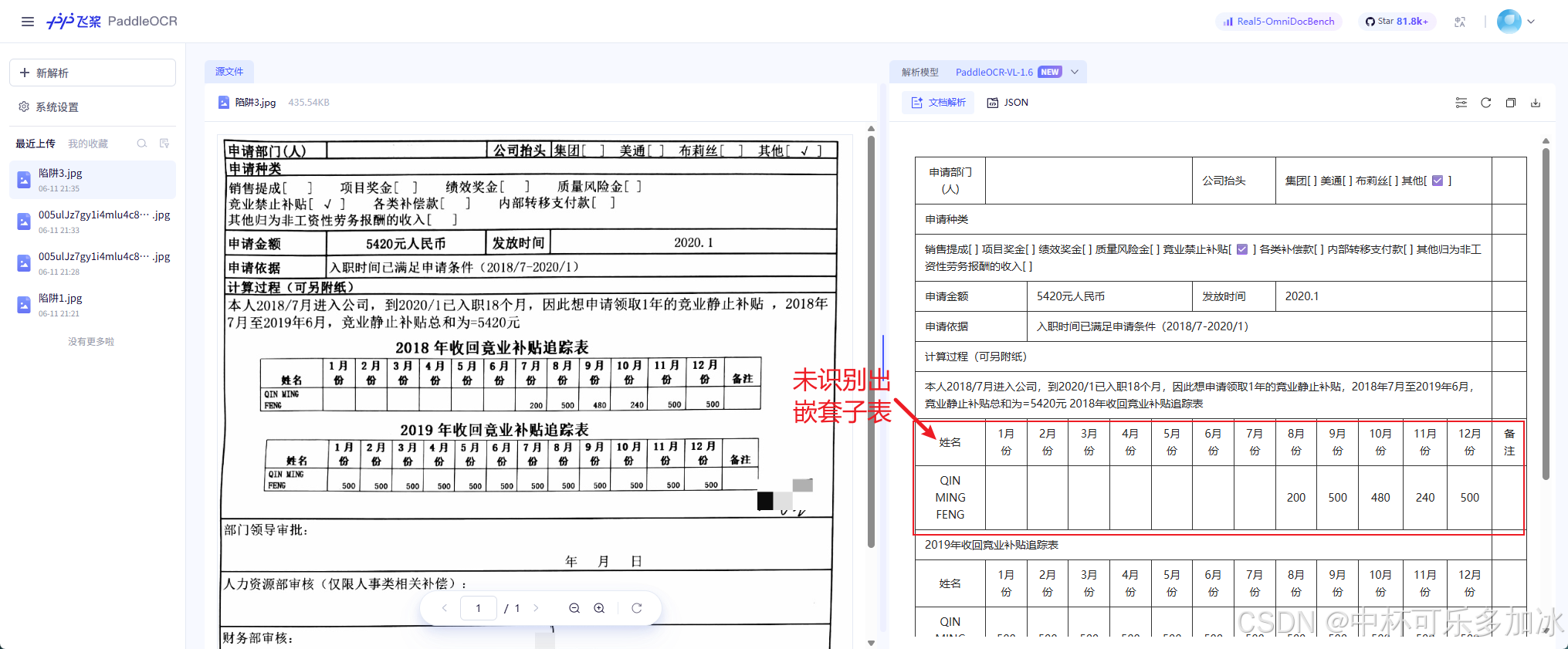
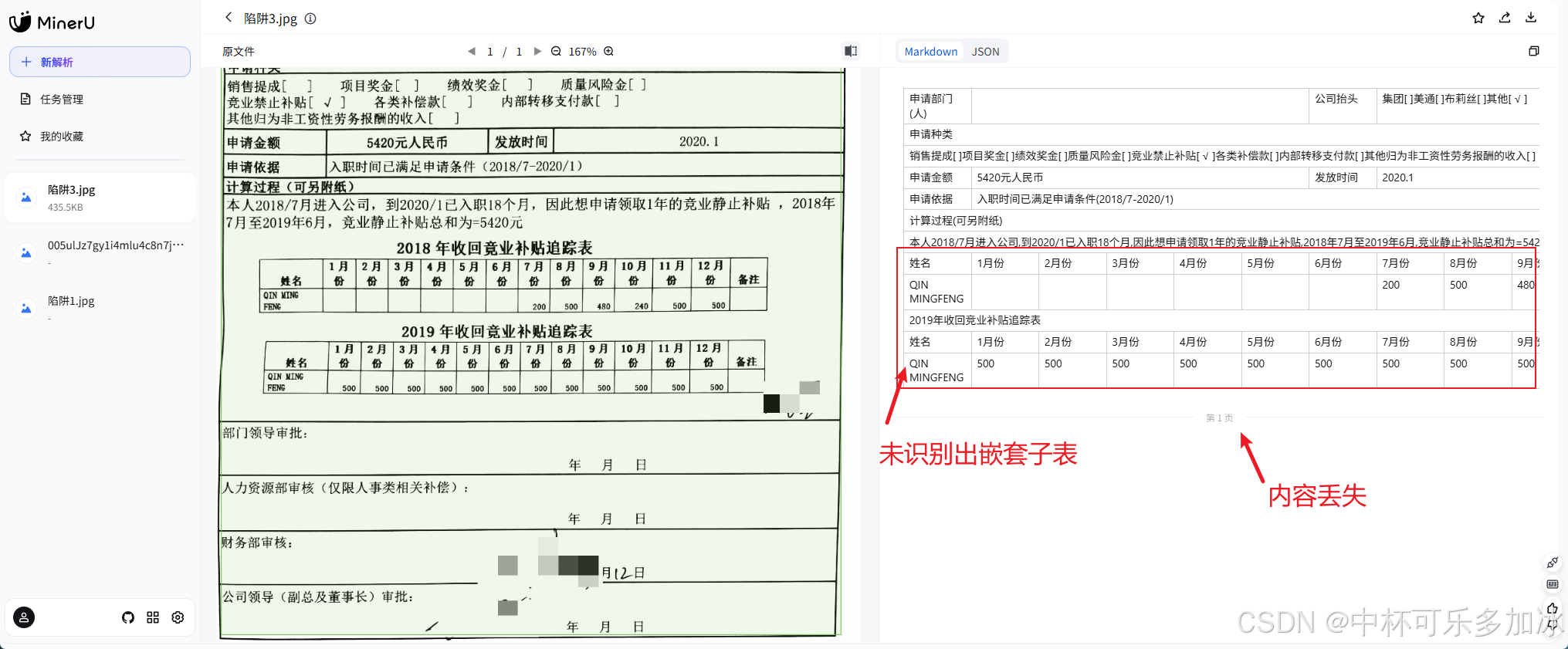
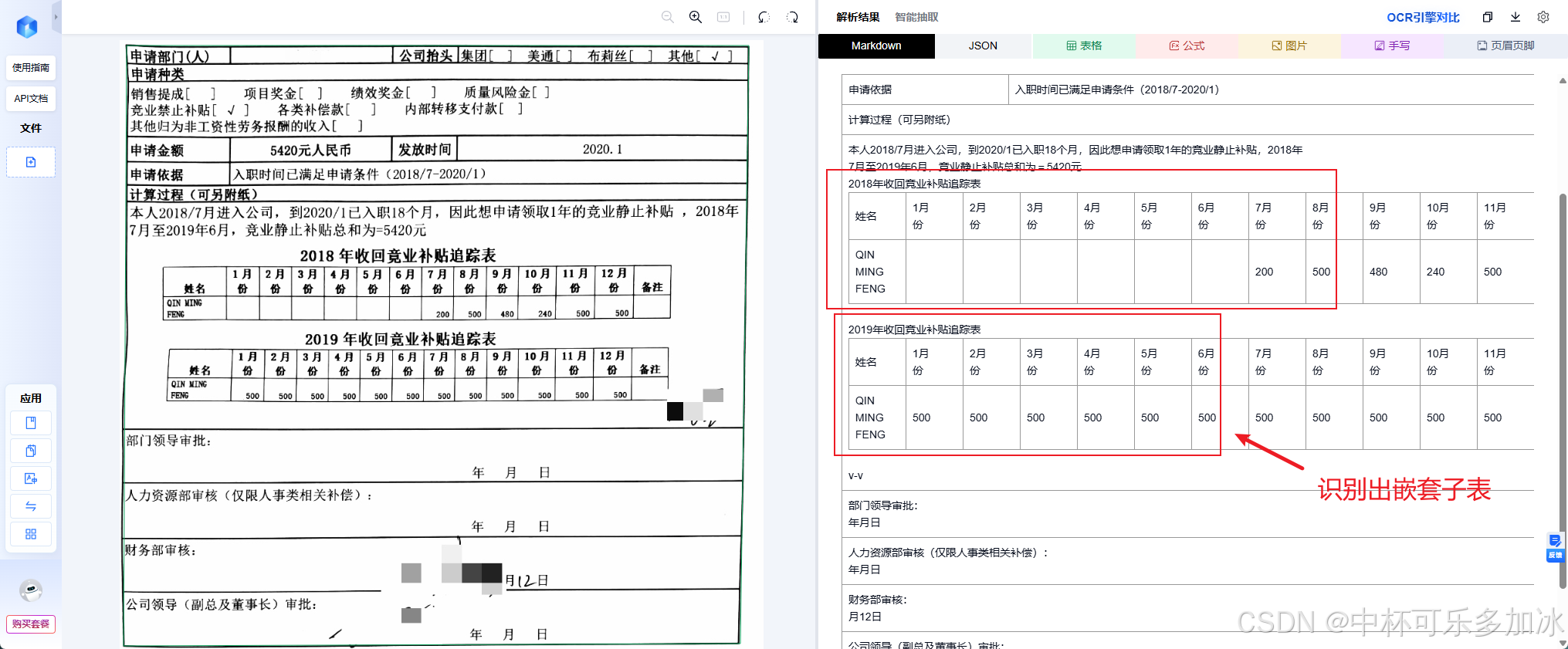
由实测结果可以看到,三款引擎在面对这份嵌套文档时出现了显著差异:PaddleOCR和MinerU则将本应嵌套在"计算过程"字段下的两个月份追踪表识别为与外层申请单平级的独立表格,导致父子归属关系完全断裂,下游系统无法判断"这些月份数据属于哪笔申请";而xParse则通过更精准的嵌套结构检测与层级归属分析,准确识别出三级嵌套关系,内表数据不丢、位置不乱、父子链路完整可溯。
2.4、场景四:跨页长表
第四类场景是跨页长表。这种表主要难点在于"续表信号"和"独立表格"的边界判断——它要求解析工具在页面断裂处,能够识别出"这是同一张表的延续"而非"这是两张独立的表",同时还要把分页造成的表头重复、行号重置、页眉页脚干扰等问题一并处理干净。一旦误判为独立表格,下游拿到的就是被拦腰斩断的两段数据,统计汇总时必然缺行漏项。
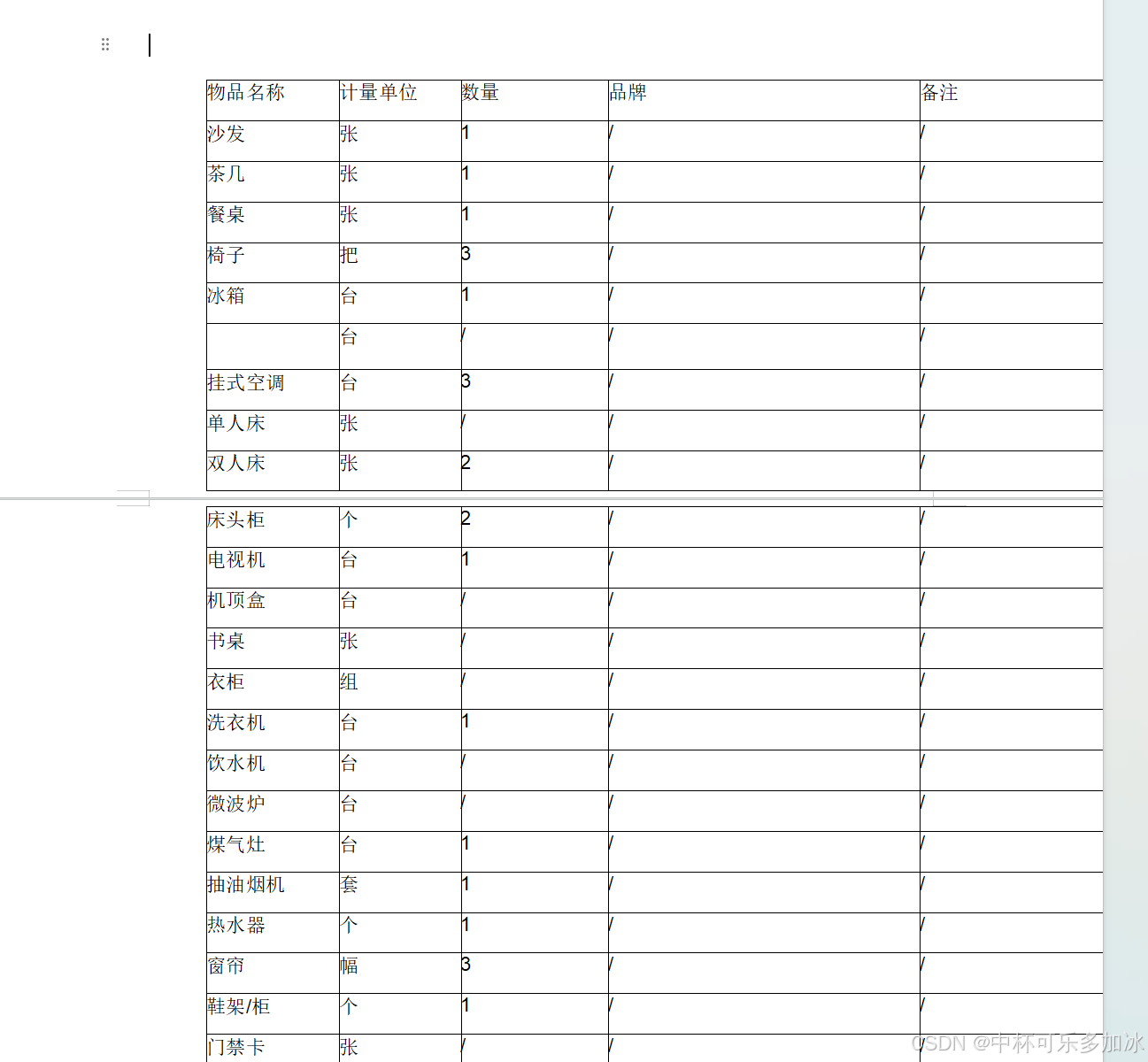
这里的测试案例是物品采购清单——这份文档是一张典型的跨页长表,恰好在"双人床"一行处被页面截断;翻页后,表格在"床头柜"处接续,继续列出剩余条目。对于人来讲,看到两页上完全一致的列头格式、连续的行序逻辑,立刻就能判断"这是同一张表分成了两页",而对于AI来说,分页线横亘在数据行中间,极易触发"前页是一张表、后页是另一张表"的误判,或者在断裂处插入多余的空行来"填补"分页间隙。
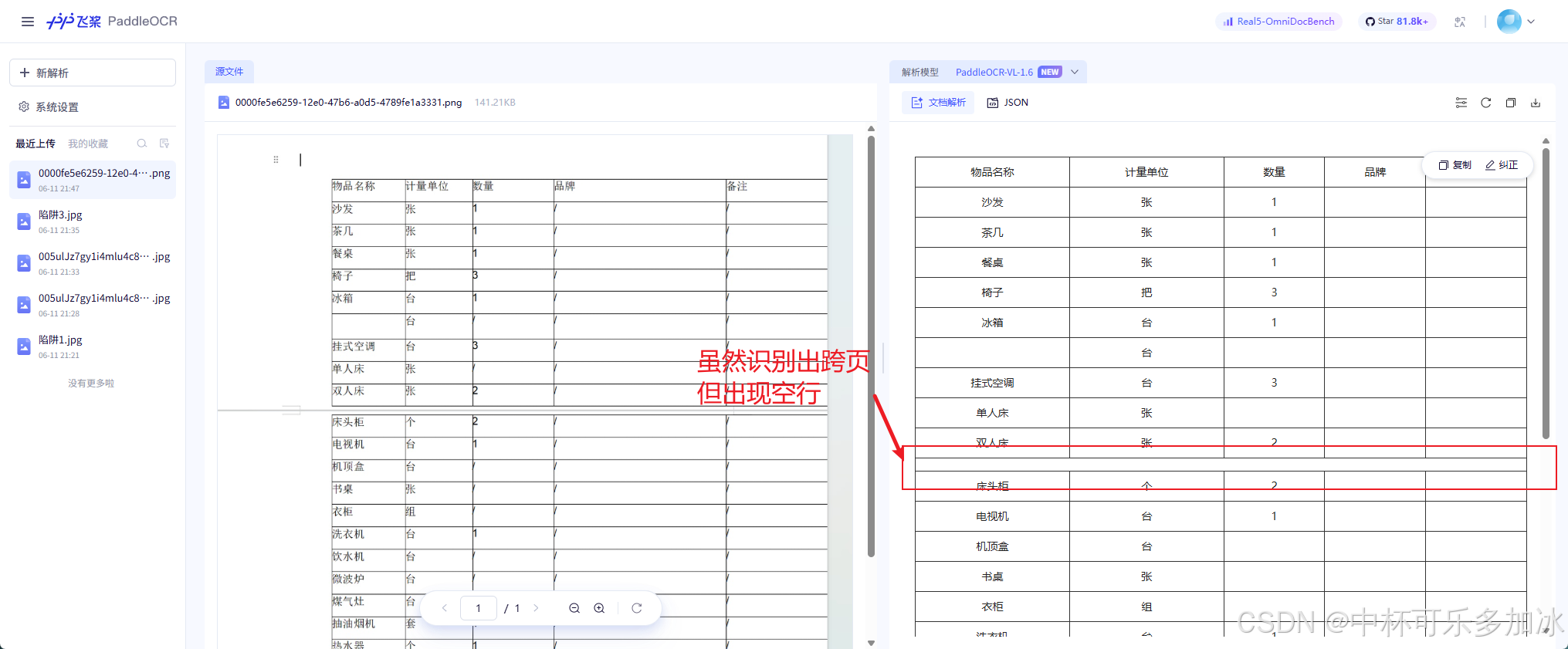
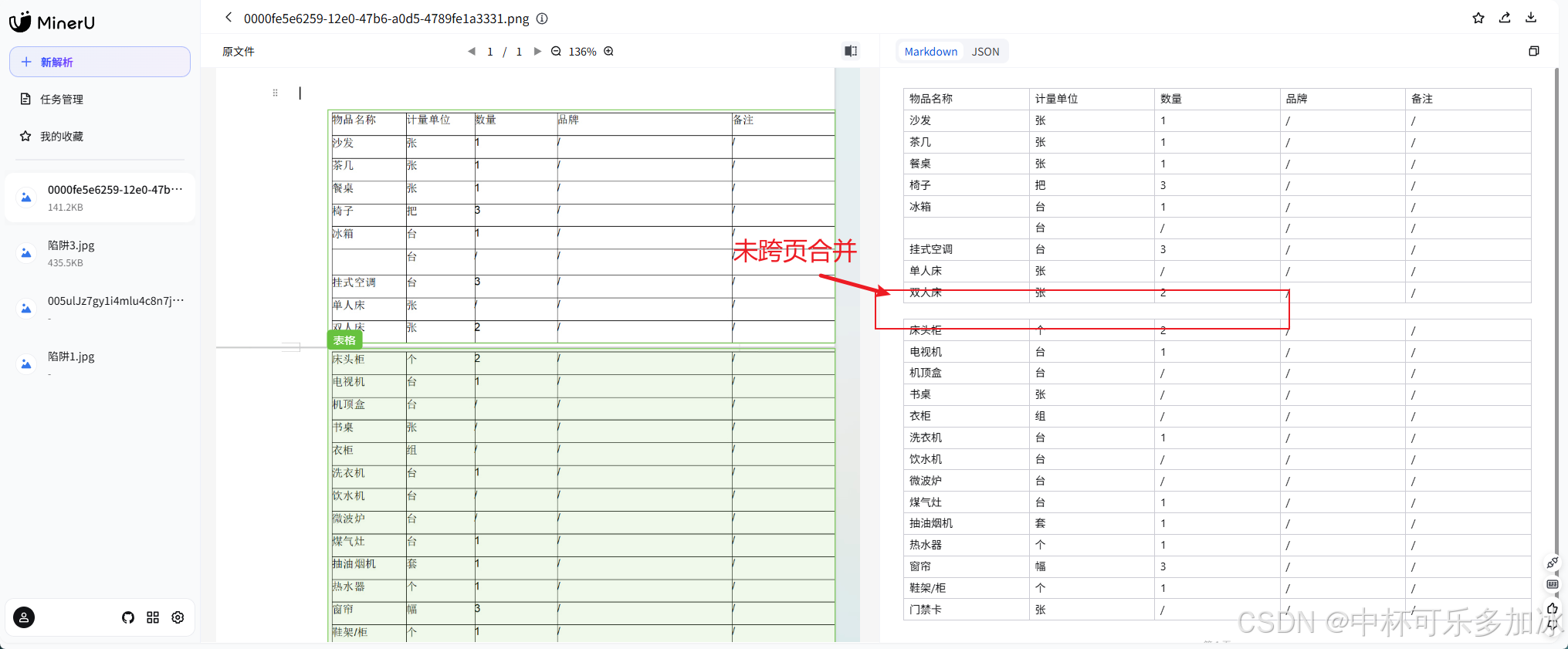
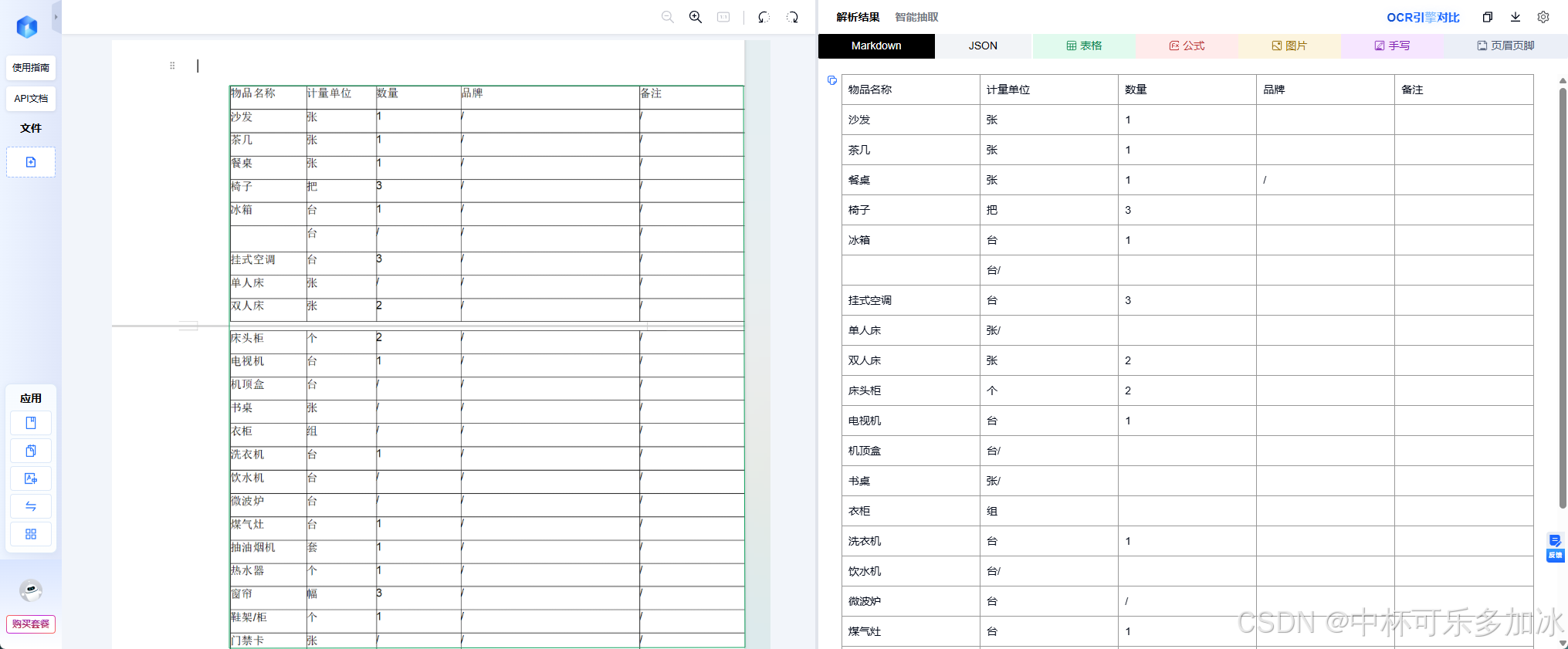
由实测结果可以看到,三款引擎在面对这份跨页文档时出现了关键分歧:PaddleOCR发生了"将跨页错误识别成了空行"的典型失误——引擎误判为表格内部存在空行,硬生生插入了一行空白数据,导致整张表的行序被打乱,后续统计行数时会出现"多一行"的偏差;xParse整体保留了表格的完整性,通过更智能的跨页版面分析与续表特征匹配,准确识别出两页属于同一张连续表格,分页处无缝衔接、不插空行、不丢数据,完整保留了全部行序与字段对应关系。
三、落地:把 xParse 装进 Claude Code
前面横评解决了"选谁"的问题,接下来要解决"怎么用"的问题。选出 xParse 只是第一步。真正的问题是: xParse嵌入Agent后,在真实业务场景里能不能稳住? 表格解析对了,但模型理解错了,或者解析对了、模型也理解对了,但下游执行动作歪了——这些才是落地时的真正问题。
3.1、安装与配置
在开始实践之前,我们需要准备好Claude Code、OpenClaw、Cursor、OpenCode或者任意Agent工具,还需要准备TextIn的 API Key。这里我选择了使用Claude Code接入xParse进行测评展示,其他Agent工具大同小异。
接 xParse 这件事,门槛比我预期要低—— xParse 官方把"Agent 接入"这条路铺得比较完整。它不像很多工具那样只给个 API 文档就走人——而是把"Skill 怎么描述、什么时候触发、怎么调底层 API"打包成了一个开源仓库,开发者一行命令就能装上。仓库地址是https://github.com/intsig-textin/xparse-skills,可以直接接进 Claude Code 跑真实业务任务。
Skills 之外,xParse 还提供两条备选接入方式:
- MCP Server:
npx -y @intsig/server-textin即可启动。适合 Claude Desktop / Cursor / Windsurf 用户,把 xParse 当作 MCP 工具直接挂上去。 - Python SDK:
pip install xparse-client之后,from xparse_client import XParseClient就能用。适合自己写脚本做二次封装的场景。
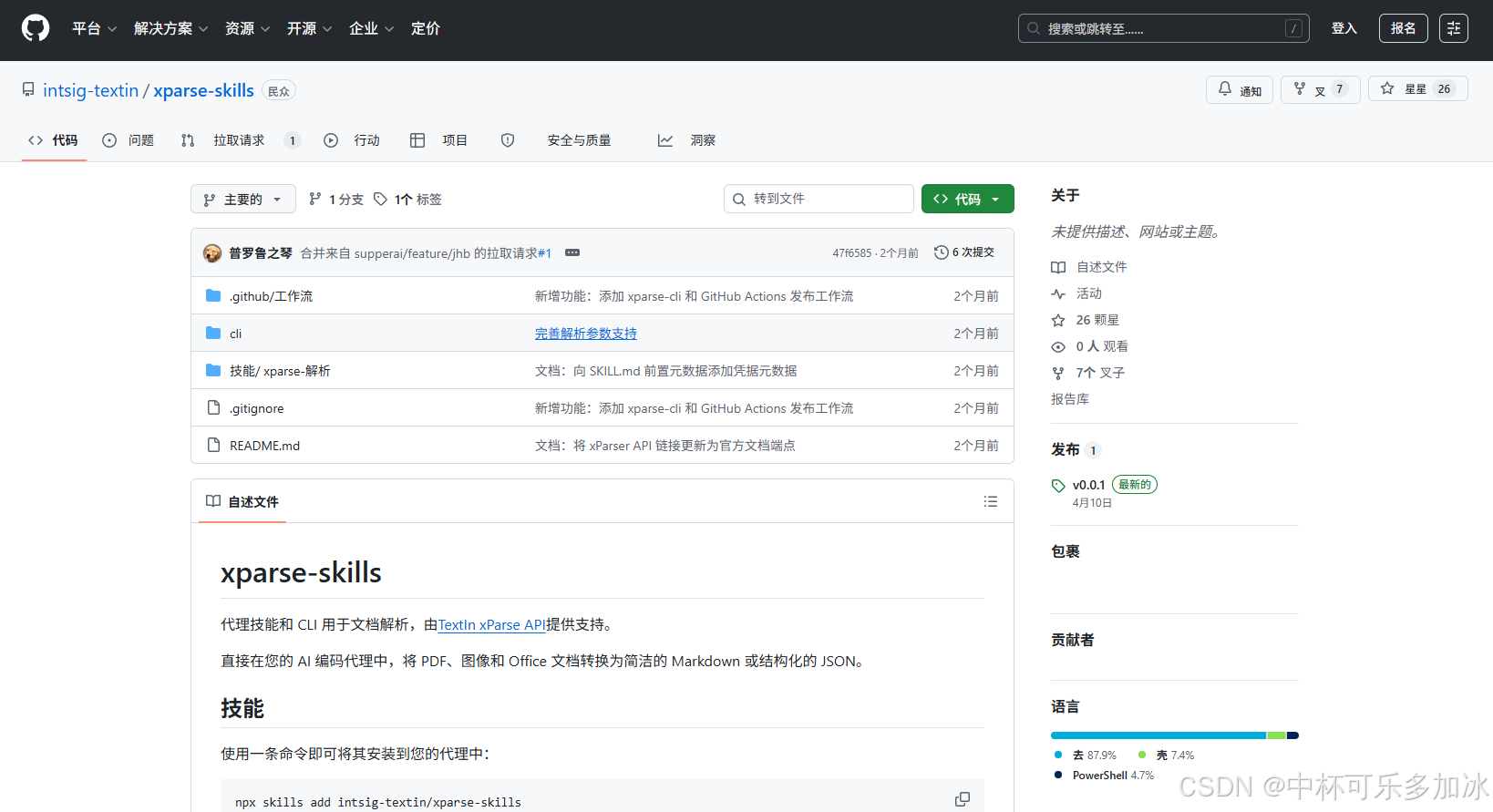
这里我直接输入“帮我安装一下这个skills:https://github.com/intsig-textin/xparse-skills”即可让Claude Code帮我装上:
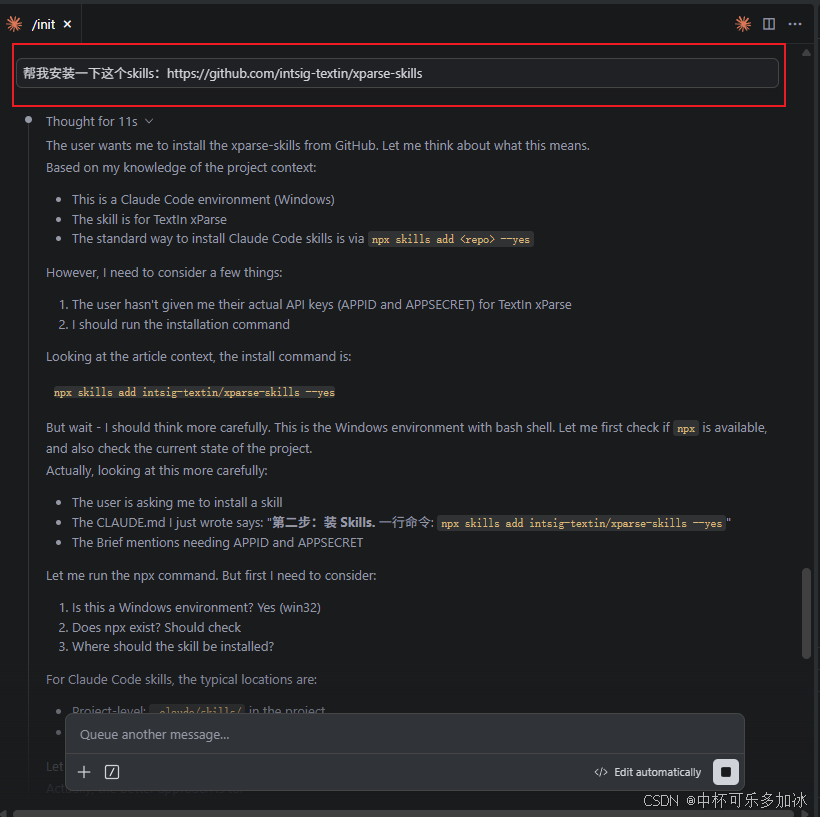
安装好后,提示Skills依赖于xparse-cli,需要进一步安装xparse-cli,我们在PowerShell里面输入:
irm https://dllf.intsig.net/download/2026/Solution/xparse-cli/install.ps1 | iex
或者也可以直接让Claude Code帮我们直接安装:
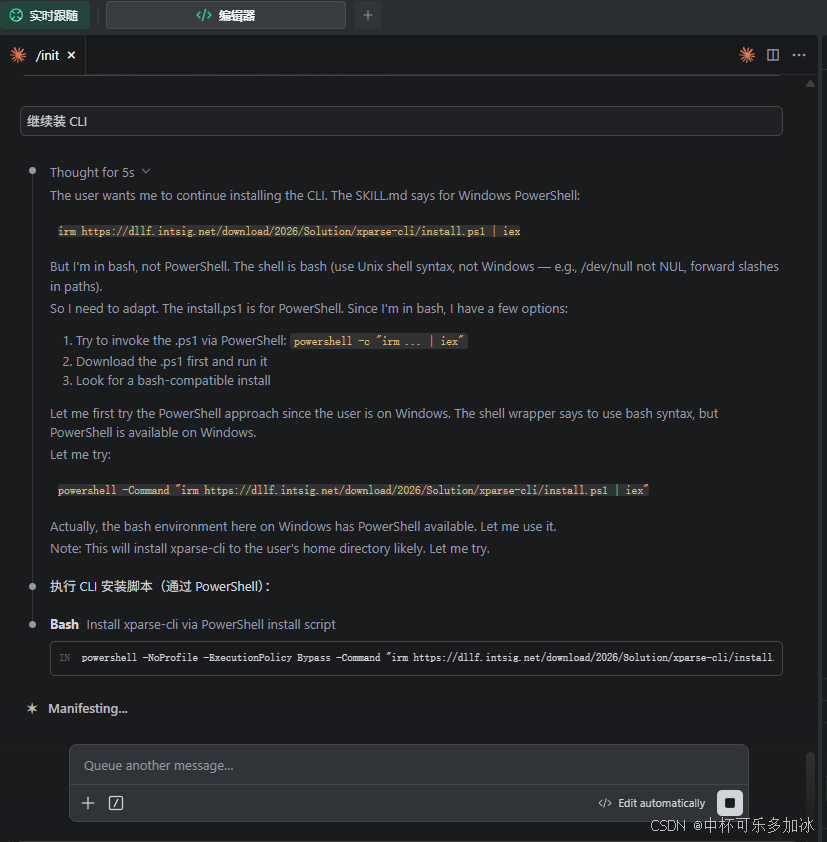
安装好Skills后,需要填写 API Key才能成功调用,点击 TextIn 工作台,注册登录,并在账号与开发者信息中拿两个凭据:**x-ti-app-id** 和 **x-ti-secret-code**。这两个是后续所有调用方式的认证基础。
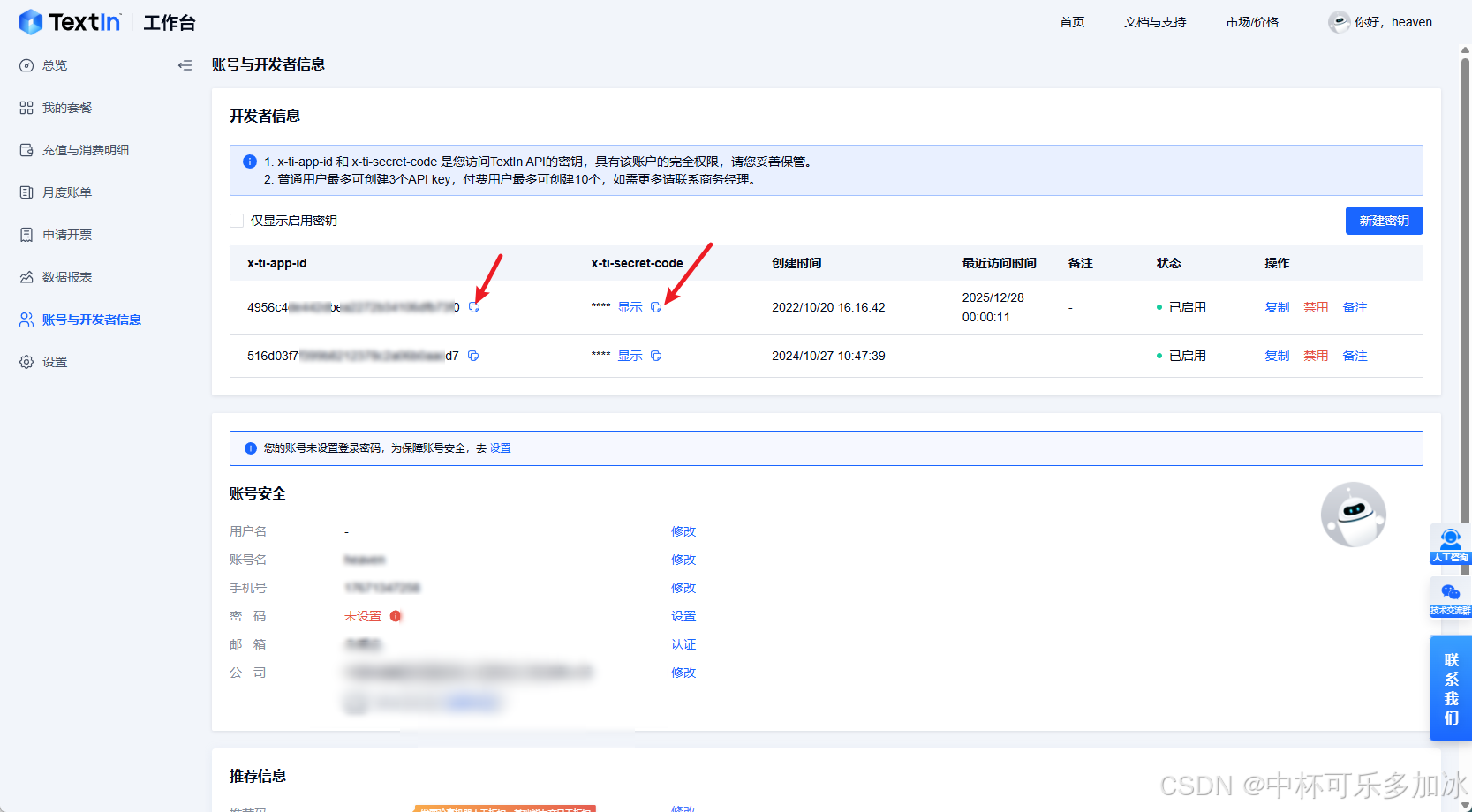
我这里也就直接让Claude Code帮我把**x-ti-app-id** 和 **x-ti-secret-code**配置到.env环境里了:
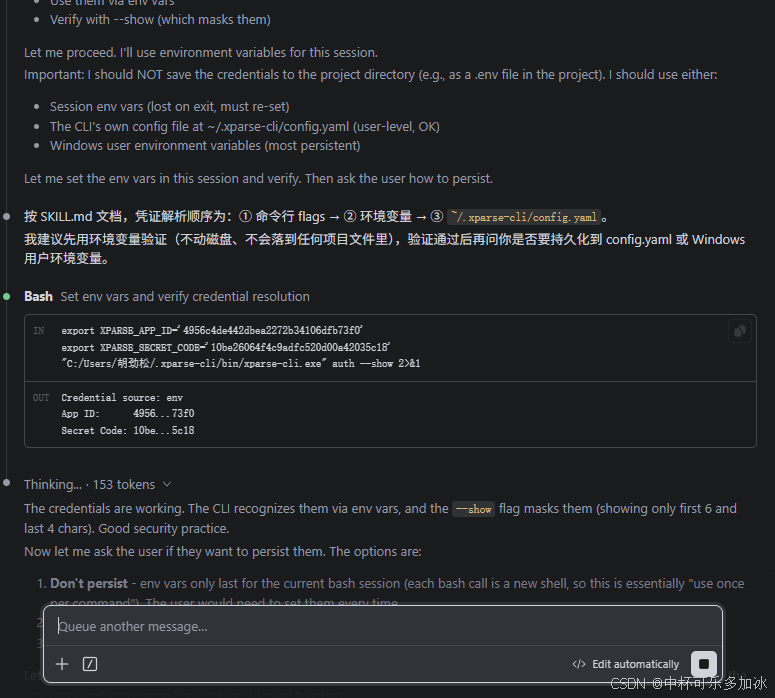
到这里,xParse 就正式接入 Claude Code 了。整个流程下来,从拿 Key 到跑通,端到端不超过 5 分钟——比手动从零撸一个 Skill 至少省了半天。
3.2、Claude Code + xParse 效果
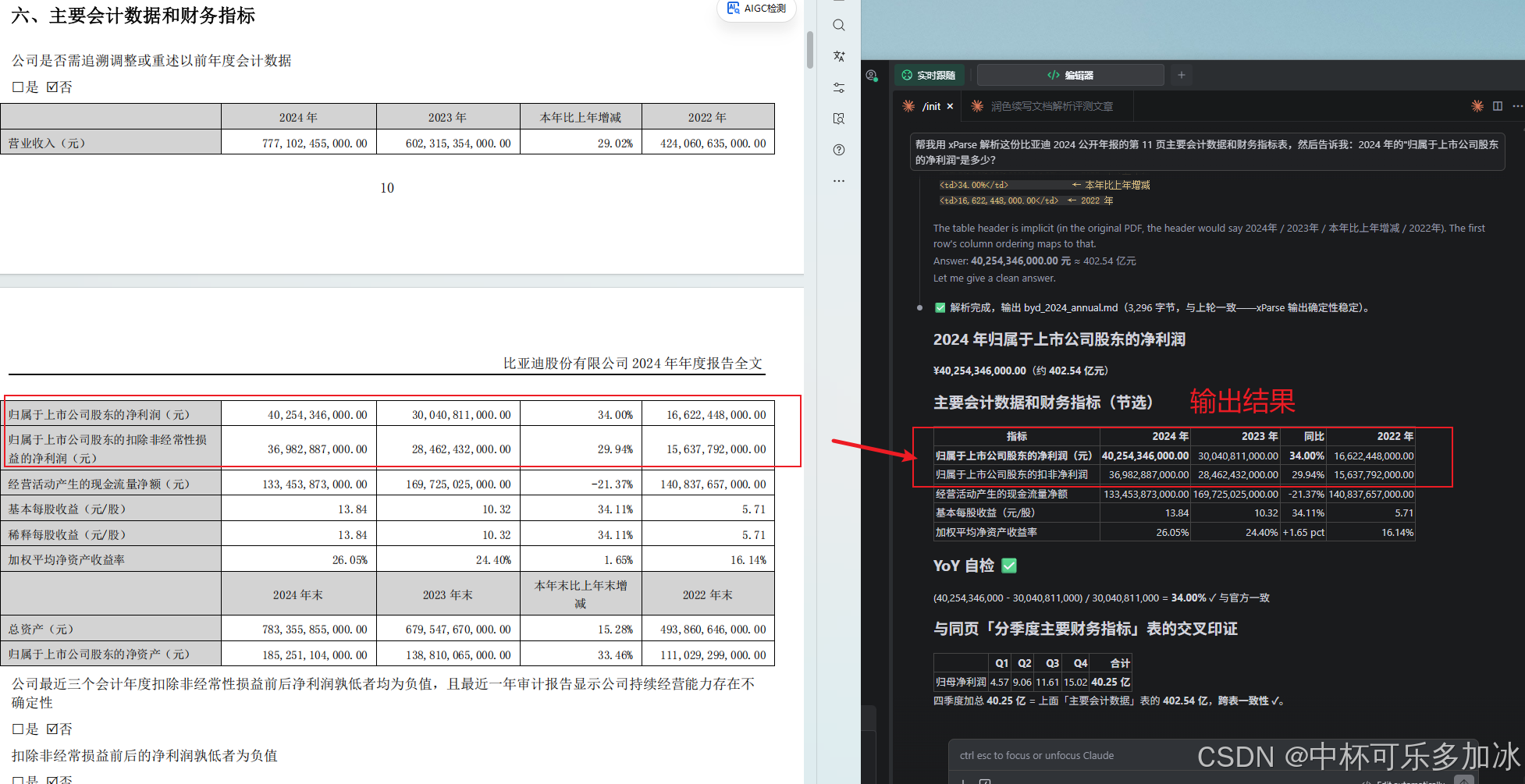
完成配置后,装好之后,我做了两件事。第一件事——把比亚迪 2024 年报那个翻车的页,重新塞回去。这里我直接把整个PDF 丢给 Claude Code,输入:
帮我用 xParse 解析这份比亚迪 2024 公开年报的第 11 页主要会计数据和财务指标表,然后告诉我:2024 年的"归属于上市公司股东的净利润"是多少?
第二件事——拿一份超长文档试试。 同一份比亚迪 2024 年报,这次不是单页——整本 290 页全塞给 Claude Code + xParse。年报里光财务相关的表格就 30 多张:合并资产负债表、合并利润表、合并现金流量表、分行业/分产品收入、研发投入、应收账款明细、关联交易……密密麻麻。这种"超长 + 多表"的场景是 LLM 直接调用的死穴——视觉 token 一上来就爆。我把整本 PDF 丢给 Claude Code,输入:
帮我用 xParse 解析这份 290 页的比亚迪 2024 年报,把里面所有财务相关表格一次性提取出来并存到我的本地——合并资产负债表、合并利润表、合并现金流量表、分行业/分产品收入、研发投入明细——输出结构化数据,跨页表要自动拼接。
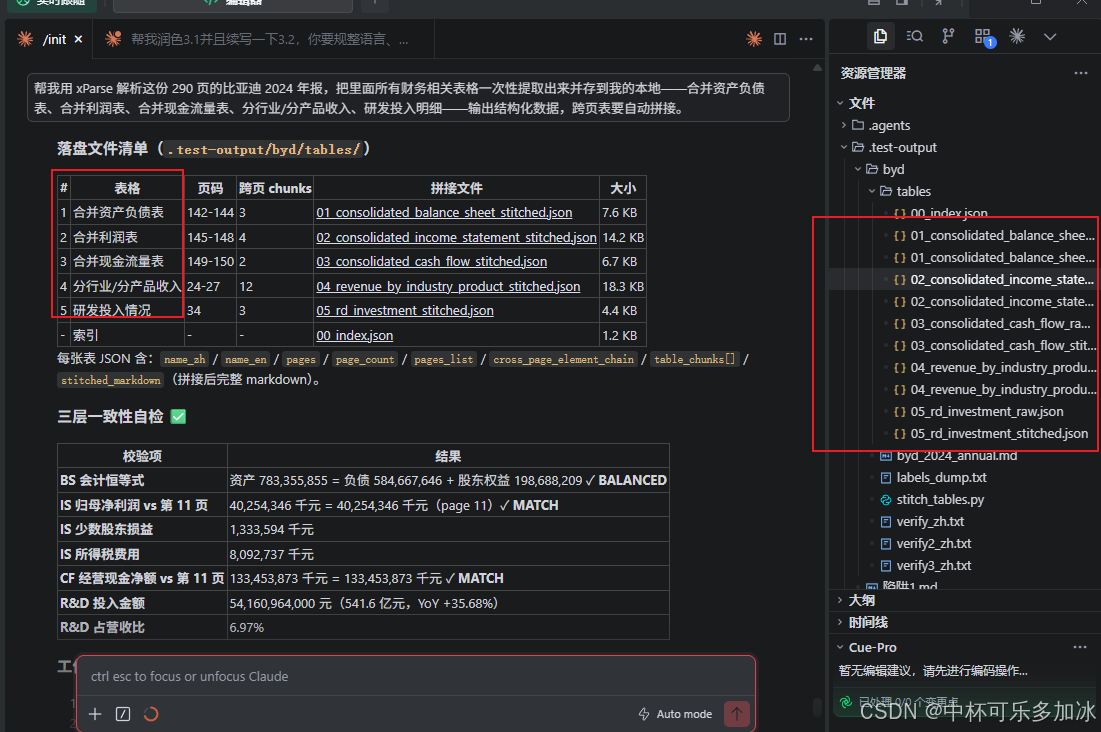
可以看到结果,290 页一口气吞下,要找的十几个表一张没漏。Claude Code + xParse 在 这次290 页全量解析中稳定完成了三件事:① 自动定位并提取 10+ 张财务报表;② 跨页长表自动拼接,无空行无断裂;③ 支持自然语言问数(如“研发投入占比”)和多表核对(如净利润一致性校验)。对比直接喂 PDF 给 Claude Code,xParse 介入后回答准确率从“常丢列、常编数”提升到稳定输出的结果, 端到端可用。
四、结论
xParse 的引入,让 Agent 的文档处理不再受限于原始 PDF 的版式复杂度。它通过输出带 schema 的结构化数据,把 Agent 的知识输入从"无序字符流"升级为"有层级、有归属、可追溯的语义块",推理准确率直接上一个台阶。
横评结果很直观:PaddleOCR 和通用 LLM 在字符级准确率上已经不差,但一到多层表头、嵌套子表、跨页长表这些真实业务场景,字段归属就断。xParse 能稳住,核心不是字认得更准,而是版面分析把"表格当结构化对象"解析——父子关系保得住,跨页拼接无缝衔接,下游拿到的才是能直接入库、能直接算数的数据。

落地测试更说明问题。Claude Code + xParse 跑 290 页比亚迪年报,十几张财务表一张没漏,自然语言问数、多表核对都能稳定输出带页码引用的结果。对比直接喂 PDF,回答准确率从"常丢列、常编数"拉到稳定可用。
总的来说,Agent 时代文档解析的竞争焦点,已经从"能不能认出字"转向了"能不能重建对的关系"。xParse 凭借在复杂版式上的技术壁垒,给 Agent 应用搭了一层可靠的基础设施。未来,随着 Agent 往更深的企业业务场景渗透,xParse 这种高精度、结构化的文档解析能力,会成为 Agent 进化中不可或缺的一环。
如果对结构化解析能力有兴趣,可以用真实复杂文档测试一下 xParse 的输出稳定性。
体验链接(注册送1000页额度):https://www.textin.com/register/code/7SR96V


















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












