





论文地址:https://ieeexplore.ieee.org/document/
Abstract(摘要):
基于Mamba的图像修复骨干网络近期在平衡全局感受野与计算效率方面展现出显著潜力。然而,Mamba固有的因果建模局限——即每个标记仅依赖于扫描序列中的前序像素——限制了对图像全域像素的充分利用,从而为图像修复任务带来了新的挑战。本文提出MambaIRv2模型,通过赋予Mamba类似视觉Transformer的非因果建模能力,构建出注意力驱动的状态空间修复模型。具体而言,所提出的注意力状态空间方程能够突破扫描序列的局限,仅通过单次扫描即可实现图像特征的高效展开。此外,我们进一步引入语义引导的邻近交互机制,以促进空间距离较远但语义相似像素之间的信息交互。大量实验表明,在轻量化超分辨率任务中,MambaIRv2以参数减少9.3%的优势,其PSNR指标仍超越SRFormer达0.35dB;在经典超分辨率任务中,该模型最高可领先HAT模型0.29dB。
1. Introduction(介绍)
图像恢复旨在从低质量观测数据中重建高质量图像,其涵盖图像超分辨率、图像去噪、JPEG压缩伪影消除等多个子领域。随着深度学习技术的发展,该领域性能纪录不断被刷新。早期研究主要采用卷积神经网络(CNN)作为骨干网络[12, 13, 30, 45, 53],随后视觉变换器(ViT)[15]凭借卓越性能获得广泛关注[5, 7, 10, 28, 29]。最近,选择性状态空间模型(Mamba)[17]在图像恢复任务中展现出巨大潜力,正逐渐成为替代性骨干网络架构[18, 36]。
尽管潜力巨大,但现有的基于Mamba的方法面临着重大挑战,这主要源于其对因果状态空间建模的依赖。具体而言,现有方法[18]通过预定义的扫描规则将二维图像展开,生成一维令牌序列。然而在Mamba中,每个像素仅基于其在扫描序列中的前序像素进行建模——即因果属性——这种特性对于非因果的图像复原任务会导致若干不利影响。
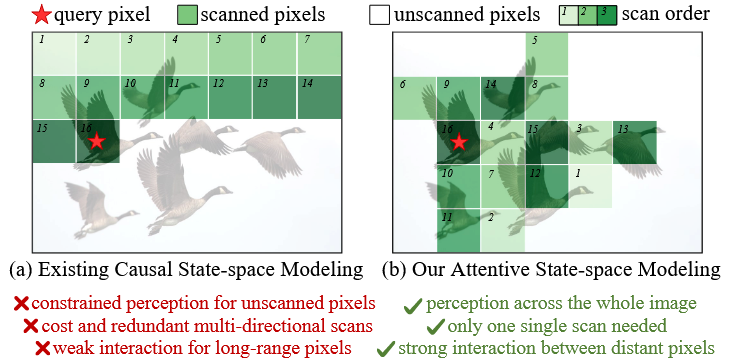
图1.
(a) 现有方法[18]受限于Mamba的因果特性影响(为图示清晰,未展示多方向扫描过程)。
- 未扫描像素的受限感知
- 成本高昂且冗余的多方向扫描
- 远距离像素间的弱交互
(b) 提出的MambaIRv2能够实现注意力驱动的状态空间建模,将类似ViT的非因果特性融入Mamba架构。
- 全域图像感知
- 仅需单次扫描
- 增强远距离像素交互
首先如图所示1(a),查询像素仅能捕获其前序像素的信息,无法感知后续像素,导致图像中有助于修复的像素未被充分利用。其次,固有的因果属性使得多方向扫描成为必要,现有方法普遍采用这种策略来缓解信息损失。然而,多方向扫描不可避免地增加了计算复杂度,尤其对于高分辨率输入。此外,我们在第三节的实证研究表明,这些多方向扫描之间还存在显著的信息冗余。再次,我们在第三节中的发现表明,Mamba容易在序列的远距离像素互动中出现衰减效应,这意味着序列中距离较远但相关的先前扫描像素无法被查询像素有效利用。
在本研究中,我们提出MambaIRv2,旨在解决因果状态空间建模的负面影响。由于视觉Transformer(ViT)天然支持非因果处理,我们的核心思想是将类ViT的非因果建



















&spm=1001.2101.3001.5002&articleId=156426707&d=1&t=3&u=10d70335e798427aa0b8ed518b69057c)
 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










