




各位同学,今天我们聚焦扣子开发平台的核心能力之一——大模型知识库。它是解决大模型“知识过时、回答不准”问题的关键工具,也是打造专业智能体(如行业客服、专业助手)的核心组件。接下来我们从“为什么用”“是什么”“怎么用”到“实战做”,完整掌握知识库的应用。
第一章 认知基础:为什么需要知识库?
在接触具体操作前,我们先明确核心问题:已经有强大的大模型了,为什么还要单独搭建知识库?大模型微调又该在什么场景用?这两个问题直接决定我们后续的技术选型方向。
1.1 大模型的“天生短板”
大模型(如文心一言、GPT)虽强,但存在三个无法回避的问题,
-
知识滞后性:大模型的训练数据有“截止日期”,即有时间限制,比如2025年训练的模型无法知晓2026年的新政策、新产品信息。
-
专业领域空白:通用大模型训练数据主要来源互联网上的公开数据,对垂直行业(如医疗、金融、企业内部业务)的专业知识覆盖不足,无法精准回答“某公司产品的售后政策”这类问题。通用大模型训练数据主要来源互联网的公开数据,对于企业内部的私有数据,前沿数据,无法感知而无法做出专业的准确的答案
-
易产生“幻觉”:对不确定的问题,大模型可能编造看似合理但错误的答案,比如把“产品保修期1年”说成“2年”。
1.2 知识库的核心价值
知识库,本质是为大模型提供“实时、专业、精准”的外部知识源,
知识库是如何解决大模型天生短板问题而来,通过大模型可以回答通用问题,但在专业技术垂直领域中,知识的技术深度、更新的及时性和准确性都非常有限,通过引入存储在外部数据库中的专业知识库,可以显著增强大模型回答问题的专业能力,从而避免大模型产生幻觉,而回答出不专业不正确的内容。
让大模型在回答时“有据可依”。它的核心价值体现在三个方面:
-
知识精准可控:知识库中的内容由我们自主上传(如企业手册、产品资料),大模型回答严格基于这些内容,避免幻觉。
-
更新成本极低:新增或修改知识只需更新知识库文件,无需重新训练大模型,解决知识滞后问题。
-
专业能力定制:通过上传行业资料,快速让通用大模型具备“行业专家”能力,比如上传电商售后规则,就成了电商客服专家。
1.3 大模型微调有必要吗?与知识库的区别
很多同学会混淆“知识库”和“微调”,两者都是提升大模型能力的手段,但适用场景完全不同,教学中需重点区分:
| 对比维度 | 知识库(RAG技术) | 大模型微调 |
|---|---|---|
| 核心逻辑 | 让大模型“查资料”后回答 | 让大模型“记住”新知识后回答 |
| 适用场景 | 知识高频更新(如产品价格、政策)、专业资料查询(如手册、FAQ) | 深度定制模型行为(如固定回答风格、掌握复杂行业逻辑) |
| 成本与门槛 | 低,无需编程,上传文件即可 | 高,需大量标注数据、编程能力和算力支持 |
| 更新效率 | 即时,更新知识库后立即生效 | 慢,需重新训练模型,耗时几小时到几天 |
教学总结:90%的中小企业场景(如客服、助手)优先用知识库;只有需要深度定制(如法律文书生成、医疗诊断逻辑)时,才需要结合微调。
第二章 核心技术:知识库的“心脏”——RAG
扣子平台的知识库本质是基于RAG技术实现的。理解RAG的原理,能帮助我们更科学地构建和使用知识库,避免踩坑。
2.1 RAG是什么?
RAG全称Retrieval-Augmented Generation(检索增强生成),是一种将“信息检索”与“大模型生成”结合的技术。简单说,就是让大模型在回答前,先从我们的知识库中“检索”相关资料,再结合资料生成回答,而非凭空捏造。
类比:大模型是“学霸”,知识库是“专属参考书”,RAG就是让学霸“先翻书找依据,再答题”,确保答案准确。
2.2 RAG的基本架构
RAG包含三个主要过程:检索、增强和生成。
检索:根据用户输入的查询内容,从外部知识库中获取相关信息。
具体来说,就是将用户的查询通过嵌入模型转换成向量,然后与向量数据库中存储的相关知识进行对比,通过相似性搜索,找出与查询最匹配的前k个数据。
增强:将用户查询内容与检索到的相关知识文档一起嵌入一个预设的提示词模板中。
生成:将经过检索增强的提示词内容输入大模型中生成准确性和可信度更高的输出内容。
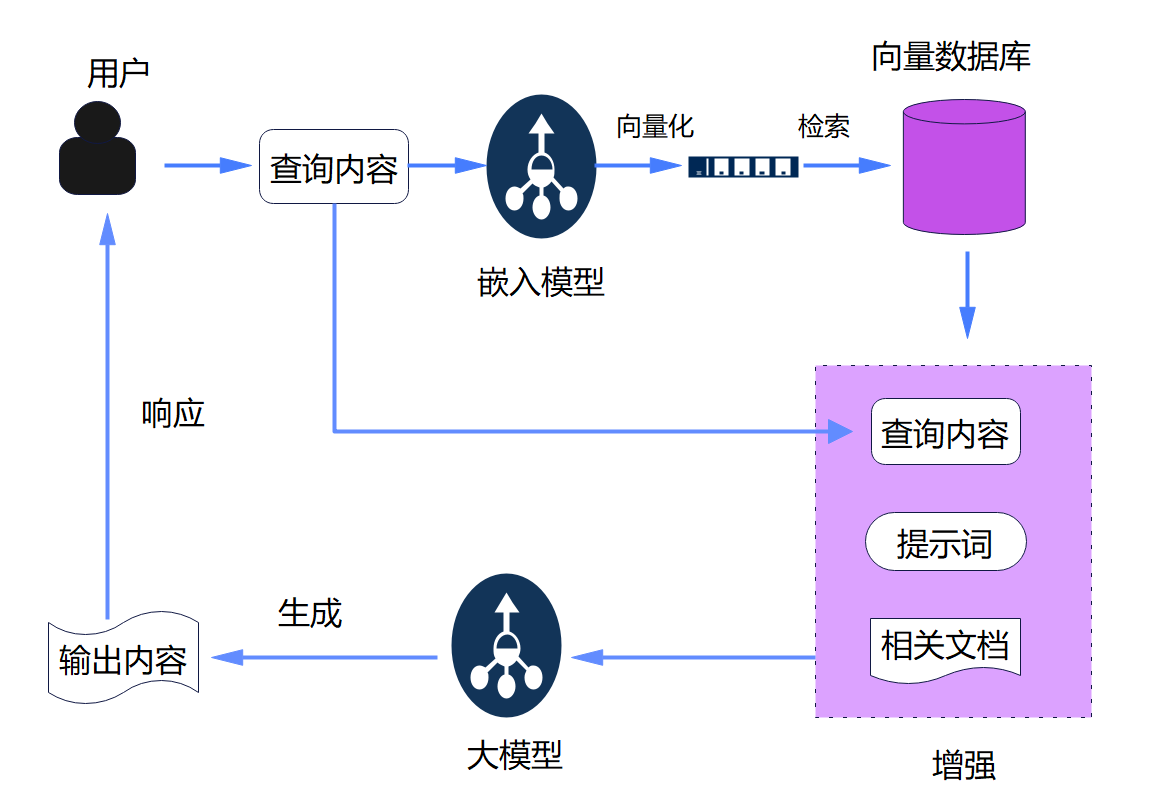
一个经典的RAG的工作流程分为“离线构建”和“在线推理”两部分
1、离线构建
-
数据收集与准备:从领域内部系统、文档、数据库等渠道收集相关信息,其知识源可能包括多种格式,如word文件、txt文档、PDF、Excel表格等
-
文档分割及预处理:对收集到的数据进行预处理,如清洗、标准化等,文档内容可能存在过长问题,还需要进行分割,将文档分割成多个文件块,以便高效处理
-
向量化:利用嵌入模型将每个文本片段转换成向量形式。通过计算向量间的距离来衡量内容的相似度。
-
索引创建:建立高效检索机制,例如使用近似最近邻搜索算法,与知识库中的向量对比,找出相关度最高的几个知识片段。
2、在线推理(应用阶段)
根据用户输入的问题与知识库查找相关知识片段,一起整合生成新的提示词(prompt)输入大模型,让大模型基于这些片段生成精准回答,并标注来源。
2.3 RAG的核心优势
相比单纯的大模型或传统数据库,RAG的优势非常突出,这也是它成为主流技术的原因:
-
回答精准可追溯:每个回答都能对应到知识库中的具体片段,方便验证和纠错;
-
知识更新灵活:新增资料只需重新上传文档分割,无需改动模型;
-
降低使用门槛:非技术人员也能通过上传文件轻松搭建专业知识库;
-
成本可控:无需为微调支付高额的算力和数据标注费用。
第三章 实操指南:扣子知识库的使用流程
这部分是教学核心,我们从“知识库概述”到“智能体中使用”“工作流中使用”,一步步掌握实操技巧,每个步骤都对应平台实际操作界面。
3.1 扣子知识库概述
-
扣子知识库支持上传和存储外部知识内容,并提供多种检索功能
-
支持多种数据源(本地文档、在线数据、飞书文档)等上传文本、表格和图片数据
-
扣子将上传文档数据内容自动切割为一个个内容数据片段进行存储,支持用户自定义内容数据分片规则。(如:通过分段标识符、字符长度等方式进行内容分割)
还提供多种检索策略对存储内容数据片段进行检索(全文、语义、混合)和召回
-
大模型会根据召回的内容数据片段生成最终的回复内容返回给用户
我们需要将用户高频咨询的产品问题和产品使用手册的内容数据上传到扣子知识库中,智能体就可以通过这些知识精确回答用户问题。
3.2 知识类型适用场景和导入方式
在上传知识文档前,建议先了解一下知识类型适用场景和导入方式,便于更好的管理知识
| 文本 | 表格 | 图片 | |
|---|---|---|---|
| 适用场景 | 基于内容片段进行检索和召回,大模型结合召回的内容生成最终的内容响应用户。适合于知识问答等场景 | 基于索引列的匹配 | 基于标注信息匹配,适用于图像生成场景 |
| 导入方式 | 本地文档:从本地导入文本内容,支持.txt、.pdf、doc。 在线数据:网页或api内容 第三方渠道:从第三方(飞书)文档中导入内容 自定义:手动输入要导入的文本内容 | 本地文档:从本地导入表格数据,支持.csv和.xlsx文件格式 在线数据:通过api导入数据 第三方数据:支持从飞书表格中导入数据。 自定义:手动输入要导入的表格数据 | 本地图片:从本地文件中导入图片,支持jpg、png等图片格式 |
| 内容分段 | 自动内容分段和手动分段方式 | 表格内容默认按行分片段。一行就是一个内容片段,不需要再进行分段设置 | 不涉及 |
扣子知识库的限制
暂不支持多人协作:只有知识库的所有者支持编辑、启用,删除自己创建的知识库。团队所有者、管理员以及普通成员都没有权利编辑、启用、删除其他成员创建的知识库
单用户最多创建1000个知识库
每个文本类型知识库下最多支持添加300个文件,上传每个文件大小不超过100MB,且表格格式文件最多10列。
基础版知识库容量最大1GB,专业版10GB,如果需要,可以购买扩容。
3.3 扣子知识库使用流程
-
导入企业文档:首先将需要的企业文档导入知识库中,扣子支持导入文本内容和表格数据并提供多种导入数据方式。
-
关联智能体或工作流:完成知识库创建和内容导入后,你可以将知识库直接与智能体进行关联,用于响应用户问题,也可以在工作流中添加知识库写入节点或知识库检索节点,使其成为工作流中的一环或一部分
-
配置知识库:在上传完成知识库内容后,可以通过相关配置来解决“从哪里查”、怎么查、用哪几条等的问题
-
优化回复效果:需要通过测试不断的优化回复的内容效果。
3.4 在智能体中使用知识库(最常用场景)
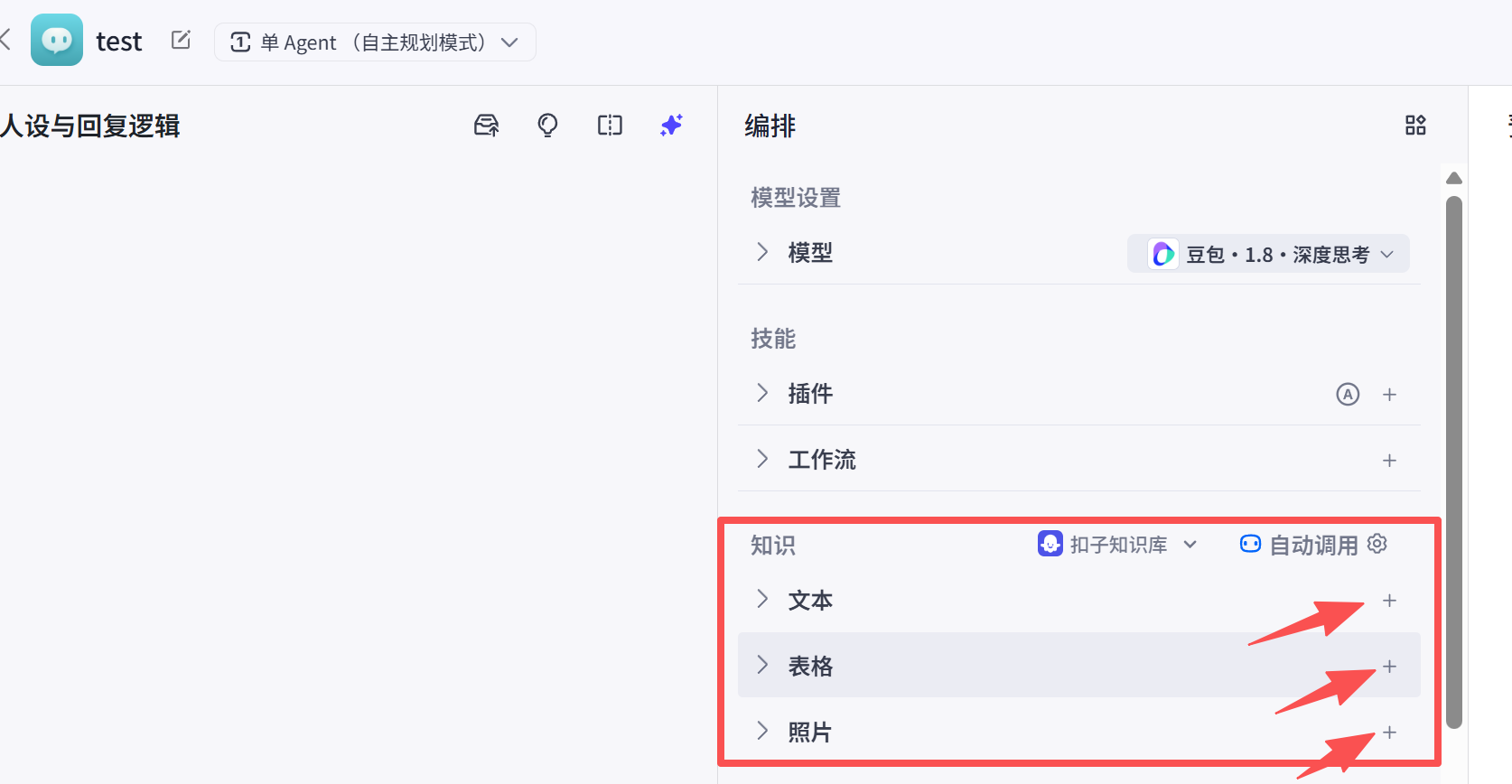
将知识库与智能体绑定后,智能体就能基于知识库内容回答问题,适用于客服、助手等场景,操作步骤:
-
创建一个智能体,路径:编排→知识功能区
-
单击对应知识库按钮+,添加使用知识库。(类型:文本、表格、图片)
3.5 在工作流中使用知识库(进阶场景)
工作流中使用知识库,可实现“用户输入→意图识别→知识库检索→大模型整理回答”的自动化流程,适用于复杂业务场景,核心是使用“知识库检索”节点。
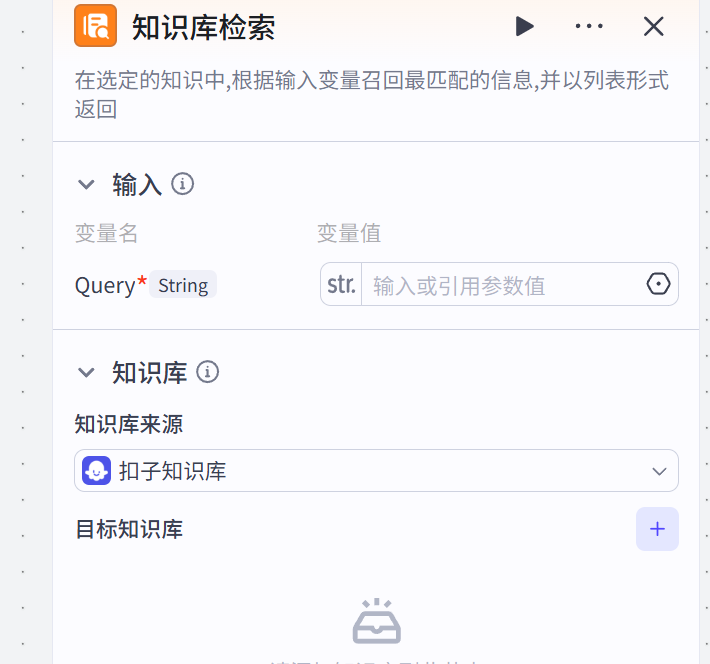
知识库检索节点:如果用户需要在知识库中检索知识
在工作流中添加知识库检索节点。
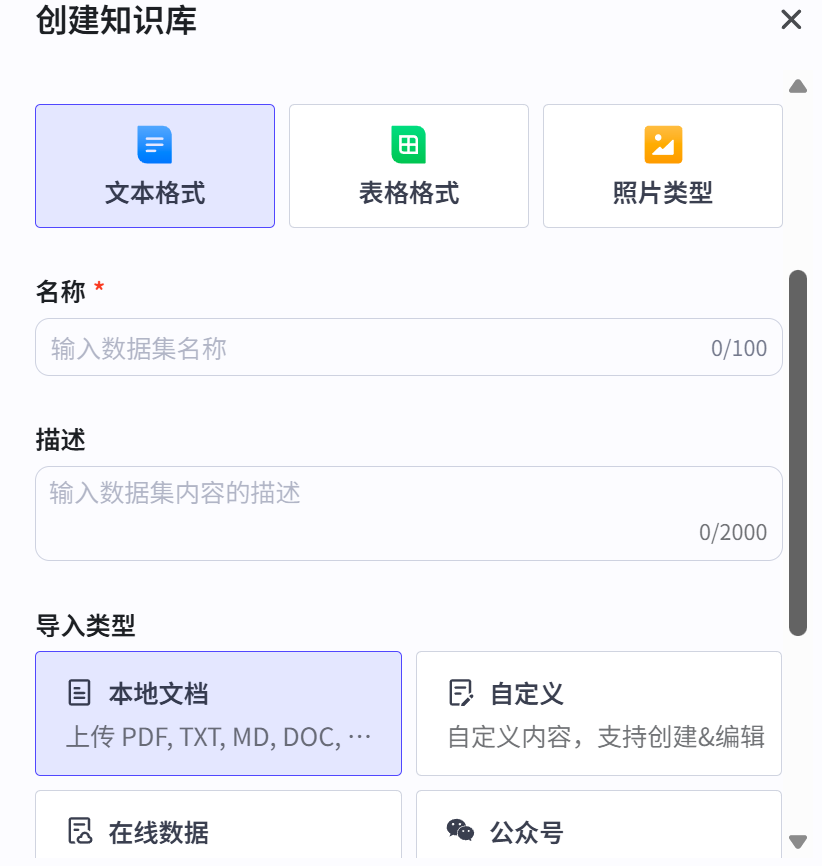
知识库写入节点:如果用户需要上传新的文档到指定的知识库
在工作流添中加知识库写入节点


















 1608
1608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










