





 超级会员免费看
超级会员免费看


文章核心内容、创新点及关键部分翻译
一、主要内容总结
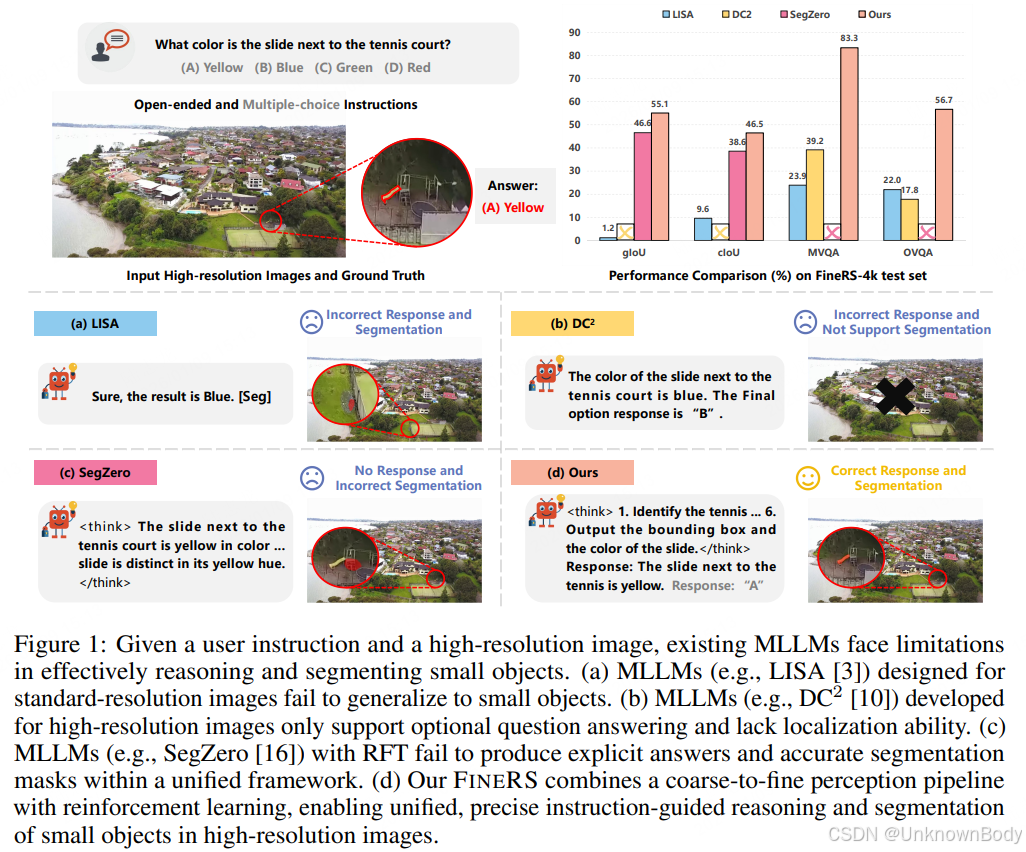
该研究针对多模态大语言模型(MLLMs)在高分辨率图像中处理超小目标时存在的推理与分割精度不足问题,提出了两阶段强化学习框架FINERS,并构建了专用数据集FINERS-4k,具体内容如下:
- 问题背景:现有MLLMs受输入分辨率限制,在高分辨率图像的复杂场景中,难以精准识别和定位超小目标,且缺乏统一框架同时支持文本推理(开放问答、多选问答)与像素级分割任务。
- 核心框架FINERS:采用“粗到细”流水线,包含两个关键模块:
- 全局语义探索(GSE):基于用户指令生成文本响应和包含目标的粗粒度区域;
- 局部感知细化(LPR):对粗粒度区域裁剪后,生成精准边界框和分割点,结合冻结的SAM2模型输出最终分割掩码。
- 强化学习机制:设计多任务奖励函数(含响应奖励、区域IoU奖励等),并引入“定位感知回溯奖励”,通过LPR的输出优化GSE的粗区域探索精度,实现两阶段协同优化。
- 数据集FINERS-4k:基于无人机拍摄的4k高分辨率图像构建,包含12,132个文本-掩码标注对,涵盖三种任务(指令引导分割IS、开放视觉问答OVQA、多选视觉问答MVQA),目

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 1944
1944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












