





 超级会员免费看
超级会员免费看


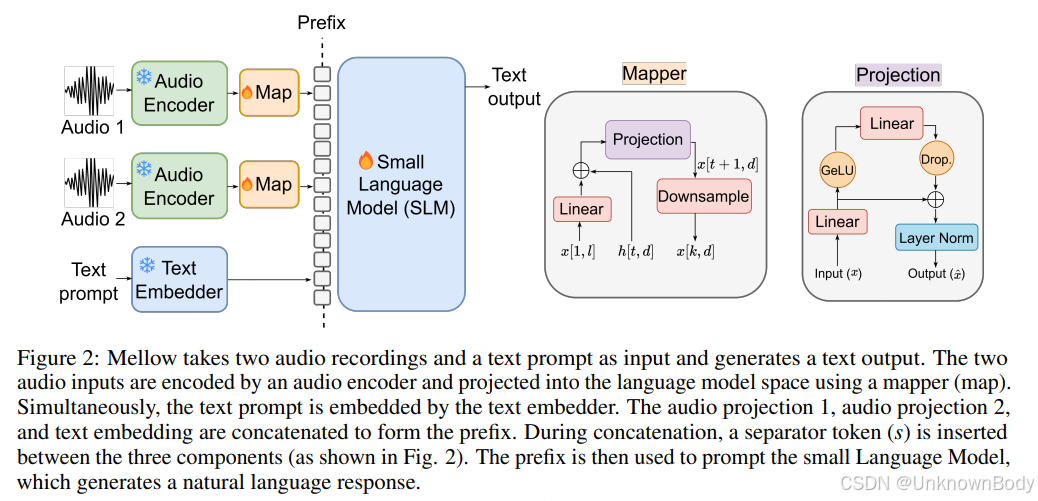
文章核心总结与创新点
核心内容
本文提出小型音频语言模型Mellow,专为音频-文本推理设计,仅用1.67亿参数和152小时音频数据,在多项推理任务中达到当前小型模型最佳性能,甚至超越部分大模型。同时构建了ReasonAQA训练数据集,通过消融实验验证了模型架构、训练策略等关键因素对推理性能的影响。
创新点
- 提出首个聚焦推理的小型音频语言模型Mellow,参数规模仅1.67亿,却在MMAU等基准测试中与84亿参数的Qwen2 Audio性能相当(52.11分 vs 52.5分),且训练数据量减少60倍。
- 构建ReasonAQA数据集,包含100万音频问答样本,其中70%为LLM生成的合成数据,覆盖音频事件、声学场景等多维度推理需求,专门优化音频接地推理能力。
- 验证了不依赖数据扩展的推理优化路径,通过架构选择(如HTSAT音频编码器、SmolLM2语言模型)、非线性投影层设计和全微调策略,提升小型模型固有推理能力。
- 系统开展消融实验,明确了语言模型预训练质量、合成数据设计、投影层结构等关键因素对音频推理性能的影响,为小型音频语言模型研发提供参考。

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 2633
2633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












