




 本文详细介绍了如何在PyTorch中利用DistributedDataParallel(DDP)进行多机多卡训练。通过创建进程组、初始化分布式计算、使用DistributedDataSampler分发数据和DistributedDataParallel分发模型,实现梯度同步和模型训练。在训练结束后,通过dist.destroy_process_group()关闭进程组。推荐进一步阅读分布式训练的相关资料以深入理解。
本文详细介绍了如何在PyTorch中利用DistributedDataParallel(DDP)进行多机多卡训练。通过创建进程组、初始化分布式计算、使用DistributedDataSampler分发数据和DistributedDataParallel分发模型,实现梯度同步和模型训练。在训练结束后,通过dist.destroy_process_group()关闭进程组。推荐进一步阅读分布式训练的相关资料以深入理解。
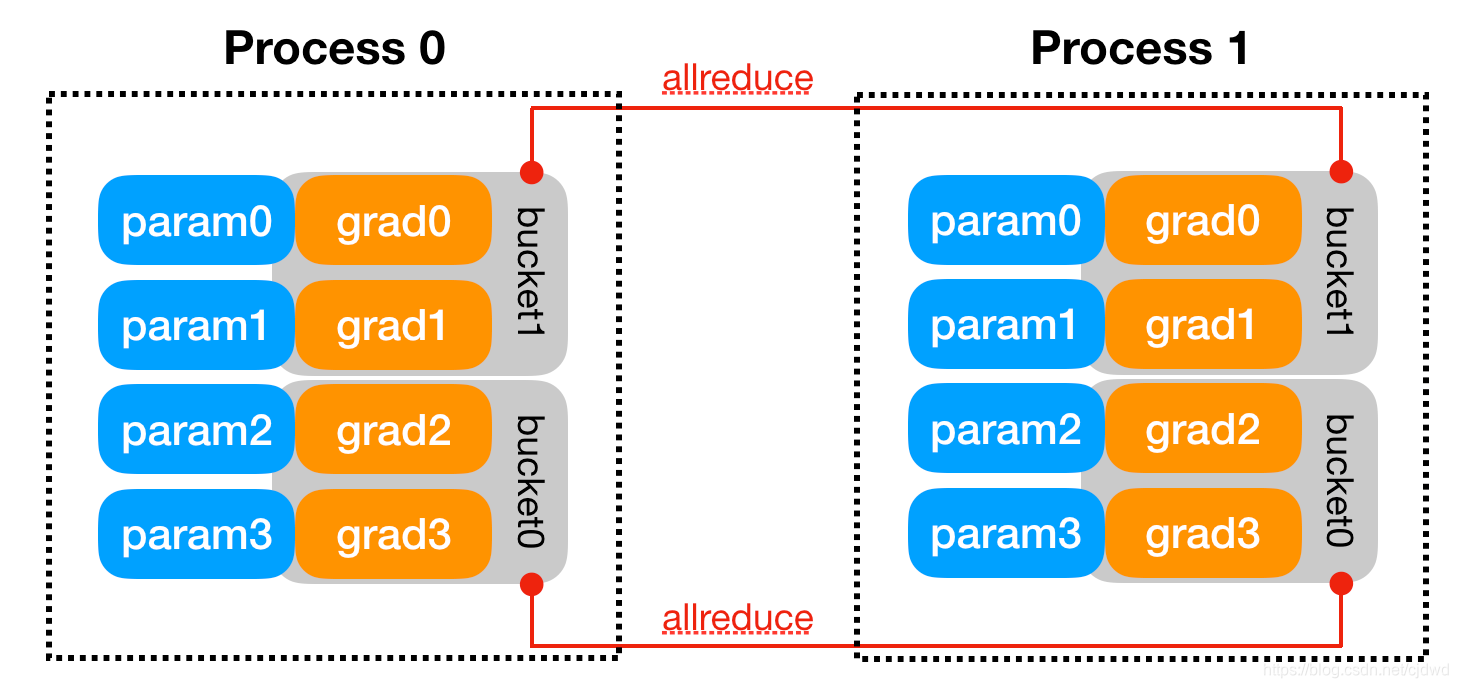
DDP使用多进程训练,在进程运行中,他们的梯度是同步的,每次iteration后梯度会逐个传播,然后一同下降,这样每次iteration后它们的梯度都是一样的,如上图process 0传梯度到process 1,process 1又传回梯度到process 0。
在多机多卡训练中使用DDP,我们需要为每张卡创建一个进程,例如两台机(pc1、pc2),每台四卡,我们需要创建8个进程,以下均使用此例子,设pc1的gpu编号为0–3,pc2的为4–7,即他们的global node rank为0–7,它们的local node rank(本地rank)分别均为0–3。
为了让进程之间连接,我们需要先设置一个process group
使用torch.distributed.init_process_group()即可
推荐使用tcp初始化,选定pc1为主机,设其ip地址为196.168.0.1
import torch.distributed as dist
#以下是函数原型
torch.cuda.set_device(local_rank)
device = torch.device("cuda",local_rank)
dist.init_process_group(backend=opt.backend, # distributed backend (nccl for gpu or gloo)
init_method=opt.init_method, # init method (tcp+空闲端口)
world_size=opt.world_size, # number of nodes (8)
rank=opt.rank) #global


















多机多卡训练详解&spm=1001.2101.3001.5002&articleId=116148744&d=1&t=3&u=6685d9c2bb114c5b8bddb35e406573e6)
 5211
5211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










