




高级查找
1、在结果集中翻页
问题:你想在结果集中翻页或“滚动”。例如,你想返回 EMP 表中前 5 名员工的薪水,然后再返回接下来 5 名员工的薪水,以此类推。你的目标是,让用户每次查看 5 条记录,且每当用户单击 Next 按钮时都向前滚动。
解决方案:在 SQL 中,没有“第一个”“最后一个”和“下一个”的概念,因此你必须给行指定排列顺序。仅当指定排列顺序后,才能准确地返回记录区间。
可以使用窗口函数 ROW_NUMBER OVER 指定排列顺序,并使用 WHERE 子句指定要返回的记录窗口。例如,下面的查询会返回第 1~5 行。
select sal
from (
select row_number() over (order by sal) as rn, sal
from emp
) x
where rn between 1 and 5;
sal
------
950
1250
1250
1500
1600
(5 rows)
下面的查询会返回第 6~10 行。
select sal
from (
select row_number() over (order by sal) as rn, sal
from emp
) x
where rn between 6 and 10;
sal
------
2850
4000
4000
4000
5000
(5 rows)
你可以返回任何记录区间,为此只需修改查询中的WHERE 子句。
对于 Oracle 用户,还有另一种替代方案:使用函数ROWNUM(而不是函数 ROW NUMBER OVER)给行生成序列号。
select sal
from (
select sal, rownum rn
from (
select sal
from emp
order by sal
)
)
where rn between 6 and 10
SAL
-----
1300
1500
1600
2450
2850
使用函数 ROWNUM 时,必须增加一层子查询嵌套。最内层的子查询根据薪水对行进行排序,中间的子查询给行添加行号,而最外层的 SELECT 返回你查找的数据。
2、在表中跳过n行数据
问题:你想编写一个查询,以每次跳过一人的方式返回 EMP 表中的员工。换言之,你想返回第一个员工、第三个员工……例如,对于下面的结果集:
ENAME
--------
ADAMS
ALLEN
BLAKE
CLARK
FORD
JAMES
JONES
KING
MARTIN
MILLER
SCOTT
SMITH
TURNER
WARD
你想从中返回如下结果集。
ENAME
----------
ADAMS
BLAKE
FORD
JONES
MARTIN
SCOTT
TURNER
解决方案:要跳过结果集中的第 2 行、第 4 行或第 n 行,必须先对结果集进行排序,否则将不存在“第一个”“下一个”“第二个”或“第四个”的概念。
使用窗口函数 ROW_NUMBER OVER 给每一行都指定一个编号,然后结合使用这些编号和求模函数来跳过不想返回的行。在 DB2、MySQL、PostgreSQL 和 Oracle 中,求模函数为 MOD。在 SQL Server 中,使用运算符 % 来求模。下面的示例使用了 MOD 来跳过偶数行。
select ename
from (
select row_number() over (order by ename) rn, ename
from emp
) x
where mod(rn,2) = 1;
ename
--------
ALLEN
CLARK
KING
MILLER
WARD
(5 rows)
3、在外连接中使用OR逻辑
问题:你想返回部门编号为 10 和部门编号为 20 的所有员工的名字及其所属部门的信息,以及部门编号为 30 和部门编号为 40 的部门信息(但不返回这些部门的员工信息)。你首先想到的可能是像下面这样做。
select e.ename, d.deptno, d.dname, d.loc
from dept d, emp e
where d.deptno = e.deptno
and (e.deptno = 10 or e.deptno = 20)
order by 2
ENAME DEPTNO DNAME LOC
------- ---------- -------------- -----------
CLARK 10 ACCOUNTING NEW YORK
KING 10 ACCOUNTING NEW YORK
MILLER 10 ACCOUNTING NEW YORK
SMITH 20 RESEARCH DALLAS
ADAMS 20 RESEARCH DALLAS
FORD 20 RESEARCH DALLAS
SCOTT 20 RESEARCH DALLAS
JONES 20 RESEARCH DALLAS
由于这个查询使用的是内连接,因此结果集中没有部门编号为 30 和部门编号为 40 的部门信息。
你尝试使用下面的查询将 EMP 表外连接到 DEPT 表,但结果还是不正确。
select e.ename, d.deptno, d.dname, d.loc
from dept d left join emp e
on (d.deptno = e.deptno)
where e.deptno = 10 or e.deptno = 20
order by 2;
ENAME DEPTNO DNAME LOC
------- ---------- ------------ -----------
CLARK 10 ACCOUNTING NEW YORK
KING 10 ACCOUNTING NEW YORK
MILLER 10 ACCOUNTING NEW YORK
SMITH 20 RESEARCH DALLAS
ADAMS 20 RESEARCH DALLAS
FORD 20 RESEARCH DALLAS
SCOTT 20 RESEARCH DALLAS
JONES 20 RESEARCH DALLAS
你希望最终的结果集像下面这样。
ENAME DEPTNO DNAME LOC
------- ---------- ------------ ---------
CLARK 10 ACCOUNTING NEW YORK
KING 10 ACCOUNTING NEW YORK
MILLER 10 ACCOUNTING NEW YORK
SMITH 20 RESEARCH DALLAS
JONES 20 RESEARCH DALLAS
SCOTT 20 RESEARCH DALLAS
ADAMS 20 RESEARCH DALLAS
FORD 20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
解决方案:
将 OR 条件移到 JOIN 子句中。
select e.ename, d.deptno, d.dname, d.loc
from dept d left join emp e
on (d.deptno = e.deptno and (e.deptno=10 or e.deptno=20))
order by 2;
ename | deptno | dname | loc
--------+--------+------------+----------
MILLER | 10 | ACCOUNTING | NEW YORK
CLARK | 10 | ACCOUNTING | NEW YORK
KING | 10 | ACCOUNTING | NEW YORK
SCOTT | 20 | RESEARCH | DALLAS
SMITH | 20 | RESEARCH | DALLAS
ADAMS | 20 | RESEARCH | DALLAS
JONES | 20 | RESEARCH | DALLAS
FORD | 20 | RESEARCH | DALLAS
| 40 | OPERATIONS | BOSTON
(9 rows)
也可以先在内嵌视图中根据 EMP.DEPTNO 进行筛选,然后再进行外连接。
select e.ename, d.deptno, d.dname, d.loc
from dept d
left join (
select ename, deptno
from emp
where deptno in ( 10, 20 )
) e on ( e.deptno = d.deptno )
order by 2;
ename | deptno | dname | loc
--------+--------+------------+----------
MILLER | 10 | ACCOUNTING | NEW YORK
CLARK | 10 | ACCOUNTING | NEW YORK
KING | 10 | ACCOUNTING | NEW YORK
SCOTT | 20 | RESEARCH | DALLAS
SMITH | 20 | RESEARCH | DALLAS
ADAMS | 20 | RESEARCH | DALLAS
JONES | 20 | RESEARCH | DALLAS
FORD | 20 | RESEARCH | DALLAS
| 40 | OPERATIONS | BOSTON
(9 rows)
4、确定哪些行是互逆的
问题:你有一张包含两次考试结果的表,你想确定哪两组成绩是互逆的。请看如下来自视图 V 的结果集。
create table V(
TEST1 INTEGER,
TEST2 INTEGER
);
INSERT INTO V VALUES
(20,20),
(50,25),
(20,20),
(60,30),
(70,90),
(80,130),
(90,70),
(100,50),
(110,55),
(120,60),
(130,80),
(140,70);
从这些结果可知,TEST1 为 70、TEST2 为 90 与TEST1 为 90、TEST2 为 70 是互逆的。同理,TEST1为 80、TEST2 为 130 与 TEST1 为 130、TEST2 为 80是互逆的。另外,TEST1 为 20、TEST2 为 20 与TEST2 为 20、TEST1 为 20 也是互逆的。对于两组互逆的成绩,你只想返回其中的一组。换言之,你希望结果集是这样的。
TEST1 TEST2
----- ---------
20 20
70 90
80 130
解决方案:使用自连接找出这样的行,即一行的 TEST1 和 TEST2分别与另一行的 TEST2 和 TEST1 相等。
select distinct v1.*
from V v1, V v2
where v1.test1 = v2.test2
and v1.test2 = v2.test1
and v1.test1 <= v1.test2;
test1 | test2
-------+-------
20 | 20
70 | 90
80 | 130
(3 rows)
自连接会生成笛卡儿积,以使每一行的 TEST1 和 TEST2都能与另一行的 TEST2 和 TEST1 进行比较。下面的查询会找出互逆的行。
select v1.*
from V v1, V v2
where v1.test1 = v2.test2
and v1.test2 = v2.test1
TEST1 TEST2
----- ----------
20 20
20 20
20 20
20 20
90 70
130 80
70 90
80 130
使用关键字 DISTINCT 可以消除最终结果集中的重复行。在 WHERE 子句中,最后的筛选器(and V1.TEST1<= V1.TEST2)将确保只返回两组互逆成绩中的一组(TEST1 小于或等于 TEST2 的那组)。
5、返回前n条记录
问题:你想限制结果集的规模,使其只包含排名前 n 的记录。例如,你想返回薪水排在前 5 位的员工的名字和薪水。
解决方案:解决这个问题需要使用窗口函数。具体使用哪个窗口函数取决于你在不分伯仲的情况下要怎么办?下面的解决方案使用了函数 DENSE_RANK,在薪水相同的情况下,只将总数加 1。
select ename,sal
from (
select ename, sal,
dense_rank() over (order by sal desc) dr
from emp
) x
where dr <= 5;
ename | sal
-------+------
KING | 5000
FORD | 3000
SCOTT | 3000
JONES | 2975
BLAKE | 2850
CLARK | 2450
(6 rows)
返回的行数可能超过 5,但这些行只包含 5 个不同的薪水值。如果不管是否存在薪水相同的情况,你都只想返回5 行数据,那么可以使用函数 ROW_NUMBER OVER(因为这个函数不允许平局)。
所有的工作都是由内嵌视图 X 中的窗口函数DENSE_RANK OVER 完成的。下面显示了应用这个函数得到的完整结果。
select ename, sal,
dense_rank() over (order by sal desc) dr
from emp
ENAME SAL DR
------- ------ ----------
KING 5000 1
SCOTT 3000 2
FORD 3000 2
JONES 2975 3
BLAKE 2850 4
CLARK 2450 5
ALLEN 1600 6
TURNER 1500 7
MILLER 1300 8
WARD 1250 9
MARTIN 1250 9
ADAMS 1100 10
JAMES 950 11
SMITH 800 12
现在只需返回 DR 小于或等于 5 的行。
6、找出值最高和最低的记录
问题:你想找出表中的极值。例如,你想在 EMP 表中找出薪水最高和薪水最低的员工。
解决方案:
DB2、Oracle 和 SQL Server:使用窗口函数 MIN OVER 和 MAX OVER 分别找出最低薪水和最高薪水。
select ename
from (
select ename, sal,
min(sal)over() min_sal,
max(sal)over() max_sal
from emp
) x
where sal in (min_sal,max_sal);
ename
-------
SMITH
KING
(2 rows)
窗口函数 MIN OVER 和 MAX OVER 让每一行都能够访问最低薪水和最高薪水。内嵌视图 X 返回的结果集如下所示。
select ename, sal,
min(sal)over() min_sal,
max(sal)over() max_sal
from emp
ENAME SAL MIN_SAL MAX_SAL
------- ------ ---------- ----------
SMITH 800 800 5000
ALLEN 1600 800 5000
WARD 1250 800 5000
JONES 2975 800 5000
MARTIN 1250 800 5000
BLAKE 2850 800 5000
CLARK 2450 800 5000
SCOTT 3000 800 5000
KING 5000 800 5000
TURNER 1500 800 5000
ADAMS 1100 800 5000
JAMES 950 800 5000
FORD 3000 800 5000
MILLER 1300 800 5000
有了这个结果集后,余下的全部工作就是返回 SAL 等于MIN_SAL 或 MAX_SAL 的行。
7、查看后面的行
问题:你想找出所有这样的员工,即其薪水比他获聘后第一个获聘的员工的薪水低。从下面的结果集可知,SMITH、WARD、MARTIN、JAMES 和 MILLER 的薪水都比他们获聘后第一个获聘的员工的薪水低,因此你想编写一个返回这些员工的查询。
ENAME SAL HIREDATE
---------- ---------- ---------
SMITH 800 17-DEC-80
ALLEN 1600 20-FEB-81
WARD 1250 22-FEB-81
JONES 2975 02-APR-81
BLAKE 2850 01-MAY-81
CLARK 2450 09-JUN-81
TURNER 1500 08-SEP-81
MARTIN 1250 28-SEP-81
KING 5000 17-NOV-81
JAMES 950 03-DEC-81
FORD 3000 03-DEC-81
MILLER 1300 23-JAN-82
SCOTT 3000 09-DEC-82
ADAMS 1100 12-JAN-83
解决方案:首先要定义“后面”的含义。要确定一行位于另一行后面,必须对结果集进行排序。
可以使用窗口函数 LEAD OVER 来访问下一个获聘的员工的薪水,然后再检查这个薪水值是否更高。
select ename, sal, hiredate
from (
select ename, sal, hiredate,
lead(sal)over(order by hiredate) next_sal
from emp
) alias
where sal < next_sal;
ename | sal | hiredate
--------+------+-------------
BLAKE | 2850 | 01-MAY-2006
JONES | 2975 | 02-APR-2006
JAMES | 950 | 03-DEC-2006
TURNER | 1500 | 08-SEP-2006
SMITH | 800 | 17-DEC-2005
WARD | 1250 | 22-FEB-2006
(6 rows)
窗口函数 LEAD OVER 非常适合解决本实例这样的问题。使用它不仅可以提高查询的可读性,还可以提高解决方案的灵活性,因为你可以给它传递一个参数,指出要查看接下来的第几行(默认为第 1 行)。作为排序依据的列可能包含重复值时,能够往前跳多行很重要。
下面的示例表明,使用 LEAD OVER 来查看下一个获聘的员工的薪水易如反掌。
select ename, sal, hiredate,
lead(sal)over(order by hiredate) next_sal
from emp
ENAME SAL HIREDATE NEXT_SAL
------- ------ --------- ----------
SMITH 800 17-DEC-80 1600
ALLEN 1600 20-FEB-81 1250
WARD 1250 22-FEB-81 2975
JONES 2975 02-APR-81 2850
BLAKE 2850 01-MAY-81 2450
CLARK 2450 09-JUN-81 1500
TURNER 1500 08-SEP-81 1250
MARTIN 1250 28-SEP-81 5000
KING 5000 17-NOV-81 950
JAMES 950 03-DEC-81 3000
FORD 3000 03-DEC-81 1300
MILLER 1300 23-JAN-82 3000
SCOTT 3000 09-DEC-82 1100
ADAMS 1100 12-JAN-83
最后,只返回 SAL 比 NEXT_SAL 小的行。由于 LEADOVER 默认往前跳 1 行,因此如果在 EMP 表中有多名员工的获聘日期相同,那么将比较他们的 SAL 值。这可能是你希望的,也可能不是。如果你的目标是将每位员工的 SAL 值与下一位获聘的员工的 SAL 值进行比较,就需要将同一天获聘的其他员工排除在外,为此可以使用如下解决方案。
select ename, sal, hiredate
from (
select ename, sal, hiredate,
lead(sal,cnt-rn+1)over(order by hiredate) next_sal
from (
select ename,sal,hiredate,
count(*)over(partition by hiredate) cnt,
row_number()over(partition by hiredate order by empno) rn
from emp
)
)
where sal < next_sal
该解决方案的思路是,找出当前行到要与当前行比较的行的距离。如果有 5 行的值是相同的,那么对于其中的第 1行,需要向前跳 5 行。CNT 表示 HIREDATE 值相同的员工数量,RN 表示员工排名。排名是按 HIREDATE 分区的,因此仅当员工的 HIREDATE 值与其他员工相同时,其排名才可能大于 1。排名是基于 EMPNO 的。(这种选择是随意的。)知道有多少名员工的 HIREDATE 值相同以及这些员工的排名后,计算到下一个 HIREDATE 值的距离很简单,只需将 HIREDATE 值相同的员工数减去当前排名再加 1(CNT - RN + 1)。
8、平移行值
问题:你想返回每位员工的名字、薪水以及下一个更高和更低的薪水值。如果没有更高或更低的薪水值,就执行回转操作:如果当前员工的薪水是最低的,就将下一个更低的薪水设置为最高的薪水;如果当前员工的薪水是最高的,就将下一个更高的薪水设置为最低的薪水。你想返回如下结果集。
ENAME SAL FORWARD REWIND
---------- ---------- ---------- ----------
SMITH 800 950 5000
JAMES 950 1100 800
ADAMS 1100 1250 950
WARD 1250 1250 1100
MARTIN 1250 1300 1250
MILLER 1300 1500 1250
TURNER 1500 1600 1300
ALLEN 1600 2450 1500
CLARK 2450 2850 1600
BLAKE 2850 2975 2450
JONES 2975 3000 2850
SCOTT 3000 3000 2975
FORD 3000 5000 3000
KING 5000 800 3000
解决方案:窗口函数 LEAD OVER 和 LAG OVER 能够轻松解决这个问题,而且编写出来的查询的可读性极高。要访问当前行的前一行和下一行,可以分别使用窗口函数 LAG OVER和 LEAD OVER。
select ename,sal,
coalesce(lead(sal)over(order by sal),min(sal)over()) forward,
coalesce(lag(sal)over(order by sal),max(sal)over()) rewind
from emp;
ename | sal | forward | rewind
--------+------+---------+--------
SMITH | 800 | 950 | 5000
JAMES | 950 | 1100 | 800
ADAMS | 1100 | 1250 | 950
WARD | 1250 | 1250 | 1100
MARTIN | 1250 | 1300 | 1250
MILLER | 1300 | 1500 | 1250
TURNER | 1500 | 1600 | 1300
ALLEN | 1600 | 2450 | 1500
CLARK | 2450 | 2850 | 1600
BLAKE | 2850 | 2975 | 2450
JONES | 2975 | 3000 | 2850
FORD | 3000 | 3000 | 2975
SCOTT | 3000 | 5000 | 3000
KING | 5000 | 800 | 3000
(14 rows)
默认情况下,窗口函数 LAG OVER 和 LEAD OVER 会分别返回前一行的值和后一行的值。在 OVER 子句的ORDER BY 部分,可以定义“前一行”和“后一行”。如果查看上述解决方案,你将发现第一步是返回后一行和前一行,而行的排列顺序是基于 SAL 的。
select ename,sal,
lead(sal)over(order by sal) forward,
lag(sal)over(order by sal) rewind
from emp
ENAME SAL FORWARD REWIND
---------- ---------- ---------- ----------
SMITH 800 950
JAMES 950 1100 800
ADAMS 1100 1250 950
WARD 1250 1250 1100
MARTIN 1250 1300 1250
MILLER 1300 1500 1250
TURNER 1500 1600 1300
ALLEN 1600 2450 1500
CLARK 2450 2850 1600
BLAKE 2850 2975 2450
JONES 2975 3000 2850
SCOTT 3000 3000 2975
FORD 3000 5000 3000
KING 5000 3000
注意,员工 SMITH 的 REWIND 为 NULL,而员工 KING的 FORWARD 为 NULL,因为这两名员工的薪水分别是最 低和最高的。本节“问题”部分指出,如果 FORWARD 或REWIND 的值为 NULL,就执行回转操作。这意味着对于薪水最高的员工,应将其 FORWARD 值设置为表中最低的薪水值,而对于薪水最低的员工,应将其 REWIND 值设置为表中最高的薪水值。在没有指定分区或窗口的情况下(OVER 子句后面的括号内是空的),窗口函数 MINOVER 和 MAX OVER 将分别返回表中最低薪水值和最高薪水值。
select ename,sal,
coalesce(lead(sal)over(order by sal),min(sal)over()) forward,
coalesce(lag(sal)over(order by sal),max(sal)over()) rewind
from emp
ENAME SAL FORWARD REWIND
---------- ---------- ---------- ----------
SMITH 800 950 5000
JAMES 950 1100 800
ADAMS 1100 1250 950
WARD 1250 1250 1100
MARTIN 1250 1300 1250
MILLER 1300 1500 1250
TURNER 1500 1600 1300
ALLEN 1600 2450 1500
CLARK 2450 2850 1600
BLAKE 2850 2975 2450
JONES 2975 3000 2850
SCOTT 3000 3000 2975
FORD 3000 5000 3000
KING 5000 800 3000
LAG OVER 和 LEAD OVER 另一个很有用的特征是,可以指定你能向前或向后跳多远。在本例中,你只往前或往后跳了一行。要分别往前跳 3 行、往后跳 5 行很容易,只需指定 3 和 5。
select ename,sal,
lead(sal,3)over(order by sal) forward,
lag(sal,5)over(order by sal) rewind
from emp
ENAME SAL FORWARD REWIND
---------- ---------- ---------- ----------
SMITH 800 1250
JAMES 950 1250
ADAMS 1100 1300
WARD 1250 1500
MARTIN 1250 1600
MILLER 1300 2450 800
TURNER 1500 2850 950
ALLEN 1600 2975 1100
CLARK 2450 3000 1250
BLAKE 2850 3000 1250
JONES 2975 5000 1300
SCOTT 3000 1500
FORD 3000 1600
KING 5000 2450
9、结果排名
问题:你想对 EMP 表中的薪水排名,并保留相同的值。你想返回如下结果集。
RNK SAL
--- -------
1 800
2 950
3 1100
4 1250
4 1250
5 1300
6 1500
7 1600
8 2450
9 2850
10 2975
11 3000
11 3000
12 5000
解决方案:窗口函数使得编写排名查询超级简单。对排名来说,有 3个窗口函数特别有用,即 DENSE_RANK OVER、ROW_NUMBER OVER 和 RANK OVER。
由于你想保留相同的值,因此使用窗口函数DENSE_RANK OVER。
select dense_rank() over(order by sal) rnk, sal
from emp;
rnk | sal
-----+------
1 | 800
2 | 950
3 | 1100
4 | 1250
4 | 1250
5 | 1300
6 | 1500
7 | 1600
8 | 2450
9 | 2850
10 | 2975
11 | 3000
11 | 3000
12 | 5000
(14 rows)
10、消除重复行
问题:你想找出 EMP 表中不同的职位类型,但不想看到重复的行。结果集如下所示。
JOB
---------
ANALYST
CLERK
MANAGER
PRESIDENT
SALESMAN
解决方案:所有 RDBMS 都支持关键字 DISTINCT,这也是消除结果集中重复行的最简单机制。然而,本实例还将介绍另外两种消除重复行的方法。
使用 DISTINCT(或 GROUP BY)的传统方法肯定管用。下面是另一种解决方案,使用的是窗口函数ROW_NUMBER OVER。
select job
from (
select job, row_number()over(partition by job order by job) rn
from emp
) x
where rn = 1;
job
-----------
ANALYST
CLERK
MANAGER
PRESIDENT
SALESMAN
(5 rows)
传统解决方案:使用关键字 DISTINCT 来消除结果集中的重复行。
select distinct job
from emp;
另外,也可以使用 GROUP BY 来消除重复行。
select job
from emp
group by job
11、查找马值
问题:你想返回一个结果集,其中包含每位员工的名字、所属的部门、薪水、获聘日期以及所属部门最后聘请的员工的薪水。你想返回的结果集如下所示。
DEPTNO ENAME SAL HIREDATE LATEST_SAL
------ ---------- ---------- ----------- ----------
10 MILLER 1300 23-JAN-2007 1300
10 KING 5000 17-NOV-2006 1300
10 CLARK 2450 09-JUN-2006 1300
20 ADAMS 1100 12-JAN-2007 1100
20 SCOTT 3000 09-DEC-2007 1100
20 FORD 3000 03-DEC-2006 1100
20 JONES 2975 02-APR-2006 1100
20 SMITH 800 17-DEC-2005 1100
30 JAMES 950 03-DEC-2006 950
30 MARTIN 1250 28-SEP-2006 950
30 TURNER 1500 08-SEP-2006 950
30 BLAKE 2850 01-MAY-2006 950
30 WARD 1250 22-FEB-2006 950
30 ALLEN 1600 20-FEB-2006 950
其中 LATEST_SAL 列的值就是马值(knight value),因为查找这些值的方法与国际象棋中马的走法类似。确定结果的方式与确定马的下一个位置相同:先跳到某一行,然后跳到某一列,如图 11-1 所示。要找到正确的LATEST_SAL 值,必须先定位到(跳到)当前部门中最后的 HIREDATE 所在的行,然后跳到该行的 SAL 列。
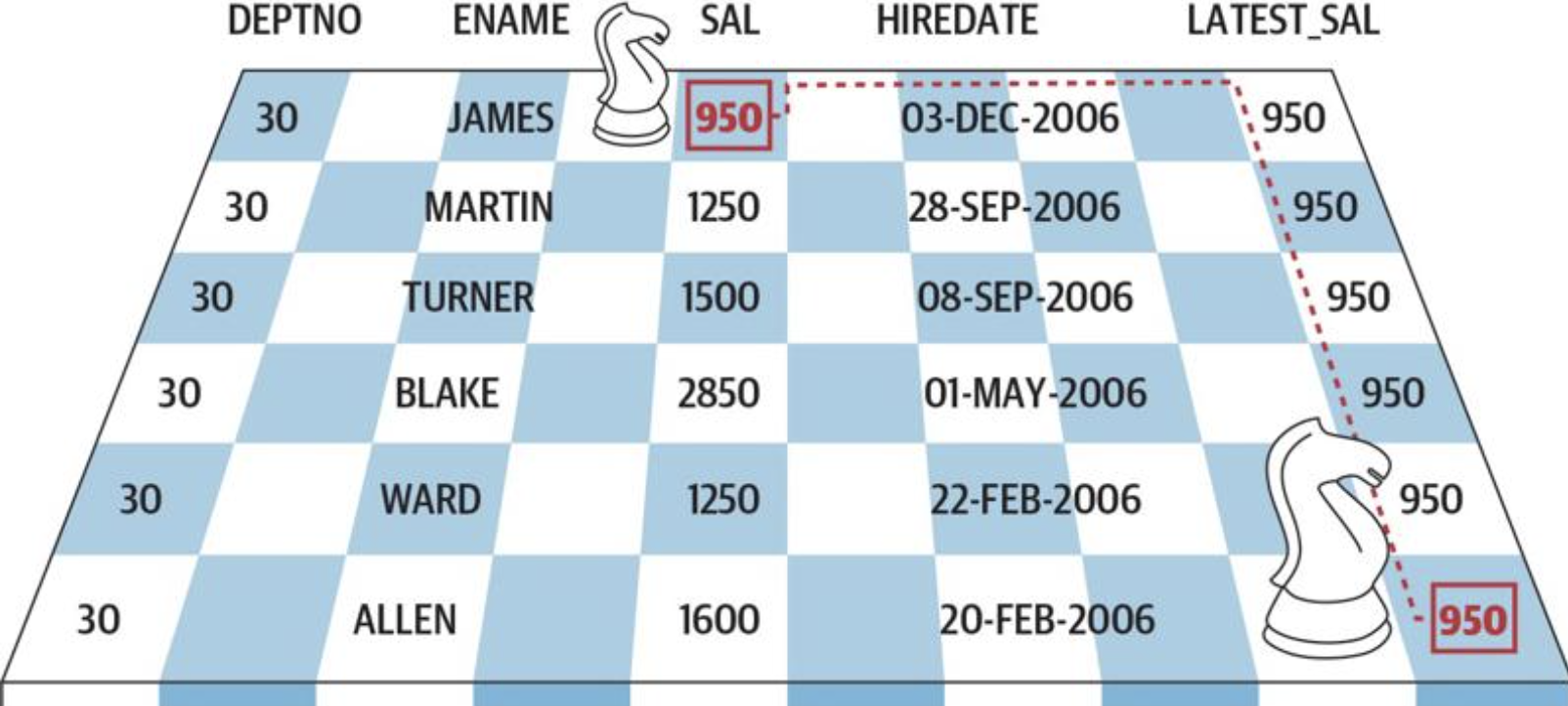
“马值”这个术语是我的一个非常机灵的同事 Kay Young 杜撰的。在 Kay 帮我审阅完本书的实例后,我跟他说不知道如何命名这个实例。考虑到需要先查看一行,再跳到另一行获取值,Kay 想出了“马值”这个名词。
解决方案:
DB2 和 SQL Server:在子查询中使用 CASE 表达式,将每个部门最后聘请的员工的 LATEST_SAL 值设置为其 SAL,将其他员工的LATEST_SAL 值设置为 0。在外部查询中,使用窗口函数 MAX OVER 将每位员工的 LATEST_SAL 值都设置为其部门的非零 LATEST_SAL 值。
select deptno,
ename,
sal,
hiredate,
max(latest_sal)over(partition by deptno) latest_sal
from (
select deptno,
ename,
sal,
hiredate,
case
when hiredate = max(hiredate)over(partition by deptno)
then sal else 0
end latest_sal
from emp
) x
order by 1, 4 desc;
Oracle:使用窗口函数 MAX OVER 返回每个部门最后聘请的员工的 SAL。为此,在 KEEP 子句中使用函数 DENSE_RANK和 LAST,并按 HIREDATE 排序,以返回给定部门中最后聘请的员工的 SAL。
select deptno,
ename,
sal,
hiredate,
max(sal)
keep(dense_rank last order by hiredate)
over(partition by deptno) latest_sal
from emp
order by 1, 4 desc;
12、生成简单预测
问题:你想根据当前的数据返回表示未来行动的行和列。例如,请看下面的结果集。
ID ORDER_DATE PROCESS_DATE
-- ----------- ------------
1 25-SEP-2005 27-SEP-2005
2 26-SEP-2005 28-SEP-2005
3 27-SEP-2005 29-SEP-2005
对于这个结果集中的每一行,你都想返回 3 行(当前行和另外两行)数据。除了额外的行,你还想返回另外两列,其中包含预期的订单处理日期。
从前面的结果集可知,订单将在两天后处理。假设订单处理完成后,下一步是订单核验,最后一步是发货。订单核验在订单处理后一天进行,而发货在订单核验后一天进行。你想返回一个呈现整个过程的结果集。换言之,你想将前面的结果集转换为下面的结果集。
ID ORDER_DATE PROCESS_DATE VERIFIED SHIPPED
-- ----------- ------------ ----------- -----------
1 25-SEP-2005 27-SEP-2005
1 25-SEP-2005 27-SEP-2005 28-SEP-2005
1 25-SEP-2005 27-SEP-2005 28-SEP-2005 29-SEP-2005
2 26-SEP-2005 28-SEP-2005
2 26-SEP-2005 28-SEP-2005 29-SEP-2005
2 26-SEP-2005 28-SEP-2005 29-SEP-2005 30-SEP-2005
3 27-SEP-2005 29-SEP-2005
3 27-SEP-2005 29-SEP-2005 30-SEP-2005
3 27-SEP-2005 29-SEP-2005 30-SEP-2005 01-OCT-2005
解决方案:关键是使用笛卡儿积为每个订单再生成两行数据,然后使用 CASE 表达式来创建所需的列值。
DB2、MySQL 和 SQL Server:使用递归式 WITH 子句生成笛卡儿积所需的行。除了用来获取当前日期的函数外,DB2 和 SQL Server 解决方案完全相同。DB2 解决方案使用的是 CURRENT_DATE,而SQL Server 解决方案使用的是 GETDATE。MySQL 解决方案使用的是 CURDATE,并需要在 WITH 后面插入关键字 RECURSIVE,以指出这是一个递归式 CTE。下面显示了 SQL Server 解决方案。
with nrows(n) as (
select 1 from t1 union all
select n+1 from nrows where n+1 <= 3
)
select id,
order_date,
process_date,
case when nrows.n >= 2
then process_date+1
else null
end as verified,
case when nrows.n = 3
then process_date+2
else null
end as shipped
from (
select nrows.n id,
getdate()+nrows.n as order_date,
getdate()+nrows.n+2 as process_date
from nrows
) orders, nrows
order by 1;
Oracle:使用分层子句 CONNECT BY 生成笛卡儿积所需的 3 行数据。使用 WITH 子句,以便重用 CONNECT BY 返回的结果,从而避免再次调用它。
with nrows as (
select level n
from dual
connect by level <= 3
)
select id,
order_date,
process_date,
case when nrows.n >= 2
then process_date+1
else null
end as verified,
case when nrows.n = 3
then process_date+2
else null
end as shipped
from (
select nrows.n id,
sysdate+nrows.n as order_date,
sysdate+nrows.n+2 as process_date
from nrows
) orders, nrows;
PostgreSQL:可以使用多种不同的方式生成笛卡儿积,该解决方案使用了 PostgreSQL 函数 GENERATE_SERIES。
select id,
order_date,
process_date,
case when gs.n >= 2
then process_date+1
else null
end as verified,
case when gs.n = 3
then process_date+2
else null
end as shipped
from (
select gs.id,
current_date+gs.id as order_date,
current_date+gs.id+2 as process_date
from generate_series(1,3) gs (id)
) orders, generate_series(1,3) gs(n);
id | order_date | process_date | verified | shipped
----+------------+--------------+------------+------------
1 | 2026-06-19 | 2026-06-21 | |
1 | 2026-06-19 | 2026-06-21 | 2026-06-22 |
1 | 2026-06-19 | 2026-06-21 | 2026-06-22 | 2026-06-23
2 | 2026-06-20 | 2026-06-22 | |
2 | 2026-06-20 | 2026-06-22 | 2026-06-23 |
2 | 2026-06-20 | 2026-06-22 | 2026-06-23 | 2026-06-24
3 | 2026-06-21 | 2026-06-23 | |
3 | 2026-06-21 | 2026-06-23 | 2026-06-24 |
3 | 2026-06-21 | 2026-06-23 | 2026-06-24 | 2026-06-25
(9 rows)
MySQL:MySQL 不支持自动生成行的函数。


















 1324
1324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










