



概要
AI 技术的应用极大地提升了运营效率,并为电商行业带来了个性化推荐、用户行为分析、库存管理和市场趋势预测等关键领域的数据分析能力,在这种背景下,构建一个高效、可靠的AI电商数据分析系统显得尤为关键。
本文旨在详细指导大家如何利用腾讯云的高性能应用服务 HAI 和TDSQL-C MySQL Serverless 版构建 AI电商数据分析系统。HAI作为一个面向AI和科学计算的GPU应用服务产品,提供了强大的计算能力,使得复杂AI模型如LLM的快速部署和运行成为可能,进而支持自然语言处理和图像生成等高级任务。与此同时,TDSQL-C MySQL版作为一款云原生关系型数据库,其100%的MySQL兼容性,以及极致的弹性、高性能和高可用性,使其成为电商业务中处理海量数据存储和查询的理想选择。
本文将通过 Python 编程语言和基于 Langchain 的框架,逐步引导大家完成系统的构建和部署。
整体架构流程
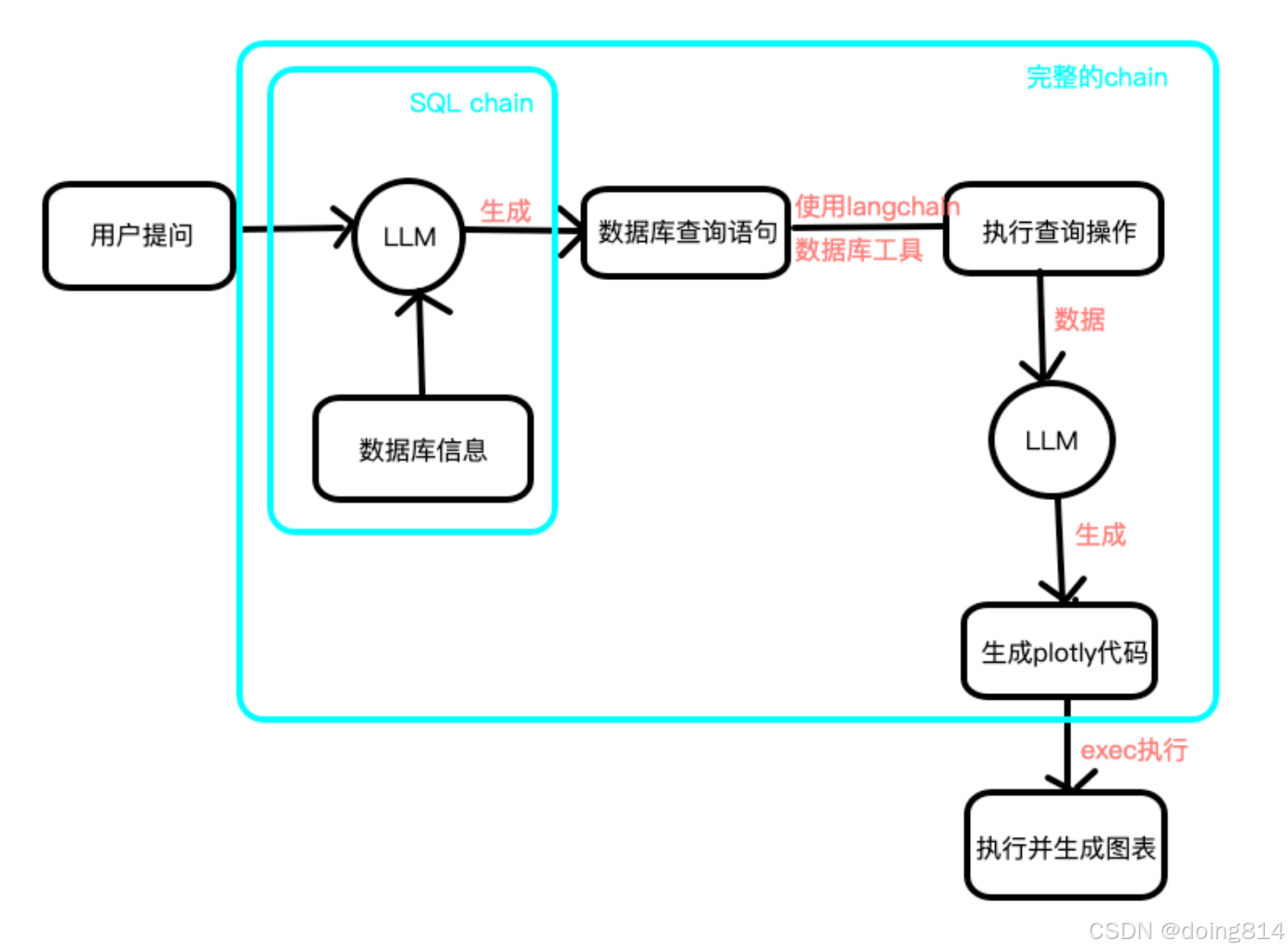
本次实验我们基于 TDSQL-C Mysql Serverless 快速搭建 AI电商数据分析系统,实现思路如下:
1、程序流程图设计
2、TDSQL-C Mysql Serverless 搭建
3、HAI llama 大模型部署
4、开发环境搭建
5、AI电商数据分析系统构建
技术细节
第一步:学习相关视频:AI驱动的TDSQL-Cserverless实战营:https://cloud.tencent.com/developer/learning/camp/25?fromSource=gwzcw.8888588.8888588.8888588&utm_medium=cpc&utm_id=gwzcw.8888588.8888588.8888588
第二步:新建腾讯云账号并登录,根据视频提供的信息,新建【算力管理】和【数据库】,详细配置见【第一步】里的视频-任务6视频。
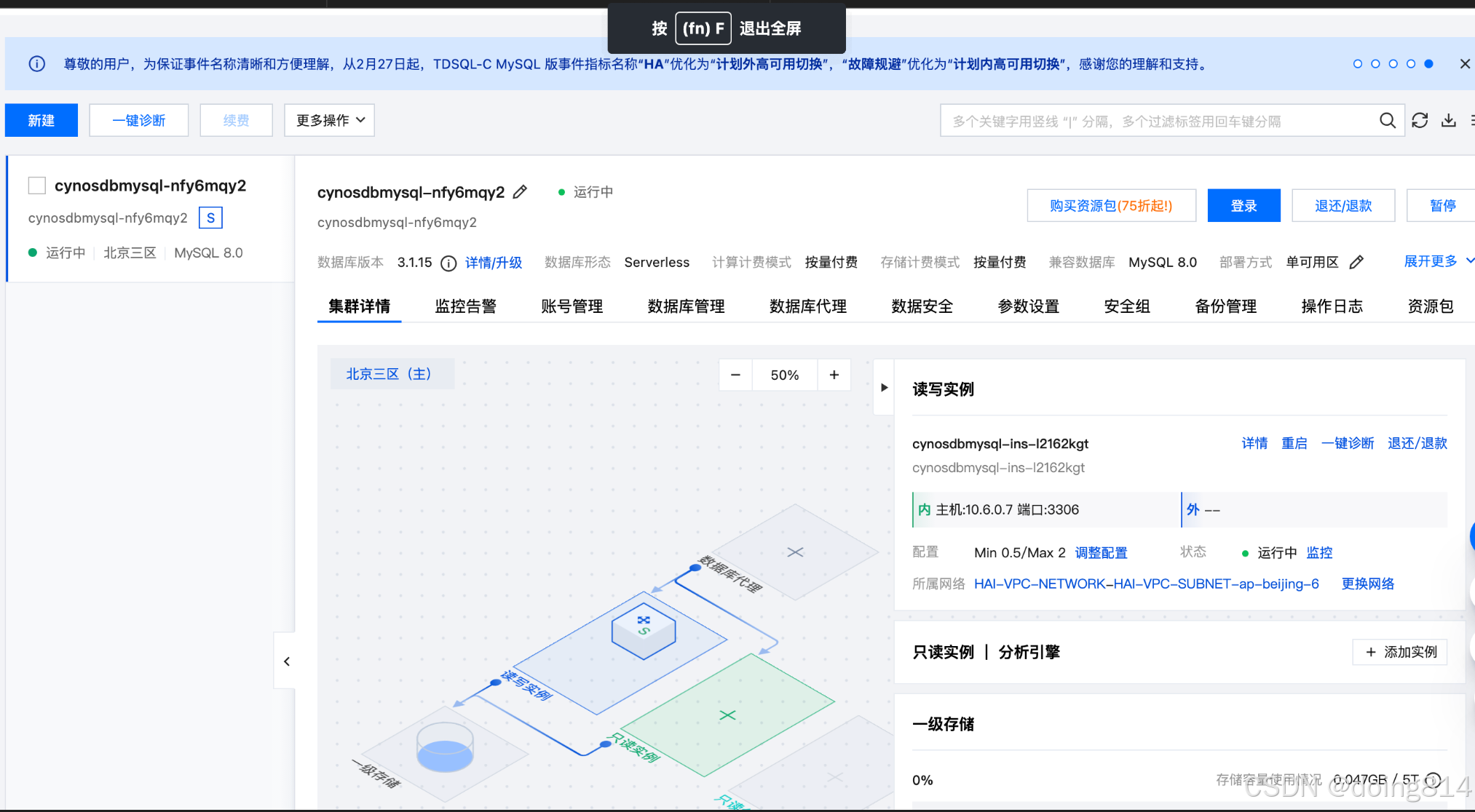
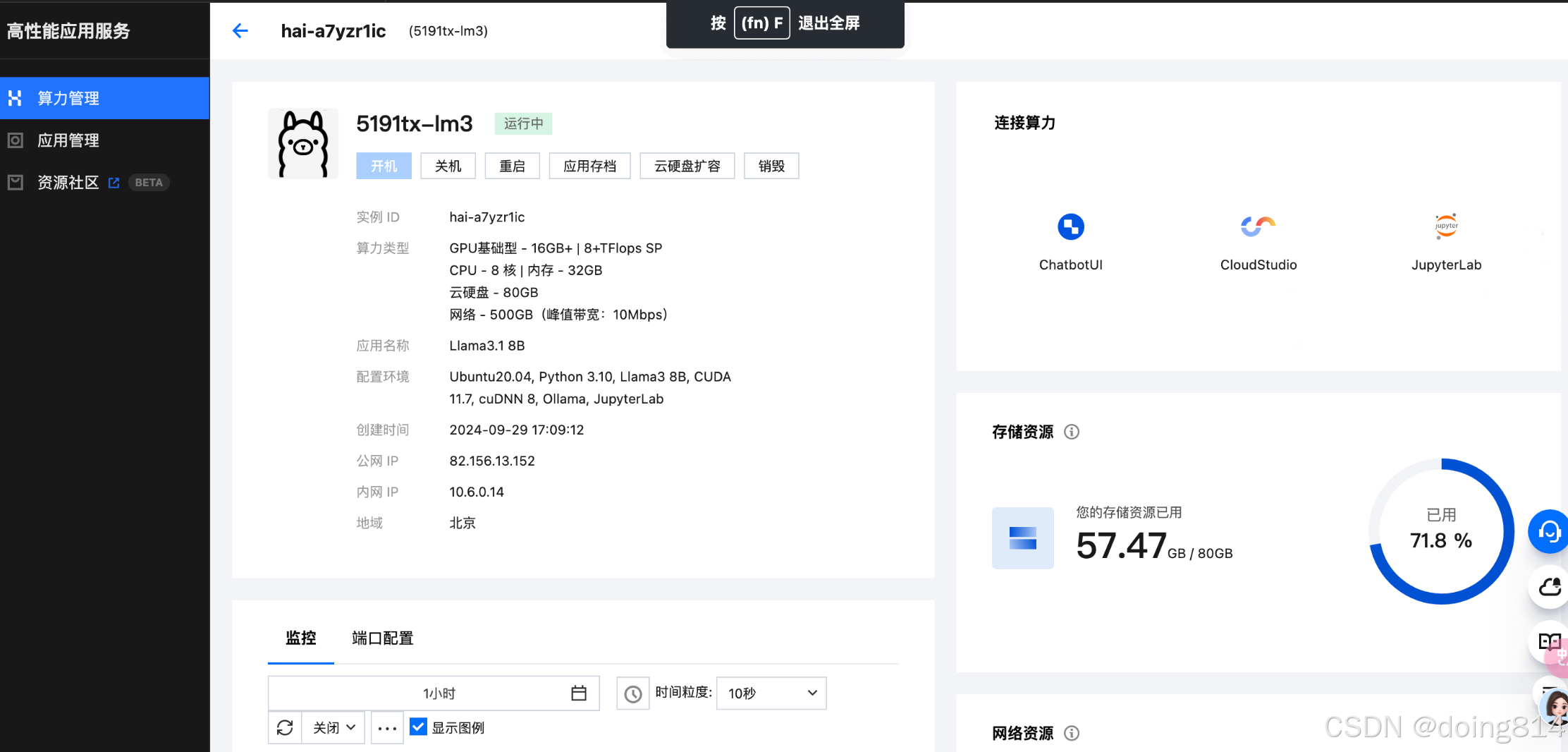
注意:算力中心一旦建立,就会收费,避免欠费,请预存10元,最好在3个小时内完成实验,并销毁。
第三步:按照python环境,运行相关代码
python环境一定要大于3.8.否则会安装失败。本人是3.7版本,导致卸载重装,非常费事。最好用brew 安装,然后修改相关配置后,需要安装
···
pip3 install openai
pip3 install langchain
pip3 install langchain-core
pip3 install langchain-community
pip3 install mysql-connector-python
pip3 install streamlit
pip3 install plotly
pip3 install numpy
pip3 install pandas
pip3 install watchdog
pip3 install matplotlib
pip3 install kaleido
···
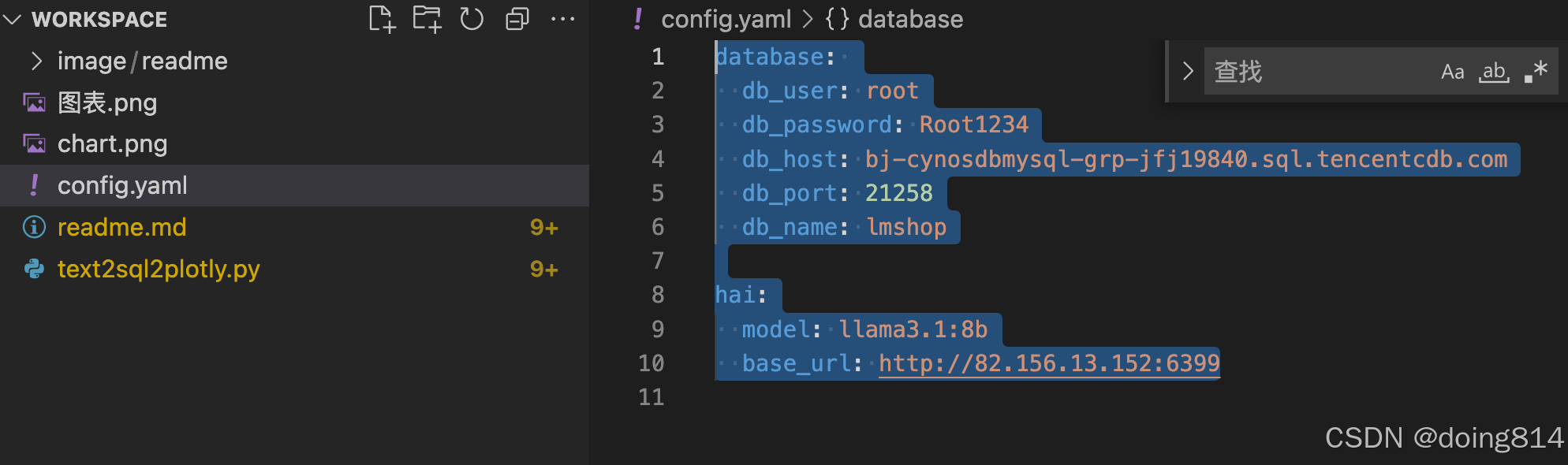
一切安装完成后,配置数据库连接:
···
database:
db_user: root
db_password: Root1234
db_host: bj-cynosdbmysql-grp-jfj19840.sql.tencentcdb.com
db_port: 21258
db_name: lmshop
hai:
model: llama3.1:8b
base_url: http://82.156.13.152:6399
···
python代码如下:
···
from langchain_community.utilities import SQLDatabase
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
import yaml
import mysql.connector
from decimal import Decimal
import plotly.graph_objects as go
import plotly
import pkg_resources
import matplotlib
yaml_file_path = ‘config.yaml’
with open(yaml_file_path, ‘r’) as file:
config_data = yaml.safe_load(file)
#获取所有的已安装的pip包
def get_piplist§:
return [d.project_name for d in pkg_resources.working_set]
#获取llm用于提供AI交互
ollama = ChatOllama(model=config_data[‘hai’][‘model’],base_url=config_data[‘hai’][‘base_url’])
db_user = config_data[‘database’][‘db_user’]
db_password = config_data[‘database’][‘db_password’]
db_host = config_data[‘database’][‘db_host’]
db_port= config_data[‘database’][‘db_port’]
db_name = config_data[‘database’][‘db_name’]
获得schema
def get_schema(db):
schema = mysql_db.get_table_info()
return schema
def getResult(content):
global mysql_db
# 数据库连接
mysql_db = SQLDatabase.from_uri(f"mysql+mysqlconnector://{db_user}:{db_password}@{db_host}:{db_port}/{db_name}")
# 获得 数据库中表的信息
#mysql_db_schema = mysql_db.get_table_info()
#print(mysql_db_schema)
template = “”“基于下面提供的数据库schema, 根据用户提供的要求编写sql查询语句,要求尽量使用最优sql,每次查询都是独立的问题,不要收到其他查询的干扰:
{schema}
Question: {question}
只返回sql语句,不要任何其他多余的字符,例如markdown的格式字符等:
如果有异常抛出不要显示出来
“””
prompt = ChatPromptTemplate.from_template(template)
text_2_sql_chain = (
RunnablePassthrough.assign(schema=get_schema)
| prompt
| ollama
| StrOutputParser()
)
# 执行langchain 获取操作的sql语句
sql = text_2_sql_chain.invoke({"question": content})
print(sql)
#连接数据库进行数据的获取
# 配置连接信息
conn = mysql.connector.connect(
host=db_host,
port=db_port,
user=db_user,
password=db_password,
database=db_name
)
# 创建游标对象
cursor = conn.cursor()
# 查询数据
cursor.execute(sql.strip("```").strip("```sql"))
info = cursor.fetchall()
# 打印结果
#for row in info:
#print(row)
# 关闭游标和数据库连接
cursor.close()
conn.close()
#根据数据生成对应的图表
print(info)
template2 = """
以下提供当前python环境已经安装的pip包集合:
{installed_packages};
请根据data提供的信息,生成是一个适合展示数据的plotly的图表的可执行代码,要求如下:
1.不要导入没有安装的pip包代码
2.如果存在多个数据类别,尽量使用柱状图,循环生成时图表中对不同数据请使用不同颜色区分,
3.图表要生成图片格式,保存在当前文件夹下即可,名称固定为:图表.png,
4.我需要您生成的代码是没有 Markdown 标记的,纯粹的编程语言代码。
5.生成的代码请注意将所有依赖包提前导入,
6.不要使用iplot等需要特定环境的代码
7.请注意数据之间是否可以转换,使用正确的代码
8.不需要生成注释
data:{data}
这是查询的sql语句与文本:
sql:{sql}
question:{question}
返回数据要求:
仅仅返回python代码,不要有额外的字符
"""
prompt2 = ChatPromptTemplate.from_template(template2)
data_2_code_chain = (
RunnablePassthrough.assign(installed_packages=get_piplist)
| prompt2
| ollama
| StrOutputParser()
)
# 执行langchain 获取操作的sql语句
code = data_2_code_chain.invoke({"data": info,"sql":sql,'question':content})
#删除数据两端可能存在的markdown格式
print(code.strip("```").strip("```python"))
exec(code.strip("```").strip("```python"))
return {"code":code,"SQL":sql,"Query":info}
构建展示页面
import streamlit
设置页面标题
streamlit.title(‘AI驱动的数据库TDSQL-C 电商可视化分析小助手’)
设置对话框
content = streamlit.text_area(‘请输入想查询的信息’, value=‘’, max_chars=None)
提问按钮 # 设置点击操作
if streamlit.button(‘提问’):
#开始ai及langchain操作
if content:
#进行结果获取
result = getResult(content)
#显示操作结果
streamlit.write(‘AI生成的SQL语句:’)
streamlit.write(result[‘SQL’])
streamlit.write(‘SQL语句的查询结果:’)
streamlit.write(result[‘Query’])
streamlit.write(‘plotly图表代码:’)
streamlit.write(result[‘code’])
# 显示图表内容(生成在getResult中)
streamlit.image(‘./图表.png’, width=800)
···
代码写好之后,在终端运行:
``streamlit run text2sql2plotly.py```
生成如下内容:
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://10.254.50.200:8501
会自动打开这个地址:http://localhost:8501/
然后在文本框输入:查询一下每类商品的名称和对应的销售总额
就会得到一些信息:
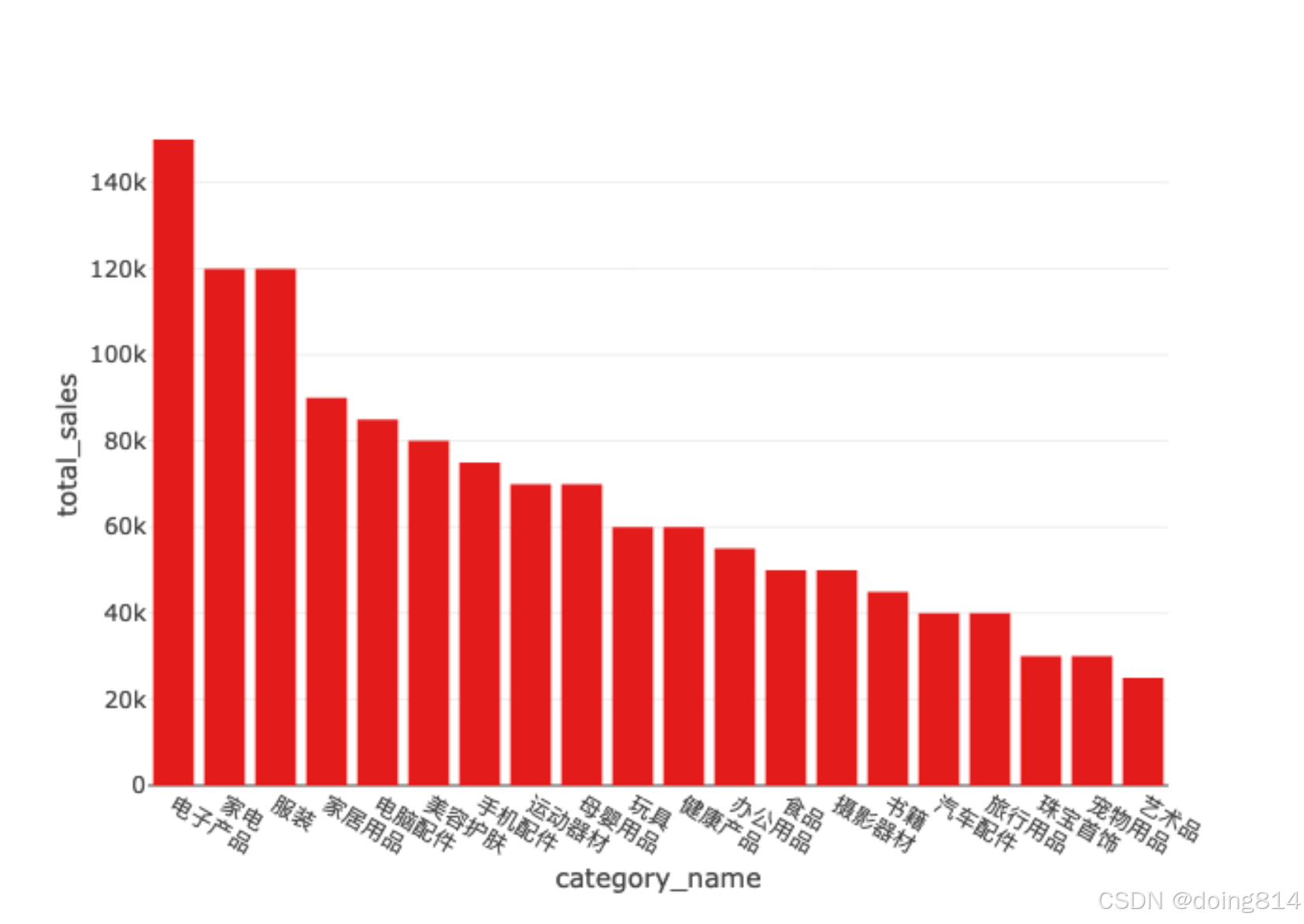
到这里,一切都体验完了。
小结
`整个体验的流程非常顺畅。通过这个项目,感知到行业的变化,Ai的强大。一站式的后台搭建,从数据库到算力到大模型的结合,然后很少的编码就能实现日常数据分析需求,非常的强大。对于一些公司,这个一个非常好的降本提升人效的方案。


















 1739
1739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










