




层归一化让神经网络的每层输出回归统一尺度,但统一了尺度的信号到底该怎么理解呢?Transformer架构中,自注意力层负责找出词与词之间的关联关系,但这还不够。模型需要一种机制,对注意力层的输出做深度加工,提炼出更有代表性的语义特征。这个机制就是前馈网络——它的作用就像给模型配了一只放大镜,放大看细节,找到关键特征。
什么是前馈网络
在Transformer的每一层中,数据流转经过两个核心模块:先是自注意力层,再是前馈网络。前馈网络(Feed Forward Network,简称FFN)的结构其实非常简单,就是两个线性变换之间夹一个非线性激活函数:
$$FFN(x) = W_2 \cdot \sigma(W_1 \cdot x + b_1) + b_2$$
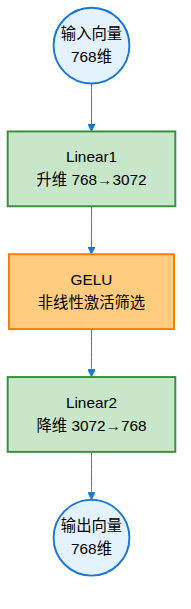
这里的 $x$ 是输入向量,$W_1$ 和 $W_2$ 是两个线性变换矩阵,$\sigma$ 是非线性激活函数(LLM中几乎全部使用GELU,早期用ReLU),$b_1$ 和 $b_2$ 是偏置项。
这个结构的核心思路可以概括为三个步骤:升维放大、非线性筛选、降维回收。
三步法:放大、筛选、回收
第一步:升维放大
前馈网络的第一个线性变换 $W_1$ 负责"升维"。它将输入向量从一个较低的维度映射到一个更高的维度。以经典的Transformer架构为例,如果输入维度是768维,经过 $W_1$ 后会放大到3072维,通常是输入维度的四倍。
为什么要升维?这背后的直觉是:低维空间的信息容量有限,很多复杂模式在低维空间中无法被线性分离。当我们将向量映射到高维空间时,模型获得了更多的"自由度"和"参数空间",能够捕捉更精细的语义特征。
举个生活中的例子:如果你只说"一个年轻人",这个描述非常宽泛,涵盖了从十几岁到四十多岁、各种体型和风格的人。但如果我做了升维——描述变成"20到25岁,身高175公分,短发,戴黑框眼镜,喜欢听音乐"——虽然描述的是同一个对象的信息量,但特征已经清晰具体了很多。升维就是这样一种从模糊到精确的映射过程。
高维空间为模型提供了更丰富的特征表示能力,这实际上就是核方法(Kernel Method)的核心思想:在高维空间中,原本在低维空间中不可分的数据模式变得线性可分。
第二步:非线性筛选
升维之后,数据进入非线性激活函数。在大型语言模型中,GELU(Gaussian Error Linear Unit)是绝对的主流选择,早期的Transformer和BERT则使用ReLU。
GELU的数学表达式是 $x \cdot \Phi(x)$,其中 $\Phi(x)$ 是标准正态分布的累积分布函数。它的特点是平滑过渡——当输入值为正时,输出接近输入值本身;当输入值为负时,输出趋近于零;在零




















:前馈网络 —— 特征提取的关键&spm=1001.2101.3001.5002&articleId=161838441&d=1&t=3&u=c525ba409a744cd099351b22d1e21075)
 2158
2158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












