




BERT vs GPT——编码器 vs 解码器
上节课我们讲了Softmax,它负责把打分变成概率,是注意力机制的基石。有了概率,模型能做分类。但要真正理解语言、生成文本,还需要编码器和解码器这两个核心组件。BERT和GPT,正是把这两个组件分别放大后得到的模型。
一、从翻译说起:Transformer的初衷
Transformer诞生之初,是为了机器翻译问题。翻译这件事,天然需要两半:一半天干的是理解——读懂源语言的意思;另一半天干的是生成——用目标语言把它写出来。所以Transformer设计了编码器来理解,解码器来生成。
Transformer的翻译场景:编码器理解源语言,解码器生成目标语言
后来有人发现,如果把编码器单独拉长,堆叠很多层,就变成了BERT;如果把解码器单独拉长,就变成了GPT。这就是BERT和GPT最根本的由来——翻译的"理解"和"生成"两端,分别长成了两个参天大树。
这个理解方式很关键:BERT和GPT不是两种完全不同的模型,它们用的是同一套积木,只是搭法不同。理解了Transformer的编码器-解码器架构,就理解了BERT和GPT的根本区别。
二、BERT:双向理解的大师
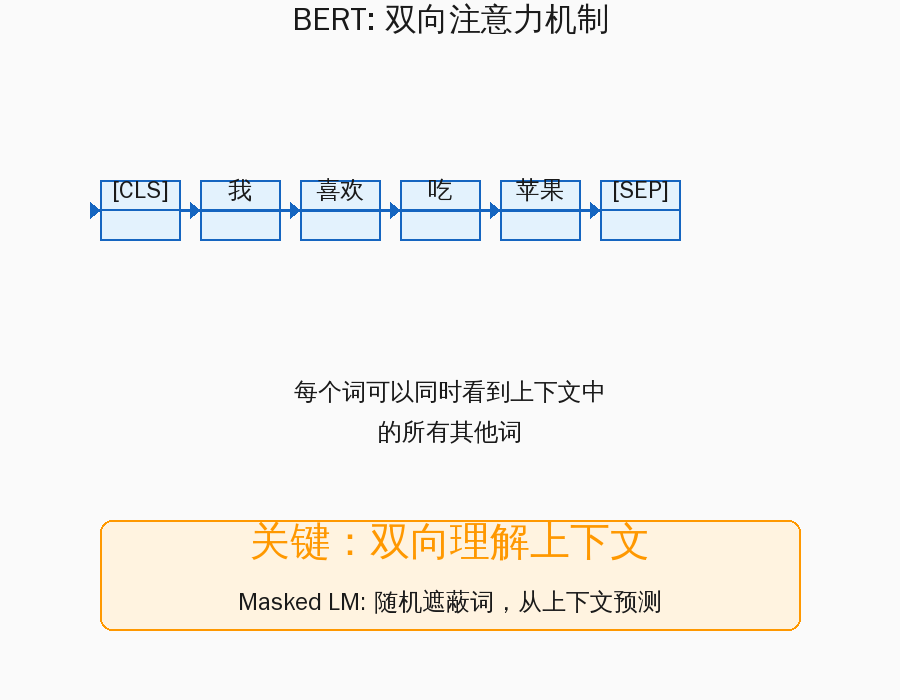
BERT的全称是Bidirectional Encoder Representations from Transformers,核心就是双向编码器。它里面全是编码器层堆叠,每个词在计算时能看到整个句子里的所有其他词,不管是前面的还是后面的。
B





















 2665
2665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












