




 本文深入探讨了神经网络模型的稀疏性,包括CNNs、序列到序列模型、GANs、脉冲神经网络和图神经网络等。分析了稀疏性的来源,如激活函数、dropout和权重剪枝,及其对模型性能和计算效率的影响。讨论了结构化与非结构化稀疏性,以及在GPU加速和硬件优化方面的策略。此外,还涉及了推荐系统、目标检测网络和文本分析中的稀疏性问题,并提出了处理高维数据稀疏性的方法。
本文深入探讨了神经网络模型的稀疏性,包括CNNs、序列到序列模型、GANs、脉冲神经网络和图神经网络等。分析了稀疏性的来源,如激活函数、dropout和权重剪枝,及其对模型性能和计算效率的影响。讨论了结构化与非结构化稀疏性,以及在GPU加速和硬件优化方面的策略。此外,还涉及了推荐系统、目标检测网络和文本分析中的稀疏性问题,并提出了处理高维数据稀疏性的方法。

背景
人工智能在诸多领域都取得了突破性进展,例如计算机视觉,nlp等。但是,各种机器学习模型存在一个很致命的问题:神经网络巨大的计算量+访存量,这对性能提出了较高的要求(能耗、延时、访存等)。一种可行的解决方案:充分利用机器学习模型中的稀疏性。所谓的稀疏性是指在计算中不必要,没用的计算。通过减少计算量,就可以保证降低不必要的存储和计算,提升机器学习模型部署时的性能。
稀疏性的分布
根据稀疏性的来源,我们可以基本分为以下几类。
- 科学计算和传统的机器学习
- 神经网络:神经网络(CNN,DNN)中存在大量的不需要计算的数据。例如大量的非零权重,dropout,一些典型模型构建和操作(如Relu,dropout)等操作将大量零值引入到activation中。为了解决这些不必要的计算,一些主流神经网络压缩技术(如稀疏化和量化)通过对神经网络模型参数的稀疏化来压缩模型大小。稀疏化就是跳过不必要的计算,包含剪枝。量化是指将需要浮点数表示的小数用int或者二值来表示。一般稀疏性分为权重和activation两种。
- 输入数据

CNNs
用于图像(自动驾驶)。CNN的特征是包括大量的全连接层(FC)和卷积层(Conv),前面的层提取低纬的信息(图像中物体的边缘),后面的层提取高维的信息(分类)。CNNs的稀疏性主要来源于
- 激活函数:例如relu会引入大量的中间变量的稀疏性。
- Dropout:这个是为了解决过拟合的问题。目前有target dropout和weight dropout等,这些会一如fc和conv的稀疏性。
- 参数的稀疏性:一般会利用一些剪枝的算法。根据剪枝出来的粒度可以分为
Structured sparsity / unstructured sparsity
结构化稀疏就是指我们需要剪掉的计算的分布是有一定规律的,这种对硬件更加友好,但是在影响模型的精度方面是有很大的负面影响的;非结构化稀疏是指我们需要剪掉的计算的分布没有什么规律,因此我们可以剪掉完全的0值,这样对精度的影响很小,但是这种会对硬件的加速非常不友好。
结构化稀疏根据粒度可以分为下面的几个方面:
- vector-level:它相对于细粒度更大,属于对卷积核内部的剪枝,例如剪掉一行或者一列。
- kernel-level:即去除某个卷积核的channel,它将丢弃对输入通道中对应计算通道的activation。
- filter-level:对整个卷积核组进行剪枝,会造成activation过程中输出特征通道数的改变。这种的剪掉的东西太多了,有可能会造成整个accuracy的drop。
Balanced Sparsity
平衡稀疏是一种新颖的细粒度稀疏性,这种稀疏性在持较高的模型精度的同时,高效地实现了GPU加速。对于一个权值矩阵来说,每个矩阵行均分为多个大小相等的块,并且每个块具有相同数量的非零权重。 图显示了从密集矩阵行中删除的块平衡稀疏矩阵行的示例。在此示例中,矩阵行被分为4个块,并且每个区块的稀疏度为50%。每个块的长度为4。相同的分割方法和稀疏性适用于权重矩阵中的其他行。
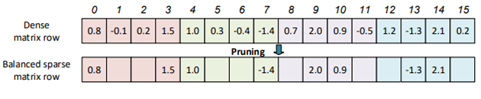
设计平衡稀疏性的优点是:
1)计算工作量均衡的块分区,每个块自然适合具有高实用并行度的GPU。
2)内部非零权重的随机分布对稀疏结构几乎没有限制,并且可能不会影响模型的准确性。
加速计算的方式
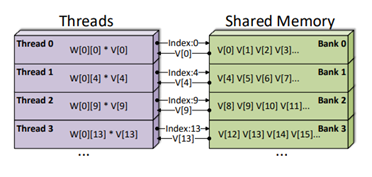
Pattern sparsity
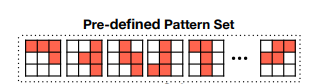
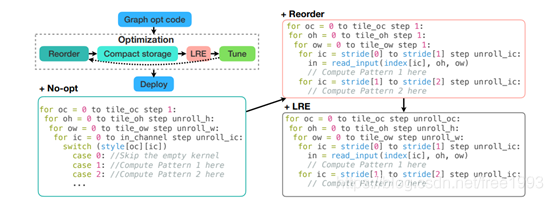
所谓的pattern sparsity就是以某种预定义稀疏的分布来mask相应的数据。这种方式因为知道预定义的sparsity的分布,所以在相应的硬件上进行加速是很方便的。这一部分可以参考王言治老师2020 asplos的论文,在论文中他们的加速方式是reorder和LRE。
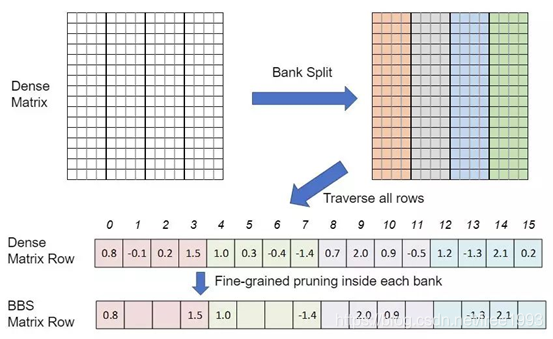
Bank-Balanced Sparsity(BBS)
对于一个稠密权值矩阵,首先将矩阵中的每一行分割成多个大小相同的bank。然后在每一行的每一个bank中采用细粒度剪枝方法。同时为了使每一个bank达到相同的稀疏度,对每一个bank的细粒度剪枝均采用相同的百分比作为阈值。
Sequence-to-sequence models
用于文本处理,包括recurrent neural networks (RNNs), gated recurrent units (GRU), long-short term memory。这类模型的特征是有大量的MLP.因为稀疏性主要来源于两个方面。
- dropout
- mlp参数矩阵中的0、非0元素。
Generative adversarial networks (GANs)
- 参数的稀疏性:generator and discriminative networks卷积参数的稀疏性
- Feature map的稀疏性:在generator网络中,GANs被要求遗忘一些生成的特征值(置0)
脉冲神经网络
脉冲神经网络的稀疏性主要来源于输入。脉冲神经网络中的神经元不是在每一次迭代传播中都被激活(而在典型的多层感知机网络中却是),而是在它的膜电位达到某一个特定值才被激活。当一个神经元被激活,它会产生一个信号传递给其他神经元,提高或降低其膜电位。
在脉冲神经网络中,神经元的当前激活水平(被建模成某种微分方程)通常被认为是当前状态,一个输入脉冲会使当前这个值升高,持续一段时间,然后逐渐衰退。出现了很多编码方式把这些输出脉冲序列解释为一个实际的数字,这些编码方式会同时考虑到脉冲频率和脉冲间隔时间。
因此脉冲神经网络的稀疏性主要来源于输入,输入每次被激活设为1,不被激活被设为0.
Graph neural networks (GNNs)
临近节点的embedding的向量,涉及矩阵乘。
Transformer
transformer中最重要的是self-attention结构。这种结构的稀疏性主要来源于两个方面。
- transformer根据score选出来的注意力矩阵:这个注意力矩阵关注一个词上面的所有单词,因此注意力是高度分散的。为了集中注意力在某几个单词上,sparse transformer被提出来了。
- 注意力矩阵:参与运算的参数的数值。
输入数据
推荐系统
推荐系统输入(图文、视频等)–召回(返回可能相关的结果,也就是候选结果的生成)–排序(基于上述的候选结果,进行排序,返回最有可能的结果。一般这些结果以概率的形式返回.一般会有各种各样的统计数值:CTR(点击量/展现量)、CVR(转换量/点击量)、CPM(消费量/展现量))。对于推荐系统里面来说,最重要的稀疏性一般来自于输入的特征。特征里面一般会有大量0值,那么现在的应用一般是需要设计编码方式来把输入的维度进行压缩的。
Embedding
经典的特征 Onehot 到稠密 Embedding 映射模式:几乎所有的深度学习推荐模型都会由Embedding层负责将高维稀疏特征向量转换成稠密低维特征向量。
Embedding,就是用一个低维稠密的向量“表示”一个对象,这里所说的对象可以是一个词(Word2Vec),也可以是一个物品(Item2Vec),亦或是网络关系中的节点(Graph Embedding)。其中“表示”这个词意味着Embedding向量能够表达相应对象的某些特征,同时向量之间的距离反映了对象之间的相似性。
user-item matrix
矩阵分解和协同过滤是经典的推荐算法,都可能存在交互(评分)矩阵稀疏的问题。矩阵分解需要”用户-物品”交互矩阵,这时候的数据稀疏,是由于用户的评分记录太少,交互矩阵的非零项很少。解决方案: 矩阵分解的优点就是相对能较好地处理数据稀疏问题。基于用户的协同过滤算法,主要思想就是相似用户有相似的喜好。当我们计算用户之间的相似度时,用户用评分向量表示,等价于计算不同用户的评分向量的相似度。如果评分向量大部分为空(几乎没有评分),没有区分度,这样的相似度衡量就不太准确。基于物品的矩阵分解类似
目标检测网络
目标检测网络输入是高维数据,例如自动驾驶场景中雷达检测到的3D点云,高维数据空间中,其实有用的点只集中在整个空间的一小部分。

文本分析
文本分析根据语料库中的单词来描述输入,但是一个document只有部分的单词,这导致了输入的稀疏性。
科学计算和传统的机器学习
科学计算是指利用计算机再现、预测和发现客观世界运动规律和演化特征的全过程。科学计算即是数值计算,科学计算是指应用计算机处理科学研究和工程技术中所遇到的数学计算。有关科学计算的一个例子就是一维弹簧系统。根据高数的知识,我们可以将参与运算的参数全部表示为矩阵。一般情况下,科矩阵计算计算的稀疏性主要来源于矩阵中的零值元素。例如稀疏矩阵如下图。所以我们的关键就是如何加速稀疏矩阵的计算。

利用系数矩阵的主要的方式有下面几种。
构造更为有效的数据结构
利用新的数据结果来表示稀疏矩阵。
- Dictionary of Keys:使用字典,其中行和列索引映射到值。
- List of Lists:矩阵的每一行都存储为一个列表,每个子列表包含列索引和值。
- Coordinate List :每个元组都存储一个元组列表,其中包含行索引、列索引和值。包括COO,CSR等具体的方法。对着这种常用方式的spmv(稀疏矩阵乘法)的加速。
降维
同系列文章参考
图层面的技术
神经网络编译器图层面IR
神经网络编译器-常量折叠
神经网络编译器优化-死代码消除
算子层面的技术
Halide-based IR和 Polyhedral-based IR简介
后端优化技术loop transformation
神经网络编译器的Tensor优化:auto tune和auto schedule


















 1228
1228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










