



一、前言
最近我想爬取一个网站,需要登录才能爬取里面的消息,接着我就使用了selenium登录,获取cookie,接着交给scrapy.Request请求,然后发现他还是重定向到了登录的页面,这个问题困扰了我好久,大概有一周了吧,今天看了一个帖子才解决。
二、解决方案
在函数__init__初始函数里设置self.meta
self.meta = {
'dont_redirect': True, # 禁止网页重定向
'handle_httpstatus_list': [301, 302] # 对哪些异常返回进行处理
}
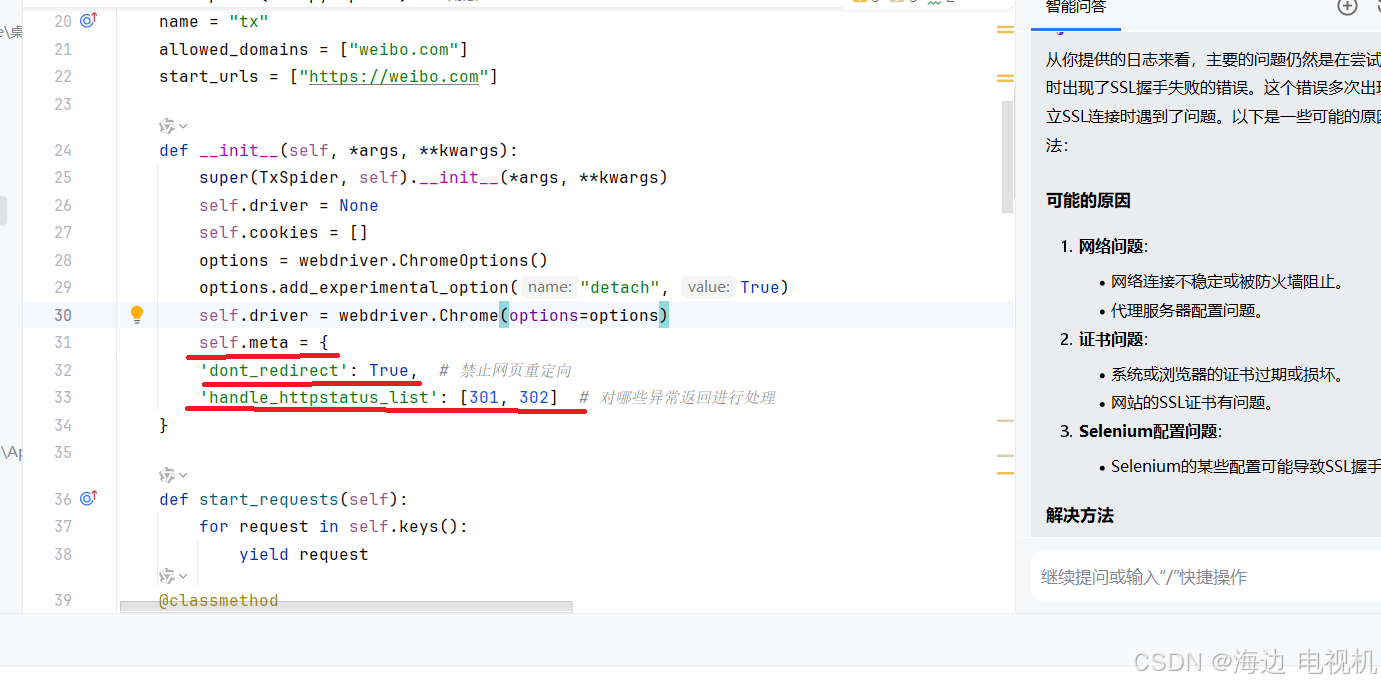
接着我们处理完cookie后,使用scrapy.Request返回cookie和self.meta
yield scrapy.Request(url=self.driver.current_url, callback=self.parse, cookies=self.cookies,meta=self.meta)
类似于这样,这样就可以防止爬取的页面重定向到登录页面。
三、结言
如果这篇文章能帮到你,我很开心为你节约了去除试错的时间,如果还有什么不懂的可以私信我


















 1907
1907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










